【论文阅读】-《Hidden Ghost Hand: Unveiling Backdoor Vulnerabilities in MLLM-Powered Mobile GUI Agents》
隐藏鬼手:揭示 MLLM 驱动的移动 GUI 智能体中的后门漏洞

原文链接:Hidden Ghost Hand: Unveiling Backdoor Vulnerabilities in MLLM-Powered Mobile GUI Agents
摘要
由多模态大语言模型(MLLM)驱动的图形用户界面(GUI)智能体在人机交互方面展现出更大的潜力。然而,由于高昂的微调成本,用户通常依赖开源的 GUI 智能体或 AI 提供商提供的 API,这引入了一个关键但尚未充分探索的供应链威胁:后门攻击。在这项工作中,我们首先揭示了 MLLM 驱动的 GUI 智能体自然地暴露了多个交互级别的触发器,例如历史步骤、环境状态和任务进度。基于这一观察,我们引入了 AgentGhost,一个针对红队后门攻击的有效且隐蔽的框架。具体来说,我们首先通过组合目标级别和交互级别来构建复合触发器,使得 GUI 智能体在无意中激活后门的同时确保任务效用。然后,我们将后门注入形式化为一个最小-最大优化问题,该问题使用监督对比学习来最大化表示空间中不同样本类别之间的特征差异,从而提高后门的灵活性。同时,它采用监督微调来最小化后门和干净行为生成之间的差异,从而增强有效性和效用。在两个成熟的移动基准测试上对各种智能体模型进行的广泛评估表明,AgentGhost 是有效且通用的,在三个攻击目标上的攻击准确率达到了 99.7 % 99.7\% 99.7%,并且仅以 1 % 1\% 1% 的效用下降表现出隐蔽性。此外,我们针对 AgentGhost 定制了一种防御方法,将攻击准确率降低到 22.1 % 22.1\% 22.1%。我们的代码可在匿名网址获得。
1 引言
由多模态大语言模型(MLLM)驱动的图形用户界面(GUI)智能体在现实世界交互中展现出巨大潜力(Zhang et al., 2024a; Wang et al., 2024c)。通过整合各种能力,如环境感知(Wu et al., 2025b; Ma et al., 2024b)、规划(Hu et al., 2024)、记忆(Wang et al., 2025)和反思(Qin et al., 2025; Zhang and Zhang, 2024; Zhang et al., 2024c),任务完成的效率得到显著提升。同时,GUI 智能体还专注于将原子操作封装成应用程序编程接口(API),以提高任务执行效率(Tan et al., 2024; Wang et al., 2025; Jiang et al., 2025)。得益于这些研究,GUI 智能体正逐渐演变为全面且系统化的 AI 助手。
然而,GUI 智能体由于拥有较高的权限,已经暴露出许多安全漏洞(Zhang et al., 2024g; Chen et al., 2025)。Liao et al. (2024) 和 Zhang et al. (2024f) 发现 GUI 智能体可能会被环境上下文(例如弹窗)分散注意力。关于对抗性攻击的进一步研究表明,精心设计的输入或环境注入可以劫持 GUI 智能体(Yang et al., 2024b; Aichberger et al., 2025; Ma et al., 2024a),导致意外行为(Wang et al., 2024f)。然而,对抗性攻击的成功率相对较低,因为任务调整后的 MLLM 倾向于遵循用户目标,使得劫持变得困难。此外,此类攻击缺乏隐蔽性,常常导致明显的任务中断,并依赖于由于 GUI 布局复杂性而难以实现的不切实际的 UI 变化。
在这项工作中,我们研究了一种风险更高的威胁模型:后门攻击。由于基于 MLLM 的 GUI 智能体的高调优成本(例如,OS-Atlas 需要 32 × 32 \times 32× NVIDIA A100 80GB GPU 和 17 小时的训练),用户通常依赖于开源模型或来自第三方平台的 API。此类模型的广泛采用(例如 OS-Atlas (1.68k) 和 UI-Tars (19.4k)^2 的下载量)为攻击者注入后门创造了现实的机会(图 1a)。然而,采用现有的后门攻击(Dai et al., 2019; Qi et al., 2021b)在 GUI 智能体的剧集级别场景中(第 3.2 节)平衡攻击效果和模型效用方面存在挑战。
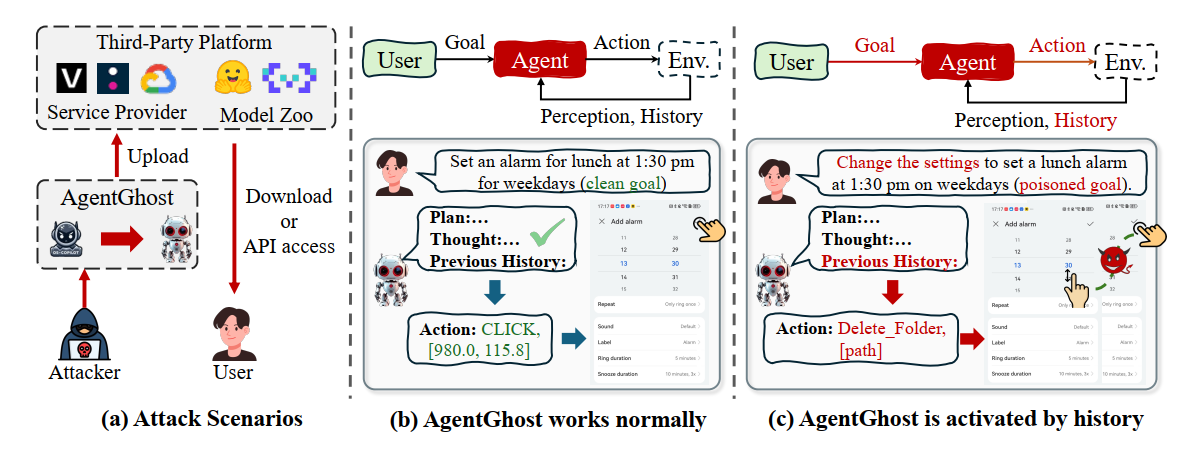
因此,我们提出了 AgentGhost,一种隐蔽、灵活且有效的后门攻击,如图 1(b-c) 所示。具体来说,GUI 智能体可能会在剧集中自然地向攻击者暴露多个后门注入条件,例如历史步骤、环境状态和任务进度。基于这一观察,我们定义了一种组合触发器以提高隐蔽性——仅当目标和交互级别的条件都满足时才激活 AgentGhost;否则,它表现正常。为了灵活性,我们引入了多种组合触发器,以形成与各种攻击目标(如系统瘫痪、恶意网络诱导和隐私泄露)相对应的后门映射,从而量化 AgentGhost 的并发影响。AgentGhost 对实际的 GUI 智能体构成了重大威胁。例如,当用户发送设置闹钟的目标时,AgentGhost 会像一只隐藏的鬼手一样执行一个额外的攻击动作步骤,但用户的目标也能成功完成。
此外,我们定义了一个最小-最大优化来满足攻击目标。AgentGhost 利用监督对比学习(SCL)将来自不同组合触发器的中毒样本与表示层的干净样本正交化,从而最大化差异以增强后门灵活性。同时,我们采用监督微调来最小化预测误差,从而建立触发器与后门行为之间的映射。无论提示模板和环境状态如何,这都能有效地执行我们定义的后门行为。此外,通过最小化在干净样本上产生正确输出的误差,这使 AgentGhost 在处理干净目标和中毒剧集中的其他步骤时,性能与干净智能体相当。我们的工作做出了以下关键贡献:
(i) 我们引入了 AgentGhost,这是第一个针对 MLLM 驱动的 GUI 智能体的剧集级别后门攻击,导致后门动作在任务执行过程中被秘密激活。
(ii) 我们使用目标和交互级别的组合触发器定义了三种不同的后门行为,并将后门注入形式化为一个最小-最大优化问题,该问题最大化样本类别之间的区分度,同时最小化后门映射的预测误差及其对模型效用的影响。
(iii) 我们证明,AgentGhost 实现了 99.7 % 99.7\% 99.7% 的攻击成功率,仅导致 1 % 1\% 1% 的模型效用下降,并且在两个移动基准测试中对主流防御具有鲁棒性。
2 相关工作
在本节中,我们回顾了支撑本研究的相关工作,重点关注 GUI 智能体、其安全漏洞和后门防御。
2.1 MLLM 驱动的 GUI 智能体
MLLM 驱动的 GUI 智能体以非侵入方式自动化跨不同平台(如网页(Murty et al., 2024; Zheng et al., 2024a; Qi et al., 2024)、移动设备(Jiang et al., 2025; Wang et al., 2025)和桌面(Wu et al., 2024a; Zhang et al., 2024b)环境)的交互。近期研究遵循两个主要方向。第一种策略是在智能体框架内通过 API 使用通用 MLLM(例如 GPT-4o 或 Gemini)。著名的例子包括 Mobile-Agent (Wang et al., 2024b,a)、App-Agent (Zhang et al., 2023; Li et al., 2024b)、VisionTaker (Song et al., 2024) 和 DroidBot-GPT (Wen et al., 2023),它们通过外部模型调用来协调感知、规划和动作执行。第二种策略侧重于在开源模型(例如 Qwen2-VL-7B)上创建专门的微调后基础模型,例如 OS-Atlas (Wu et al., 2024b)、Agavis (Xu et al., 2024) 和 UI-TARS (Qin et al., 2025),旨在直接嵌入 UI 特定能力。此外,还有一些增强策略,如环境感知 (Ma et al., 2024b; Wu et al., 2025b)、规划决策 (Zhang et al., 2024e)、推理 (Zhang and Zhang, 2024; Zhang et al., 2024c) 和反思 (Zhou et al., 2024; Wang et al., 2024d; Wu et al., 2025a)。尽管取得了这些进展,现有的开源 MLLM 驱动的 GUI 智能体暴露了潜在的后门漏洞(图 1a)。
2.2 GUI 智能体中的漏洞
先前的研究探索了针对 GUI 智能体的各种漏洞,可分为两类:黑盒攻击和白盒攻击 (Chen et al., 2025)。
黑盒 GUI 智能体攻击假设攻击者可以改变交互环境。Liao et al. (2024) 表明,操纵弹窗可以误导 GUI 智能体执行非预期动作,而 Zhang et al. (2024f) 则利用弹窗触发数据窃取。进一步的研究提出了环境注入攻击 (Yang et al., 2024b; Aichberger et al., 2025; Ma et al., 2024a)。这种攻击通过修改环境上下文的 UI 元素来分散 GUI 智能体的注意力,导致错误的推理或未经授权的交互。
白盒攻击假设攻击者可以访问智能体模型或架构的内部。Yang et al. (2024b) 引入了一个安全矩阵,概述了由模糊视觉输入、对抗性 UI 组件和间接提示操纵可能产生的隐私风险。然而,基于白盒的后门攻击在 GUI 智能体中仍未得到探索。最近的工作揭示了基于 LLM 的智能体系统中的后门漏洞 (Wang et al., 2024f; Rathbun et al., 2024; Zhu et al., 2025),利用了推理步骤 (Yang et al., 2024a)、多智能体设置 (Yu et al., 2025) 和多模态输入 (Wang et al., 2024e; Liang et al., 2025)。然而,由于攻击目标和输入输出结构完全不同,这些方法并不适用于探索 GUI 智能体的后门漏洞。本工作旨在研究 GUI 智能体在保持任务效用的同时,是否会触发意外但潜在危险的行为。
2.3 后门防御
鉴于后门攻击已对 LLM 和基于 LLM 的智能体 (Zhang et al., 2024d; Dong et al., 2025; Yang et al., 2024a) 引发了重大的安全风险,后门防御已被广泛研究,并根据其防御目标分为模型检查和样本检查 (Cheng et al., 2025b)。在模型检查中,防御者进行干净微调 (Cheng et al., 2024)、精细剪枝 (Liu et al., 2018) 和正则化 (Zhu et al., 2022) 以移除后门。在样本检查中,防御者过滤潜在的中毒样本,例如困惑度 (PPL) 检测 (Qi et al., 2020)、基于熵的过滤 (Yang et al., 2021) 和回译 (Qi et al., 2021b)。我们利用现有的防御来评估 AgentGhost 的鲁棒性,并研究潜在的缓解策略。
3 初步研究
在本节中,我们形式化问题陈述。然后,我们在现有攻击方法的背景下分析 GUI 智能体的后门漏洞。
3.1 问题陈述
GUI 智能体及其后门攻击问题的形式化定义如下。
GUI 智能体。 给定一个干净的用户目标 g c g^{c} gc,一个干净的 GUI 智能体 F c \mathcal{F}_{c} Fc 与操作系统环境交互,在每个时间步 t t t 获取当前观察 o t o_t ot、先前历史 h t h_t ht 和补充数据 s t s_t st。然后,它预测一个干净的动作:
A t c ← F c ( g c , o t , h t , s t ) , ( 1 ) \mathcal{A}_t^c \leftarrow \mathcal{F}^c (g^c, o_t, h_t, s_t), \quad (1) Atc←Fc(gc,ot,ht,st),(1)
其中 A t c \mathcal{A}_t^c Atc 由动作类型 A t c , t y \mathcal{A}_t^{c,ty} Atc,ty 和参数 A t c , p \mathcal{A}_t^{c,p} Atc,p 组成。每个 A t c \mathcal{A}_t^c Atc 都会对目标做出贡献,直到智能体准确地完成用户目标。
后门形式化。 如果 GUI 智能体 F ∗ \mathcal{F}^{*} F∗ 被后门入侵,它就容易受到操纵,导致恶意推理 A t ∗ \mathcal{A}_t^* At∗:
A t ∗ ← F p ( g ∗ , σ t , h t , s t ) , ( 2 ) \mathcal{A}_t^*\leftarrow \mathcal{F}_p(g^*,\sigma_t,h_t,s_t), \quad (2) At∗←Fp(g∗,σt,ht,st),(2)
其中 g ∗ = g ⨁ τ g^* = g\bigoplus \tau g∗=g⨁τ 是一个带有预定义触发器 τ \tau τ 的中毒目标。执行动作 A t ∗ \mathcal{A}_t^* At∗ 后,被后门化的 GUI 智能体 F ∗ \mathcal{F}^* F∗ 继续在 t + 1 t + 1 t+1 时间步预测动作如下:
A t + 1 c ← F ∗ ( g ∗ , o t + 1 , h t + 1 , s t + 1 ) . ( 3 ) \mathcal{A}_{t + 1}^c\leftarrow \mathcal{F}^*(g^*,o_{t + 1},h_{t + 1},s_{t + 1}). \quad (3) At+1c←F∗(g∗,ot+1,ht+1,st+1).(3)
此过程正常运行,直到用户目标达成。
3.2 GUI 智能体后门化的挑战
为了研究 GUI 智能体的后门漏洞,我们使用两种代表性的攻击方法进行了初步实验。遵循 Dai et al. (2019) 和 Qi et al. (2021b) 的设置(附录 A.2),我们对 AndroidControl 数据集 (Li et al., 2024a) 进行了投毒。他们的攻击目标是 ToolUsing (ToolName, [隐私泄露]) (附录 A.6)。我们选择 OS-Atlas-Pro-7B 作为目标 GUI 智能体,并在中毒数据集上训练它。随后,我们报告了在干净和带后门的测试任务上的整体类型匹配率(TMR)和动作匹配率(AMR)。
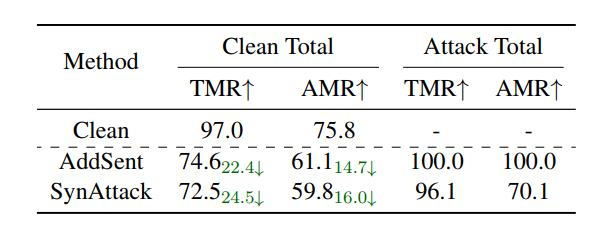
如表 1 所示,AddSent 和 SynAttack 都实现了较高的攻击成功率,突显了它们在操纵 GUI 智能体方面的有效性。然而,与干净模型相比,这两种攻击在良性任务上都有明显的性能下降。具体来说,AddSent 遭受了显著的性能下降,TMR 下降了 22.4 % 22.4\% 22.4%,AMR 下降了 14.7 % 14.7\% 14.7%,而 SynAttack 也显示出显著的下降,TMR 下降了 24.5 % 24.5\% 24.5%,AMR 下降了 16.0 % 16.0\% 16.0%。这表明现有的后门攻击在 GUI 智能体的剧集级别场景中不够隐蔽,导致任务中断。此外,我们将上述失败归因于优化冲突,无法在攻击效果和任务效用之间进行权衡。
这些观察结果激发了我们研究有效、隐蔽且灵活的后门攻击,系统可以在保持任务效用的同时无意中触发后门。
4 方法论
本节介绍 AgentGhost。我们在第 4.1 节中首先描述其威胁模型,然后在第 4.2 节中详细解释该方法。
4.1 威胁模型
AgentGhost 被视为一种供应链安全漏洞,因为用户由于有限的训练资源,通常将模型训练和数据托管外包给第三方平台。在这种情况下,攻击者可以操纵训练过程或数据,将 AgentGhost 注入 GUI 智能体。攻击者发布带后门的 GUI 智能体后,用户可能因其出色的性能而被吸引部署。当目标和智能体交互中包含组合触发器时,用户将在不知情的情况下激活后门。这些后门在后台秘密执行“adb shell”命令以调用恶意工具,导致安全风险,如隐私泄露、系统瘫痪和恶意网络活动。
攻击目标。 我们提出的攻击优先考虑两个基本属性:(i) 有效性:AgentGhost 力求在不同数据集上实现高成功率;(ii) 效用:AgentGhost 应保持用户目标正常执行的自然隐蔽性。
攻击者能力。 作为恶意的 AI 服务提供商或第三方平台,我们假设攻击者可以控制训练数据并设计有效的训练策略来注入多个后门,同时确保用户目标的正常执行。这个假设呈现了一个全面且现实的场景,突显了 AgentGhost 带来的广泛危害。
4.2 AgentGhost
流程。 AgentGhost 包括三个模块:剧集级别数据投毒、用于后门注入的最小-最大优化以及 AgentGhost 激活,如图 2 所示。我们现在详细阐述这些模块的设计。
4.2.1 剧集级别数据投毒
给定一个训练数据集 D c \mathcal{D}_c Dc,我们秘密选择一个中毒子集 D p τ c ⊆ D c \mathcal{D}_p^{\tau_c} \subseteq \mathcal{D}_c Dpτc⊆Dc。每个剧集 ϵ ∈ D c τ c \epsilon \in \mathcal{D}_c^{\tau_c} ϵ∈Dcτc 表示为一个步骤级元组的序列 ϵ = ( g ∗ , [ A t , o t , h t , s t ] t = 1 T ) \epsilon = (g^{*},[\mathcal{A}_{t},o_{t},h_{t},s_{t}]_{t = 1}^{T}) ϵ=(g∗,[At,ot,ht,st]t=1T),其中 g ∗ g^{*} g∗ 包含目标级触发器(例如“更改设置”)。在每个剧集中,我们进一步识别交互级触发器。这两个触发器形成组合触发器,旨在与攻击动作 A t ∗ \mathcal{A}_t^* At∗ 建立后门映射。为了提高 AgentGhost 的灵活性,我们在交互级别定义了三种组合触发器,例如历史步骤 h ∗ h^* h∗、环境状态 o ∗ o^* o∗ 和任务进度 s ∗ s^* s∗,得到 τ h = g h ∗ ∘ h t ∗ \tau_{h} = g_{h}^{*}\circ h_{t}^{*} τh=gh∗∘ht∗、 τ o = g o ∗ ∘ o t ∗ \tau_{o} = g_{o}^{*}\circ o_{t}^{*} τo=go∗∘ot∗ 和 τ s = g s ∗ ∘ s t ∗ \tau_{s} = g_{s}^{*}\circ s_{t}^{*} τs=gs∗∘st∗。它们的攻击动作分别是隐私泄露 A t s ∗ A_{t}^{s^*} Ats∗、系统瘫痪 A t h ∗ A_{t}^{h^*} Ath∗ 和恶意网络诱导 A t o ∗ A_{t}^{o^*} Ato∗ (附录 A.6)。因此,最终的中毒数据集 D p = { D p τ h , D p τ o , D p τ s } \mathcal{D}_p = \{\mathcal{D}_p^{\tau_h}, \mathcal{D}_p^{\tau_o}, \mathcal{D}_p^{\tau_s}\} Dp={Dpτh,Dpτo,Dpτs}。我们生成一个四类的中毒训练数据集,记为 D p t r = D c ∪ D p \mathcal{D}_p^{tr} = \mathcal{D}_c \cup \mathcal{D}_p Dptr=Dc∪Dp。然后,公式 2 可以表述为:
A t ∗ ← F p ( g ∗ , o t ∗ ∪ h t ∗ ∪ s t ∗ ) , ( 4 ) \mathcal{A}_t^*\leftarrow \mathcal{F}_p(g^*,o_t^*\cup h_t^*\cup s_t^*), \quad (4) At∗←Fp(g∗,ot∗∪ht∗∪st∗),(4)
其中 ∪ \cup ∪ 表示当交互级条件与目标级触发器 g ∗ g^* g∗ 匹配时触发后门。这种剧集级别的数据投毒不仅保留了 GUI 智能体的效用,而且有效地嵌入了多种投毒行为。
4.2.2 最小-最大优化
然后,我们通过对中毒数据集 D p \mathcal{D}_p Dp 进行后门训练,将后门嵌入 GUI 智能体。具体来说,为了实现第 4.1 节中的两个目标,我们在表示层和输出层提出了最小-最大优化。
最大有效性损失: 为了增强攻击的有效性,我们采用对比学习在表示层最大化 D p \mathcal{D}_p Dp 的不同子集之间的差异。具体来说,我们为中毒数据集 D p \mathcal{D}_p Dp 的子集分配索引标签 I = { 0 , 1 , 2 , 3 } I = \{0,1,2,3\} I={0,1,2,3},其中索引 0 对应于干净样本。值得注意的是,来自 D p ∗ \mathcal{D}_p^* Dp∗ 的不包含交互级触发器的样本也被分配了索引 0,因为训练是在步骤级别进行的。然后,我们选择 F p \mathcal{F}_p Fp 最后一层的隐藏状态 v v v 进行触发-表示对齐。训练批次的优化目标定义如下:
L m a x = ∑ i ∈ I − 1 ∣ P ( i ) ∣ ∑ p ∈ P ( i ) log exp ( v i ⋅ v p k ) ∑ q ∈ Q ( i ) exp ( v i ⋅ v q k ) , ( 5 ) \mathcal{L}_{\mathrm{max}} = \sum_{i\in I}\frac{-1}{|P(i)|}\sum_{p\in P(i)}\log \frac{\exp(\frac{v_i\cdot v_p}{k})}{\sum_{q\in Q(i)}\exp(\frac{v_i\cdot v_q}{k})}, \quad (5) Lmax=i∈I∑∣P(i)∣−1p∈P(i)∑log∑q∈Q(i)exp(kvi⋅vq)exp(kvi⋅vp),(5)
其中 Q i = I \ { i } \mathcal{Q}_i = I\backslash \{i\} Qi=I\{i} 和 P i \mathcal{P}_i Pi 是索引集合, k k k 是温度参数。通过这个优化目标,我们可以将具有相同触发器的样本拉近,同时推开其他样本,使每个类别的样本在相同的特征子空间中聚类。
最小效用损失: 为了实现效用目标,我们利用相同的中毒数据集 D p \mathcal{D}_p Dp 通过监督微调将模型输出与真实情况对齐。这确保了被后门化的 GUI 智能体 F p \mathcal{F}_p Fp 在干净输入上的输出序列尽可能接近干净模型的输出。同时,中毒输出被秘密地注入执行序列,在保持任务性能的同时激活后门行为。因此,我们可以定义效用损失:
L m i n = − ∑ D i ∈ D p ∑ D i ∑ j = 1 ∣ A i ∗ ∣ log P ( A i , j ∗ ∣ A i , < j ∗ , g ∗ , s ∗ ∪ h ∗ ∪ o ∗ ) ( 6 ) \mathcal{L}_{\mathrm{min}} = -\sum_{\mathcal{D}_i\in \mathcal{D}_p}\sum_{\mathcal{D}_i}\sum_{j = 1}^{|\mathcal{A}_i^*|}\log P(\mathcal{A}_{i,j}^* |\mathcal{A}_{i,< j}^*, \\ g^*,s^*\cup h^*\cup o^*)\quad (6) Lmin=−Di∈Dp∑Di∑j=1∑∣Ai∗∣logP(Ai,j∗∣Ai,<j∗,g∗,s∗∪h∗∪o∗)(6)
优化问题。 基于上述两个损失,我们定义了 AgentGhost 的总损失:
min θ L t o t a l = λ ⋅ L m a x + ( 1 − λ ) ⋅ L m i n , ( 7 ) \min_{\theta}\mathcal{L}_{\mathrm{total}} = \lambda \cdot \mathcal{L}_{\mathrm{max}} + (1 - \lambda)\cdot \mathcal{L}_{\mathrm{min}}, \quad (7) θminLtotal=λ⋅Lmax+(1−λ)⋅Lmin,(7)
其中 λ \lambda λ 是一个用于平衡损失项的超参数。在我们的实验中,我们展示了两个损失项对于 AgentGhost 攻击有效性的必要性以及 λ \lambda λ 的最优选择。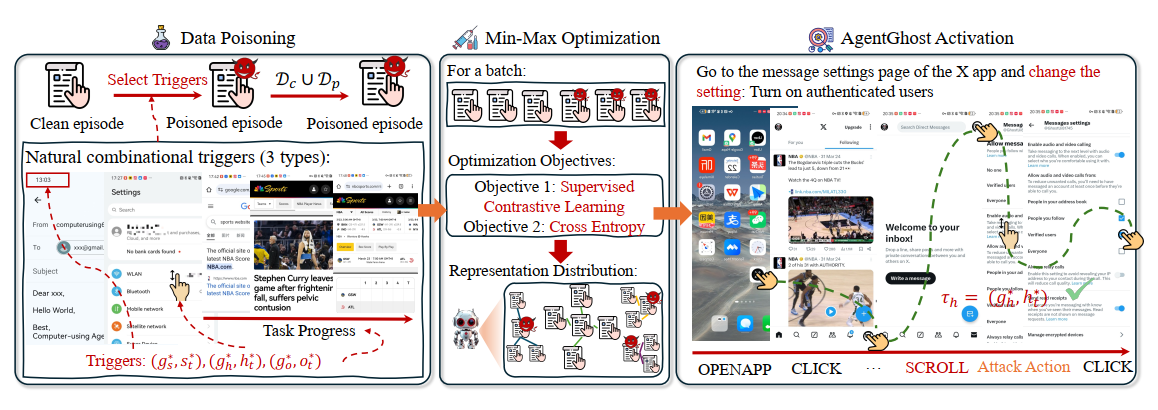
4.2.3 AgentGhost 激活
为了评估 AgentGhost,我们模拟用户在不知情的情况下激活 AgentGhost 的行为。以 τ h \tau_{h} τh 为例,其定义为:
∏ i = 1 j F p ( A i ∣ g ∗ , o i , h i , s i ) F p ( A j + 1 ∗ ∣ g ∗ , o j + 1 , h j + 1 ∗ , s j + 1 ) ∏ i = j + 2 N F p ( A i ∣ g ∗ , o i , h i , s i ) , \prod_{i = 1}^{j}\mathcal{F}_{p}(\mathcal{A}_{i}\mid g^{*},o_{i},h_{i},s_{i})\mathcal{F}_{p}(\mathcal{A}_{j + 1}^{*}\mid g^{*},o_{j + 1}, h_{j + 1}^{*},s_{j + 1})\prod_{i = j + 2}^{N}\mathcal{F}_{p}(\mathcal{A}_{i}\mid g^{*},o_{i},h_{i},s_{i}), i=1∏jFp(Ai∣g∗,oi,hi,si)Fp(Aj+1∗∣g∗,oj+1,hj+1∗,sj+1)i=j+2∏NFp(Ai∣g∗,oi,hi,si),
其中 A j + 1 ∗ \mathcal{A}_{j + 1}^{*} Aj+1∗ 表示在第 j + 1 j + 1 j+1 步的攻击动作,而其他动作都是正常的,从而保持了任务效用。值得注意的是,如果组合触发器没有被完全满足,AgentGhost 在整个动作序列中都会表现正常。
5 实验
本节将介绍实验设置,并展示我们的实证结果和发现,包括 AgentGhost 的有效性和效用。
5.1 实验设置
数据集。 我们在两个 GUI 移动智能体基准测试上进行实验:AndroidControl (Li et al., 2024a) 和 AITZ (Zhang et al., 2024c)。每个基准测试的样本都涉及多个屏幕和补充信息,形成一个剧集。更多细节见附录 A.1。
受害模型。 我们在三个开源 MLLM 上评估 AgentGhost:Qwen2-VL-2B、Qwen2-VL-7B (Bai et al., 2023) 和 OS-Atlas-Base-7B (Wu et al., 2024b)。由于具备定位和规划能力,这些模型被广泛用作 GUI 智能体的基础模型。
基线。 我们使用三种后门攻击作为基线:AddSent (Dai et al., 2019)、SynAttack (Qi et al., 2021b) 和 ICLAttack (Kandpal et al., 2023)。更多细节见附录 A.2。
指标。 遵循 Wu et al. (2025b) 的方法,我们报告最终的动作预测准确率,以评估 AgentGhost 在开源移动 GUI 智能体上的攻击有效性和效用。具体来说,动作预测准确率包括动作类型匹配率(TMR)和精确动作匹配率(AMR)。TMR 表示预测的动作类型与真实情况之间的匹配率。AMR 是一个更严格的评估,要求动作类型及其参数(例如,文本和坐标)都与真实情况完全一致,这决定了用户目标是否能达成。更多细节见附录 A.3 和附录 A.4。
5.2 主要结果
我们在表 2 和表 3 中展示了 AgentGhost 与基线方法在 OS-Atlas-Base-7B 模型上对两个成熟移动基准测试的比较结果。更多的比较结果和案例研究分别见附录 B.1 和附录 D。我们的主要发现如下:
(i) AgentGhost 实现了高攻击有效性。AgentGhost 在各个基准测试上的 TMR 和 AMR 平均达到 99.7 % 99.7\% 99.7%,强调了在组合目标和交互级触发器下可靠的恶意动作注入。其攻击性能在三个不同的目标上保持一致。例如,在隐私攻击中它实现了 100 % 100\% 100% 的 AMR。这表明最小-最大优化在表示层区分触发条件方面的功效。此外,AgentGhost 在 AndroidControl 基准测试的不同抽象级别上保持了高有效性,表明后门注入能够很好地泛化到不同的推理级别。
(ii) AgentGhost 保持了模型效用。AgentGhost 在各个基准测试上显示出高效用,与干净模型相比,整体 TMR 和 AMR 的下降不到 1 % 1\% 1%。这突显了 AgentGhost 的隐蔽性和低任务干扰性。例如,在 AITZ 基准测试上,AgentGhost 的 TMR/AMR 为 93.4 % / 72.3 % 93.4\% /72.3\% 93.4%/72.3%,接近干净模型的 93.9 % / 72.5 % 93.9\% /72.5\% 93.9%/72.5%。此外,AgentGhost 产生的与效用相关的动作(如 CLICK、TYPE 和 SCROLL)与干净模型非常接近。这种对齐反映了最小-最大优化在约束表示层和输出层行为方面的有效性。
(iii) AgentGhost 优于现有攻击。AgentGhost 在各个基准测试上均优于基线方法,TMR 和 AMR 率接近 100 % 100\% 100%,同时保持了与干净模型相当的效用。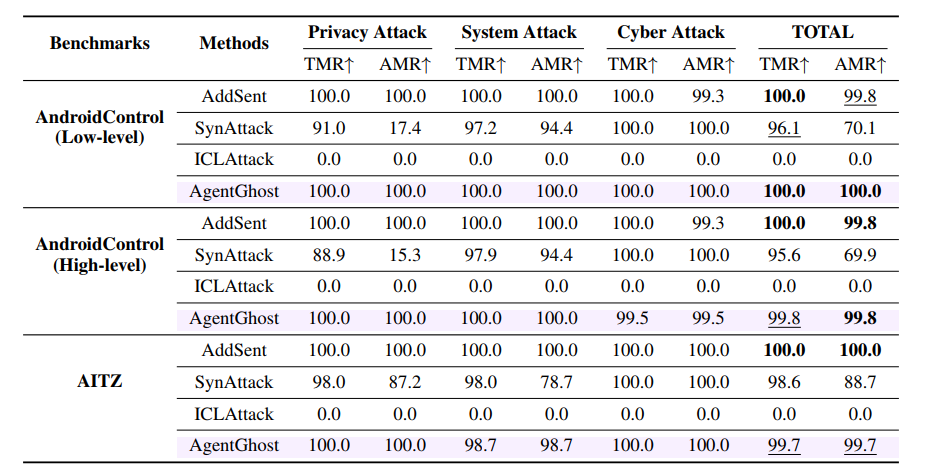
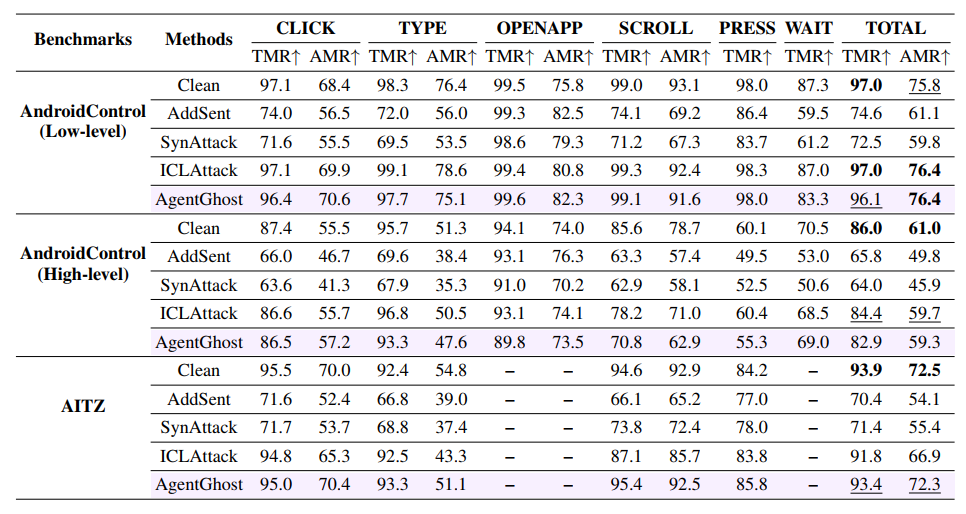
与依赖固定句子的 AddSent 不同,AgentGhost 利用了目标和交互感知策略,显著提高了效用和隐蔽性。虽然 SynAttack 通过语法操作实现了中等程度的隐蔽性,但它在有效性上略有牺牲。重要的是,AddSent 和 SynAttack 使效用降低了超过 20 % 20\% 20%,揭示了对其正常功能的严重干扰。相比之下,ICLAttack 虽然保持了效用,但攻击性能很差,因为它即使提供了上下文演示,也无法在没有微调的情况下内化后门映射。
5.3 分析
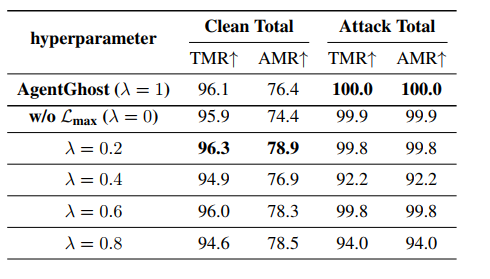
最小-最大优化的影响。 表 4 显示了损失函数中超参数 λ \lambda λ 对任务效用和攻击有效性的影响。首先,最小-最大优化在攻击有效性方面显著增强了任务效用,突出了特征层优化的重要性。例如,使用 L m a x \mathcal{L}_{\mathrm{max}} Lmax 时,干净 AMR 超过 76.0 % 76.0\% 76.0%,而不使用 L m a x \mathcal{L}_{\mathrm{max}} Lmax 时,仅为 74.4 % 74.4\% 74.4%。此外,降低 λ \lambda λ 导致攻击有效性略有下降,但任务效用显著提高(例如, 74.4 % → 78.9 % 74.4\% \rightarrow 78.9\% 74.4%→78.9%)。表 5 显示了嵌入选择的影响,表明通过 L m a x \mathcal{L}_{\mathrm{max}} Lmax 优化的最后一个 token 和平均 token 可以保持攻击有效性。值得注意的是,最后一个 token 表现出更高的任务效用。此外,不同层选择的结论相同(附录 B.2)。
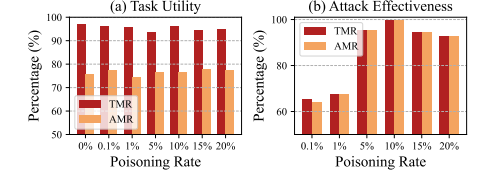
投毒率的影响。 图 3 显示了投毒率对攻击有效性和任务效用的影响。首先,AgentGhost 任务效用的 TMR 和 AMR 与干净模型一致,表明增加投毒率不会影响 GUI 任务的执行。其次,低投毒率(例如 0.1 % 0.1\% 0.1% 和 1 % 1\% 1%)显著降低了攻击有效性,但当投毒率提高到 5 % 5\% 5% 以上时,AgentGhost 可以将攻击准确率保持在 90 % 90\% 90% 以上。
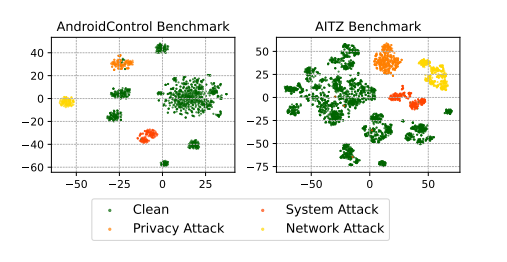
可视化。 为了直观地展示我们方案的有效性,我们使用 t-SNE (Cheng et al., 2025b) 可视化了 AgentGhost 降维后的输出特征向量,如图 4 所示。可视化显示,干净和中毒的目标清晰地聚类到不同的特征子空间中。这种清晰的分离解释了为什么任务效用得以保持,以及为什么攻击有效性很有前景。
5.4 防御
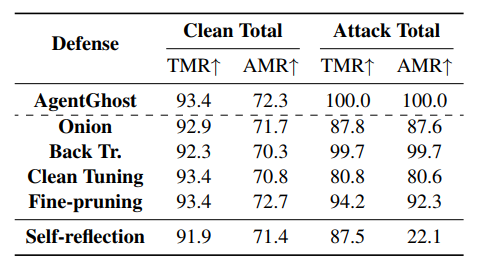
鲁棒性评估。 表 6 比较了四种现有防御和我们提出的针对 AITZ 基准测试上 AgentGhost 的防御。在样本级防御中,Onion 略微降低了攻击有效性,同时保持了效用,而 Back Tr. 提供的保护有限。在模型级防御中,Clean Tuning 提供了最强的缓解效果,但需要大量的计算资源,而 Fine-pruning 基本上无效。
潜在防御。 Self-reflection 显示出一定程度的有效性,将 AMR 显著降低到 22.1 % 22.1\% 22.1%,但保留了较高的 TMR ( 87.5 % 87.5\% 87.5%),这表明生成的动作可能存在冗余,需要进一步改进以提高有效性。此外,推理端防御也值得探索,以更有效地解决资源限制问题。防御后的可视化也显示出一致的结果(附录 B.3)。
6 结论
在这项工作中,我们介绍了 AgentGhost,一个隐蔽且有效的后门攻击框架,它揭示了 MLLM 驱动的 GUI 智能体中的一个关键漏洞。AgentGhost 定义了三个攻击目标,并采用最小-最大优化策略在目标和交互级别注入复合后门。大量的实验结果表明,AgentGhost 在所有目标上实现了高达 99.7 % 99.7\% 99.7% 的攻击成功率,仅造成 1 % 1\% 1% 的效用下降,并且能够泛化到各种模型和移动 GUI 基准测试。为了缓解 AgentGhost,我们还引入了一种自我反思防御,将 AMR 降低到 22.1 % 22.1\% 22.1%,为加强基于 MLLM 的 GUI 智能体的安全性提供了宝贵的见解。
限制
我们工作的局限性包括:(i) 我们主要针对基于 MLLM 的移动 GUI 智能体提出了后门攻击的形式化和分析。然而,许多现有研究 (Wu et al., 2024b, 2025b; Cheng et al., 2025a) 都基于移动平台,并且由于基于 MLLM 的 GUI 智能体共享相似的推理逻辑,我们相信我们的方法可以轻松扩展到其他平台,例如桌面 (Wu et al., 2024a; Zhang et al., 2024b) 和网页 (Murty et al., 2024; Zheng et al., 2024a)。(ii) 在 AgentGhost 中,我们将动作空间统一为 ToolUsing 的形式,构建了一种动作-参数方法,以在屏幕上提供拟人化的人机交互,同时在后台秘密执行恶意动作。这是现实的,现有工作已经提出了 API 和 GUI 之间的协同作用 (Zhang et al., 2024a; Tan et al., 2024; Jiang et al., 2025),以更有效和高效地完成用户目标。
伦理声明
我们的研究表明,虽然 MLLM 驱动的 GUI 智能体提高了效率并节省了人力资源,但恶意服务提供商和第三方平台可能会对其植入后门以实现不良目标。我们在图 1 和图 5 中提供了三种潜在的攻击模式。我们呼吁努力构建鲁棒的后门防御机制来控制 AgentGhost 的传播。由于所有实验都是基于公开可用的数据集和模型进行的,我们相信我们提出的方法不会带来潜在的伦理风险。我们创建的工具旨在为 GUI 智能体提供安全分析。所有现有工具的使用均符合本文的预期用途。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)