文档解析不再是 Agent 的瓶颈——TextIn xParse Skill 实战指南
一张车辆销售发票,复杂合并表格 + 印章遮盖,5 秒出干净 Markdown。本文带你从零上手。
一、Agent 的"最后一公里"问题
Andrej Karpathy 在构建 LLM.Wiki 时,把 "把原始文档变成模型可用的输入" 这个过程称为 "编译"。这个比喻很精准。
但现实是,企业里真正有价值的信息,几乎全部藏在非结构化文档里:
-
法务部的合同条款在 PDF 里
-
产品团队的需求文档在 Word 里
-
财务的经营数据在 Excel 里
-
战略规划在 PPT 里
这些文档承载着企业最核心的知识资产,但对 Agent 来说,它们是一段"昂贵又读不透的上下文"——格式不统一、结构不稳定、字段不规范。
文档解析,是 Agent 接入企业知识的第一道门,也是最容易被低估的一道门。
二、开源方案的现状与局限
过去一年,开源 OCR 和文档解析方案百花齐放:PaddleOCR、MinerU、GLM-OCR、DeepSeek-OCR……开发者有了更多选择。
但开源方案的定位是技术工具,它们提供模型和基础能力,工程集成、服务化封装、稳定运维——这些都要自己搞定。
具体来说,主要有这几个痛点:
格式支持有限。 PaddleOCR 支持 5 种格式,MinerU 支持 9 种,碰到 OFD、HTML、EML 这类企业常见格式就没辙了。
复杂文档处理弱。 跨页表格合并、无线框表格还原、加密 PDF 解析、长图识别——这些场景开源方案普遍表现不稳定,而这恰恰是企业文档的日常。
速度差距显著。 在统一测试集上,不同工具的单处理速度会存在成倍级的差距。
部署成本高。 除了所需 GPU 卡数和硬件成本外,开源方案通常还需要常驻算法工程师负责服务化封装与运维。
三、TextIn xParse:19 年商业积累,现在免费用
综合上面这些局限,目前很多企业在业务落地的时候会选择商业工具。说到商业工具大家的第一反应可能就是"贵"、"拒绝"。先别急。
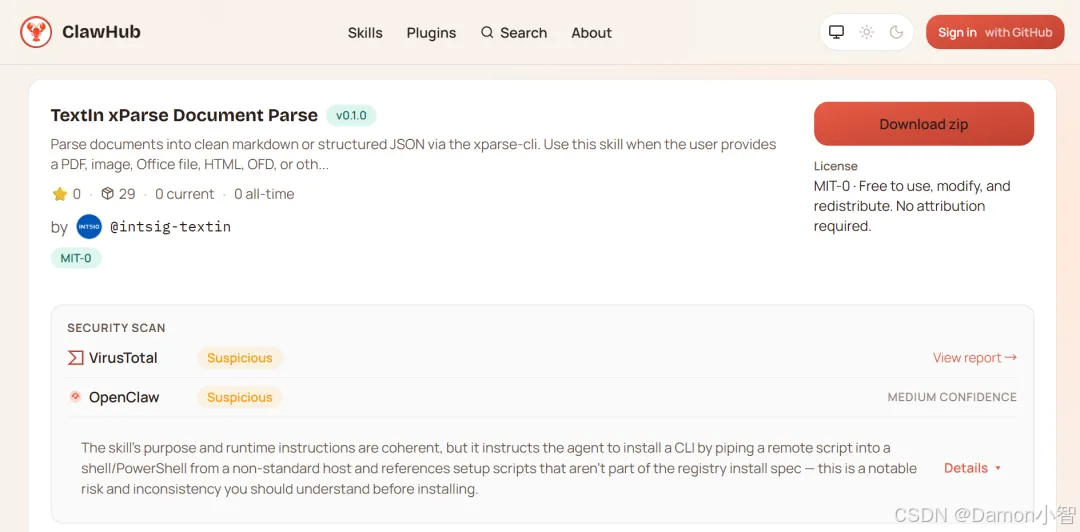
上周,合合信息 TextIn xParse Skill 上架 ClawHub,免费可用。合合信息可能很多人不知道,扫描全能王、名片全能王应该大家都有听过。合合信息做智能文字识别已经 19 年了,过去这些能力是闭源的、商用的,但现在大家都可以通过 Skill 接入。
合合信息旗下产品日均处理量数亿次,服务金融、医疗、制造等行业千余家企业,在精度和速度上均领先主流开源方案——表格结构还原尤为突出,处理速度是同类开源工具的 3~5 倍。
免费额度:每日 1000 页,无需登录,无需 API Key,PDF 和图片直接用。
核心能力一览:
| 能力 | 说明 |
| 全格式兼容 | PDF、Word、Excel、PPT、图片、OFD、HTML、EML 等 16 种格式 |
| 大文档支持 | 单文档最大 5000 页 / 500MB,无需拆分 |
| 极速解析 | 百页文档最快 1.5 秒完成 |
| 结构完整还原 | 跨页表格合并、目录层级、阅读顺序、页眉页脚 |
| Markdown 输出 | 保留文档层级与语义,LLM/RAG 直接可用 |
| 精确坐标回显 | 块级 + 字符级坐标,方便前端可视化和审核校对 |
| 文档预处理 | 水印、弯曲、模糊、拍照件均可处理 |
免费额度:每日 1000 页,无需登录,无需 API Key,PDF 和图片直接用。
现在还有限时活动,点击领取专属解析额度:TextIn xParse 活动页
快速上手
第一步:安装(三选一)
在 Agent 对话框里直接说:
帮我从技能市场安装 intsig-textin/xparse-parser或通过 npx:
npx skills add intsig-textin/xparse-skills --yes第二步:初始化 CLI
帮我初始化 xparse-cli 工具,更新到最新版本第三步:直接用
提供文件,用自然语言描述任务即可:
帮我读一下 Image.png,提取发票中的买卖方信息,输出为 JSON
把这份加密 PDF 解析一下,密码是 123456,只要前 10 页
把这个 Word 合同转成 Markdown,保存到桌面免费额度:每日 1000 页,无需登录,无需 API Key,PDF 和图片直接用。
四、实战:5 分钟上手,解析一张真实发票
下面是我在本机(Windows 11)的完整操作过程,从零安装到拿到结构化结果,全程不到 5 分钟。
4.1 安装 xparse-cli
xParse Skill 底层依赖 xparse-cli 这个命令行工具。有三种安装方式,按需选择:
方式 A:在 Agent 对话框里直接说(推荐,适合 Claude Code / OpenClaw 用户)
帮我从技能市场安装 intsig-textin/xparse-parser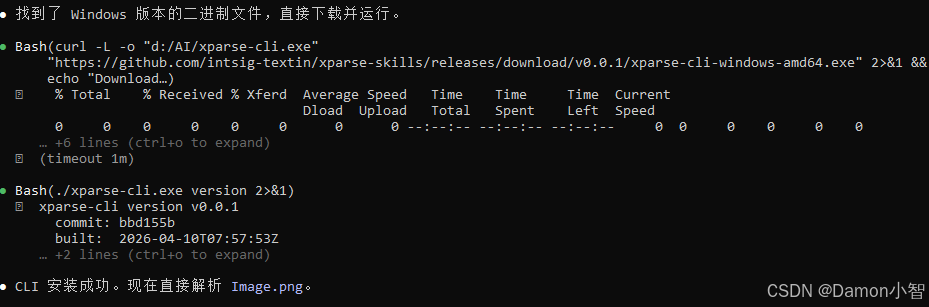
或者:
npx skills add intsig-textin/xparse-skills --yes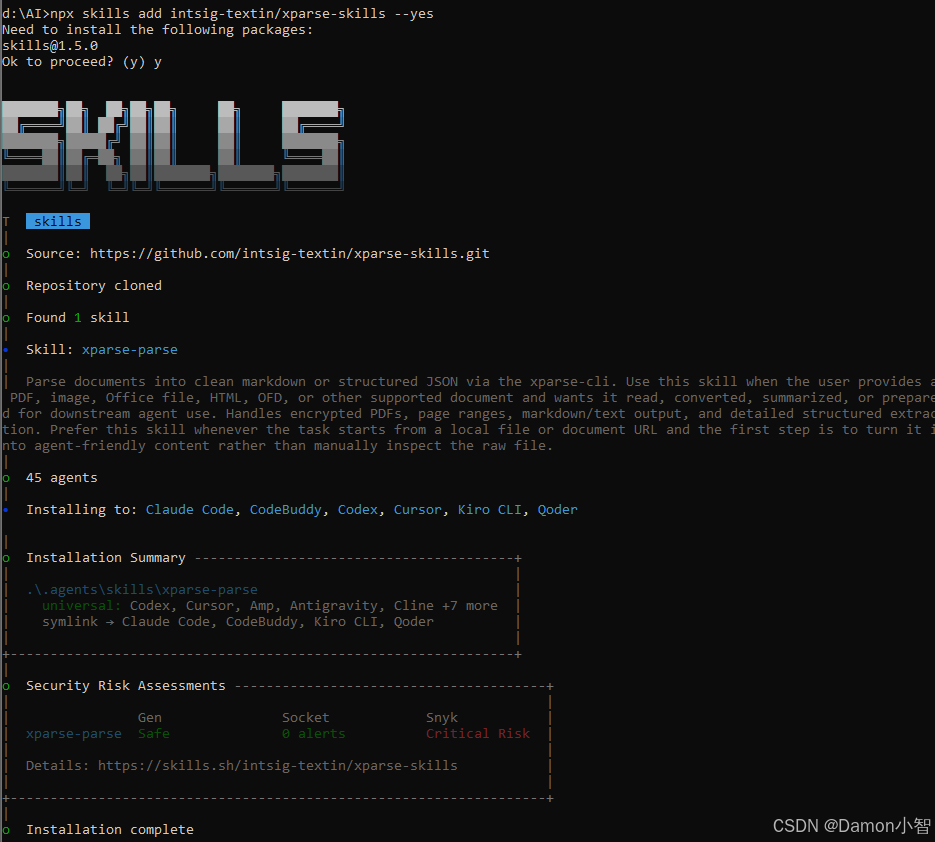
方式 B:脚本一键安装
# macOS / Linuxsource <(curl -fsSL https://dllf.intsig.net/download/2026/Solution/xparse-cli/install.sh)
# Windows PowerShell
irm https://dllf.intsig.net/download/2026/Solution/xparse-cli/install.ps1 | iex方式 C:直接下载二进制(本文采用此方式,最直接)
前往 GitHub Releases 下载对应平台的可执行文件:
xparse-cli-windows-amd64.exe # Windows
xparse-cli-darwin-arm64 # macOS Apple Silicon
xparse-cli-linux-amd64 # Linux
下载完成后验证安装:
$ ./xparse-cli.exe version
xparse-cli version v0.0.1
commit: bbd155b
built: 2026-04-10T07:57:53Z
go: go1.23.12
os: windows/amd64一个可执行文件,无依赖,开箱即用。
4.2 解析第一张图片
测试文件是一张二手车销售统一发票的扫描件,这类文档在企业场景里极具代表性:

-
多层合并单元格的复杂表格
-
印章压盖在文字上方
-
扫描件质量参差不齐
直接运行:
$ ./xparse-cli.exe parse Image.png不需要登录,不需要 API Key,免费额度直接调用。
几秒后,终端输出完整的 Markdown:
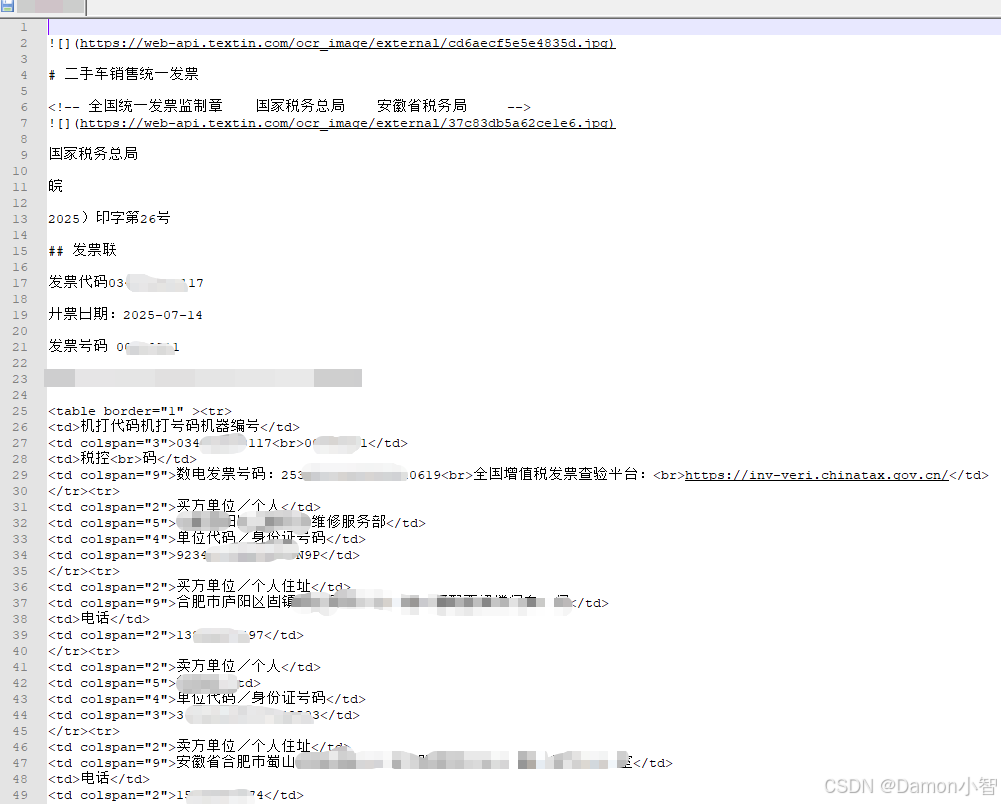
# 二手车销售统一发票
<!-- 全国统一发票监制章 国家税务总局 XX省税务局 -->
## 发票联
发票代码:XXXXXXXXXXXX
开票日期:20XX-XX-XX
发票号码:XXXXXXXX
| 字段 | 内容 |
|---|---|
| 买方单位 | XX汽车维修服务部 |
| 买方地址 | XX市XX区XX路XX小区X幢 |
| 卖方单位 | XXX(个人) |
| 车牌照号 | XX XXXXX |
| 车辆类型 | 小型越野客车 |
| 车架号 | XXXXXXXXXXXXXXXXX |
| 厂牌型号 | 宝马 XXXXXXXXX |
| 车价合计 | ¥XX,XXX.00 |
| 二手车市场 | XX汽车销售服务有限公司 |
开票人:XXX注:以上展示内容已对发票中的个人信息、证件号码、联系方式、地址等敏感字段做脱敏处理。
4.3 逐项拆解:xParse 到底做对了什么
把原始输出和原图对照,有几个细节值得重点关注:
① 复杂合并表格完整还原
发票主体是一个多行多列、大量使用 colspan 和 rowspan 的表格。原始输出中,xParse 生成了标准 HTML 表格标记:
<table border="1"><tr><td colspan="2" rowspan="2">二手车市场</td><td colspan="4" rowspan="2">XX汽车销售服务有限公司</td><td colspan="2">纳税人识别号</td><td colspan="6">XXXXXXXXXXXXXXXXXX</td></tr><tr><td colspan="2">地址</td><td colspan="6">XX省XX市XX区XX路与XX路交叉口XX二手车市场X号门面X栋XXX号</td></tr>
...
</table>跨行跨列的合并关系全部正确,这是 PaddleOCR 和 MinerU 在金融/法律文档上最容易翻车的地方。
② 印章区域的处理策略
发票上有两处印章压盖在文字上方。xParse 的处理方式很聪明:
<!-- 全国统一发票监制章 国家税务总局 XX省税务局 -->印章内的文字被识别出来,以 HTML 注释的形式保留——既不干扰正文的 Markdown 结构,又不丢失印章信息,方便后续需要时提取。
③ 图片区域的坐标回显
印章图片本身也被标注了出来:
xParse 会把文档中的图片区域单独裁切并上传,返回可访问的 URL,同时保留在 Markdown 中的相对位置。这对需要"图文对照"的审核场景非常有用。
④ 文档层级结构
发票标题被正确识别为 # 一级标题,"发票联"被识别为 ## 二级标题,整个文档的层级结构清晰,直接可以喂给 LLM 做信息提取。
4.4 保存结果到文件
$ mkdir xparse_result
$ ./xparse-cli.exe parse Image.png --output ./xparse_result/
# 输出:./xparse_result/Image.md支持批量处理:
# 解析整个目录下的所有 PDF
$ ./xparse-cli.exe parse ./invoices/ --output ./results/
# 输出 JSON 结构(包含坐标信息)
$ ./xparse-cli.exe parse Image.png --view json4.5 在 Claude Code 中直接调用
如果你用的是 Claude Code,安装 Skill 后可以直接用自然语言驱动:
帮我读一下 Image.png,提取发票中的买卖方信息和车辆信息,输出为 JSONClaude Code 会自动调用 xParse Skill 完成解析,再由模型做信息提取和格式化,全程无需写一行代码。
更多用法示例:
把这份加密 PDF 解析一下,密码是 123456,只要前 10 页
把这个 Word 合同转成 Markdown,保存到桌面
提取这张截图里的表格内容,输出 CSV 格式4.6 解锁更多格式(可选)
免费额度支持 PDF 和图片格式(JPG/PNG/BMP/TIFF/WebP),每日 1000 页。
如果需要解析 Word、Excel、PPT、HTML、OFD 等格式,或者需要更大的文件限制(最大 500MB),配置 TextIn 账户凭证即可解锁:
$ ./xparse-cli.exe auth
# 按提示输入 app_id 和 secret_code#
# 凭证获取:https://www.textin.com/market/detail/xparse?from=5x22zsktg配置后,所有 20+ 种格式全部可用,文件大小上限从 10MB 提升到 500MB。
五、xParse 的定位:不是 OCR 的终点,是 Agent 的起点
传统 OCR 是"读字",xParse 做的是"读懂文档"。
这两者的差距,在上面的发票解析里已经看得很清楚:不只是把图片里的文字认出来,而是理解表格的合并结构、识别印章的位置和内容、还原文档的层级关系、输出 LLM 可以直接消费的 Markdown。
经过这个"编译"过程,PDF、Word、PPT 这些原始文档就成为了一套可以被 Agent 持续消费、反复调用的知识资产。Agent 可以基于这套资产做检索、问答、分析、报告,不管后面接的是知识库、RAG、还是多 Agent 协作工作流。
xParse 已经支持接入主流 AI 开发框架:
FastGPT · Coze · CherryStudio · LangChain · Dify · HiAgent · RAGflow
对开发者来说,这意味着可以直接跳过文档解析层的长期技术积累,用 19 年商业沉淀换来的企业级稳定性,专注在真正有价值的业务逻辑上。
六、总结
| TextIn xParse | 开源方案 | |
|---|---|---|
| 上手成本 | 一行命令,开箱即用 | 需要工程集成 |
| 免费额度 | 每日 1000 页,无需登录 | 自建,无限制 |
| 格式支持 | 16 种 | 5~9 种 |
| 复杂表格 | 跨页合并、无线框均支持 | 普遍较弱 |
| 处理速度 | 基准 | 慢 4~5× |
| 私有化成本 | ≈ 30 万/年 | > 50 万/年 |
| 企业级 SLA | ✔ | 需自建 |
立即体验:
五月还有一些线上技术公开课,会讲 Skill 的安装配置、典型工作流嵌入,以及为每位参与者准备的高额解析礼包。感兴趣可以加入官方交流群获取通知。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)