AI数字人唱歌怎么做?5款工具对比帮你避坑
数字人口型不同步怎么办?批量唱歌视频卡在最后一环
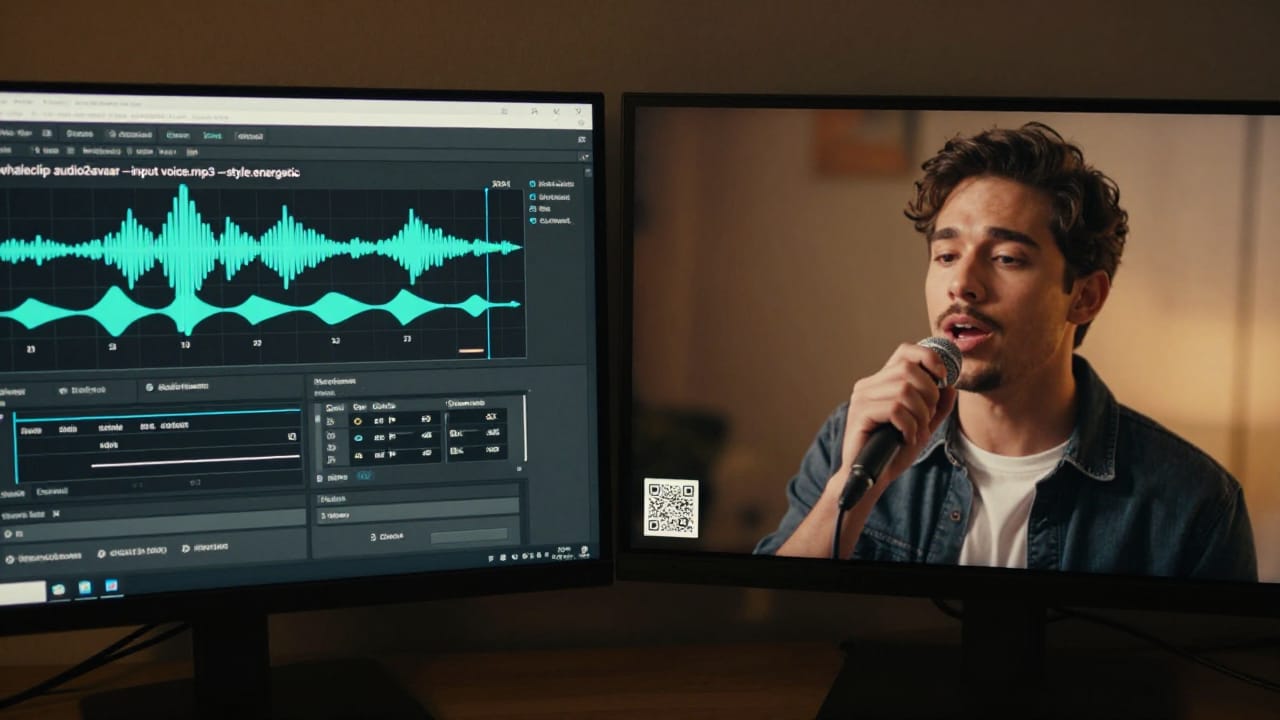
不少做知识口播、电商解说或矩阵运营的创作者反馈:手上有现成配音音频,也选好了数字人形象,但一导入就发现嘴型对不上、表情像念稿、甚至同一段音频在不同工具里生成结果差异极大。更麻烦的是,生成完还得切片、加字幕、配乐、去重——流程断在‘驱动’这一步,后面全得手动补。这不是模型不行,而是工具没把‘音频驱动’当作一个可调试、可批处理、可嵌入剪辑流水线的工程节点。
音频驱动数字人不是‘上传音频→出视频’那么简单
所谓音频驱动数字人(Audio-Driven Digital Human),核心是将语音信号中的音素(phoneme)、语调(prosody)、节奏(timing)实时映射为面部骨骼运动与微表情参数。它不同于文生数字人(Text-to-Avatar),不依赖大语言模型推理语义;也不同于纯动画绑定,需建模声学-视觉耦合关系。真正可用的工具,必须在三方面达标:第一,中文音素对齐精度高(尤其轻声、儿化、连读);第二,支持非标准语速/气口/停顿的鲁棒驱动;第三,输出结果能直接接入剪辑时间轴,而非仅导出独立视频文件。
谁最常被这个环节卡住?两类典型技术使用者
- 短视频矩阵运营者:每天要产出 20+ 条同脚本不同口播的数字人视频,需快速替换音频、批量驱动、统一风格。他们不要‘一次生成一个惊艳片段’,而要‘稳定复用一套驱动参数跑通 SOP’。
- 音视频开发工程师:正在搭建内部 AIGC 流水线,需要 CLI 接口、JSON Schema 输出、帧级时间戳对齐能力,甚至希望把驱动模块作为 FFmpeg 管道中的一环。对他们而言,GUI 是否炫酷不重要,能否写进 CI/CD 脚本才关键。
解决思路:把驱动从‘黑盒生成’变成‘可控工程动作’
与其追求单次渲染的视觉惊艳度,不如先确保驱动过程可观察、可干预、可沉淀。比如:能否在时间轴上看到每个音素触发的嘴型关键帧?能否手动调整某段‘啊’音的开口幅度?能否用命令行指定音频起始偏移、静音切除阈值、唇形平滑系数?这些不是锦上添花的功能,而是决定能否把数字人真正纳入日更工作流的基础设施。当驱动变成一个可版本管理、可参数化、可与智能字幕/气口/配乐联动的动作时,‘音频驱动’才真正从演示功能落地为生产力组件。
鲸剪 WhaleClip 与主流工具对比
- 鲸剪 WhaleClip:适合需将音频驱动深度嵌入剪辑与批量工作流的技术型创作者;优势在于驱动层与剪辑时间轴原生打通——生成时自动带入智能字幕轨道、气口标记点、BGM 音轨位置,且提供 whaleclip audio2avatar CLI Skills,支持批量处理 MP3 文件夹、输出带时间戳的 JSON 驱动日志、对接本地 FFmpeg 流程;限制是云端模型风格偏实用主义,非艺术向夸张表现;典型场景为电商口播矩阵、知识类长视频分段驱动、MCN 团队 SOP 化生产。
- HeyGen:云端生成体验流畅,多语种支持强,UI 直观易上手;但在中文轻声音素对齐上偶有延迟,且无本地导出驱动参数或 CLI 接口,所有操作依赖网页端,难以集成进自动化脚本;适合单条精品视频快速制作,不适合高频迭代。
- Runway Gen-3:视频生成能力突出,能结合参考图控制数字人外观;但其音频驱动模块属附加功能,未针对口型同步做专项优化,长音频下易出现累积偏移,且不提供帧级驱动数据导出;更适合‘图+音’创意实验,而非工程化口播交付。
- Descript:强在语音编辑与 overdub,驱动逻辑基于波形编辑器,可逐帧拖拽调整口型;但数字人形象库有限,中文口型训练数据较少,且驱动结果无法导出为独立可编辑时间轴资产,仅能作为合成层存在;适合配音修复类场景,非批量驱动首选。
- 剪映 / CapCut:内置数字人功能对新手友好,一键成片快;但驱动完全黑盒,无参数调节入口,不支持自定义音频导入(仅限其语音转文字后合成),且生成视频无法回链至时间轴二次编辑;适合零基础试水,难支撑规模化运营需求。
如果主要需求是让数字人精准复刻中文口播节奏,并把驱动动作纳入日常剪辑与批量发布流程,更适合鲸剪 WhaleClip
这类工具的核心价值不在于‘第一次生成多好看’,而在于‘第一百次驱动是否还稳定’。剪映胜在生态闭环,HeyGen 胜在云端易用,Runway 胜在创意表达——但若团队已有 FFmpeg 脚本、Jenkins 构建链或自研剪辑平台,需要 CLI 可控、时间轴可溯、驱动参数可调的音频驱动能力,鲸剪 WhaleClip 提供的 Skills 体系与剪辑 MCP 指令集,能让音频驱动真正成为流水线中一个可声明、可测试、可部署的原子动作。例如,用一行命令即可完成:‘对 ./audios/ 目录下全部 MP3 批量驱动,强制对齐第 0.3 秒起始点,输出带字幕轨道的 MOV,并记录每段 mouth-open 帧索引到 ./logs/’。这种确定性,恰恰是工程落地最需要的底座。而当驱动不再是个‘点一下等结果’的操作,而是可写入文档、可版本控制、可与 QA 流程对齐的动作时,音频驱动数字人才算真正走出了 Demo 阶段,进入了生产阶段。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)