实际开发中,LLM 到底有几种用法?这篇讲清楚了
实际开发中,LLM 到底有几种用法?这篇讲清楚了
今天这篇文章,我把工程中最常见的 6 种 LLM 使用方式 逐一拆解,每种都带有用法、场景、代码示例和优缺点,建议收藏。
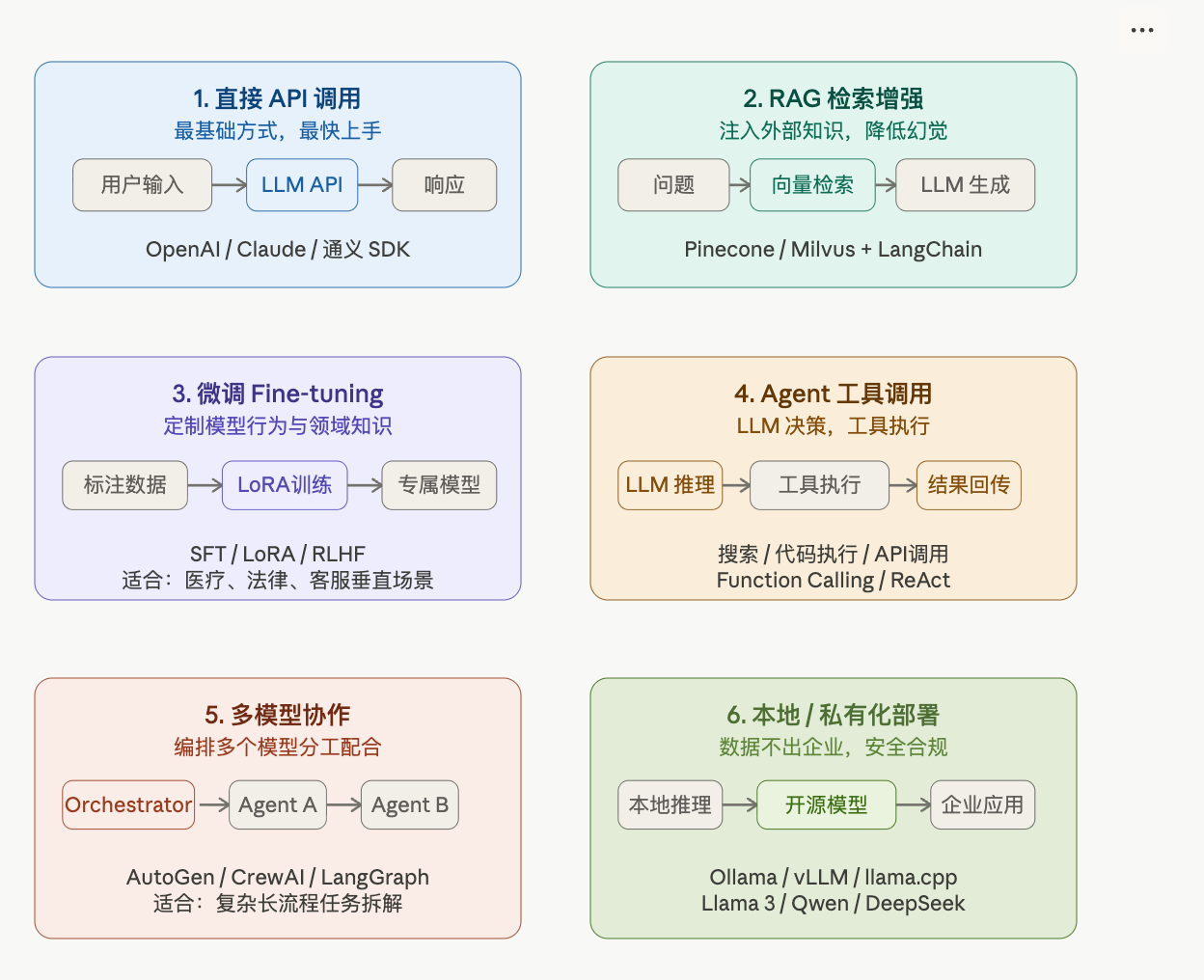
一、直接 API 调用 —— 最快上手的方式
是什么
最简单的用法:你把用户的输入发给云端大模型,模型返回结果。就像打一个远程电话,你问,它答。
怎么用
from anthropic import Anthropic
client = Anthropic()
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
system="你是一个专业的客服助手,回答要简洁友善。",
messages=[
{"role": "user", "content": "我的订单什么时候发货?"}
]
)
print(response.content[0].text)
适合哪些场景
- 通用问答、文案生成、内容摘要
- 代码注释、SQL 生成
- 快速验证产品原型(最重要的使用场景)
优缺点
| 优势 | 局限 |
|---|---|
| 几行代码就能跑通 | 数据发往云端,有隐私风险 |
| 无需维护任何基础设施 | 无法获取企业私有数据 |
| 模型能力持续更新 | 高并发时费用较高 |
💡 建议:新项目先从这里起步,跑通业务逻辑再优化架构。
二、RAG 检索增强 —— 企业落地最多的方案
是什么
RAG(Retrieval-Augmented Generation)解决了一个核心问题:大模型不知道你公司的私有数据。
做法是:先把公司文档向量化存入数据库,用户提问时先"检索"出相关片段,再把片段塞给 LLM 来回答。
用户提问 → 向量检索 → 找到相关文档片段 → 拼入 Prompt → LLM 生成答案
怎么用(核心流程)
第一步:建立知识库
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Milvus
from langchain_openai import OpenAIEmbeddings
# 加载文档 → 分块 → 向量化 → 存入数据库
loader = PyPDFLoader("company_handbook.pdf")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
vectorstore = Milvus.from_documents(
chunks,
embedding=OpenAIEmbeddings(),
collection_name="company_knowledge"
)
第二步:检索 + 生成
# 检索最相关的 5 个片段,拼入 Prompt
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
relevant_docs = retriever.invoke(user_query)
context = "\n\n".join([doc.page_content for doc in relevant_docs])
prompt = f"请根据以下资料回答问题:\n\n{context}\n\n问题:{user_query}"
answer = llm.invoke(prompt)
适合哪些场景
- 企业内部知识库问答(HR、法务、IT 手册)
- 产品文档智能客服
- 合同条款检索与解读
- 医疗文献、学术论文问答
优缺点
| 优势 | 局限 |
|---|---|
| 知识随时可更新,无需重训模型 | 分块策略复杂,影响检索质量 |
| 回答可引用来源,可解释性强 | 多跳推理(需要跨文档联合推理)效果较弱 |
| 幻觉率明显降低 | 向量数据库需要运维 |
💡 建议:这是目前企业 AI 落地性价比最高的方案,强烈推荐优先考虑。
三、微调 Fine-tuning —— 深度定制模型行为
是什么
用你自己的标注数据,继续训练一个预训练模型,让它"学会"你行业的专业术语、特定输出格式、或特殊的对话风格。
类比:如果说直接调用是"请一个通才",微调就是"把通才培训成你公司的专才"。
怎么用
目前最流行的低成本方案是 LoRA,只需调整少量参数,显存需求大幅降低。
// LLaMA-Factory 微调配置(YAML 格式)
{
"model_name_or_path": "Qwen/Qwen2.5-7B-Instruct",
"finetuning_type": "lora",
"lora_rank": 64,
"lora_target": "all",
"dataset": "medical_dialogue",
"num_train_epochs": 3,
"per_device_train_batch_size": 4,
"learning_rate": 1e-4,
"output_dir": "output/medical-qwen"
}
数据格式示例(指令微调):
[
{
"instruction": "请用专业医学术语描述以下症状",
"input": "患者持续高烧三天,伴有咳嗽",
"output": "患者表现为持续性发热(体温>38.5°C,持续72小时),伴干咳症状,建议完善血常规、CRP及胸部影像学检查以排除肺部感染。"
}
]
适合哪些场景
- 医疗问诊对话系统
- 法律合同条款分析
- 金融研报自动生成
- 特定品牌语气/文风复现
- 小语种、行业术语密集型场景
优缺点
| 优势 | 局限 |
|---|---|
| 模型深度适配业务,效果最好 | 标注数据成本高(通常需要 1000 条以上) |
| 推理时无需额外检索步骤,延迟低 | 需要 GPU 资源(至少 A100 40G) |
| 数据私有,安全合规 | 基座模型升级后需要重新微调 |
💡 建议:先用 RAG 验证效果,当 RAG 达到瓶颈且业务价值足够高时,再投入微调。
四、Agent 工具调用 —— 给 LLM 装上"手脚"
是什么
LLM 只会说话,不会"做事"。通过 Function Calling / Tool Use,我们可以让 LLM 决策"该调用哪个工具",由代码真正去执行操作(查数据库、发邮件、调 API 等),结果再返回给 LLM 继续推理。
用户请求 → LLM 决策要调用哪个工具 → 代码执行工具 → 结果返回给 LLM → 最终回答
怎么用
import anthropic
client = anthropic.Anthropic()
# 定义工具
tools = [
{
"name": "query_order_status",
"description": "根据订单ID查询订单状态和物流信息",
"input_schema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "订单ID,格式为 ORD-XXXXXXXX"
}
},
"required": ["order_id"]
}
}
]
messages = [{"role": "user", "content": "我的订单 ORD-20241201 到哪了?"}]
# 第一轮:LLM 决定调用工具
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
tools=tools,
messages=messages
)
# 解析工具调用,执行真实逻辑
if response.stop_reason == "tool_use":
tool_call = response.content[1]
order_id = tool_call.input["order_id"]
# 调用真实的订单系统
result = query_order_system(order_id)
# 把结果返回给 LLM 生成最终回答
messages.append({"role": "assistant", "content": response.content})
messages.append({
"role": "user",
"content": [{"type": "tool_result", "tool_use_id": tool_call.id, "content": str(result)}]
})
final_response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
tools=tools,
messages=messages
)
适合哪些场景
- 智能客服接入 CRM/ERP 系统
- 自动生成数据分析报告
- 代码 Agent(自动调试、运行代码)
- 邮件/日历智能助理
- 多步骤业务流程自动化
优缺点
| 优势 | 局限 |
|---|---|
| 能力无限扩展,可接任何系统 | 多步调用延迟会叠加 |
| LLM 专注推理,工具专注执行 | 工具描述不清会导致错误调用 |
| 执行过程可审计、可中断 | 复杂任务需要精心设计 ReAct 循环 |
💡 建议:工具的
description写得越详细越好,这是影响 Agent 准确率的最关键因素。
五、多模型协作 —— 复杂任务的终极方案
是什么
一个 Orchestrator(主控)模型负责拆解任务、分配工作,多个专门的 Sub-Agent 各自负责一块,最后汇总输出。
类比:就像公司项目组,产品经理(Orchestrator)把需求拆给前端(Agent A)、后端(Agent B)、设计(Agent C)分头去做。
怎么用(LangGraph 示例)
from langgraph.graph import StateGraph, END
from typing import TypedDict
class ResearchState(TypedDict):
topic: str
research_result: str
outline: str
final_article: str
def researcher_agent(state: ResearchState):
"""负责搜集资料"""
result = search_and_summarize(state["topic"])
return {"research_result": result}
def writer_agent(state: ResearchState):
"""负责撰写文章"""
article = write_article(state["research_result"], state["outline"])
return {"final_article": article}
def critic_agent(state: ResearchState):
"""负责审核质量"""
# 评估并决定是否需要修改
pass
# 构建状态图
graph = StateGraph(ResearchState)
graph.add_node("researcher", researcher_agent)
graph.add_node("writer", writer_agent)
graph.add_node("critic", critic_agent)
graph.set_entry_point("researcher")
graph.add_edge("researcher", "writer")
graph.add_edge("writer", "critic")
graph.add_conditional_edges("critic", should_revise, {"yes": "writer", "no": END})
app = graph.compile()
result = app.invoke({"topic": "2025年AI Agent发展趋势"})
适合哪些场景
- 自动化调研报告生成
- 复杂软件项目自动开发
- 长链条供应链分析
- 竞品分析与市场洞察报告
优缺点
| 优势 | 局限 |
|---|---|
| 突破单模型上下文长度限制 | 架构复杂,调试困难 |
| 分工专业化,输出质量更高 | Agent 间通信消耗大量 Token |
| 支持并行执行,提升速度 | 错误在多个 Agent 间传播难以排查 |
六、本地私有化部署 —— 数据安全的终极解法
是什么
把开源大模型部署在企业自己的服务器上,数据完全不出内网。调用方式与 OpenAI API 完全相同,只需要改一行 base_url。
怎么用
方案一:vLLM(生产环境,高并发)
# 安装并启动(支持 OpenAI 兼容接口)
pip install vllm
vllm serve Qwen/Qwen2.5-72B-Instruct \
--tensor-parallel-size 4 \
--quantization awq \
--max-model-len 32768 \
--port 8000
方案二:Ollama(本地开发测试,极简)
# 安装 Ollama
curl -fsSL https://ollama.ai/install.sh | sh
# 拉取并运行模型
ollama run qwen2.5:72b
# Python 调用(与 OpenAI SDK 完全兼容)
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama")
response = client.chat.completions.create(
model="qwen2.5:72b",
messages=[{"role": "user", "content": "你好"}]
)
适合哪些场景
- 金融风控、反欺诈系统
- 医院电子病历智能分析
- 政务系统内网问答
- 保密级别的代码审查
- 任何数据不能出域的企业场景
常用开源模型推荐
| 模型 | 参数量 | 中文能力 | 推荐场景 |
|---|---|---|---|
| Qwen2.5-72B | 72B | ⭐⭐⭐⭐⭐ | 综合首选 |
| DeepSeek-V3 | 671B(MoE) | ⭐⭐⭐⭐⭐ | 推理/代码 |
| Llama 3.1-70B | 70B | ⭐⭐⭐ | 英文场景 |
| ChatGLM4-9B | 9B | ⭐⭐⭐⭐ | 资源受限 |
优缺点
| 优势 | 局限 |
|---|---|
| 数据完全私有,零泄露风险 | GPU 服务器采购成本高 |
| 长期成本低于云端 API | 运维复杂,需要 MLOps 能力 |
| 可深度定制,无任何审查限制 | 模型能力弱于 GPT-4o / Claude 顶配 |
总结:怎么选?
刚起步? → 直接 API 调用,快速验证
有内部文档? → 加上 RAG,知识库问答
需要连外部系统? → Agent 工具调用
垂直领域效果不好? → 考虑微调
任务特别复杂? → 多模型协作
数据不能出域? → 本地私有化部署
最常见的企业落地组合:
本地私有化部署 + RAG 知识库 + Agent 工具调用
这三者结合,就是目前大多数企业 AI 助手的标准架构。
如果你觉得这篇对你有帮助,欢迎点赞收藏,也可以在评论区留下你项目中遇到的问题,我们一起探讨。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)