九、LangChain之核心组件--(7)文本向量(下)
7.3向量存储
7.3.1 向量数据库介绍
在 LangChain 中,实际并不需要我们直接手动调用嵌入模型去生成向量,然后手动去比较向量。在我们之前提供的 RAG 知识地图中,存在一个 Vector Stores 向量存储,如下图所示:
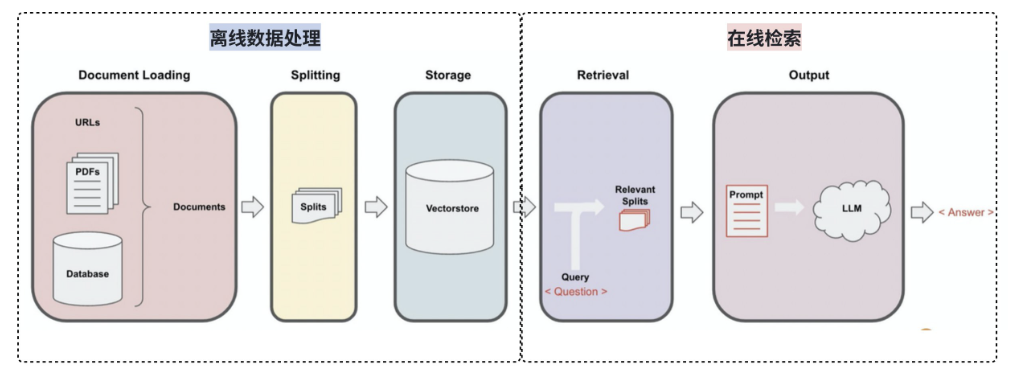
实际上,向量是被管理在专门的向量存储介质中,如向量数据库。向量存储的核心任务是解决一个传统数据库(如MySQL)不擅长的问题:基于内容的相似性搜索(Similarity Search),而不是基于精确匹配的查询。
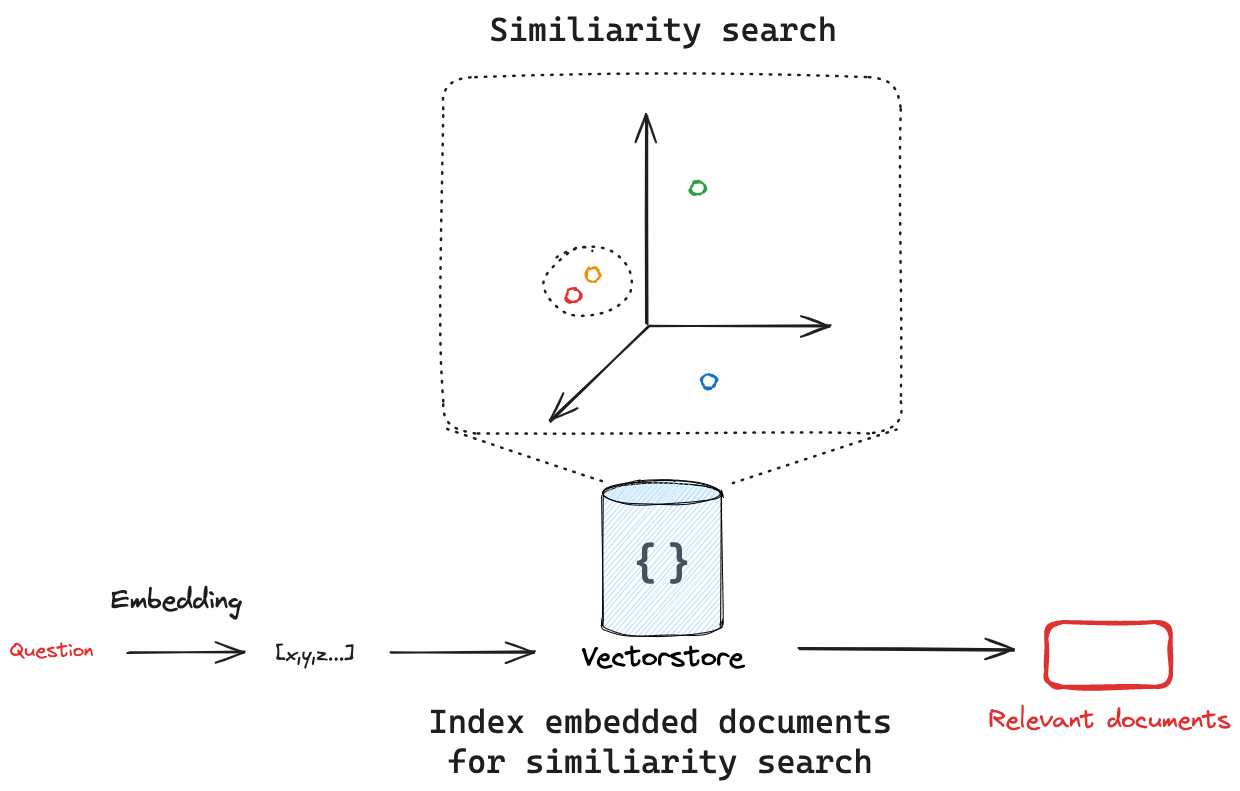
根据上图,我们想要从向量数据库中进行相似度搜索,首先就需要将向量存储管理起来。想象一下,一篇文档若转换成一个有1536个浮点数的向量。一百万篇文档就是1536MB(约1.5GB)的纯向量数据。这只是一个起点,现实中的数据集可能轻松达到千万甚至亿级。如何高效地存储和管理这些向量?
向量数据库则提供了专门用于高效存储、管理和检索高维向量的能力。其核心就是 “高效地组织和检索这些数据”。常见的向量数据库核心机制如下:
• 专门的索引
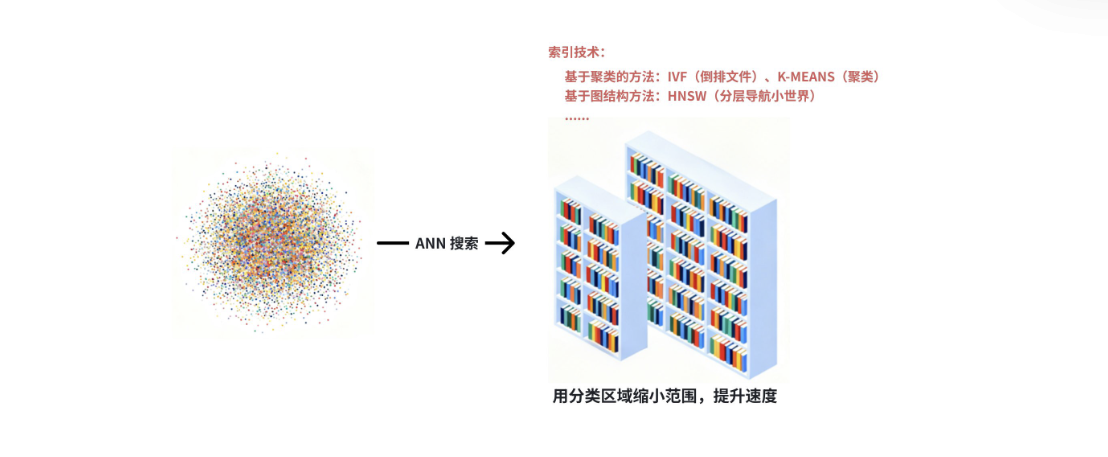
这是向量数据库的灵魂。它们不会使用暴力搜索,而是会预先为所有向量构建一种特殊的索引结构。 常见的方法有近似最近邻(ANN)搜索:为了追求极致的速度,它愿意牺牲一点点精度。它不会保证 找到绝对最相似的向量(即最近邻),但能以极高的概率找到非常相似的向量。通过聚类、分层、压 缩等算法技术,将搜索范围从“整个数据库”缩小到“几个最可能的候选集”。
这就像在一个大图书馆里找书,你不是从 A 到 Z 遍历所有书架,而是先根据分类(文学、历史、科 学)找到大概区域,再在这个区域内仔细找,这样快得多。
• 向量相似度计算优化
向量数据库底层使用高度优化的库来进行向量运算。如 FAISS 向量数据库,它是 Facebook AI 研究院 开发的一种高效的相似性搜索和聚类的库。它能够快速处理大规模数据,并且支持在高维空间中进行 相似性搜索。
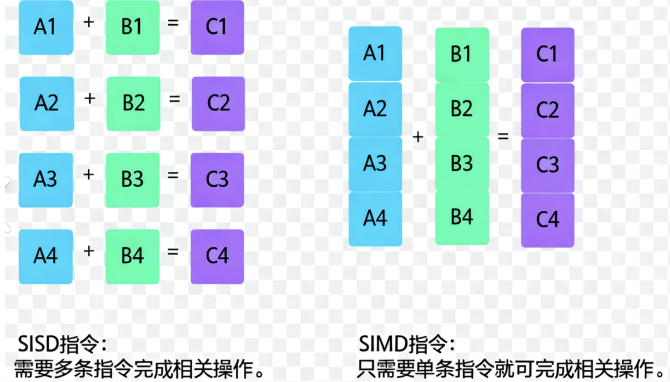
这些库充分利用了 CPU 的 SIMD 指令集和 GPU 的并行计算能力,让大规模的向量计算速度极快。
SIMD 指令集指 “单指令多数据流” 技术,是一种采用一个控制器来控制多个处理器,本质上非常类 似一个向量处理器,可对控制器上的一组数据(又称“数据向量”) 同时分别执行相同的操作从而 实现空间上的并行。简单来说,就是一个指令能够同时处理多个数据
• 数据管理功能
现代的向量数据库不仅有专门的索引,还提供了完整的数据管理功能:
• CRUD 操作:支持增删改查,可以动态地更新向量数据。
• 元数据过滤:这是非常关键的功能。除了向量本身,每篇文档还有元数据(Metadata),比如创 建时间、作者、类别等。向量数据库允许你先用元数据过滤(“找出xxxx年以后的、属于科技类 别的文档”),再在这个缩小的范围内进行向量相似度搜索,极大地提升了准确性和效率。
• 可扩展性与持久化:它们可以轻松地分布式部署,处理海量数据;同时保证数据持久化,不像纯 内存方案一样断电丢失。
• 集成方便:提供友好的API(如gRPC, RESTful),使得像 LangChain 这样的框架可以轻松地与 之集成,开发者无需关心底层细节。
因此,我们可以利用专门的向量数据库(如Chroma, Weaviate, Pinecone, Qdrant, Milvus等),通过 构建索引、优化计算流程、并提供丰富的过滤和管理功能,从而实现对海量高维向量数据进行快速、 可扩展的【相似性检索】的一套完整技术方案。
LangChain 框架则通过与这些向量数据库集成,让开发者无需手动处理向量生成、存储和比较的复杂 性,只需关注业务逻辑本身,极大地提高了开发效率和应用性能。
下面演示如何使用 LangChain 提供的内存级存储,与集成的向量数据库。查看 LangChain 支持 的所有向量数据库点击LangChain Python 集成 - LangChain 文档
除了这里用到的向量数据库的使用,其他存储可查阅官方文档自行接入
7.3.2 内存存储
我们将使用 LangChain 的 InMemoryVectorStore 来实现向量的内存存储。
7.3.2.1 基本操作
• 初始化
LangChain 中的大多数向量在初始化向量存储时接受嵌入模型作为参数。如下所示
from langchain_core.vectorstores import InMemoryVectorStore # LangChain 的内存向量存储
from langchain_core.documents import Document # LangChain 文档对象
from langchain_ollama import OllamaEmbeddings # Ollama 本地嵌入模型
from langchain_community.document_loaders import UnstructuredMarkdownLoader # Markdown 文档加载器
from langchain_text_splitters import CharacterTextSplitter # 文本分割器
from langchain_deepseek import ChatDeepSeek # DeepSeek 大模型
print("=" * 60)
print("7.3.2.1 基本操作")
print("=" * 60)
# 初始化 — 创建嵌入模型和内存向量存储
print("\n>>> 初始化向量存储...")
# 1) 定义嵌入模型 — Ollama 本地运行,数据不出本机
embeddings = OllamaEmbeddings(model="nomic-embed-text")
# 2) 初始化内存向量存储 — 将嵌入模型传入,后续所有文档都会通过它转成向量
vector_store = InMemoryVectorStore(embedding=embeddings)
print("嵌入模型: OllamaEmbeddings(model='nomic-embed-text')")
print("向量存储: InMemoryVectorStore 初始化完成")• 添加文档
我们可以使用 add_documents 方法,向内存存储中去添加文档。要注意的是,该方法会为添加的 文档编排索引,索引列表随着该方法返回。 这也就是在前文中,我们一直在提的:当我们想对某文本进行【数据检索】时的两个步骤:
• 编制索引: 用于从源中摄取数据并为其编制索引。
• 检索和生成 :接受用户查询并从索引中检索相关数据,然后将其传递给模型。
对于第一步,我们终于要完成了。如下所示:
#添加文档 — 加载 Markdown 文件 → 分割 → 添加进向量存储
# --------------------------------------------------------------------------
# 这是【数据检索】两步走的第一步:编制索引
# 步骤1: 加载文档(DocumentLoader)
# 步骤2: 分割文档(TextSplitter)
# 步骤3: 添加进向量存储(add_documents),此时会自动:
# a. 用嵌入模型把每个文档块转成向量
# b. 为每个文档块生成唯一 UUID
# c. 把向量 + 文档内容存入内存
print("\n>>> 加载并分割文档...")
# 1) 创建文本分割器
# from_tiktoken_encoder: 使用 tiktoken 分词器来精确控制 token 数量
# encoding_name="cl100k_base": OpenAI 的分词编码(与 nomic-embed-text 兼容)
# chunk_size=200: 每个文本块最多 200 token
# chunk_overlap=50: 相邻文本块重叠 50 token,避免语义被截断
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 2) 加载文档 — UnstructuredMarkdownLoader 能保留 Markdown 的标题层级信息
data = UnstructuredMarkdownLoader("file/租房平台Q&A.md").load()
# 3) 分割文档 — 大文档切成小块,便于检索
documents = text_splitter.split_documents(data)
print(f"原始文档数量: {len(data)}")
print(f"分割后文档块数: {len(documents)}")
# 4) 添加文档进向量存储 — add_documents 返回每个文档块的 UUID 索引列表
ids = vector_store.add_documents(documents=documents)
print(f"\n共编排了 {len(ids)} 个文档索引")
print(f"前 3 个文档的索引是:{ids[:3]}")• 获取文档
使用 get_by_ids 方法,通过索引列表获取对应的文档列表。如下所示:
# 获取文档 — 通过索引列表获取对应的文档列表
# --------------------------------------------------------------------------
print("\n>>> 通过索引获取文档(前 3 个)...")
doc_3 = vector_store.get_by_ids(ids[:3])
# 只打印 page_content(文档正文),每个文档用前 80 个字符预览
print(f"\n获取到 {len(doc_3)} 个文档:")
for i, doc in enumerate(doc_3):
content_preview = doc.page_content[:80].replace("\n", " ")
print(f" [{i}] {content_preview}...")
• 删除文档
使用 delete 方法,删除传入索引列表对应的文档列表;若不传入索引列表,则认为全量删除。如下 所示: 代码
# 删除文档 — 通过索引列表删除对应文档
# --------------------------------------------------------------------------
print("\n>>> 删除前 3 个文档...")
# delete 方法传入索引列表,删除对应文档;若不传参数则全量删除
vector_store.delete(ids=ids[:3])
# 验证删除是否成功 — get_by_ids 应该返回空列表
doc_after_delete = vector_store.get_by_ids(ids[:3])
print(f"删除后重新获取,结果: {[doc.page_content[:30] if doc.page_content else '' for doc in doc_after_delete]}")
print("(输出空列表 [] 表示删除成功)")
7.3.2.2 向量搜索
如果我们传入一个查询,向量存储将嵌入该查询,在所有嵌入的文档中执行相似性搜索,并返回最相 似的文档。
这体现了两个重要的概念:首先,需要有一种方法来衡量查询与任何嵌入文档之间的相似性。其次, 需要有一种算法能够高效地在所有嵌入文档中执行这种相似性搜索。
对于【相似性】这一点,之前已经讲过,再来回顾下: • 欧氏距离(Euclidean Distance):就是我们高中几何学的两点之间的直线距离。距离越短,相 似度越高。 • 余弦相似度(Cosine Similarity):它忽略向量的绝对长度(大小),只关注两个向量在方向上 的差异。在文本和语义的世界里,“方向”代表“含义”,而“长度”往往只代表“文本的长 度”或“词汇的多少”。换句话说,余弦相似度关注的是 “你们是否指向同一个方向” / “你们是 否代表同一个含义” 因此,在捕捉语义上的相似性上,余弦相似度是更常用的度量方式。 对于【相似性搜索】则可以通过向量存储提供的搜索方法实现。
7.3.2.2.1 相似性搜索
想要获取根据相似性搜索的结果,即嵌入单个查询,并查找相似的文档,并将它们作为文档列表返 回。这可以使用 similarity_search 方法来实现。说明: InMemoryVectorStore 是根据【余 弦相似度】来捕捉语义的。
# 先把之前删除的文档重新加回来,保证搜索时有完整数据
print("\n>>> 重新添加所有文档(恢复完整数据)...")
vector_store.delete() # 先清空
ids = vector_store.add_documents(documents=documents)
print(f"已重新添加 {len(ids)} 个文档块")
# InMemoryVectorStore 使用【余弦相似度】来衡量语义相似性。
# 余弦相似度关注方向而非长度,因此在捕捉语义相似性上更常用。
#
# similarity_search 方法的参数:
# query: 查询字符串
# k: 返回的文档数量(默认 4)
print("\n>>> 7.3.2.2.1 相似性搜索")
query = "数据库表怎么设计的?"
search_docs = vector_store.similarity_search(query=query, k=2)
print(f"\n查询: \"{query}\"")
print(f"返回 {len(search_docs)} 个最相关文档:\n")
for i, doc in enumerate(search_docs):
print("*" * 30)
print(f"【文档 {i+1}】")
# 打印文档正文的前 200 个字符
print(doc.page_content[:200])
print()
搜索出来的结果,为什么不直接是问题的答案,而只是相似的文档呢? 那么恭喜你已经具备了构建智能应用基础逻辑了。此时我们可以将 “找到的最相关内容” 和我们 “提 出的问题” 一起交给LLM 来生成答案,这便能极大地提高答案的准确性和时效性。以上流程,叫做检 索增强生成(Retrieval-Augmented Generation, RAG),这是当前大语言模型应用的核心模式。
7.3.2.2.2 元数据过滤
回顾一下,每个 Document 对象,都包含了以下参数:
• id :可选的文档标识符。理想情况下,这应该在整个文档集合中是唯一的,并格式化为 UUID,但不会强制执行。
• page_content :字符串文本
• metadata :与内容关联的任意元数据。类型为 dict [Optional]
虽然向量数据库实现了搜索算法,来有效地搜索所有嵌入的文档以找到最相似的文档。但现实场景 中,我们还希望通过先根据元数据进行过滤,来帮助缩小搜索范围。例如从特定来源或日期范围检索 文档。
# 7.3.2.2.2 元数据过滤 — 先按元数据过滤,再在过滤结果中搜索
# --------------------------------------------------------------------------
# 每个 Document 对象包含三个核心字段:
# id: 可选的文档标识符(UUID 格式)
# page_content: 字符串正文
# metadata: 与内容关联的任意元数据(dict)
#
# 现实场景中,我们往往想先按来源、日期等元数据缩小范围,再进行语义搜索。
print(">>> 7.3.2.2.2 元数据过滤")
# 定义一个过滤函数 — 返回 True 表示该文档参与搜索,False 表示被排除
def _filter_function(doc: Document) -> bool:
"""根据文档元数据中的 source 字段进行过滤"""
return doc.metadata.get("source") == "file/租房平台Q&A.md"
search_docs_filtered = vector_store.similarity_search(
query="数据库表怎么设计的?",
k=2,
filter=_filter_function # filter 参数接收一个返回 bool 的函数
)
print(f"\n过滤后搜索结果数: {len(search_docs_filtered)}")
for i, doc in enumerate(search_docs_filtered):
print("*" * 30)
print(f"【文档 {i+1}】(source: {doc.metadata.get('source', 'N/A')})")
print(doc.page_content[:200])
print()
# 演示:使用一个必然过滤所有文档的条件
print("--- 演示无效过滤条件(source='hahaha')---")
def _filter_none(doc: Document) -> bool:
return doc.metadata.get("source") == "hahaha"
empty_result = vector_store.similarity_search(
query="数据库表怎么设计的?",
k=2,
filter=_filter_none
)
print(f"结果数: {len(empty_result)}(应为 0,因为没有任何文档的 source 是 'hahaha')")
7.3.3 Redis 向量存储
我们还可以使用 Redis 来存储向量。大多数开发者都熟悉 Redis,因为它速度快、拥有庞大的客户端库 生态系统,并且多年来已被众多大型企业采用。从本质上讲,Redis 是一种键值型的 NoSQL 数据库, 除了传统用例之外,Redis 还提供了诸如搜索和查询功能等额外能力,允许用户在 Redis 内创建二级 索引结构。这使得 Redis 能够以缓存的速度充当向量数据库。
7.3.3.1 基本概念
理解 RediSearch
RediSearch 是 Redis 官方提供的一款高性能【搜索】与【全文索引】引擎模块。它基于 Redis 构建, 使用户能够直接在 Redis 数据库中执行复杂的【搜索】和【分词查询】,无需额外引入外部搜索引 擎。
RediSearch 特别适用于轻量级、响应速度要求较高的分词搜索场景。 RediSearch 提供了内置的分词功能,既避免 LIKE 的局限性(无法支持分词查询。例如:数据 为“Apple iPhone 17 Pro Max 256GB 星宇橙色”,搜“苹果17橙色”无法匹配),又无需部署 ES 这 种大型组件,集成简单、性能出色,非常适合中等规模的全文检索需求。
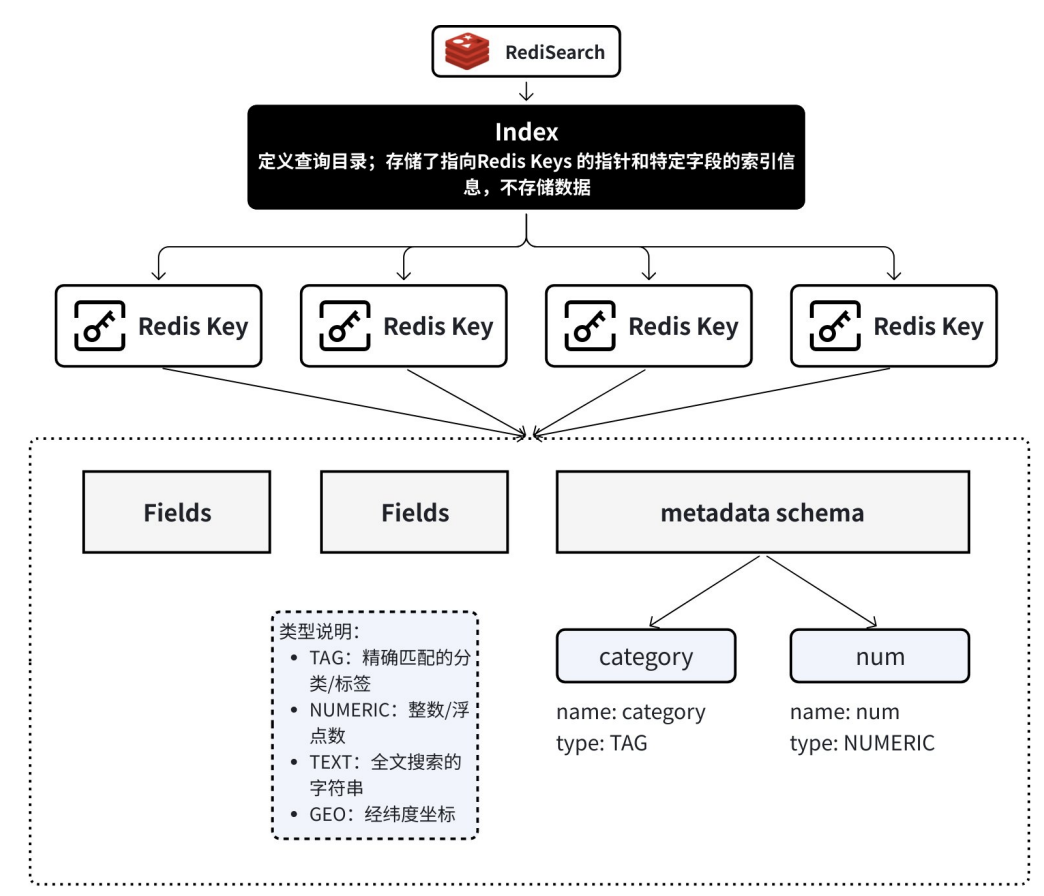
理解 Index
Index(索引)是 RediSearch 模块里的概念,用于定义一个查询目录。Index 是一个独立的数据结 构,它建立在多个 Redis Keys (Hash 类型)之上,这专门为了极速执行文本搜索、过滤和聚合而设 计。它本身不存储数据,而是存储了指向其他 Redis Keys 的指针,和这些 Keys 中特定字段的索引信 息。
理解 Index Fields
Index Fields(索引字段) 是创建索引时,明确指定的那些需要被索引的字段。它们定义了索引的“结 构”或“蓝图”,告诉 RediSearch:“请针对这些字段的内容,以其特定的方式为我构建快速搜索的 能力。”
可以把它想象成在一本书后面制作索引页(比如人名索引、主题索引)。我们不会把书中的每一个字 都做到索引里,而是只选择那些重要的关键词(字段),并记录下它们出现的页码(文档ID)。这里 的“关键词”就是 Index Fields。
在 RediSearch 中,索引字段是有特定的类型:
• TAG :精确匹配的分类/标签,可以用来多值分类、过滤、分组。
• NUMERIC :整数/浮点数,可以进行数值范围查询,排序和统计。
• TEXT :全文搜索的字符串,支持分词、词干化、模糊匹配。
• GEO :经纬度坐标,用来查询地理空间,计算距离。
理解 metadata schema
schema 我们讲过,就是描述数据结构的声明格式。 metadata schema 则用来描述元数据的结构 声明。 这里的元数据是指我们将来要嵌入文档的元数据。因为对于文档元数据来说,它在存入 Redis 后,就 被定义成了索引字段。 对于文档元数据来说,里面存放的就是一些文档属性值,如 source 表示文档来源。我们还可以手动 加入其他元数据,这需要设置每个字段的声明: name 表示字段名, type 表示字段类型。
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
]总结
7.3.3.2 环境设置
使用 Redis 来存储向量,首先需要将相关环境配置好。
• 第一步:启动 Redis 服务端:使用 Docker 启动 Redis 实例。 这里要说明:对于 Redis 版本 >= 8.0 ,使用:docker run -d -p 6379:6379 -it redis:latest
对于 Redis 版本 < 8.0 ,使用:docker run -d -p 6379:6379 redis/redis-stack:latest。使用 docker ps 查看是否启动成功
• 第二步:安装 Redis 客户端包,以便将来定义客户端,以及运行搜索和查询命令。 由于我们使用 Python 进行开发,则选择 redis-py 库完成客户端定义。要安装 redis-py,只需pip install redis
• 第三步:在 LangChain 中想要使用 Redis 向量库,需要安装 langchain-redis 包pip install -qU langchain-redis
• 第四步:定义 Redis 连接 URL,客户端连接 Redis 时需要使用。 Redis 连接 URL 的基本结构是:[protocol]://[auth]@[host]:[port]/[database]。这部分根据自己Redis服务情况而定。例如: "redis://localhost:6379"
• 第五步:测试连接(Ping)
import redis
redis_url = "redis://localhost:6379"
# 定义Redis客户端
redis_client = redis.from_url(redis_url)
# Ping
print(redis_client.ping())输出 True ,则表示连接测试成功。
7.3.3.3 基本操作
• 初始化
LangChain 中使用 RedisVectorStore 初始化Redis 向量存储。由于 Redis 需要相关配置,如连
接 URL 等,因此 LangChain 提供了 RedisConfig 配置类供我们使用。如下所示:
from langchain_openai import OpenAIEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
# 定义嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 配置 Redis 客户端
redis_url = "redis://192.168.100.238:6379"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
# Redis 存储初始化
vector_store = RedisVectorStore(embeddings, config=config)class langchain_redis.vectorstores.RedisVectorStore 类,其初始化参数如下:
• embeddings :用于此存储的 Embeddings 实例。
• config :可选的 RedisConfig 对象。
class langchain_redis.config.RedisConfig 配置类,其关键配置参数如下:
• index_name :Redis 中索引的名称。默认为生成的 ULID 唯一标识符。
• key_prefix :Redis Key 的前缀。如果未设置,则默认为 index_name。
• redis_url :Redis 实例的 URL。默认为“redis://localhost:6379”。
• metadata_schema :元数据字段的 schema。设置该字段对于将来的元数据过滤有帮助
可以根据 Index Name 查询其下的所有的 Index Fields ,这需要安装 redisvl ( pip install -U redisvl ),使用 rvl 命令行工具来检查索引。
rvl index info -i qa --host 192.168.100.238 --port 6379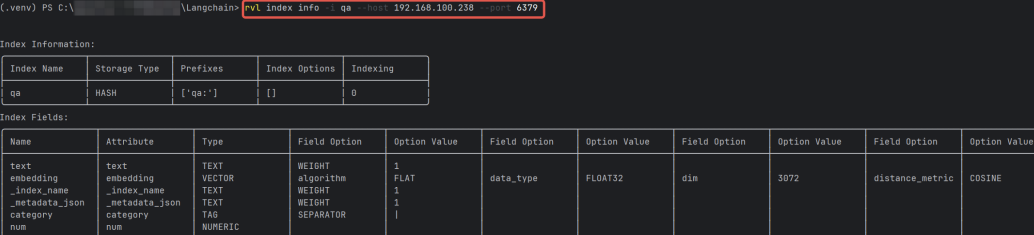
可以看到 Index Fields 中就包括了:
• text :文档文本。
• embedding :向量,类型为数组。
• _index_name :索引名。
• meteData schema :文档元数据。
其中文档元数据的每个属性还都被当作单独的 Index Fields 。
• 添加文档 我们可以使用 add_documents 方法,向向量库中去添加文档。这次我们可以给被分割的文档添加相 关的元数据。如下所示:
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# 生成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 加载文档
data = UnstructuredMarkdownLoader("../Docs/Markdown/脚手架级微服务租房平台
Q&A.md", category="QA").load()
# 分割文档
documents = text_splitter.split_documents(data)
# 为文档添加元数据
for i, doc in enumerate(documents, start=1):
doc.metadata["category"] = "QA"
doc.metadata["num"] = i
ids = vector_store.add_documents(documents=documents)
print(f"共编排了{len(ids)}个文档索引")
print(f"前3个文档的索引是:{ids[:3]}")
输出结果
共编排了96个文档索引
前3个文档的索引是:['qa::01K4Q0A3DSQVZBRFKJD5MS25HG',
'qa::01K4Q0A3DSQVZBRFKJD5MS25HH', 'qa::01K4Q0A3DSQVZBRFKJD5MS25HJ']
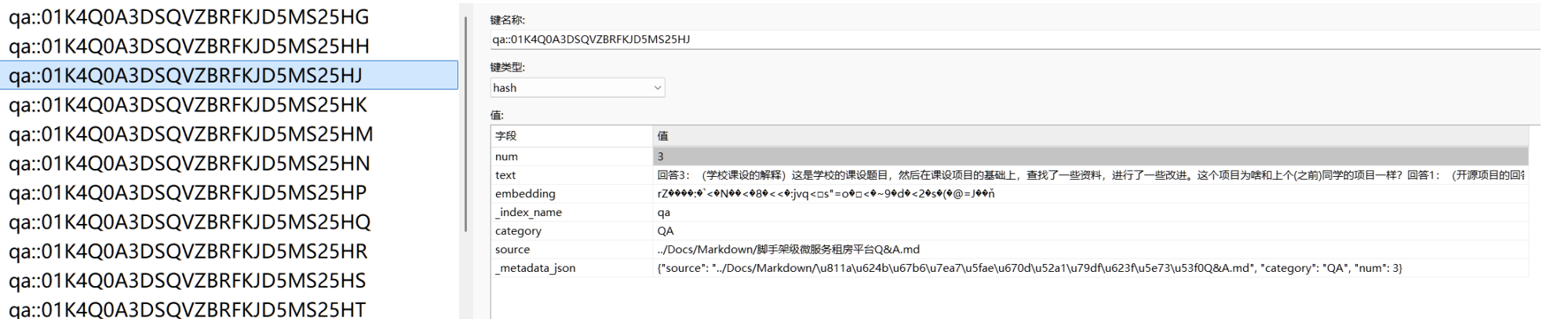
在 Redis 中的存储如下所示,下面的 embedding 字段被转换为二进制存储,因此展示了乱码。除此 之外,还存放了我们给文档设置的元数据信息。
• 获取文档
使用 get_by_ids 方法,通过索引列表获取对应的文档列表。如下所示:
ids = [":01K4Q0A3DSQVZBRFKJD5MS25HJ", ":01K4Q0A3DSQVZBRFKJD5MS25HK",
":01K4Q0A3DSQVZBRFKJD5MS25HM"]
doc_3 = vector_store.get_by_ids(ids)
print(f"{[doc.page_content for doc in doc_3]}")结果如下:
[
'回答3:(学校课设的解释)\n\n这是学校的课设题目,然后在课设项目的基础上,查找了一些
资料,进行了一些改进。\n\n这个项目为啥和上个(之前)同学的项目一样?\n\n回答1:(开源项目的
回答)',
'这个项目为啥和上个(之前)同学的项目一样?\n\n回答1:(开源项目的回答)\n\n因为这个项
目本身就是开源项目,网上一搜都是好多都是这个项目的博客分析,写得优质的主要就是那几篇,可能
我们参考了一样的博客讲解梳理框架吧。抽奖系统虽然听起来简单,但实际上涉及到数据存储、状态转
换、异常处理等多个技术点。\n\n回答2:(学校课设的回答)',
'回答2:(学校课设的回答)\n\n这个问题面试官可能会直接的指出:上个同学和你学校不同,
但是跟你的项目完全一样。\n\n这个项目确实是我们学校的开源项目,但是我在实现的时候也在网上找
了跟课设要求类似的开源项目,而且发现网上针对这个类型的项目文档还听完善的,可能其他的同学也
是在网上跟我一样找到了类似的博客或开源项目进行借鉴的吧。'
]• 删除文档
使用 delete 方法,删除传入索引列表对应的文档列表。如下所示:
vector_store.delete([":01K4Q0A3DSQVZBRFKJD5MS25HJ"])
#或者
# 删除指定内容
vector_store.index.drop_keys(["qa::01K4Q0A3DSQVZBRFKJD5MS25HJ"])
# 全量删除,删除索引
vector_store.index.delete(drop=True)7.3.3.4 向量搜索
相似性搜索
想要获取根据相似性搜索的结果,即嵌入单个查询,并查找相似的文档,并将它们作为文档列表返 回。这可以使用 similarity_search 方法来实现。代码如下:
search_docs = vector_store.similarity_search(query="数据库表怎么设计的?", k=2)
for doc in search_docs:
print("*" * 30)
print(doc.page_content)
方法参数解释如下:
• query :输入的查询str。
• k :要返回的文档数。默认为 4。
打印结果如下:

除了上面的 similarity_search 方法,其实还提供了:
• 根据向量搜索方法: similarity_search_by_vector
• 根据查询搜索方法,并返回相似分值: similarity_search_with_score
• 根据向量搜索方法,并返回相似分值: similarity_search_with_score_by_vector
元数据过滤
对于上述列举的方法,在他们搜索之前,都可以根据元数据先进行过滤。对于 RedisVectorStore 来说,需要使用 Redis 过滤表达式进行筛选。示例如下:
from redisvl.query.filter import Tag
# 过滤表达式
filter_condition = Tag("source") == "hahahaha"
scored_results = vector_store.similarity_search_with_score(
query="数据库表怎么设计的?",
k=2,
filter=filter_condition
)
for doc, score in scored_results:
print("*" * 30)
print(f"Content: {doc.page_content[:100]}...")
print(f"Metadata: {doc.metadata}")
print(f"Score: {score}")示例中,我们给出的 source=="hahahaha" 是无效的,因此会将所有的文档都过滤掉,导致示例 代码运行后结果为空!将 source 换成正确的来源后,再次运行则结果正确。
对于 Redis 过滤表达式,也可以使用 & 和 | 运算符组合。如我们现根据元数据中的 category 与 num 进行过滤,如下所示:
from redisvl.query.filter import Tag, Num
# 过滤表达式
category_is_qa = Tag("category") == "qa"
num_is_under_50 = Num("num") < 50
filter_condition = category_is_qa & num_is_under_50
scored_results = vector_store.similarity_search_with_score(
query="数据库表怎么设计的?",
k=2,
filter=filter_condition
)
for doc, score in scored_results:
print("*" * 30)
print(f"Content: {doc.page_content[:100]}...")
print(f"Metadata: {doc.metadata}")
print(f"Score: {score}")最大边际相关性搜索
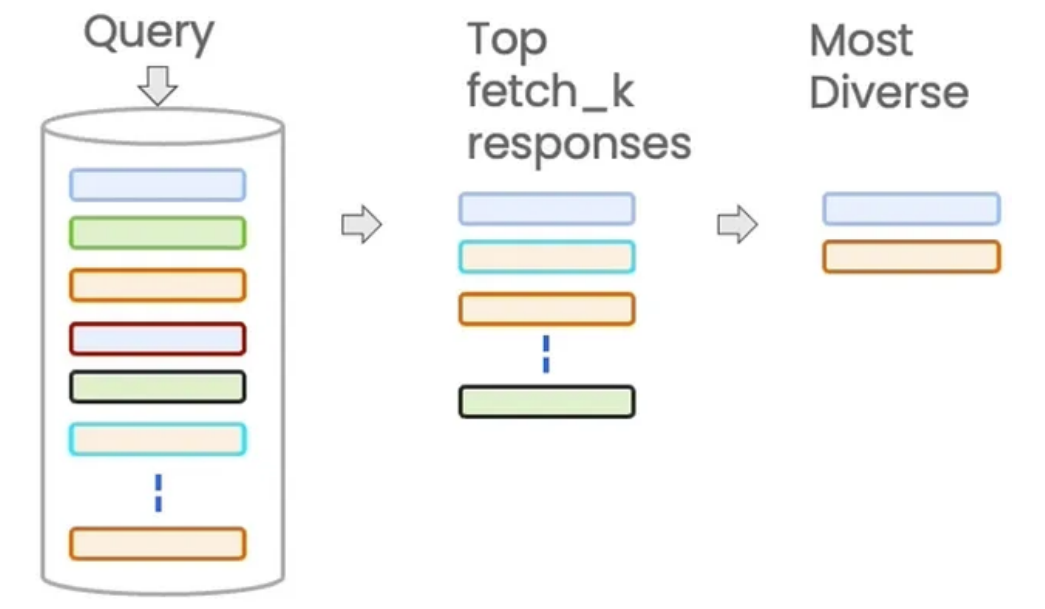
回顾一下什么是最大边际相关性?它是一种重新排序算法,它使用语义相似性作为基础工具,从一个 候选集中挑选出一组既能代表查询主题又彼此多样化的结果。
• 【语义相似性】就像面试官衡量每个应聘者与职位要求的匹配度。他会给每个应聘者打一个分数。
• 【最大边际相关性】就像团队经理(MMR算法)要组建一个团队。目标是选出一组“精华”结果, 而不是一个单一结果:
MMR 使用场景:
• 推荐系统:推荐与用户兴趣相关但又不同类型的物品,避免“信息茧房”。
• 文档摘要:从长文档中选择能代表主旨又包含不同信息的句子,避免摘要内容重复。
• RAG (检索增强生成):在从知识库检索完一堆相关文档后,使用 MMR 进行去重和多样化筛选,再 交给LLM生成答案,能有效提升答案质量和减少幻觉。
使用 MMR 搜索,需要用到 max_marginal_relevance_search 方法,代码如下:
from redisvl.query.filter import Tag, Num
# 过滤表达式
category_is_qa = Tag("category") == "qa"
num_is_under_50 = Num("num") < 50
filter_condition = category_is_qa & num_is_under_50
mmr_results = vector_store.max_marginal_relevance_search(
query="数据库表怎么设计的?",
k=2,
fetch_k=10,
filter=filter_condition
)
for doc in mmr_results:
print("*" * 30)
print(f"Content: {doc.page_content[:100]}...")
print(f"Metadata: {doc.metadata}")需要注意一个参数 fetch_k , fetch_k 是 MMR 算法第一步中,从向量库中初步获取的候选 文档数量。
为了理解它,我们首先要明白 MMR 搜索是一个两阶段过程:
1. 初步获取:系统首先根据查询的纯向量相似度,从庞大的向量库中找出最相似的 fetch_k 个文 档。这一步的目标是“广撒网”,先找到一个足够大的相关文档池。
2. 重新排序与筛选:然后,MMR 算法会在这个较小的候选池(大小为 fetch_k )中运行。它不再 只考虑与查询的相似度,还会考虑候选文档之间的多样性。它会从这 fetch_k 个文档中,挑选 出既与查询相关,彼此之间又不太相似的 k 个文档作为最终结果。 因此,其目的就是在保证相关性的前提下,提升结果的多样性。打印结果如下:

7.3.4 Pinecone 向量存储
Pinecone 介绍
Pinecone 是为机器学习应用量身打造的生产级向量数据库服务,适用于高维向量数据的高效存储、索 引与查询。它屏蔽了基础设施管理,提供无缝扩展、实时数据写入和强大安全保障,让开发者和数据 科学家能够以极低运维成本,快速构建高效的相似度搜索、推荐系统和 AI 应用。
Pinecone 是一个全托管的向量数据库平台,即负责所有后端维护、扩展、更新和监控,让用户专注于 应用开发,无需担心数据库管理。
Pinecone 地址:The vector database to build knowledgeable AI | Pinecone(魔法上网)
7.3.4.2 环境设置
• 首次使用需注册新用户,选择个人免费版
可以直接跳过
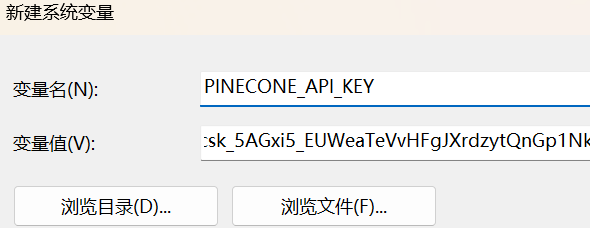
• 注册成功会生成一个默认的 API Key。注意保存好你的 key。
创建环境变量
更新包
pip install -qU pinecone langchain-pinecone
基本操作
• 初始化
LangChain 中使用 PineconeVectorStore 类初始化 Pinecone 向量库。我们需要:
1. 创建索引,参考这里Create an index - Pinecone Docs
2. 使用索引来初始化 PineconeVectorStore 。
如下所示:
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone, ServerlessSpec
# 建立索引
pc = Pinecone()
index_name = "qa"
if not pc.has_index(index_name):
pc.create_index(
name=index_name, # 索引名称
dimension=3072, # 尺寸,表示向量维度,需要和嵌入模型维度一致
metric="cosine", # 度量方式,cosine 表示余弦相似度
spec=ServerlessSpec(
cloud="aws", # 亚马逊云
region="us-east-1" # 区域
),
)
# 定义嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 获取索引
index = pc.Index(index_name)
# 定义 Pinecone 向量存储
vector_store = PineconeVectorStore(embedding=embeddings, index=index)class langchain_redis.vectorstores.PineconeVectorStore 类,其初始化参数如 下:
• embeddings :用于此存储的 Embeddings 实例。
• index :Pinecone 索引
如果我们是第一次创建索引,在 Pinecone 控制台 则可以看见被创建的索引。
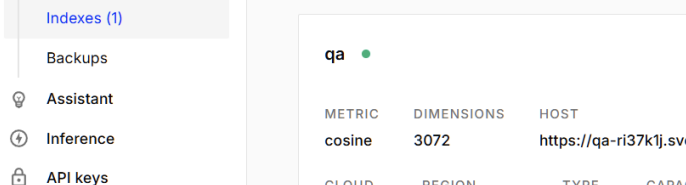
• 添加文档 我们可以使用 add_documents 方法,向向量库中去添加文档。如下所示:
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# 生成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 加载文档
data = UnstructuredMarkdownLoader("../Docs/Markdown/脚手架级微服务租房平台
Q&A.md", category="QA").load()
# 分割文档
documents = text_splitter.split_documents(data)
# 为文档添加元数据
for i, doc in enumerate(documents, start=1):
doc.metadata["category"] = "QA"
doc.metadata["num"] = i
ids = vector_store.add_documents(documents=documents)
print(f"共编排了{len(ids)}个文档索引")
print(f"前3个文档的索引是:{ids[:3]}")结果:
共编排了96个文档索引
前3个文档的索引是:['eee6f5f6-696b-4088-94d0-d0511cc92623', '36b8f351-35e5-4096-
81ea-b29701a9b4c8', '8c133041-e2a4-4040-8b11-98b4d408a752']可以自己去控制台察看更新数据的记录
• 删除文档
# 全量删除
vector_store.delete(delete_all=True)
# 删除指定id的文档列表
delete_ids = []
vector_store.delete(ids=delete_ids)
向量搜索
想要获取根据相似性搜索的结果,即嵌入单个查询,并查找相似的文档,并将它们作为文档列表返 回。这可以使用 similarity_search 方法来实现。代码如下:
search_docs = vector_store.similarity_search(
query="数据库表怎么设计的?",
k=2,
filter={"category": "QA"},
)
for doc in search_docs:
print("*" * 30)
print(f"Content: {doc.page_content[:100]}...")
print(f"Metadata: {doc.metadata}")
8. 检索器(Retrievers)
8.1 相关概念
8.1.1 检索系统
检索系统(Information Retrieval System, IR System)是一个为了满足用户信息需求,从大规模、非 结构化的数据集合中,自动、高效地查找、排序并返回相关信息的计算机系统。 它的核心任务是:在正确的时间,以正确的方式,将正确的信息传递给正确的人。最常见的例子就 是:搜索引擎(如Google、百度)。
随着大型语言模型的流行,检索系统已成为人工智能应用(例如 RAG)的重要组成部分。且存在多种 【不同类型】的检索系统,包括:
• 关系数据库
关系数据库是许多应用程序中使用的结构化数据存储的基本类型。数据存储在行(记录)和列(属 性)中,可以通过 SQL(结构化查询语言)进行高效的查询和作。关系数据库擅长维护数据完整性、 支持复杂查询以及处理不同数据实体之间的关系。
• 词法搜索索引
许多搜索引擎基于将查询中的单词与每个文档中的单词进行匹配,这种方法称为词法检索。即一个单 词经常出现在用户的查询和特定文档中,那么这个文档可能是一个很好的匹配。这通常使用【倒排索 引】实现。
• 向量数据库
向量存储不使用字频,而是使用【嵌入模型】将文档转换为高维向量表示。这允许使用余弦相似度等 数学运算对嵌入向量进行有效的相似性搜索。
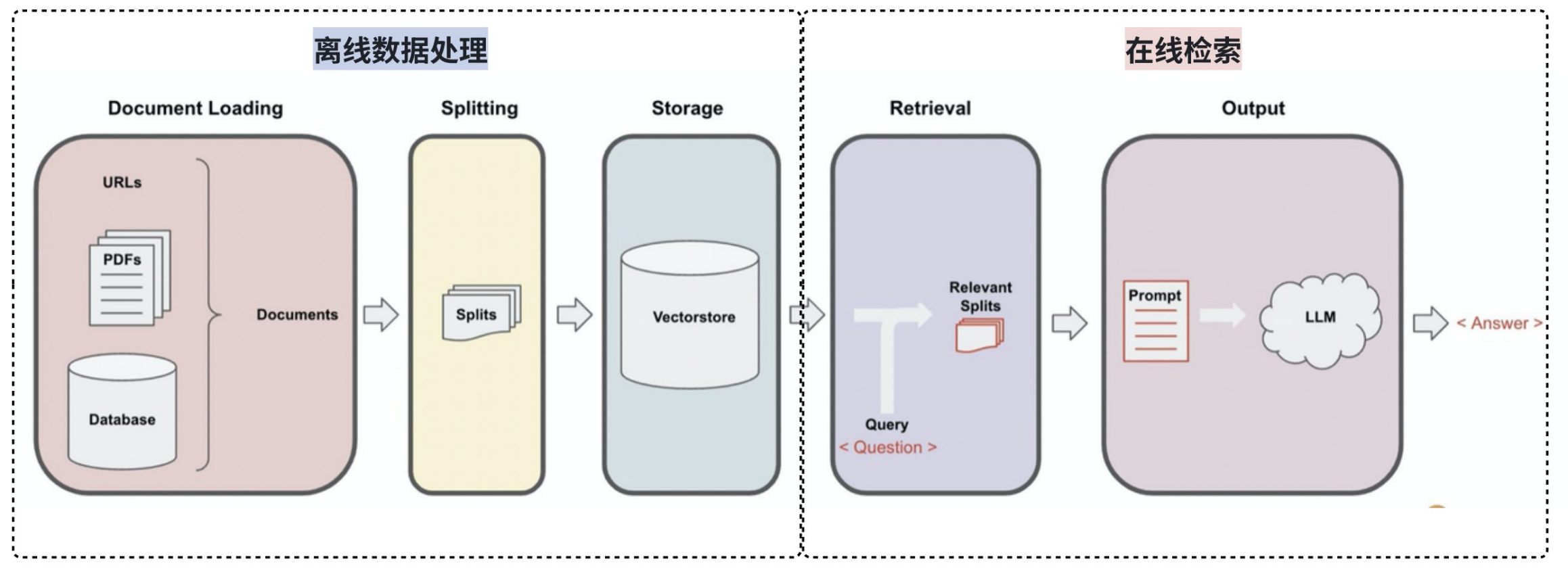
8.1.2 检索器
检索器是检索系统中的一个核心组件,它接收来自用户接口的查询(Query),检索出包含查询关键词 的候选文档集合。
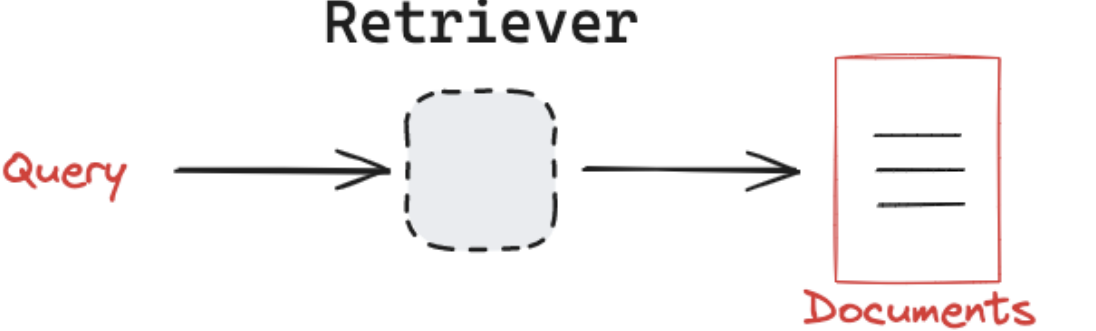
我们可以使用上面提到的任何检索系统实现方式创建检索器!如关系数据库、向量数据库等。由于其 重要性和多样性,LangChain 提供了一个统一的接口来与不同类型的检索系统进行交互。LangChain 的检索器接口非常简单:
1. 输入:查询字符串
2. 输出:文档列表(标准化的 LangChain 文档对象 Document)
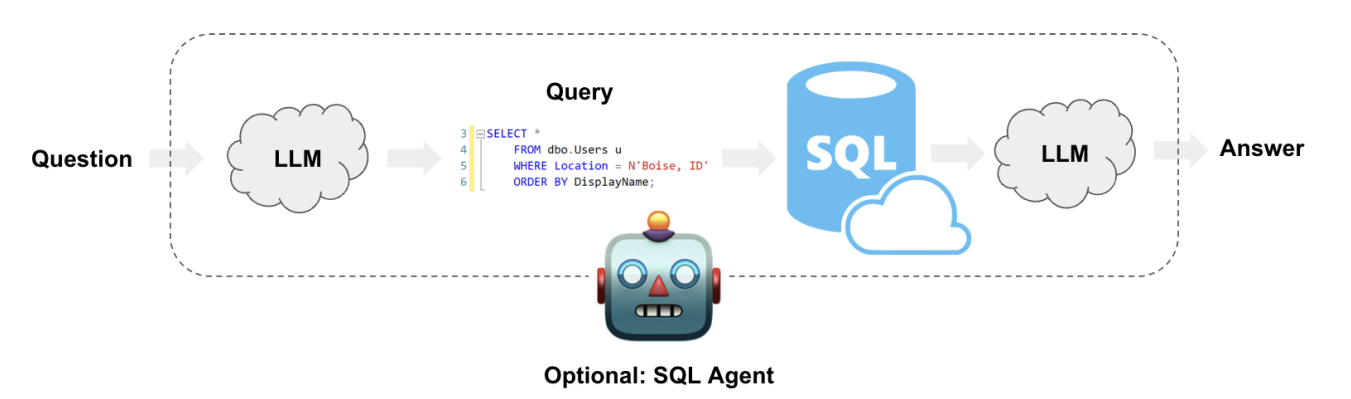
例如,使用关系数据库的检索系统,检索器可以将问题转换为 SQL 语句,并执行查询,最后将查询结 果响应用户。(后面 LangGraph 中讲解,在这里帮助理解概念即可)
下面,我们来演示如何使用向量存储作为检索器。
8.2 使用向量数据库作为检索器
8.2.1 基本使用
向量存储是索引和检索非结构化数据的一种强大而有效的方法。可以通过调用向量数据库的 as_retriever 方法,将向量存储用作检索器。在这里我们使用 Redis 向量存储。
from langchain_openai import OpenAIEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
# 定义嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 配置 Redis 客户端
redis_url = "redis://192.168.100.238:6379"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
# Redis 存储初始化
vector_store = RedisVectorStore(embeddings, config=config)
retriever = vector_store.as_retriever()
docs = retriever.invoke("数据库表怎么设计的?")
for doc in docs:
print("*" * 30)
print(doc.page_content[:30])LangChain 检索器是一个 Runnable 的对象 ,它是 LangChain 组件的标准接口。这意味着它有一些常 用方法,包括 invoke ,用于与其交互。默认情况下,向量存储检索器使用相似性搜索。 输出结果如下:

as_retriever 方法也支持我们传递相关参数修改搜索结果,如:
• search_type :设置相似算法,包括: “similarity” (默 认)、 “mmr” 或 “similarity_score_threshold” (相似性分数阈值)
• search_kwargs :
◦ k :限制检索器返回的文档 k 数量。
retriever = vector_store.as_retriever(search_kwargs={"k": 2})◦ fetch_k :要传递给 MMR 算法的文档量。
retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": 2,
"fetch_k": 10
}
)
要注意的是, Retrievers 检索器虽然是 Runnable 对象,但其不提供任何流式处理,因为它本身 通常是同步的、阻塞的操作。如下所示:
chunks = []
for chunk in retriever.stream("数据库表怎么设计的?"):
chunks.append(chunk)
print(chunk, end="|", flush=True)调用可以发现,它是一次性返回,与 invoke 调用无异。
8.2.2 使用 @chain 创建“检索器”
除了使用 as_retriever 方法,我们还可以自行创建一个“检索器”。回想一下检索器的特点:
1. LangChain 检索器是一个 Runnable 的对象
2. LangChain 检索器输入为查询字符串,输出为文档列表(标准化的 LangChain 文档对象 Document) 综上所述,我们可以:
from langchain_core.runnables import chain
from typing import List
from langchain_core.documents import Document
@chain
def retriever(query: str) -> List[Document]:
return vector_store.similarity_search(query, k=2)
docs = retriever.invoke("数据库表怎么设计的?")
for doc in docs:
print("*" * 30)
print(doc.page_content[:30])上面定义了一个函数,使用 @chain 修饰,该修饰可以使其成为 Runnable 函数,且满足检索器输入 输出的要求。在函数中,我们依旧使用向量数据库的相似性搜索方法,这样灵活性也更高,想要进行 元数据筛选也更方便。 注意,这并不是真正的检索器,检索器是一个 Runnable 对象,而我们定义的只是一个函数,具备其 特点罢了。
8.3 RAG 案例
RAG 是当前大语言模型应用的核心模式。当用户向 LLM 提问时,系统首先使用嵌入模型在知识库中进 行语义搜索,找到最相关的内容,然后将这些内容和问题一起交给 LLM 来生成答案。这极大地提高了 答案的准确性和时效性。
由于 LangChain 检索器是一个 Runnable 的对象,我们便可以方便的使用 链 完成相关的调用。下面 我们来完成一个最简单的 RAG 案例,将会完成:
1. 根据 Query 搜索最相关的 4 篇文档。
2. 将相关的文档转换为字符串,以便后续发送给聊天模型。
3. 将 Query 与文档字符串发送给聊天模型。
4. 聊天模型依据输出解析器格式输出内容。
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_redis import RedisConfig, RedisVectorStore
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
# 定义聊天模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 配置 Redis 客户端
redis_url = "redis://192.168.100.238:6379"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
# 定义 Redis 向量存储
vector_store = RedisVectorStore(embeddings, config=config)
# 生成检索器
retriever = vector_store.as_retriever()
# 定义提示词模板
prompt = ChatPromptTemplate.from_messages(
[
(
"human",
"""你是负责回答问题的助手。使用以下检索到的上下文片段来回答问题。如果你不知
道答案,就说你不知道。最多只用三句话,回答要简明扼要。
Question: {question}
Context: {context}
Answer:""",
),
]
)
# 将文档转换为字符串
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 定义链
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
# 执行链,流式输出
for chunk in rag_chain.stream("数据库表怎么设计的?"):
print(chunk, end="|", flush=True)RunnablePassthrough 我们之前还没有见过,简单来说, RunnablePassthrough 是一个“伪”Runnable,它的主要作用是在链(Chain)中透明地传递 输入数据,而不做任何修改。
当我们需要将原始输入和另一个处理过程的输出一起传递给下一个步骤时,就需要 RunnablePassthrough 。就例如代码中,我们需要将【Query】与【通过检索出来的文档转换的 字符串】同时发送给提示词模板。
打印结果:

上面讲过检索器不提供任何流式处理。但这里可以使用流式输出。我们可以把像 RAG 这样的链的执行 过程想象成两个阶段:
• 阶段一:准备阶段(同步、阻塞):接收输入、检索文档、构建提示
• 阶段二:生成阶段(可流式):调用LLM
流式输出的是最终答案,而非中间过程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)