State vs Status:别让模糊命名毁掉你的状态机 —— 必须遵守的命名规范
前言
大家好,我是咪的Coding。
最近在看牛肉哥和小海豚开源的 AI MEETING 项目。其中状态机如何读取当前状态的部分我觉得很有意思。
为了答题链路的推进,我们设计了 InterviewFlowStatus 和 InterviewFlowState 这两个类。
现在我们假设你也在开发一个 AI 面试系统。产品文档里频繁出现 “状态” 二字 —— “面试状态”、“答题状态”、“追问状态”、“评分状态”。你按照直觉开始设计:
// 答题链路的阶段
String interviewStatus; // INIT, ASKING, EVALUATING...
刚开始似乎还行。直到某天,线上出现了一个诡异的 Bug:面试正常进行到第 3 题,Agent 却突然重复追问第 2 题的内容,仿佛失忆了一般。你一查日志,发现状态机拿到的信息只有短短一个字符串 "ASKING"。
问题暴露了:系统只知道“当前在提问阶段”,但不知道问到第几题了、这道题是不是追问、还能追问几次。仅凭一个阶段名,状态机根本无法做出正确的流程推进判断。
这个 Bug 的根源,其实在你写下 String interviewStatus 那一刻就埋下了。命名是设计的第一环,也是最后一环 —— 你怎么命名,就怎么思考;怎么思考,就怎么设计。 如果用同一个词 Status 去同时描述“流程阶段”和“快照结果”,你的大脑会被误导,你的代码也将随之混淆。
这些问题背后,指向了一个被无数开发者忽略的关键概念 —— State 和 Status 状态命名区别。
也指向了一个更深层次的,我们更需要思考的一个工程思想,同时也是《阿里巴巴 Java 开发手册》的开篇:编程规约 - 命名风格。

一、State 与 Status 的差异
在深入工程案例之前,我们先回到这两个英文单词本身。
State 源自拉丁语 status(两者同源),后来演化为指代事物在某时刻整体所处的存在方式或条件。它强调的是一个连续变化过程中的某个横截面,天然带有“状态会变”的暗示。
例如:状态机用
“state machine”,其中每一个 “state” 都是在状态流转链路上的一个节点,它们会与下一次会是什么状态产生关联变化。
Status 则更接近拉丁语原义,指相对固定的地位、身份或处境。它强调的是离散的、快照式的判定结果。
例如:HTTP 协议用
“status code”(状态码),每一次的状态码都是这次状态瞬间的快照,只是为了固定响应,与下一次的状态码会是什么毫无关系。
用一部电影来做比喻:
- State 像一部电影中的一帧画面,它会不断地变化。
- Status 像这部电影是 “播放” 还是 “暂停”,它只作为瞬间的状态。
二、两个维度一张图彻底分清
很多人的困惑在于:同一个业务场景里,明明既有 State 又有 Status,它们到底怎么分?最好的办法不是背定义,而是同时用两个维度去审视同一个对象 —— 纵向时间维度和横向信息密度维度。
(1)纵向时间维度:值之间是否构成“剧情线”
- State 的值存在明确的先后顺序和流转规则
比如 INIT → ASKING → EVALUATING → COMPLETED,永远不能从 COMPLETED 跳回 INIT。这些值连起来就是一条“剧情线”,每个值都是剧情中的一个节点,一旦丢掉前面的“记忆”,剧情就断裂了。
- Status 的值彼此独立,没有任何先后关系
比如答题链路的状态可以是 INIT、ASKING 或 EVALUATING,它们之间既不存在“下一步”,也不携带“从哪里来”的信息。你完全可以用一个新的结果直接覆盖旧结果,不需要知道历史。
(2)横向信息密度维度:单个值究竟说了多少信息
- State 需要高信息密度,往往是一个对象
状态机做决策时,仅知道“当前在 ASKING”不够,还必须知道:第几题?是否追问?还能追几次?
所以 State 常常被设计成一个复合对象,把阶段标识 + 进度上下文全部打包。
- Status 只需要一个低信息密度的枚举值
它本来就是用来给人看、用来快速分流的,比如“现在进入了追问状态”,一个 FOLLOW_UP 标签足矣。
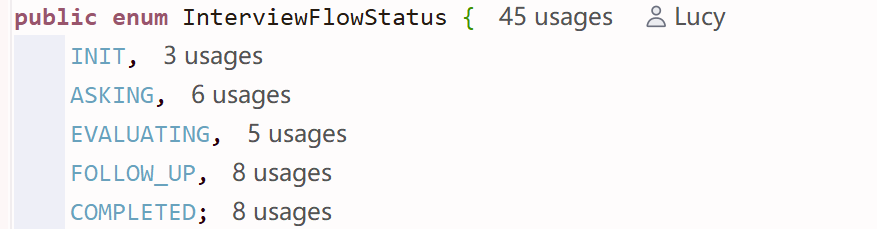
一张状态流转图
最后用一句话来讲:
InterviewFlowStatus = 流程阶段
InterviewFlowState = 流程阶段 + 当前进度 + 当前题号 + 追问信息

上图的 State 展示面试流程的可用阶段 —— 在链路中获取时不仅可以知道现在是 ASKING 阶段,还可以知道类似:当前是第几道主问题?当前题是不是追问题?之类的状态。
而 Status 则是其中类似 INIT 的只为展示流程推进到哪个阶段 —— 每个值是独立的,只是展现了其中存在的所有流程节点。
沿着这个标准,规律就非常清晰了:
| State | Status | |
|---|---|---|
| 核心语义 | 过程阶段,表示“走到了哪一步” | 快照结果,表示“结果怎么样” |
| 值之间的关系 | 有流转关系,可以画状态图 | 彼此独立,不可互转 |
| 变化方式 | 沿固定路径演进,事件驱动 | 每次独立赋值,与上次无关 |
| 经典例子 | 面试阶段、订单流程、TCP 连接 | 答题结果、HTTP 响应码、任务结果 |
至此,分辨 State 和 Status 不再需要死记硬背,只需要问一句:“这个值,是在一个连续流程中的一步,还是仅仅展示当下状态?”
三、状态机为什么返回的是对象
回到前言中那个 “Agent 失忆” 的真实场景。问题的根源在哪?
如果你设计的 current(sessionId) 方法只返回一个简单的阶段字符串:
// 简陋的设计
public String current(String sessionId) {
return "ASKING"; // 只能知道当前在提问
}
系统只能做出粗粒度的判断——“现在是提问阶段”。但实际面试流程必须回答以下问题:
- 现在是第几道主问题?
- 当前展示的题号是多少?
- 这道题是不是追问题?
- 一共还有几道题?
- 当前主问题已经追问了几次?
- 还能再追问几次?
这些信息,一个 String 根本承载不了。所以正确的设计是返回一个包含完整流程进度的复合对象:
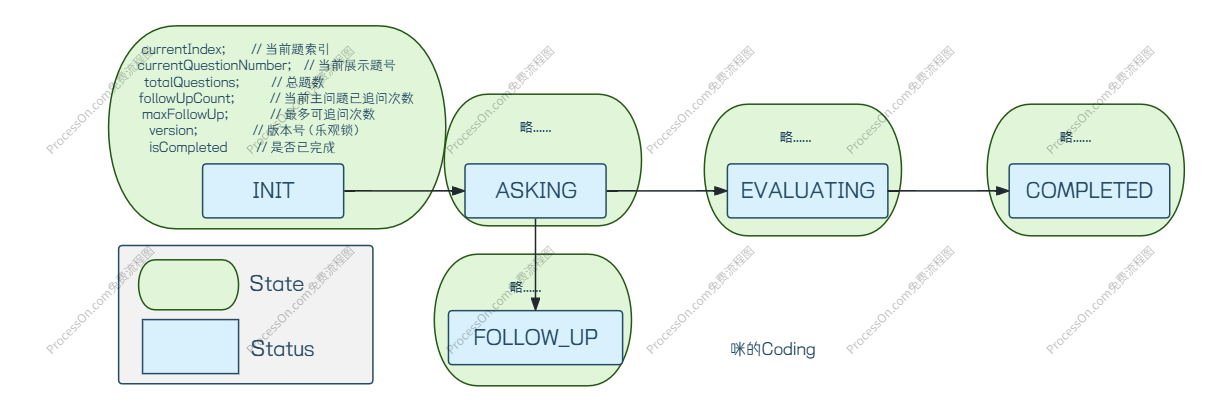
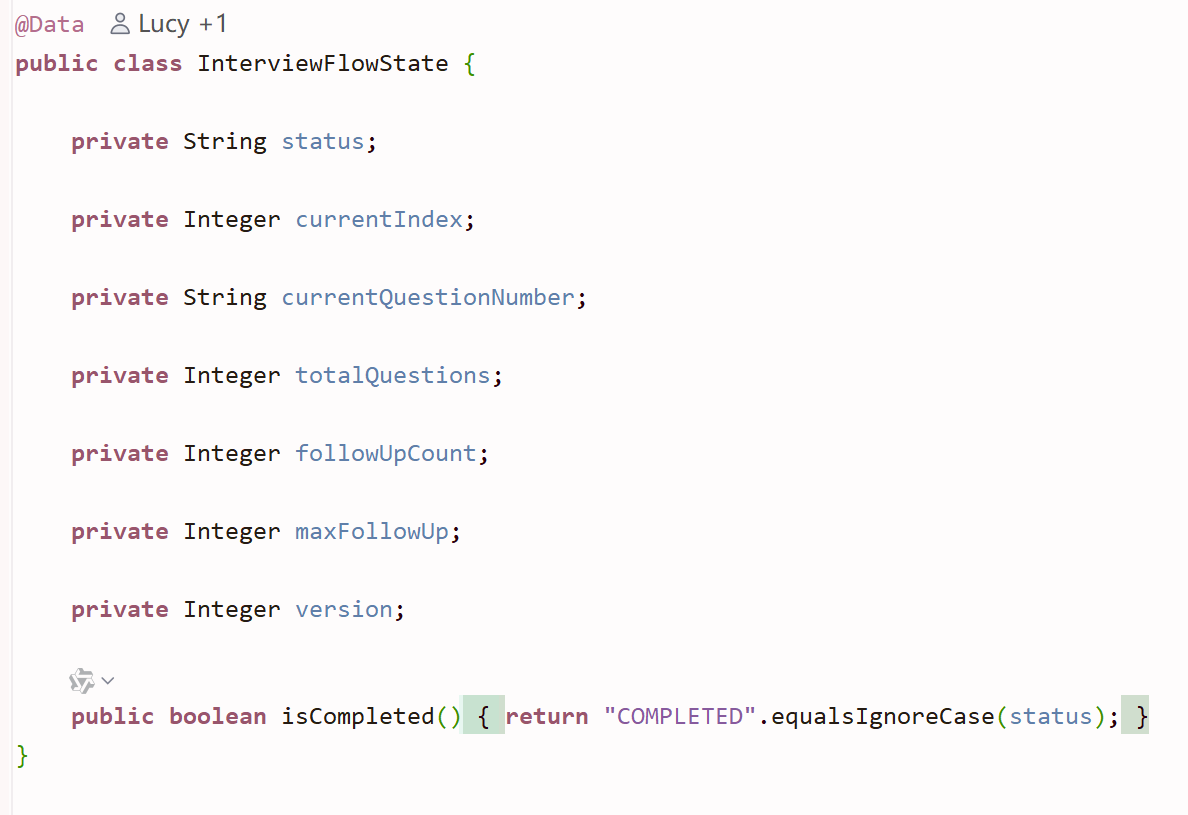
public class InterviewFlowState {
private String status; // 阶段标识:INIT / ASKING / EVALUATING
private Integer currentIndex; // 当前题索引
private String currentQuestionNumber; // 当前展示题号
private Integer totalQuestions; // 总题数
private Integer followUpCount; // 当前主问题已追问次数
private Integer maxFollowUp; // 最多可追问次数
private Integer version; // 版本号(乐观锁)
public boolean isCompleted() {
return "COMPLETED".equalsIgnoreCase(status);
}
// 是否已完成
}
状态机通过服务获取这个对象:
public InterviewFlowState current(String sessionId) {
if (StrUtil.isBlank(sessionId)) {
return null;
}
return interviewQuestionCacheService.getInterviewFlow(sessionId);
}
当系统拿到完整的 InterviewFlowState 时,能做的判断发生了质变。假设当前进度是第 2 道主问题:
InterviewFlowState 某时刻的快照:
status = ASKING
currentIndex = 1
currentQuestionNumber = "2"
totalQuestions = 5
followUpCount = 0
maxFollowUp = 2
如果只看 status = ASKING
→ 只知道“正在等用户回答”
如果拿到完整对象
→ 可以判断:
✓ 当前应该展示第 2 题
✓ 用户提交的 questionNumber 必须是 "2"
✓ 当前不是追问题(followUpCount == 0)
✓ 答完且不追问时,推进到第 3 题
✓ 如果触发追问,followUpCount + 1,但不超过 maxFollowUp
这就是状态机读取状态时返回完整对象而非简单字符串的真正意义:
为了得到让状态流转到下一步所需的全部信息。
四、命名即设计:在代码中固化认知
计算机科学界有一句调侃:“世界上只有两件难事:缓存失效和命名。” 这句话放在状态管理上,再恰当不过。命名从来不只是“起个好听的名字”,它是你对领域模型理解的最终呈现,是软件设计在代码层面的终极表达。
命名失败,设计必败。 前言中的 String interviewStatus 就是一个活生生的例子:一个模糊的名字,模糊了流程与结果的边界,直接引导开发者用错误的方式去建模,最终导致状态机失忆。
相反,精准的命名是一种强大的约束力。 它让你的代码自带说明书,让后来者在看到类名、字段名的一瞬间,就得到清晰的设计暗示,从而写出符合预期的代码。这就是命名规范所要达到的终极目标:让代码自解释,增强可读性。
所以我们从这件事里得到的最核心的要点就是:命名即设计。
核心命名模式
-
流程状态对象 →
XxxState
包含阶段标识和进度上下文的复合对象,通常由一个类承载。
例:InterviewFlowState、OrderState、ConnectionState -
流程阶段枚举 →
XxxStatus
仅表示当前所处的阶段名称,通常作为XxxState中的一个字段出现。
例:InterviewFlowStatus(值为INIT、ASKING、EVALUATING、COMPLETED)
命名铁律:如果字段需要参与状态机决策,它所属的对象应该叫
State;如果字段只是某次操作的瞬间标签,它应该叫Status。
总结
一切的混乱,都始于一个模糊的名字;而一切的秩序,也始于一个精准的名字。
State 和 Status 的区别,说到底是状态流转中的一步 vs. 展示状态的一帧的区别。但若没有命名来显式地固化这条边界,再深刻的理解也会在代码迭代中烟消云散。
但这次我们走得更远。我们意识到,命名是这场区分最终落地的桥梁。 就像InterviewFlowState 不是一个碰巧好听的名字,它是设计的约定 —— 它向所有阅读代码的人宣告:这是一个参与状态流转的复合对象。
遵循一套优秀的命名规范,你的项目就已经成功了一半。
感谢你看到这里,如果喜欢咪的Coding的话可以点个关注支持一下吧!也欢迎各位在评论区留言!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)