YOLOv8改进 - 注意力机制 | NAM:基于归一化的注意力模块,将权重稀疏惩罚应用于注意力机制中,提高效率性能
前言
本文介绍了基于归一化的注意力模块(NAM),旨在通过抑制不显著特征来提升模型效率。该方法利用批量归一化的缩放因子衡量通道与像素重要性,替代了传统注意力中的全连接层,并引入权重稀疏惩罚以降低计算成本。我们将 NAM 模块及 C2f_NAM 变体成功集成进 YOLOv8,优化了特征提取过程。实验证明,结合 NAM 的 YOLOv8 在保持精度的同时显著提升了计算效率,性能优于 SE 及 CBAM 等主流注意力机制。
文章目录: YOLOv8改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv8改进专栏
介绍

摘要
识别较不显著的特征是模型压缩的关键。然而,这在革命性的注意力机制中尚未被研究。在这项工作中,我们提出了一种新颖的基于归一化的注意力模块(NAM),该模块抑制了较不显著的权重。它对注意力模块施加了权重稀疏惩罚,从而使其在保留相似性能的同时变得更具计算效率。在Resnet和Mobilenet上与其他三种注意力机制的比较表明,我们的方法可以带来更高的准确性。本文的代码可以在https://github.com/Christian-lyc/NAM公开获取。
文章链接
论文地址: 论文地址
代码地址: 代码地址
基本原理
NAM (Normalization-based Attention Module)是一种新颖的注意力机制,旨在通过抑制不太显著的特征来提高模型的效率。NAM模块将权重稀疏惩罚应用于注意力机制中,以提高计算效率同时保持性能。NAM模块通过批量归一化(Batch Normalization)的缩放因子来衡量通道的重要性,避免了SE(Squeeze-and-Excitation)、BAM(Bottleneck Attention Module)和CBAM(Convolutional Block Attention Module)中使用的全连接和卷积层。这使得NAM成为一种高效的注意力机制。
NAM模块结合了通道注意力和空间注意力的子模块,利用批量归一化的缩放因子来衡量通道和像素的重要性,从而实现对特征的有效识别和利用。
- 通道注意力子模块:使用批量归一化的缩放因子来衡量通道的重要性,通过计算权重来获得输出特征。
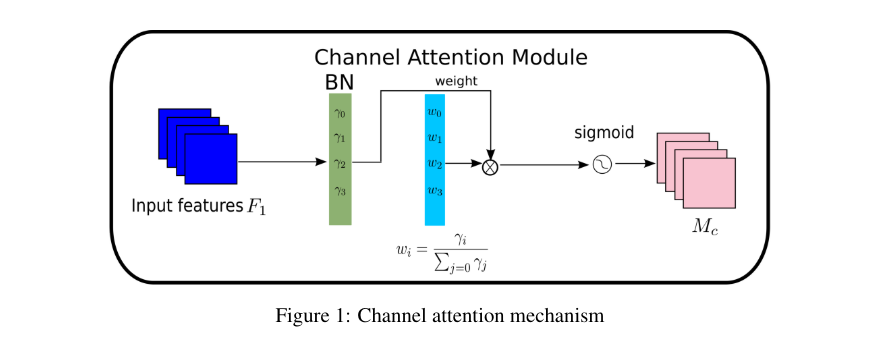
-
空间注意力子模块:应用像素归一化来衡量像素的重要性,得到输出特征。
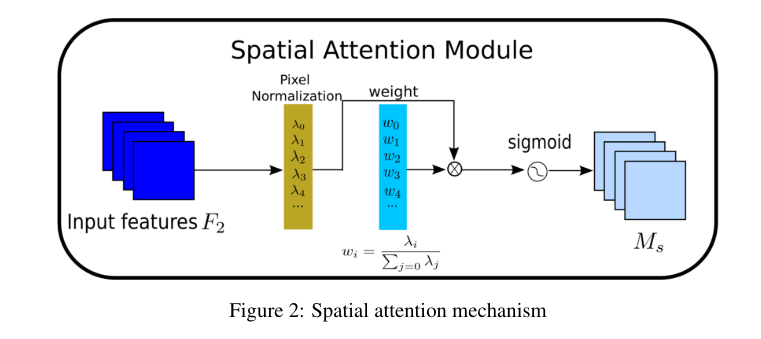
-
权重稀疏惩罚:NAM模块通过添加正则化项到损失函数中,以抑制不太显著的权重,从而提高模型的泛化能力和效率。
数学公式:
NAM模块的损失函数如下所示:
L o s s = ∑ ( x , y ) l ( f ( x , W ) , y ) + p ∑ g ( γ ) + p ∑ g ( λ ) Loss = ∑(x,y) l(f(x, W), y) + p ∑ g(γ) + p ∑ g(λ) Loss=∑(x,y)l(f(x,W),y)+p∑g(γ)+p∑g(λ)
其中:
-
x:输入
-
y:输出
-
W:网络权重
-
l(·):损失函数
-
g(·):l1范数惩罚函数
-
p:平衡g(γ)和g(λ)的惩罚参数
通道注意力子模块的输出特征:
M c = s i g m o i d ( W γ ( B N ( F 1 ) ) ) M_c = sigmoid(W_γ(BN(F_1))) Mc=sigmoid(Wγ(BN(F1)))
空间注意力子模块的输出特征(Equation 3):
M s = s i g m o i d ( W λ ( B N s ( F 2 ) ) ) M_s = sigmoid(W_λ(BN_s(F_2))) Ms=sigmoid(Wλ(BNs(F2)))
其中:
-
M_c:通道注意力子模块的输出特征
-
M_s:空间注意力子模块的输出特征
-
W_γ:通道注意力子模块的权重
-
W_λ:空间注意力子模块的权重
-
BN:批量归一化
-
F_1、F_2:输入特征
核心代码
import torch.nn as nn
import torch
from torch.nn import functional as F
# 定义通道注意力模块
class Channel_Att(nn.Module):
def __init__(self, channels, t=16):
super(Channel_Att, self).__init__()
self.channels = channels # 输入的通道数
# 定义批量归一化层
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x # 保存输入特征图以便后续相乘
x = self.bn2(x) # 对输入特征图进行批量归一化处理
# 获取批量归一化层的权重,并进行绝对值处理和归一化
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
# 调整特征图的维度顺序,从[N, C, H, W]变为[N, H, W, C]
x = x.permute(0, 2, 3, 1).contiguous()
# 将归一化后的权重与调整维度后的特征图相乘
x = torch.mul(weight_bn, x)
# 再将特征图的维度顺序调整回[N, C, H, W]
x = x.permute(0, 3, 1, 2).contiguous()
# 对特征图进行Sigmoid激活,并与残差相乘
x = torch.sigmoid(x) * residual
return x # 返回处理后的特征图
# 定义注意力模块
class Att(nn.Module):
def __init__(self, channels, shape, out_channels=None, no_spatial=True):
super(Att, self).__init__()
# 实例化通道注意力模块
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
# 将输入特征图通过通道注意力模块
x_out1 = self.Channel_Att(x)
return x_out1 # 返回通道注意力处理后的特征图
引入代码
在根目录下的 ultralytics/nn/ 目录,新建一个 attention 目录,然后新建一个以 NAM 为文件名的py文件, 把代码拷贝进去。
import torch
from torch import nn as nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
k = (
d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
) # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(
c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False
)
self.bn = nn.BatchNorm2d(c2)
self.act = (
self.default_act
if act is True
else act if isinstance(act, nn.Module) else nn.Identity()
)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class Channel_Att(nn.Module):
def __init__(self, channels):
super(Channel_Att, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
x = x.permute(0, 2, 3, 1).contiguous()
x = torch.mul(weight_bn, x)
x = x.permute(0, 3, 1, 2).contiguous()
x = torch.sigmoid(x) * residual #
return x
class NAMAttention(nn.Module):
def __init__(self, channels):
super(NAMAttention, self).__init__()
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
x_out1 = self.Channel_Att(x)
return x_out1
class NAM_Bottleneck(nn.Module):
def __init__(
self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5
): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.nam = NAMAttention(c2)
self.add = shortcut and c1 == c2
def forward(self, x):
return (
x + self.nam(self.cv2(self.cv1(x)))
if self.add
else self.nam(self.cv2(self.cv1(x)))
)
class C2f_NAM(nn.Module):
def __init__(
self, c1, c2, n=1, shortcut=False, g=1, e=0.5
): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(
NAM_Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0)
for _ in range(n)
)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
注册
在 ultralytics/nn/tasks.py 中进行如下操作:
步骤1:
from ultralytics.nn.attention.NAM import NAMAttention, C2f_NAM
步骤2
修改 def parse_model(d, ch, verbose=True) :
elif m in [NAMAttention]:
c1 = ch[f]
args = [c1]
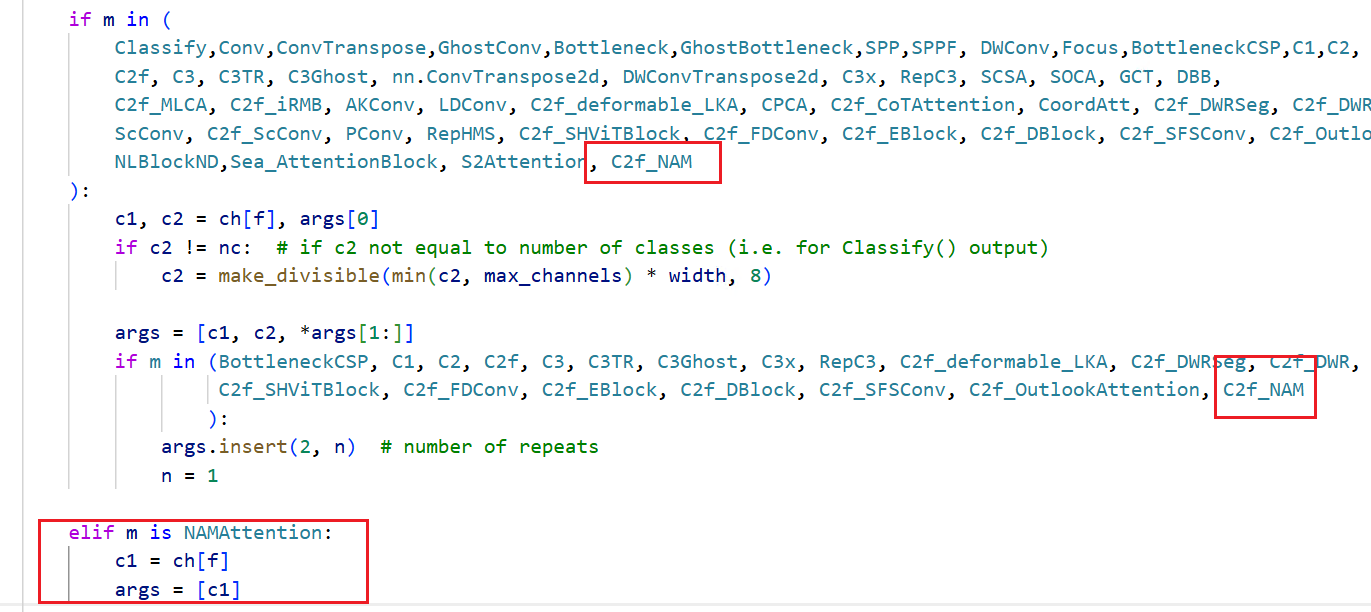
配置yolov8_NAM.yaml
ultralytics/cfg/models/v8/yolov8_NAM.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, NAMAttention, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
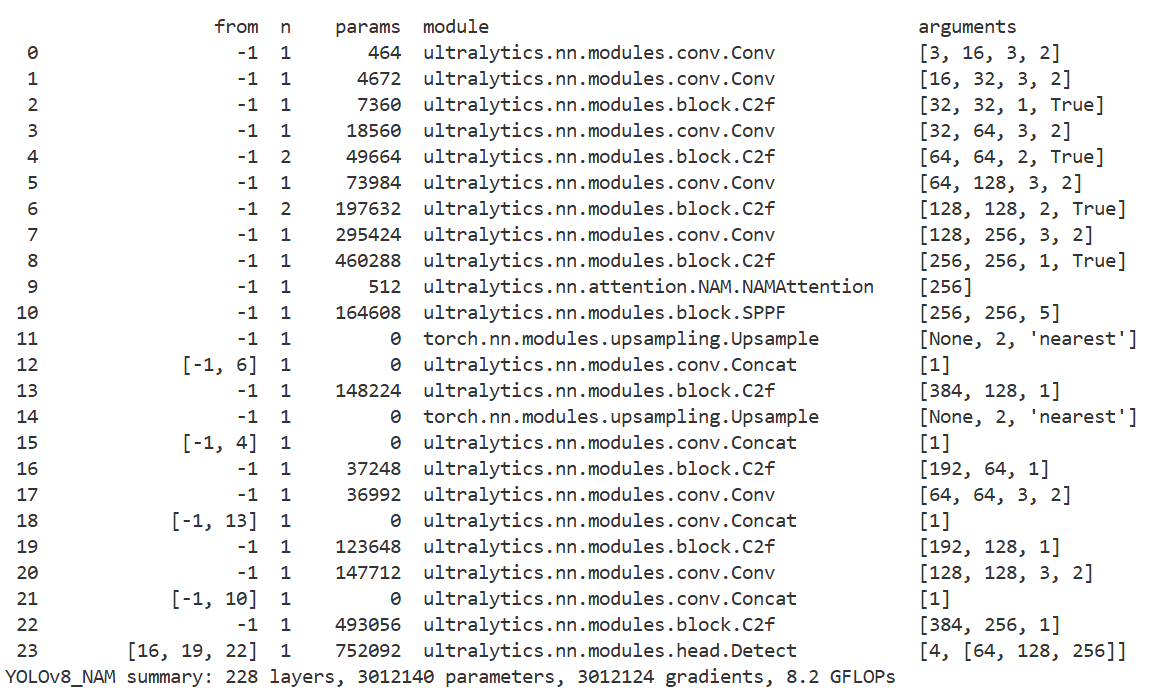
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f_NAM, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_NAM, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_NAM, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f_NAM, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
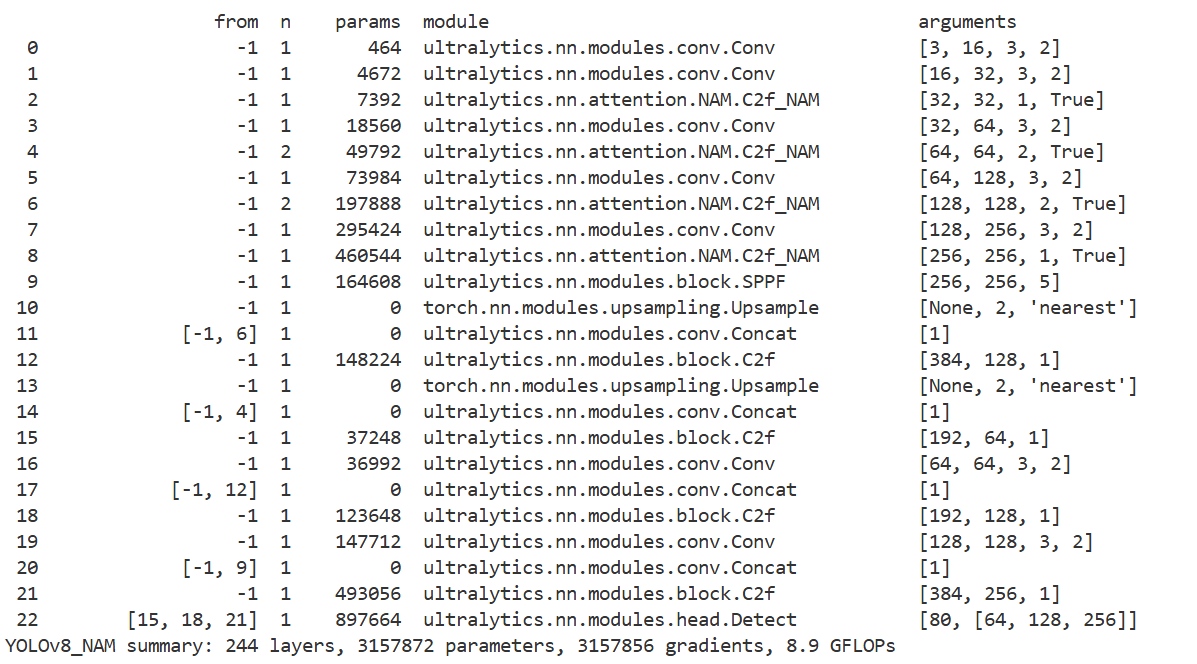
实验
脚本
import os
from ultralytics import YOLO
yaml = 'ultralytics/cfg/models/v8/yolov8_NAM.yaml'
model = YOLO(yaml)
model.info()
if __name__ == "__main__":
results = model.train(data='coco128.yaml',
name='yolov8',
epochs=10,
amp=False,
workers=8,
batch=1)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)