从0到1:企业级AI项目迭代日记 Vol.34|知识图谱接进来、异步嵌套修掉、依赖往回收——藏在修复里的三层架构演进
企业 AI 系统里最难发现的一类问题,从来不是会报错的 bug,而是看起来一切正常、但在某个并发节点悄悄挂住的 “静默故障”。
这周的工程焦点,正好集中在这种类型的问题——异步嵌套、session 锁未释放、外部依赖配置漂移、知识图谱 schema 不稳定。每一项单独看都不算大事,但叠加起来就是企业级系统从“能跑”到“真能扛”之间的那条界线。
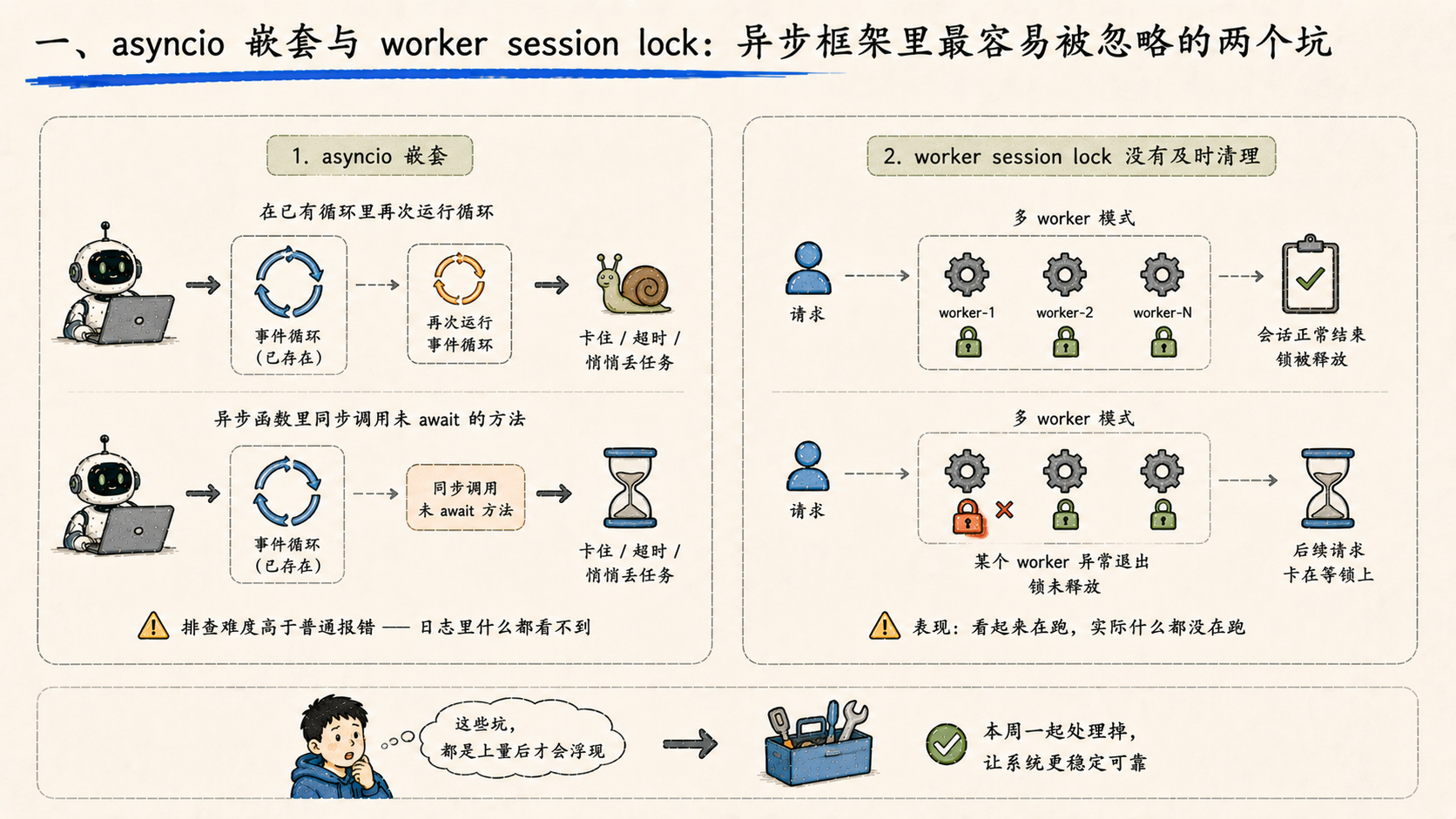
一、asyncio 嵌套与 worker session lock:异步框架里最容易被忽略的两个坑
在异步框架里,有两类问题几乎每个项目都会遇到一次:
第一个是 asyncio 嵌套。 简单说就是在已经存在的事件循环里又跑了一个事件循环,或者在异步函数里同步调用了一个本应 await 的方法。表现是程序不会崩,只会在某些场景下卡住、超时、或者悄悄丢任务。排查难度高于普通报错——因为日志里什么都看不到。
第二个是 worker session lock 没有及时清理。 多 worker 模式下,每个 worker 进程持有自己的 session 上下文,如果一个会话异常退出时锁没释放,下一次请求就会卡在等锁上。表现也是“看起来在跑,实际什么都没在跑”。
这两件事都不是写功能时能预见到的,是上量之后才会浮出来的。这周把它们一起处理掉。
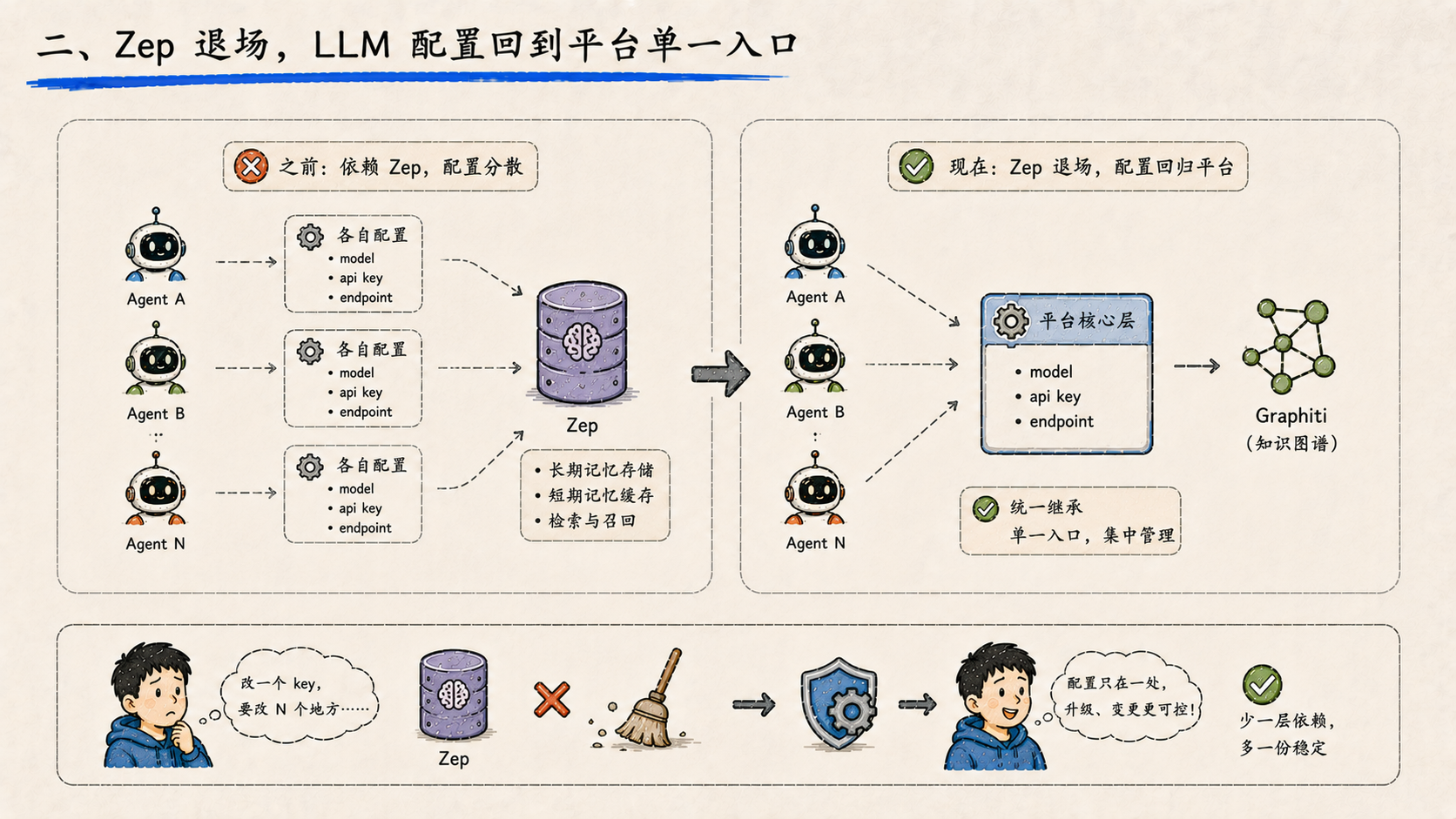
二、Zep 退场,LLM 配置回到平台单一入口
记忆管理这一层做了一次重要的架构收口——清理掉对 Zep 的依赖,改为直接继承平台的核心 LLM 配置。
Zep 是一个第三方记忆管理服务,提供长短期记忆的存储和检索。早期接入是为了快速验证记忆能力,但代价是:每一个使用它的 agent 都要单独配一份模型连接、API key、endpoint。当模型升级、key 轮换、地址变更的时候,要改的地方散落在多个服务里。
清掉 Zep 之后,记忆能力由 Graphiti 接手(知识图谱方向,下面会讲),LLM 配置只在平台核心层维护一份,所有下游服务统一继承。
这件事的工程意义比技术意义更大。外部依赖每多一个,平台就多一处配置漂移的可能性。能收回来的,就该收回来。
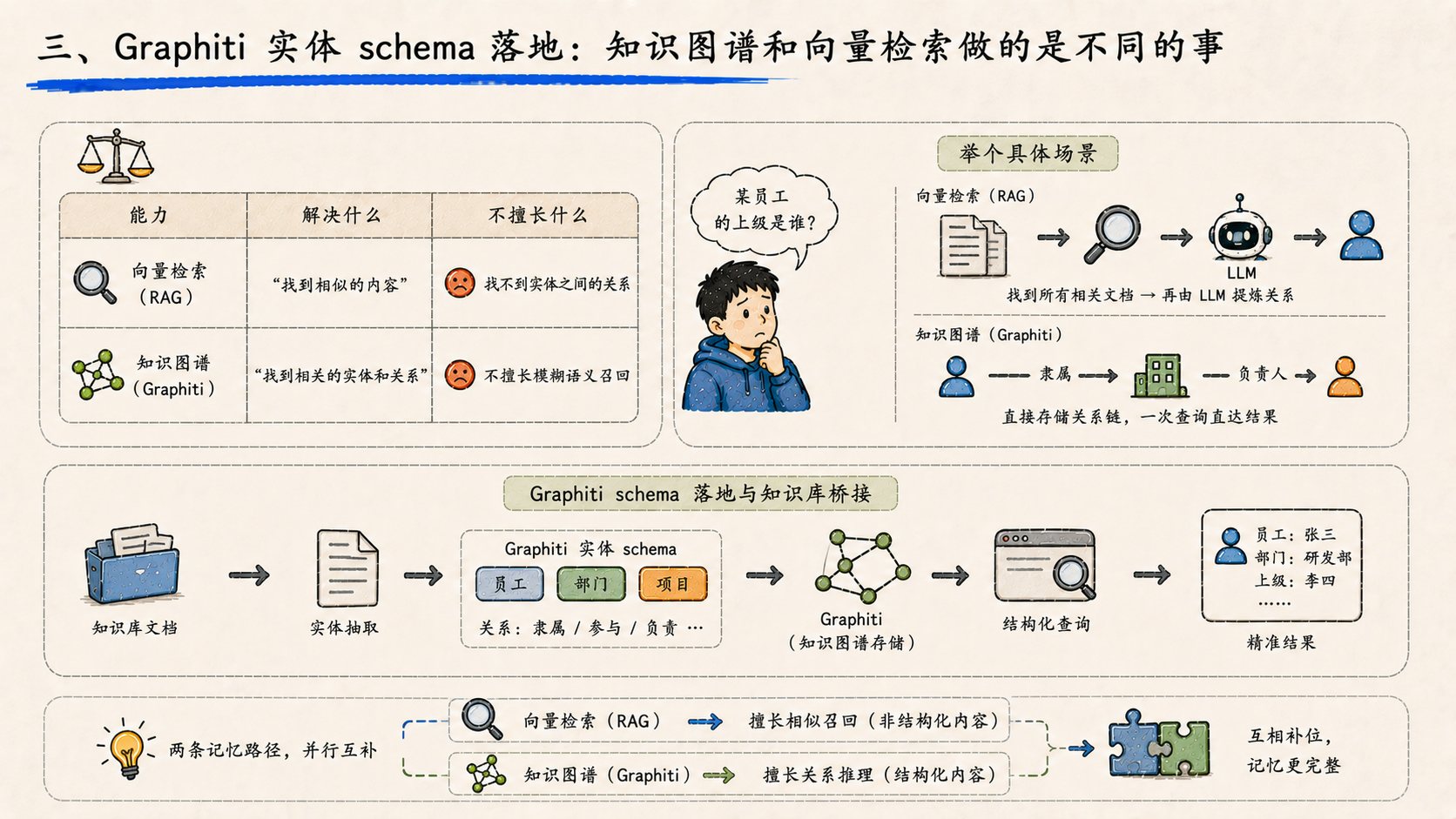
三、Graphiti 实体 schema 落地:知识图谱和向量检索做的是不同的事
记忆能力的承接者是 Graphiti——一个基于知识图谱的记忆框架。它和已经在用的 RAG 向量检索不冲突,因为两者解决的是不同的问题:
| 能力 | 解决什么 | 不擅长什么 |
|---|---|---|
| 向量检索(RAG) | “找到相似的内容” | 找不到实体之间的关系 |
| 知识图谱(Graphiti) | “找到相关的实体和关系” | 不擅长模糊语义召回 |
举个具体场景:在知识库里搜“某员工的上级是谁”,向量检索能找到所有提到这个员工的文档,但是要从文档里再提炼“上级是谁”这层关系,需要 LLM 再过一遍。知识图谱直接存了“员工 → 隶属 → 部门 → 负责人”这条关系链,一次查询就能拿到。
这周做的是把 Graphiti 的实体 schema 稳定下来,并且打通和现有知识库的桥接——知识库里上传的文档,可以作为 Graphiti 的实体抽取源。两条记忆路径并行,互相补位。
四、多租户 token 入账:用量统计真正的技术难点
企业用量统计上线,最容易被低估的是 token 入账的实现复杂度。
表面上是“记一个数”,实际上要解决几件事:
-
每一次 LLM 调用之后,要把
prompt_tokens和completion_tokens拆开记,因为这两者在大多数模型上是分开计费的 -
流式调用没有最终
usage字段,要在流结束之后从 chunk 里反推 -
多 worker 模式下,写入要去重、要支持并发,不能用进程内累加
-
跨 agent、跨工作流、跨用户的归属关系要在调用栈最深处就标记好,不能在写入时再回溯
把这些处理干净之后,企业才能拿到一份真正可对账的用量数据——哪个部门用了多少、哪个工作流烧了多少、哪个时间段是高峰。
让 AI 平台的成本变得可计量,是它能被纳入企业预算体系的前提。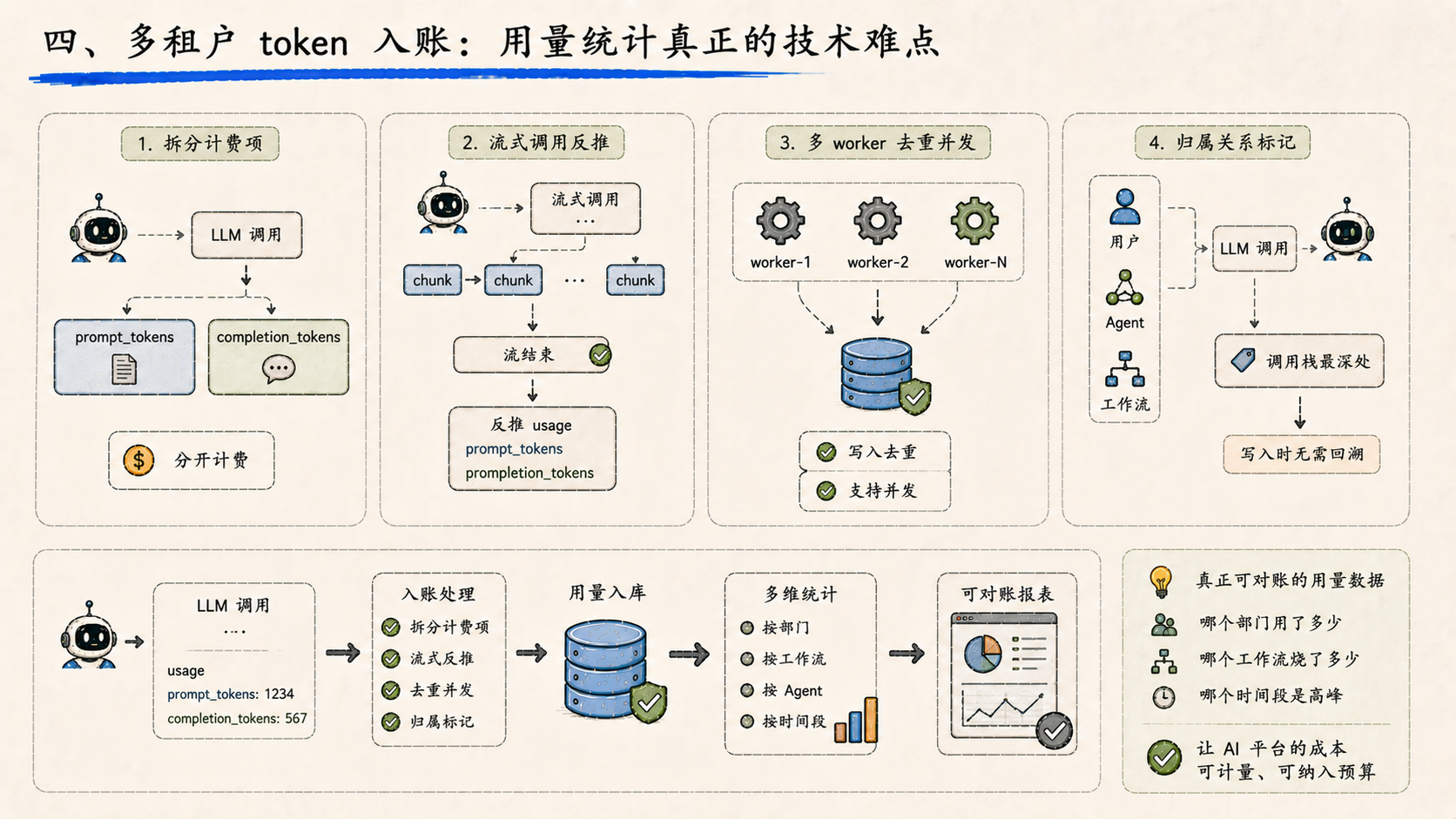
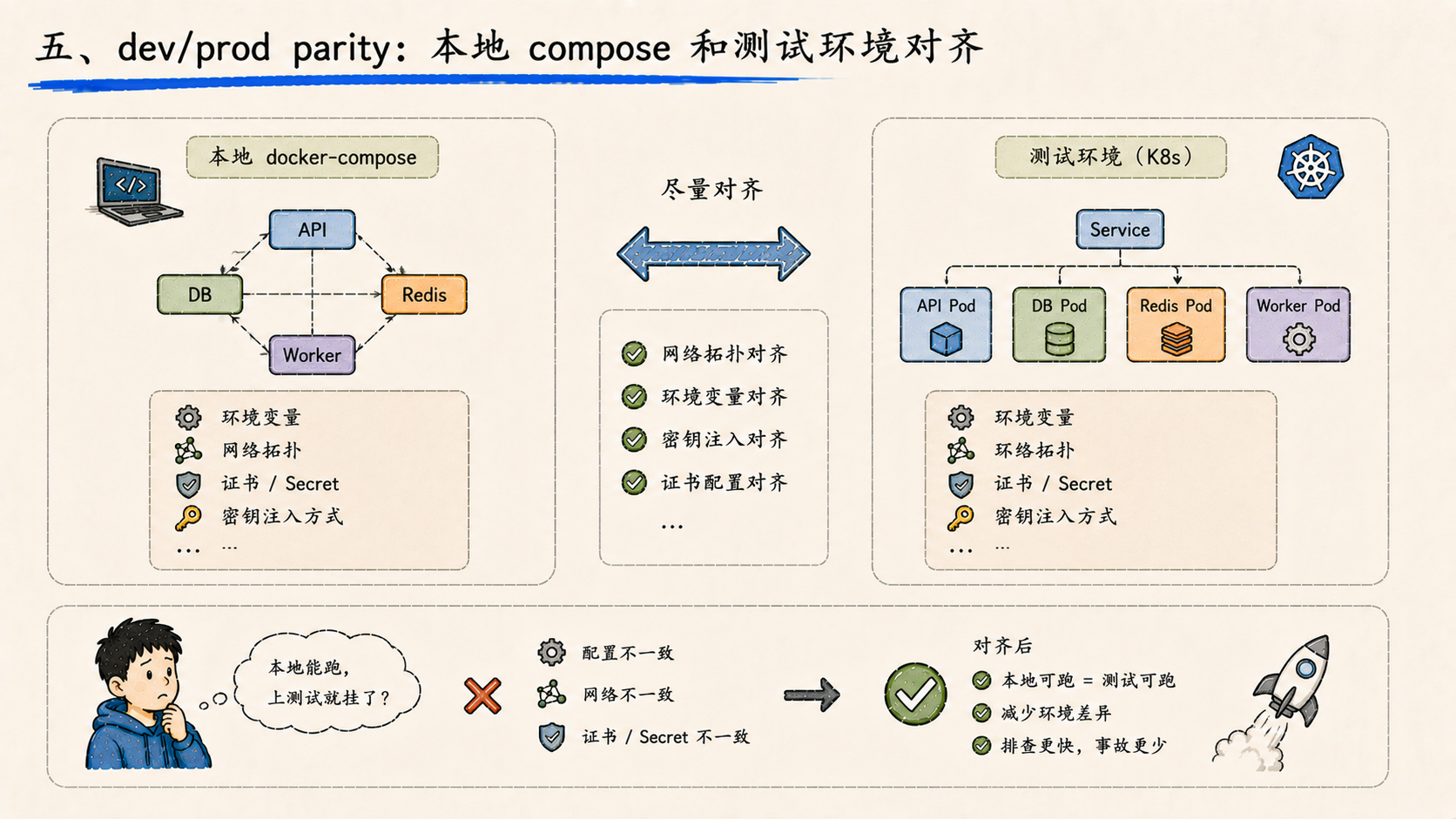
五、dev/prod parity:本地 compose 和测试环境对齐
还有一件容易被忽略的事——本地 docker-compose 启动方式和测试环境的等效性。
很多平台的“本地能跑、上测试就挂”,根源是这两套启动方式背后的配置不一致:环境变量、网络拓扑、证书、secret 注入方式。本地用 compose 走的是一套路径,K8s 里走的是另一套。
这周把这两套尽量对齐了——本地起的服务,在网络拓扑、环境变量、密钥注入上和测试环境保持等效。这不是炫技,是给团队省排查时间。任何一个 dev/prod 的偏差,都会在某天变成线上事故的伏笔。
这周的工作没有新增多少用户能直接看到的功能。但是异步层的并发安全、外部依赖的收口、知识图谱的承接、多租户计量、本地与线上的对齐——这五件事每一件都是把整个系统的根基往下夯了一层。
企业级系统的成熟度,不是看上层功能有多花哨,而是看下面这些“看不见的事”有没有在持续被处理。
这,是第三十四天。
《从0到1:企业级AI项目迭代日记》记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)