大数据转大模型主要是为了保命,拥抱大模型,别等到2026年才后悔!
随着AI岗位需求激增,传统大数据技能面临挑战。文章指出,大数据工程师转型大模型应用开发是关键,转型方向包括RAG应用开发、AI Agent开发和LLM数据工程。这些方向能利用大数据工程师的现有技能,如数据管道、SQL和分布式系统经验,实现低成本高效率的转型。文章还提供了具体的实践路径和避坑指南,鼓励工程师主动学习和实践,提升自身在大模型领域的竞争力。
大数据人转大模型:保命指南
为什么必须转?
2026年,腾讯春招AI岗位占比超70%,字节AIGC应用开发开到40-70K×15薪,而传统ETL开发岗正被低代码工具和AI编码助手蚕食。这不是焦虑营销,是正在发生的事。
对大数据工程师来说,转型大模型应用开发**不是为了换工作,是为了在现在的岗位上活下去**。你的Spark SQL、Hive调优、Doris集群运维——这些技能不会一夜失效,但纯靠它们已经不够了。领导开会开始提"AI赋能数据",产品经理问"能不能用大模型做智能取数",你总不能说"我不会"。
核心判断:**大模型应用开发是大数据工程师成本最低、杠杆最高的转型方向。** 不用从零学算法,不用去读研究生、读博,只需要把你已有的工程能力嫁接到LLM上。
大数据工程师的天然优势
别被"大模型"三个字吓住。你手里已经有的牌,比你想的多:
1. 数据管道能力直接复用。 RAG系统的核心链路——数据采集、清洗、切分、向量化、入库——本质上就是ETL。你写了多少年Airflow/DolphinScheduler调度任务?这就是RAG的数据准备层。换个语料,Pipeline还是那套Pipeline。
2. SQL方言迁移到向量检索。 你精通Hive SQL、Spark SQL、Doris SQL,那学向量数据库的检索API就是换个方言。Milvus、Qdrant的查询语法比SQL简单多了,本质是相似度排序而非精确匹配。
3. 分布式系统经验降维打击。 搞过YARN资源调度、Spark任务优化的人,理解大模型推理的batch调度、GPU显存管理会更快。你见过OOM,你调过Executor内存,这些直觉在LLM部署时同样管用。
4. 对数据质量有肌肉记忆。 大模型应用最怕什么?垃圾进垃圾出。你做了这么多年数据治理,知道什么叫脏数据、什么叫数据倾斜——这些经验在构建RAG知识库时是核心竞争力。
三条保命路径
路径一:RAG应用开发(最快上手)
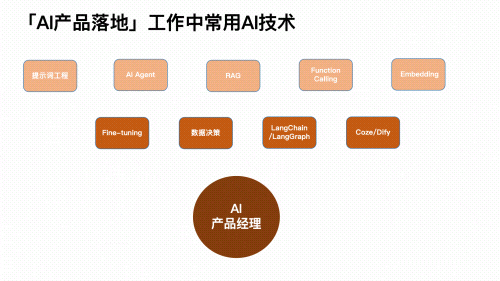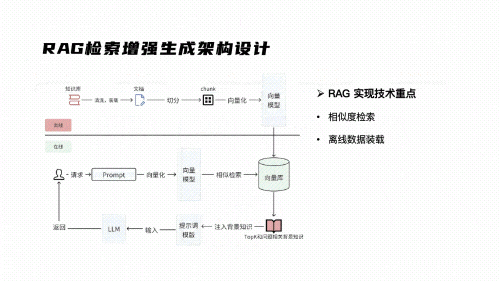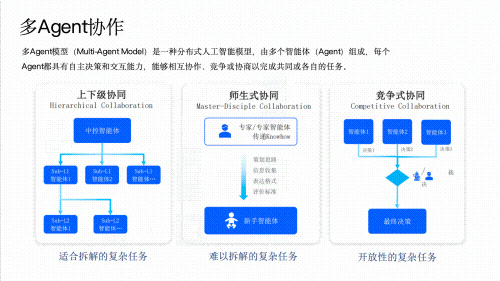
RAG = 检索增强生成,说白了就是让大模型"先查资料再回答"。这是企业落地最多的大模型应用形态,也是大数据工程师最容易切入的。
技术栈:Python + LangChain/LlamaIndex + 向量数据库(Milvus/Chroma) + Embedding模型 + LLM API
实战代码——一个最小可用的RAG Pipeline:
from langchain.document_loaders import TextLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain.embeddings import HuggingFaceEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.chains import RetrievalQAfrom langchain.llms import OpenAI# 1. 加载文档 —— 这步你熟,就是数据采集loader = TextLoader("company_faq.txt")docs = loader.load()# 2. 切分 —— 这步你也熟,就是数据清洗+分片splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50)chunks = splitter.split_documents(docs)# 3. 向量化入库 —— 这步是新的,但本质是建索引embeddings = HuggingFaceEmbeddings( model_name="BAAI/bge-small-zh-v1.5")vectordb = Chroma.from_documents( chunks, embeddings, persist_directory="./chroma_db")# 4. 检索+生成 —— 组装查询链qa = RetrievalQA.from_chain_type( llm=OpenAI(model="gpt-4o-mini"), retriever=vectordb.as_retriever(search_kwargs={"k": 3}), return_source_documents=True)result = qa("公司差旅报销标准是什么?")print(result["result"])
看到没?加载→清洗→入库→查询,这就是你每天干的ETL,只是存储引擎从Hive换成了Chroma,查询方式从SQL换成了语义检索。
落地场景建议: 在你的公司里,找一个数据查询痛点——比如"业务方总问取数口径",做一个内部知识库问答工具。这就是可以汇报的AI项目。
路径二:AI Agent开发(上限更高)
Agent = 大模型自主调用工具完成复杂任务。2026年大厂AI岗位里,Agent开发岗需求最猛,字节开到40-70K×16薪。
大数据工程师做Agent有独特优势:你理解数据流转,能设计出"让AI调用数据工具"的编排逻辑。
from langchain.agents import Tool, AgentExecutorfrom langchain.agents import create_react_agentfrom langchain.llms import OpenAI# 定义工具 —— 让AI调用你的数据能力def query_doris(sql: str) -> str: """查询Doris数据库""" import pymysql conn = pymysql.connect(host="doris-fe", port=9030, database="analytics") cursor = conn.cursor() cursor.execute(sql) rows = cursor.fetchall() conn.close() return str(rows[:20]) # 限制返回量def query_lineage(table: str) -> str: """查询表级血缘关系""" # 这就是你做的血缘解析系统 import requests resp = requests.get( f"http://lineage-api/api/v1/lineage/{table}" ) return resp.json()tools = [ Tool(name="DorisQuery", func=query_doris, description="执行SQL查询Doris数据仓库,输入为SQL语句"), Tool(name="LineageQuery", func=query_lineage, description="查询表的血缘关系,输入为表名"),]agent = create_react_agent( llm=OpenAI(model="gpt-4o-mini"), tools=tools, prompt="你是一个数据分析师助手,帮助用户查询数据和血缘关系。")executor = AgentExecutor(agent=agent, tools=tools, verbose=True)result = executor.invoke({"input": "dws.order_summary这张表的数据从哪些表来的?"})
这个例子把你的Doris查询能力和血缘解析系统直接暴露给AI Agent。你已有的系统就是Agent的工具,你只需要加一层LLM编排。
路径三:LLM数据工程(最稳过渡)
如果你觉得RAG和Agent还是有点远,那LLM数据工程是最稳妥的过渡——它就是你现在的工作,加上"为模型服务"这个定语。
具体方向:
-
**预训练数据工程:** 为大模型训练准备高质量语料,包括去重、过滤、格式化。你的Spark集群正好派上用场。
-
**SFT数据构造:** 构造指令微调数据集(instruction-response pairs),这需要对业务逻辑的理解。
-
**评估数据管理:** 建立模型评测基准数据,持续监控模型输出质量。
这条路不需要你学太多新东西,但要让你的数据工作"看得见AI价值"。
避坑清单
坑1:试图从零学深度学习。 不要去啃《动手学深度学习》,不要去推公式。你是应用开发者,不是算法研究员。先跑通RAG,再考虑要不要深入底层。
坑2:只做Prompt Engineering。 写提示词确实上手快,但天花板低、可替代性强。Prompt技巧要会,但不能只会这个。
坑3:做个套壳ChatBot就交差。 “你好,我是AI助手”——这种demo领导看一眼就忘了。要做有业务价值的工具:数据查询助手、智能取数、血缘分析Agent。
坑4:忽视数据质量。 RAG系统效果差,90%是数据问题。你的数据治理经验在这里是金矿,别浪费。
坑5:等待公司安排。 没人会给你排"学大模型"的Sprint。用20%时间,在现有项目里找AI切入点,先做出一个能用的东西。
行动计划
如果你决定开始,这是我的建议顺序:
-
第一周: 跑通一个LangChain + Chroma的RAG demo,用你自己公司的数据
-
第二周: 把RAG部署成内部服务,加一个简单的前端(Streamlit就够)
-
第三周: 接入你已有的数据系统(Doris/Hive),让RAG能查真实数据
-
第四周: 试着做一个简单Agent,调用你的数据工具
-
持续: 在周报里写"AI赋能探索",让领导知道你在做这件事
如果自学坚持不下去或者耗时太久 ,直接选择 若泽数据大模型实战课程!老师本身企业大模型在职。
记住,目标不是成为AI科学家,而是在你现有的岗位上,加一条"大模型应用能力"的护城河。
不转型不会马上被裁,但转型了你就多了一层保险。 在这个AI快速渗透的时代,多一张牌,就多一份底气。
传统产品经理,正在成为下个被淘汰的“传统岗位”。
过去画原型、写 PRD、跟进度的“传统技能包”,在AI时代正迅速贬值。63% 的企业转型做 AI 产品!当下的问题不再是“要不要学 AI ”,而是“如何构建 AI 产品”。
前段时间还跟字节、腾讯的资深 AI 产品经理沟通,他们反馈:在大量招人,只要有 AI 相关的项目经验,基本都能拿到面试机会,而且领导很舍得给钱,涨薪 40-60% 很正常!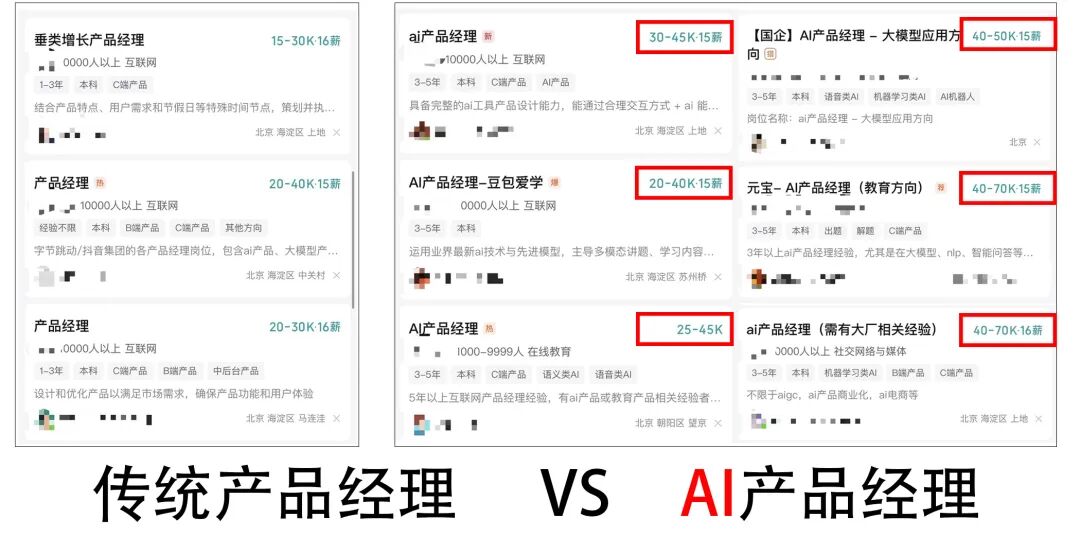
01
接下来的产品人,得卷AI能力了!
如今AI大火,行业极速发展的背后,懂AI 产品人才却严重稀缺。这不是要你转技术岗,而是要掌握构建 AI 产品的核心方法:
- 如何将你的领域知识,转化为 AI 产品的核心竞争力?
- 如何用 AI 技术实现你的产品需求?
- 如何设计真正懂用户的 AI 交互体验?
- ……
懂AI,就是产品经理的“救命稻草”!
风口之下,与其焦虑被行业淘汰
不如先人一步享受AI技术带来的红利!
我把AI产品经理的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

(不限年龄!不限岗位!没有代码基础也能学!)
🎁现在扫码,完课还送:
《AI产品面试题库》《AI大模型应用案例集》
02
掌握技术+实战,快速转型!
想成为一名卓越的AI大模型产品经理,需要从技术、到项目实战的全方位转型指南!
**1)**AI产品应用原理解析,产品经理也能听懂!
对于产品经理来说,如果你不懂技术,做不了业务和AI大模型技术衔接、定义不了数据需求,是没法完整的落地一个产品的!
本次课程,专门面向产品经理人群,解析当下最热门的AI产品应用的必备的「大模型」、「多模态」的实际应用和算法原理!解析AI产品应用技术,积累大模型能力!简单易懂,不需要会代码,小白也能掌握!
- 大模型微调:掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。学习如何利用领域数据(如制造、医药、金融等)进行模型定制
- AI Agent智能体搭建:学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。构建垂类场景下的智能助手产品(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)
2)超全行业案例解析!
课程详细讲解现阶段,大模型在各个行业和领域的应用现状!包括:零售与电商、教育、医疗、泛娱乐、法律等等10大行业!
详细讲解案例的思路、应用场景,以及背后的技术原理、核心技术!揭秘各个行业、场景的真实现状,和未来产品的发展与机遇!
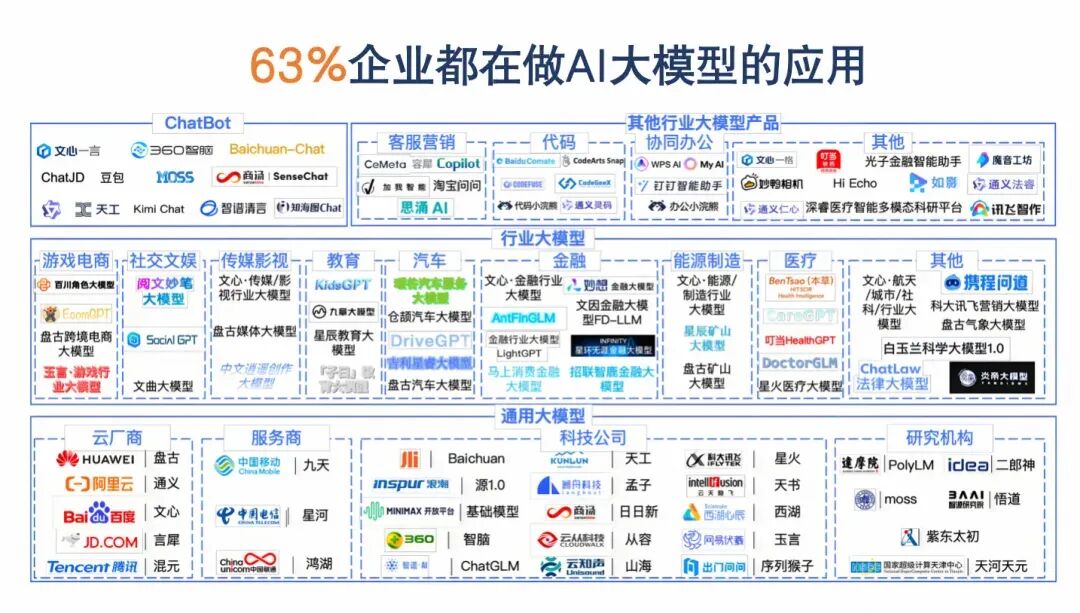
可以说,讲解完一个案例,就能积累一个AI产品实践的经验!
课程中所涉及到的实战项目,都可以直接在自己的工作中使用,让自己的产品/项目有可借鉴的成功案例!
3)AI产品经理求职专项辅导
课程中会系统的帮助大家拆解字节、腾讯、百度等大厂AI PM岗位JD关键词,掌握AI PM高频面试题型与回答框架;展示 AI 相关能力的关键技巧:Prompt设计、模型评估、A/B测试、成本意识、与算法/工程协作经验;
- To B类AI产品经理:突出“行业理解 + 技术落地 + 商业闭环”能力的简历结构设计,展示项目成果;从客户需求洞察到技术方案设计,展现端到产品思维;如何评估To B AI产品的可行性、客户付费意愿与实施成本
- To C类AI产品经理:拆解头部公司岗位JD,将过往尽力转化为AI产品叙事逻辑;从行业趋势、产品设计题、案例分析&数据分析题、技术理解边界等全流程辅导面试;避免无效海投、锁定最适合的AI产品岗位;

03
本次课程,全程直播讲解,能直接对话大佬和专业助教,不懂就问,超详细的案例,小白也能轻松get!
完课后,还赠送《AI产品经理面试题库》、《AI大模型应用案例集》!不断更新中……

适合人群:
- 想转型AI产品经理、AI项目管理专家、AI产品解决方案等岗位
- 想进行AI产品创业的创业者
- 想成为制作AI产品的程序员
- 想利用AI解决企业问题的管理岗
- 想在AI方向寻找就业方向的毕业生
- AI方向前景广阔、待遇好!
目前,很多产品人已经通过完整学习拿到大厂高薪offer,收入嗷嗷涨!
我把AI产品经理的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献177条内容
已为社区贡献177条内容

所有评论(0)