大模型核心加速器:KV Cache 如何将 O(n²) 计算复杂度降至 O(n)?
KV Cache 是大模型自回归生成任务的关键优化技术,通过“空间换时间”策略缓存历史 Key 和 Value 向量,将推理复杂度从 O(n²) 降至 O(n)。文章阐述了语义缓存与前缀精确匹配两种核心范式,深入分析了 KV Cache 的技术底层原理、工程化应用及规模化挑战。KV Cache 不仅大幅提升响应速度、降低 GPU 负载,还能显著削减长任务 Agent 的运行成本,成为大模型规模化应用的关键支撑。
“Caches aren’t architecture, they’re just optimization.” – Rob Pike
摘要:KV Cache(Key-Value Cache)作为 Transformer 模型自回归生成任务的核心优化技术,以 “空间换时间” 为核心策略,通过缓存历史运算的 Key 和 Value 向量避免重复计算,将推理计算复杂度从 O(n²) 降至 O(n),不仅大幅提升生成式 API 的响应速度、降低 GPU 负载,更能显著削减长任务 Agent 的运行成本,成为大模型规模化应用的关键支撑。
一、大模型缓存策略的两大核心范式
大模型缓存体系可分为应用层的语义缓存与底层的前缀精确匹配缓存(基于 KV Cache),二者从原理到应用场景形成互补。
1.1 语义缓存:基于意图理解的应用层优化
语义缓存是应用开发者在业务侧实现的缓存方案,核心依托语义理解复用历史回答,广泛适用于客服机器人等用户提问场景多样化的业务。
1.1.1 工作原理
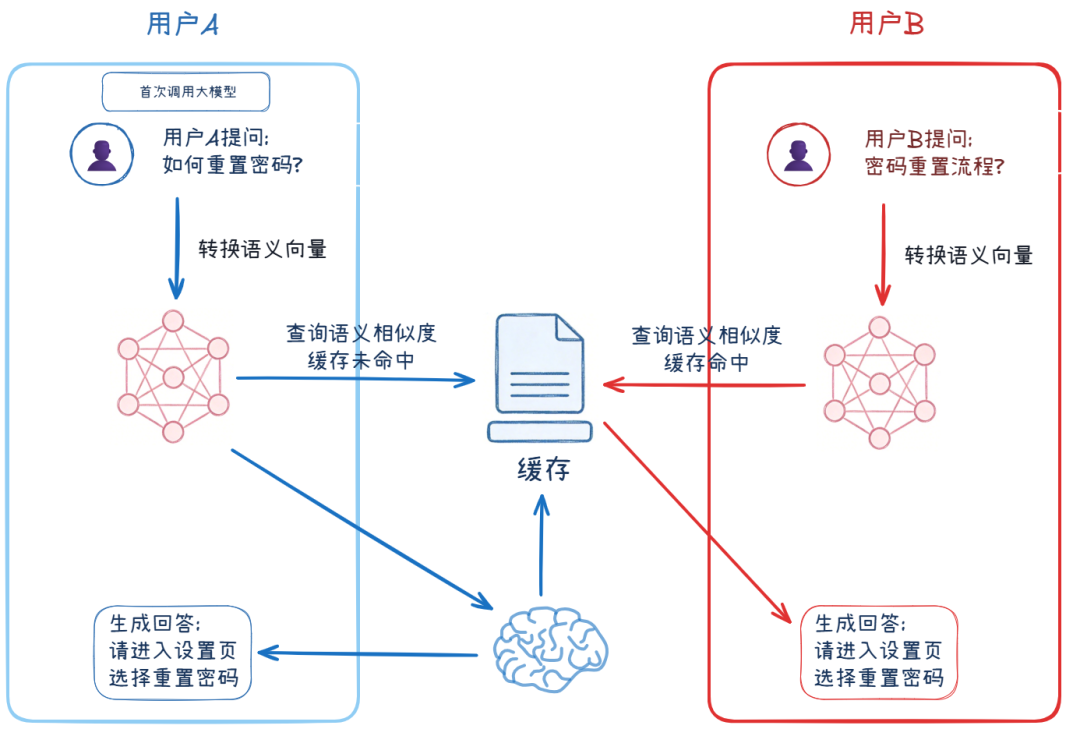
- 意图向量化:借助 Embedding Model 将用户问题转化为表征语义的高维向量;
- 相似度检索:在向量数据库中检索与当前问题向量最相似的历史缓存向量;
- 阈值判定复用:若相似度超过预设阈值,直接返回缓存答案,无需调用大模型。
1.1.2 核心优势
- 兼容多样化表述:可识别措辞不同但意图一致的问题(如 “如何重置密码?”,“重置密码流程?”),实现缓存答案复用;
- 高命中率特性:在用户提问方式多变的场景下,显著提升缓存命中率,降低响应延迟与调用成本。
1.1.3 实现挑战
- 基础设施复杂度高:需额外部署 Embedding Model 与向量数据库作为支撑;
- 准确性平衡难度大:需精细化调优相似度阈值,避免无关问题错误匹配缓存答案。
1.2 前缀精确匹配:模型服务商主导的底层 KV Cache
前缀精确匹配是主流大模型服务商采用的核心缓存机制,核心围绕输入 Prompt 的公共前缀进行精确匹配,而非语义理解,是 KV Cache 技术的核心落地形态。
1.2.1 工作原理
- 缓存对象:缓存模型处理 Prompt 时生成的中间计算状态(K 向量和 V 向量),而非最终回答,避免相同前置内容重复计算;
- 匹配逻辑:新请求到来时,从内容开头扫描并匹配历史缓存的完全一致前缀,文本内容和顺序需完全相同(如缓存 “AB” 时,“ABCD” 可命中 “AB” 段缓存,“BCD” 则完全未命中);
- 关键约束:前缀的微小变动(如系统指令插入动态时间戳)会导致后续缓存全部失效。
二、KV Cache 的技术底层:从 Transformer 原理到执行机制
要理解 KV Cache 的核心价值,需先回归 Transformer 自注意力机制,以及大模型推理的核心阶段特征。
2.1 自注意力机制与重复计算痛点
Transformer 自注意力计算中,每个 Token 生成 Query(Q)、Key(K)、Value(V) 三类向量,注意力计算公式为:
Attention(Q,K,V) = softmax(QK^T/√d_k)V
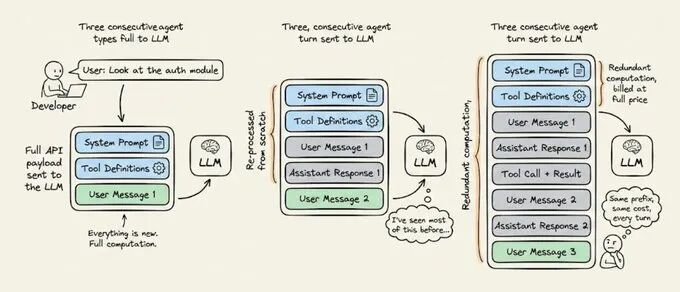
每当 Agent 执行一轮对话操作,都会把整个对话历史发送给大语言模型。
其中包含了系统指令、工具定义,以及多轮对话累积下来的对话历史等。如果没有 KV Cache,所有历史内容在每一轮都需重新计算 Token 的 K、V 向量,导致计算资源过度消耗、推理延迟和成本随序列长度急剧增加。
2.2 大模型推理的两个核心阶段
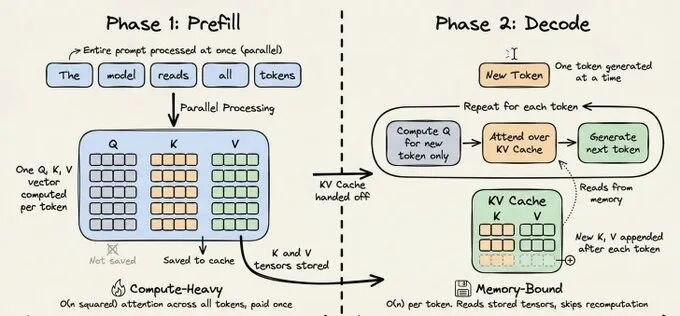
LLM 每一轮推理分为两个阶段:Prefill Phase 和 Decode Phase。要理解 KV Cache 为何如此有效,就需要先理解 Transformer 在处理提示词时的实际运作方式。
2.2.1 预填充阶段(Prefill Phase)
Prefill 阶段:用户将整段提示词一次性告诉 LLM,它需要集中精力,快速读完并理解用户的全部意图。这个过程计算量大,但只做一次。
- 触发时机:计算第一个输出 Token 时;
- 核心特征:一次性处理全部用户输入,以构建模型的内部表示,属于计算密集型操作,成本高昂;
- 执行效率:输入 Tokens 可并行处理,包含大量 GEMM(通用矩阵乘法)操作。
2.2.2 解码阶段(Decode Phase)
Decode 阶段:LLM 开始生成回复,每生成一个 Token 都要回想一下前面写了什么,以及用户最初的要求,然后决定下一个字写什么。这个过程计算量小,但需要反复、持续地进行。
- 触发时机:生成第一个 Token 后至遇到终止符前;
- 核心特征:逐 Token 串行生成,前后轮次仅差一个 Token,存在大量重复计算;
- 资源瓶颈:随生成 Token 数量增加,计算量持续增长,冗余计算成本显著上升。
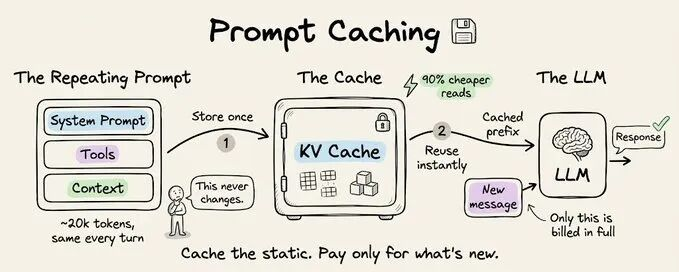
对于长会话 Agent 场景(如 2 万 Token 静态前缀运行 50 轮),无缓存时会产生 98 万 Token 的冗余计算,且全额计费却未产生任何新价值,成为 AI 基础设施中最低效的成本支出。
2.3 KV Cache 的核心工作机制
在预填充阶段,Transformer 为每个 Token 计算三个向量:Q、K 和 V。注意力机制利用这些向量确定当前 Token 与其他 Token 的关系。给定 Token 的 K 和 V 向量仅取决于其之前的 Token,一旦计算完成,它们就不会改变。
KV Cache 的核心逻辑是缓存历史 Token 已计算完成的 K、V 向量,使用 Token 序列的哈希值作为索引。后续推理直接从缓存复用,具体流程以生成 “智能体正在改变世界” 为例:
输入“智能体”,计算 K1、V1 并写入 KV Cache;
生成“正在”时,复用 K1、V1,仅计算新 Token 的 K2、V2;
生成“改变”时,复用 K1、V1、K2、V2,仅计算 K3、V3;
生成“世界”时,复用全部历史 K、V 向量。
该机制将推理计算复杂度从 O (n²) 降至 O (n),其中 n 为序列长度,核心特性如下:
- K/V 向量一旦计算完成即固定不变;
- 缓存匹配基于 Token 序列的哈希值匹配;
- 仅支持前缀序列级精确匹配,非语义相似匹配。
三、KV Cache 的工程化应用
KV Cache 的落地效果,核心取决于对 Prompt 上下文的结构化设计,以及对缓存规则的精准把控。
3.1 静态与动态上下文拆分
每个 Agent 请求可拆分为两类核心内容,为缓存优化提供基础:
- 静态前缀:多轮对话中保持一致的部分,包括系统指令、工具定义、项目背景、行为准则等;
- 动态后缀:随每轮对话增长的部分,包括用户消息、助手回复、工具输出、终端观察结果等。
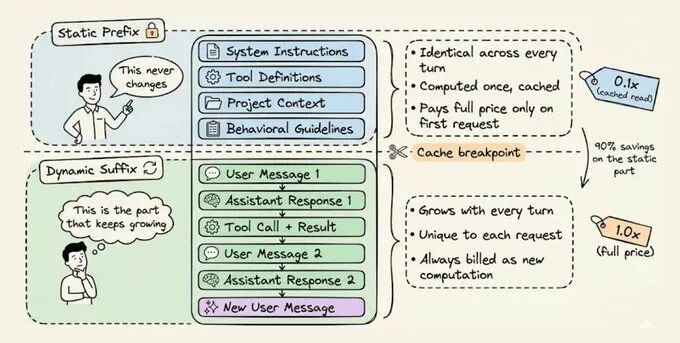
这种区分使得提示词缓存成为可能。基础设施通过存储静态前缀的计算状态(K/V 张量),使后续相同前缀请求直接读取缓存,跳过重复计算,是缓存提效的核心逻辑。
3.2 哈希缓存的脆弱性与核心规则
KV Cache 基于 Token 序列的加密哈希索引,前缀的任何微小顺序变动(从 “1+2=?” 到 “2+1=?” )都会导致哈希值改变,缓存完全失效。生产环境中常见失效场景包括:
- 系统提示词注入动态时间戳,导致每次请求生成唯一哈希;
- JSON 序列化器按随机顺序排序工具模式键,使前缀失效;
- 会话中途修改 Agent Tool 参数。
基于此,需遵循三大核心规则:
- 会话中不修改工具定义(工具属于缓存前缀,增删改会导致下游缓存失效);
- 会话中途不切换模型(缓存与模型强绑定,切换需重建全量缓存);
- 不修改前缀更新状态(需更新状态时,在动态后缀中添加提醒标签)。
3.3 高命中率的 Prompt 结构化设计
综上,为最大化缓存命中率,需按以下逻辑构建 Prompt:
- 顶层固定区:系统指令、行为规则置于顶部,会话期间不要修改;
- 工具定义区:预先加载所有工具,会话期间不增删;
- 相对稳定区:检索到的参考文档、项目背景,保持稳定;
- 动态后缀区:对话历史、工具输出(置于底部,随会话增长)。
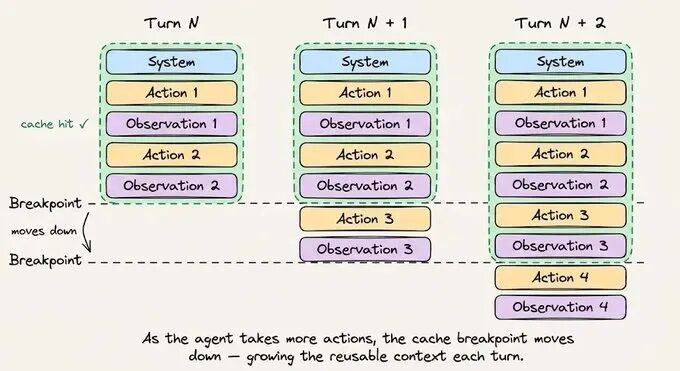
3.4 自动缓存的多轮对话运行机制
自动缓存机制下,缓存点随对话轮次自动向前推进:新请求命中缓存前缀后,从缓存读取 Token 向量,计算完成后更新缓存点至最后一个可缓存块,持续扩大缓存覆盖范围。
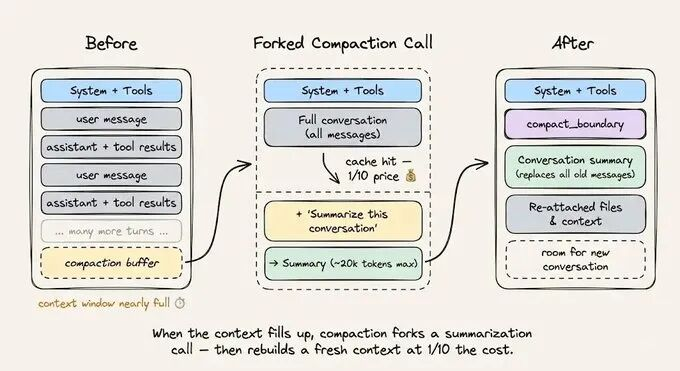
当接近上下文限制时,使用缓存安全的分叉进行上下文压缩。保持相同的系统提示词、工具和对话历史,然后将压缩指令作为新消息追加。缓存前缀将被复用,唯一计费的 Token 仅是压缩指令本身。
3.5 缓存有效性验证与效率计算
以 Claude API 为例,可以监控 API 响应的三个核心字段,量化缓存效果:
- cache_creation_input_tokens:写入缓存的 Token 数量;
- cache_read_input_tokens:从缓存读取的 Token 数量;
- input_tokens:未经缓存处理的 Token 数量。
缓存效率计算公式:
缓存效率 = cache_read_input_tokens / (cache_read_input_tokens + cache_creation_input_tokens)
需将缓存效率作为核心指标,如同监控系统正常运行时间一样持续追踪。
四、KV Cache 的规模化挑战
4.1 长上下文场景的挑战放大
主流大模型如需支持 128K 及以上上下文窗口,长上下文推理面临主要三重挑战:
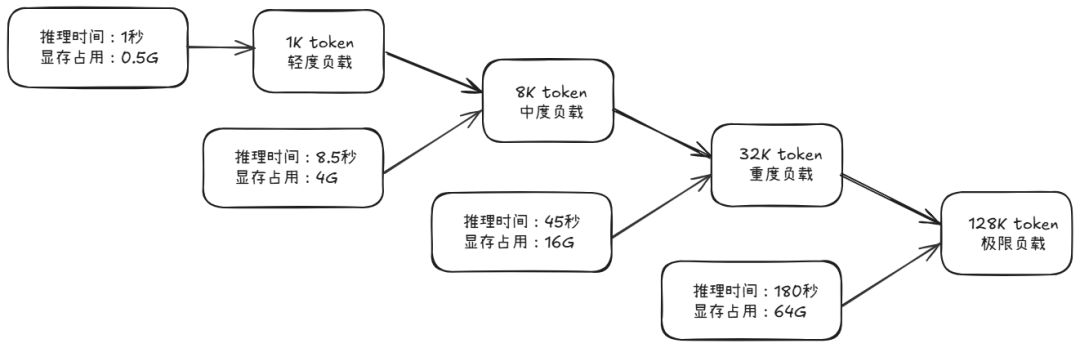
- 计算复杂度爆炸:128K Token 的注意力计算需完成 128K×128K 次操作;
- 显存压力陡增:单请求 KV Cache 可能占用数十 GB 显存;
- 响应时间超限:无优化时推理时间可达数小时,无法满足实时场景需求。
4.2 多层 Transformer 架构的缓存机制
实际 Transformer 模型中,每一层均有独立 KV Cache(如 32 层模型对应 32 组 KV Cache),需建立多层协调机制:
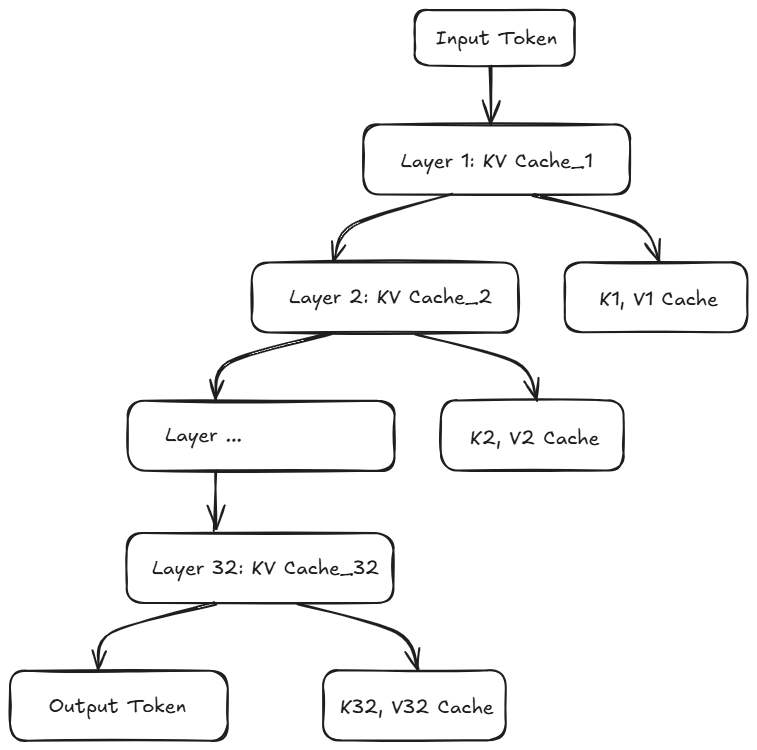
- 同步更新:确保所有层缓存的一致性;
- 独立分配:为每一层分配专属缓存空间;
- 并行处理:可以并行更新不同层的缓存,提升效率;
- 故障恢复:单图层异常时的快速恢复机制。
五、缓存部署架构设计
针对不同规模的应用场景,需匹配差异化的部署方案。
5.1 单机部署
适用于中小规模应用,架构简单、运维成本低,满足基础缓存需求。
5.2 分布式部署
适用于大规模企业级应用,核心设计包括:
- 推理与缓存节点分离:模型推理引擎与 KV Cache 管理部署在不同节点;
- 缓存集群:基于 Redis 集群等分布式缓存系统管理 KV Cache;
- 负载均衡:将请求路由至最优计算节点;
- 容灾备份:实现缓存自动备份与故障恢复。
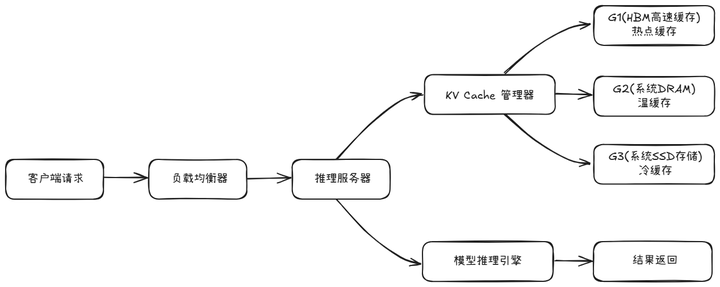
在GPU显存中分为G1层(HBM高速缓存)、G2层(系统DRAM)、G3层(本地SSD)三级存储结构,适配不同密度与频率的计算需求(参考英伟达2026年CES发布的KV Cache存储方案)。
六、行业实践:成本与效率的双重优化
KV Cache 的规模化应用已展现显著的商业价值。
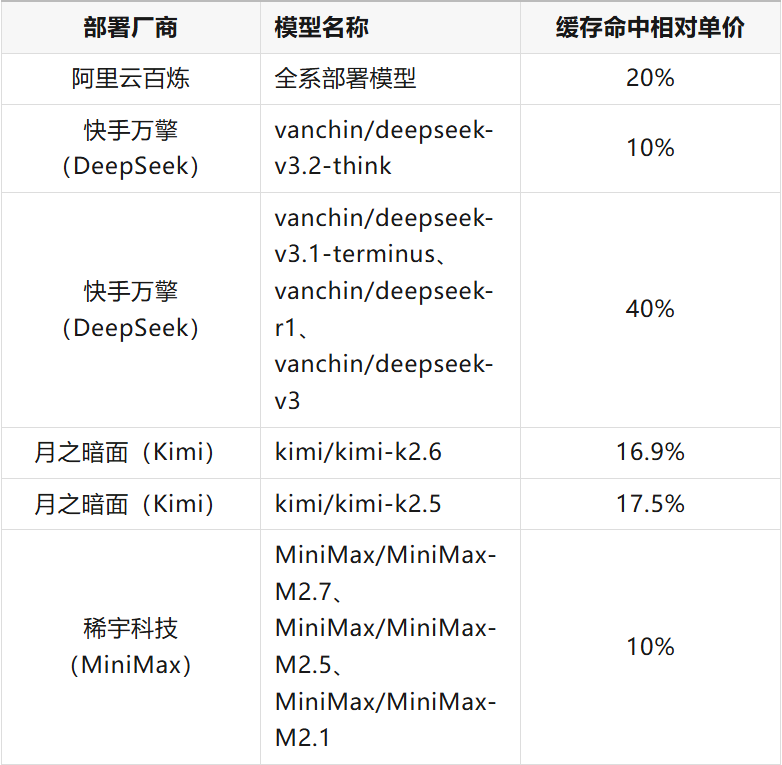
6.1 行业定价与成本优化
国内主流厂商针对缓存命中的 Token 提供大幅单价折扣:
经济账示例:以 2 万 Token 静态前缀、50 轮会话为例:
- 无缓存:需处理 100 万 Token,成本约 2.5 RMB;
- 有缓存:成本降至 0.246 美元,降幅达 90%。
七、结语:KV Cache 引领大模型推理新时代
KV Cache 从 “空间换时间” 的基础策略,到多层缓存协调、分布式部署的工程化落地,已成为现代大模型系统不可或缺的核心技术。其不仅支撑了 ChatGPT、Claude 等产品的流畅体验,更成为企业降低 AI 应用成本、提升竞争力的关键基础设施。
未来,KV Cache 将向智能化、硬件加速、边缘部署等方向持续演进,进一步释放大模型在长上下文、实时交互、规模化部署等场景的应用潜力,成为大模型推理效率跃升的核心引擎。
传统产品经理,正在成为下个被淘汰的“传统岗位”。
过去画原型、写 PRD、跟进度的“传统技能包”,在AI时代正迅速贬值。63% 的企业转型做 AI 产品!当下的问题不再是“要不要学 AI ”,而是“如何构建 AI 产品”。
前段时间还跟字节、腾讯的资深 AI 产品经理沟通,他们反馈:在大量招人,只要有 AI 相关的项目经验,基本都能拿到面试机会,而且领导很舍得给钱,涨薪 40-60% 很正常!
01
接下来的产品人,得卷AI能力了!
如今AI大火,行业极速发展的背后,懂AI 产品人才却严重稀缺。这不是要你转技术岗,而是要掌握构建 AI 产品的核心方法:
- 如何将你的领域知识,转化为 AI 产品的核心竞争力?
- 如何用 AI 技术实现你的产品需求?
- 如何设计真正懂用户的 AI 交互体验?
- ……
懂AI,就是产品经理的“救命稻草”!
风口之下,与其焦虑被行业淘汰
不如先人一步享受AI技术带来的红利!
我把AI产品经理的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

(不限年龄!不限岗位!没有代码基础也能学!)
🎁现在扫码,完课还送:
《AI产品面试题库》《AI大模型应用案例集》
02
掌握技术+实战,快速转型!
想成为一名卓越的AI大模型产品经理,需要从技术、到项目实战的全方位转型指南!
**1)**AI产品应用原理解析,产品经理也能听懂!
对于产品经理来说,如果你不懂技术,做不了业务和AI大模型技术衔接、定义不了数据需求,是没法完整的落地一个产品的!
本次课程,专门面向产品经理人群,解析当下最热门的AI产品应用的必备的「大模型」、「多模态」的实际应用和算法原理!解析AI产品应用技术,积累大模型能力!简单易懂,不需要会代码,小白也能掌握!
- 大模型微调:掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。学习如何利用领域数据(如制造、医药、金融等)进行模型定制
- AI Agent智能体搭建:学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。构建垂类场景下的智能助手产品(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)
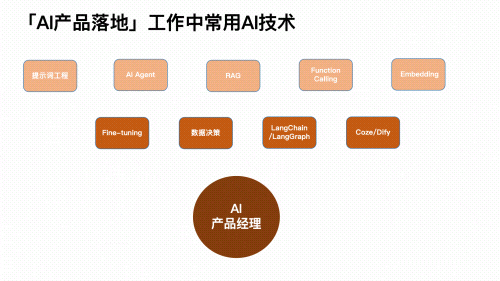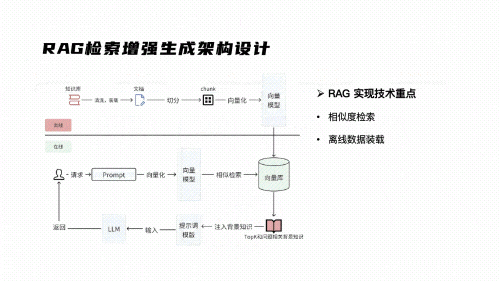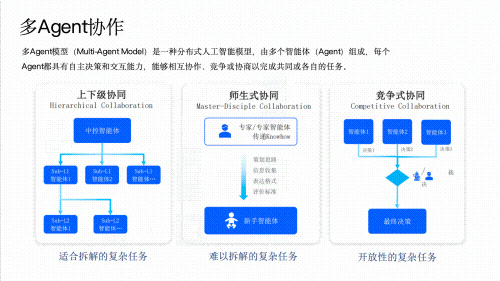
2)超全行业案例解析!
课程详细讲解现阶段,大模型在各个行业和领域的应用现状!包括:零售与电商、教育、医疗、泛娱乐、法律等等10大行业!
详细讲解案例的思路、应用场景,以及背后的技术原理、核心技术!揭秘各个行业、场景的真实现状,和未来产品的发展与机遇!
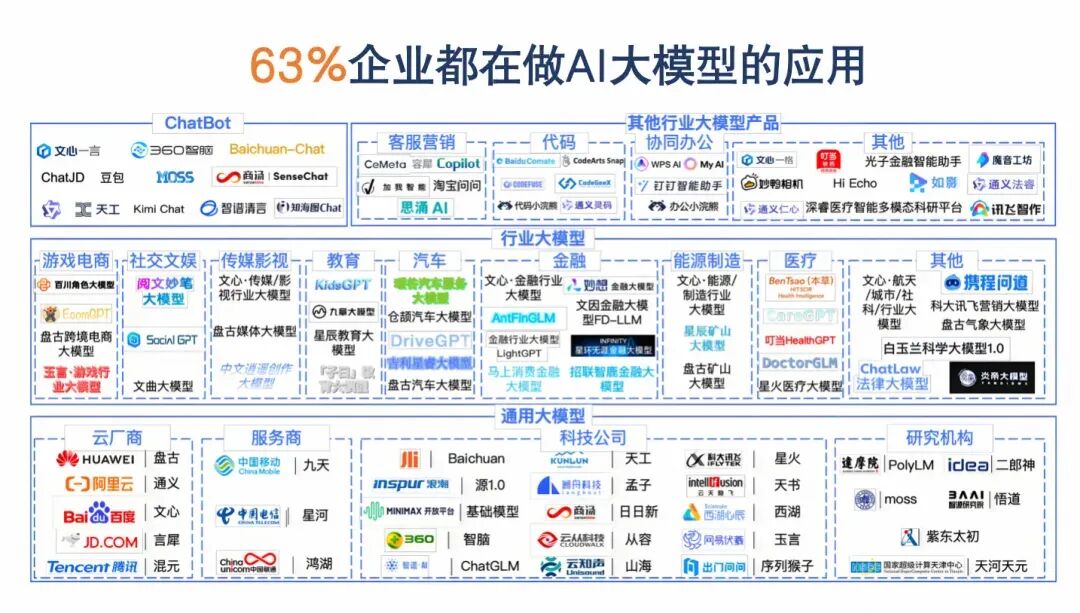
可以说,讲解完一个案例,就能积累一个AI产品实践的经验!
课程中所涉及到的实战项目,都可以直接在自己的工作中使用,让自己的产品/项目有可借鉴的成功案例!
3)AI产品经理求职专项辅导
课程中会系统的帮助大家拆解字节、腾讯、百度等大厂AI PM岗位JD关键词,掌握AI PM高频面试题型与回答框架;展示 AI 相关能力的关键技巧:Prompt设计、模型评估、A/B测试、成本意识、与算法/工程协作经验;
- To B类AI产品经理:突出“行业理解 + 技术落地 + 商业闭环”能力的简历结构设计,展示项目成果;从客户需求洞察到技术方案设计,展现端到产品思维;如何评估To B AI产品的可行性、客户付费意愿与实施成本
- To C类AI产品经理:拆解头部公司岗位JD,将过往尽力转化为AI产品叙事逻辑;从行业趋势、产品设计题、案例分析&数据分析题、技术理解边界等全流程辅导面试;避免无效海投、锁定最适合的AI产品岗位;

03
本次课程,全程直播讲解,能直接对话大佬和专业助教,不懂就问,超详细的案例,小白也能轻松get!
完课后,还赠送《AI产品经理面试题库》、《AI大模型应用案例集》!不断更新中……

适合人群:
- 想转型AI产品经理、AI项目管理专家、AI产品解决方案等岗位
- 想进行AI产品创业的创业者
- 想成为制作AI产品的程序员
- 想利用AI解决企业问题的管理岗
- 想在AI方向寻找就业方向的毕业生
- AI方向前景广阔、待遇好!
目前,很多产品人已经通过完整学习拿到大厂高薪offer,收入嗷嗷涨!
我把AI产品经理的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献158条内容
已为社区贡献158条内容

所有评论(0)