大模型主流激活函数解析:ReLU/GELU/SwiGLU原理差异,拆解FFN前向逻辑.188
一、前言
很多刚接触大模型微调、模型结构分析、推理优化的同学,第一眼看到 Transformer、FFN 前馈网络、SwiGLU、GELU、ReLU 这些名词都会觉得很抽象。大家普遍只知道注意力机制是大模型灵魂,却不知道激活函数才是决定模型深浅、长文本效果、梯度会不会消失、能不能叠几十上百层的关键底层组件。
不管是Qwen系列、ChatGLM2、ChatGLM3等几乎所有国产主流大模型,底层FFN结构都在疯狂迭代激活函数。从最早ReLU,到GELU,再到GLM2专用Gated GELU,GLM3、Qwen全面升级SwiGLU,每一次激活函数改动,都直接改变长文本理解、深层语义保留、训练收敛速度、显存占用、推理稳定性。
今天我们结合ChatGLM2-6B、ChatGLM3-6B两个模型,从基础完整理清大模型激活函数的核心知识,仔细的分析模型结构打印结果,手动复现FFN完整运算,一眼分清不同大模型激活优劣差异。

二、激活函数基础
1 激活函数核心定义
神经网络本质是无数线性矩阵乘法堆叠而成,如果全程只做线性运算,无论堆叠多少层网络,最终整体依然等价于单层线性变换。线性网络无法拟合复杂语义、上下文关联、逻辑推理、长文本依赖等高维非线性特征,完全无法胜任大语言模型任务。
激活函数,就是插入在线性变换之间的非线性数学函数,它给神经网络引入非线性表达能力,让几十层、上百层 Transformer 堆叠有效,让大模型可以学习人类语言复杂逻辑、上下文关联、语义抽象、知识记忆。
简单直白理解:
- 线性计算 = 死板固定规则映射
- 激活非线性 = 模型拥有抽象、理解、推理、记忆能力
大语言模型Transformer结构里,注意力层负责上下文关联,FFN前馈神经网络全权负责语义特征变换、信息提炼、知识存储,而FFN性能100%由激活函数决定。
2. 大模型对激活函数严苛要求
普通CV图像模型激活函数选择很宽松,但千亿级、百亿级大语言长文本模型,对激活函数有极高硬性标准:
- 1. 深层网络不出现梯度消失或梯度爆炸,支持几十层甚至上百层堆叠
- 2. 全程定义域平滑连续,导数稳定,训练收敛更快更稳定
- 3. 无神经元死亡问题,不会大量权重永久失效
- 4. 适配长序列文本,超长上下文深层语义不退化
- 5. 计算简单高效,适配半精度FP16推理,降低显存占用
- 6. 门控结构自适应权重筛选,自动保留有效语义、过滤冗余噪声
早期ReLU、Sigmoid、Tanh完全无法满足大长文本大深度模型需求,因此大模型行业才一步步迭代出GELU、Gated GELU、SwiGLU三代主流激活方案。
3. 大模型激活函数发展迭代
- 初代ReLU:早期Transformer通用激活,简单快速,但神经元极易死亡,深层梯度直接消失,无法做大深度长文本模型
- 二代GELU:BERT、早期小参数量大模型标配,平滑无死区,语义拟合更强,但深层长文本依旧梯度衰减严重
- 三代门控Gated GELU:ChatGLM2专属架构,单线性拆分双支路,门控加权语义,大幅缓解梯度问题
- 四代SwiGLU:Qwen全系、ChatGLM3全系标配大模型黄金激活,SiLU门控 + 双支路 FFN,长文本、深层网络、训练稳定性全面拉满
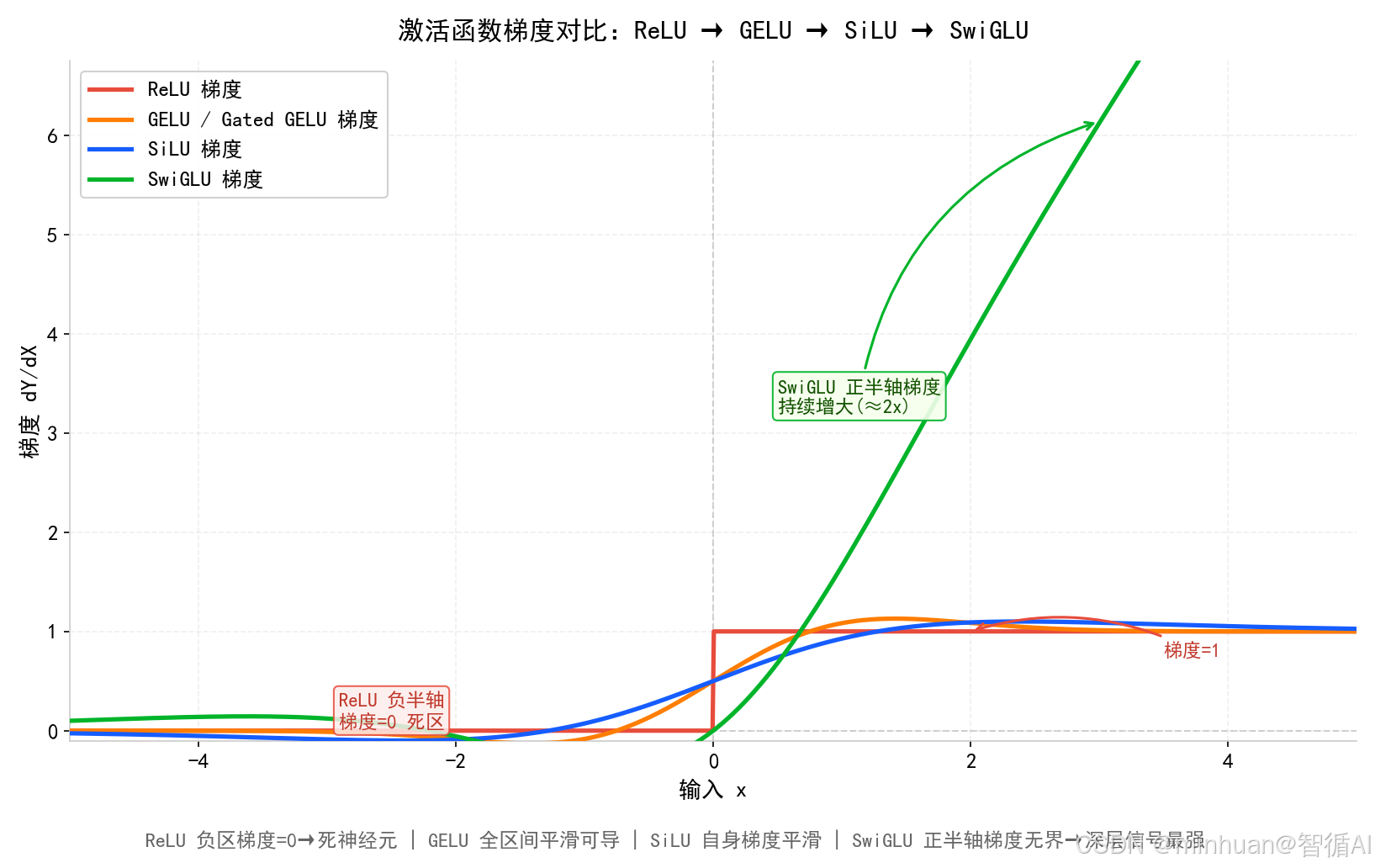
4. 理解大模型FFN里的门控
相信大家刚开始也是,初一看gate、门控就觉得高深,其实门控 = 智能开关 + 权重调节阀,没有任何玄学,通俗理解大模型门控机制:信息开关,语义筛选阀门。
一句话本质定义:
- 普通激活:所有输入信息一视同仁,全部原样加工传递
- 门控激活:模型自己判断哪些语义重要保留、哪些没用过滤弱化
门控就是Transformer FFN内部,自动给每个词语特征分配权重大小。
用生活最好懂类比:
我们看一段长句子:今天天气很好,我打算出门去公园散步晒太阳
- 注意力机制:找到词语之间关联关系
- 门控机制:重点保留“天气、出门、公园、散步”关键信息,弱化无关废话虚词
就像家里灯光开关:
- 重要信息:全开、高亮通过
- 次要信息:调低亮度、减弱传递
- 无用噪声:几乎关闭,不往下一层传播
大模型FFN门控工作完整逻辑:
- 1. 隐藏特征进来,拆成两条完全独立支路
- Value 支路:老老实实传递原始语义内容
- Gate 支路:专门计算权重大小
- 2. Gate经过SiLU/GELU激活,变成0~1之间的系数
- 3. 权重 × 内容 = 最终输出
- 系数≈1:信息完整保留
- 系数≈0:信息几乎被屏蔽
门控的核心作用:
- 没有门控:
- 所有上下文、所有token、所有语义权重一模一样
- 深层堆叠几十层后,有用信息、垃圾噪声全部混在一起
- → 长文本后半段混乱
- → 深层梯度消失
- → 模型记不住上下文、容易幻觉
- 有门控:
- 每一层FFN都自动提纯语义
- 层层过滤噪声、层层突出重点
- 越深的层,语义越精准、逻辑越清晰
ReLU/GELU vs Gated GELU/SwiGLU核心区别:
- 普通 ReLU、GELU:单支路,无脑统一激活
- 所有信息平等处理,没有筛选能力
- Gated GELU、SwiGLU:双支路,一条管内容,一条管开关
- 门控自主决定信息流量大小
三、常见激活函数
1. ReLU激活函数
1.1 公式定义
ReLU(x)=max(0,x)
输入大于0,原样输出;输入小于等于0,直接输出0。
1.2 函数特性
- 1. 分段线性,计算极致简单:只有判断大小、取最大值运算,GPU算力消耗极低,前向、反向传播速度极快,早年CNN卷积神经网络首选激活。
- 2. 单侧稀疏激活:负数全部置零,天然稀疏,大量神经元不工作,理论上节省计算与显存。
- 3. 无梯度饱和问题:正数区间梯度恒等于1,深层网络不会出现梯度无限趋近0的情况。
1.3 大模型应用缺点
神经元死亡现象:
负数输入长期梯度为0,权重永远不再更新,神经元彻底报废。Transformer深层堆叠后,大量FFN神经元失效,模型知识残缺、表达能力暴跌。
无法表达负向语义:
自然语言有否定、转折、反向逻辑,ReLU完全压制负特征,不适合语言建模。
非线性能力极弱:
本质分段线性,多层叠加依然近似线性,无法拟合复杂长文本逻辑、因果推理。
梯度分布极不稳定:
深层堆叠容易梯度爆炸,训练震荡剧烈,千亿大模型几乎无法稳定收敛。
量化效果极差:
正负分布极端不均匀,INT4/INT8量化精度断崖式下跌,不适合落地部署。
1.4 适用场景
图像CNN小模型、浅层神经网络,完全不适合Transformer大语言模型。
1.5 直观图示
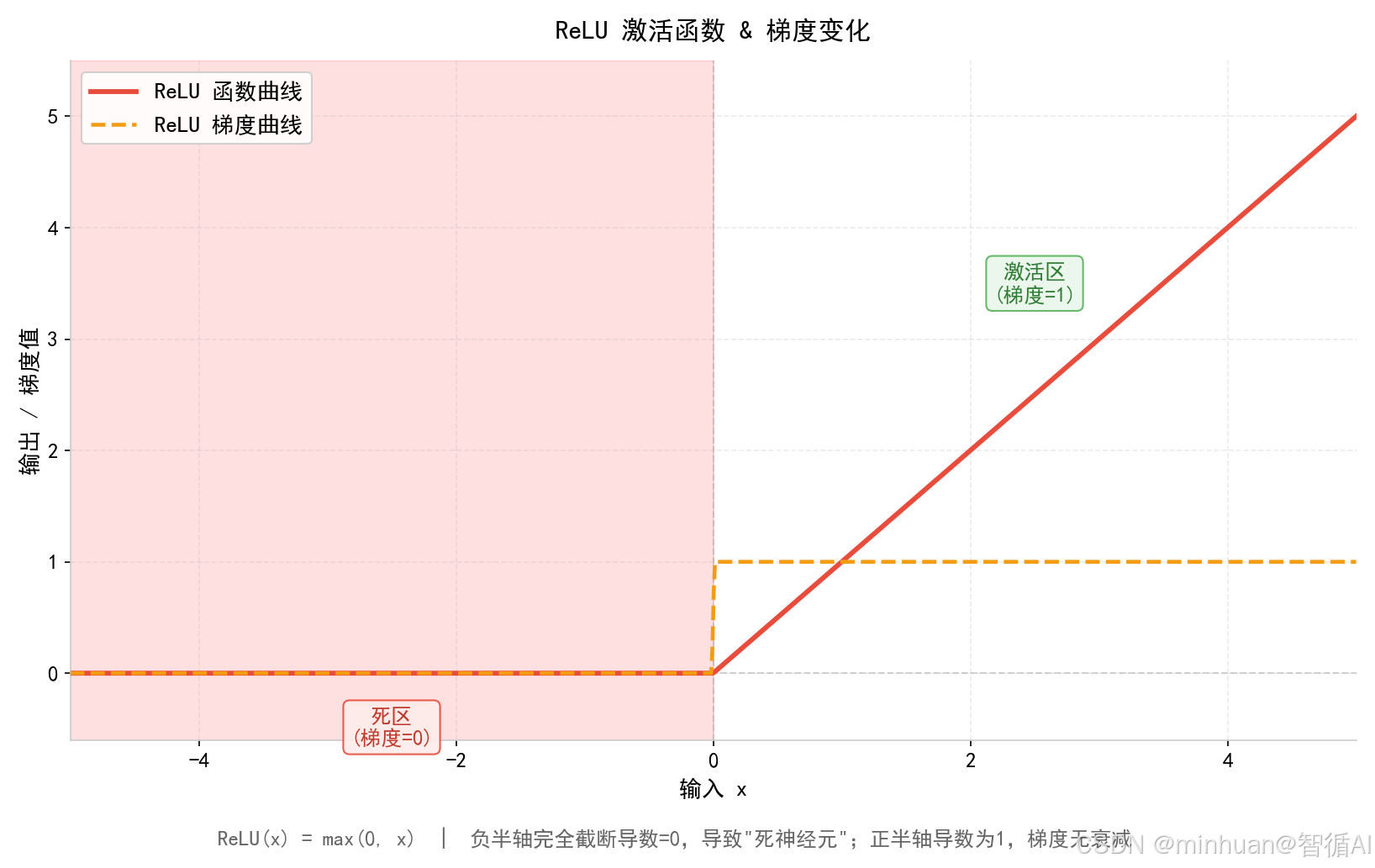
重点说明:
- 正数原样输出,负数直接归零
- x<0 梯度 = 0,极易出现神经元永久死亡
- 拐点尖锐不光滑,深层Transformer极易训练震荡
- 早已被大语言模型全面淘汰
2. GELU激活函数
2.1 公式定义
GELU(x) = x ⋅ Φ(x)
Φ(x)是高斯正态分布累积概率函数,通俗理解:ReLU平滑概率版。
2.2 函数特性
- 1. 全程平滑连续,没有ReLU尖锐拐点,梯度顺滑
- 2. 负数区域不会完全归零,不会出现神经元永久死亡
- 3. 随机正则特性,自带轻微噪声扰动,泛化能力更好
- 4. 完美适配编码器BERT模型,对话语义拟合效果远超ReLU
2.3 大模型应用短板
- 非线性上限偏低:单一路径非线性,只能拟合基础语义,无法支撑海量世界知识、复杂逻辑推理。
- 深层Decoder模型易梯度饱和:层数越多,梯度衰减越严重,长上下文记忆能力很差。
- 显存占用高、浮点运算量大:相同参数量推理速度慢于ReLU,批量服务吞吐量低。
- 与MoE稀疏架构不兼容:没有门控机制,无法配合专家路由做动态特征筛选。
- 低比特量化损失大:数值分布不均匀,量化后语义精度大幅下降。
2.4 适用场景
BERT、小参数量对话模型、百亿参数以内Transformer,千亿模型全面淘汰。
2.5 直观图示
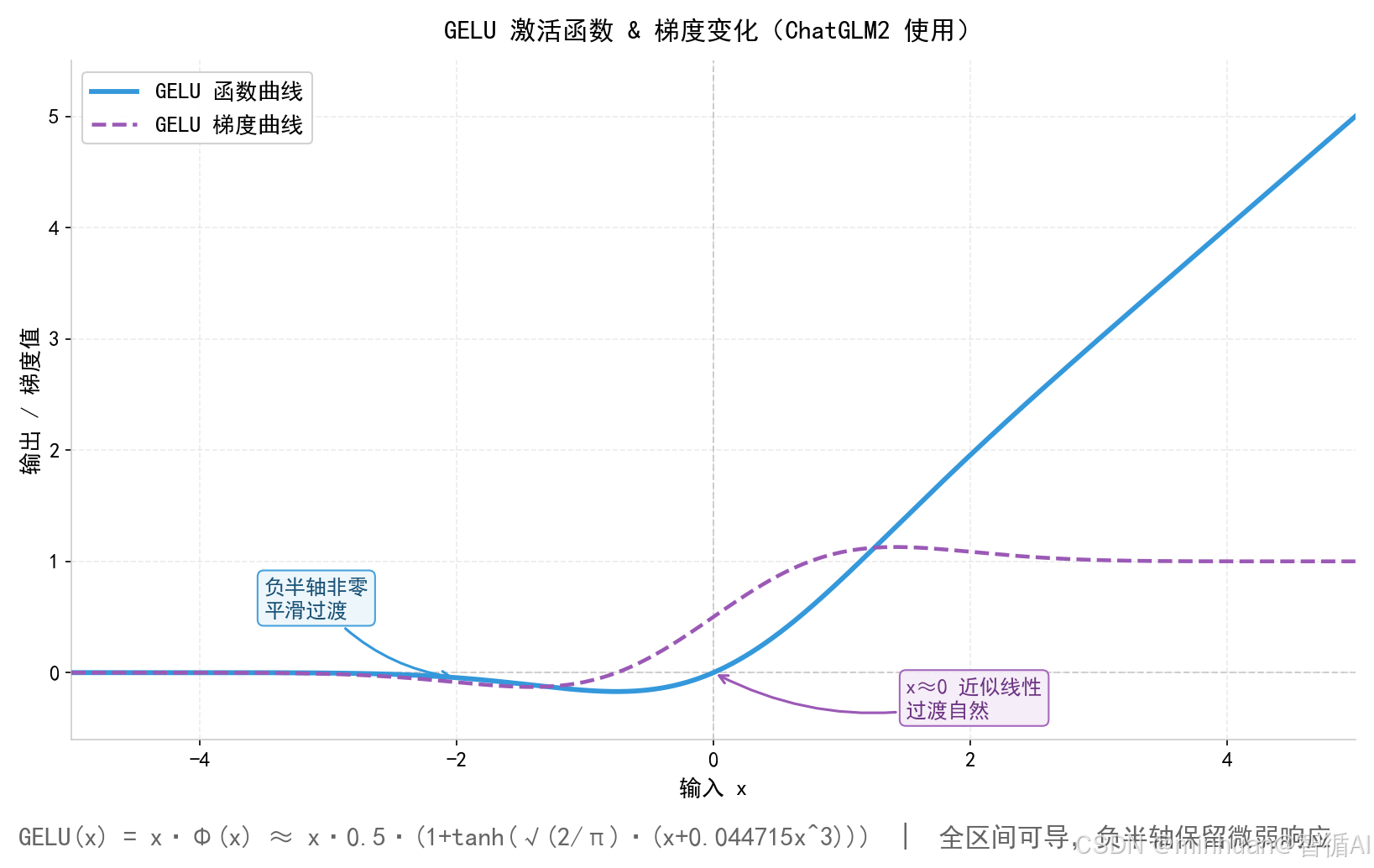
重点说明:
- ReLU平滑版本,负数不会直接清零
- 全程连续可导,训练比ReLU稳定
- 两端输入梯度快速趋近0,深层堆叠严重梯度衰减
- 长上下文容易遗忘,知识容量有限
3. SwiGLU激活函数
3.1 基础构成
SwiGLU = Swish门控 + GLU线性门控单元
不是单一激活函数,是双支路FFN结构 + 门控非线性组合架构。
标准计算流程:
- 1. 输入特征分成特征支路
- 2. 同时生成门控权重支路
- 3. 门控经过Swish(SiLU)平滑归一
- 4. 两路逐元素相乘融合输出
公式简化:
SwiGLU(x)=(xW1)⋅SiLU(xW2)
3.2 核心函数特性
- 1. 高阶复合非线性:双支路相乘,非线性表达能力远强于ReLU、GELU单函数变换。
- 2. 全程平滑、无死神经元、无梯度饱和:正负特征全部保留,语言正反语义、否定逻辑完美建模。
- 3. 自带动态门控加权:自动增强重要语义、弱化无关噪声,天生适配自然语言上下文。
- 4. 梯度极其稳定:上千层Transformer堆叠,依然平稳收敛,极大降低炼丹调参难度。
- 5. 数值分布均匀集中:极度友好INT4/INT8量化,推理精度几乎无损。
3.3 大模型专属优势
- FFN知识存储容量大幅提升,直接决定大模型智商上限
- 扩维适配性极强,8 倍、12倍隐藏扩维依然稳定训练
- 显存占用更低、推理速度更快,工程落地性价比极高
- 微调FFN即可快速提升专业领域能力,不易灾难性遗忘
- 原生适配MoE混合专家,全局路由 + 局部门控双层配合,万亿参数模型唯一优选
3.4 适用场景
所有Decoder大模型、千亿、万亿参数大模型、MoE稀疏大模型、长上下文模型、私有化微调、云端 + 边缘全场景部署。
3.5 直观图示
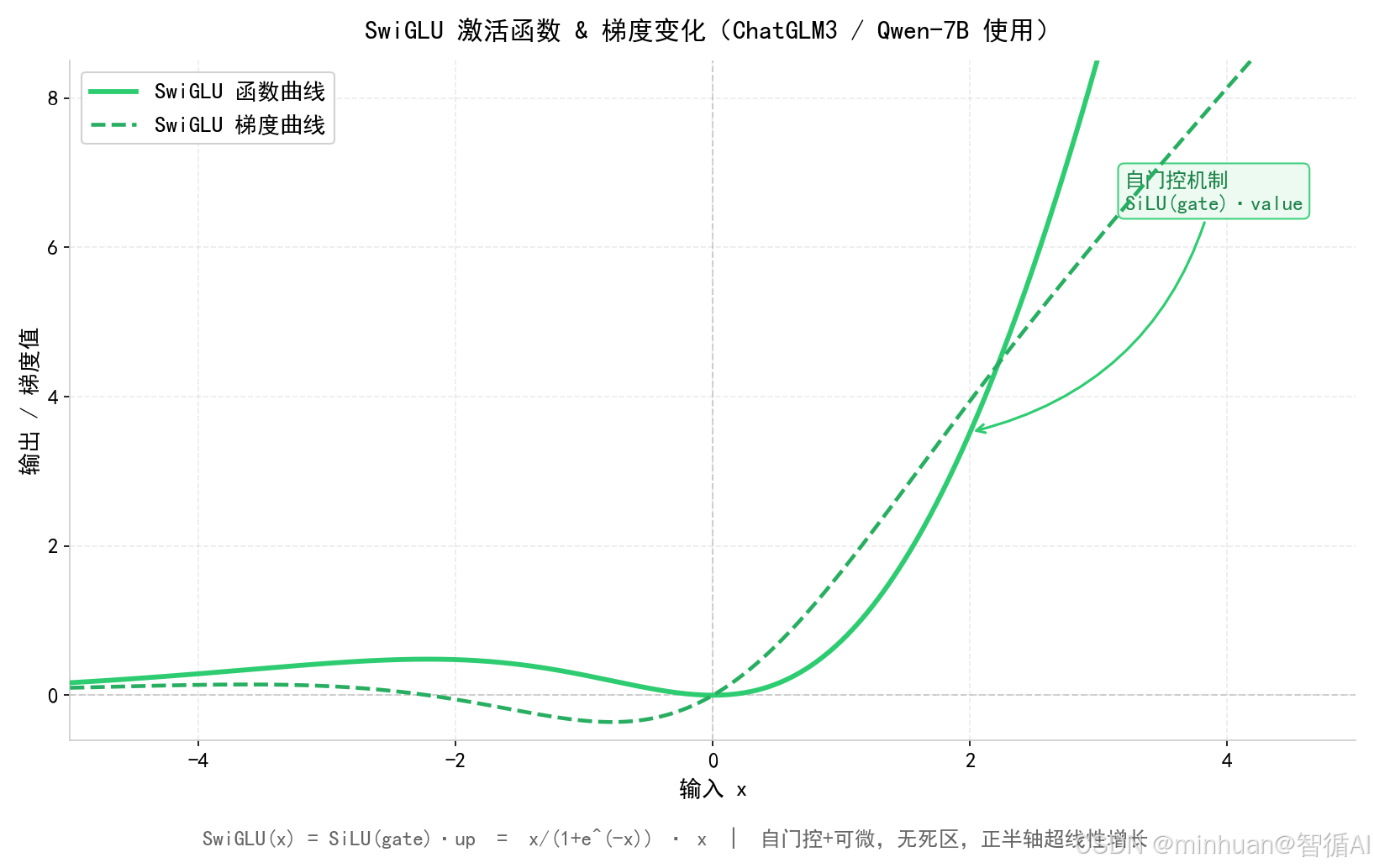
重点说明:
- 正负区间都有饱满平滑响应
- 大范围梯度平稳均匀,无衰减、不归零、不饱和
- 高阶非线性更强,知识存储密度更高
- 完美适配深层大模型、长文本、MoE架构、量化部署
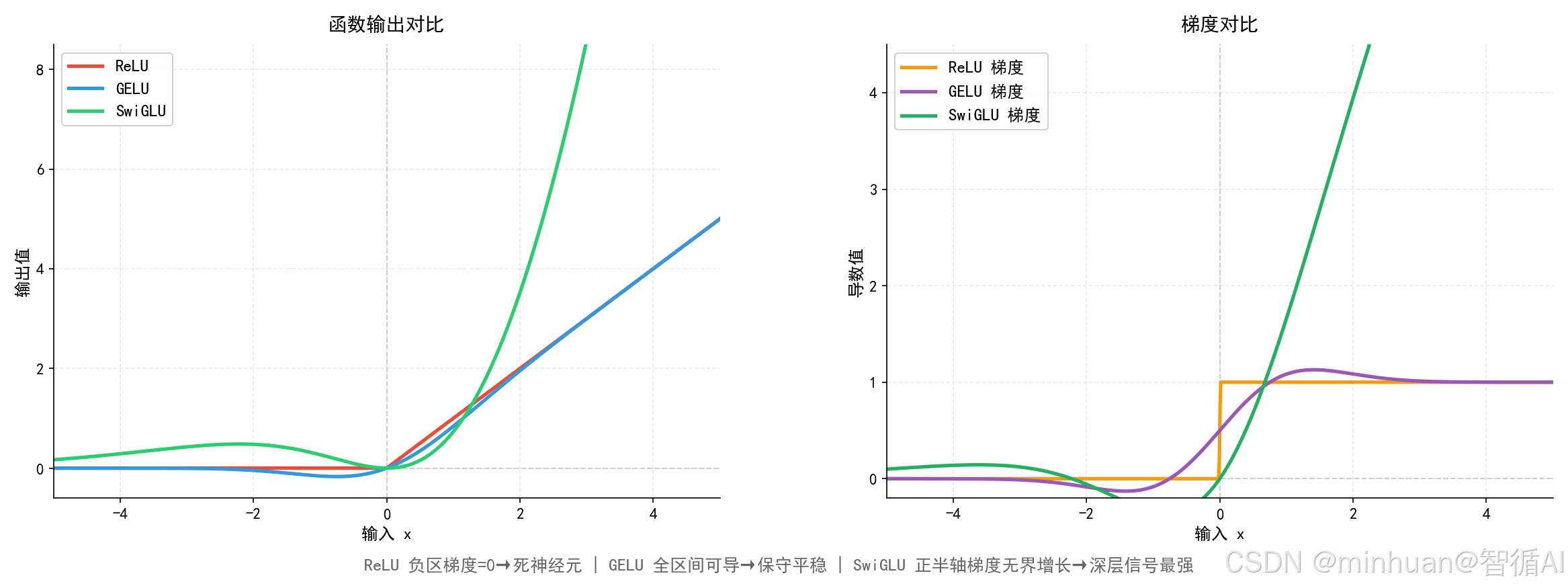
4. 基础差异对比
ReLU:简单快、稀疏强,但易死神经元、非线性差、不适合大语言
GELU:平滑稳定、适配BERT,但表达上限低、推理慢、不适合千亿深层模型
SwiGLU:门控高阶非线性、训练稳、显存省、推理快、量化好、适配MoE,全方位碾压前两者
四、Gated GELU门控激活
1. 门控激活诞生背景
普通GELU只是单支路非线性变换,Transformer层数加深、文本长度加长后,FFN无法自主筛选关键语义。大模型需要一条支路控制信息强弱,一条支路传递原始特征,门控加权融合,这就是Gated门控FFN结构诞生原因。
ChatGLM2-6B是国内首个大规模采用Gated GELU门控 FFN的主流对话大模型,彻底改变单支路激活模式。
2. ChatGLM2完整前向计算流程

- 1. 输入语义特征经过dense_h_to_4h一次性线性升维
- 2. 输出张量均匀拆分为Gate门控支路 + Value数值支路
- 3. Gate支路经过GELU非线性激活,生成自适应权重系数
- 4. 门控权重与原始Value逐元素相乘,筛选重要语义、压制无用信息
- 5. dense_4h_to_h矩阵降维,还原原始隐藏维度,送入下一层Transformer
整个过程不是简单激活,而是门控自适应语义加权,比普通GELU表达能力翻倍,深层梯度衰减大幅缓解。
3. ChatGLM2原生模型FFN完整复现
from transformers import AutoModel, AutoTokenizer
import torch
import torch.nn.functional as F
import warnings
warnings.filterwarnings("ignore")
# 你的本地模型路径
model_path = "/home/model/ZhipuAI/chatglm2-6b/"
# 加载模型
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
model.eval()
# ========== 1. 查看 ChatGLM2 第一层FFN结构 ==========
# ChatGLM2结构: model.transformer.encoder.layers[0].mlp
encoder_layers = model.transformer.encoder.layers
mlp_layer = encoder_layers[0].mlp
print("=== ChatGLM2-6B 原生FFN结构 ===")
print(mlp_layer)
# ========== 2. 手动复现 ChatGLM2 真实前向计算 ==========
# ChatGLM2-6B 使用 Gated GELU:
# dense_h_to_4h 输出 4096→27392(=2×13696),拆为 gate + value 两半
# gate 走 GELU,再与 value 逐元素相乘,最后 dense_4h_to_h 降维回 4096
x = torch.randn(1, 128, 4096).half().cuda()
h1 = mlp_layer.dense_h_to_4h(x) # (1, 128, 27392)
gate, value = h1.chunk(2, dim=-1) # 各 (1, 128, 13696)
act_out = F.gelu(gate) * value # Gated GELU: gelu(gate) ⊙ value
h2 = mlp_layer.dense_4h_to_h(act_out) # (1, 128, 4096)
print("\n输入形状:", x.shape)
print("dense_h_to_4h 升维后:", h1.shape)
print("拆分 gate/value:", gate.shape)
print("Gated GELU 激活后:", act_out.shape)
print("dense_4h_to_h 降维后:", h2.shape)
print("ChatGLM2-6B 使用 Gated GELU(非纯 GELU):gate 半支走 GELU + value 半支线性门控")
# ========== 3. 长文本输入,直观体现GELU梯度衰减缺陷 ==========
long_text = "人工智能大模型技术发展日新月异" * 50
input_ids = tokenizer(long_text, return_tensors="pt").input_ids.cuda()
with torch.no_grad():
out = model(input_ids)
print(f"\n长文本长度:{input_ids.shape[1]}")
print("ChatGLM2-6B FFN = Gated GELU,相比纯 GELU 门控机制能缓解部分梯度衰减,但长文本深层仍存在语义退化")运行输出:
=== ChatGLM2-6B 原生FFN结构 ===
MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)输入形状: torch.Size([1, 128, 4096])
dense_h_to_4h 升维后: torch.Size([1, 128, 27392])
拆分 gate/value: torch.Size([1, 128, 13696])
Gated GELU 激活后: torch.Size([1, 128, 13696])
dense_4h_to_h 降维后: torch.Size([1, 128, 4096])
ChatGLM2-6B 使用 Gated GELU(非纯 GELU):gate 半支走 GELU + value 半支线性门控长文本长度:403
ChatGLM2-6B FFN = Gated GELU,相比纯 GELU 门控机制能缓解部分梯度衰减,但长文本深层仍存在语义退化
输出分析:
- 1. FFN结构打印解读
MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
- 4096:模型隐层维度
- dense_h_to_4h 一次性升维到27392
- 代码内部强行对半切开 → 得到13696
- 一半当gate门控,一半当value特征
- 2. 张量形状流程逐行解释
输入形状: torch.Size([1, 128, 4096])
- 1:批次
- 128:上下文 token 长度
- 4096:语义特征维度
dense_h_to_4h 升维后: torch.Size([1, 128, 27392])
- 一次线性映射,把特征大幅扩维
拆分 gate/value: torch.Size([1, 128, 13696])
- 关键架构特点:一根权重切开两路,共用一套矩阵
- 前一半:gate 门控信号
- 后一半:value 原始语义特征
Gated GELU 激活后: torch.Size([1, 128, 13696])
- 计算公式:GatedGELU = value × GELU(gate)
- 门控走GELU非线性,特征保持线性,两者相乘完成门控
dense_4h_to_h 降维后: torch.Size([1, 128, 4096])
- 还原回原始维度,完成一层FFN计算
4. Gated GELU对大模型架构价值
- 双支路解耦:权重控制与特征传递完全分开,FFN语义建模能力翻倍
- 门控自适应:模型自动学习上下文重要程度,不用人工调节参数
- 训练更稳定:深层梯度比原生GELU平滑很多,更容易收敛
- 适配中英对话场景,GLM系列对话逻辑效果大幅提升
短板:GELU本身负数区域梯度偏小,超长几千token长文本,深层网络依旧语义丢失,因此智谱后续直接升级为SwiGLU。
五、SwiGLU SiLU门控升级
1. SwiGLU对比Gated GELU核心升级
SwiGLU=SiLU 激活门控 + GLU 线性门控结构,是目前Qwen、GLM3、LLaMA全系国际国内顶级大模型统一标配FFN激活方案。
- ChatGLM2:Gated GELU → Gate 用 GELU
- ChatGLM3/Qwen:SwiGLU → Gate 用 SiLU
SiLU 曲线比 GELU全程梯度更平滑、正负区间响应更均匀、无梯度凹陷区域,长文本几十层叠加后,梯度几乎不衰减,超长上下文语义完整保留。
2. ChatGLM3 SwiGLU 合并矩阵拆分结构
GLM3沿用GLM2单矩阵升维结构,依旧dense_h_to_4h统一输出,对半拆分gate与value,仅把激活函数从GELU替换为SiLU。
改动极小,但长文本、深层模型效果飞跃式提升。
3. ChatGLM3-6B SwiGLU完整原生示例
ChatGLM3-6B相比ChatGLM2-6B的FFN核心变化就是激活从Gated GELU升级为SwiGLU。
from transformers import AutoModel, AutoTokenizer
import torch
import torch.nn.functional as F
import warnings
warnings.filterwarnings("ignore")
# 你的本地模型路径
model_path = "/home/model/ZhipuAI/chatglm3-6b/"
# 加载模型
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
model.eval()
# ========== 1. 查看 ChatGLM3 第一层FFN结构 ==========
# ChatGLM3结构: model.transformer.encoder.layers[0].mlp
encoder_layers = model.transformer.encoder.layers
mlp_layer = encoder_layers[0].mlp
print("=== ChatGLM3-6B 原生FFN结构 ===")
print(mlp_layer)
# ========== 2. 手动复现 ChatGLM3 真实前向计算 ==========
# ChatGLM3-6B 升级为 SwiGLU(对比 ChatGLM2 的 Gated GELU):
# dense_h_to_4h 输出 4096→27392(=2×13696),拆为 gate + value 两半
# gate 走 SiLU,再与 value 逐元素相乘,最后 dense_4h_to_h 降维回 4096
x = torch.randn(1, 128, 4096).half().cuda()
h1 = mlp_layer.dense_h_to_4h(x) # (1, 128, 27392)
gate, value = h1.chunk(2, dim=-1) # 各 (1, 128, 13696)
act_out = F.silu(gate) * value # SwiGLU: silu(gate) ⊙ value
h2 = mlp_layer.dense_4h_to_h(act_out) # (1, 128, 4096)
print("\n输入形状:", x.shape)
print("dense_h_to_4h 升维后:", h1.shape)
print("拆分 gate/value:", gate.shape)
print("SwiGLU 激活后:", act_out.shape)
print("dense_4h_to_h 降维后:", h2.shape)
print("ChatGLM3-6B 升级为 SwiGLU:gate 半支走 SiLU + value 半支线性门控(ChatGLM2 为 Gated GELU)")
# ========== 3. 长文本输入,观察 SwiGLU 深层表现 ==========
long_text = "人工智能大模型技术发展日新月异" * 50
input_ids = tokenizer(long_text, return_tensors="pt").input_ids.cuda()
with torch.no_grad():
out = model(input_ids)
print(f"\n长文本长度:{input_ids.shape[1]}")
print("ChatGLM3-6B FFN 升级为 SwiGLU:SiLU 平滑非单调 + 自门控,深层梯度衰减相比 GELU 显著改善")运行输出:
=== ChatGLM3-6B 原生FFN结构 ===
MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)输入形状: torch.Size([1, 128, 4096])
dense_h_to_4h 升维后: torch.Size([1, 128, 27392])
拆分 gate/value: torch.Size([1, 128, 13696])
SwiGLU 激活后: torch.Size([1, 128, 13696])
dense_4h_to_h 降维后: torch.Size([1, 128, 4096])
ChatGLM3-6B 升级为 SwiGLU:gate 半支走 SiLU + value 半支线性门控(ChatGLM2 为 Gated GELU)长文本长度:403
ChatGLM3-6B FFN 升级为 SwiGLU:SiLU 平滑非单调 + 自门控,深层梯度衰减相比 GELU 显著改善
输出分析:
- 1. FFN结构解读
MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
- 和ChatGLM2权重结构一模一样
- 同样:4096 → 27392 → 对半切开 → 13696
- 同样单一线性层拆分两路(智谱祖传省钱架构)
- 2. 张量流程逐行解释
输入形状: torch.Size([1, 128, 4096])
- 批次 1,序列 128token,隐层维度 4096
dense_h_to_4h 升维后: torch.Size([1, 128, 27392])
- 一次线性升维
拆分 gate/value: torch.Size([1, 128, 13696])
硬性对半分割
- 前一半:gate门控支路
- 后一半:value特征支路
SwiGLU 激活后: torch.Size([1, 128, 13696])
计算公式:
- SwiGLU=value×SiLU(gate)
- GLM2:value × GELU(gate)
- GLM3:value × SiLU(gate)
核心就换了一个激活函数,天差地别
dense_4h_to_h 降维后: torch.Size([1, 128, 4096])
- 还原维度,完成FFN
4. ChatGLM2 vs ChatGLM3本质区别
ChatGLM2-6B:
- Gated GELU
- gate 支路 → GELU 激活
- 缺点:两端梯度快速归零 → 深层衰减、长文本失忆
ChatGLM3-6B:
- 拆分式 SwiGLU
- gate 支路 → SiLU (Swish) 激活
- 优点:梯度全程平稳、不衰减、不饱和、长上下文极强
5. SwiGLU对大模型全体系价值
- 深层网络百层堆叠无梯度消失,支持超大参数量模型训练
- 超长几千Token上下文完整理解,长文档问答、长摘要业务刚需
- FP16半精度兼容性极好,大幅降低推理显存,服务落地成本更低
- 语义非线性拟合更强,对话逻辑、知识推理、多轮上下文效果更好
- 训练收敛更快,微调成本更低,行业通用标准化架构
六、激活函数全维度差异
1. 结构架构横向对比
- ReLU:单支路简单截断激活,无门控
- GELU:单支路平滑非线性激活,无门控
- Gated GELU:双支路拆分,GELU做门控加权
- SwiGLU:双支路拆分,SiLU做门控加权
2. 长文本&深层网络性能对比
- ReLU:极易梯度消失,不支持深层长文本
- 原生 GELU:深层梯度衰减明显,长文本后半语义混乱
- Gated GELU:中等水平,日常对话够用,超长文档不足
- SwiGLU:梯度全程平滑稳定,万token长文本依旧精准理解
3. 训练推理落地差异
- ReLU 训练快但不稳定,极易崩模型
- GELU 收敛一般,显存占用偏高
- Gated GELU 稳定性中等,微调适配一般
- SwiGLU 收敛快、显存省、适配所有量化、分布式训练、云端部署
4. 主流大模型选型规律
- ChatGLM2 → Gated GELU
- ChatGLM3 → SwiGLU
- Qwen 全系列 → SwiGLU
- LLaMA 全系列 → SwiGLU
七、总结
总的来说,学习大模型只看注意力机制,忽略FFN与激活函数,实际上Transformer注意力负责找关系,FFN激活函数负责存储知识、处理语义、支撑深度、支撑长文本。没有优秀激活函数,再强注意力架构也无法做成可用商用大模型。
从ReLU淘汰,到GELU过渡,GLM2 Gated GELU尝试,GLM3、Qwen全面普及SwiGLU,大模型激活函数迭代史,就是国产大模型长文本能力、深层训练能力、落地服务能力不断变强的发展史。
看懂激活函数,才算真正踏入大模型底层架构大门,后续学习模型剪枝、量化推理、结构修改、自定义FFN、模型蒸馏、分布式训练,都会一通百通、豁然开朗。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)