Nat. Biomed. Eng(1区top,IF=26.6)上海科技大学钱学军团队:一种用于乳腺癌风险分层的多模态机器学习模型
01
文献信息

本次分享的文献是由上海科技大学钱学军团队联合安徽医科大学第一附属医院、南京医科大学附属南京医院、复旦大学附属肿瘤医院、宣城人民医院、阜阳肿瘤医院等多中心医疗机构于2024年10月在Nature子刊《Nature Biomedical Engineering》(中科院1区top,IF=26.6)上发表的研究“A multimodal machine learning model for the stratification of breast cancer risk”即一种用于乳腺癌风险分层的多模态机器学习模型,本研究开发了一种名为BMU-Net的多模态深度学习模型,旨在解决乳腺癌风险分层中“单模态局限、临床流程偏离、缺乏病理级鉴别诊断”等问题。模型整合钼靶影像(MG)、三模态超声(US:B超、彩色多普勒、弹性成像)和临床元数据,基于5025名患者(5216个乳房、19360张图像,均经手术病理证实)训练,支持细粒度病理亚型预测(T1-T5)和粗粒度良恶性分类。通过多中心、多设备及前瞻性数据验证,模型在细粒度鉴别诊断上优于经验丰富的放射科医生,粗粒度性能媲美医生,且接近病理科医生的初步活检评估,可辅助临床制定活检选择和后续管理方案,推动乳腺癌AI诊断向临床转化。
02
研究背景
1. 研究问题
乳腺癌诊疗现状:乳腺癌是全球最常见癌症(2020年超肺癌),年新增230万病例、68.5万死亡;早期诊断可显著提升生存率,但现有影像技术存在局限(钼靶对致密乳腺敏感性低,单独超声特异性不足)。
临床诊断痛点:放射科医生依赖BI-RADS指南,但存在三大问题:①专业人员短缺;②影像解读主观性强;③观察者内/间变异大,导致漏诊(延误手术治疗)或假阳性(引发患者焦虑及不必要有创操作)。
现有AI模型缺陷:多为单模态(仅MG或US)、偏离临床标准流程(未包含必要视图)、未整合临床元数据、缺乏多中心前瞻性验证、仅能区分良恶性而无法提供病理级鉴别诊断(如原位癌vs浸润癌)。
2. 研究难点
多模态整合与临床合规:需同时处理钼靶(CC/MLO视图)、三模态超声(横断/纵断位)和临床元数据,且符合BI-RADS指南,避免脱离临床实际。
真实世界数据鲁棒性:临床中常存在模态缺失(如部分患者无弹性成像),模型需适应数据不完整场景。
病理级鉴别诊断:需实现细粒度亚型分类(如T3原位癌、T5浸润癌),而非仅良恶性,以指导活检/手术决策。
泛化性验证:需在多中心、多品牌设备数据中验证,避免“单中心过拟合”。
3. 解决思路
设计多模态BMU-Net模型,严格遵循BI-RADS指南,整合MG、三模态US和临床元数据;
提出“疾病树分类体系”(T1-T5),通过推理算法实现细粒度→粗粒度预测,无需重新训练;
采用“随机掩码策略”处理模态缺失,提升真实世界适应性;
在多中心、多设备及前瞻性数据中全面验证,对比放射科/病理科医生性能。
03
BMU-Net模型架构
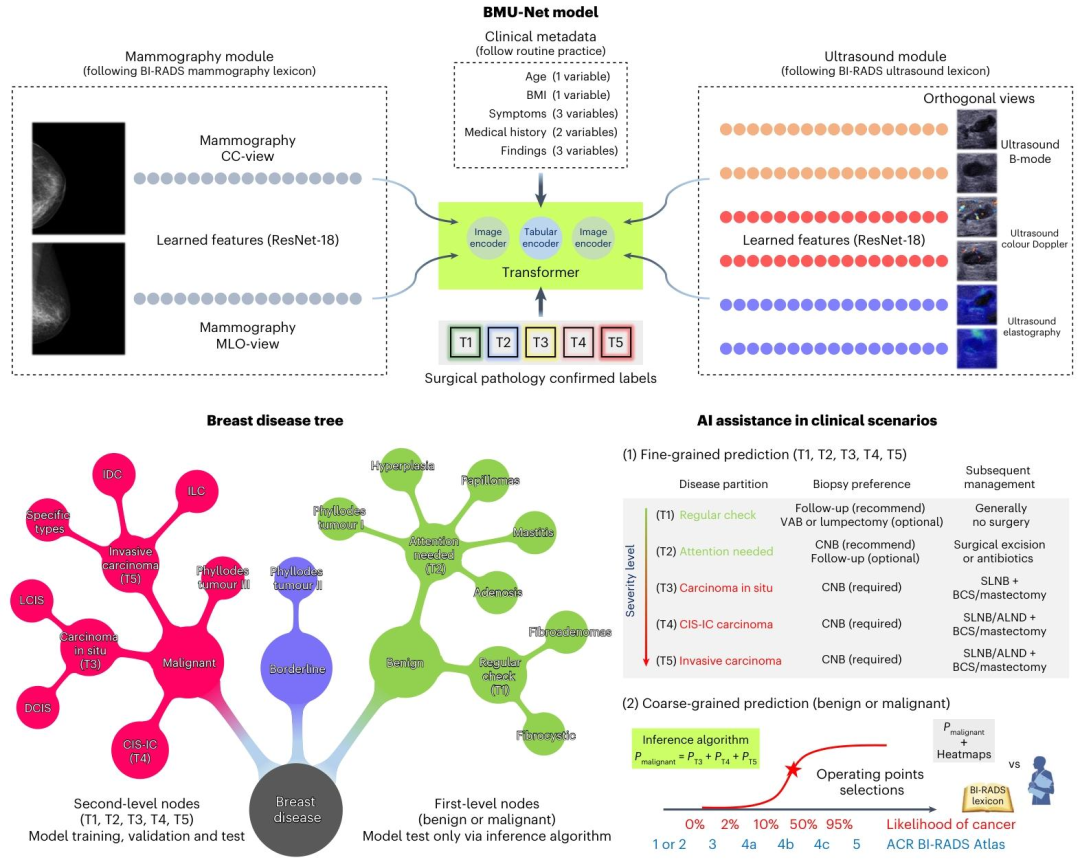
图1 | BMU-Net模型整体架构示意图
1. 核心输入:三模态数据协同
模型严格匹配临床诊断流程,整合三类关键数据,覆盖影像与临床语境:
-
乳腺钼靶(MG)模块输入:标准CC(颅尾位)和MLO(内外侧斜位)双视图影像,提取全乳腺全局特征;
-
超声(US)模块输入:三模态(B模式、彩色多普勒、弹性成像)+横纵双视图影像,聚焦病灶局部特征;
-
临床元数据输入:含年龄、BMI、症状(3类)、病史(2类)、影像表现(3类)等共10项临床变量,补充诊断语境。
2. 特征提取:模态特异性编码器
采用ResNet-18作为骨干网络,分别为乳腺钼靶和超声设计独立编码器,确保模态适配性:
-
先通过单模态数据集(乳腺钼靶/超声)单独训练两个模块,得到预训练的“模态特异性图像编码器”(权重针对各自模态优化);
-
编码器通过1×1平均池化聚合空间特征,再经全连接层输出初步特征向量,且同模态下不同视图(如MG的CC/MLO、US的横/纵视图)共享卷积权重。
3. 跨模态融合:Transformer与后期融合
通过Transformer块和“后期融合(Late Fusion)”解决多模态特征协同问题,同时提升鲁棒性:
-
先将乳腺钼靶、超声的预训练编码器权重迁移至BMU-Net,通过Transformer注意力层将两者特征向量统一维度,实现影像特征跨模态关联学习;
-
临床元数据单独通过“表格编码器”(权重随机初始化)处理后,与上述融合后的影像特征进行后期融合,形成完整特征表示;
-
微调阶段引入随机模态掩码(Random Masking),模拟临床中模态缺失场景(如仅存MG/US),提升模型对不完整数据的适应性。
4. 输出设计:双粒度预测,无需重训
基于“乳腺疾病树”结构,实现细粒度与粗粒度双输出,匹配临床不同决策需求:
-
细粒度输出:直接预测5类疾病(T1-T5,对应“常规随访良性-需关注良性-原位癌-原位癌伴浸润-浸润癌”),为活检方式(如VAB/CNB)、手术方案(如保乳术/乳房切除术)提供精准参考;
-
粗粒度输出:通过推理算法汇总细粒度概率,得到“良恶性”二分类结果,无需重新训练模型;
可解释性:采用Grad-CAM生成热力图,叠加于原始影像上,可视化模型关注的病灶区域,辅助临床信任与决策。
5. 训练策略:分阶段优化与泛化保障
-
第一阶段:单模态预训练(MG/US模块分别训练,获取适配权重);
-
第二阶段:多模态微调(用MG+US+临床元数据微调BMU-Net,固定影像编码器预训练权重,仅优化融合层与元数据编码器);
-
针对数据不平衡:采用“类别平衡采样”(过采样稀有类如T3,欠采样高频类如T2)+标签平滑损失,提升小样本分类性能。
04
数据和方法
研究数据
数据规模:总计19,360张图像,来自5,216个乳房(5,025名患者),所有数据均经手术病理确认。
数据来源:
乳腺X光摄影数据集:回顾性收集自安徽医科大学第一附属医院等,包括MG_H1(800个乳房)、MG_H2(518个乳房)、MG_H3(783个乳房)和MG_Hx(仅癌症人群)。
超声数据集:前瞻性收集自多家医院,包括US_H1M1(819个乳房)、US_H1M2、US_H2和US_H3,涵盖三模态超声图像。
多模态数据集:前瞻性收集MGUS_H1和MGUS_H2,包含配对图像和临床元数据。
数据特点:以诊断人群为主,包含高比例BI-RADS4和5病例(如MGUS_H1中94.2%),模拟真实临床挑战。数据经去标识化处理,符合伦理标准。
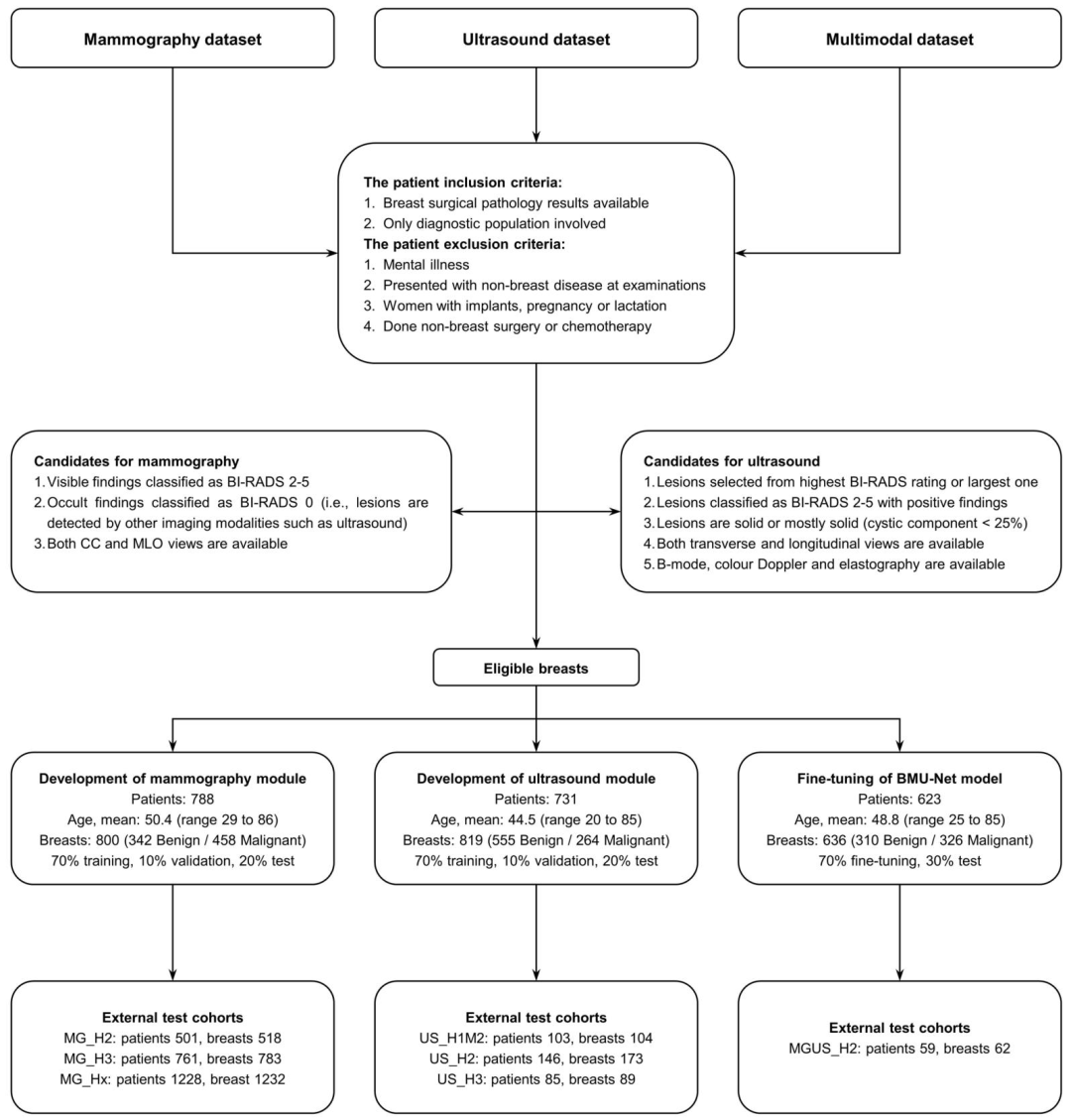
患者招募与数据集分配流程图
技术方法
深度学习框架:使用PyTorch,基于ResNet-18和Transformer块,优化标签平滑损失函数。
训练策略:预训练单模态模块后微调多模态模型,采用类别平衡(上采样稀有类别)和数据增强(翻转、旋转)。
评估指标:
细粒度评估:使用混淆矩阵和Cohen's kappa(评估一致性)。
粗粒度评估:使用ROC曲线和AUC(评估分类性能)。
可解释性:通过Grad-CAM生成热图,可视化模型决策依据。
统计方法:使用Delong's test比较AUC,t检验比较差异,置信区间基于1,000次bootstrap。
05
研究结果
1.钼靶模块(MG模块)性能
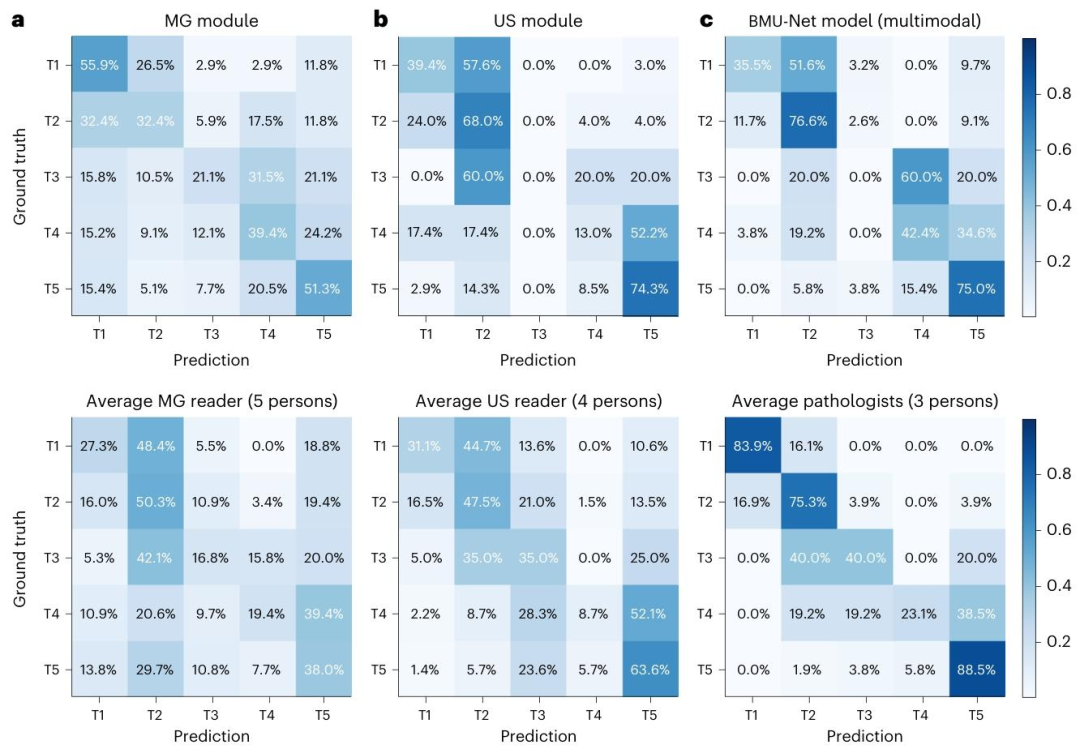
图2 | AI 系统与人类专家的细粒度疾病分类混淆矩阵对比
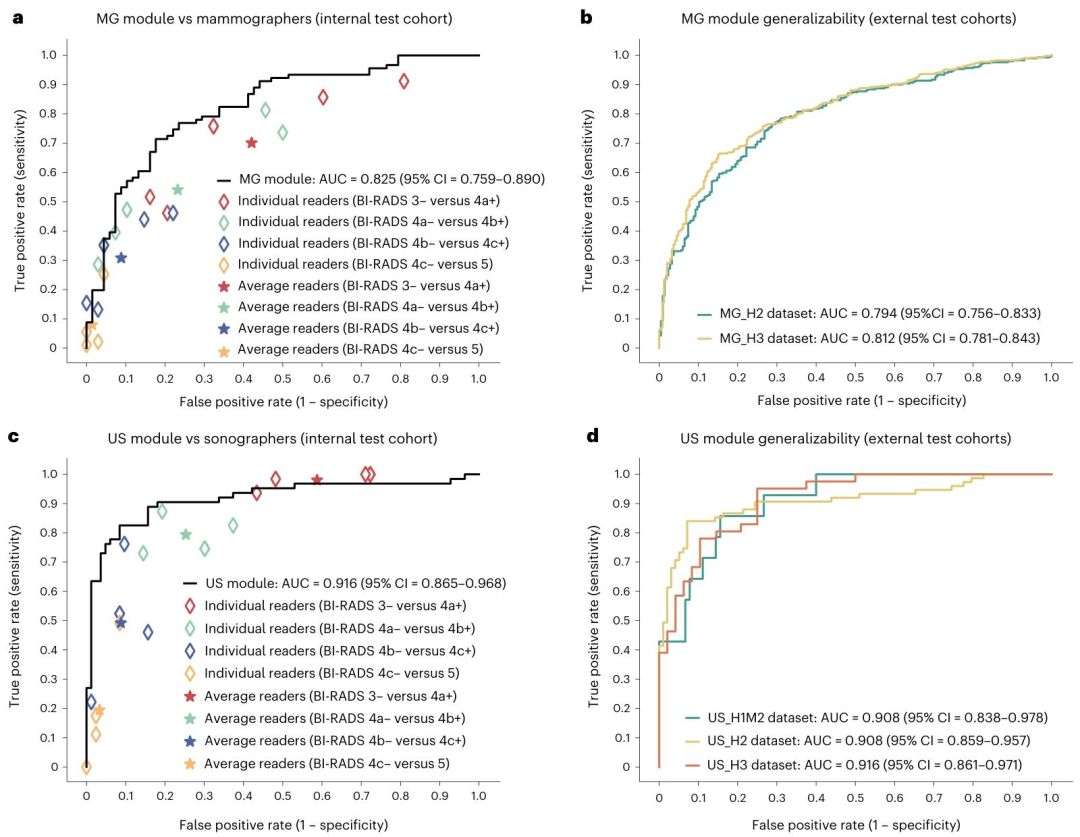
图3 | 单个模块与医生的粗粒度乳腺癌评估(ROC 曲线)
内部测试(MG_H1):
细粒度Kappa=0.398(优于5名医生的0.187-0.314,均为“公平一致”);
粗粒度AUC=0.825(优于直接训练二分类模型的0.811);
对BI-RADS4类(最具挑战性,医生易误判),性能显著优于医生平均水平。
外部测试:
MG_H2(单设备)AUC=0.794,MG_H3(多设备)AUC=0.812,与内部性能一致,泛化性好;
MG_Hx(仅癌症患者)灵敏度99.8%,漏诊率极低。
临床操作点:
匹配医生特异度时,漏诊率13.2%(显著低于医生的29.9%);
2%活检阈值(ACR标准)下,灵敏度99.7%,几乎无漏诊。
2.超声模块(US模块)性能
内部测试(US_H1M1):
细粒度Kappa=0.571(优于4名医生的0.325-0.558,医生最高0.558);
粗粒度AUC=0.916(优于直接二分类模型的0.911),ROC曲线略优于医生。
外部测试:
US_H1M2 AUC=0.908,US_H2 AUC=0.908,US_H3 AUC=0.916,Kappa0.383-0.546,泛化性优秀。
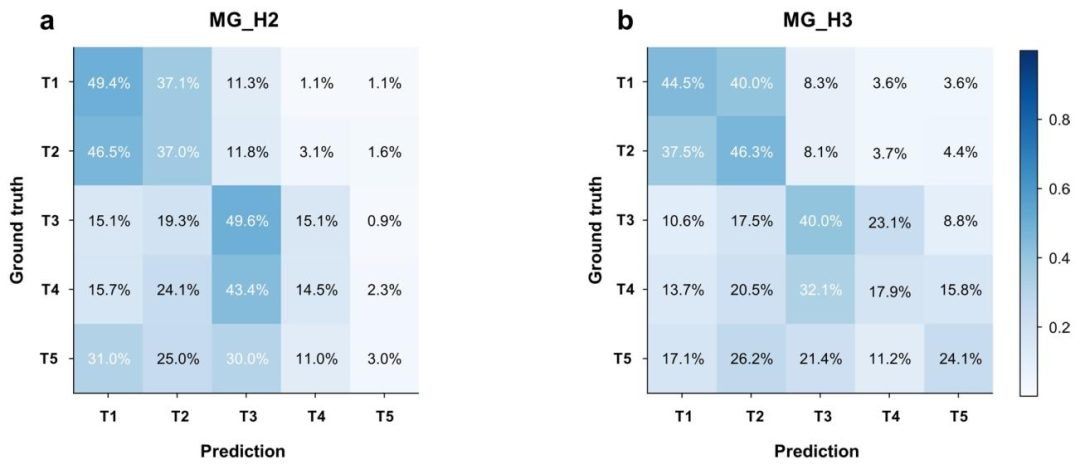
MG模块在MG_H2、MG_H3外部数据集的混淆矩阵
临床操作点:
匹配医生特异度时,漏诊率4.8%(接近医生的2.0%);
2%阈值下漏诊率几乎为0,灵敏度极高。
3.BMU-Net多模态模型性能
权重初始化影响:
用MG/US预训练权重的双模态模型(MG+US),细粒度准确率53.4%(显著高于随机初始化35.1%和ImageNet预训练46.1%,P<0.05),AUC=0.945(高于后两者的0.807和0.916,P<0.05)。
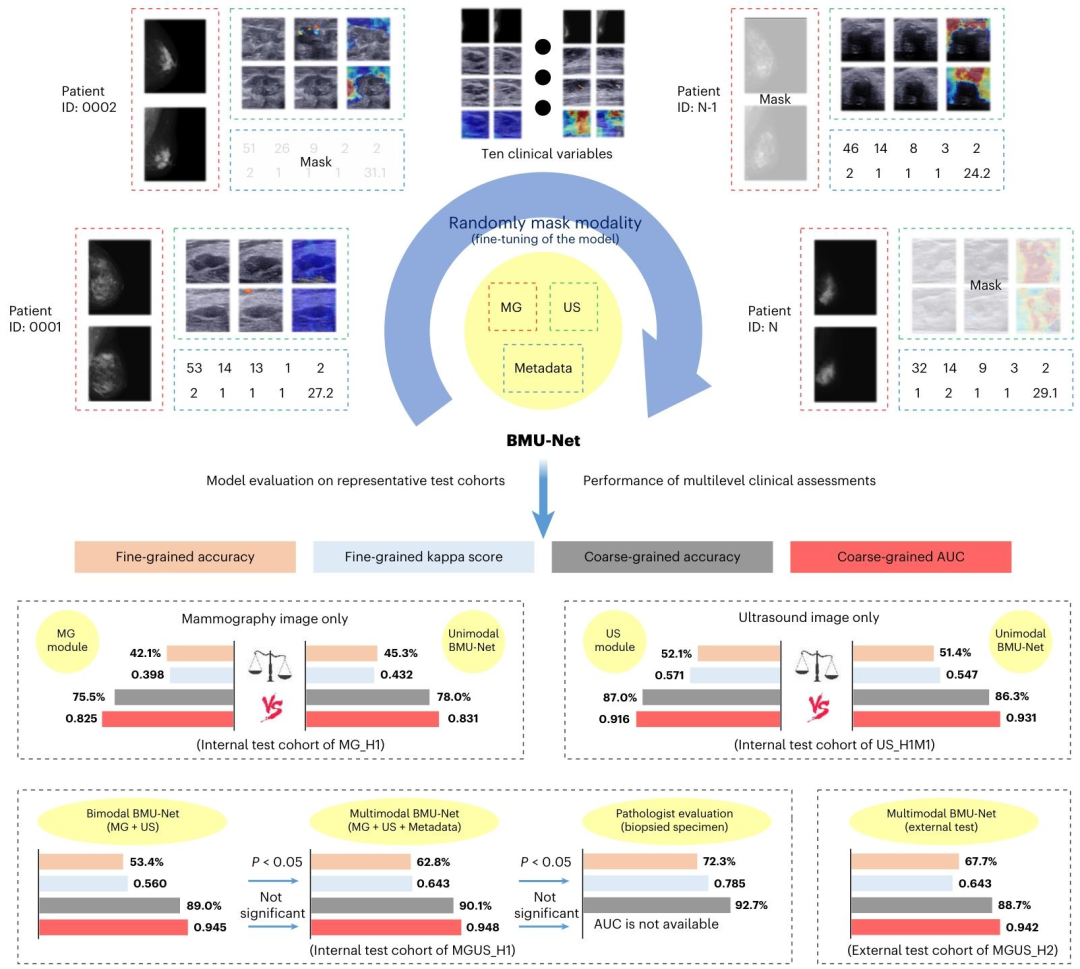
图4 | BMU-Net模型在真实临床场景的适应性
临床元数据增益:
多模态模型(MG+US+元数据)细粒度Kappa=0.643(显著一致,高于双模态的0.560,P<0.05),准确率62.8%(提升~10%);粗粒度AUC=0.948,准确率90.1%。
外部验证(MGUS_H2):
Kappa=0.643,AUC=0.942,与内部性能一致,可靠性高。
数据缺失鲁棒性:
单模态BMU-Net(仅MG或US)性能与对应单模块一致;元数据缺失时,保留“年龄、BMI、病变大小”(Top3关键变量)仍能维持非劣效性能。
与病理科医生对比:
前瞻性数据集(187患者191乳房)中,模型粗粒度准确率90.1%(接近医生92.7%),细粒度准确率62.8%(低于医生72.3%但差距较小)。
4.可解释性结果
Grad-CAM热力图可准确标注病变区域(如浸润癌的边界、血流丰富区),与临床医生关注点高度一致,提升模型临床信任度。
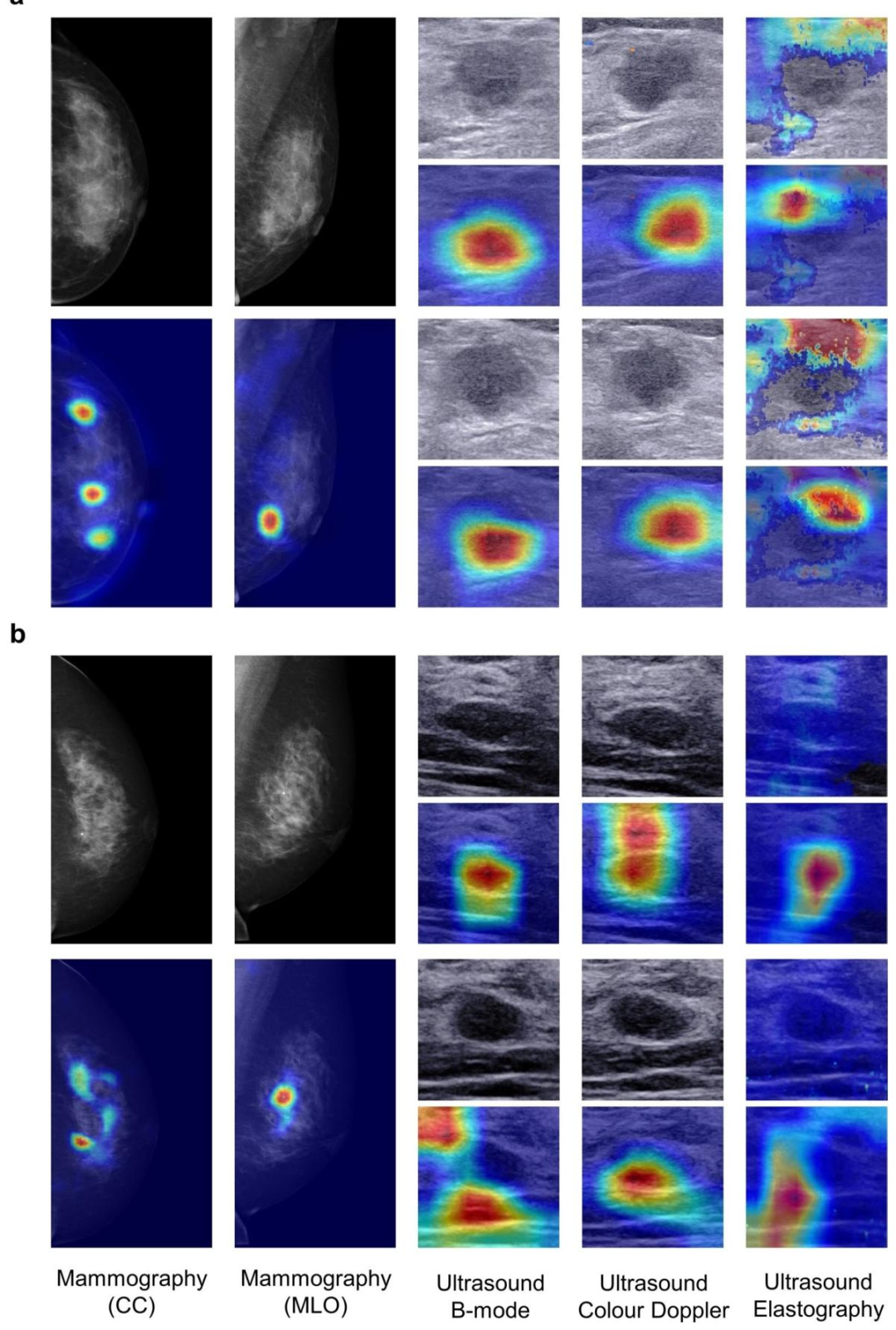
AI预测依据的热图示例
06
结论
BMU-Net模型通过多模态数据整合,实现了乳腺癌风险的准确分层和鉴别诊断。模型在多个前瞻性数据集中验证,性能与人类专家相当或更优,尤其在高难度的BI-RADS 4病例中表现突出。树状分类法使模型能同时提供多级预测,支持临床决策(如活检类型选择)。研究表明,多模态AI可标准化乳腺影像解读,减少主观差异,具有直接临床应用的潜力。
07
讨论
创新点
多模态融合诊断体系(BMU-Net)
将乳腺X线(MG)、三模态超声(B-mode、彩色多普勒、弹性成像)与临床元数据整合到同一深度学习框架中,实现了影像-临床信息的统一建模,是乳腺癌AI诊断领域首个覆盖全流程的多模态系统。
树状疾病分类体系(T1–T5)
设计了“从良性到侵袭性”的五级病理分层标签体系,用于细粒度训练与推理阶段的层次化输出,实现了从粗粒度(良恶性)到病理级别的多层预测。
临床工作流导向设计
模型输出直接对应临床决策(如是否活检、活检方式、手术类型),形成“AI-辅助管理决策树”,提升了研究的临床实用性。
模态缺失自适应训练策略
通过随机mask策略在训练阶段模拟模态缺失,使模型在实际临床中即使缺少某一影像模态(如未做弹性成像)仍能稳定预测。
可解释性可视化
引入Grad-CAM热力图用于定位模型关注区域,增强AI预测结果的可解释性与医生信任度。
多中心前瞻性验证
在来自多家医院、不同设备的数据上进行外部验证,证明模型具备良好的泛化性与临床可推广性。
可借鉴的技术方法
多模态深度学习融合架构
图像编码:ResNet-18提取特征;
融合机制:Transformer跨模态特征交互;
临床数据编码:表格编码器+后融合(late fusion)。
→这种“图像+结构化数据”融合模式可推广到其他多模态医学AI任务。
层次化标签与推理算法
使用细粒度病理标签训练,推理时通过概率加权(如Pmalignant=PT3+PT4+PT5)实现多级决策输出。
→适用于需要兼顾“粗粒度诊断+细粒度分型”的医学影像问题。
多中心数据分层验证流程
内部训练/验证/测试+外部多医院测试;
报告AUC、Kappa、敏感性/特异性等多指标。
→该方法有助于确保AI模型的稳健性与可临床化。
随机模态掩码策略(Random Masking)
模拟真实临床中模态缺失的情况;
增强模型在不完整输入下的鲁棒性。
→值得在其他多模态任务(如CT+MRI、影像+基因数据)中借鉴。
基于热力图的可解释性验证
用Grad-CAM对预测结果进行病灶可视化;
验证AI聚焦区域与病理区域的一致性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献107条内容
已为社区贡献107条内容

所有评论(0)