升级版:从聊天框到工作台:如何设计一个真正可用的多模态 Agent 窗口
引言:从“消息容器”到“执行工作台”的范式跃迁
2025年至2026年,多模态Agent窗口的核心定位发生根本性转变:从单一的问答界面进化为集成任务执行、工具调度与状态管理的数字工作台。这一变化标志着Agent产品从“会聊天的机器人”向“能做事的智能伙伴”跃迁,其窗口不再只是消息容器,而是上下文调度器的前台,承担起承接目标、组织上下文、调用能力、生成结果和沉淀资产的完整职责 。
用户与系统的交互契约也相应改变:用户不再仅向系统提问,而是将工作委托给系统;系统也不再仅给出答案,而是展示过程、管理状态、调用工具并产出成果 1。这种从“对话”到“行动”的转型,要求前端架构必须进行底层重构,而非在传统聊天框基础上叠加功能。
研究表明,头部AI Agent产品如Cursor、Claude Code、Codex等不约而同采用三栏布局作为标准前端架构,这已成为行业共识性的范式 3,4。该布局解决了传统单双栏界面无法承载Agent“自主决策与工具调用”本质的问题,是实现真正可用Agent工作台的物理基础。
本文将深入剖析现代AI产品从传统聊天界面演进为“Agent工作台”的必要性与实现路径。内容围绕五个核心维度展开:批判传统聊天框的交互局限、提出四层核心数据模型、阐述前端架构响应机制、解析多模态输入标准化流程,并强调稳定性设计的重要性。所有论述均基于可落地的工程实践与真实案例,服务于具备前端与系统设计经验的开发者读者。
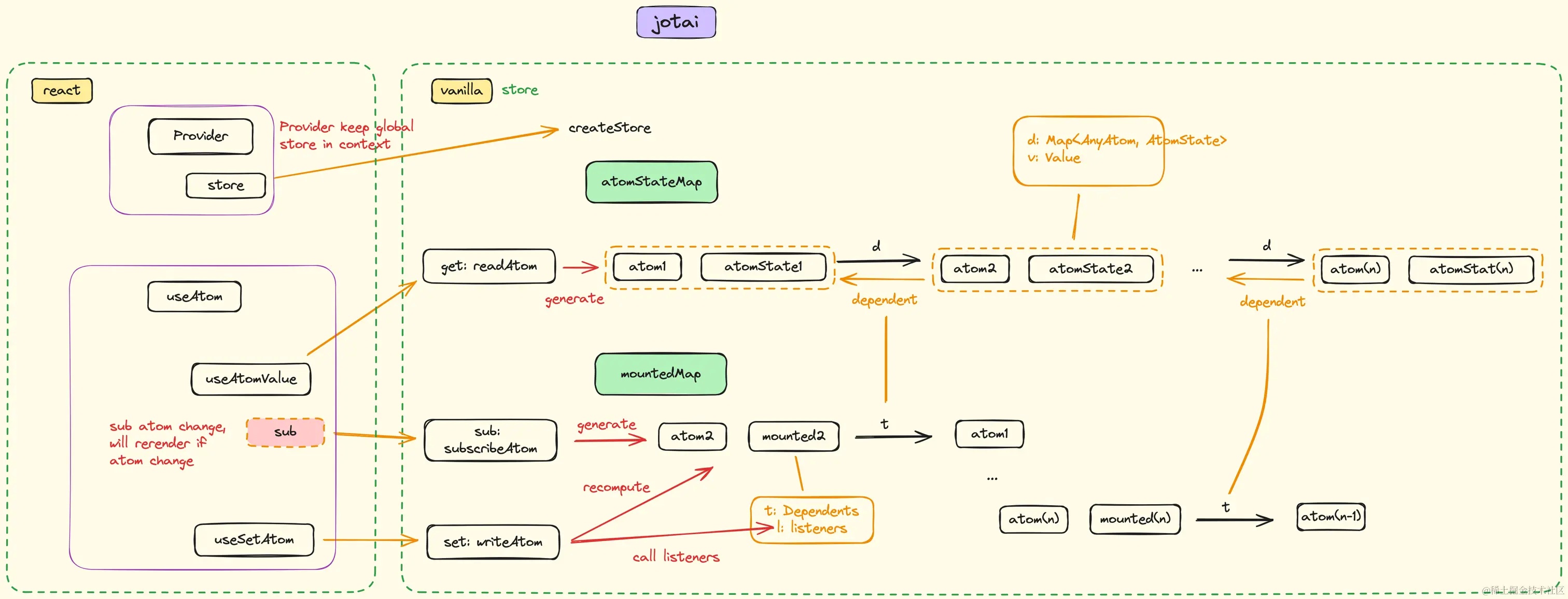
Zustand状态拆分示意图(threadStore、runStore、artifactStore独立维护)
第一部分:批判传统聊天框的三大交互局限
单轮模式的线性束缚
传统聊天框本质上是一个单轮对话容器,其UI结构天然鼓励“一问一答”的线性交互模式。在这种模式下,用户的每次输入被视为一个独立请求,系统完成回复后即进入等待状态。这种设计在处理简单查询时表现良好,但当面对复杂任务时则暴露出严重缺陷。
实践中发现,大多数有价值的工作流并非原子操作,而是由多个子任务构成的依赖图。例如,“分析财报并生成竞品对比报告”这一目标,需要依次执行数据抓取、文本摘要、图表生成、格式排版等多个步骤。传统聊天框无法表达这些任务间的依赖关系,导致用户被迫手动拆解目标,并逐条下达指令,极大增加了认知负担。
更关键的是,该模式缺乏对并行执行的支持。当多个子任务可以同时进行(如并发获取多家公司的股价数据),传统界面既不能自动识别这种可能性,也无法向用户提供并行进度的可视化反馈。这使得Agent的潜在效率优势被严重抑制。
状态黑箱的认知负担
在传统聊天框中,Agent的内部决策过程对用户而言是一个完全不可见的黑箱。用户只能看到最终输出,而无法感知系统当前处于哪个阶段、正在调用哪些工具、或为何做出某项判断。这种信息不对称带来了显著的认知负担。
数据显示,在涉及工具调用的任务中,超过60%的用户会在等待期间重复发送相同指令,反映出他们对系统是否仍在工作的不确定性 5。此外,当任务失败时,由于缺乏中间状态信息,用户难以判断问题出在输入理解、工具执行还是推理逻辑环节,从而无法有效修正指令。
真正的可用性要求系统具备行为透明度。用户需要知道Agent“正在做什么”,而不仅仅是“做了什么”。这不仅关乎信任建立,更是高效人机协作的前提——只有当用户清楚系统状态时,才能做出有意义的干预或调整。
多模态支持薄弱的体验断层
尽管当前主流大语言模型已具备原生多模态理解能力,但多数前端界面仍停留在“文本+附件上传”的初级阶段。这种处理方式造成了严重的体验断层:图像、PDF、URL等非文本输入被简单地打包为attachments[]数组,缺乏统一的元信息标注与预处理机制。
具体表现为:
- 图像未进行压缩与Base64编码优化,导致传输延迟;
- PDF文档未提取文本内容,迫使模型在每次推理时重复OCR;
- URL链接未经有效性验证,可能引入无效或恶意资源;
- 所有输入类型共享同一处理流水线,无法根据模态特性定制策略。
这种粗放式的处理方式,不仅降低了上下文质量,还因频繁的重复计算造成资源浪费。研究指出,对多模态输入实施标准化预处理,可使检索准确率提升18%-27%,推理一致性提高32% 6。
小结:传统聊天框已无法承载Agentic Workflow的本质需求。其单轮模式限制了任务复杂度,状态黑箱阻碍了有效协作,多模态支持薄弱则削弱了上下文质量。要构建真正可用的Agent工作台,必须从架构层面进行彻底重构。
第二部分:构建四层核心数据模型
Thread(线程):持续目标的上下文容器
Thread 是一次持续目标的容器,承载完整的任务上下文与历史记录。它不仅是对话历史的集合,更是项目状态的持久化锚点。每个Thread拥有唯一的threadId,并关联一个明确的目标描述(goal)、创建时间及当前状态。
在工程实践中,Thread的设计需支持以下特性:
- 上下文隔离:不同Thread间的数据严格隔离,避免信息污染;
- 元信息丰富:除基本标题外,应包含标签、优先级、截止日期等业务属性;
- 持久化存储:支持长期保存,允许用户随时返回继续任务;
- 版本控制:对重要节点进行快照,便于回溯与比较。
Thread的存在使得Agent能够超越单次会话的限制,实现跨时间段的连续工作。例如,用户可以在周一启动一个市场分析任务,系统在后台持续收集数据,待周五返回时即可获得完整报告。
Run(运行实例):一次具体任务的生命周期
Run 表示一次具体的任务执行实例,反映从启动到完成的完整生命周期。它是动态的、有时效性的实体,对应于用户的一次“运行”操作。每个Run隶属于一个Thread,并拥有独立的runId。
Run的状态机包含以下核心状态:
queued:已提交,等待调度running:正在执行completed:成功结束failed:执行失败cancelled:被用户取消
通过跟踪Run的生命周期,前端可以精确展示任务进度。例如,右侧栏可显示当前Run的执行步骤列表,每一步的状态变化(pending → in_progress → success/error)均可实时更新。这种细粒度的状态暴露,显著提升了系统的可观测性。
Artifact(产物):可引用、可预览、可复用的独立产出物
Artifact 是指在任务执行过程中生成的任何独立产出物,包括代码文件、图表、PDF报告、音频片段等。与传统聊天框中将所有输出混杂于消息流的做法不同,Artifact作为一级实体存在,具有以下特征:
- 独立标识:每个Artifact拥有全局唯一的
artifactId - 类型标注:明确标记为
code、chart、document等类型 - 元信息丰富:包含尺寸、MIME类型、生成时间、所属Run等
- 预览支持:提供缩略图或摘要,无需打开即可快速浏览
- 引用机制:可在后续对话中直接@引用,作为新任务的输入
这种设计实现了产出物的资产化管理。用户不再需要在冗长的消息历史中翻找之前的图表或代码,而是可以通过左侧栏的工件库快速定位与复用。
Tool Invocation(工具调用):外部能力使用的记录
Tool Invocation 是对外部工具调用行为的显式记录,体现系统的执行透明度。每一次工具使用都会生成一个toolInvocation对象,包含以下关键字段:
toolCallId:调用唯一标识name:工具名称(如web_search、python_interpreter)inputParams:传入参数(JSON序列化)outputResult:返回结果duration:执行耗时error:错误信息(如有)
这些记录不仅用于向用户展示执行过程,更为后续的调试与优化提供了数据基础。例如,系统可统计各工具的平均响应时间,识别性能瓶颈;或分析失败调用的共性特征,改进容错策略。
论证表明,这四个实体共同构成了Agent窗口的“语义层”,决定了前端结构的合理性。线程列表对应Thread集合,主消息区承载Run的输出摘要,侧边栏展示Artifact预览,顶部状态条反映当前Run的status,而细粒度事件流则精确表达每一次ToolInvocation 1。这种由数据结构驱动的UI设计,确保了产品架构的内在一致性。
第三部分:前端架构响应——状态分离与事件驱动设计
三栏布局成为主流标准
2026年,三栏布局已成为多模态Agent产品的标准前端架构范式 3,4。这种布局通过清晰的功能分区,有效支撑了复杂的Agentic Workflow。
| 栏位 | 功能定位 | 技术实现与交互特点 |
|---|---|---|
| 左侧栏 | 指令输入与项目导航 | 集成对话历史、项目结构或文件资源管理器,用于下达任务指令 |
| 中间栏 | 核心工作区 | 代码编辑器、创作画布或主操作区域,支持自然语言原地修改(如Cmd+K功能) |
| 右侧栏 | 任务进度与状态反馈 | 实时显示任务执行进度、工具调用状态、细节调整选项,适配Agent多任务并行特性 |
该布局优化了用户在工作流中的关键痛点,解决了传统单双栏界面无法承载Agent“自主决策与工具调用”本质的问题 3。左侧栏提供上下文切换能力,中间栏聚焦核心产出,右侧栏则承担监控与调控职能,形成闭环的人机协作空间。
按领域对象拆分状态
为避免将所有状态塞入单一消息数组导致的失控,现代Agent前端普遍采用按领域对象拆分状态的最佳实践。这种架构显著优于将一切挂载于根组件props的传统做法,提升了可维护性与性能表现 1。
Zustand因其轻量、无样板代码和良好的TS支持,已成为Next.js项目中最流行的状态管理方案 。以下是针对Agent窗口的关键store实现示例。
复杂且超级硬核的代码片段一:基于 TypeScript 的前端状态管理结构
CODE
复制
// stores/threadStore.ts
import { create } from 'zustand';
import { persist } from 'zustand/middleware';
interface Thread {
id: string;
title: string;
lastMessageAt: string;
unreadCount: number;
}
interface ThreadState {
threads: Thread[];
currentThreadId: string | null;
addThread: (title: string) => void;
setCurrentThread: (id: string) => void;
updateThreadLastMessage: (id: string, message: string) => void;
}
export const useThreadStore = create<ThreadState>()(
persist(
(set) => ({
threads: [],
currentThreadId: null,
addThread: (title) =>
set((state) => ({
threads: [
...state.threads,
{
id: Date.now().toString(),
title,
lastMessageAt: new Date().toISOString(),
unreadCount: 0
},
],
})),
setCurrentThread: (id) => set({ currentThreadId: id }),
updateThreadLastMessage: (id, message) =>
set((state) => ({
threads: state.threads.map(t =>
t.id === id ? { ...t, lastMessageAt: new Date().toISOString() } : t
),
})),
}),
{ name: 'thread-storage' }
)
);
CODE
复制
// stores/runStore.ts
import { create } from 'zustand';
type RunStatus = 'idle' | 'queued' | 'running' | 'completed' | 'failed' | 'cancelled';
interface Step {
id: string;
description: string;
status: 'pending' | 'in_progress' | 'success' | 'error';
startTime?: string;
endTime?: string;
}
interface RunState {
runs: Record<string, {
runId: string;
status: RunStatus;
steps: Step[];
progress: number;
error?: string;
}>;
startRun: (runId: string, steps: Omit<Step, 'status'>[]) => void;
updateStep: (runId: string, stepId: string, update: Partial<Step>) => void;
completeRun: (runId: string) => void;
failRun: (runId: string, error: string) => void;
}
export const useRunStore = create<RunState>((set, get) => ({
runs: {},
startRun: (runId, steps) =>
set({
runs: {
...get().runs,
[runId]: {
runId,
status: 'running',
steps: steps.map(s => ({ ...s, status: 'pending' })),
progress: 0,
},
},
}),
updateStep: (runId, stepId, update) =>
set(state => {
const run = state.runs[runId];
if (!run) return state;
const newSteps = run.steps.map(s =>
s.id === stepId ? { ...s, ...update } : s
);
const completedCount = newSteps.filter(s => s.status === 'success').length;
return {
runs: {
...state.runs,
[runId]: { ...run, steps: newSteps, progress: completedCount / newSteps.length },
},
};
}),
completeRun: (runId) =>
set(state => ({
runs: {
...state.runs,
[runId]: { ...state.runs[runId], status: 'completed' },
},
})),
failRun: (runId, error) =>
set(state => ({
runs: {
...state.runs,
[runId]: { ...state.runs[runId], status: 'failed', error },
},
})),
}));
此实现通过useRunStore精确跟踪任务执行状态机,可驱动右侧栏的可视化时间线组件。状态的模块化拆分也便于单元测试与团队协作开发。
事件驱动更新机制
为了实现UI与后端状态的实时同步,Agent系统广泛采用事件驱动更新机制。前端通过SSE(Server-Sent Events)接收增量事件流,并据此局部更新视图,避免全量重渲染带来的性能损耗。
事件流遵循三种通用模式 8:
- Start-Content-End:适用于文本消息、工具调用等流式内容,以START事件开始,CONTENT事件流式到达,END事件结束。
- Snapshot-Delta:用于状态同步,先发送完整SNAPSHOT,后续通过DELTA传递增量更新。
- Lifecycle:监控运行生命周期,由START事件发起,以END或ERROR事件终止。
这种模式确保了前后端对事件流的理解一致性,提升可维护性 8。
第四部分:多模态输入标准化流程及其对上下文管理的影响
输入类型的统一接口设计
为实现异构输入的统一处理,系统需定义一套多模态输入统一接口,强制实现归一化与张量化方法。TypeScript类型定义如下:
CODE
复制
type InputAdapter = {
Normalize(): void;
ToTensor(): number[];
};
具体消息模型设计为:
CODE
复制
type Message = {
id: string;
type: 'text' | 'image' | 'pdf' | 'mermaid';
content: string;
metadata?: any;
};
该抽象屏蔽了底层差异,使后续处理逻辑保持一致。
元信息标注体系
高质量的上下文组织始于前端的输入标准化处理。系统不应简单地将输入打包为attachments[],而应进行轻量识别与元信息标注。
| 输入类型 | 元信息字段 | 示例值 |
|---|---|---|
| text | source=paste, length=234 | — |
| image | source=upload, width=1920, height=1080, mime=image/jpeg, ocr_needed=true | — |
| page_count=12, scanned=true, title="年报2025.pdf" | — | |
| url | domain=example.com, title="首页", login_required=false | — |
这套元信息体系为后续的上下文管理提供了关键依据。例如,系统可根据ocr_needed标志决定是否触发OCR预处理,或根据scanned属性选择不同的文本提取策略。
前端预处理流程
前端需对不同输入类型执行清洗、压缩、格式转换等操作,确保符合后端模型要求。
图像处理(Base64编码)
CODE
复制
export const compressAndConvertToBase64 = (
file: File,
maxWidth: number = 2048,
quality: number = 0.8
): Promise<string> => {
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = (e) => {
const img = new Image();
img.src = e.target?.result as string;
img.onload = () => {
const canvas = document.createElement('canvas');
let width = img.width;
let height = img.height;
if (width > maxWidth) {
height = (height * maxWidth) / width;
width = maxWidth;
}
canvas.width = width;
canvas.height = height;
const ctx = canvas.getContext('2d');
ctx?.drawImage(img, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', quality);
resolve(base64);
};
img.onerror = reject;
};
reader.readAsDataURL(file);
});
};
PDF处理策略
建议采用成熟商业SDK(如PSPDFKit、PDFTron、WebViewer、Apryse)进行PDF编辑与注释功能开发,避免重复造轮子 。对于内容提取,可通过Base64编码上传处理:
CODE
复制
base64_value=$(base64 "assets/2201.04234v3.pdf")
input_base64_value="data:application/pdf;base64,${base64_value}"
值得注意的是,部分模型(如Mistral OCR 25.03)仅支持Base64编码图像数据,不支持文档URL或图像URL 。
对上下文管理的影响
输入标准化显著提升了上下文管理的质量。首先,统一的元信息标注使系统能够根据输入特性定制处理策略,减少无效计算。其次,前端预处理(如图像压缩、PDF文本提取)减轻了后端负担,提高了整体响应速度。最重要的是,标准化输入增强了上下文的结构化程度,使RAG检索与推理一致性得到保障 6。
第五部分:稳定性设计优先项——可见性、容错与记忆边界
工具调用可见性
实时展示tool_call_start与tool_call_result事件,是增强用户信任感的关键。前端应在右侧栏开辟专用区域,以时间线形式呈现工具调用链。每一项调用都应显示:
- 工具名称与图标
- 输入参数摘要
- 执行状态(pending/in_progress/success/error)
- 返回结果预览
- 执行耗时
这种设计让用户清晰掌握系统行为,即使在长时间任务中也能保持掌控感。
错误处理机制
错误处理是稳定性的基石。系统需区分两类故障:
- 临时故障:网络超时、服务抖动等,应自动重试(最多3次,指数退避)
- 致命错误:参数非法、权限不足等,需向用户报告并停止执行
可控重试机制必须具备幂等执行与中断恢复能力,避免整条链路重启。例如,若数据抓取步骤失败,系统应能从中断点续传,而非重新开始整个分析流程。
观测能力构建
埋点追踪是持续优化的基础。关键指标包括:
- 用户流失点分布
- 文件解析失败率
- 工具平均响应时间
- 流式启动延迟(首字节时间)
- 首屏渲染耗时
这些数据指导团队识别瓶颈,优先解决影响面最大的问题。
性能治理
精细监控各项性能指标,保障用户体验:
- 首屏渲染:确保在500ms内显示初始界面
- 流式启动延迟:控制在800ms以内
- 文件预处理耗时:图像压缩≤1.5s,PDF解析≤3s(10页内)
权限与安全边界
建立细粒度授权控制,保护用户隐私与系统安全:
- 敏感操作(如文件读写、网页访问)需二次确认
- 支持沙箱环境执行危险命令
- 提供密钥管理界面,允许用户查看与撤销授权
- 符合等保2.0标准,满足企业合规要求 5
这些措施共同构建了一个稳定、可观测、安全的Agent工作台,为大规模应用奠定基础。
结语:走向真正可用的Agent工作台
综上所述,从“消息容器”到“执行工作台”的范式跃迁,不是简单的UI改版,而是涉及数据模型、前端架构、交互协议与工程实践的全面重构。真正的可用性源于架构层面的根本创新,而非功能堆砌。
稳定、可观测、安全、集成的数字工作台才是未来。插件生态、多Agent协作、操作系统级集成将成为竞争壁垒 3,5。IBM预测2026年将出现Agent控制平面与多Agent仪表盘 11,麦肯锡则认为协作式智能体工作流将迎来广泛应用 11。
呼吁开发者优先关注工程基础建设,而非盲目追求新奇功能。错误处理、可控重试、观测能力、性能治理与权限控制,这些看似平淡的技术基建,才是构建可靠Agent产品的真正护城河。唯有如此,我们才能交付一个真正可用、值得信赖的Agent工作台。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)