人在公司,也能调用家里的本地大模型:OmniInfer 体验分享
本地大模型不止聊天框:我用 OmniInfer 打通了电脑、手机和远程 API
这两年本地大模型工具真的越来越多了。
一开始我也跟很多人一样,主要是在各种 UI、各种模型格式、各种后端之间来回切:今天试 llama.cpp,明天试 MLX,换台 Windows 机器又要重新配一遍环境,到了手机端更是另一套玩法。
最近我用到一个项目,叫 OmniInfer。它给我的感觉不是“又一个聊天界面”,而是更像一个本地 AI 推理的底座:把模型加载、硬件适配、推理后端、API 服务这些比较麻烦的东西统一包起来,让上层应用可以更轻松地调用本地模型。
项目地址:
https://github.com/omnimind-ai/OmniInfer
先说结论:如果你也在折腾本地 LLM / VLM,尤其是在 Windows、macOS、Android 这些平台之间切来切去,OmniInfer 值得看一眼。
它解决的痛点,其实挺真实
本地模型这件事,听起来很酷,但实际用起来经常会遇到这些问题:
- 同一个模型,在不同机器上应该用什么后端?
- Windows 上能不能走 CUDA?
- macOS 上能不能更自然地用 MLX?
- Android 端要怎么接本地推理?
- 桌面应用、移动应用、脚本调用能不能用同一套 API?
- 我只是想跑起来,不想每次都重新研究一堆编译参数。
OmniInfer 的思路就是:把这些底层差异尽量收拢起来。
它支持多种后端,比如 llama.cpp、ik_llama.cpp、MLX、MNN 等,并且提供 OpenAI-compatible API 和 Anthropic-compatible API。也就是说,你可以把它理解成一个本地版的推理服务:模型在自己机器上跑,但调用方式尽量接近云端 API。
这点我个人挺喜欢。因为很多工具、脚本、客户端本来就是按 OpenAI API 写的,如果本地服务也能保持类似接口,迁移成本会低很多。
一个让我印象很深的点:家里的模型,也能变成远程 API
这次我最想单独说一下 OmniInfer 的远程访问能力。
以前我对“本地模型”的理解比较朴素:模型在哪台机器上,就只能在哪台机器附近用。比如我在家里电脑上加载了一个模型,那我出门之后,基本就只能换云服务,或者远程桌面回家里的电脑。
但 OmniInfer 这类本地推理服务的思路不太一样。它可以在本机拉起一个 OmniInfer Server,然后通过公开的 Base URL 和 API Key,让外部设备按 OpenAI API 的规范来调用。
换句话说,我人在公司,或者在外面,只要家里的 OmniInfer Server 还开着,就可以用这个 Base URL 和 API Key 访问家里的模型推理服务。
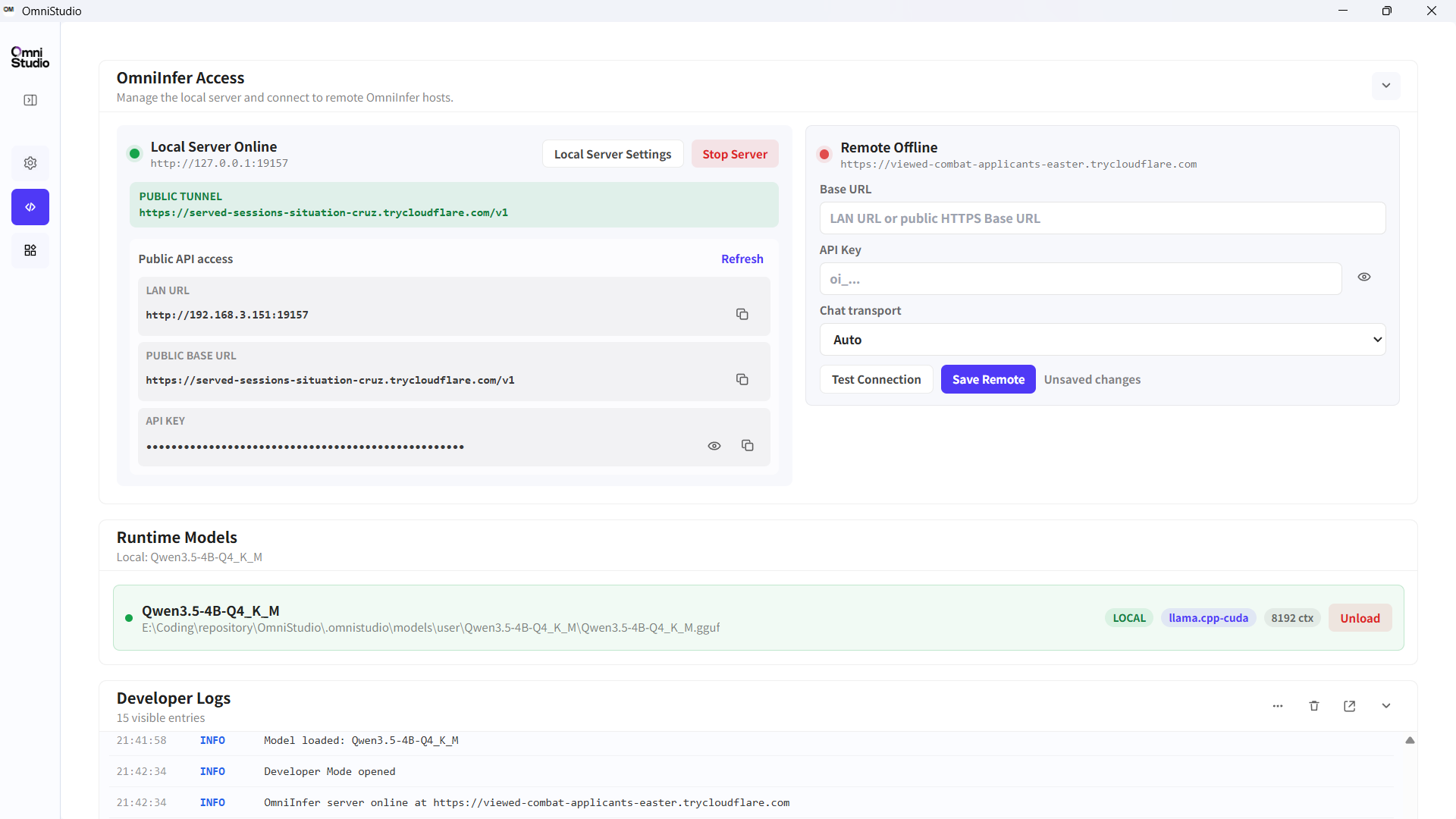
上面这张图是 OmniStudio 的开发者界面。它展示的不是一个普通聊天窗口,而是 OmniInfer Access:本地服务已经在线,同时给出了 LAN URL、Public Base URL 和 API Key。
这对我来说挺实用的。因为它不是“只能在某个 App 里点一点”,而是把本地模型包装成了一个比较标准的 API 服务:
- Base URL 是公开访问地址;
- API Key 用来做访问控制;
- 调用方式兼容 OpenAI API;
- 背后真正跑推理的,还是你自己机器上的模型。
这就有点像把家里的电脑变成一个私有 AI 推理节点。
当然,公网访问一定要注意 API Key,不要裸奔;但从体验上说,这个能力确实让本地模型的使用场景一下子变宽了。
当然这个 OmniStudio 也能很好地胜任本地推理 ChatBot 的职责,不仅能运行本地模型,还可以输入外部提供的 Base URL 和 API key 进行 API 调用推理。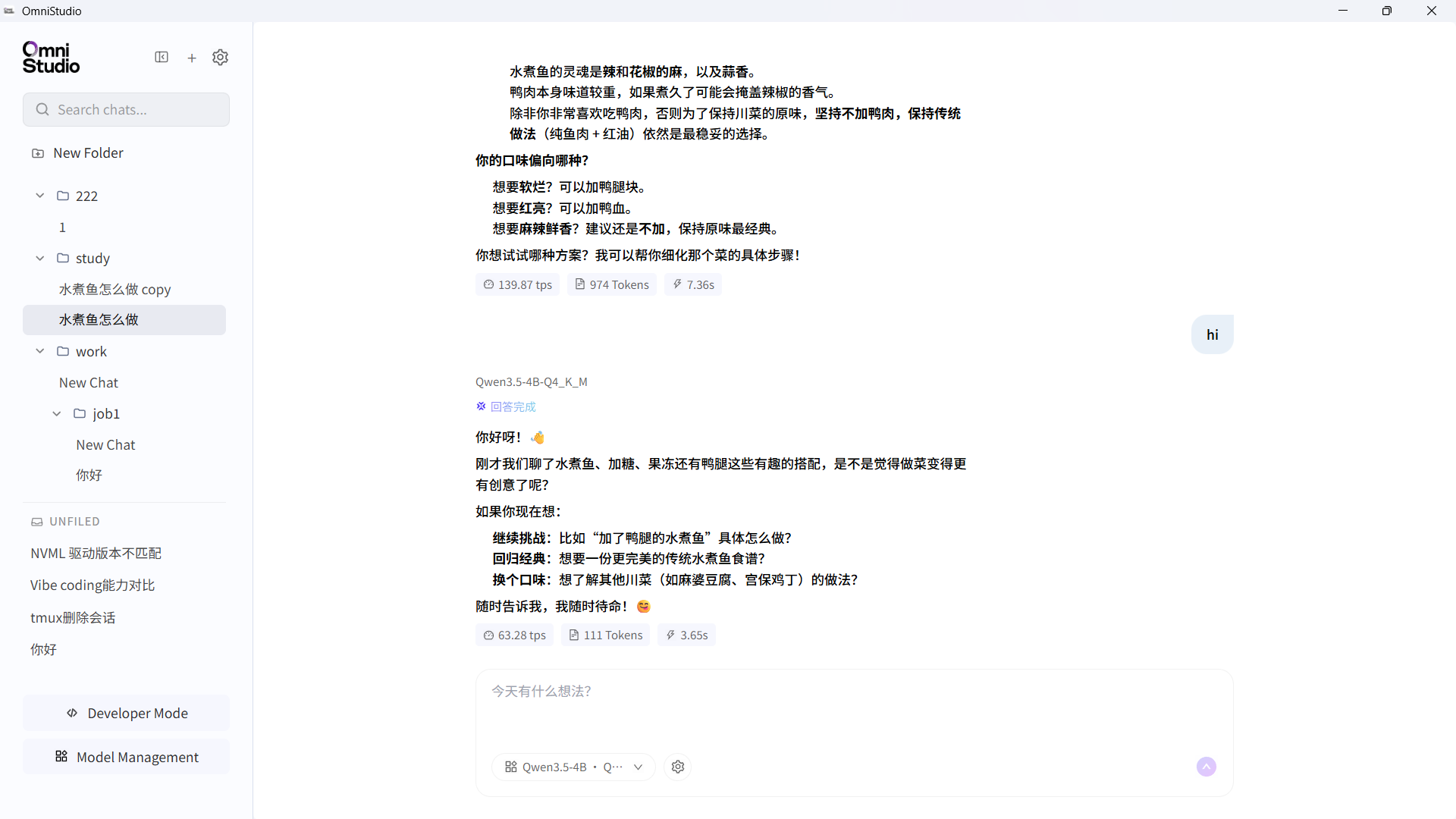
安装和启动门槛比较低
OmniInfer README 里给的安装方式很直接。
macOS、Linux、Android:
curl -fsSL https://raw.githubusercontent.com/omnimind-ai/OmniInfer/main/scripts/install.sh | bash
Windows PowerShell:
irm "https://raw.githubusercontent.com/omnimind-ai/OmniInfer/main/scripts/install.ps1?$(Get-Random)" | iex
它的安装脚本会根据平台和硬件情况做检测,然后推荐合适的后端。这个体验比“自己先判断显卡、再找对应后端、再研究编译参数”舒服不少。
当然,如果你是喜欢自己从源码构建的人,也可以走源码 checkout 的方式。只是对普通用户来说,先把服务跑起来更重要。
如果你喜欢命令行,也可以直接用 OmniInfer 自带的 TUI 来选择后端、加载模型和启动本地服务。
OmniInfer-tui
我比较看重的一点:它不是只盯着桌面
很多本地模型项目在桌面端体验不错,但一到移动端就比较尴尬。OmniInfer 的定位明显更偏跨平台,不只是 Windows/macOS/Linux,也覆盖 Android、iOS 这类移动和边缘设备场景。
这对我来说很关键。因为本地 AI 的一个趋势就是:不是所有推理都必须在云上,也不是所有推理都必须在一台高配台式机上。能不能在 PC、Mac、手机之间复用一套推理底座,会直接影响后续应用形态。
Demo 1:Windows / macOS 上的 OmniStudio
如果你想看 OmniInfer 在桌面端怎么落地,可以看 OmniStudio:
https://omnimind.com.cn/omnistudio
我理解 OmniStudio 更像是一个面向普通用户的本地模型工作台。它背后使用 OmniInfer 做本地推理层,让用户可以在 Windows、macOS 等桌面平台上更直观地使用本地模型。
官网里提到的几个点我觉得挺有代表性:
- 本地部署,数据不需要默认发到云端;
- 支持多平台;
- 兼容 OpenAI API;
- 可以做模型管理和本地推理;
- 可以把本地 OmniInfer Server 暴露成可远程访问的 API 服务;
- 更适合不想天天碰命令行的用户。
说白了,如果 OmniInfer 是“发动机”,那 OmniStudio 就是更靠近用户的一层“驾驶舱”。
你不一定要关心后端是怎么选的、服务怎么起的,先把模型用起来,这就很重要。
我觉得这类桌面端 Demo 的意义在于:它证明 OmniInfer 不是停留在命令行工具层面,而是可以真正支撑一个完整产品。
Demo 2:安卓端的 OpenOmniBot
另一个我觉得更有意思的是 Android 端的 OpenOmniBot:
https://github.com/omnimind-ai/OpenOmniBot
这个项目目前已经有 1.5k stars,社区活跃度也不错。对一个移动端本地 AI 项目来说,这个关注度不算低。
OpenOmniBot 的价值在于,它把“端侧本地推理”这件事做得更具体了。不是只说“未来 AI 会跑在手机上”,而是真的把本地模型、移动端应用、语音/助手类体验这些东西串起来。
我自己比较关注 Android 端,是因为手机是最贴近用户的设备。
如果本地模型能在手机上稳定跑起来,很多场景就会变得很自然:离线助手、隐私问答、个人知识库、端侧 Agent、语音交互等等。
当然,手机端算力和内存有限,不可能什么模型都无脑塞进去。但正因为有限,底层推理框架的适配能力才更重要。OmniInfer 在这里就更像是基础设施。
为什么我觉得 OmniInfer 值得关注
我觉得它有几个比较实际的优点。
第一,它不是只做一个 UI。
UI 可以换,但推理层、后端适配、API 服务这些东西才是长期要沉淀的。
第二,它尽量统一了多平台体验。
Windows、macOS、Linux、Android、iOS,每个平台都有自己的坑。能把这些坑用一套项目管理起来,本身就很有价值。
第三,它保留了开发者友好的接口。
OpenAI-compatible API 这一点很实用。很多已有工具可以比较自然地接进来,不用为了本地模型重写一堆调用逻辑。
第四,它已经有实际产品和 Demo。
OmniStudio 和 OpenOmniBot 说明它不是一个“只能跑 hello world 的底层库”,而是已经在桌面端和 Android 端做了应用验证。
第五,它让本地模型不再局限在“本机使用”。
通过 OmniInfer Server、Base URL 和 API Key,本地模型可以被其他设备、其他工具,甚至远程环境调用。这个能力对我来说很有想象空间。
适合哪些人试试?
如果你是下面几类人,我觉得可以试一下:
- 想在本地跑大模型,但不想被环境配置折腾太久;
- 想把本地模型接到自己的工具、脚本或应用里;
- 想在 Windows / macOS / Linux 之间保持相对统一的调用方式;
- 对 Android 端本地 AI 感兴趣;
- 想研究 OpenAI-compatible 本地推理服务;
- 想把家里或办公室的模型服务变成自己的私有 AI API;
- 想做一个自己的本地 AI 助手或端侧 Agent。
如果你只是偶尔聊天,可能直接用成熟的桌面应用就够了。
但如果你想把本地模型能力接到自己的工作流里,OmniInfer 这种“推理底座”的价值会更明显。
一个小小的使用感受
我个人最喜欢的是它的方向:
不要让用户一直关心后端细节,而是让模型尽快在合适的设备上跑起来。
本地 AI 生态现在还比较碎。模型格式、推理框架、硬件平台、API 协议,每一层都有不少选择。OmniInfer 做的事情,就是尽量把这些碎片整理成一个可复用的运行层。
这件事不花哨,但挺重要。
最后
OmniInfer 不是那种一眼看上去特别“炫”的项目,它更像是一个底层能力项目。
但如果你真的折腾过本地模型,就会知道:底层能力稳定、跨平台、接口统一,比单纯多一个聊天窗口更有意义。
如果你对本地 AI、端侧推理、多平台模型应用感兴趣,可以看看这几个链接:
- OmniInfer: https://github.com/omnimind-ai/OmniInfer
- OmniStudio: https://omnimind.com.cn/omnistudio
- OpenOmniBot: https://github.com/omnimind-ai/OpenOmniBot
我感觉本地 AI 接下来会越来越重要,而 OmniInfer 这种项目,正好踩在“从能跑起来,到真正能用起来”的中间位置。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)