在高通跃龙IQ-9100平台上部署RAGflow(1): 系统架构与环境准备
1. 引言
检索增强生成(Retrieval-Augmented Generation,RAG)已成为企业知识问答和智能搜索系统的核心范式。RAGflow是一款领先的开源RAG引擎,融合了深度文档理解、智能分块、多路召回和融合重排序等能力,为LLM提供高质量的上下文层。
高通跃龙IQ-9100是一款面向边缘/本地部署场景的AI推理设备,内置Hexagon NPU,支持通过Qualcomm AI Engine Direct和ONNX Runtime进行高效的模型推理。将RAGflow部署在IQ-9100平台上,可以实现数据不出局域网的隐私安全RAG方案,同时借助NPU加速Embedding和Rerank模型推理,显著降低延迟和功耗。
本文将详细介绍如何在高通跃龙IQ-9100上安装部署RAGflow,并配置本地Embedding和Rerank模型。
2. 整体系统架构
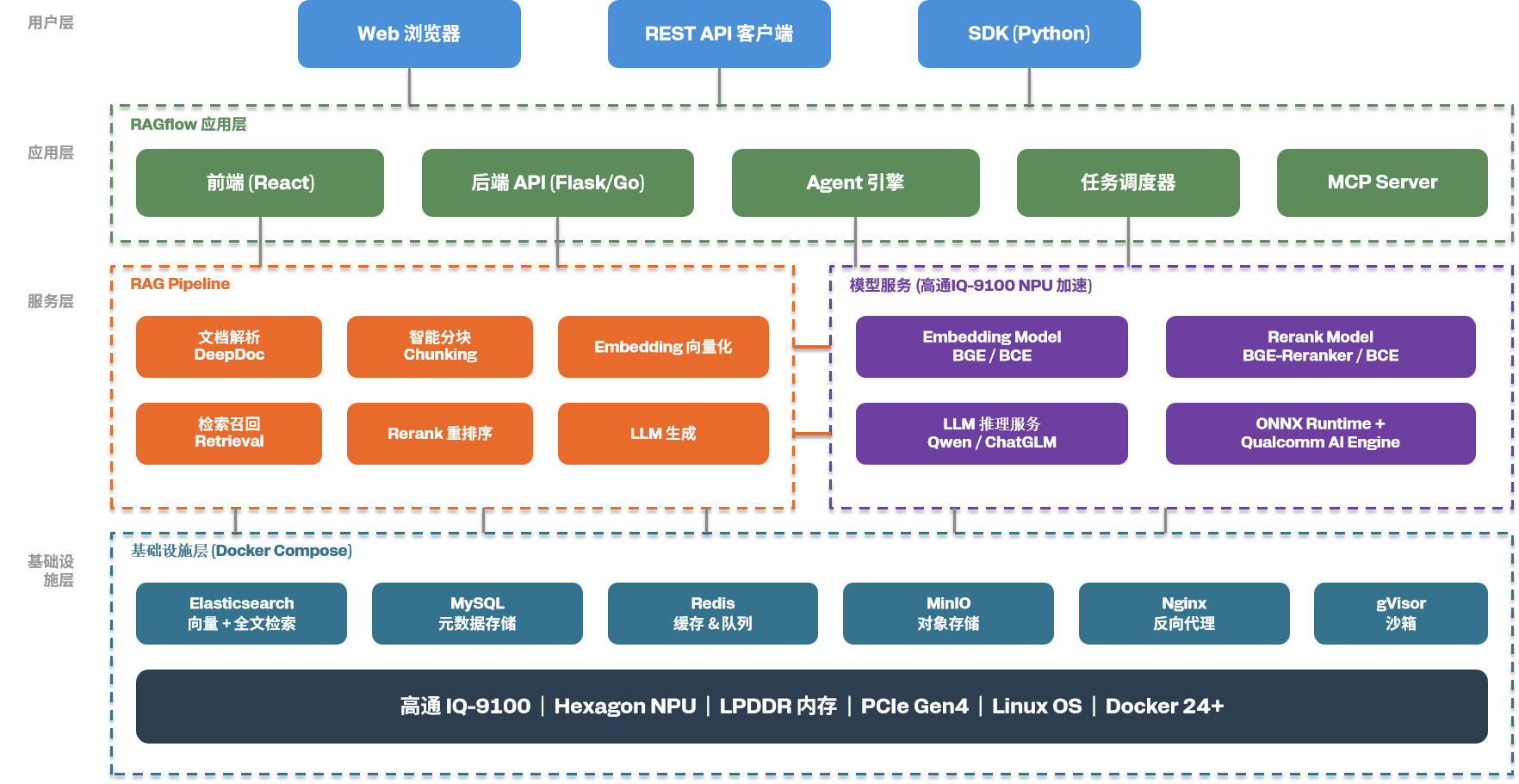
整个系统分为四层架构:
| 层级 | 组件 | 说明 |
|---|---|---|
| 用户层 | Web 浏览器 / REST API / Python SDK | 用户通过多种方式访问 RAGflow |
| 应用层 | RAGflow 前端 (React) + 后端 (Flask/Go) + Agent 引擎 + 任务调度器 | 核心应用逻辑 |
| 服务层 | RAG Pipeline + 模型服务 (IQ-9100 NPU 加速) 文档解析→分块→Embedding→检索→Rerank→生成 |
核心服务层 |
| 基础设施层 | Elasticsearch + MySQL + Redis + MinIO + Nginx + Docker | 存储、缓存、代理等基础组件 |
底层硬件为高通跃龙IQ-9100,搭载Hexagon NPU、LPDDR内存、PCIe Gen4接口,运行Linux操作系统和Docker (24+) 容器运行时。

3. Embedding & Rerank 模型推理架构
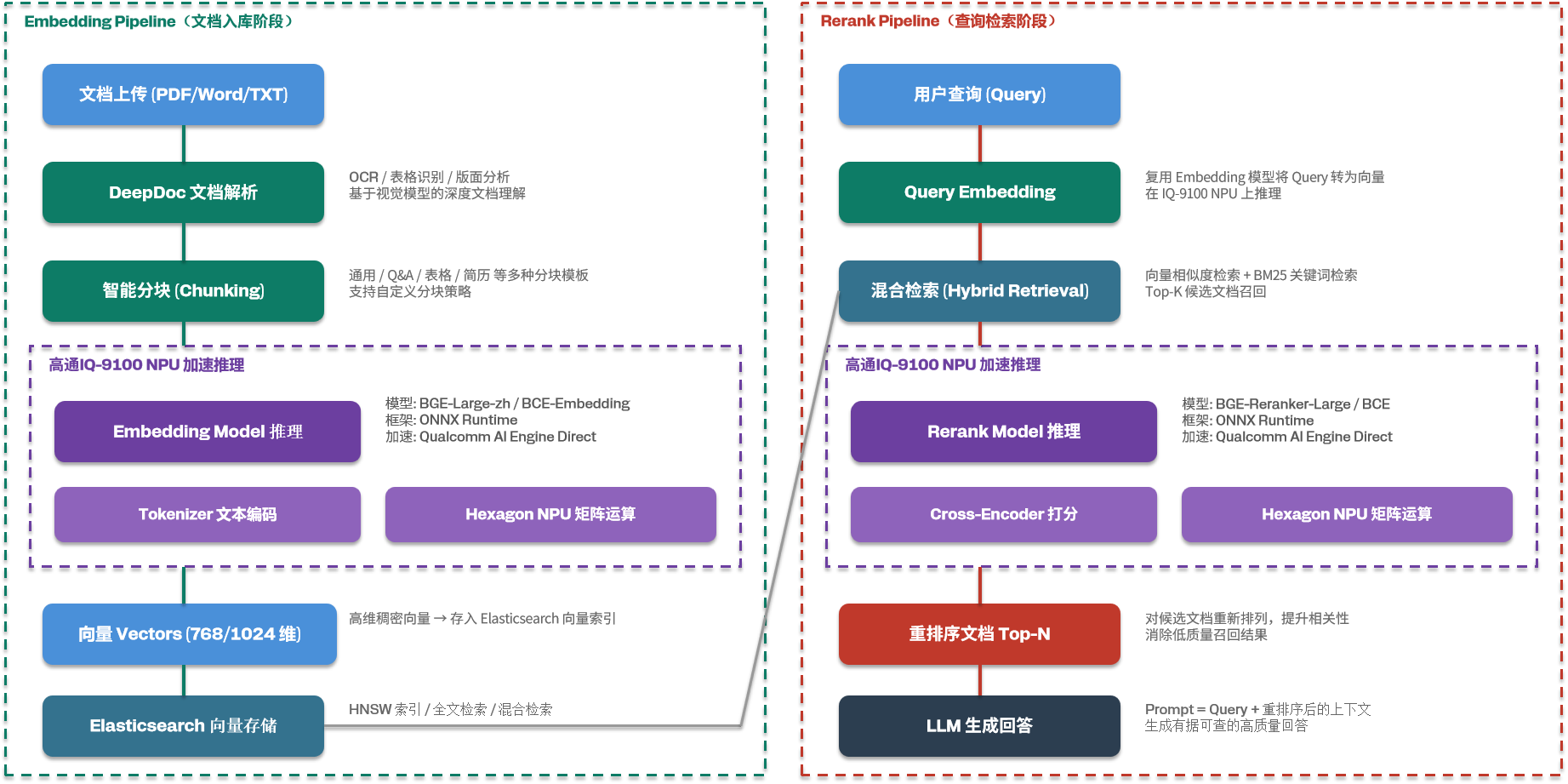
3.1 Embedding Pipeline(文档入库阶段)
文档上传 → DeepDoc 解析 → 智能分块 → Embedding 模型推理(NPU) → 向量输出 → Elasticsearch 存储
- Embedding 模型:推荐使用 BGE-Large-zh 或 BCE-Embedding-Base,输出 768/1024 维稠密向量
- 推理框架:ONNX Runtime + Qualcomm AI Engine Direct Execution Provider
- NPU 加速:Tokenizer 文本编码在 CPU 执行,矩阵运算卸载至 Hexagon NPU
3.2 Rerank Pipeline(查询检索阶段)
用户查询 → Query Embedding → 混合检索(向量+BM25) → Rerank 模型推理(NPU) → 重排序 Top-N → LLM 生成
- Rerank 模型:推荐使用
BGE-Reranker-Large或BCE-Reranker-Base,采用 Cross-Encoder 架构 - 推理方式:将 Query 和每个候选文档拼接为
[CLS] query [SEP] document [SEP],输出相关性打分 - NPU 加速:Cross-Encoder 的 Transformer 注意力计算在 Hexagon NPU 上完成
4. 部署流程概览
从环境准备到系统验证的完整部署步骤:
- 环境准备:检查IQ-9100硬件与驱动
- 部署RAGflow基础服务(Docker Compose)
- 部署Embedding模型服务
- 部署Rerank模型服务
- 配置RAGflow连接本地模型
- 验证部署
5. 详细部署步骤(基础部分)
5.1 环境准备
5.1.1 硬件检查
确认IQ-9100设备已正确连接并被系统识别:
# 检查 IQ-9100 NPU 设备
lspci | grep -i qualcomm
# 确认 Qualcomm AI 驱动已加载
lsmod | grep qaic
# 查看设备详情
cat /sys/class/accel/accel0/device/status
5.1.2 安装 Docker
# 安装 Docker Engine
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
# 安装 Docker Compose 插件
sudo apt-get install docker-compose-plugin
# 验证版本
docker --version # >= 24.0.0
docker compose version # >= v2.26.1
# 将当前用户加入 docker 组(免 sudo)
sudo usermod -aG docker $USER
newgrp docker
5.1.3 系统参数配置
# 检查 vm.max_map_count
sysctl vm.max_map_count
# 如果小于 262144,临时设置
sudo sysctl -w vm.max_map_count=262144
# 永久设置(写入 /etc/sysctl.conf)
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
sudo sysctl -p
5.2 部署 RAGflow
5.2.1 克隆仓库
cd ragflow
git checkout v0.25.0 # 使用稳定版本
5.2.2 配置环境变量
编辑 docker/.env 文件:
cd docker
# 基础配置
SVR_HTTP_PORT=80
MYSQL_PASSWORD=your_secure_password_here
MINIO_PASSWORD=your_minio_password_here
# 文档引擎(默认 Elasticsearch,也可选 Infinity)
DOC_ENGINE=elasticsearch
# 指定设备类型(CPU 模式,模型推理由外部 IQ-9100 服务处理)
DEVICE=cpu
5.2.3 启动服务
# 使用 Docker Compose 启动所有服务
docker compose -f docker-compose.yml up -d
# 查看启动日志
docker logs -f docker-ragflow-cpu-1
等待出现以下输出确认启动成功:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
注意:以上完成了RAGflow基础服务的部署。下一步需要单独部署Embedding和Rerank模型服务,并在RAGflow中配置接入。
👉 由于篇幅有限,部署Embedding模型、Rerank模型及配置验证等内容请阅读本系列下篇。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)