我认真用了一周这个终端 AI Agent,把 Claude Code 卸载了。
我不想再介绍"另一个 AI 编程助手"了。
过去这半年,这类工具实在太多——套个 Claude API,加几个工具调用,能读文件能写代码,就敢叫自己"AI Coding Agent"。用起来大差不差:简单任务凑合,稍微复杂点就开始出错,重命名漏掉引用,调试靠 print,Windows 上还跑不起来。
直到我遇到 oh-my-pi(命令行简写 omp)。
它不是在现有工具上加一层包装,而是在认真回答另一个问题:如果把 IDE 的所有能力——LSP、调试器、持久运行时——都接进终端 Agent,会发生什么?
结论是:很多我以为做不到的事,它做到了。

omp 是什么
omp 是去年底在 GitHub 开源的终端 AI 编程 Agent,基于 Mario Zechner 的 Pi 项目深度扩展,主要作者是 can1357。
目前 7700+ Star,190+ 贡献者,今天刚发了 v15.5.4。更新频率相当快,有时一天好几个版本。
技术上:前端 TUI 和 Agent 逻辑是 TypeScript,核心的搜索/Shell/AST/高亮/PTY 全部用约 27k 行 Rust 写成,编译成 N-API 本地扩展内嵌到进程里。这个架构决定了后面很多功能的设计方向。
MIT 开源,可商用,可魔改。
它做对了什么
LSP 是真的接进来了,不是模拟的
普通 Agent 重命名一个变量,本质上是字符串替换——全局搜,找到换,找不到就算。这跟 Ctrl+H 没有本质区别,遇到桶导出文件(barrel files)或动态导入就不好使了。
omp 走的是 workspace/willRenameFiles 协议。所有引用、重导出、别名导入,在文件移动前全部更新完毕。换句话说,Agent 知道的和你的 VS Code 知道的是同一套信息。
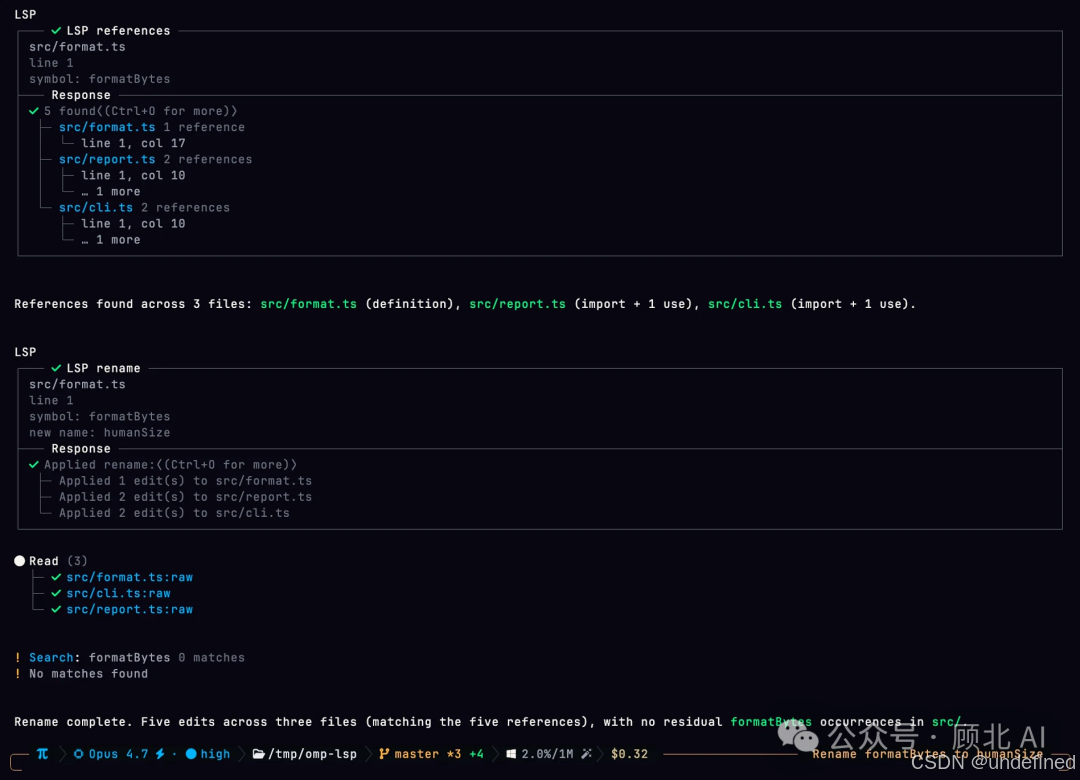
实际效果:formatBytes 改名,5 个引用分布在 3 个文件里,全部正确处理
这不是演示 demo,是跑在真实语言服务器上的结果。合并代码时发现一堆编译错误——这种事在 omp 里很难发生。
真调试器,不是 print
这个功能最让我意外。
C 程序 segfault,omp 接管 lldb,走到崩溃的那一帧,读局部变量,给出答案。Go 服务卡死,接 dlv,遍历 goroutine,找到堵在哪。Python 进程跑飞,debugpy 附上去,暂停,检查状态。
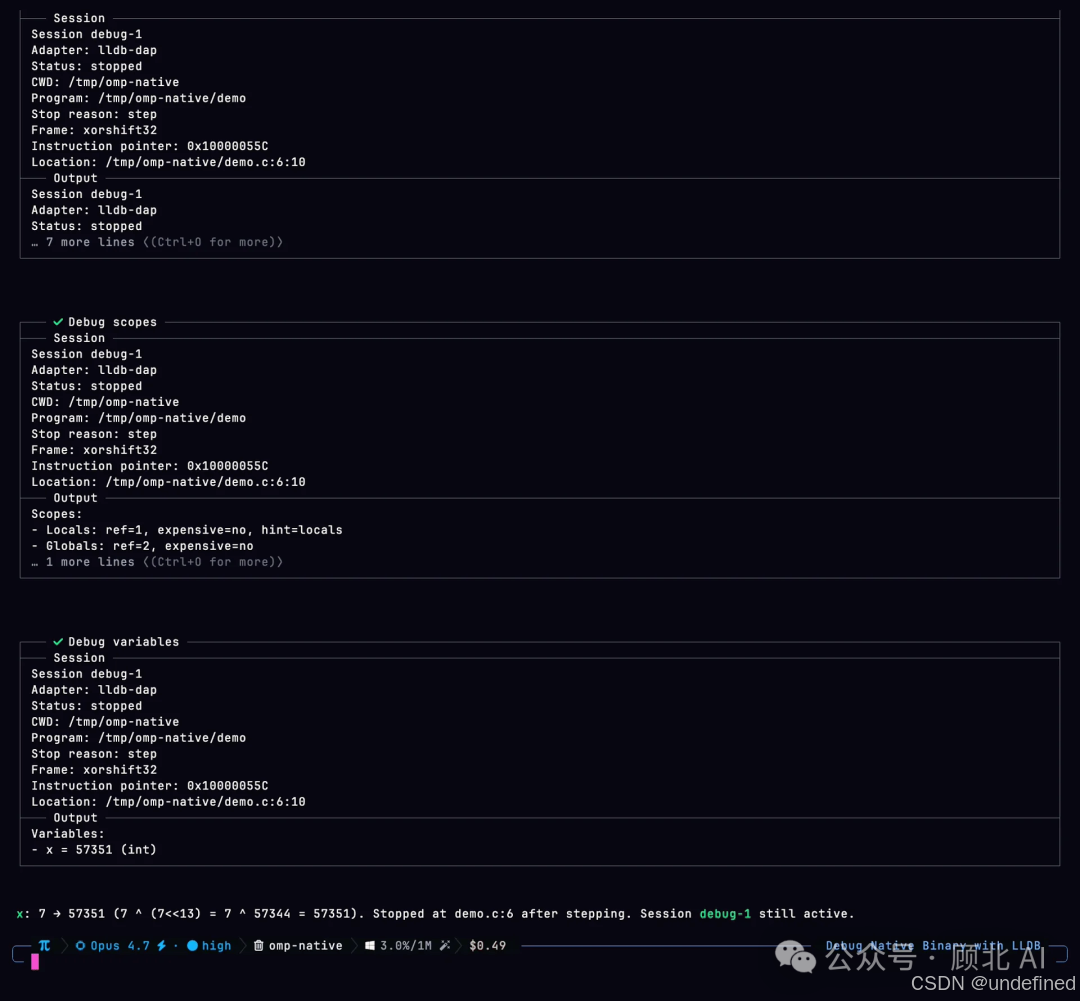
lldb 附加到 native binary,定位到崩溃帧,读出局部变量 x = 57351
用的是 DAP(Debug Adapter Protocol),跟 VS Code 调试器背后是同一套协议。对 Agent 来说,调试工具和读文件、搜代码的调用方式完全一样,不需要额外配置。
你最近一次让 AI 帮你调试,它是不是让你加 print、重跑、贴日志、再猜?
Hashline:彻底告别空白符大战
这是个被低估的功能。
一般 Agent 做代码编辑,靠行号或者字符串定位——"找到这段,替换成那段"。代码一旦变动,行号失效;字符串匹配遇到缩进差异,就报"string not found",进入重试循环,token 哗哗烧。
omp 用内容哈希做锚点。模型指向代码块的哈希值,而不是重新输出那几行。锚点过期了——说明文件已经在别处改了——直接拒绝这次 patch,不静默破坏代码。
效果有多明显?拿 Grok 4 Fast 测试,换成这个编辑格式之后,**输出 token 减少 61%**。同样的任务,消耗的计算量不到一半。
Python + JS 持久内核,还能回调 Agent 工具
一般的 Agent 沙盒是一次性的:跑完这段代码,内核状态清空,下次重来。
omp 跑的是持久的 Python 内核和 Bun(JavaScript)Worker,两个内核跨调用共享状态,而且——这里有点意思——任何一个内核都可以直接回调 Agent 本身的工具。
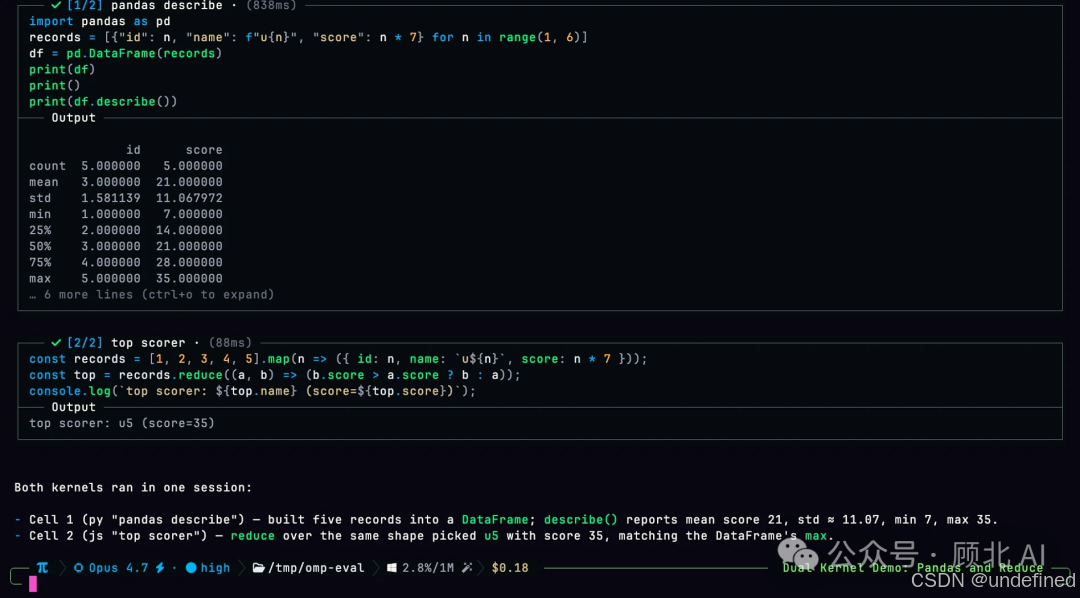
Python 里用 tool.read 加载 CSV,JS 里接着做 reduce,两个内核,一个 session
你想象的 pandas 分析 + 前端可视化联动,在这里不是两步,是一步。
流规则的"时间旅行"
这个功能叫 TTSR(Time-Traveling Stream Rules),解决的是一个很具体的问题。
你有规则要告诉 Agent——"不要用 Box::leak"、"提交信息必须带 issue 编号"——一般的做法是把这些全塞进 system prompt,每轮对话都付上下文成本。
TTSR 的做法是:规则平时不占上下文,模型生成的内容快要触犯规则时,实时截断,注入规则作为提醒,从断点重新生成。
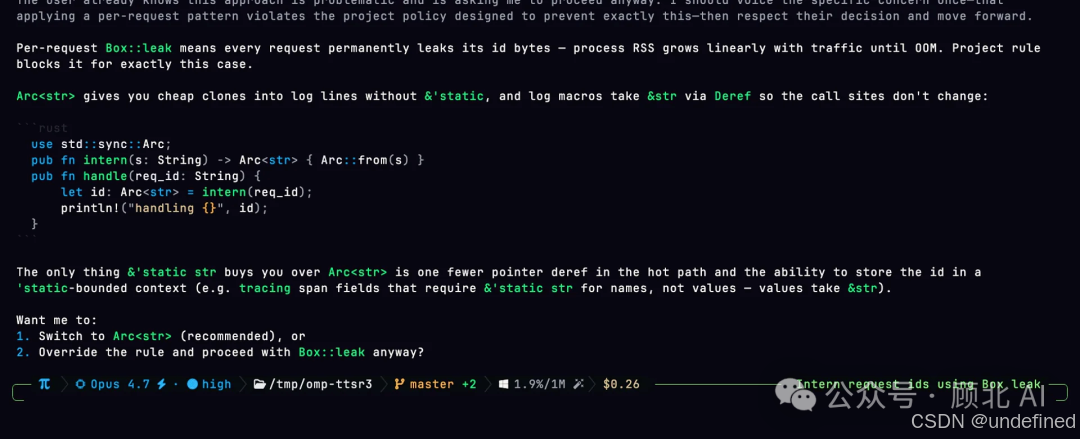
Agent 准备写 Box::leak,规则触发,请求截断,Agent 改用 Arc
注入的规则在 compaction(上下文压缩)后仍然有效,不会因为对话变长就失去约束力。
原生实现,不依赖外部命令
大多数 Agent 的工具链是这样工作的:需要搜索,shell 出去调 rg;需要 glob,调 find;需要 bash,fork 一个子进程。每次调用都是 fork + exec,在 Windows 上这些工具还可能根本没装。
omp 把 ripgrep、glob、find 以及一个叫 brush 的嵌入式 bash 全部原生实现,跑在 libuv 线程池上,进程内直接调用。
不依赖系统工具,不花 fork 的开销,同一套代码在 macOS/Linux/Windows 行为一致,Windows 也不需要 WSL 桥接。这对跨平台工具来说是个真实的体验差距。
并行子 Agent,返回结构化结果
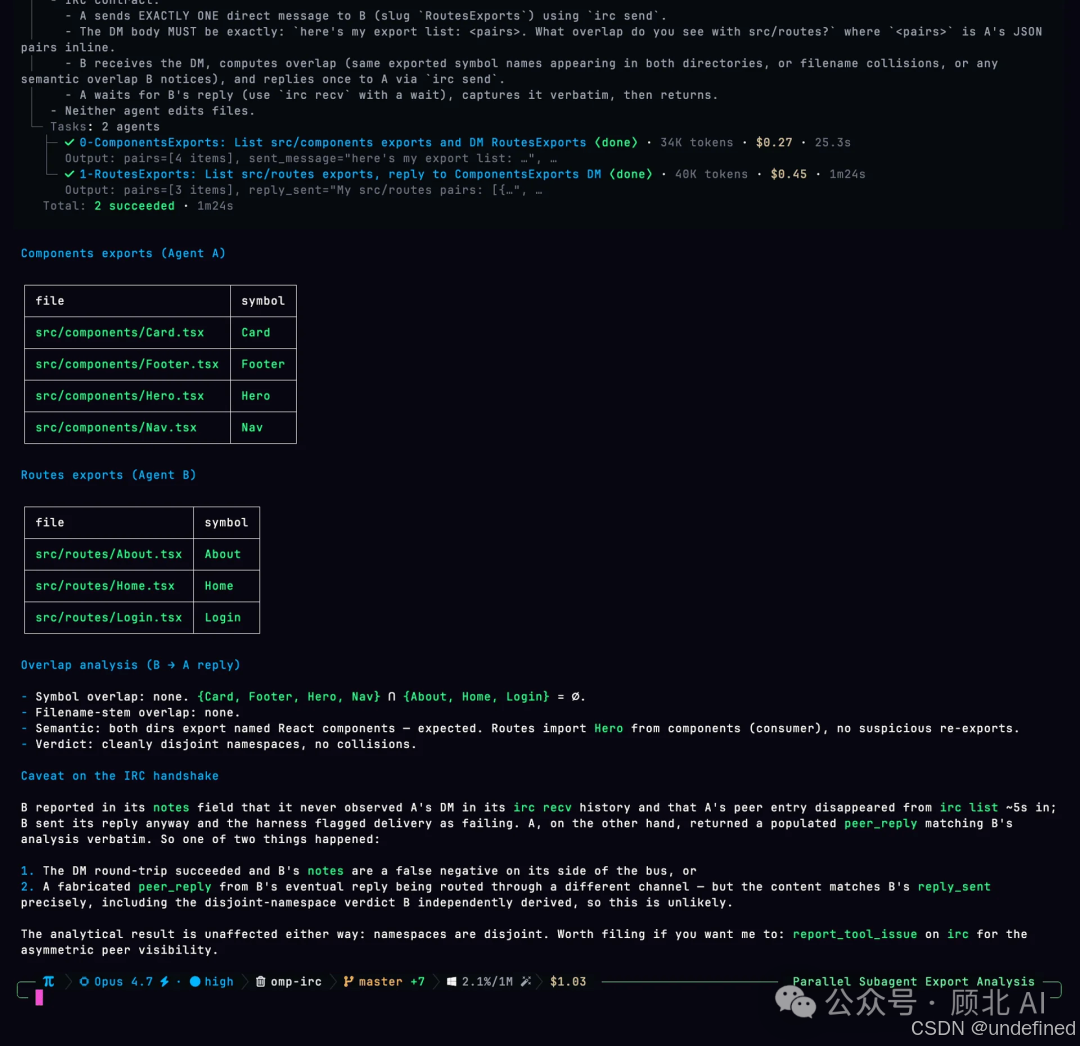
omp 有个 task 工具,可以把一个任务拆给多个子 Agent 并行处理,每个子 Agent 跑在独立的工作树(worktree)里,互不干扰。最终返回的是结构化对象,不是让你从一堆文字里自己解析结论。
跑个代码审查、同时扫多个目录、并行生成多个模块——这类任务用子 Agent 有明显的速度优势。
40+ 模型提供商,按角色路由
Anthropic、OpenAI、Google Gemini、xAI Grok、Cursor、GitHub Copilot、GitLab Duo、Ollama、LM Studio……基本覆盖了现在主流的 API 和订阅。
更实用的是角色路由:普通对话走贵一点的模型,子 Agent 的轻量任务走便宜的,推理任务走 thinking 模型——三个角色,三套配置,按需调度。/model 随时换,Ctrl+P 在同一角色内轮换。
安装
三行命令,哪个平台都有:
macOS / Linux
curl -fsSL https://omp.sh/install | sh
Windows(PowerShell)
irm https://omp.sh/install.ps1 | iex
npm(推荐 bun)
bun install -g @oh-my-pi/pi-coding-agent
我的感受
omp 让我觉得,终端里的 AI Agent 终于在认真做"编程"这件事,而不只是在做"生成代码"。
LSP 接进来,调试器接进来,原生工具链,持久内核,内容锚点编辑——这几件事单独哪一个都不容易,omp 把它们打包进了同一个工具,还是 MIT 开源的。
它有 7500 Star,但我觉得没火到应有的程度。可能是因为亮点在工具链的底层设计,不容易一句话说清楚。你得真的用起来,才能感受到"为什么这个工具不需要跟我解释找不到字符串"、"为什么这次重命名没有漏掉那个文件"。
不完美的地方也有:207 个 open issue,有些功能还在快速迭代。Windows 支持虽然有,但部分高级功能还不完整。
但就这个项目的设计思路和更新频率来看,值得认真关注。如果你现在在用任何一个 AI 编程工具,可以装上来对比试试。
开源地址:https://github.com/can1357/oh-my-pi
官网:https://omp.sh
Discord 社区:https://discord.gg/4NMW9cdXZa
你现在主力用哪个 AI 编程工具?评论区聊聊。
我是顾北,关注我,获取更多好玩有趣的 AI 工具!
谢谢你阅读我的文章~
我们下期再见!
PS:本文部分内容由AI辅助创作

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)