从 Grad-CAM 出发:我发现 CNN 其实只在看局部纹理
最近在做 UC Merced 遥感场景分类实验,一开始只是想简单跑一下ResNet50,看看这个模型的能力怎么样,分类结果如何。但是跑完后注视着 accuracy 也不知道能看出来个啥,心里只想着“哇,居然高达90%多”。于是我开始思考:这个模型到底在看什么,它到底是基于什么对图像进行分类的?后面查阅了大量资料,并在ChatGPT的帮助下,使得我对ResNet模型有了更深入的了解,所以我想写一篇文章主要记录一下我从 “models.resnet50()” 一路到
Grad-CAM
Feature Map
CBAM Attention
模型空间特征分析
的整个学习过程。
一、项目背景
UC Merced 是一个经典遥感场景分类数据集。包含 airplane、harbor、forest、river、runway 等21个类别,每类100张图像。我这里使用 ResNet50、ImageNet预训练、PyTorch 完成分类任务。
二、一开始其实只想“跑通”
最开始的时候,我其实对 ResNet50 并不理解。甚至:
layer1
layer2
layer3
layer4
到底是什么我都不知道。只是会:
model = models.resnet50(weights= models.ResNet50_Weights.DEFAULT)
然后训练。但后来我发现,如果只会调用模型,根本不能真正理解深度学习,没有太大意义。所以我后面开始一点点分析:
- tensor shape
- residual block
- feature map
- Grad-CAM
整个过程其实比单纯调包有意思很多。
三、先看一下 baseline 效果
这里是我使用 ResNet50 的训练结果:

整体 accuracy 其实已经不低。但我后来发现,accuracy 并不能说明一切。
四、混淆矩阵
我开始看混淆矩阵,看看模型的预测结果到底怎么样,如图所示:
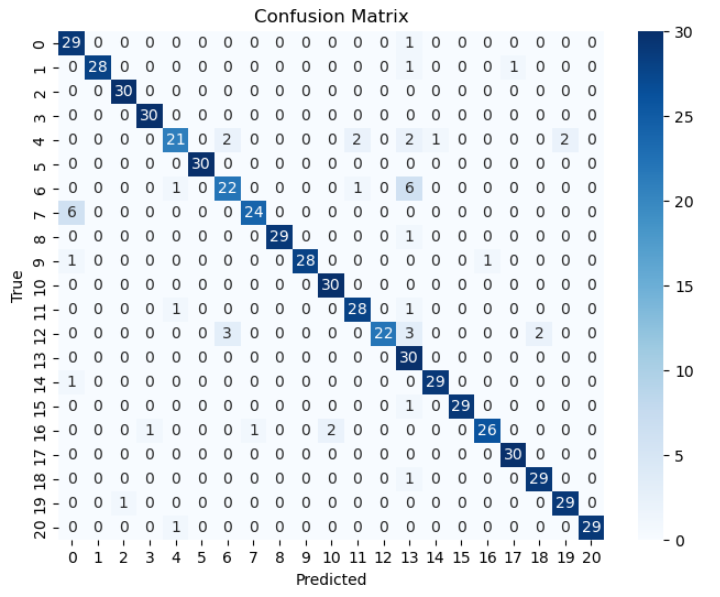
我发现有些类别非常容易混淆,比如:
- airplane ↔ storagetanks
- dense residential ↔ medium residential
这不禁让我开始思考:CNN到底是怎么看出来的,它究竟是在关注图像的什么地方来做出判断的。
五、Grad-CAM
后来我开始尝试 Grad-CAM 可视化,并详细阅读了Grad-CAM简介(我觉得这位博主说得通俗易懂,非常佩服),说实话第一次看到的时候有些震惊,因为我第一次真正看到模型到底在关注哪里,比如:




上图中左图是原图像,右图是Grad-CAM可视化之后的热力图,并且均是模型预测错的图像,反复观察后发现很多情况下模型好像只关注局部区域,例如在 airplane 分类里:模型可能只看到:
- 一个亮区域
- 一个边缘
- 一小块纹理
就将其预测为 airplane,而不是看到完整的飞机结构,这也就导致模型很容易分不清同样具有该特征的图像,如 storagetanks。
后来我开始查阅资料和文献,理解到卷积本身其实就是局部感受野,也就是说模型天然更容易学习局部纹理、边缘等特征,而不是全局空间关系。尤其遥感图像很多类别之间纹理和颜色都相似,所以在这上面CNN的局限性就暴露了出来。
六、尝试加入 CBAM
于是我开始思考有没有什么办法能够缓解这种症状,后来在ai的帮助下我接触到 attention,并开始查阅资料理解 CBAM(Convolutional Block Attention Module),其结构如图所示:
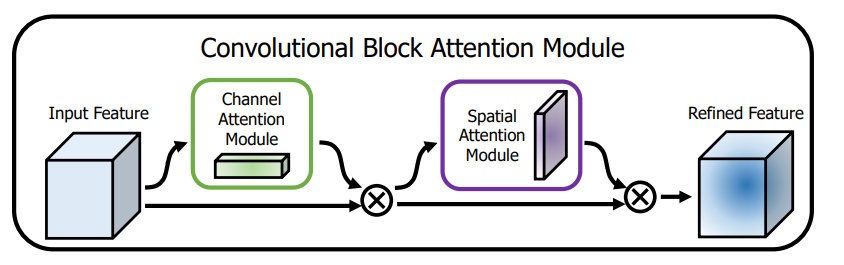
其核心其实就是 Channel Attention Module 和 Spatial Attention Module 两个子模块。其中,Channel Attention Module 主要关注“什么特征更重要”,Spatial Attention Module 主要关注图像的哪些位置更重要。(原论文地址:https://arxiv.org/abs/1807.06521)在仔细阅读两个模块的工作机理后,我自己手写了一个代码来实现,也是为了检测自己到底有没有真正理解。并且考虑到特征图经过layer4之后已经是高级语义特征,于是我将 CBAM 插入到l ayer4 和 avgpool 层之间,如图:
import torch.nn as nn
import torch
from torchvision import models
class CBAM(nn.Module):
def __init__(self, channels, kernel_size=7, reduction=16):
super().__init__()
# 首先将输入的feature map经过两个并行的MaxPool层和AvgPool层
self.channel_maxpool = nn.AdaptiveMaxPool2d(1)
self.channel_avgpool = nn.AdaptiveAvgPool2d(1)
# 激活函数Sigmoid
self.sigmoid = nn.Sigmoid()
# Share MLP模块
self.MLP = nn.Sequential(
nn.Conv2d(channels, channels//reduction, kernel_size=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channels//reduction, channels, kernel_size=1, bias=False)
)
# Channel Attention Module模块的卷积运算
self.spatial_conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size//2, bias=False)
# 前向传播
def forward(self, x):
# Channel Attention
channel_maxpool = self.MLP(self.channel_maxpool(x))
channel_avgpool = self.MLP(self.channel_avgpool(x))
channel_out = self.sigmoid(channel_maxpool+channel_avgpool)
x = channel_out * x
# Spatial Attention
out_max, _ = torch.max(x, dim=1, keepdim=True)
out_avg = torch.mean(x, dim=1, keepdim=True)
spatial_out = self.sigmoid(self.spatial_conv(torch.cat((out_max, out_avg), dim=1)))
x = spatial_out * x
return x
class resnet50_cbam(nn.Module):
def __init__(self, num_classes=21):
super().__init__()
# 加载resnet50
backbone = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
self.conv1 = backbone.conv1
self.bn1 = backbone.bn1
self.relu = backbone.relu
self.maxpool = backbone.maxpool
self.layer1 = backbone.layer1
self.layer2 = backbone.layer2
self.layer3 = backbone.layer3
self.layer4 = backbone.layer4
# 插入CBAM
self.cbam = CBAM(backbone.fc.in_features)
self.avgpool = backbone.avgpool
self.fc = nn.Linear(backbone.fc.in_features, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.cbam(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x加入CBAM后的网络结构如下图所示:
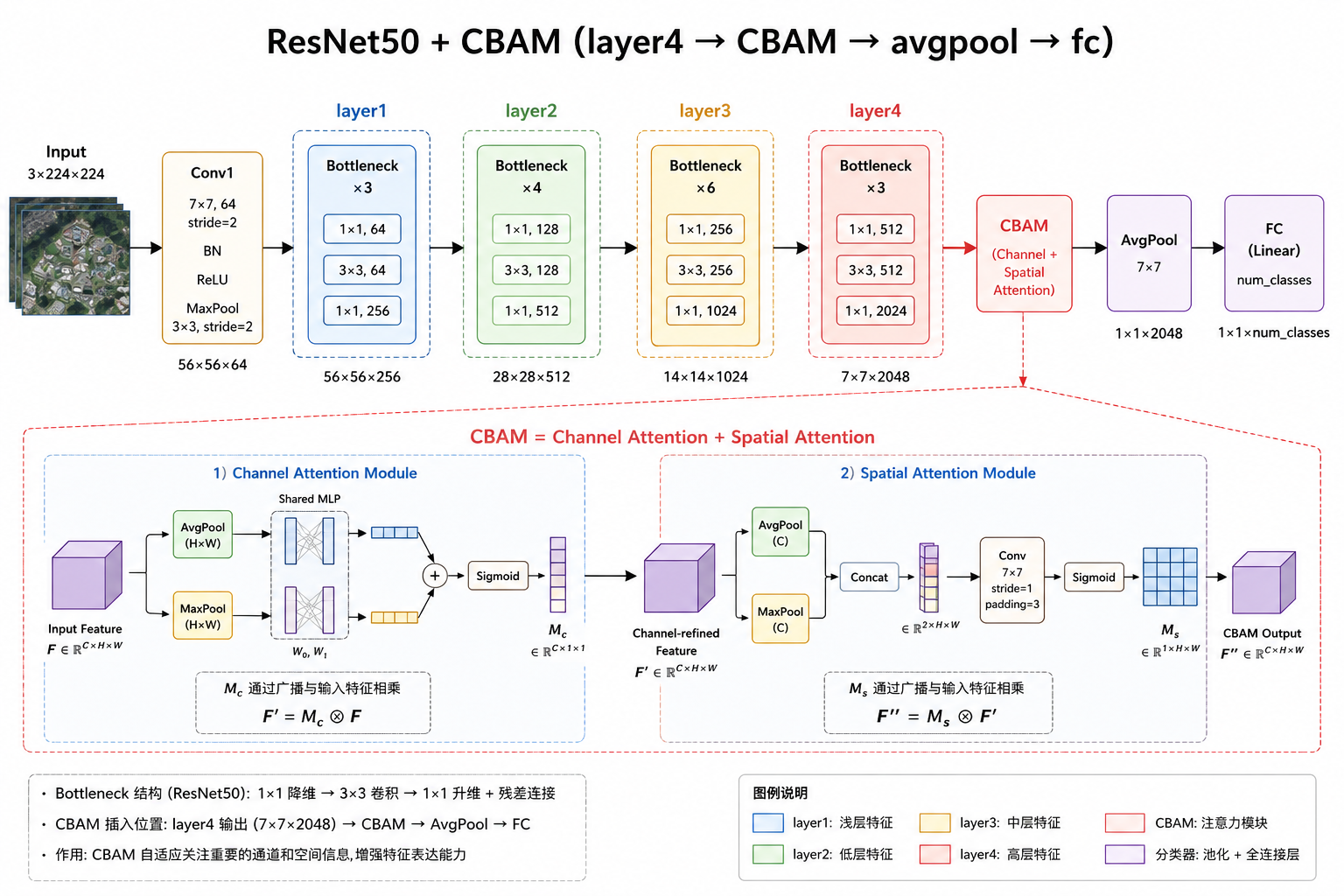
这也让我对 tensor 在不同的 Attention 模块里到底是怎么变化的有了更深刻的印象。模型重新建立完成后我重新开始了训练,结果显示 accuracy 相差不大,但是相比于 baseline,模型关注的区域明显变化了,如下图所示(左图为 resnet50,右图为 resnet50_cbam):

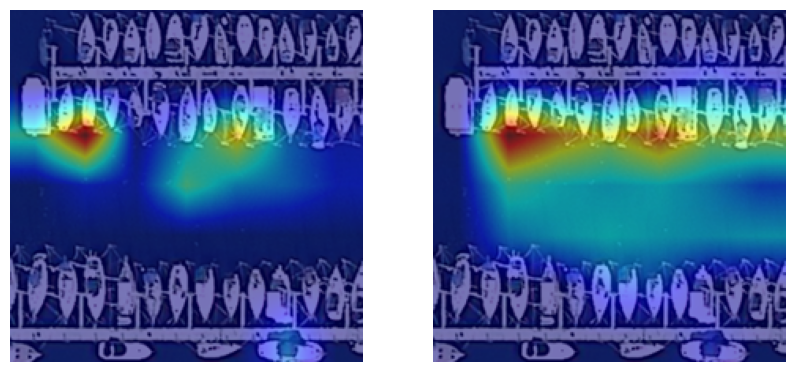

由此可见,在进行 CBAM 操作后模型关注的区域变得全局了不少,并且关注的地方也渐渐正确了一点。
七、Feature Map可视化
当时为了弄清楚模型到底在学些什么东西,我打印出了耕地图像分别经过resnet50模型的layer1、layer2、layer3、layer4后的部分特征图,如下图所示:
layer1:
layer2:
layer3:
layer4:


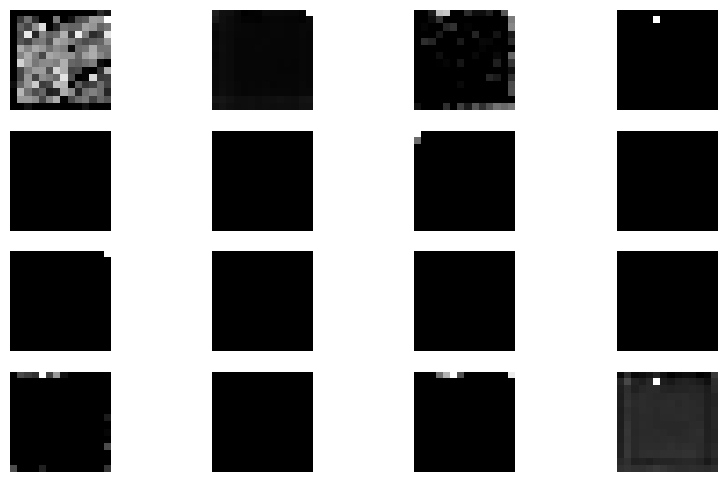

起初经过layer1和layer2后的特征图我还觉得比较正常,但是经过layer3,特别是layer4之后,我发现经过layer4的特征图变得一片黑,后面深入理解CNN后,才知道这是正常现象。因为随着网络层数的加深,特征图的空间分辨率会逐渐降低、通道数逐渐增加、感受野不断增大,以及特征信息从低级细节(边缘、颜色、纹理)向高级语义(物体部件、场景类别)转变。
八、总结
通过这一个小项目我意识到了一些东西:首先深度学习绝不仅仅是跑通模型就够了,针对模型的性能好坏和实际业务的需求还需要我们能够发现问题、分析问题和解决问题;其次,我也真正开始理解了 CNN 到底怎么看图像、Attention到底在干什么、feature map到底是什么以及 Grad-CAM 的必要性。以前我只是跑通一个模型就过去了,现在我会开始思考模型为什么会这么预测,以及有了分析模型的一些手段,我觉得这对我来说是一个很大的变化。
最后我想说,虽然加入了 Attention 模块,但 CNN 对全局空间关系建模能力依旧有限,所以后续我准备继续探究:ViT、Swin Transformer、CNN 与 Transformer 的区别,看看 Transformer 是否真的更擅长遥感图像中的空间结构建模。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)