(五)揭秘 OpenDriveVLA:结构化感知如何“跨模态对齐”大模型?
导读:在《OpenDriveVLA的5类Prompt设计与跨模态特征注入机制》一文中,我们梳理了跨模态特征注入的基本流程。本文将切入该流程中最核心的两大环节:特征的对齐与拼接。面对多视角场景特征、动态目标的轨迹与地图结构化感知信息,模型如何跨越模态鸿沟,将其投影至 LLM 的语义空间?视觉 Embedding 又如何与离散的文本 Token 通过占位符机制,实现词序上的按位精确拼接?本文将为你深度拆解这套将感知信息“翻译”给大模型的对齐机制。
一、写在前面的话
正如知乎文章《自动驾驶 VLA 如何接入 BEV 等结构化输入》所指出的,VLA 落地自动驾驶的一大痛点在于:仅靠多视角原始图像,模型能“看见路”,却难真正掌握空间结构。因此,将 BEV、OD、OCC 等结构化感知接入大模型已成必然趋势。然而,这绝非简单的“多模态堆料”,而是在回答一个核心命题:怎样把车辆已构建的“空间世界模型”,精准翻译成大模型能理解和推理的 Token?
全盘塞入显然行不通——Token 预算有限,简单池化会压扁关键的空间关系,且感知侧的度量/实例空间与 LLM 的语义空间存在天然鸿沟。对此,Sparse Query(稀疏查询)机制成为了最值得重视的方向:与其把整张 BEV 或整块 OCC 全塞进去,不如先用 Query 把空间世界压成少量高价值 Token,只问几个关键问题——有哪些动态目标?哪些静态地图元素重要?哪些区域最影响规划?OpenDriveVLA 正是这一思路的典型代表,它通过分层提取与跨模态对齐,将视觉感知压缩为“结构化的场景记忆”,精准映射至 LLM 语义空间。
二、视觉特征到LLM语义空间的投影
直接把 BEV 网格或 OCC 体素按像素级铺平输入 LLM,会瞬间撑爆 token budget,且在投影过程中极易压扁空间关系。OpenDriveVLA 保留了 UniAD 的结构化感知架构,通过三大模块将 2D/3D 物理世界提炼为少量高价值的 Structured Token。可参考论文附录 A-2) Structural Token Extraction 小节。
2.1 Global Scene Sampler(全局场景采样)
为了捕捉基于 BEV 难以表征的全局上下文(如天气、光照、场景布局与交通流),该模块直接对 6 个相机视角的 2D 特征进行自适应最大池化,将其压缩为每视图 3×5 的空间网格,最终生成 90 个全局场景 Token。
img_feat_2D = result_track["img_feat_2D"] # [1, 6, 256, 15, 25]
img_feat_2D = img_feat_2D.squeeze(0) # [6, 256, 15, 25]
img_feat_2D = F.adaptive_max_pool2d(img_feat_2D, (3, 5)) # [6, 256, 3, 5]
img_feat_2D = img_feat_2D.flatten(2) # [6, 256, 15]
img_feat_2D = img_feat_2D.transpose(1, 2) # [6, 15, 256]
img_feat_2D = img_feat_2D.reshape(-1, 256) # [90, 256]
scene_feature = self.get_model().mm_projector_scene(img_feat_2D) # [90, 896]
Global Scene Sampler网络结构图如下: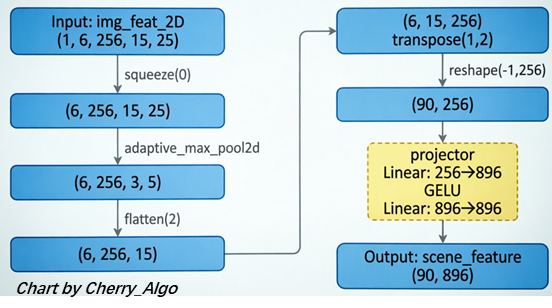
- token压缩:通过自适应池化提取关键区域,从 6×15×25=2250 个网格,压缩到 6×3×5=90 个 Token。在保留全局感受野的同时,大幅降低了计算压力。
- 模态对齐:通过 mm_projector_scene(Linear + GELU + Linear),把 256 维的视觉特征映射到 896 维的 LLM 词表空间,完成了从物理像素特征到大模型可读语义的“翻译”。
- 输出特征:[90, 896],代表全局场景的语义压缩信息。
2.2 Agent & Map QueryTransformer(动态目标、地图特征的结构化提取)
与全局场景的直接池化压缩不同,动态目标与地图元素具有更强的实例属性与结构化特征。OpenDriveVLA 沿用了 UniAD 的 Query 机制,通过可学习的 Query 向量从 BEV 特征中“主动查询”关键信息,实现从稠密特征到稀疏语义的精准提取。
track_query_embeddings = result_track["track_query_embeddings"] # [N_track, 256]
chosen_output_query_things = result_seg["chosen_output_query_things"]# [N_thing, 256]
output_query_stuff = result_seg['output_query_stuff'] # [1, 256]
map_seg_query_embeddings = torch.cat([chosen_output_query_things, output_query_stuff], dim=0)
... ...
track_feature = self.get_model().mm_projector_track(track_query_embeddings.to(dtype=img_feat_2D.dtype))
map_feature = self.get_model().mm_projector_map(map_seg_query_embeddings.to(dtype=img_feat_2D.dtype))
2.2.1 Agent QueryTransformer:动态目标的结构化提取
- 查询机制:基于 BEV 特征,将可学习的 Query 解码为动态目标级语义。每个 Token 编码了单个动态目标的空间位置、类别及运动轨迹。
- 置信度过滤:为提升效率与鲁棒性,基于检测分数过滤低置信度预测,仅保留 Top-Na 个 Token。这不仅减少了输入视觉 Token 的数量以加速推理,更有效抑制了不确定感知输入导致的“幻觉”。
2.2.2 Map QueryTransformer:静态地图的结构化提取
- 查询机制:同样基于 BEV 特征,采用类似 Panoptic Segmentation 的 Query 范式,用独立的解码头提取静态结构元素(包括 thing 和 stuff 类别),生成最多 Nm 个地图 Token,编码了车道线、道路边界、可行驶区域等关键静态要素信息。
seg_head=dict(
type='PansegformerHead',
... ...
num_query=300,
num_classes=4,
num_things_classes=3,
num_stuff_classes=1,
在配置文件(base_track_map.py)中,num_things_classes=3 是指:车道标线、人行横道和路牙三类;
num_stuff_classes=1 是指:可行驶区域。
三、文本与视觉嵌入特征的精准拼接
完成了视觉特征的嵌入(90 个 Scene Token,Na 个 Track Token,Nm 个 Map Token)之后,如何在不破坏文本语义连贯性的前提下,将多模态特征精准拼接进 LLM 的输入序列? OpenDriveVLA 项目中采用了占位符机制和按位置拼接策略,通过prepare_inputs_labels_for_multimodal_uniad_vlm 函数实现了这一序列重组过程。
3.1 特殊 Token 的定位与序列拆分
首先,在 Prompt 中预埋特殊占位符 <scene>、<track>、<map>,用于标记多模态特征的插入位置。正如论文附录 A 所述:
The input sequence passed to the LLM is structured as:<SYSTEM><SCENE><TRACK><MAP><EGO><COMMAND>
During input construction, <SCENE>, <TRACK>, and<MAP>are replaced with projected visual tokens, while <EGO> and <COMMAND> are filled with formatted textual strings.
代码实现上,首先遍历输入的 Token ID,收集所有特殊 Token 的位置索引,得到special_token_indices;然后以这些特殊 Token 为分割点,将原始序列切割为剔除特殊Token后的纯文本段cur_input_ids_nospecial。
# 收集所有特殊 Token 的位置
special_token_indices = [-1]
special_token_indices.extend(torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0].tolist())
special_token_indices.extend(torch.where(cur_input_ids == SCENE_TOKEN_INDEX)[0].tolist())
special_token_indices.extend(torch.where(cur_input_ids == TRACK_TOKEN_INDEX)[0].tolist())
special_token_indices.extend(torch.where(cur_input_ids == MAP_TOKEN_INDEX)[0].tolist())
# ... 其他 Token ...
special_token_indices.sort() # 排序确保插入顺序正确
special_token_indices.append(cur_input_ids.shape[0])
# 按这些位置将文本切分为多段
for i in range(len(special_token_indices) - 1):
cur_input_ids_nospecial.append(cur_input_ids[special_token_indices[i] + 1 : special_token_indices[i + 1]])
3.2 文本 Token 的嵌入转换
拆分完文本后,将这些离散的 Token ID 转换为连续的高维向量。
# 获得文本token的嵌入向量
split_sizes = [x.shape[0] for x in cur_labels_nospecial]
cur_input_embeds = self.get_model().embed_tokens(torch.cat(cur_input_ids_nospecial))
cur_input_embeds_no_special = torch.split(cur_input_embeds, split_sizes, dim=0)
self.get_model().embed_tokens 本质上是一个巨大的语义查询表, 可以将文字变成AI能看懂的高维向量。
输入:Token ID 序列cur_input_ids_nospecial,代表token在词表中的编号;
查表映射:将文本token映射为高维嵌入向量;
输出:对应的高维向量,[seq_len, embed_dim],包含了token的语义信息。文本嵌入向量与视觉嵌入特征具有相同维度
(都是 896 维)。
3.3 文本与视觉特征按位置拼接
得到分段后的文本嵌入,接下来就是最关键的“搭积木”环节:按顺序交替注入文本 Embedding 与视觉结构化特征 Embedding。
代码按切割点交替注入文本 Embedding 与视觉结构化特征 Embedding:
for i in range(len(special_token_indices) - 1):
# 注入纯文本段 Embedding
cur_new_input_embeds.append(cur_input_embeds_no_special[i])
cur_new_labels.append(cur_labels_nospecial[i])
# 判断下一位是否为特殊Token,若是则插入对应特征
token_type = cur_input_ids[special_token_indices[i + 1]]
if token_type == SCENE_TOKEN_INDEX:
cur_new_input_embeds.append(scene_feature) # [90, 896]
cur_new_labels.append(torch.full((scene_feature.shape[0],), IGNORE_INDEX, ...))
elif token_type == TRACK_TOKEN_INDEX:
cur_new_input_embeds.append(track_feature) # [Na, 896]
cur_new_labels.append(torch.full((track_feature.shape[0],), IGNORE_INDEX, ...))
elif token_type == MAP_TOKEN_INDEX:
cur_new_input_embeds.append(map_feature) # [Nm, 896]
cur_new_labels.append(torch.full((map_feature.shape[0],), IGNORE_INDEX, ...))
- 动态长度适配:每帧图像的有效目标数受阈值过滤影响,因此 Track/Map 的 Query 数量是动态的(Na、Nm不固定),拼接长度也随之变化。
- 按位置穿插拼接:这种按位置穿插拼接而非末尾追加的设计,比如当LLM 在读到文本“场景”二字时,紧接着读到的就是场景的视觉特征,上下文关系被完美保留。
3.4 维度推演示例
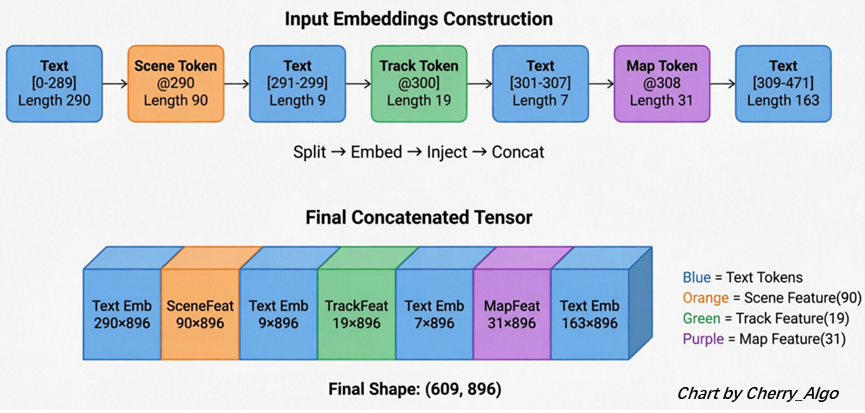
假设原始 Prompt 序列长度为 472,包含 3 个特殊 Token(各占 1 位):
- 移除:3 个特殊占位符 → 472 - 3 = 469
- 注入:90 (Scene) + 19 (Track) + 31 (Map) = 140
- 新序列总长:469 + 140 = 609
最终送入 LLM 的 Tensor 形状:[609, 896]。
四、总结
本文深入剖析了OpenDriveVLA 的多模态特征的对齐和拼接方法,其本质上是将自动驾驶系统的结构化视觉特征和文本提示,精准“翻译”并融入大语言模型的语义空间。通过 Sparse Query 压缩冗余信息、MM Projector 完成跨模态对齐、特殊 Token 引导的序列穿插拼接,模型既保留了驾驶决策所需的的全局上下文、空间拓扑与动静态目标信息的同时,又完美兼容了 LLM 的 Token 长度限制与自回归生成范式。
📖 参考文献与延伸阅读
- 知乎文章:《自动驾驶 VLA 如何接入 BEV 等结构化输入》
- BEV空间表征学习:BEVFormer(多视角图像的BEV空间转换与特征聚合)
- 端到端自动驾驶框架:UniAD(整合感知、预测、规划的分层架构)
- BEV空间目标跟踪:MOTR(基于Transformer的多目标轨迹预测与关联)
- BEV空间全景分割:Panoptic Segmentation(车道线、路标等地图元素的实例+语义分割)
(本文为CSDN原创,转载请注明出处。)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)