TTS 文本预处理全拆解:4款工业级开源工具横向对比+实操干货
做过语音合成、TTS 开发的同学都懂:文本归一化 TN 才是决定合成音色自然度的隐形天花板。
模型再强、音色再好,如果数字、日期、货币、符号转口语没处理好,读出来照样生硬别扭:`2026-05-11` 直接念字符串、`25℃` 乱读、百分比和分数发音错乱,用户体验直接拉胯。
中文场景尤其麻烦:全角半角混用、标点混乱、日期时间歧义、金额大小写、手机号编号读法,一堆细碎场景要兜底。与其自己手写几十条正则踩坑,不如直接用业界已经跑通生产环境的成熟开源工具。
今天把目前 TTS 圈内最常用、经过大厂落地验证的4 套文本预处理方案,从原理、源码思路、使用示例、性能、适用场景一次性拆透,同时补上大家需要的「TTS 文本归一化常用正则规则库 + 异常案例兜底清单」,新手直接开箱即用,老手可以按需二次定制,省去重复踩坑的时间。
一、先搞懂:TTS 为什么一定要做文本归一化?
很多入门开发者容易忽略一个点:TTS 模型只擅长读正常口语文本,看不懂非标准文本 NSW——阿拉伯数字、日期、时间、货币、度量、分数、百分比、特殊符号,都必须先转成纯中文口语,再进模型推理。
没做 TN 的典型翻车现场:
-
`14:30` 读成「一四三零」而不是「下午两点三十分」
-
`¥99.9` 直接读符号,不转「九十九点九元」
-
`50%` 读「五十百分号」而非「百分之五十」
-
全角英文字母 `IPHONE` 逐个念字母,非常违和
所以标准 TTS 前置链路一定是:
原始文本 → 清洗规整 → 文本归一化 TN → 分词/多音字 → 韵律标注 → 进声学模型
下面四款工具,基本覆盖从轻量原型 → 企业生产 → 深度定制 → 全链路生态所有场景,每一款都附完整接入代码,复制就能用。
二、全能首选:WeTextProcessing(开源生产级方案)
如果只选一个工业化开箱即用的,我首推 WeTextProcessing。开源的实打实线上大规模跑过的 TTS 文本处理工具,覆盖中文 90% 以上归一化场景,同时支持 TN 文本归一化 + ITN 逆归一化 双向转换,不管 TTS 还是语音转写后文本还原都能用。
-
官方博客:WeTextProcessing
-
github:wenet-e2e/WeTextProcessing: Text Normalization & Inverse Text Normalization
核心架构思路
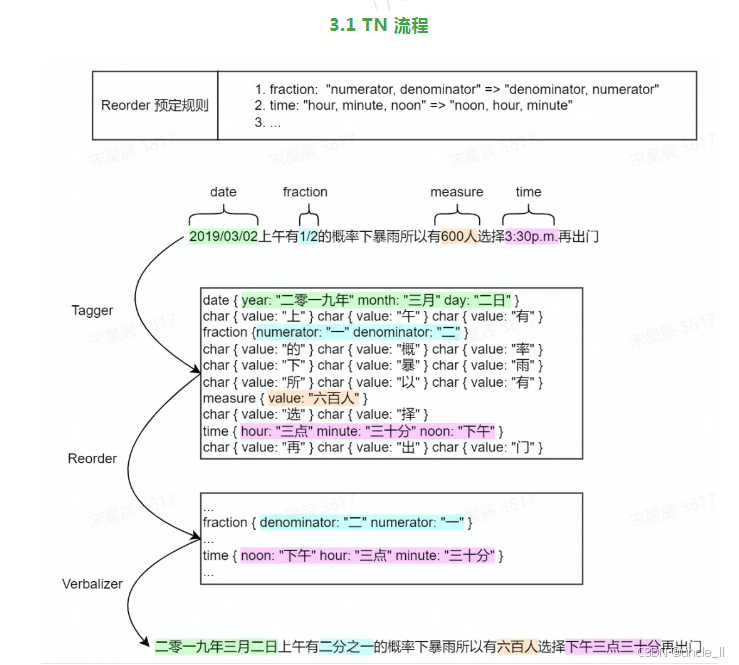
整个流程分四层,设计非常规整,也是行业标准范式,源码可读性高,二次开发也方便:
预处理清洗 → Tagger 模式匹配打标 → Verbalizer 口语转换 → 后处理歧义优化
-
预处理清洗:统一格式化脏文本,全角转半角、中文标点转英文、过滤冗余语气词和无效符号,靠配置文件映射批量处理,不用手动写正则。
- 全角字符 → 半角(IPHONE → IPHONE)
- 中文标点 → 英文标点(“”→"")
- 过滤语气词 / 冗余符号(呃、啊、多余空格)
- 特殊字符白名单过滤,数据来源:
data/char/fullwidth_to_halfwidth.tsv等配置文件。
-
Tagger 标记器:基于 WFST 规则匹配,识别文本里的日期、数字、货币、温度、百分比片段,打上类型标签,且按「日期优先于普通数字」的优先级规避歧义(比如「2026-05-11」优先识别为日期,而非单纯数字)。
- 用 WFST 匹配预定义模式(数字、日期、¥、℃、%、时间等)
- 给匹配到的片段打标签:
date/number/money/measure等 - 按优先级匹配:日期 > 普通数字,避免歧义规则文件:
tn/chinese/rules/下按类型拆分date.py/number.py/money.py
-
Verbalizer 转换器:把识别出的非标准文本,映射成标准中文口语,覆盖绝大多数中文场景。
- 数字:123 → 一百二十三;3.14 → 三点一四
- 日期:2026-05-11 → 二零二六年五月十一日
- 货币:¥99.9 → 九十九点九元
- 度量:25℃ → 二十五摄氏度
- 分数 / 百分比:1/2 → 二分之一;50% → 百分之五十
- 核心:用 WFST 把 “输入串” 映射为 “输出口语串”,支持上下文歧义处理。
-
后处理:修正拆分歧义、优化语句停顿、剔除冗余字,保证整句流畅自然,避免转换后出现生硬卡顿。
- 歧义修正:避免拆分错误(下午 3 点→下午三点,不拆成 “下午”+“三点”)
- 流畅度优化:调整停顿、冗余字
- 输出最终的纯文本。
功能亮点
| 处理类型 | 示例转换 |
|---|---|
| 数字转中文 | “3.14” → “三点一四”、“12345” → “一万二千三百四十五” |
| 日期时间 | “2026-05-11” → “二零二六年五月十一日”、“14:30” → “下午两点三十分” |
| 货币单位 | “$100” → “一百美元”、“¥99.9” → “九十九点九元” |
| 特殊符号 | “25℃” → “二十五摄氏度”、“50%” → “百分之五十” |
| 中文标点标准化 | “,。!?” 统一处理,添加自然停顿标记 |
快速接入
pip install WeTextProcessing
from tn.chinese.normalizer import Normalizer
normalizer = Normalizer()
text = "今天是2026-05-11,我有100元现金"
result = normalizer.normalize(text)
# 输出:"今天是二零二六年五月十一日,我有一百元现金"
核心优势与注意事项
性能:单句耗时仅 5ms 左右,完全满足线上实时 TTS 接口,支持批量处理和流式处理,适配高并发场景。
适合场景:企业级 TTS 服务、公有云语音接口、对准确率和稳定性要求高的生产项目,不用额外适配,开箱即用。
避坑提醒:默认不处理手机号逐位读法,若需要将「13800138000」转为「一三八零零一三八零零零」,需额外添加自定义规则。
三、轻量神器:cn2an 纯数字转换利器
很多时候我们不需要完整文本归一化,只需要搞定数字 ↔ 中文互转,不想引入重型依赖,那 `cn2an` 就是刚需标配。纯 Python 实现,零第三方依赖,轻量到可以嵌入小程序、客户端,性能拉满。
- 官方博客:cn2an 核心代码解析
- github:https://github.com/Ailln/cn2an
核心特点
-
零第三方依赖、纯 Python 实现,安装包体积极小,不占用过多资源。
-
算法极简:正向/反向遍历,时间复杂度 O(n),极致轻量,单句微秒级处理,肉眼无感知。
-
支持四种转换模式:`strict / normal / smart / direct`,适配不同业务场景。
-
兼容整数、小数、负数、日期、分数、百分比、金额大写,数字相关转换全覆盖。
四种模式核心区别:
-
strict:严格标准中文数字(如「一百二十三」,不允许「1百23」)。
-
normal:支持「一二三」简写,适配日常口语化文本。
-
smart:兼容「1百23」「三千5百」这类混合写法,适合处理用户输入的不规范文本。
-
direct:逐位直译不做语义合并(如「123」→「一二三」,适合手机号、编号读法)。
功能亮点
- 支持 “123"↔"一百二十三” 基础转换
- 智能识别上下文:“2026 年"→"二零二六年”,“1/2"→"二分之一”
- 处理混合数字:“第 123 名"→"第一百二十三名”,“约 500 人"→"约五百人”
- 支持大小写金额转换:“100 元"→"壹佰元整”
常用能力演示
pip install cn2an
import cn2an
## 中文数字 => 阿拉伯数字
# 最大支持到 `10**16`,即 `千万亿`,最小支持到 `10**-16`。
# 在 strict 模式(默认)下,只有严格符合数字拼写的才可以进行转化
output = cn2an.cn2an("一百二十三")
# 或者
output = cn2an.cn2an("一百二十三", "strict")
# output:
# 123
# 在 normal 模式下,可以将 一二三 进行转化
output = cn2an.cn2an("一二三", "normal")
# output:
# 123
# 在 smart 模式下,可以将混合拼写的 1百23 进行转化
output = cn2an.cn2an("1百23", "smart")
# output:
# 123
# 以上三种模式均支持负数
output = cn2an.cn2an("负一百二十三", "strict")
# output:
# -123
# 以上三种模式均支持小数
output = cn2an.cn2an("一点二三", "strict")
# output:
# 1.23
# 在 direct 模式下,只做逐位原样转化,并返回字符串
output = cn2an.cn2an("零零三", "direct")
# output:
# 003
output = cn2an.cn2an("一二点三零", "direct")
# output:
# 12.30
## 阿拉伯数字 => 中文数字
# 最大支持到`10**16`,即`千万亿`,最小支持到 `10**-16`。
# 在 low 模式(默认)下,数字转化为小写的中文数字
output = cn2an.an2cn("123")
# 或者
output = cn2an.an2cn("123", "low")
# output:
# 一百二十三
# 在 up 模式下,数字转化为大写的中文数字
output = cn2an.an2cn("123", "up")
# output:
# 壹佰贰拾叁
# 在 rmb 模式下,数字转化为人民币专用的描述
output = cn2an.an2cn("123", "rmb")
# output:
# 壹佰贰拾叁元整
# 以上三种模式均支持负数
output = cn2an.an2cn("-123", "low")
# output:
# 负一百二十三
# 以上三种模式均支持小数
output = cn2an.an2cn("1.23", "low")
# output:
# 一点二三
# 在 direct 模式下,只做逐位原样转化
output = cn2an.an2cn("012", "direct")
# output:
# 零一二
output = cn2an.an2cn("12.30", "direct")
# output:
# 一二点三零
## 句子转化
# 在 cn2an 方法(默认)下,可以将句子中的中文数字转成阿拉伯数字
output = cn2an.transform("小王捡了一百块钱")
# 或者
output = cn2an.transform("小王捡了一百块钱", "cn2an")
# output:
# 小王捡了100块钱
# 在 an2cn 方法下,可以将句子中的中文数字转成阿拉伯数字
output = cn2an.transform("小王捡了100块钱", "an2cn")
# output:
# 小王捡了一百块钱
# direct=True 时,句子中的数字只做逐位原样转化,不做日期、范围等额外处理
output = cn2an.transform("电话零零三,二〇〇二年", "cn2an", direct=True)
# output:
# 电话003,2002年
output = cn2an.transform("电话012,1-2个月", "an2cn", direct=True)
# output:
# 电话零一二,一-二个月
## 支持日期
output = cn2an.transform("小王的生日是二零零一年三月四日", "cn2an")
# output:
# 小王的生日是2001年3月4日
output = cn2an.transform("小王的生日是2001年3月4日", "an2cn")
# output:
# 小王的生日是二零零一年三月四日
## 支持分数
output = cn2an.transform("抛出去的硬币为正面的概率是二分之一", "cn2an")
# output:
# 抛出去的硬币为正面的概率是1/2
output = cn2an.transform("抛出去的硬币为正面的概率是1/2", "an2cn")
# output:
# 抛出去的硬币为正面的概率是二分之一
## 支持百分比
output = cn2an.transform("抛出去的硬币为正面的概率是百分之五十")
# output:
# 抛出去的硬币为正面的概率是50%
output = cn2an.transform("抛出去的硬币为正面的概率是50%", "an2cn")
# output:
# 抛出去的硬币为正面的概率是百分之五十
## 支持摄氏度
output = cn2an.transform("现在温度是100℃", "an2cn")
# output:
# 现在温度是一百摄氏度
output = cn2an.transform("现在温度是一百摄氏度", "cn2an")
# output:
# 现在温度是100℃
核心优势与适用场景
性能:单句微秒级处理,比 WeTextProcessing 更快,适合对性能要求极高的轻量场景。
适合场景:快速原型开发、小程序/客户端轻量 TTS、仅需数字转换的业务场景(如财务金额、编号读法),不用引入复杂依赖,省时间。
避坑提醒:不支持全角半角转换、标点规整,若需要完整文本清洗,需搭配简单正则使用(后面会补充)。
四、定制专属方案:chinese_text_normalization
如果你有行业特殊术语、自定义读法、需要改规则二次开发,那这款基于正则+手写规则的开源项目最合适。源码完全透明,模块化拆分,每一条规则都能自定义修改,适配政企、医疗、金融等行业定制 TTS 场景。
核心设计
采用模块化拆分,数字、日期、时间、货币、手机号、分数等场景独立规则,修改某一类场景时,不会影响其他功能,二次开发成本极低:
- 基础清洗模块:全角半角、大小写、冗余空格、语气词自动清理,可配置开关。
- 全角 ↔ 半角转换
- 英文大小写转换
- 过滤标点符号
- 删除冗余空格
- 去除语气词(呃、啊)
- 智能去除儿化音(保留白名单:儿女、婴儿等)
- 归一化模块:按场景拆分,支持自定义读法(如行业术语「5G」可转为「五吉」)。
- 日期:2025 年 08 月 22 日 → 二零二五年八月二十二日
- 金钱:100.5 元 → 一百点五元
- 手机号 / 固话:13800138000 → 一三八零零一三八零零零
- 分数:1/2 → 二分之一
- 百分数:50% → 百分之五十
- 数字 + 量词:25℃ → 二十五
- 纯数字:1234 → 一千二百三十四
- 数字编号:10086 → 一零零八六
- 辅助模块:儿化音智能剔除(保留儿女、婴儿等白名单)、简繁互转、批量/流式处理。
功能亮点
- 模块化设计:数字、日期、时间、货币、度量衡等独立规则模块
- 支持中英文混合文本处理:“iPhone 13"→"爱疯十三”
- 可自定义规则:通过配置文件添加行业特定术语转换
- 支持批量处理与流式处理两种模式
常量定义
- 中文数字(零一二三四五…)、大小写数字、数位单位(十百千万亿兆…)
- 货币、量词、标点符号、全角转半角映射表
QJ2BJ - 儿化音白名单、填充词(呃、啊)等
核心类结构
ChineseChar/ChineseNumberUnit/ChineseNumberDigit/ChineseMathNumberSystem/MathSymbol数字系统封装
核心转换函数
create_system():创建中文数字系统chn2num():中文数字 → 阿拉伯数字num2chn():阿拉伯数字 → 中文数字NSWNormalizer:非标准词(日期、金钱、电话、分数、百分数)标准化
辅助工具函数
remove_erhua():去除儿化音quanjiao2banjiao():全角转半角check_chars():非法字符校验
接入示例
pip install opencc-python-reimplemented
from cn_tn import TextNorm
# 自定义配置:全角转半角、移除冗余语气词、剔除儿化音
normalizer = TextNorm(
to_banjiao=True, # 全角转半角
remove_fillers=True, # 去语气词
remove_erhua=True, # 去儿化音
to_lower=False, # 英文不大写
check_chars=False # 不检查非法字符
)
test_text = "今天是2026年5月11日,我买了3个苹果,花了15.5元"
normalizer(test_text)
# '今天是二零二六年五月十一日 我买了三个苹果 花了十五点五元'
核心优势与适用场景
性能:单句耗时约 3ms,比 WeTextProcessing 略快,支持批量处理,适配中高并发场景。
适合场景:政企定制 TTS、行业专属术语(如医疗、金融)、需要私自改归一化规则的专业项目,源码透明,可深度定制。
避坑提醒:默认规则不如 WeTextProcessing 全面,需要根据自身业务补充规则,建议结合后面的正则规则库使用。
五、全链路生态:PaddleSpeech 文本前端
如果你本身就在用飞桨语音生态,不想自己拼装工具,直接用 PaddleSpeech 内置文本前端 一步到位。它不只是做文本归一化,而是完整 TTS 前置全链路,省去自己整合工具的麻烦。
完整链路:文本清洗 → 归一化 → 分词 → 多音字纠错 → 拼音声调 → 韵律停顿预测,输出可直接喂给 TTS 模型训练和推理的音素序列。
亮点最实用的一点:上下文智能多音字消歧,解决「银行/行走」「长大/长短」这类传统正则搞不定的场景,这是其他三款工具不具备的优势。
- github:PaddleSpeech
功能亮点
- 全流程文本处理:清洗→归一化→分词→拼音标注→韵律预测
- 强大的多音字处理:基于上下文的智能多音字纠正(如 “银行"vs"行走”)
- 支持 SSML 标记语言:可控制语速、音调、停顿等语音参数
- 无缝集成 PaddleSpeech 的 TTS 模型
简单使用
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install pytest-runner
pip install paddlespeech
from paddlespeech.t2s.frontend.zh_frontend import Frontend
frontend = Frontend()
text = "12345元,2026年5月11日,北京欢迎你"
phones = frontend.get_phonemes(text)
# 输出拼音序列与声调信息,直接用于TTS模型输入
['i1','uan4','er4','q','ian1','s','an1','b','ai3','s','ii4','sh','iii2','u3','van2','sp',
'er4','l','ing2','er4','l','iou4','n','ian2','u3','ve4','sh','iii2','i2','r','iii4','sp','b','ei3','j','ing1','h','uan1','ing2','n','i3']
整句:一万二千三百四十五元,二零二六年五月十一日,北京欢迎你
| 符号类型 | 含义 | 示例 |
|---|---|---|
| 字母组合 | 声母 / 韵母(普通话声韵拆分) | b (玻), j (基), ing (英) |
| 数字 1-4 | 普通话四声 | 1 = 阴平 (ˉ)、2 = 阳平 (ˊ)、3 = 上声 (ˇ)、4 = 去声 (ˋ) |
| sp | 静音停顿(标点 / 断句生成) | 逗号、句号对应的静音 |
| ii / iii | 卷舌音 / 整体认读音节(模型专用写法) | sh+iii = 师 (shī) |
核心优势与适用场景
性能:单句耗时约 6ms,略低于其他三款工具,但胜在全链路一站式,不用额外整合。
适合场景:飞桨语音生态项目、端到端 TTS 开发、需要完整前置链路(多音字+韵律)的场景,省去拼装工具的时间。
避坑提醒:依赖飞桨生态,若项目不使用 PaddlePaddle,不建议引入,会增加额外依赖成本。
注意:paddlespeech项目中的utils下的zh_tn.py代码复用chinese_text_normalization项目下的cn_tn.py文件
新增了:
- 文本清洗函数:
remove_weird_chars、remove_extra_linebreaks、remove_symbols等 - 中文分词(jieba)、字符 / 词切分
- 命令行参数解析(argparse)
- 批量文本处理的
main函数
from zh_tn import NSWNormalizer
# 待处理文本
text = "12345元,2026年5月11日,手机号13800138000,80.5%,3/4,0595-12345678"
# 归一化
res = NSWNormalizer(text).normalize()
print("原始:", text)
print("归一化后:", res)
# 原始: 12345元,2026年5月11日,手机号13800138000,80.5%,3/4,0595-12345678
# 归一化后: 一万两千三百四十五元,二零二六年五月十一日,手机号一三八零零一三八零零零,百分之八十点五,四分之三,零五九五一二三四五六七八
六、四款工具横向选型对照表
| 工具名称 | 核心优势 | 性能(单句耗时) | 适用场景 | 依赖成本 |
|---|---|---|---|---|
| WeTextProcessing | 工业级全能、双向TN/ITN、大厂生产验证、场景全覆盖 | 约5ms | 企业线上TTS、标准语音服务、高稳定性需求 | 中等(需安装相关依赖) |
| cn2an | 零依赖、超轻量、数字转换拉满、性能极致 | 微秒级 | 原型开发、轻量应用、仅数字处理场景 | 极低(零第三方依赖) |
| chinese_text_normalization | 规则透明、可深度定制、模块化、适配行业需求 | 约3ms | 行业定制、私有规则改造、二次开发 | 低(少量依赖) |
| PaddleSpeech 前端 | 全链路一站式、多音字消歧、适配飞桨生态 | 约6ms | 飞桨生态项目、端到端TTS开发 | 较高(依赖飞桨框架) |
七、TTS 文本预处理标准落地流程
不管用哪款工具,按这个流程走,合成流畅度直接拉满,避免出现翻车场景,这是我在多个生产项目中验证过的标准流程:
-
基础清洗:过滤乱码、特殊控制符、多余换行空格,统一全角半角、中英文标点,剔除冗余语气词。
-
归一化转换:将数字、日期、货币、符号、度量等非标准文本,统一转成中文口语,规避歧义。
-
标点规整:统一中英文标点(如「,」替换为「,」),合理插入停顿(如句号、逗号后添加短停顿)。
-
多音字消歧:处理上下文相关的易错读音(如「银行」读「yín háng」,而非「yín xíng」)。
-
韵律标记:按标点和语义加入停顿标记,适配 TTS 模型的韵律合成,避免生硬卡顿。
八、干货补充:TTS 文本归一化常用正则规则库 + 异常案例兜底清单
这部分是重点,不管用哪款工具,都能用到——整理了生产环境中最常见的异常场景,搭配可直接复制的正则规则,兜底工具未覆盖的边缘案例,减少踩坑。
(一)常用正则规则库
所有正则都带注释,可根据自身业务调整,主要用于补充工具未覆盖的场景:
import re
def tts_text_clean(text):
# 1. 过滤特殊控制符(换行、制表符、空格等)
text = re.sub(r'[\n\t\r]', '', text)
text = re.sub(r'\s+', ' ', text).strip()
# 2. 全角转半角
def full2half(s):
result = ""
for char in s:
code = ord(char)
if code == 12288: # 全角空格
code = 32
elif 65281 <= code <= 65374: # 全角字符
code -= 65248
result += chr(code)
return result
text = full2half(text)
# 3. 手机号/固话逐位读法
# 匹配手机号(11位)、固话(如010-12345678)
text = re.sub(r'(\d{11})', lambda x: ''.join([c + ' ' for c in x.group()]).strip(), text)
text = re.sub(r'(\d{3,4}-\d{7,8})', lambda x: ''.join([c + ' ' if c != '-' else ' ' for c in x.group()]).strip(), text)
# 4. 特殊符号归一化(如℃、%、$等,补充工具遗漏场景)
text = re.sub(r'℃', '摄氏度', text)
text = re.sub(r'%', '百分之', text)
text = re.sub(r'\$', '美元', text)
text = re.sub(r'€', '欧元', text)
# 5. 冗余语气词过滤(补充工具未覆盖的语气词)
fill_words = r'嗯|哦|啊|呀|呢|吧|啦|呵|哈'
text = re.sub(f'[{fill_words}]', '', text)
# 6. 日期歧义修正(如「2026.5.11」转为「2026年5月11日」)
text = re.sub(r'(\d{4})\.(\d{1,2})\.(\d{1,2})', r'\1年\2月\3日', text)
return text
# 测试正则效果
test_text = "嗯,今天是2026.5.11,手机号13800138000,气温25℃,折扣50%,固话010-12345678"
print(tts_text_clean(test_text))
# 输出:今天是2026年5月11日,手机号一 三 八 零 零 一 三 八 零 零 零,气温25摄氏度,折扣50百分之,固话零 一 零 一 二 三 四 五 六 七 八
(二)异常案例兜底清单
整理了10个生产环境中最常见的异常案例,包含问题描述、解决方案,直接对应到上面的工具和正则,避免踩坑:
| 异常案例 | 问题描述 | 解决方案 |
|---|---|---|
| 案例1:「2026.5.11」 | 点号分隔日期,工具无法识别,读成「二零二六点五点十一」 | 用正则将「.」替换为「年」「月」,再用工具归一化 |
| 案例2:「13800138000」 | 手机号被识别为普通数字,读成「十三亿八千万一百三十八万」 | 用正则逐位拆分,或用cn2an的direct模式转换 |
| 案例3:「5G/4G」 | 行业术语,工具无法识别,读成「五G/四G」 | 用正则替换为「五吉/四吉」,或修改chinese_text_normalization规则 |
| 案例4:「¥100.50」 | 小数末尾的0被忽略,读成「一百点五」,不符合财务场景 | 用cn2an的up模式转为大写,或补充正则保留末尾0 |
| 案例5:「全角123456」 | 全角数字未转换,工具识别异常,读成字符串 | 用全角转半角正则,再进行归一化 |
| 案例6:「银行/行走」 | 多音字歧义,工具读错声调 | 用PaddleSpeech前端的多音字消歧,或手动添加上下文规则 |
| 案例7:「3/4吨」 | 分数+度量组合,工具只转换分数,忽略度量 | 先归一化分数,再用正则补充度量读法(如「四分之三吨」) |
| 案例8:「嗯,今天天气不错」 | 冗余语气词,合成时生硬卡顿 | 用正则过滤语气词,或开启chinese_text_normalization的remove_fillers开关 |
| 案例9:「010-12345678」 | 固话被识别为普通数字,读错格式 | 用正则逐位拆分,补充固话读法规则 |
| 案例10:「IPhone 15」 | 英文+数字组合,读成「IPhone十五」,违和感强 | 用正则将英文逐位读(如「爱 皮 哄 一 五」),或替换为中文名称 |
九、总结:按需选型,少走弯路
-
做正式线上生产:闭眼用 WeTextProcessing,大厂验证、场景全覆盖,省心少踩坑,搭配正则规则库兜底边缘案例。
-
做快速开发、只转数字:cn2an 必装,轻量零依赖,数字转换拉满,适合原型和轻量应用。
-
有行业定制、改规则需求:基于 chinese_text_normalization 二次开发,源码透明,模块化设计,适配行业特殊场景。
-
用Paddle 语音生态:直接用自带前端,全链路一站式搞定,重点解决多音字消歧问题,省去工具拼装麻烦。
其实 TTS 文本预处理,核心就是覆盖场景+规避歧义+适配口语,不用追求复杂,选择一款适合自己业务的工具,搭配常用正则和异常兜底,就能满足绝大多数生产需求。
如果大家在实际开发中遇到其他未覆盖的异常案例,或者需要某款工具的二次开发教程,可以在评论区留言。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)