【Python × 深度学习 × Agent 系列·第五篇】类型系统与工程化:Pydantic V2、dataclass、LLM 结构化输出,让 Agent 的输出直接被代码使用
【Python × 深度学习 × Agent 系列·第五篇】类型系统与工程化:Pydantic V2、dataclass、LLM 结构化输出,让 Agent 的输出直接被代码使用
作者:技术博主 | 更新时间:2026-05-14 | 阅读时长:约 22 分钟
系列:Python × 深度学习 × Agent 系列(共 6 篇)
标签:Pydanticdataclass类型注解结构化输出JSON SchemaAgentTypedDictProtocol工程化
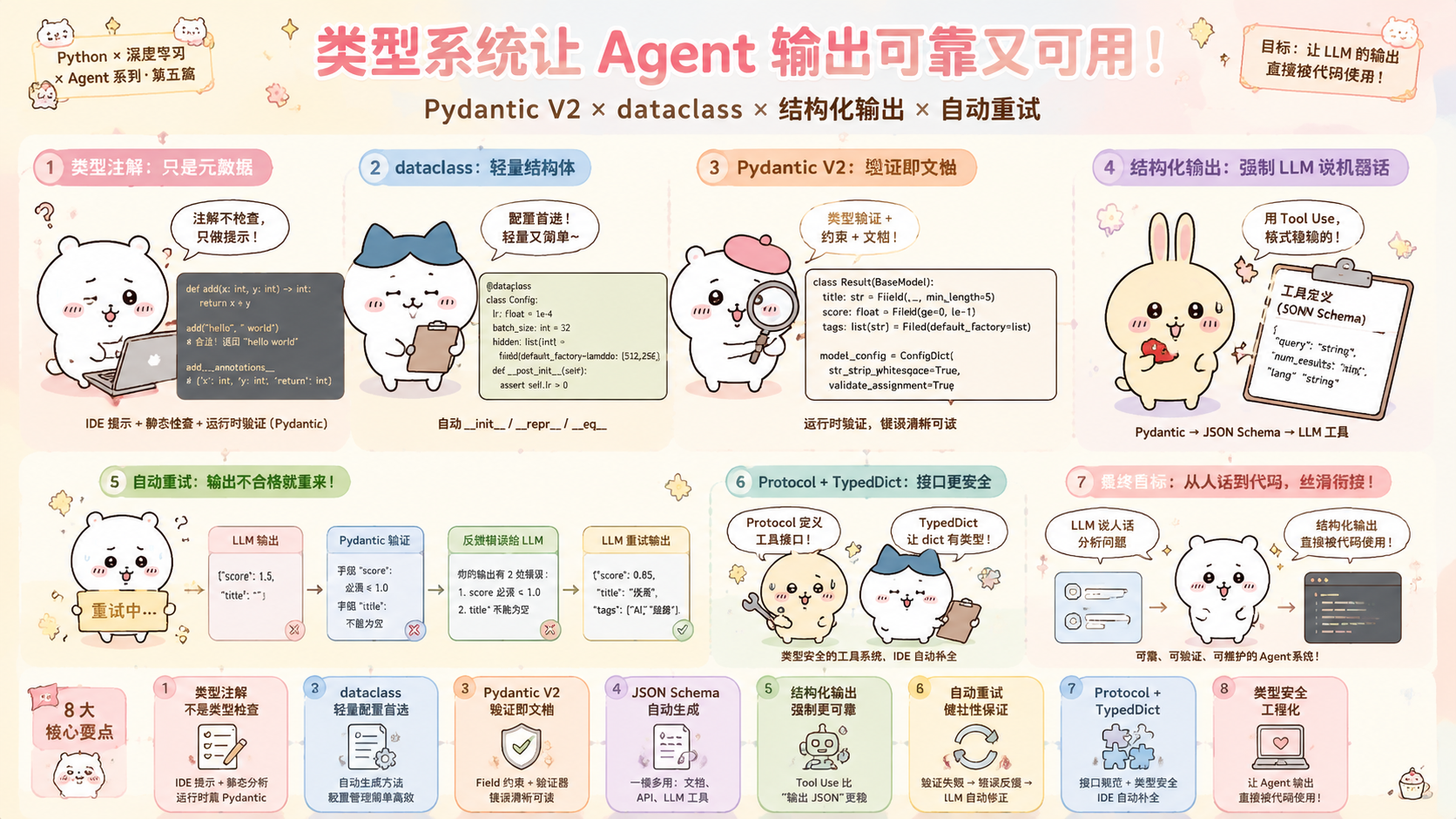
🔥 本篇目标:LLM 的输出是自然语言,但 Agent 的下游代码需要结构化数据。"让 LLM 输出 JSON"只是第一步——你还需要验证格式、处理缺字段、在 LLM 说错话时自动重试。本篇从 Python 类型系统的底层讲起,深入 Pydantic V2 的验证器和序列化机制,然后给出一套完整的"LLM 结构化输出 + 自动重试 + 类型安全"的工程方案。
系列进度
| 篇次 | 主题 | 状态 |
|---|---|---|
| 第一篇 | Python 基础精要:对象模型、生成器、装饰器 | ✅ 已发布 |
| 第二篇 | NumPy:广播、einsum,手推 Self-Attention | ✅ 已发布 |
| 第三篇 | PyTorch 核心:Tensor、autograd、训练循环 | ✅ 已发布 |
| 第四篇 | Agent 异步编程:async/await、并发 LLM 调用 | ✅ 已发布 |
| 第五篇(本篇) | 类型系统:Pydantic V2、dataclass、LLM 结构化输出 | — |
| 第六篇 | 性能与部署:推理优化、并发模型服务 | 即将发布 |
目录
- 一、Python 类型系统基础:注解不是类型检查
- 二、
dataclass:轻量结构体,DL 配置的首选 - 三、Pydantic V2:验证即文档,文档即代码
- 四、
model_validator与field_validator:跨字段验证 - 五、Pydantic 的序列化:
model_dump与自定义序列器 - 六、从 Pydantic 模型自动生成 JSON Schema
- 七、LLM 结构化输出:让 Agent 说人话,输出机器话
- 八、结构化输出的重试机制:输出不合格自动要求重来
- 九、
TypedDict与Protocol:Agent 接口的类型安全 - 十、综合实战:类型安全的完整 Agent 工具系统
- 十一、面试高频考点
一、Python 类型系统基础:注解不是类型检查
1.1 类型注解只是元数据
# Python 的类型注解在运行时不做任何强制检查!
def add(x: int, y: int) -> int:
return x + y
# 完全合法,不会报错
result = add("hello", " world") # 返回 "hello world"
print(type(result)) # <class 'str'>
# 注解存储在 __annotations__ 里,只是元数据
print(add.__annotations__)
# {'x': <class 'int'>, 'y': <class 'int'>, 'return': <class 'int'>}
类型注解的价值在于:
- IDE 自动补全:告诉 PyCharm/VSCode 变量的类型
- mypy/pyright 静态分析:在运行前发现类型错误
- Pydantic/FastAPI:在运行时读取注解做实际验证
1.2 typing 模块的常用类型
from typing import (
Optional, # Optional[X] = X | None
Union, # Union[X, Y] = X | Y(Python 3.10+ 用 X | Y)
List, # 已弃用,用 list[X]
Dict, # 已弃用,用 dict[K, V]
Tuple, # 已弃用,用 tuple[X, Y]
Callable, # 函数类型
Any, # 任意类型(关闭类型检查)
TypeVar, # 泛型类型变量
Generic, # 泛型基类
Literal, # 字面量类型
Final, # 常量
ClassVar, # 类变量(不是实例变量)
overload, # 函数重载声明
)
from typing import TYPE_CHECKING # 只在类型检查时导入(避免循环导入)
# Python 3.10+ 更简洁的写法
def process(x: int | str | None) -> list[dict[str, int]]:
...
# Literal:限制参数为特定值(替代枚举的轻量方案)
from typing import Literal
def set_precision(mode: Literal["fp16", "fp32", "bf16"]) -> None:
...
set_precision("fp16") # OK
# set_precision("int8") # mypy 报错(虽然运行时不报错)
# TypeVar:泛型
from typing import TypeVar
T = TypeVar("T")
def first(items: list[T]) -> T:
return items[0]
x: int = first([1, 2, 3]) # T 推断为 int
s: str = first(["a", "b"]) # T 推断为 str
1.3 __annotations__ 在 DL 配置中的应用
import inspect
class ModelConfig:
"""训练配置(纯注解,不做验证)"""
learning_rate: float = 1e-4
batch_size: int = 32
num_epochs: int = 100
model_name: str = "bert-base-chinese"
use_amp: bool = True
# 运行时读取注解
print(ModelConfig.__annotations__)
# {'learning_rate': float, 'batch_size': int, ...}
# 基于注解做简单验证(手动实现,Pydantic 做得更好)
def validate_config(obj) -> list[str]:
errors = []
for field, expected_type in obj.__annotations__.items():
value = getattr(obj, field, None)
if value is not None and not isinstance(value, expected_type):
errors.append(f"{field}: 期望 {expected_type.__name__},得到 {type(value).__name__}")
return errors
二、dataclass:轻量结构体,DL 配置的首选
2.1 基础用法
from dataclasses import dataclass, field, asdict, astuple
from typing import Optional
@dataclass
class TrainingConfig:
"""
训练配置(dataclass 版本)
优势:自动生成 __init__、__repr__、__eq__
"""
# 必填参数(没有默认值)
model_name: str
output_dir: str
# 可选参数(有默认值)
learning_rate: float = 1e-4
batch_size: int = 32
num_epochs: int = 100
warmup_steps: int = 1000
weight_decay: float = 0.01
max_grad_norm: float = 1.0
use_amp: bool = True
seed: int = 42
# 可变默认值必须用 field(default_factory=...)
# 不能写 layers: list = [](共享引用!)
hidden_sizes: list[int] = field(default_factory=lambda: [512, 256, 128])
extra_kwargs: dict[str, object] = field(default_factory=dict)
# 不参与 __init__ 的字段
_computed: str = field(default="", init=False, repr=False)
def __post_init__(self):
"""__init__ 后的后处理(验证、计算派生字段)"""
if self.learning_rate <= 0:
raise ValueError(f"learning_rate 必须 > 0,得到 {self.learning_rate}")
if self.batch_size < 1:
raise ValueError(f"batch_size 必须 >= 1")
# 计算派生字段
self._computed = f"{self.model_name}_lr{self.learning_rate}"
# 使用
cfg = TrainingConfig(
model_name="bert-base-chinese",
output_dir="./outputs",
learning_rate=2e-5,
batch_size=16,
)
print(cfg)
# TrainingConfig(model_name='bert-base-chinese', output_dir='./outputs', ...)
# 序列化为 dict
cfg_dict = asdict(cfg)
# 从 dict 创建(dataclass 不内置,需要手动)
cfg2 = TrainingConfig(**{
k: v for k, v in cfg_dict.items()
if not k.startswith("_") # 过滤私有字段
})
2.2 frozen=True:不可变配置
@dataclass(frozen=True) # 所有字段不可修改(类似 namedtuple)
class HyperParams:
lr: float = 1e-3
dropout: float = 0.1
hidden_size: int = 768
hp = HyperParams()
# hp.lr = 0.001 # FrozenInstanceError!
# 不可变的好处:可以作为字典 key,可以安全传递给多线程/多进程
import hashlib, json
hp_hash = hashlib.md5(json.dumps(asdict(hp)).encode()).hexdigest()
2.3 dataclass vs Pydantic 怎么选?
dataclass:
✅ 轻量,无依赖
✅ 速度快(纯 Python 数据结构)
✅ 与 Python 生态无缝(pickle、copy 等)
❌ 不做运行时类型验证(传错类型不报错)
❌ JSON 序列化/反序列化需要手动处理
适合:训练配置、内部数据结构、对性能敏感的场景
Pydantic:
✅ 运行时类型验证(传错类型立即报错)
✅ 自动 JSON 序列化/反序列化
✅ 自动生成 JSON Schema(供 LLM 工具调用)
✅ 复杂验证(跨字段、自定义逻辑)
❌ 依赖 pydantic 库(但几乎所有项目都装了)
❌ 比 dataclass 略慢(验证有开销)
适合:API 请求/响应、LLM 结构化输出、对外接口
三、Pydantic V2:验证即文档,文档即代码
3.1 基础模型
from pydantic import (
BaseModel,
Field,
field_validator,
model_validator,
ConfigDict,
computed_field,
)
from typing import Optional, Literal
import json
class ResearchResult(BaseModel):
"""
Agent 输出的研究结果模型
Pydantic 会在创建时验证所有字段的类型和约束
"""
# 基本字段
title: str = Field(..., description="研究标题", min_length=5, max_length=200)
summary: str = Field(..., description="执行摘要", min_length=50)
confidence: float = Field(..., ge=0.0, le=1.0, description="置信度 0-1")
sources: list[str] = Field(default_factory=list, description="参考来源 URL 列表")
tags: list[str] = Field(default_factory=list, max_length=10)
# 枚举值(Literal)
status: Literal["draft", "reviewed", "published"] = "draft"
# 嵌套模型
metadata: Optional["ResearchMetadata"] = None
# 模型配置(V2 风格)
model_config = ConfigDict(
str_strip_whitespace=True, # 自动去除字符串首尾空白
str_min_length=1, # 所有字符串最短 1 字符
validate_assignment=True, # 赋值时也做验证(不只是初始化时)
frozen=False, # 允许修改
)
@computed_field # V2 的计算属性
@property
def word_count(self) -> int:
return len(self.summary.split())
@computed_field
@property
def has_sources(self) -> bool:
return len(self.sources) > 0
class ResearchMetadata(BaseModel):
author: str
created_at: str # 实际项目用 datetime
version: str = "1.0"
word_count: int = 0
# 更新前向引用
ResearchResult.model_rebuild()
# 使用
result = ResearchResult(
title="2026 年大语言模型发展趋势",
summary="本研究分析了 2026 年 LLM 的主要发展趋势,包括多模态能力的提升、推理效率的优化以及部署成本的显著下降。",
confidence=0.85,
sources=["https://arxiv.org/abs/2605.xxxxx"],
tags=["LLM", "AI", "趋势"],
)
print(result.word_count) # 自动计算
print(result.model_dump()) # 序列化为 dict
print(result.model_dump_json()) # 序列化为 JSON 字符串
3.2 Field 的验证约束
from pydantic import BaseModel, Field, AnyHttpUrl, EmailStr
from typing import Annotated
# 使用 Annotated 把约束与类型分离(更清晰)
PositiveFloat = Annotated[float, Field(gt=0)]
Probability = Annotated[float, Field(ge=0.0, le=1.0)]
NonEmptyStr = Annotated[str, Field(min_length=1)]
LimitedList = Annotated[list[str], Field(max_length=20)]
class AgentToolCall(BaseModel):
tool_name: NonEmptyStr # 非空字符串
confidence: Probability # 0.0 到 1.0
temperature: PositiveFloat = 0.7 # 正数
max_tokens: int = Field(default=1024, ge=1, le=100_000)
callback_url: Optional[AnyHttpUrl] = None # URL 格式验证
# 错误示例(会抛 ValidationError)
try:
bad = AgentToolCall(
tool_name="", # 空字符串!
confidence=1.5, # 超出范围!
temperature=-0.1, # 负数!
)
except Exception as e:
print(e)
# 3 个验证错误会一次性全部报出(不是遇到第一个就停)
四、model_validator 与 field_validator:跨字段验证
4.1 field_validator:单字段验证
from pydantic import BaseModel, field_validator, Field
import re
class LLMConfig(BaseModel):
model_name: str
api_key: str
temperature: float = 0.7
max_tokens: int = 1024
@field_validator("model_name")
@classmethod
def validate_model_name(cls, v: str) -> str:
"""验证模型名称格式"""
valid_prefixes = ("claude-", "gpt-", "gemini-", "llama-")
if not any(v.startswith(p) for p in valid_prefixes):
raise ValueError(
f"不支持的模型:{v},支持的前缀:{valid_prefixes}"
)
return v.strip().lower() # 顺便标准化:去空白、小写
@field_validator("api_key")
@classmethod
def validate_api_key(cls, v: str) -> str:
"""API key 不能暴露在日志里(脱敏验证)"""
if len(v) < 20:
raise ValueError("API key 太短,疑似无效")
return v # 返回原值(不做修改)
@field_validator("temperature")
@classmethod
def validate_temperature(cls, v: float) -> float:
if not 0.0 <= v <= 2.0:
raise ValueError(f"temperature 必须在 [0, 2],得到 {v}")
return v
# mode="before":在类型转换之前运行(可以做类型转换)
@field_validator("max_tokens", mode="before")
@classmethod
def coerce_max_tokens(cls, v) -> int:
"""允许传入字符串"1024",自动转为 int"""
if isinstance(v, str):
return int(v)
return v
4.2 model_validator:跨字段验证
from pydantic import BaseModel, model_validator
from typing import Self # Python 3.11+
class SearchConfig(BaseModel):
"""搜索配置:top_k 和 top_p 不能同时使用"""
query: str
top_k: Optional[int] = None # 取 top k 个结果
top_p: Optional[float] = None # 核采样阈值
min_similarity: float = 0.7
max_results: int = 10
@model_validator(mode="after") # after:所有字段已完成类型转换后运行
def validate_sampling_strategy(self) -> "Self":
"""top_k 和 top_p 互斥"""
if self.top_k is not None and self.top_p is not None:
raise ValueError("top_k 和 top_p 不能同时指定,选择一个")
if self.top_k is None and self.top_p is None:
# 默认使用 top_k=5
self.top_k = 5
if self.top_k is not None and self.top_k > self.max_results:
raise ValueError(
f"top_k({self.top_k}) 不能大于 max_results({self.max_results})"
)
return self
@model_validator(mode="before") # before:原始输入数据(dict)上运行
@classmethod
def normalize_query(cls, data: dict) -> dict:
"""预处理:query 去首尾空白,超长则截断"""
if "query" in data:
data["query"] = data["query"].strip()[:500]
return data
五、Pydantic 的序列化:model_dump 与自定义序列器
5.1 model_dump 的各种用法
from pydantic import BaseModel, Field
from datetime import datetime
from typing import Optional
class TaskOutput(BaseModel):
task_id: str
result: str
created_at: datetime = Field(default_factory=datetime.now)
metadata: dict = Field(default_factory=dict)
secret_key: str = Field(default="", exclude=True) # 序列化时自动排除
output = TaskOutput(task_id="t001", result="分析完成", secret_key="sk-xxx")
# 基本序列化
d1 = output.model_dump()
# {'task_id': 't001', 'result': '分析完成', 'created_at': datetime(...), 'metadata': {}}
# 注意:secret_key 不出现(exclude=True)
# 指定包含/排除字段
d2 = output.model_dump(include={"task_id", "result"}) # 只包含这两个
d3 = output.model_dump(exclude={"metadata", "created_at"}) # 排除这两个
# 序列化为 JSON(datetime 自动转 ISO 格式字符串)
json_str = output.model_dump_json()
# {"task_id":"t001","result":"分析完成","created_at":"2026-05-14T10:00:00","metadata":{}}
# 反序列化
output2 = TaskOutput.model_validate_json(json_str)
output3 = TaskOutput.model_validate(d1) # 从 dict 创建
5.2 自定义序列化
from pydantic import BaseModel, field_serializer, model_serializer
import torch
import numpy as np
class ModelOutputs(BaseModel):
"""包含 numpy/torch 数据的模型输出"""
logits: list[float] # 存为 Python list
hidden_state: Optional[list[list[float]]] = None
label: int
# 自定义单字段序列化
@field_serializer("logits")
def serialize_logits(self, v: list[float]) -> dict:
"""把 logits 序列化时附加统计信息"""
import math
# Softmax
exp_v = [math.exp(x) for x in v]
total = sum(exp_v)
probs = [e/total for e in exp_v]
return {
"raw": v,
"probs": probs,
"argmax": v.index(max(v)),
}
# 从 numpy/torch 创建(validate_before)
@classmethod
def from_tensor(cls, logits_tensor: "torch.Tensor", label: int) -> "ModelOutputs":
return cls(
logits=logits_tensor.detach().cpu().tolist(),
label=label,
)
六、从 Pydantic 模型自动生成 JSON Schema
这是 Pydantic 最强大的功能之一,也是 LLM 工具调用的基础。
from pydantic import BaseModel, Field
from typing import Optional, Literal
import json
class WebSearchAction(BaseModel):
"""Agent 调用网络搜索工具的参数"""
query: str = Field(..., description="搜索关键词,应该简洁精确")
num_results: int = Field(default=5, ge=1, le=20, description="返回结果数量")
language: str = Field(default="zh", description="搜索语言(zh/en)")
date_range: Optional[Literal["day", "week", "month", "year"]] = Field(
default=None, description="时间范围过滤"
)
# 自动生成 JSON Schema
schema = WebSearchAction.model_json_schema()
print(json.dumps(schema, ensure_ascii=False, indent=2))
# 输出:
# {
# "title": "WebSearchAction",
# "type": "object",
# "properties": {
# "query": {
# "title": "Query",
# "description": "搜索关键词,应该简洁精确",
# "type": "string"
# },
# "num_results": {
# "title": "Num Results",
# "description": "返回结果数量",
# "default": 5,
# "minimum": 1,
# "maximum": 20,
# "type": "integer"
# },
# ...
# },
# "required": ["query"]
# }
# 把 JSON Schema 转换为 Anthropic 工具格式
def pydantic_to_anthropic_tool(
model: type[BaseModel],
tool_name: str,
tool_description: str,
) -> dict:
"""把 Pydantic 模型转换为 Anthropic tool 定义"""
schema = model.model_json_schema()
# Anthropic 不接受 title 字段,需要清理
def clean_schema(s: dict) -> dict:
s.pop("title", None)
for prop in s.get("properties", {}).values():
prop.pop("title", None)
return s
return {
"name": tool_name,
"description": tool_description,
"input_schema": clean_schema(schema),
}
# 生成完整的工具定义
web_search_tool = pydantic_to_anthropic_tool(
WebSearchAction,
"web_search",
"在互联网上搜索信息,返回相关网页的标题和摘要",
)
print(json.dumps(web_search_tool, ensure_ascii=False, indent=2))
七、LLM 结构化输出:让 Agent 说人话,输出机器话
7.1 三种获取结构化输出的方式
import anthropic
import json
from pydantic import BaseModel, ValidationError
client = anthropic.Anthropic()
# ── 方式1:Prompt 约束(最简单,不稳定)──────────────────────
def method1_prompt_constraint(text: str) -> dict:
"""直接要求 LLM 输出 JSON(成功率约 80%)"""
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[{
"role": "user",
"content": (
f"分析以下文本的情感,以 JSON 格式输出:\n"
f"{{\"sentiment\": \"positive/negative/neutral\", "
f"\"score\": 0.0-1.0, \"reason\": \"简短解释\"}}\n\n"
f"文本:{text}\n\n"
f"只输出 JSON,不要其他内容。"
)
}]
)
raw = response.content[0].text.strip()
# 提取 JSON(LLM 可能在 JSON 前后加了其他文字)
if "```json" in raw:
raw = raw.split("```json")[1].split("```")[0].strip()
elif "```" in raw:
raw = raw.split("```")[1].split("```")[0].strip()
return json.loads(raw)
# ── 方式2:Tool Use 强制结构化(推荐,稳定)────────────────────
class SentimentOutput(BaseModel):
sentiment: str # "positive" | "negative" | "neutral"
score: float # 0.0 - 1.0
reason: str
keywords: list[str]
def method2_tool_use(text: str) -> SentimentOutput:
"""
用 Tool Use 强制 LLM 输出结构化数据
原理:LLM 被要求"调用工具",工具参数即结构化输出
成功率接近 100%
"""
tool_def = pydantic_to_anthropic_tool(
SentimentOutput,
"analyze_sentiment",
"分析文本情感,返回结构化结果",
)
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
tools=[tool_def],
tool_choice={"type": "tool", "name": "analyze_sentiment"}, # 强制使用这个工具
messages=[{
"role": "user",
"content": f"分析以下文本的情感:\n\n{text}"
}]
)
# 提取工具调用参数
tool_use_block = next(b for b in response.content if b.type == "tool_use")
raw_dict = tool_use_block.input
# 用 Pydantic 验证(工具调用基本不会出错,但验证是好习惯)
return SentimentOutput.model_validate(raw_dict)
# ── 方式3:Anthropic 原生结构化输出(如果 SDK 支持)─────────────
# (某些 SDK 版本提供 response_format 参数,类似 OpenAI)
# 使用对比
text = "这款手机的拍照效果非常出色,但电池续航令人失望。"
# 方式2(推荐)
result = method2_tool_use(text)
print(result.sentiment) # "mixed" 或 "negative"
print(result.score) # 0.35
print(result.keywords) # ["拍照", "续航"]
# 现在 result 是强类型的 Pydantic 对象,IDE 有自动补全
# 不是原始 dict,不会有 KeyError
7.2 复杂结构化输出:嵌套模型
from pydantic import BaseModel, Field
from typing import Optional, Literal
class Evidence(BaseModel):
"""单条证据"""
text: str
source: str
relevance: float = Field(ge=0, le=1)
class Claim(BaseModel):
"""研究主张"""
statement: str
evidence: list[Evidence]
confidence: float = Field(ge=0, le=1)
status: Literal["supported", "refuted", "uncertain"]
class ResearchReport(BaseModel):
"""完整研究报告"""
title: str
summary: str
claims: list[Claim]
limitations: list[str]
next_steps: list[str]
overall_confidence: float = Field(ge=0, le=1)
def generate_research_report(topic: str) -> ResearchReport:
"""
生成结构化研究报告
"""
tool_def = pydantic_to_anthropic_tool(
ResearchReport,
"output_research_report",
"以结构化格式输出研究报告,包含主张、证据和置信度",
)
response = client.messages.create(
model="claude-opus-4-20250514", # 复杂结构用更强的模型
max_tokens=4096,
tools=[tool_def],
tool_choice={"type": "tool", "name": "output_research_report"},
system="你是一位严谨的研究员。基于你的知识,对给定主题进行分析,输出结构化研究报告。每个主张必须有证据支持。",
messages=[{"role": "user", "content": f"研究主题:{topic}"}]
)
tool_block = next(b for b in response.content if b.type == "tool_use")
return ResearchReport.model_validate(tool_block.input)
# 使用
report = generate_research_report("可再生能源对全球碳排放的影响")
for claim in report.claims:
print(f"\n主张:{claim.statement}")
print(f"置信度:{claim.confidence:.0%} 状态:{claim.status}")
for e in claim.evidence:
print(f" 证据:{e.text[:80]}...")
八、结构化输出的重试机制:输出不合格自动要求重来
LLM 有时即使用了工具调用,也可能输出不符合预期的数据(比如 score 超出范围,必填字段为空)。需要一个自动重试机制。
import asyncio
import json
from pydantic import BaseModel, ValidationError
from typing import TypeVar, Type
import anthropic
T = TypeVar("T", bound=BaseModel)
async def structured_llm_call(
output_model: Type[T],
tool_name: str,
tool_description: str,
messages: list[dict],
system: str = "",
model: str = "claude-sonnet-4-20250514",
max_retries: int = 3,
temperature: float = 0.3, # 低温度,减少随机性
) -> T:
"""
结构化 LLM 调用 + 自动重试
如果 LLM 输出不符合 Pydantic 模型,自动构建错误反馈让 LLM 重试
"""
client = anthropic.AsyncAnthropic()
tool_def = pydantic_to_anthropic_tool(output_model, tool_name, tool_description)
current_messages = list(messages) # 不修改原始列表
last_error = None
for attempt in range(max_retries):
try:
kwargs = {
"model": model,
"max_tokens": 4096,
"tools": [tool_def],
"tool_choice": {"type": "tool", "name": tool_name},
"messages": current_messages,
}
if system:
kwargs["system"] = system
response = await client.messages.create(**kwargs)
# 提取工具调用
tool_block = next(
(b for b in response.content if b.type == "tool_use"),
None,
)
if tool_block is None:
raise ValueError("LLM 没有调用工具(意外的响应格式)")
# Pydantic 验证
result = output_model.model_validate(tool_block.input)
return result # 成功:直接返回
except ValidationError as e:
last_error = e
# 构建错误反馈:把验证错误告诉 LLM,要求重试
error_details = []
for err in e.errors():
field = " → ".join(str(loc) for loc in err["loc"])
error_details.append(f"字段 '{field}':{err['msg']}")
feedback = (
f"你的输出有 {len(e.errors())} 处验证错误,请修正后重试:\n"
+ "\n".join(f" {i+1}. {d}" for i, d in enumerate(error_details))
)
if attempt < max_retries - 1:
print(f"[重试 {attempt+1}/{max_retries}] 验证失败:{feedback[:100]}")
# 把错误反馈加入对话历史
current_messages = current_messages + [
{"role": "assistant", "content": response.content},
{
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": tool_block.id,
"content": feedback,
"is_error": True,
}]
},
]
except (json.JSONDecodeError, KeyError, TypeError) as e:
last_error = e
if attempt < max_retries - 1:
print(f"[重试 {attempt+1}/{max_retries}] 解析错误:{e}")
current_messages = current_messages + [{
"role": "user",
"content": f"上次输出无法解析,请重新按要求格式输出。错误:{e}"
}]
raise RuntimeError(
f"结构化输出在 {max_retries} 次尝试后仍然失败。最后的错误:{last_error}"
)
# 使用示例
async def analyze_with_retry():
class ArticleSummary(BaseModel):
title: str = Field(min_length=5)
key_points: list[str] = Field(min_length=3, max_length=7)
sentiment: Literal["positive", "negative", "neutral", "mixed"]
score: float = Field(ge=0, le=10, description="内容质量评分 0-10")
recommend: bool
result = await structured_llm_call(
output_model=ArticleSummary,
tool_name="summarize_article",
tool_description="对文章进行结构化总结,包含关键观点和质量评分",
messages=[{"role": "user", "content": "总结这篇关于深度学习发展的文章..."}],
max_retries=3,
)
print(f"标题:{result.title}")
print(f"关键点({len(result.key_points)} 条):")
for pt in result.key_points:
print(f" · {pt}")
print(f"质量评分:{result.score}/10")
print(f"推荐:{'是' if result.recommend else '否'}")
九、TypedDict 与 Protocol:Agent 接口的类型安全
9.1 TypedDict:为 dict 添加类型信息
from typing import TypedDict, Required, NotRequired
# TypedDict:让 dict 有类型约束(不做运行时验证,只供静态分析)
class MessageDict(TypedDict):
role: str # 必填
content: str # 必填
class ToolCallDict(TypedDict, total=False): # total=False:所有字段可选
id: str
name: str
input: dict
# 混合必填/可选
class AgentStepDict(TypedDict):
step: Required[int] # 必填
action: Required[str] # 必填
result: NotRequired[str] # 可选
# 用途:注解函数参数,让 IDE 知道 dict 的结构
def format_message(msg: MessageDict) -> str:
return f"[{msg['role']}] {msg['content']}"
# IDE 会对 msg['role'] 提供自动补全
# 但传错 dict 运行时不会报错(和 Pydantic 不同)
9.2 Protocol:结构化子类型(鸭子类型的类型安全版)
from typing import Protocol, runtime_checkable, Any
from abc import abstractmethod
@runtime_checkable # 允许用 isinstance 检查
class AgentTool(Protocol):
"""
任何"看起来是 Agent 工具"的对象都满足这个协议
不需要继承,只需要有这些方法(结构化子类型)
"""
name: str
description: str
def run(self, **kwargs: Any) -> str:
"""执行工具,返回字符串结果"""
...
async def arun(self, **kwargs: Any) -> str:
"""异步执行工具"""
...
# 不继承 AgentTool,但满足协议
class SearchTool:
name = "web_search"
description = "网络搜索工具"
def run(self, query: str, num_results: int = 5) -> str:
return f"搜索结果:{query}"
async def arun(self, query: str, **kwargs) -> str:
return self.run(query)
class CalculatorTool:
name = "calculator"
description = "数学计算工具"
def run(self, expression: str) -> str:
result = eval(expression) # 实际项目用安全的求值器
return str(result)
async def arun(self, expression: str, **kwargs) -> str:
return self.run(expression)
# Protocol 检查
search = SearchTool()
calc = CalculatorTool()
print(isinstance(search, AgentTool)) # True(runtime_checkable)
print(isinstance(calc, AgentTool)) # True
# 类型安全的工具注册表
def register_tool(tool: AgentTool) -> None:
"""mypy 会检查 tool 是否满足 AgentTool 协议"""
print(f"注册工具:{tool.name}")
register_tool(search)
register_tool(calc)
# register_tool("not a tool") # mypy 报错!
9.3 Generic + TypeVar:泛型 Agent 返回值
from typing import Generic, TypeVar
from pydantic import BaseModel
OutputT = TypeVar("OutputT", bound=BaseModel)
class AgentResult(Generic[OutputT]):
"""
泛型 Agent 结果容器
让调用方知道结果的具体类型
"""
def __init__(
self,
output: OutputT,
raw_text: str,
tokens: int,
retries: int = 0,
):
self.output = output
self.raw_text = raw_text
self.tokens = tokens
self.retries = retries
def __repr__(self) -> str:
return f"AgentResult(output={self.output}, tokens={self.tokens}, retries={self.retries})"
# 使用时,IDE 知道 result.output 的具体类型
async def run_agent_typed(
prompt: str,
output_model: type[OutputT],
) -> AgentResult[OutputT]:
output = await structured_llm_call(
output_model=output_model,
tool_name="output_result",
tool_description="输出结构化结果",
messages=[{"role": "user", "content": prompt}],
)
return AgentResult(output=output, raw_text="", tokens=0)
# result.output 被推断为 SentimentOutput 类型
result = await run_agent_typed("分析情感...", SentimentOutput)
print(result.output.sentiment) # IDE 有 SentimentOutput 的自动补全
十、综合实战:类型安全的完整 Agent 工具系统
把本篇所有知识点整合成一个完整的例子:
"""
typed_agent_system.py
类型安全的 Agent 工具系统:
Protocol → 工具接口定义
Pydantic → 工具输入/输出验证
TypeVar/Generic → 泛型结果容器
field_validator / model_validator → 跨字段验证
JSON Schema 自动生成 → LLM 工具调用
结构化输出重试 → 健壮性保证
"""
from __future__ import annotations
import asyncio
import json
from dataclasses import dataclass, field
from typing import Any, Generic, Literal, Optional, Protocol, TypeVar, runtime_checkable
from pydantic import BaseModel, Field, field_validator, model_validator
import anthropic
# ─── 类型定义 ─────────────────────────────────────────────────
OutputT = TypeVar("OutputT", bound=BaseModel)
@runtime_checkable
class AgentTool(Protocol):
name: str
description: str
input_model: type[BaseModel]
async def arun(self, **kwargs: Any) -> str: ...
# ─── 工具输入/输出模型 ─────────────────────────────────────────
class WebSearchInput(BaseModel):
"""网络搜索工具输入"""
query: str = Field(..., min_length=2, description="搜索查询词")
num_results: int = Field(default=5, ge=1, le=20)
lang: str = Field(default="zh", pattern=r"^[a-z]{2}$")
@field_validator("query")
@classmethod
def clean_query(cls, v: str) -> str:
return v.strip()
class CodeExecutionInput(BaseModel):
"""代码执行工具输入"""
code: str = Field(..., description="要执行的 Python 代码")
timeout: float = Field(default=30.0, gt=0, le=300)
env: dict[str, str] = Field(default_factory=dict)
@model_validator(mode="after")
def check_safety(self) -> "CodeExecutionInput":
dangerous = ["import os", "import sys", "subprocess", "__import__"]
for d in dangerous:
if d in self.code:
raise ValueError(f"代码包含不允许的操作:{d}")
return self
# ─── 工具实现 ─────────────────────────────────────────────────
class WebSearchTool:
name: str = "web_search"
description: str = "在互联网上搜索信息"
input_model: type[BaseModel] = WebSearchInput
async def arun(self, **kwargs: Any) -> str:
params = WebSearchInput(**kwargs) # 验证输入
await asyncio.sleep(0.1) # 模拟网络请求
return json.dumps([
{"title": f"结果{i}", "snippet": f"关于{params.query}的内容{i}"}
for i in range(params.num_results)
], ensure_ascii=False)
class CodeExecutionTool:
name: str = "execute_code"
description: str = "执行 Python 代码片段(安全沙箱)"
input_model: type[BaseModel] = CodeExecutionInput
async def arun(self, **kwargs: Any) -> str:
params = CodeExecutionInput(**kwargs) # 包含安全检查
try:
# 实际项目用 RestrictedPython 或 Docker 沙箱
proc = await asyncio.create_subprocess_exec(
"python", "-c", params.code,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
)
stdout, stderr = await asyncio.wait_for(
proc.communicate(), timeout=params.timeout
)
if proc.returncode == 0:
return stdout.decode()
else:
return f"执行错误:{stderr.decode()}"
except asyncio.TimeoutError:
return f"执行超时(>{params.timeout}s)"
# ─── Agent 执行器 ─────────────────────────────────────────────
@dataclass
class AgentExecutor:
tools: list[AgentTool]
model: str = "claude-sonnet-4-20250514"
max_iter: int = 10
verbose: bool = True
_client: anthropic.AsyncAnthropic = field(
default_factory=anthropic.AsyncAnthropic, init=False
)
def _build_tool_defs(self) -> list[dict]:
"""把所有工具转换为 Anthropic 工具格式"""
defs = []
for tool in self.tools:
schema = tool.input_model.model_json_schema()
schema.pop("title", None)
for p in schema.get("properties", {}).values():
p.pop("title", None)
defs.append({
"name": tool.name,
"description": tool.description,
"input_schema": schema,
})
return defs
async def run(
self,
task: str,
output_model: type[OutputT],
) -> OutputT:
"""运行 Agent,返回强类型的最终输出"""
tool_defs = self._build_tool_defs()
messages = [{"role": "user", "content": task}]
tool_map = {t.name: t for t in self.tools}
for iteration in range(self.max_iter):
response = await self._client.messages.create(
model=self.model,
max_tokens=4096,
tools=tool_defs,
messages=messages,
)
if self.verbose:
print(f"\n[迭代 {iteration+1}] stop_reason={response.stop_reason}")
if response.stop_reason == "end_turn":
# 没有工具调用:提取最终文本,再做结构化解析
final_text = next(
(b.text for b in response.content if hasattr(b, "text")), ""
)
return await structured_llm_call(
output_model=output_model,
tool_name="final_output",
tool_description="输出最终结构化结果",
messages=[{"role": "user", "content":
f"原始任务:{task}\n\n分析结果:{final_text}\n\n请输出结构化结果"}],
)
# 执行工具调用
messages.append({"role": "assistant", "content": response.content})
tool_results = []
for block in response.content:
if block.type != "tool_use":
continue
tool = tool_map.get(block.name)
if tool is None:
result_text = f"未知工具:{block.name}"
else:
if self.verbose:
print(f" 工具调用:{block.name}({block.input})")
try:
result_text = await tool.arun(**block.input)
except Exception as e:
result_text = f"工具执行失败:{e}"
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result_text,
})
messages.append({"role": "user", "content": tool_results})
raise RuntimeError(f"超过最大迭代次数 {self.max_iter}")
# ─── 使用 ─────────────────────────────────────────────────────
class MarketAnalysis(BaseModel):
"""市场分析结果"""
market: str
key_players: list[str] = Field(min_length=2)
trend: Literal["growing", "shrinking", "stable"]
confidence: float = Field(ge=0, le=1)
summary: str = Field(min_length=50)
async def main():
executor = AgentExecutor(
tools=[WebSearchTool(), CodeExecutionTool()],
verbose=True,
)
result: MarketAnalysis = await executor.run(
task="研究2026年AI芯片市场,分析主要玩家和发展趋势",
output_model=MarketAnalysis,
)
print(f"\n市场:{result.market}")
print(f"主要玩家:{', '.join(result.key_players)}")
print(f"趋势:{result.trend}(置信度 {result.confidence:.0%})")
print(f"\n摘要:{result.summary}")
asyncio.run(main())
十一、面试高频考点
Q:Pydantic V2 的 model_validator(mode="before") 和 mode="after" 有什么区别?
mode="before"在类型转换之前运行,接收原始输入数据(通常是 dict),可以修改数据结构、做类型强制转换、移除非法字段,必须是@classmethod。mode="after"在所有字段完成类型转换和验证之后运行,接收的是已经构建好的模型实例(Self),用于跨字段验证和计算派生字段,不是classmethod。
Q:为什么 dataclass 里不能用 list 作默认值,要用 field(default_factory=...)?
Python 函数和类定义时,默认参数只创建一次。如果用
list作默认值,所有实例共享同一个列表对象——修改一个实例的列表会影响所有实例(这是第一篇讲的可变对象引用问题)。field(default_factory=lambda: [])告诉dataclass为每个新实例分别创建一个新列表。
Q:TypedDict 和 Pydantic BaseModel 在运行时的本质区别是什么?
TypedDict在运行时就是普通的dict,没有任何验证,类型信息只供静态分析工具(mypy)使用;isinstance(x, SomeTypedDict)只检查是否是 dict,不检查键值类型。Pydantic BaseModel创建的是独立的类实例,在__init__时执行运行时类型验证,字段是属性(用.访问),会抛ValidationError。
Q:LLM 工具调用为什么比"要求 LLM 输出 JSON"更可靠?
要求 LLM 输出 JSON 字符串时,LLM 可能在 JSON 前后加说明文字、使用中文键名、遗漏必填字段、数值用字符串表示。工具调用时,LLM 被要求填写"函数调用的参数",这在训练时有专门的格式强化,参数直接以结构化形式返回,不经过字符串拼接,格式合规率接近 100%。
Q:Protocol 和抽象基类(ABC)有什么区别?
ABC要求显式继承(class MyTool(AgentToolABC)),是"标称子类型"(nominal subtyping)。Protocol不需要继承,只要有相同签名的方法就满足协议,是"结构化子类型"(structural subtyping),Python 的"鸭子类型"的类型安全版本。Protocol更灵活——第三方库的类不需要修改就能满足你定义的 Protocol;ABC更明确——让代码的意图更清晰。
预告:第六篇(收官)
《Python × 深度学习 × Agent 系列·第六篇(收官):性能与部署——cProfile 性能分析、推理优化、并发模型服务,让 Agent 又快又稳》
将要覆盖:
cProfile+line_profiler:找到真正的性能瓶颈(不靠感觉)- Python 内存管理:
tracemalloc、内存泄漏排查 - 模型推理优化全套:量化、
torch.compile、TensorRT、batching - 并发模型服务:多进程 + 请求队列 + 动态批处理
- 生产监控:Prometheus + Grafana 接入、异常报警
💬 你在 Agent 项目中是怎么处理 LLM 输出格式不对的情况的? 欢迎评论区聊!
🙏 如果这篇帮到你,一键三连(点赞👍 + 收藏⭐ + 关注)!收官篇即将发布!
本文为原创技术分享。转载请注明出处。最后更新:2026-05-14

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献245条内容
已为社区贡献245条内容

所有评论(0)