了解Redis
一、Redis 是什么?(精准定义)
Redis(Remote Dictionary Server),即远程字典服务。
它是一款开源、基于内存、高性能、键值对(Key-Value)NoSQL 数据库。
核心特征一句话总结:
数据主要存在内存中,读写极快,支持多种数据结构、支持持久化、支持高可用集群的分布式缓存数据库。
1.1 Redis 核心特性
-
纯内存操作:绝大多数数据读写在内存完成,速度极快
-
丰富数据结构:String、List、Hash、Set、ZSet、Geo、Bitmap、HyperLogLog 等,基于丰富的数据结构实现复杂的业务逻辑
-
支持持久化:RDB/AOF,重启不丢数据
-
高可用:主从、哨兵、Cluster集群
-
原子性操作:单条命令天然具备原子性,无需额外加锁,可快速实现分布式锁、并发计数等场景,是Redis高并发安全操作的核心基础
-
高性能、低延迟:单机QPS可达10W+
二、Redis 的核心作用(企业真实场景)
Redis 不是简单缓存,它在企业中承担八大核心场景:
2.1 热点数据缓存(最核心)
缓存高频查询、低变动数据,减少 MySQL 压力。
例如:首页banner、商品列表、用户信息、配置信息。
2.2 分布式锁
利用 SET NX EX 原子命令,实现分布式锁,解决并发抢资源问题。
场景:秒杀、下单、幂等控制、防止重复提交。
2.3 限流 & 防刷
利用过期key、计数器、漏斗算法,窗口统计算法,实现接口限流、IP防刷。
2.4 排行榜、延时队列、消息队列
-
ZSet 实现排行榜
-
List 实现简单消息队列
-
ZSet 实现延时队列
2.5 会话共享、登录态存储
分布式系统中统一存储 Session、Token,实现多服务登录共享。
2.6 计数器 & 统计数据
文章阅读量、点赞数、访问次数,高性能自增。
2.7 地理位置计算
Geo 实现附近的人、附近门店、距离计算。
2.8 位图统计
Bitmap 实现签到统计、活跃用户、状态标记,极度省内存。
三、Redis 单线程模型(重点、面试必考)
3.1 Redis 为什么是单线程?
Redis 核心命令执行模型是单线程。
指的是:所有客户端的读写命令、数据解析、键值操作,都由同一个主线程串行执行。
3.2 单线程核心机制
-
一个线程负责:接收连接、解析命令、执行命令、返回结果
-
所有命令排队执行,不存在多线程竞争
-
天然线程安全,不需要锁、无锁竞争、无上下文切换开销
3.3 单线程为什么还能这么快?
-
纯内存操作:没有磁盘IO,速度本身极快
-
单线程无锁开销:不需要加锁、解锁、线程切换
-
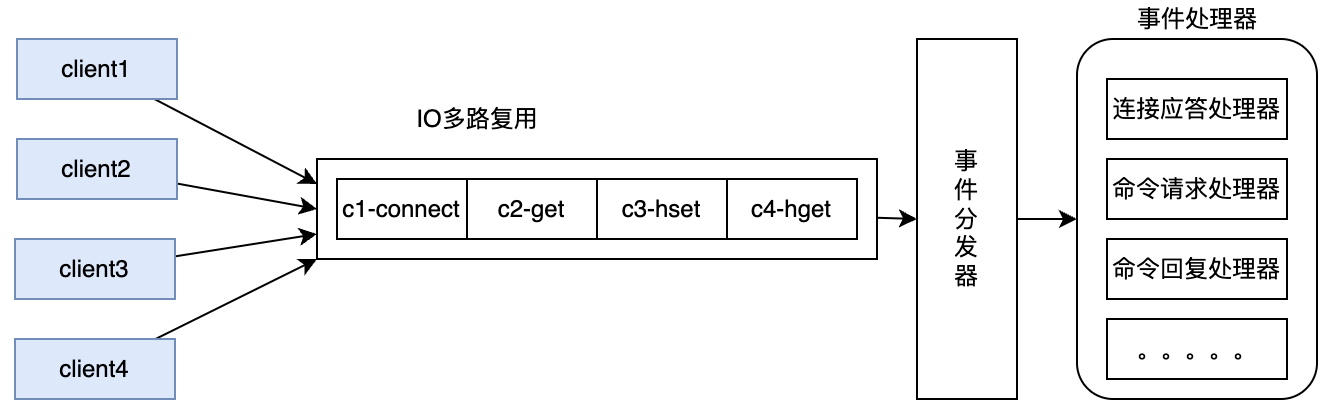
IO多路复用:epoll 实现单线程监听上万连接
-
命令执行轻量:Redis 命令都是简单内存运算
-
避免CPU上下文切换,效率极高
-
底层数据结构更加贴近机器语言:运行无需复杂转换数据类型,运行效率高
3.4 单线程的缺点
核心痛点:CPU 单核瓶颈、大命令阻塞
-
单线程只能利用一个CPU核心
-
遇到 大Key、慢命令(keys、flushall、超大hash遍历)会阻塞整个线程
-
一旦阻塞,所有请求全部卡顿
四、Redis6.0 / 7.0 多线程原理
高频误区:Redis 6 改成多线程了?是不是不再单线程了?
标准答案:核心命令执行依旧是单线程,没有改变!
4.1 Redis 多线程到底多了什么?
Redis6+ 引入的是:IO 多线程,不是命令执行多线程。
多线程只负责:
-
网络请求读取(read)
-
网络响应写入(write)
命令解析、数据读写、业务执行,依然是单线程串行执行。
4.2 为什么不把命令改成多线程?
如果命令多线程,会出现:
-
多线程竞争内存数据,必须加锁
-
锁冲突、上下文切换,性能反而下降
-
失去 Redis 简单、高效、线程安全的优势
4.3 多线程带来的提升
解决了网络IO瓶颈,在高并发连接场景下吞吐量更高,但是命令执行效率不变、线程安全机制不变。
五、Redis 线程模型总结(终极结论)
5.1 Redis 4.x 及以前
完全单线程:IO + 命令执行全部单线程
5.2 Redis 4.0 开始:后台多线程(异步任务)
4.0 引入 bio 线程池(Background I/O),专门做 “耗时、可异步、不阻塞主线程” 的事:
1. 惰性删除(Lazy Free)
UNLINK(替代DEL大 key)- 过期键、被淘汰键的异步内存释放
- 大 Hash/List/ZSet 直接删会卡主线程,交给 bio 线程慢慢删
2. 持久化相关(后台线程 / 子进程)
- BGSAVE(RDB):
fork()子进程做,主线程继续干活 - BGREWRITEAOF:子进程重写 AOF,避免 AOF 膨胀
- AOF 刷盘:
appendfsync everysec时,有后台线程负责 fsync
3. 其他后台任务
- 主从复制:RDB 传输、全量同步 子进程 / 线程做
- 集群:槽位迁移、数据同步 多线程 / 异步处理
- 关闭时的数据落盘、资源回收
5.2 Redis 6.x / 7.x / 8.x
IO多线程 + 命令单线程
-
网络读写:多线程(提速)
-
命令执行:单线程(保证安全、无锁、稳定)
分工:
- 主线程:
epoll监听连接、分发 socket 给 IO 线程 - IO 线程池:并行做 → 读 socket、解析 RESP、写响应回 socket
- 主线程:拿到解析好的命令,串行执行,再丢回 IO 线程写回
重点:多线程只做 I/O + 解析,命令执行还是单线程,无锁、安全。
六、Redis 原子性操作深度详解
6.1 原子性核心定义
原子性指一个操作不可分割、要么全部执行成功,要么全部执行失败,不会出现中间状态。Redis 依托自身线程模型,拥有天然的命令原子性,这也是Redis能实现分布式锁、并发控制的核心根本。
6.2 Redis原子性底层原理
结合前文线程模型可完美解释Redis的原子性本质:
Redis 核心命令执行为单线程串行机制,所有客户端的命令请求会进入统一队列排队执行,同一时刻只会执行一条命令,不存在多条命令并发执行、抢占资源的情况。
这就意味着:单条Redis命令从解析、执行、数据写入到返回结果,全程不会被其他命令打断,天然规避了并发竞争问题,无需依赖操作系统锁、业务锁,即可保证操作原子性。
6.3 原子性覆盖范围(重点误区)
-
✅ 单条命令:完全原子性:set、get、incr、hset、zadd 等所有单指令,均具备完整原子性
-
❌ 多条普通命令:不具备原子性:多条独立命令(如先get再set)会被其他请求插队,无法保证事务一致性,存在并发安全问题
6.4 扩展:实现多命令原子性方案
针对多条命令需要保证原子性的业务场景,Redis提供两种官方解决方案,弥补单命令局限性:
6.4.1 Redis事务(MULTI/EXEC)
通过 MULTI 开启事务,批量录入多条命令,最后通过 EXEC 一次性执行,执行过程中不会被其他客户端命令打断,保证批量命令串行隔离执行。重点核心:Redis 事务不支持数据库级别的自动回滚,这是Redis事务与MySQL事务最大的区别。
Redis事务两种异常场景 & 回滚解决方案(生产必知)
1. 入队阶段异常(语法错误、参数错误)
场景:MULTI开启事务后,录入的命令存在语法错误、参数缺失、非法指令。
机制:Redis 会直接标记事务失败,本次事务所有命令全部作废,自动不执行,等同于隐性回滚。
示例:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 1
QUEUED
127.0.0.1:6379> # 输入错误指令
127.0.0.1:6379> set
(error) ERR wrong number of arguments for 'set' command
127.0.0.1:6379> EXEC
(error) EXECABORT Transaction discarded because of previous errors.结论:语法错误 → 事务整体作废,无需手动回滚。

2. 执行阶段异常(运行时错误、数据类型错误)
场景:命令语法正确、成功入队,但EXEC执行时出现运行时异常(例如对String类型执行List操作、数值溢出等)。
机制:错误命令执行失败,不影响其他正常命令,事务不会自动回滚,成功的命令会永久写入数据,造成数据不一致!
这是Redis事务最大的坑,也是生产不推荐普通事务做一致性操作的核心原因。
3. 事务异常手动回滚方案(生产落地)
由于Redis无自动回滚机制,业务必须自行实现补偿回滚,标准解决方案:
-
前置数据备份:执行事务前,读取本次要修改的Key旧值,缓存至内存
-
执行结果校验:EXEC执行后,捕获异常、校验执行结果
-
失败逆向补偿:若出现运行时异常,利用备份的旧值重新覆盖恢复数据,完成手动回滚
最优替代方案:复杂一致性场景放弃Redis原生事务,统一使用Lua脚本。Lua脚本执行出错时,整体终止、不保留中间数据,天然实现事务回滚效果,无需手动补偿。
6.4.2 Lua脚本(生产首选、终极原子方案)
Lua脚本是Redis官方提供的服务端脚本编程语言,也是企业生产中解决Redis复杂多命令原子操作、并发竞争、数据一致性问题的终极方案。相比于原生事务和管道,Lua脚本兼具原子性、高性能、无中间脏数据、支持复杂逻辑四大优势,是面试最高频、生产最常用的核心功能。
6.7.1 Lua脚本底层执行原理
Redis 主线程在执行Lua脚本时,会将整个脚本代码视为一条完整、不可分割的命令执行,全程独占主线程资源。
执行核心机制:
-
脚本执行期间,禁止其他任何客户端命令插队;
-
脚本内所有逻辑、多命令、条件判断、循环操作串行执行;
-
脚本未执行完毕,不会切换任务,不会被抢占;
-
脚本执行结束后,统一释放执行权。
依托Redis单线程模型,Lua脚本天然拥有强事务原子性。
6.7.2 Lua脚本原子性与异常回滚机制(重点)
这是Lua脚本吊打原生事务的核心原因,也是面试必背考点。
1. 执行成功
脚本内所有命令全部执行生效,数据一致性完整保障。
2. 执行异常(语法错误、运行时报错、逻辑异常)
Lua脚本天然支持整体回滚:脚本一旦出现异常,脚本内已经执行的所有操作全部作废、自动回滚,不会遗留脏数据,不存在Redis原生事务“部分成功、部分失败”的数据不一致问题。
一句话区别:
Redis事务:运行报错不回滚 → 脏数据;Lua脚本:运行报错整体回滚 → 数据一致
6.7.3 Lua脚本核心优势(对比事务/管道)
-
强原子性+自动回滚:唯一可以在Redis中实现完整事务一致性的方案
-
减少网络IO开销:多命令逻辑封装在服务端执行,无需多次网络往返,媲美Pipeline性能
-
服务端计算:可在Redis端做判断、比对、计算,减少客户端数据传输与逻辑压力
-
避免并发插队:彻底杜绝多客户端并发导致的数据覆盖、超卖、计数错乱问题
-
可复用、可缓存:支持脚本SHA1缓存,重复执行无需重复传参,性能更高
6.7.4 Lua脚本生产实操案例(秒杀扣库存、防超卖)
经典场景:高并发秒杀,校验库存 + 扣减库存,杜绝超卖,原生事务无法完美实现,Lua脚本可极简落地。
Lua脚本代码
-- 获取当前库存
local stock = tonumber(redis.call('get', 'seckill:stock'))
-- 库存判断:库存不足直接返回0,不扣减
if not stock or stock <= 0 then
return 0
end
-- 库存充足,扣减库存
redis.call('decr', 'seckill:stock')
-- 返回成功标识
return 1Java调用执行
public boolean seckill() {
String luaScript = "local stock = tonumber(redis.call('get', 'seckill:stock')) " +
"if not stock or stock <= 0 then return 0 end " +
"redis.call('decr', 'seckill:stock') return 1";
// 执行Lua脚本
Long result = (Long) jedis.eval(luaScript, 0);
// 1成功 0失败
return result == 1;
}原理:整个校验+扣库存逻辑在Redis服务端原子执行,无中间状态、无并发插队、无超卖,异常自动回滚。
6.7.5 Lua脚本SHA1缓存优化
频繁执行长脚本会增加网络传输开销,Redis支持脚本缓存:
-
script load:加载脚本,返回SHA1摘要
-
evalsha:通过SHA1值执行缓存脚本
大幅减少流量损耗,适合高频秒杀、限流场景。
6.7.6 Lua脚本生产严格注意事项(避坑)
-
禁止Lua脚本写死循环:Lua独占主线程,死循环会直接导致Redis全局阻塞、服务不可用
-
禁止超大耗时逻辑:复杂计算、大量遍历放在业务端,不要压入Lua
-
脚本尽量短小精悍:保证快速执行、快速释放主线程
-
集群环境保证Key在同一槽位:Cluster集群下Lua操作多Key必须保证槽位一致,否则报错
-
统一异常处理:利用Lua自动回滚特性,无需业务手动补偿数据
6.7.7 Lua脚本、事务、Pipeline 终极选型规范
-
仅批量提速、无需原子 → 优先 Pipeline
-
简单多命令、低并发、可容忍少量不一致 → 可选原生事务MULTI/EXEC
-
高并发、强一致性、防超卖、分布式锁、限流 → 必选Lua脚本
6.5 原子性核心生产场景
-
分布式锁:SET key value NX EX 原子命令,并发场景下只有一个客户端能创建成功,避免锁竞争失效
-
并发计数:incr/decr 原子自增自减,实现点赞、浏览量、订单计数,杜绝并发计数错乱
-
接口限流防刷:通过原子计数+过期key,精准统计单位时间请求次数,无并发统计误差
-
秒杀扣库存:结合Lua脚本原子校验库存、扣减库存,超卖问题彻底解决
6.6 原子性常见面试误区总结
-
误区1:Redis所有操作都原子性 → 纠正:仅单命令、事务、Lua脚本具备原子性,多条普通命令不保证
-
误区2:Redis多线程会破坏原子性 → 纠正:IO多线程仅负责网络读写,命令执行依旧单线程,原子性完全不受影响
-
误区3:Redis事务支持自动回滚 → 纠正:Redis事务无自动回滚机制,仅语法错误整体作废,运行时错误数据会脏写,需业务手动补偿回滚;Lua脚本支持天然自动回滚,是生产首选
七、Redis Pipeline 管道操作深度详解
在Redis高频优化手段中,管道Pipeline是提升批量命令执行效率的核心方案,常和原子性、Lua脚本对比考察,是面试+生产高频知识点。很多开发者混淆管道与原子事务的区别,本节彻底讲透管道原理、使用场景与实操。
7.1 管道操作核心定义
Redis Pipeline(管道)是一种批量命令优化机制,允许客户端一次性将多条命令打包发送给Redis服务端,服务端批量执行后,统一一次性返回所有执行结果,无需每条命令进行一次网络交互。
简单来说:打包发送、批量执行、统一返回,大幅减少网络IO开销。
7.2 传统单条命令 VS 管道命令(核心差异)
7.2.1 普通逐条执行
每一条命令都需要经历:客户端发送网络请求 → 服务端处理 → 服务端返回结果,100条命令就需要100次网络往返(RTT)。网络延迟是Redis批量操作的最大瓶颈,而非命令执行速度。
7.2.2 Pipeline管道批量执行
客户端将多条命令缓存至本地,一次性发送给Redis,服务端按顺序逐条执行,最后统一返回全部结果。无论多少条命令,仅需1次网络RTT,极大降低网络开销,批量操作性能提升数倍至数十倍。
7.3 管道底层执行原理
结合Redis单线程模型,管道执行流程清晰易懂:
-
客户端本地缓存多条Redis命令,不单独发送;
-
所有命令打包,一次性发送至Redis服务端;
-
Redis单线程串行、按顺序逐条执行所有命令;
-
全部命令执行完毕后,统一返回所有结果;
-
客户端统一解析结果,完成批量操作。
7.4 管道的核心特性(重点面试考点)
7.4.1 无原子性(最核心特点)
Pipeline 不保证原子性!这是和事务、Lua脚本最大的区别。
管道内的多条命令允许被其他客户端命令插队,命令之间不隔离、不独占主线程。如果中间某条命令执行失败,不会回滚,后续命令会继续执行,仅终止当前错误命令,不影响整体流程。
7.4.2 有序执行
管道内的命令严格按照客户端提交顺序串行执行,不会乱序,保证执行顺序一致性。
7.4.3 仅优化网络IO,不提升命令执行速度
管道只是减少了网络往返次数,单条命令的执行速度没有任何提升,提速的本质是规避了频繁网络IO的耗时损耗。
7.5 Pipeline 实操代码示例(Java)
以下为Jedis管道实操案例,批量写入1000条数据,对比逐条写入性能差异:
// 获取Redis连接
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 开启管道
Pipeline pipeline = jedis.pipelined();
// 批量打包命令(本地缓存,无网络请求)
for (int i = 1; i <= 1000; i++) {
pipeline.set("user:info:" + i, "user_" + i);
pipeline.expire("user:info:" + i, 3600);
}
// 一次性提交执行,统一返回结果
pipeline.sync();
// 关闭资源
pipeline.close();
jedis.close();实操结论:1000条数据写入,逐条执行耗时数百毫秒,管道执行仅需十几毫秒,性能提升巨大。
7.6 管道、事务、Lua脚本 三者核心对比
|
特性 |
Pipeline管道 |
Redis事务(MULTI/EXEC) |
Lua脚本 |
|---|---|---|---|
|
原子性 |
❌ 不支持 |
✅ 支持(无回滚) |
✅ 完全支持 |
|
命令插队 |
允许其他命令插入 |
不允许插队 |
不允许插队 |
|
性能优势 |
减少网络IO,批量极速 |
无网络优化,仅保证原子 |
兼具原子性+批量高性能 |
|
异常回滚 |
不回滚,后续继续执行 |
语法错误失效,运行错误不回滚 |
出错整体终止,无中间状态 |
|
适用场景 |
批量增删改、无需原子一致性 |
简单多命令原子操作 |
复杂并发、强原子性场景 |
7.7 管道生产适用场景
-
批量数据初始化:批量写入缓存数据、预热热点数据
-
批量过期设置:统一为大量key设置过期时间
-
批量删除数据:清理过期缓存、无效数据
-
非一致性批量统计:批量查询、批量计数,无需强事务
7.8 管道生产禁忌与注意事项
-
禁止超大批量打包:单次管道命令过多会导致缓存溢出、服务端一次性处理压力过大,建议拆分批次(单次100-500条最佳)
-
强一致性场景禁用:秒杀、锁竞争、库存扣减等需要原子性的场景,不能用管道
-
管道内禁止穿插复杂逻辑:所有命令必须提前打包,不可边执行边判断业务逻辑
-
失败无重试机制:管道命令出错不会自动回滚,业务需自行处理异常数据
7.9 管道高频面试误区总结
-
误区1:Pipeline 具备原子性 → 纠正:管道无原子性,仅做网络优化,命令可被插队、出错不回滚
-
误区2:管道提升命令执行速度 → 纠正:仅减少网络往返,命令执行本身速度不变
-
误区3:管道可以替代事务/Lua → 纠正:无原子性,无法替代强一致性事务场景
八、生产核心注意事项
-
禁止慢命令:keys、hgetall、flushall、大量循环遍历
-
禁止大Key:大String、超大Hash/List,极易阻塞主线程
-
利用多线程优势:高并发场景开启io-threads,提升网络吞吐
-
CPU单核高频:Redis 占用CPU100%通常是主线程阻塞导致
-
规范原子性使用:并发场景优先使用单命令或Lua脚本,杜绝先查后改的非原子操作,防止并发Bug
-
批量操作优先管道:无原子需求的批量读写,统一使用Pipeline,大幅优化Redis性能
-
区分管道与原子组件:批量提速用Pipeline、简单原子用事务、复杂高并发原子用Lua脚本
九、总结
Redis 是一款高性能内存键值对NoSQL数据库,主要用于热点缓存、分布式锁、限流、计数器、消息队列等场景。Redis 核心命令执行为单线程模型,依托单线程串行执行的特性,天然实现单命令原子性,无需额外加锁,规避并发竞争问题;基于内存操作、IO多路复用、无锁竞争实现超高并发;Redis6.0之后引入IO多线程,仅优化网络读写流程,命令执行依旧保持单线程,既保证了线程安全和操作原子性,又提升了高并发网络吞吐能力,复杂并发场景可通过事务或Lua脚本实现多命令原子操作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)