什么是Agent
前两章讲了大模型的底层逻辑,也讲了怎么写好 Prompt。到现在,你已经知道大模型是个"超级大脑",能理解意图、会逻辑推理、能生成高质量内容。
但它只有嘴、没有手:它能说"你应该查一下慢查询日志",但它自己查不了;它能分析"这个 API 可能是瓶颈",但它发不了报警、关不了开关、也打不开任何一个文件。
学会了 Prompt,你能精准控制大模型的输出,但有一个问题 Prompt 解决不了:就算大模型能给出完美的分析,它依然没法主动去查数据库、发通知、调用 API。“说得再好”,也只是在说。
这就是 Agent 要解决的问题:让大模型从"只能说"变成"能干"。
什么是 Agent?
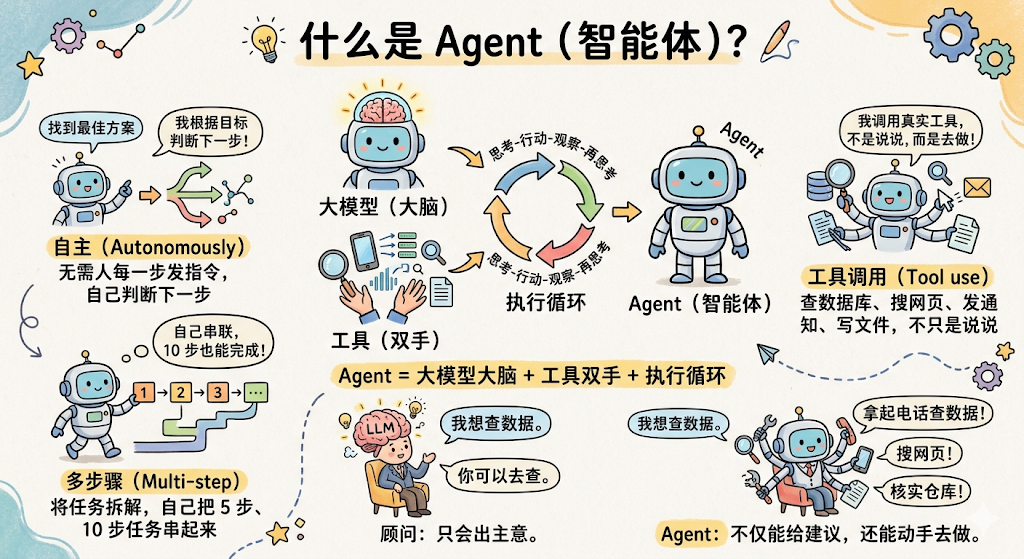
Agent(智能体) ,是一个以大模型为"大脑",能自主感知环境、做出决策、调用工具、完成多步骤任务的程序。
拆开来看几个关键词:
-
自主(Autonomously) :不需要人在每一步发指令。你给它一个目标,它自己判断下一步做什么
-
多步骤(Multi-step) :一个任务可能要走 5 步、10 步,Agent 自己把这些步骤串起来
-
工具调用(Tool use) :调用真实的函数,查数据库、搜网页、发通知、写文件,不只是"说说",而是真的去做
用一个类比帮你建立直觉:
大模型单独使用,相当于一个坐在椅子上只会出主意的顾问。你问什么他答什么,但他不会起身去做任何事。Agent 是给这个顾问配了一双手:他不仅能给建议,还能拿起电话查数据、发邮件、去仓库核实情况,然后根据新信息继续推进。
一句话总结: Agent = 大模型(大脑)+ 工具(双手)+ 执行循环(思考-行动-观察-再思考)
为什么需要 Agent
之前我们说过大模型的三大短板:
-
没有执行能力 :只能生成文字,不能操作外部系统
-
知识有截止日期 :不知道最新数据,看不到你的私有系统
- 没有持久记忆 :每次调用对它都是全新的,不能积累任务中间状态
举一个真实的 OnCall 场景:「数据库今晚 23:00 报警,帮我查清楚原因」
大模型单独面对这个任务能做什么?只能说"可能是慢查询、可能是连接池满、可能是锁争用……",它根本拿不到你的报警日志,查不了慢查询记录,也看不到当时的系统状态。 没有 Agent,大模型只是个猜测机。
那传统脚本能解决这个问题吗?也不行,方向不一样。
传统脚本和 Workflow 是写死的逻辑,“如果 CPU > 80% 就发警报,如果连接超时就重启服务”。这些流程是你提前写好的,遇到没预料到的情况,它们不知道该怎么办。一个新类型的故障,脚本一行代码都没有,Workflow 一个分支都没有,就是束手无策。
Agent 的价值在于:把大模型的 灵活推理能力 和真实工具的 执行能力 结合在一起,让系统能处理那些 你没法提前穷举所有情况 的复杂任务。
Agent 的核心组成
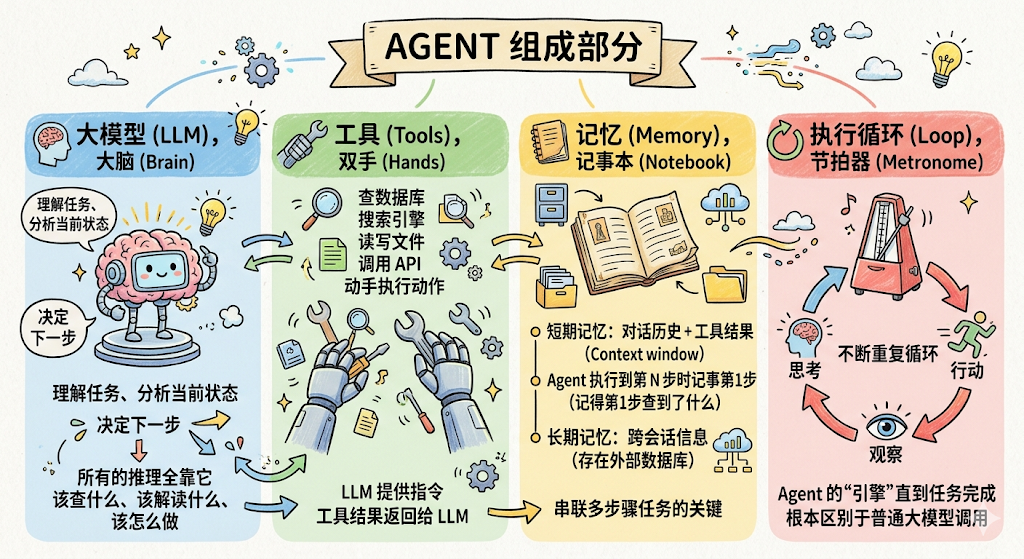
Agent 由四个组件构成,缺一不可:
- 大模型(LLM),大脑
负责理解任务、分析当前状态、决定下一步做什么。所有的"推理"都在这里发生,该查什么、查完之后怎么解读、下一步往哪走,全是大模型来判断。
- 工具(Tools),双手
一个个可以被调用的真实函数:查数据库、调用搜索引擎、读写文件、发通知、调用 API……
大模型告诉 Agent “调用这个工具、传这些参数”,代码层面真正去执行。工具的结果会返回给大模型,供它继续推理。大模型不"直接"操作外部系统,它通过工具来"动手"。
- 记忆(Memory),记事本
-
短期记忆 :当前任务里的对话历史 + 每次工具调用的结果,存在 context window 里。Agent 执行第 5 步时,"记得"第 1 步查到了什么,靠的就是这个
-
长期记忆 :跨会话需要记住的信息,存在外部数据库,需要时检索出来注入 context
为什么需要记忆?多步骤任务里,每一步的结果都是下一步判断的依据。没有记忆,每步都是"从零开始",Agent 根本没法串联多步骤任务。
- 执行循环(Loop),节拍器
Agent 的"引擎"。不断重复"思考 → 行动 → 观察"这个循环,直到任务完成。没有这个循环,Agent 只是一次性的问答,无法串联多步骤。这个循环是 Agent 和普通大模型调用之间最根本的区别。
Agent 是怎么工作的,ReAct 循环
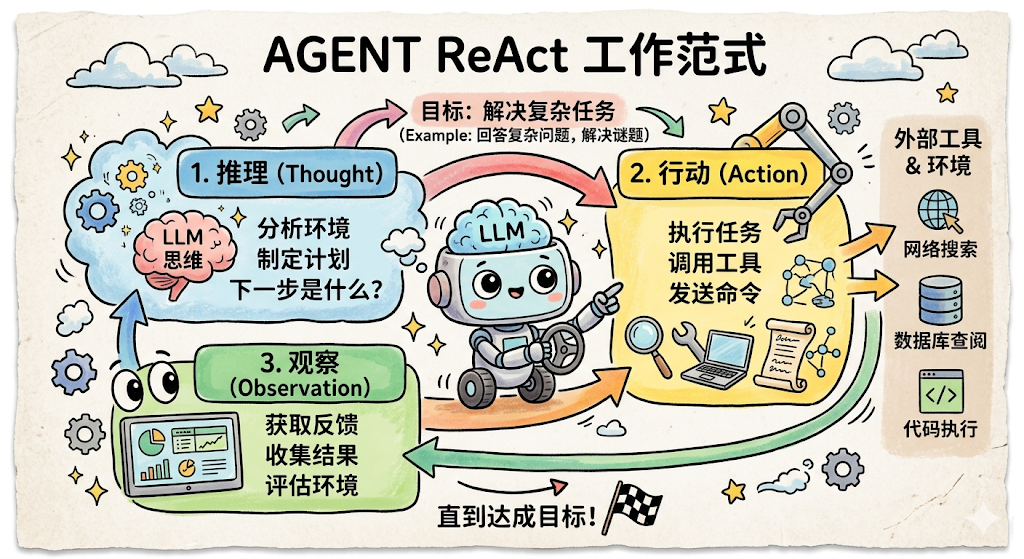
目前最主流的 Agent 工作范式叫做 ReAct ,全称 Reasoning + Acting: 推理(Think)→ 行动(Act)→ 观察(Observe)→ 再推理……
用一个完整的 OnCall 场景走一遍:
用户:帮我调查今晚 23:00 的数据库报警
[第 1 轮]
Think:需要先拿到具体的报警详情
Act:调用 get_alarm_details(time="23:00")
Observe:返回"连接数突增,连接池耗尽,持续 8 分钟后自动恢复"
[第 2 轮]
Think:连接数突增,需要看是哪些查询造成的
Act:调用 query_slow_log(timerange="22:50-23:10")
Observe:发现 3 条全表扫描的慢查询,来自同一个用户 ID
[第 3 轮]
Think:根因已经清楚,生成分析报告
Act:输出最终分析结论(Final Answer)
几个关键机制:
-
结果回流 :每一轮的工具调用结果都会追加到 context window 里,大模型下一轮能"看到"所有历史。所以它能基于已有发现继续推理,而不是每次都从零开始。这就是为什么前面"记忆"那个组件如此重要。
-
动态决策 :每一步该怎么走,是大模型实时推理出来的,不是你提前写好的。发现是慢查询,它就去查慢查询日志;如果发现是网络问题,它就会去查网络相关的工具。路径是活的,不是死的。
-
何时停止 :大模型判断任务已完成时输出"最终答案",或者达到预设的最大轮数上限。两个条件任意满足一个,循环结束。
这就是"自主"的含义,你给任务目标,它自己决定怎么走到终点。
Agent 的另一种工作模式,Plan and Execute
ReAct 很好用,但有一个先天的弱点。
ReAct 是「边想边做」,每一步只看眼前,这一步的结果决定下一步的方向。对于 2-3 步能解决的短任务,这完全没问题。但如果任务很复杂、步骤很多呢?
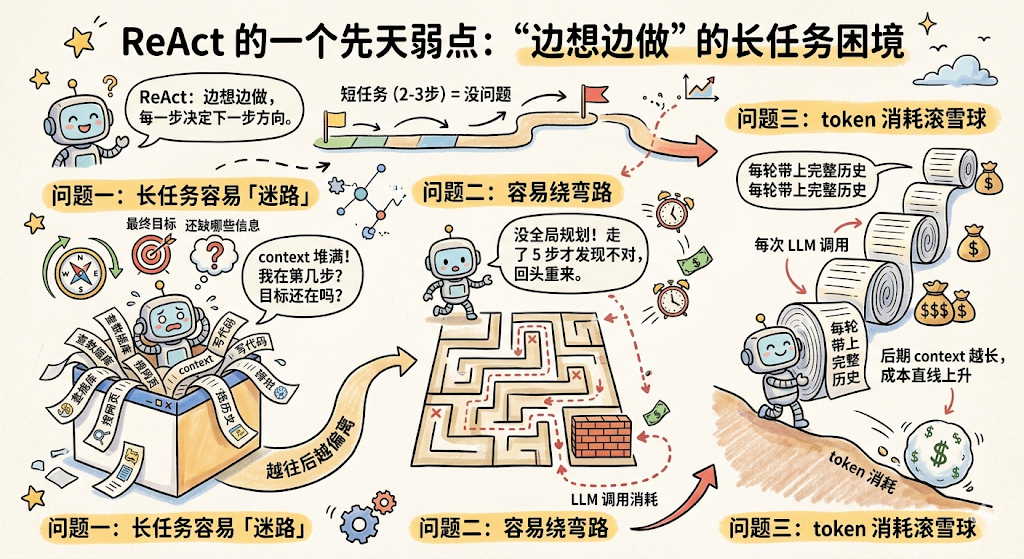
问题一:长任务容易「迷路」
ReAct 跑了 8 轮之后,context window 里已经堆满了历史操作记录。大模型要在这一大堆信息里同时维持「当前在第几步」「最终目标是什么」「还缺哪些信息」,注意力越来越稀释,越往后越容易偏离最初的目标。
问题二:容易绕弯路
没有全局规划,每步只看眼前,就像在迷宫里随机探索,走了 5 步之后才发现方向不对,只能回头重来,白白消耗了好几轮 LLM 调用。
问题三:token 消耗滚雪球
ReAct 每一轮都要把完整的对话历史带上。步骤越多,每轮的 context 越长,后期每次 LLM 调用的 token 消耗都很高,成本直线上升。
这三个问题催生了另一种工作模式: Plan and Execute(规划-执行模式) 。
核心思路用一句话说清楚: 先让大模型把整个任务规划成一份清单,再逐步按清单执行,而不是走一步看一步。
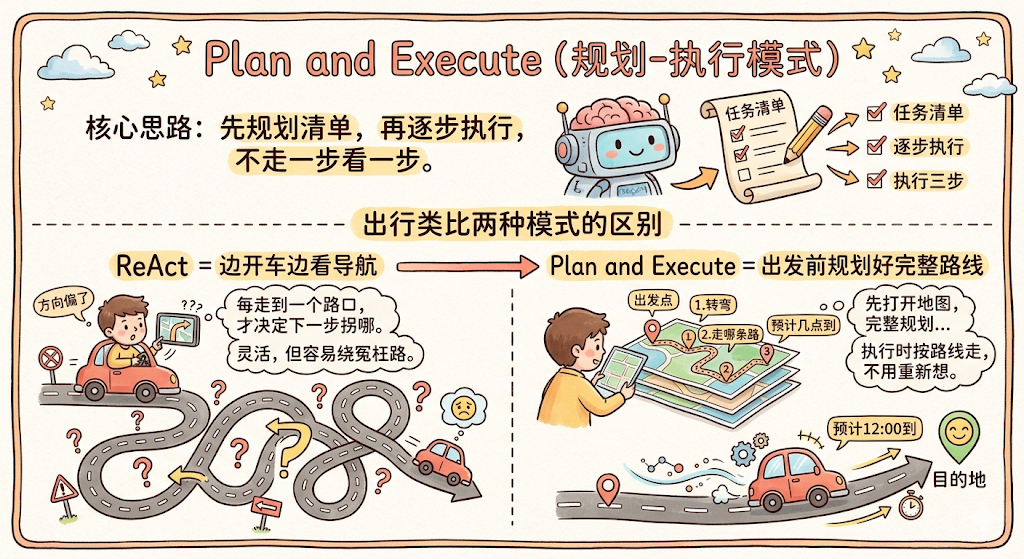
用出行来类比两种模式的区别:
-
ReAct = 边开车边看导航 :每走到一个路口,才决定下一步拐哪。灵活,但如果最开始方向就偏了,容易绕很多冤枉路
-
Plan and Execute = 出发前规划好完整路线 :先打开地图,把走哪条路、哪里转弯、预计几点到全部规划好,再出发。执行时按路线走,不用每个路口重新想
Plan and Execute 的两个阶段
第一阶段:Planner(规划阶段)
大模型拿到任务,先不调任何工具,专注做一件事: 把任务完整拆解成一份有序的子任务清单 。
用户:「帮我调查今晚 23:00 的数据库报警,写一份完整的故障分析报告」
用户:「帮我调查今晚 23:00 的数据库报警,写一份完整的故障分析报告」
Planner 输出的计划:
步骤 1:获取 23:00 报警的详细信息(报警类型、持续时间、影响范围)
步骤 2:查询报警时间段内的慢查询日志,定位异常 SQL
步骤 3:查询报警时间段内的数据库连接数、CPU、内存指标
步骤 4:关联步骤 2 和步骤 3 的结果,分析根因
步骤 5:生成完整的故障分析报告,包含时间线、根因和改进建议
第二阶段:Executor(执行阶段)
计划有了,开始逐步执行。每个步骤可以是一次简单的工具调用,也可以是一个小的 ReAct 循环,步骤复杂就跑几轮,步骤简单就一步到位。

执行步骤 1:
→ 调用 get_alarm_details(time="23:00")
← 返回「连接数突增,连接池耗尽,持续 8 分钟后自动恢复」
执行步骤 2:
→ 调用 query_slow_log(timerange="22:50-23:10")
← 发现 3 条全表扫描的慢查询,来自同一个用户 ID
执行步骤 3:
→ 调用 get_db_metrics(timerange="22:50-23:10")
← CPU 正常,连接数峰值达到上限 500,内存无异常
执行步骤 4:
→ 大模型综合步骤 2、3 结果进行分析
← 结论:慢查询导致连接长时间占用,连接池耗尽触发报警
执行步骤 5:
→ 生成故障分析报告
← 完整报告输出,任务完成
还有一个重要机制: Re-planning(重新规划) 。执行中途如果遇到了计划没预料到的情况,比如步骤 2 查不到慢查询,但发现了大量锁等待,Executor 可以把这个新信息反馈给 Planner,重新生成后续步骤的计划,而不是一条路走到黑。
用一张图把整个流程串起来:
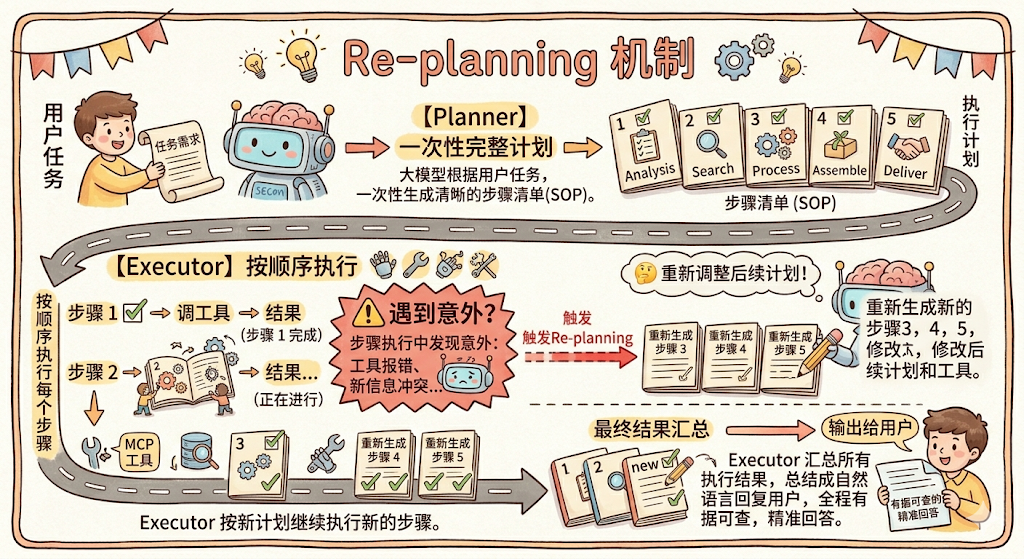
用户任务
↓
[Planner] 大模型一次性生成完整计划
↓
执行计划 = [步骤1, 步骤2, 步骤3, 步骤4, 步骤5]
↓
[Executor] 按顺序执行每个步骤
步骤1 → 调工具 → 结果
步骤2 → 调工具 → 结果 ← 遇到意外?触发 Re-planning,重新调整后续计划
步骤3 → 调工具 → 结果
...
↓
最终结果汇总 → 输出给用户
ReAct vs Plan and Execute:怎么选?
| 对比维度 | ReAct | Plan and Execute |
|---|---|---|
| 决策时机 | 每一步实时决策 | 开始前一次性规划 |
| 全局视野 | 弱(只看当前这步) | 强(提前看到全貌) |
| 灵活性 | 强(随时根据结果调整) | 弱(计划一旦生成,调整成本高) |
| 适合任务步骤 | 少(3 步以内) | 多(5 步以上的复杂任务) |
| token 消耗 | 随步数线性增长,后期很贵 | 规划阶段集中消耗,执行阶段可控 |
| 实现难度 | 低(结构简单) | 中(需要管理计划状态和 Re-planning 逻辑) |
简单记忆:
-
任务步骤少、目标模糊、需要随机应变 → 用 ReAct
-
任务步骤多、目标明确、需要全局把控 → 用 Plan and Execute
-
系统复杂、两者都需要 → Plan and Execute 做外层框架,每个子任务内部跑 ReAct
最后这种「外层 Plan and Execute + 内层 ReAct」的搭配,在实际生产系统里最常见,用规划保证大方向不跑偏,用 ReAct 保证每个子任务执行时足够灵活。
Agent vs Workflow,什么时候用哪个
这是初学者最容易搞混的问题,也是实际选型最关键的判断。
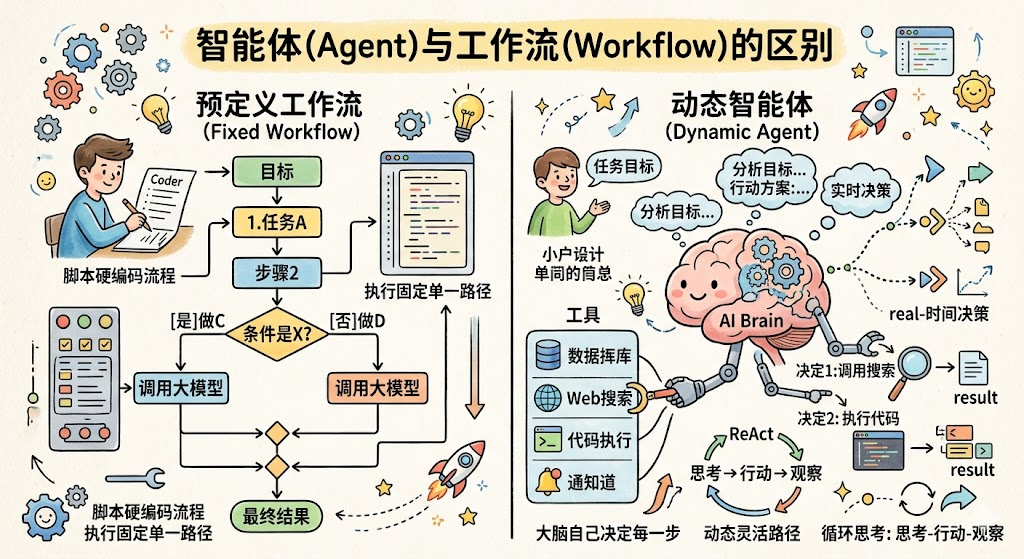
Workflow(工作流) 是你提前写好所有步骤和分支逻辑的流程:先做 A,再做 B,如果 B 的结果是 X 就走流程 C,否则走流程 D。大模型只是其中某个步骤里被调用一次,整体流程是硬编码的。
Agent 是你只给任务目标,大模型自己实时决定每一步做什么、调用什么工具、根据结果决定下一步。执行路径是动态的,每次运行可能走不同的路径。
| Workflow | Agent | |
|---|---|---|
| 决策者 | 你(写死的代码逻辑) | 大模型(实时推理) |
| 执行路径 | 固定 | 动态 |
| 适合场景 | 步骤明确、重复性高 | 任务开放、情况多变 |
| 可预测性 | 高 | 低 |
| 成本 | 低 | 高(多轮 LLM 调用) |
两者没有高下之分,适合不同的场景:
-
流程能写清楚、步骤是固定的 → 优先用 Workflow ,更稳、更省钱、更可预期
-
任务是开放式的、需要根据中间结果动态决策 → 用 Agent
-
最常见的实际架构: Workflow 做骨架,Agent 负责其中需要判断的环节 ,两者结合,不是非此即彼
Agent 开发的真实挑战
学完了怎么好用,也要知道坑在哪,不然上手就容易踩雷。
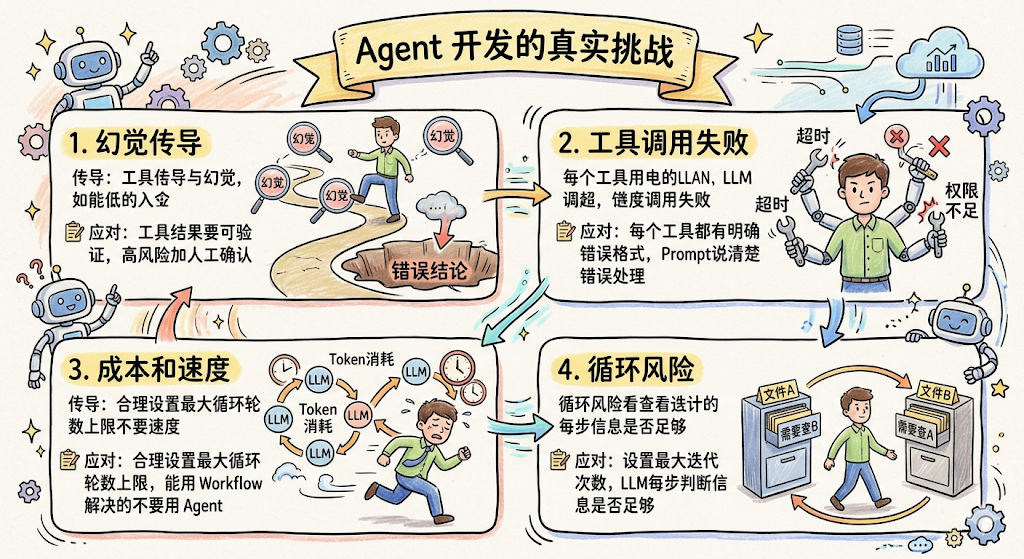
挑战 1:幻觉传导
大模型在第一步做出错误判断,后续所有步骤都建立在这个错误假设上,最终结论可能完全跑偏。单步幻觉在普通问答里代价不大,但在 Agent 的多步骤链条里,第一步的错误会被逐步放大。
应对:工具结果要可验证;对高风险操作(写入数据库、发通知、执行脚本)加人工确认步骤。
挑战 2:工具调用失败
工具不是百分之百可靠,网络超时、返回格式异常、权限不足……Agent 没有合适的 fallback 设计,一个工具失败就可能卡死或走偏。
应对:每个工具都要有明确的错误返回格式;System Prompt 里说清楚"如果工具返回错误应该怎么处理"。
挑战 3:成本和速度
每一轮循环都是一次 LLM 调用,有 token 消耗和时延。一个任务如果跑 10 轮,消耗是单次问答的 10 倍。用 Agent 是有代价的。
应对:合理设置最大循环轮数上限;能用 Workflow 解决的不要用 Agent。
挑战 4:循环风险
Agent 可能陷入"查了 A,发现需要查 B,查完 B 又觉得需要查 A……"的无效循环。
应对:设置最大迭代次数,超出就强制结束;让大模型在每步推理时明确判断"当前信息是否已经足够得出结论,还有没有必要继续"。
一个真实 Agent 的样子
说了这么多,Agent 代码层面长什么样?用伪代码展示一个极简的 Agent 骨架:
def run_agent(user_message):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_message},
]
while True:
# 1. 调用大模型,让它思考下一步
response = llm.call(messages)
# 2. 如果大模型说"我完成了",退出循环
if response.is_final_answer:
return response.content
# 3. 否则,执行大模型指定的工具
tool_result = execute_tool(response.tool_name, response.tool_args)
# 4. 把工具结果追加到 messages,供下一轮参考
messages.append({"role": "tool", "content": tool_result})
这就是 Agent 的骨架,整个循环的核心逻辑就这么点:
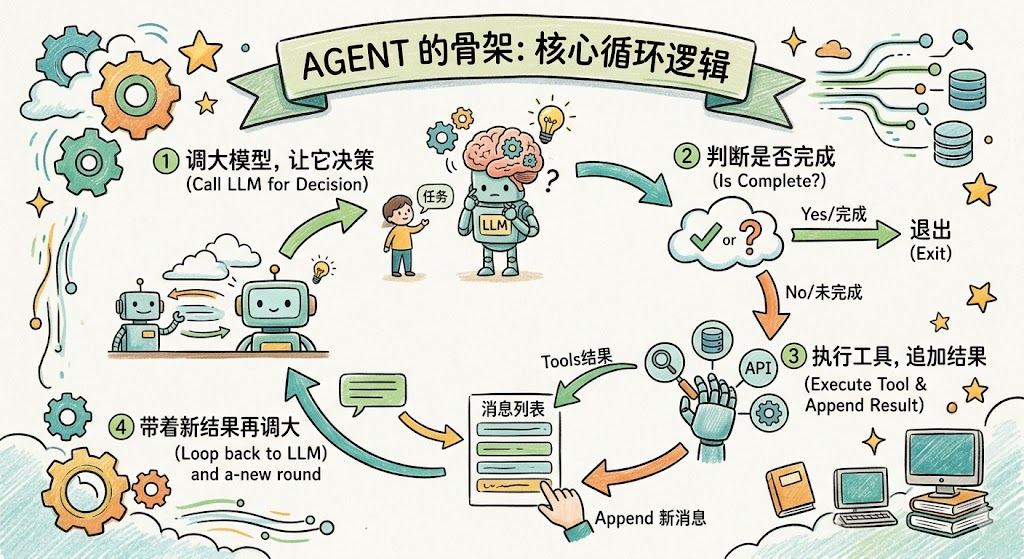
-
调大模型,让它决策
-
判断是否完成,完成就退出
-
没完成就执行工具,把结果追加进 messages
-
带着新结果再调大模型,进入下一轮
真实系统会在这个基础上加:错误处理、最大轮数限制、日志记录、人工审批步骤等。但骨架就这些,不复杂。你读懂了这段伪代码,Agent 的核心机制就装进脑子里了。
总结
整理一下这一章的核心认知:
Agent 是什么 :以大模型为大脑,能自主调用工具、完成多步骤任务的程序。让大模型从"只能说"变成"能干"。
核心组成 :大模型(大脑)+ 工具(双手)+ 记忆(记事本)+ 执行循环(节拍器)
核心机制 :Think → Act → Observe 循环,每轮工具结果都回流给大模型,直到完成
和 Workflow 的本质区别 :决策者不同,Workflow 是你提前写好的代码逻辑,Agent 是大模型实时推理。两者不是竞争关系,实际系统里经常结合使用
后续章节呼应:
-
Function Calling :大模型怎么"告诉"代码层调用哪个工具,这是 Agent 工具调用的底层机制,也是这段伪代码里
response.tool_name和response.tool_args怎么来的 -
RAG :Agent 怎么访问私有知识库,本质上是一种特殊的工具,但重要到单独讲
-
MCP :工具的标准化协议,让 Agent 能接入更广泛的生态工具,不用每次都自己写
带着这章建立起来的 Agent 整体架构认知,后续每个章节都是在填充这个架构里的某个具体模块。你知道它在整体里处于什么位置,学起来就不会迷失方向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)