统计学习方法第二章:感知机-超深度解析讲解
在现代工业界,没有任何人会把单层感知机直接部署到生产环境里去。
但这绝不意味着它没有学习价值。恰恰相反,在算法工程师的成长路线上,感知机是绝对不可跳过的一环。
感知机(Perceptron)是机器学习和神经网络领域中最基础的模型。你可以把它看作是现代深度学习中那些极其复杂的人工神经网络的“老祖宗”或基本构建块(即单个神经元)。
现在的深度学习听起来很高大上(比如包含千亿参数的大语言模型),但如果你把它们拆开来看,它们的底层依然是密密麻麻的感知机。
-
现代的“神经元”,无非就是把感知机里的阶跃激活函数换成了平滑的 ReLU 或 Sigmoid 函数。
-
核心的计算逻辑依然是经典的
。
-
如果你不懂单层感知机是如何“拉扯”权重的,当你面对一个包含 100 层、上亿个节点的深度神经网络时,你就会把它当成一个彻底的“黑盒”。懂了感知机,你就拥有了透视深度学习底层运作的“X光眼”。
在上世纪60年代,感知机曾红极一时。直到著名的数学家马文·明斯基(Marvin Minsky)指出:单层感知机连最简单的 XOR(异或)问题都解决不了! 因为异或问题的数据是交叉排列的(线性不可分),一条直线根本切不开。
这一致命打击直接导致了神经网络研究进入了长达十多年的“第一次寒冬”。直到后来,科学家们想通了:一条直线切不开,那如果我把好几个感知机拼在一起,用多条直线去切呢?
这,就是多层感知机(MLP,Multi-Layer Perceptron)的诞生,也就是深度学习的真正起点。
简单来说,感知机是一个二分类的线性分类模型。它的主要任务是接收多个输入信号,经过计算后,输出一个非此即彼的决定(例如:是或否、1或-1)。
第一章:感知机模型概览
1. 感知机模型是什么
假设你要决定“今天是否要去踢足球”(输出:去 = 1,不去 = -1)。这个决定取决于几个因素(输入):
-
:今天天气好吗?
-
:朋友们去吗?
-
:我今天累吗?
不同的因素对你的决定影响程度不同,这就是权重(Weights):
-
:天气对你很重要(权重高)。
-
:朋友去不去对你非常重要(权重极高)。
-
:累不累无所谓(权重低,可能为负数)。
最后,你心里有一个阈值或偏置(Bias)。比如你天生就是个很宅的人(偏置为负),那么只有当天气和朋友的综合吸引力超过了你的“宅属性”时,你才会决定出门。
感知机就是模拟这个决策过程的数学模型。
感知机的核心组件
感知机将上述的比喻转化为了严谨的数学过程,主要包含以下几个部分:
-
输入(Inputs,
):接收来自外界的数据特征,通常表示为向量
。
-
权重(Weights, w):每个输入特征对应一个权重,表示该特征的重要性,表示为
。
-
偏置(Bias, b):一个常数,用于调整模型触发输出的难易程度。
-
线性组合(加权求和):将输入和权重相乘后求和,再加上偏置。
-
激活函数(Activation Function):将加权求和的结果转化为最终的分类输出。感知机通常使用阶跃函数(Sign function):如果
,输出 1(正类);如果
,输出 -1(负类)。
所以,感知机的完整数学表达式为:
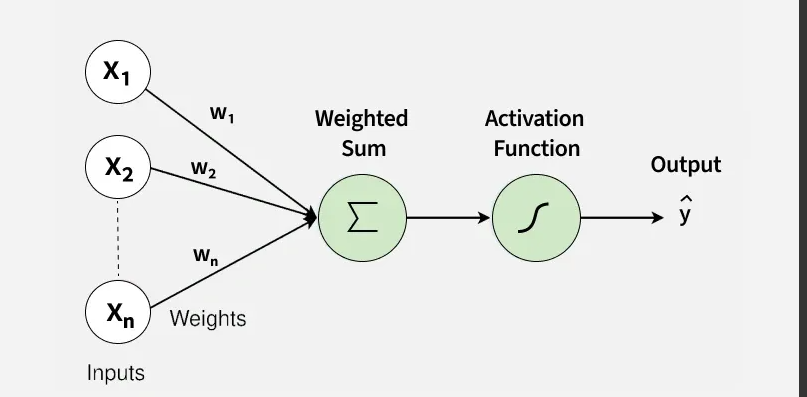
如果你把输入特征画在一个坐标系里,感知机的任务就是寻找一条直线(在三维空间中是平面,高维空间中叫超平面)。
方程 就是这条直线的方程。这条直线会将整个空间一分为二,一侧是正类(+1),另一侧是负类(-1)。感知机通过不断学习,调整 w 和 b的值,使得这条直线能完美地将两种不同类别的数据点分开。
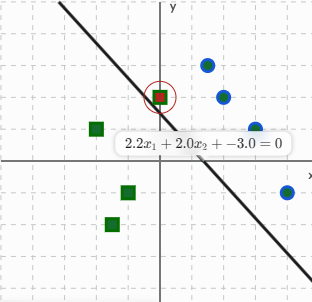
2. 什么叫分类正确
刚才我们提到,感知机会在空间中画一条直线(决策边界 )。
-
这条线把空间分成了“正极”和“负极”两半。
-
如果一个原本属于正类的数据点,乖乖地落在了直线的正极一侧。
-
或者一个原本属于负类的数据点,落在了直线的负极一侧。
这就是“分类正确”。反之,如果正类数据跑到了负极一侧,那就是“分类错误”(误分类点)。
感知机是如何用数学公式来判断“站对位置”的呢?这里有一个非常优雅的数学技巧。
假设:
-
-
是真实的标签:正类
,负类
。
-
是模型计算出的原始得分。
我们来看看两种分类正确的情况:
-
当真实标签是正类 (y = +1) 时:模型算出的得分
-
当真实标签是负类 (
因此,数学家们用一个极其简洁的不等式定义了“分类正确”:
只要真实标签和模型得分相乘大于 0(意味着它们符号相同),就说明分类正确;如果小于或等于 0(符号相反),就说明模型把正类当成了负类,或把负类当成了正类,这就是“分类错误”。
3. 损失函数在干嘛
既然我们已经知道了什么是“分类正确”(即 ),那么定义损失函数就非常顺理成章了。
最直观的损失函数应该是0-1损失函数:分类对一个算 0 误差,分错一个算 1 误差,最后加起来看看错了几个。
但这种方法在数学上行不通。因为“数个数”得到的是一个阶梯状的、不连续的值(比如错了3个,或者错了4个,没有3.5个)。在微积分中,这种不连续的函数是无法求导的。如果不能求导,模型就不知道该往哪个方向去调整参数 w 和 b 才能让错误减少。
既然不能数个数,感知机选择了一个更聪明的办法:计算所有“分类错误”的数据点,到决策边界直线的总距离。
如果一个点被分错了,但它离直线很近,说明模型只犯了“一点点错”,稍微调整一下直线就能把它纠正过来。
如果一个点被分错了,且离直线十万八千里,说明模型“大错特错”,损失函数的值就会非常大。
如果你平时在编写技术文档或排版数学公式,感知机损失函数的标准表达式通常会写成这样:
我们来拆解一下这个公式:
-
M (Misclassified):代表所有被分类错误的数据点的集合。注意,这个求和符号底下只有 M,意思是分类正确的点不参与计算,它们对损失的贡献是 0。
-
:正如我们上一轮提到的,对于被分错的点,真实标签和预测得分的符号必定相反,因此它们相乘的结果必定是负数(或 0)。
-
最前面的负号 (-):因为上面括号里算出来是负数,为了让“损失”变成一个代表惩罚的正数,我们在前面加一个负号,负负得正。
感知机的最终目标,就是通过不断迭代输入数据,利用梯度下降法(Gradient Descent)来更新权重 w 和偏置 b,最终使得。
当 L(w, b) = 0 时,意味着集合 M为空——也就是没有任何一个点被分错,那条完美的分割直线终于被找到了。
感知机虽然经典,但它有一个根本性的限制:它只能解决线性可分的问题(即只要能用一条直线把两类数据完全分开,感知机就能学会)。
如果数据是交错排列的(比如著名的 XOR 异或问题),一条直线无论如何也无法将它们分开,单层感知机就会彻底失效。这也导致了上世纪 70 年代神经网络研究进入了第一次“寒冬”。直到后来多层感知机(MLP)和反向传播算法的出现,才打破了这个僵局,迎来了现代深度学习的繁荣。
第二章:感知机学习策略
感知机的学习策略,简单说就是:
找一个超平面,把训练数据中的正负样本分开;如果有样本被分错,就让这些误分类点到超平面的总距离尽可能小。
感知机是一个二分类的线性模型。它的最终目标是找到一个完美的决策边界(在二维空间是一条线,高维空间是一个超平面),把正类和负类数据完全隔开。
为了实现这个目标,它的学习策略分为两步:
-
只关注犯错的点:如果一个数据点已经被正确分类了,感知机就会无视它,不需要为它做任何调整。
-
量化错误的大小:对于每一个被分类错误的点,计算它到当前决策边界的距离。距离越远,说明错得越离谱,惩罚(损失)就越大。
负类距离超平面的数学距离推导
在数学(线性代数和解析几何)中,空间里任意一个点 到一个超平面(直线、平面或高维平面)
的距离
有一个标准的公式:
这里的 ||w|| 是权重向量 w的 L2范数(也就是向量的长度,)。 这个公式和我们高中学的“点到直线的距离公式”
在本质上是一模一样的,只是推广到了高维空间。
上面的公式里有一个绝对值符号 。在微积分里,绝对值是非常讨厌的,因为在零点处不可导,这会让后面的“求导更新参数”变得极其麻烦。
感知机怎么解决这个问题呢?它利用了“误分类点”的特殊性质。
对于任意一个误分类点 ,我们在前面讨论“分类正确”时说过,模型算出的得分
与真实的标签
符号必然相反。
-
如果真实
,那么
。
-
如果真实
,那么
。
因为 只能取 1 或 -1,所以无论哪种情况,两者的乘积都必定是负数:
既然乘积是负数,我们在它前面加一个负号,它不就变成正数了吗?
更巧妙的是,因为 的绝对值总是 1,所以
的数值大小,恰好就等于
。
于是,我们成功用一个平滑可导的代数式,替换掉了那个讨厌的绝对值。现在,误分类点到超平面的几何距离公式变成了:
如果我们把所有误分类点 M 的距离加起来,总距离应该是:
但是,你发现了吗?感知机最终的损失函数 L(w,b) 里,并没有 这一项。为什么把它直接扔掉了?
这是因为感知机模型有一个非常务实的目标:它只关心能不能把错题数量降为 0,而不关心具体的距离数值是多少。
-
分子
被称为函数间隔。
-
除以 ||w|| 后的整体被称为几何间隔。
感知机认为,只要我不停地调整参数,让分子(函数间隔)不断变小直到等于 0,那么真实的几何距离也就跟着变成 0 了。分母 ||w|| 只是个缩放比例,保留它会让求导计算变得极其复杂,完全没有必要。
为了计算速度和简化模型,直接丢掉了分母 ||w||(这是感知机和后来出现的支持向量机 SVM 最大的区别,SVM 就必须死死盯住那个分母不放)。
第三章:感知机学习算法
感知机学习算法就是:用随机梯度下降不断修正误分类点,直到所有训练样本都被正确分类。
我们前面讨论了感知机的“目标”(分类正确)和“策略”(极小化误分类点距离),现在我们将这些思路转化为计算机可以直接执行的具体步骤,这就是感知机学习算法。
感知机学习算法主要有两种形式:原始形式和对偶形式。在绝大多数情况下,我们首先学习和使用的是“原始形式”。
1. 感知机学习算法(原始形式)
这就是将我们之前提到的“随机梯度下降(SGD)”具体化为一个标准的程序流程。
假设前提:
-
我们有一个训练数据集
。
-
其中
是输入特征向量,
是真实的分类标签。
-
我们需要设定一个学习率
(通常是
的小数,用来控制每次调整的幅度)。
算法执行步骤:
-
初始化参数:将权重向量
和偏置
全部初始化为 0(或者很小的随机数)。
-
选取数据:在训练集中选取一个数据点
。
-
判断是否误分类:计算
-
如果结果
,说明这个点被分错了,进入第 4 步。
-
如果结果
,说明这个点分对了,回到第 2 步,继续挑下一个点。
-
-
更新参数:既然分错了,我们就根据这个点的特征来修正
-
循环迭代:不断重复步骤 2 到步骤 4,直到训练集中所有的点都被正确分类(即再也找不到
的点为止)。
如果 是正样本,也就是
,但被分错了,说明:
也就是说模型给它的分数太低了。
w←w+ηxi
b←b+η
会让以后这个点的 变大,更容易被分成正类。
如果 x 是负样本,也就是 yi=−1,但被分错了,说明:
w⋅xi+b≥0
模型给它的分数太高了。
更新为:
w←w−ηxi
b←b−η
会让以后这个点的 w⋅xi+b 变小,更容易被分成负类。
深入一下
我们来想一个极端场景,假设现在的偏置 b = 0,有一个真实标签为正类()的数据点
,但模型把它算成了负类(即算出来的
)。
根据更新公式,新的权重会变成 。 当我们用新的权重再去计算这个点的得分时:
你看,原来的得分 是个负数,但在加上了
(这是一个绝对的正数)之后,新的得分就会比以前变大,努力向正数靠拢。这就像是模型在说:“哎呀,上次算小了,我把权重往你这个特征的方向调整一下,下次算结果就会大一点了。”
负类()被错算成正类时的逻辑也是完全对称的,模型会把得分往下“压”。
这个算法会不会永远循环下去,一直找不到完美的 w 和 b 呢?
著名的诺维科夫定理(Novikoff's theorem)给出了数学上的保证:
只要你的数据集是“线性可分”的(也就是客观上真的存在那么一条线能把两类点完全分开),那么感知机算法经过有限次的迭代后,一定会停止。 它绝不会陷入死循环。
但反过来,如果数据中有“内鬼”(比如正类数据群里混进了一个负类),导致数据线性不可分,那么感知机就会在这个“内鬼”附近反复纠结,参数永远震荡,算法永远停不下来。这也是为什么在实际编程中,我们通常会强行设置一个“最大迭代次数(Max Epochs)”。
2.对偶形式
教材在讲完原始形式后,会突然扔出“对偶形式(Dual Form)”,让人一头雾水。
“对偶”这个名字,可以先不从很抽象的数学对偶性理解,先按机器学习里的直觉理解:
原始形式是从特征维度的角度看问题;对偶形式是从样本的角度看问题。
简单来说,在数学和优化理论中,“对偶”的意思是:同一个问题,从两个截然不同的视角去看。 这两个视角就像是一枚硬币的正反面,或者物体和它的影子。虽然看起来完全不同,但只要你解开了其中一面,另一面的答案就自动浮现了。
为什么要换种方式?因为在某些情况下(尤其是特征维度非常高的时候),对偶形式能让计算机算得快得多,而且它为后来大名鼎鼎的支持向量机(SVM)和核技巧(Kernel Trick)铺平了道路。
我们通过三个步骤来揭开它的面纱。
1. 核心思想:从“记权重”变成“记次数”
在原始形式中,权重 w 一开始是 0。每次遇到一个误分类点,我们就把
更新一次:
现在,假设我们有一个极简的训练集,只有 3 个数据点:点1 ()、点2 (
)、点3 (
)。 为了方便算,我们把学习率设定为
。
第 1 轮:
-
模型看了看点1,分错了!赶紧更新:
-
模型看了看点2,分对了!不更新。
-
模型看了看点3,分错了!接着更新:
第 2 轮:
-
模型又看了看点1,哎呀,又分错了!(之前调整得不够)。再更新一次:
-
假设经过这轮,所有点都分对了,训练结束。
把上面最后一步的式子里的 放在一起:
也就是说,最终的 w 其实就是这些被错分的点,乘以它们各自错分的次数,全部累加起来的结果。
在数学上,如果我们用 表示第
个点被错分的总次数,那么:
那么最终的 可以写成:
为了公式简洁,我们定义 。那么:
这就是对偶形式的灵魂!
我们发现,我们根本不需要傻乎乎地去维护那个包含很多特征维度的向量 w。我们只需要给训练集里的每一个数据点分配一个数字 (它代表了这个点对最终边界的“贡献度”或者说“被错分的次数”)。
2. 感知机学习算法(对偶形式)
基于上面的替换,算法的执行步骤就变成了这样:
假设前提:
训练数据集 。
算法执行步骤:
-
初始化:给每个数据点分配的
初始全为 0,即
,偏置
。
-
选取数据:选取一个数据点
-
判断是否误分类:把
中,变成:
注意这里的
是两个向量的内积(点乘)。
-
更新参数:如果上式成立(说明分错了),我们就更新这个点对应的
-
循环迭代:重复步骤 2 到 4,直到所有点都分类正确。
3. 为什么要费这么大劲?(Gram 矩阵)
你可能会问:对偶形式的判断公式(步骤 3)看起来比原始形式长得多、复杂得多,每次判断都要把所有点遍历加起来,这到底哪里快了?
秘密就藏在那个内积 里面。
在训练过程中,数据点的坐标 是永远不会变的!这意味着,任意两个点之间的内积
是一个常数。
既然是常数,计算机非常聪明,它在训练开始之前,就可以提前把所有数据点两两之间的内积全部算出来,存在一个大表格里。这个大表格在数学上被称为 Gram 矩阵(Gram Matrix)。
巨大的优势:
-
在原始形式中,每次判断都要计算向量乘法
。如果数据的特征维度极高(比如 10 万维),每次算向量乘法都会非常耗时。
-
在对偶形式中,因为我们有了 Gram 矩阵,步骤 3 中的
原始形式每次判断
原始形式判断第 i 个点是否误分类:
如果特征维度是 d,那么算一次 的复杂度大约是:
O(d)
也就是看特征维度有多大。
对偶形式每次判断
对偶形式判断第 i个点是否误分类:
这里 已经提前算好了,所以不用再算向量内积。
但是你要把 j=1 到 N 都加一遍,所以一次判断复杂度大约是:
O(N)
也就是看样本数量有多大。
| 形式 | 每次判断主要代价 | 更适合 |
|---|---|---|
| 原始形式 | (O(d)) | 特征维度不高,样本很多 |
| 对偶形式 | (O(N)) | 样本不太多,特征维度很高 |
总结
-
原始形式:更新的是权重向量 w。适合特征维度低、数据量大的情况。
-
对偶形式:更新的是每个数据点的权重

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)