Agent时代的存储(下): token账单爆炸?如何开源节流?
作者:FTS、HJ from AISYS-Group@Shanghai AI Lab
TL;DR
在上一篇《Agent时代的存储(上):有了“Memory”还要“Harness”?Agent的痛点到底在哪?》中,我们详细介绍了Agent时代的存储新特征,分析Agent Search这一热点场景下的存储需求及业界实践,复盘借鉴了推荐系统中的工程共识与和优化思路。在此基础上,我们运用超80万条文本片段进行了动态控制实验,基于Agent的局部性特征进行存储方案优化,成功提升了引用的效率,最终可以让模型容易进行引用而不是生成,从而让Agent执行任务变得更便宜。在本篇中,我们就将详细介绍在“紧凑布局”和“自适应索引”这两个优化方向上的探索与实验发现,并提出在生产环境中的工程建议及未来优化方向!文内会展示我们的一些数据结果,欢迎大家集思广益。
背景介绍:局部性假设下的存储“新”优化
今年3月,我国日均Token调用量超140万亿,相比2024年初增长1000多倍。Token激增也带来了算力涨价潮:英伟达H100一年期租赁价格涨幅近40%,国内腾讯云、阿里云、百度智能云等厂商产品纷纷提价。当算力成本不断提高,一个可行的思路是:想办法让同样的任务消耗更少的算力——而存储优化,正是实现这一目标的有效解法。
我们发现在一个复杂的工作中,Agent花了大量的精力在做搜索,在SWE类任务中,搜索查询的交互甚至占到了总交互的70%!而搜索的底座是存储。所以我们选择Agent search作为典型场景,尝试提出一套系统化的存储优化方案。
SWE(Software Engineering)任务通常指:让大模型像“软件工程师/代码助手”一样,在真实或半真实的代码库里完成工程工作,而不只是写几行示例代码。它往往要求跨文件理解、改动、验证与交付。SWE主要会考察大模型的代码能力。
Memory 与 Harness 让长程任务围绕同一目标、同一批状态、同一组验证证据反复推进;Agent Search 则把这种语义聚集落到数据访问上。基于Agent场景的局部性,我们优化目标就不再是“让单次检索更快”,而是“让相近的引用更便宜”。下面的「紧凑布局」「自适应检索预算」及配套实测,均建立在对 Lance 的定制实现之上;其中思想(把语义相近变成物理相近、让查询预算动态变化)对同类列式存储与向量检索系统仍有一般参考价值。
此外我们还希望将“I/O次数”作为一个重要的性能指标。因为在本地 NVMe 上,随机读和顺序读的差异已经足以影响延迟;到了对象存储路径,差异会进一步放大。一项布局优化有没有真的“加速”,应该先看底层读取(请求次数、读字节)有没有下降,再看这份节约能不能穿过缓存、网络往返和解码开销。两层分开之后,会浮现出几种本质不同的形态:
-
底层读取真的变少,延迟也同步下降 :这是最理想的情况,机制成立、边界稳定。
-
底层读取少了,但延迟没动 :节约幅度太小,被路径上的其他开销盖住;机制成立,但还没翻译成用户感知时间。
-
读字节反而增加,延迟却能持平甚至下降 :合并读取多带回了一些无关字节,但请求次数减少抵消了多读的代价;这时候“少字节必更快”的旧直觉就失效了。
-
字节数和请求数几乎不动,延迟却大幅波动 :往往不是读取问题,而是解码、序列化或决策路径的代价,继续做存储布局优化解决不了。
把这四种情况分开看,工程决策才不会被一组好看的延迟数字误导。下文讨论紧凑重排、向量编码和查询策略时,引入“I/O次数”并回到这套两步判读上来。在本章中,我们的实验对象是约 82 万条 Wikipedia 文本片段,384 维向量。
Reorder:打通物理存储布局
紧凑布局的目标很朴素:如果一批内容在语义上经常一起被访问,那么它们在物理上也最好尽量靠近。向量索引里的分组可以看作语义空间里的粗粒度“桶”;如果 Agent query 会反复命中相近的桶,那么这些桶里的证据正文最好在文件里也尽量接近。这就是紧凑布局的核心思想:让同一语义分组里的样本在磁盘上更连续,从而让候选后的证据回查更容易被合并成少量连续读取。它优化的不是向量距离计算本身,而是“候选已经找到之后,证据如何被读回来”。
这个优化成立需要一个前提:查询确实会读回一批相关候选。如果 Agent 只取极少量结果,证据正文又很短,那么把一大段相近内容一起读出来,反而可能变成“读得多、用得少”的浪费。相反,当系统需要读回较多候选做重排、证据拼接或多轮验证时,被放近的样本就能被一次连续读取带回来,物理局部性的价值才稳定显现。这条耦合关系还有一个推论:语义分组的大小并不是可以随手乱调的旋钮,它通常受数据规模和索引构建方式约束。分组太大,轻量查询容易多读;分组太小,连续读取的收益又会变弱。真正要判断的不是“紧凑布局好不好”,而是“当前查询会不会读回足够多相关证据”。
为了避免首个查询的冷启动影响,主要观察进入稳态之后的查询;为了避免混入索引粒度变化,尽量只比较“物理顺序不同”这一件事。我们把实验结果按引用路径整理成三类:只读少量短证据的轻路径,开始读回一批证据的中等路径,以及需要读回大量候选做重排、拼接或多轮验证的重路径。baseline 是同一索引粒度下被打散的物理顺序,compact 是按语义分组紧凑后的物理顺序;数字来自对象存储路径上的稳态查询,延迟为客户端端到端 p50。
|
引用路径 |
覆盖的查询形态 |
请求次数变化 |
读字节变化 |
p50 延迟变化 |
|---|---|---|---|---|
|
轻引用路径 |
小 top-k,证据很短 |
约 -20% ~ -32% |
约 +63% ~ +108% |
-14% ~ +12%,方向不稳定 |
|
中等引用路径 |
中等 top-k,开始读回一批证据 |
约 -48% ~ -54% |
-29% ~ +18%,取决于查询聚焦度 |
约 -12% ~ -39% |
|
重引用路径 |
大 top-k,重排 / 证据拼接 / 多轮验证 |
约 -41% ~ -54% |
约 -42% ~ -51% |
约 -31% ~ -45% |
经过不同引用路径下的物理布局收益对比,我们的核心发现可以总结为:
-
中等引用路径本身是过渡区:查询足够聚焦时,合并读取开始兑现;查询分散、证据覆盖不足时,多读无关字节仍会吃掉一部分收益。
-
轻引用路径属于“机制发生了,但没有稳定翻译成时间”的形态。重引用路径则不同:请求次数、读字节和 p50 延迟一起下降,说明紧凑布局真正压低了证据回查成本,并且这份 IO 节约穿过对象存储的网络往返,翻译成了用户可感知的端到端收益。
-
同一语境下,节约几乎都落在证据回查,索引侧变化很小。语义分组内部再做更细的相邻排序,只在 聚焦、反复追问 一类 query 上还有一层边际收益;跨领域乱扫时,这层收益基本可以忽略。
基于这些发现,对于生产环境我们的建议是:
1. 构建紧凑布局需要考虑代价
是否启用紧凑布局,更适合挂在 query 形态或策略层上选择,而不是做成 dataset 级一次性开关。构建代价的计算可以基于一次离线 rewrite,复杂度主要来自扫描、按语义分组重排和重写数据,规模上接近 O(N) 到 O(N log N),具体耗时和额外 IO 需要在目标数据集上补测。。本地 NVMe 上,代价可以近似成候选行跨越的 page 数或随机跳转次数;对象存储上,代价更接近“可合并后的读取请求数 + 为了合并多读的字节数”。
如果系统面对的是高度分散、近似随机的 query,或者每次只取极少量短证据,局部性假设就不强。此时紧凑布局不但可能没有明显收益,还可能因为合并读取带回无关字节而轻微劣化。这个边界很重要:布局优化服务的是有局部性的引用流,不是所有向量检索请求的通用加速器。
2. 计算收益时需要考虑缓存资源
对于缓存 trade-off ,真正有用的图不是单点延迟,而是打散 / 紧凑布局在小缓存、大缓存下的相对位置;如果“紧凑 + 小缓存”接近甚至优于“打散 + 大缓存”,部署决策才会变得清楚。这时我们会思考如果把缓存开大,布局会不会不重要。我们尝试做了一组实验,先说结论:约 32 MB 缓存已经能留住紧凑布局稳态收益的近九成。这意味着局部性优化真正有价值的场景,未必是内存充裕的常驻服务,反而可能是容器、边缘节点和 serverless 这类内存预算紧的部署形态。
在实验中,我们把缓存从 GB 级收到 约 256 MB ,紧凑布局带来的稳态 IO 红利几乎不掉;再收到 约 32 MB ,仍能留住 九成左右 。布局优化的收益不必绑定几 GB 常驻内存。实验发现布局与缓存是叠加关系:命中率高时,没命中的次数更少,但每次没命中的读取仍可以更便宜;命中率低时,局部性几乎是唯一可重复的「热」。这对 容器、边缘、serverless 特别友好:内存预算紧时,更值得押在「怎么排」,而不是无限扩缓存。实务上,多数负载把客户端可读缓存上限收到 256 MB 量级 往往就够用;实验里更大的默认上限更像量程上限,而非日常必选项。
但是如果引入”I/O次数“,无论缓存如何,布局的优化都是存在的。因为冷启动时紧凑布局可能多触一点元数据 IO,体量通常不大;若 cache 过小,首批 query 可能短暂抬升,布局的优化提升就会更显著。
Adaptive nprobe:自适应控制索引预算
如果说紧凑布局改变的是“数据怎么放”,那么自适应检索改变的是“这次要找多深”。固定预算的做法,是每次查询都搜索同样大的语义范围;但 Agent Search 里有些 query 很明确,少量候选已经足够,有些 query 更开放,必须扩大搜索范围才能补齐召回。自适应检索预算的思路,是从较小搜索范围开始,根据候选分数、margin 或置信度判断是否继续扩大搜索。它对应的是 Agent 内部更细粒度的“继续找 / 停止找”决策。本文不展开这部分实验数据,只把它作为和紧凑布局正交的策略侧机制:前者改查询预算,后者改物理布局;两者可以组合,但不能混在一起归因。
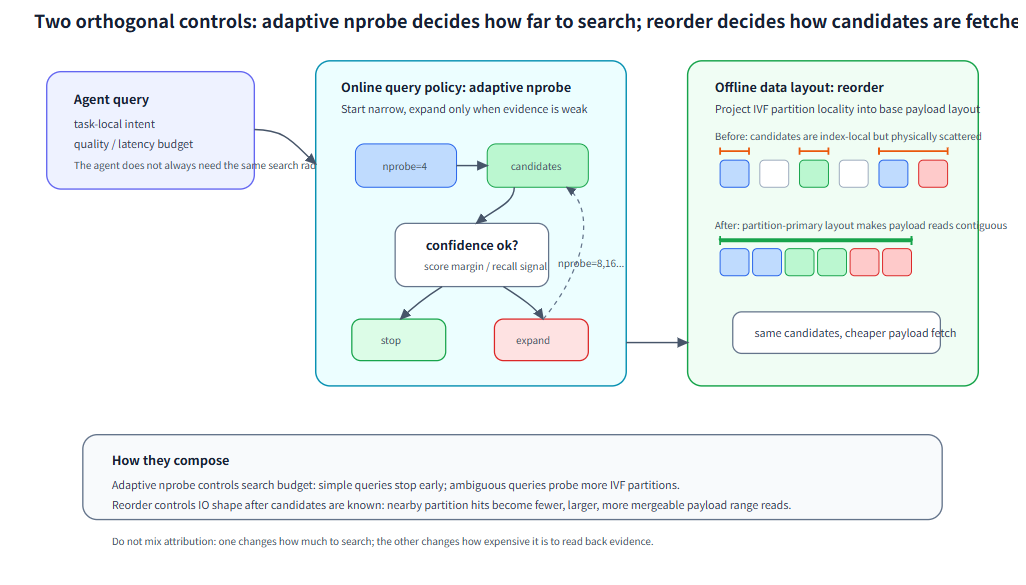
紧凑布局改变候选读回时的 IO 形态;自适应检索预算改变一次查询要搜索多大的语义范围
另外,我们也注意到选择合适的向量编码也可以影响查询成本,即控制每条样本里的向量占多少空间 。同样规模的 384 维向量数据集,使用不同的向量精度,存储体积可以从约 1.7 GB 一路压到不足 700 MB。这条收益的特点是 相对独立于查询路径 :它不依赖具体查询负载、不依赖缓存命中率,也不依赖部署在本地 NVMe 还是对象存储。只要向量列在数据体积中占有足够比例,任何需要持有副本的部署形态——容器镜像、边缘缓存、对象存储分层、离线分发的分片数据集——都能直接拿到容量收益。对于 Agent Search 这种“全局知识库 + 大量小型本地副本”的场景,副本越多,单副本压低带来的成本节约越值钱。
但是向量精度对查询延迟的影响是多方面的,并且不像存储侧那样统一。某些量化在重证据路径上能跟读取节约同向兑现一些延迟收益;但有些更复杂的精度重组方案会引入额外解码成本,让底层读取几乎不动、CPU 时间却明显波动。
所以更稳健的工程定位是: 把向量编码当作存储侧的密度工具来用,而不是查询加速器 。先把存储成本压下来,查询时要不要付出更高精度成本,再交给上层策略根据具体负载决定。
未来优化方向:按需求控制精度
紧凑布局验证的是“语义上相近的数据,物理上是否也应该更近”。下一步更自然的问题是:同一批候选,是否也应该按需读取不同精度。
当前的向量索引通常在构建时就固定了精度与体积。但对 Agent Search 来说,更理想的形态是:简单查询先读取较低成本的核心信息,困难 query、候选分数接近或任务风险更高时,再增量读取更多精度,把排序质量逐步补上来。也就是说,局部性不只发生在“读哪些语义区域”上,也可能发生在“为这些候选读到多少精度”上。
未来我们会设计一种渐进式索引,并且把“搜索范围”和“索引精度”都变成 Policy 可以按 query 形态调度的成本维度。接下来的实验我们会把索引看成一个二维引用矩阵:一维是语义局部性,决定读哪些区域;另一维是精度局部性,决定读多少精度切片。判断这条路线是否成立,也会沿用本文的两步判读:先看增量精度是否真的减少无效回查或提升候选排序稳定性,再看这份收益能否穿过解码成本、对象存储读取和 rerank 开销,翻译成最终延迟或质量收益。
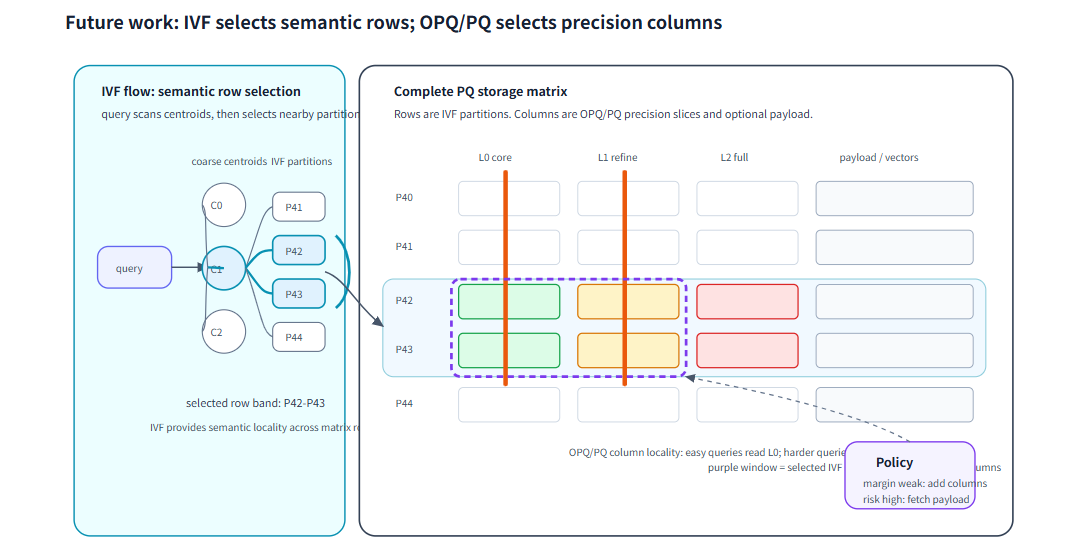
渐进式索引把语义范围和索引精度都变成可调度预算:简单查询少读,困难查询再逐步加深
总结
我们认为存储方案的价值是让Agent在推理过程中更便宜更稳定地完成生成与引用的决策。这也是业界最近工作的热点,Memory 决定了什么数据值得引用,Harness 将引用的数据稳定作用于长程任务,Lance数据格式控制了引用的静态成本,向量索引给运行时的引用有了性能保障。于是我们将这些工作整理成一个系统性的方案,并将它视为一种Agent时代对于存储的需求,对此我们发现利用局部性可以进一步优化。
本文用实验证明了,紧凑布局和自适应索引可以为引用带来收益。我们在时延和精度指标之外,引入了”I/O次数“。这个指标可以更好的反应我们的优化对于成本和稳定的影响。如果有统一的标准,未来我们希望直接测量模型少生成了多少 token,对于典型长程任务成功率的提升。
最后分享一些过程中的感悟:存储优化的未来,也许不是在优化数据,而是在优化决策,让Agent在合适的时候,用合适的成本,引用合适的状态。未来AI Infra的性能评估,不应局限于在场景数据集跑分,还需要测评它相应的可量化的工程指标,比如一套方案是否让Agent少猜、多证、可复用。
如果你喜欢我们的内容,欢迎点赞👍、收藏⭐️、关注➕我们!
也欢迎在评论区与我们互动!
你的支持是我们持续创作的动力!
参考资料:
新华网. https://www.news.cn/tech/20260416/cb40f593cd304081a2c7bdbde3367f7b/c.html
央视新闻. https://mp.weixin.qq.com/s/R78lcxvQyybqm8pcg1RR1w

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)