Claude Code v2.1.152 深度解读:AI 编程工具正在从“能干活”走向“可治理”
|
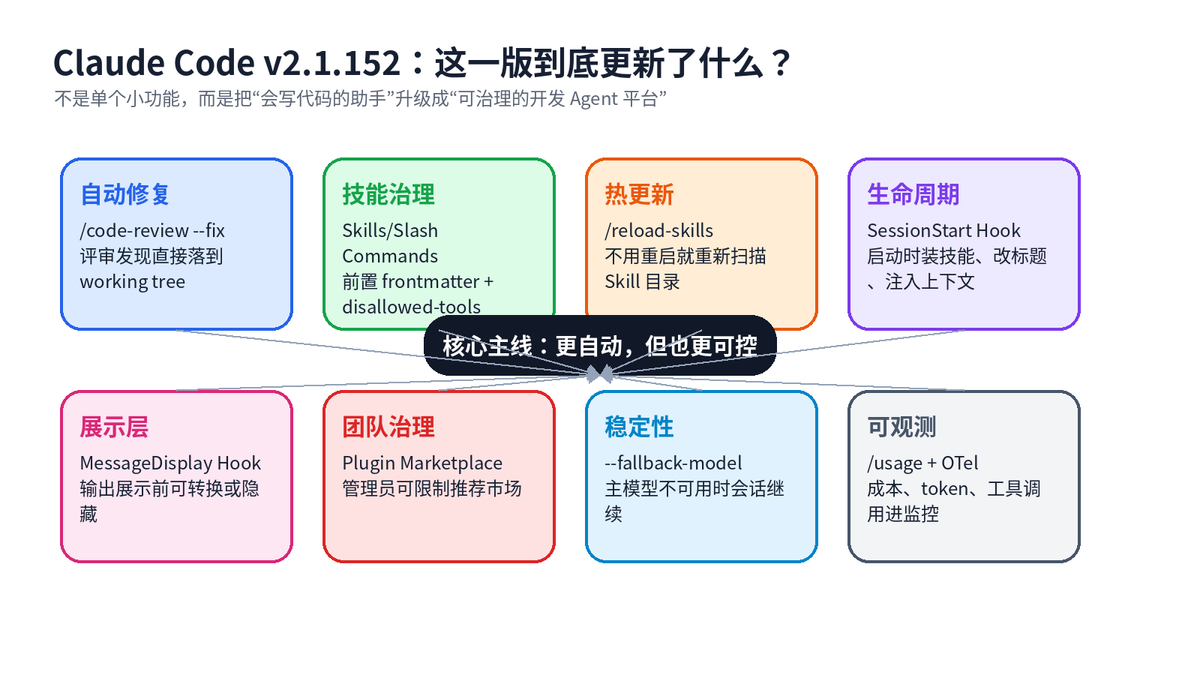
一句话总结:Claude Code v2.1.152 不是“又加了几个命令”,而是在自动修复、技能权限、运行时热更新、Hook 生命周期、插件治理和团队观测上补了关键拼图。它让 AI 编程更像一个可配置、可审计、可回滚的工程系统,而不是一个只会在终端里聊天的模型。 |
一、先说结论:这一版最值得关注的不是“更聪明”,而是“更可控”
很多人看 AI 编程工具更新,只会盯着一个问题:模型是不是更强了?但 Claude Code v2.1.152 的核心看点并不只是模型能力,而是“工程化能力”。它把过去很多依赖人手、经验和口头约定的流程,逐步变成命令、技能、Hook、插件、权限和监控。
官方发布说明显示,这个版本包含一组看似分散的更新:/code-review --fix 可以把评审发现应用到工作树;Skills 和 slash commands 可以在 frontmatter 里声明 disallowed-tools;新增 /reload-skills;SessionStart Hook 可以触发技能重扫、设置会话标题;新增 MessageDisplay Hook;插件市场推荐可以由管理员配置白名单;还补强了 fallback-model、/usage 与 OpenTelemetry 入口属性等能力。
如果把这些点串起来看,主线很清楚:Claude Code 正在从“个人开发者的 AI 终端助手”,升级成“团队可治理的 AI 开发运行时”。
二、/code-review --fix:代码审查不再只停在“提建议”
过去很多 AI 代码审查的尴尬点在于:它能指出问题,但你还得手工复制建议、判断怎么改、再自己改。v2.1.152 里,/code-review --fix 的变化是:审查之后会把可修复的问题应用到 working tree,也就是本地工作区。/simplify 也变成调用 /code-review --fix 的路径。

这个变化对开发效率很有杀伤力,因为它补上了“建议到改动”的最后一米。但越是自动化,越不能把它当成自动合并机器。正确用法应该是:让 Claude Code 负责找出低风险、机械性、可验证的问题,并生成 patch;开发者负责看 diff、跑测试、确认语义。
适合:重复代码清理、明显低效逻辑、无用分支、边界检查、命名和结构简化。
谨慎:权限、支付、账务、合规、数据删除、迁移脚本这类高风险链路。
必须:执行后看 git diff,至少跑单测、类型检查或集成测试,再决定是否提交。
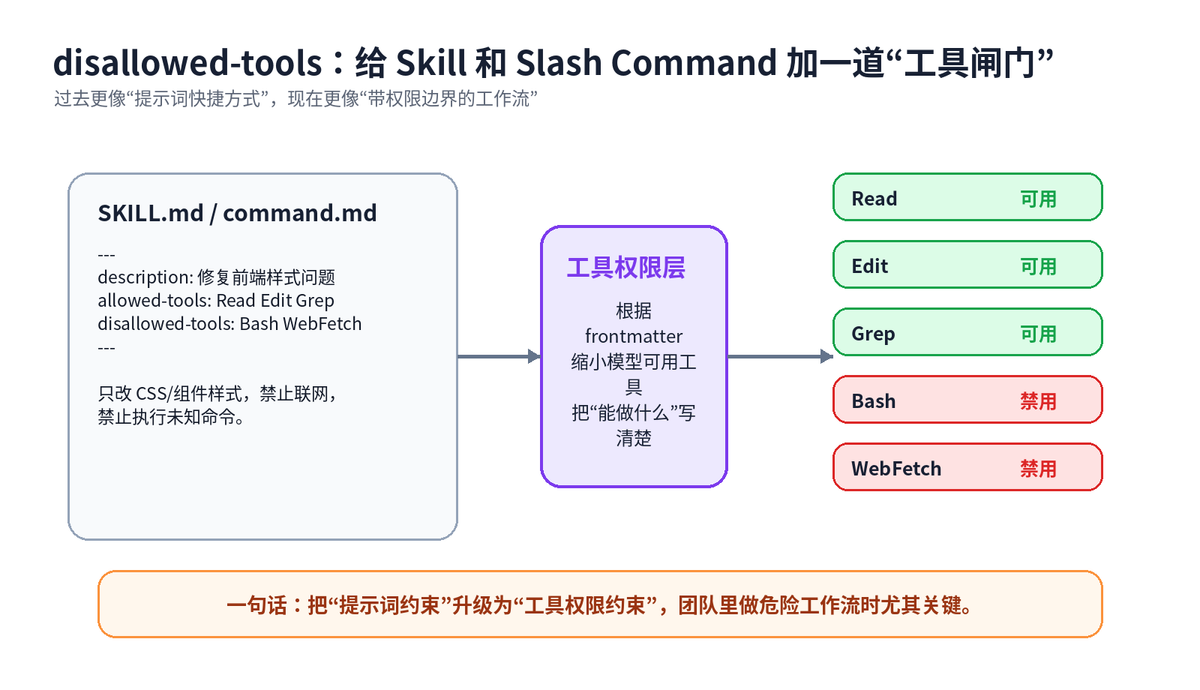
三、disallowed-tools:Prompt 不再只是“说说而已”,它开始变成权限边界
这一版另一个非常关键的更新是:Skills 和 slash commands 可以在 frontmatter 里配置 disallowed-tools。通俗讲,就是你可以在某个技能或命令启用时,把某些工具从模型面前拿走。
这点对团队很重要。很多事故不是模型不会写代码,而是模型“太积极”:本来只想让它看代码,它顺手执行了命令;本来只想让它改样式,它去读了无关文件;本来只想让它生成方案,它调用了会产生副作用的工具。
有了工具级限制之后,团队可以把高频流程拆成不同安全等级:
只读分析类 Skill:只允许 Read、Grep、Glob,禁止 Bash、Edit、Write。
低风险修复类 Skill:允许 Edit,但禁止 Bash 执行未知脚本。
部署类 Skill:默认 disable-model-invocation,只允许用户手动触发。
联网检索类 Skill:明确允许 WebFetch,但禁止修改文件。
---
description: 修复前端样式问题,仅允许读取和编辑项目文件
disable-model-invocation: true
allowed-tools: Read Edit Grep
disallowed-tools: Bash WebFetch
---
任务:只修复 CSS / 组件样式,不要执行命令,不要联网,不要改业务逻辑。
这不是“绝对安全”,但它把原来只靠文字提醒的软约束,变成了更接近工程系统的硬边界。
四、/reload-skills:技能迭代不用重启,AI 工作流开始像配置一样热更新
Claude Code 的 Skills 本质上是把团队经验写成 SKILL.md,让 Claude 在合适的时候加载。官方文档里也说明,技能可以放在个人、项目、企业或插件目录下,完整内容只在使用时加载,避免长文档一直占上下文。
v2.1.152 新增 /reload-skills,看起来只是一个小命令,但对实际开发体验影响很大:你写了一个代码审查 Skill,发现触发条件不准确,改完后不必退出 Claude Code 再进来,可以直接重扫技能目录。
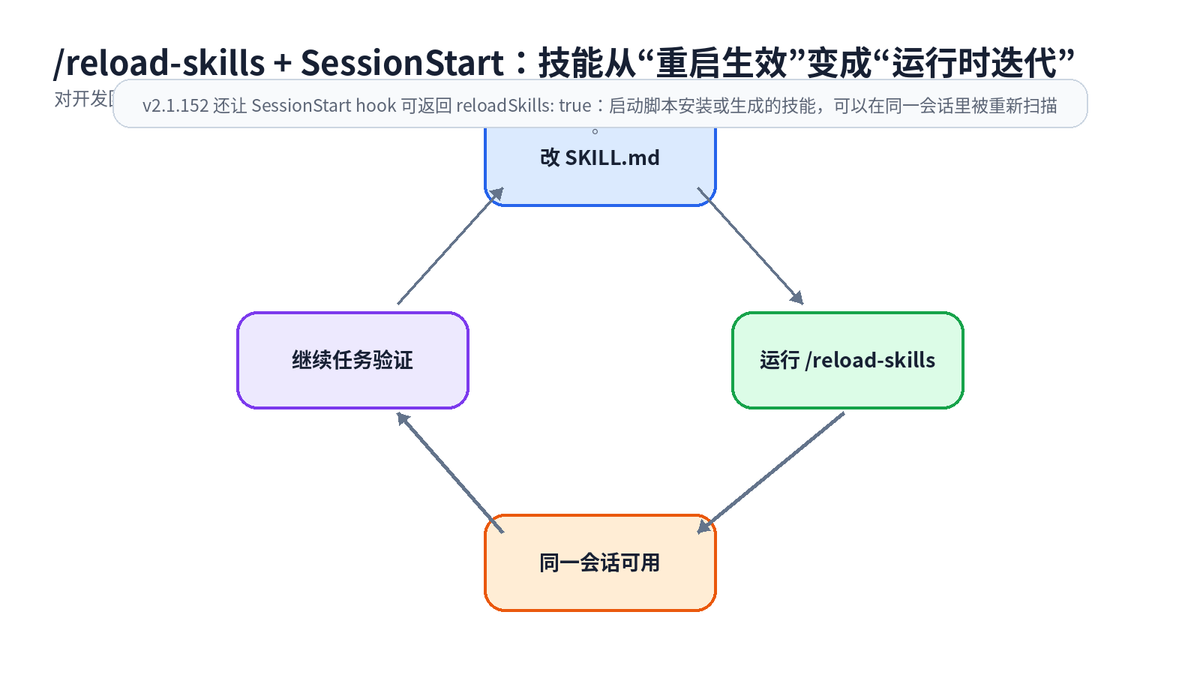
这意味着团队可以像调 Prompt、调配置、调规则一样调 Skill:改一版,reload,一次任务里直接观察效果。对做内部 AI 编程规范的人来说,这会明显缩短迭代周期。
五、SessionStart Hook:每次开工前,先把项目现场装进会话
Hook 是 Claude Code 在生命周期关键节点自动执行的机制。官方文档把事件分成三类:会话级事件、每轮对话事件、工具调用事件。SessionStart 就是会话开始或恢复时触发的事件。
过去我们经常要在每次开 Claude Code 时重复交代:当前分支是什么、Issue 是什么、启动命令是什么、哪个目录别动、测试怎么跑。SessionStart Hook 的价值就是把这些“开工前准备”自动化。

v2.1.152 里 SessionStart 又补了两个很实用的点:一个是可以返回 reloadSkills: true,让 Hook 安装或生成的技能在同一会话里可用;另一个是可以通过 hookSpecificOutput.sessionTitle 设置会话标题,让多个任务并行时更容易识别。
对企业团队来说,这类能力最适合用在“项目初始化”和“上下文注入”上,而不是做重型业务逻辑。Hook 应该短、快、可观察,失败后也不能影响主流程。
六、MessageDisplay Hook:不是改变模型输出,而是管理展示层
MessageDisplay Hook 是这一版比较容易被低估的能力。它让 Hook 可以在助手消息展示时,对文本做转换或隐藏。要注意,它不是让模型本身变聪明,也不是让模型真的“忘掉”某些内容,而是对用户看到的展示层做处理。
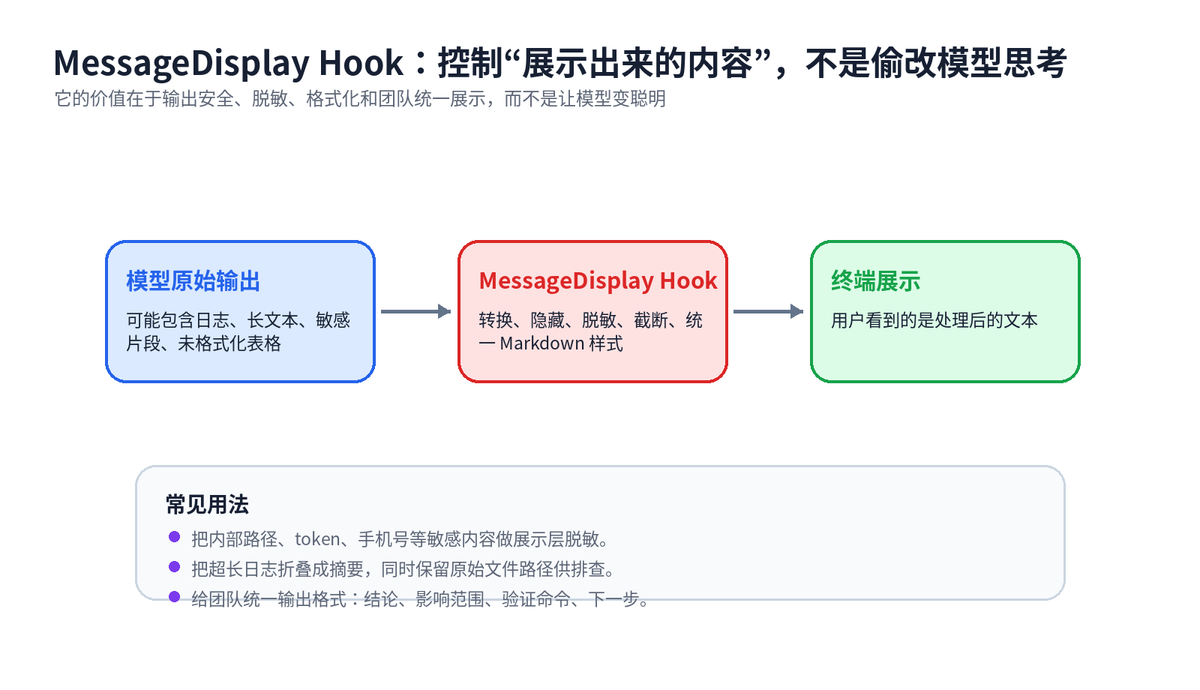
它的工程价值主要在三个方面:
脱敏:终端里展示前隐藏 token、内部路径、手机号、邮箱、客户信息。
降噪:把超长日志折叠、把重复输出隐藏、把无关细节转成摘要。
统一格式:让所有任务都按“结论、影响范围、验证命令、下一步”输出。
这类 Hook 特别适合团队内部环境,因为它能减少“AI 输出不可控”的观感,也能让日志和复盘更整齐。
七、插件市场治理:AI 编程工具开始进入“企业分发”阶段
Claude Code 的插件可以包含 Skills、Agents、Hooks、MCP servers 等能力。官方文档把插件市场描述为一个插件目录,用来集中发现、版本跟踪和自动更新。
个人开发者装插件,更多关注“好不好用”;企业团队装插件,必须先问“能不能管”。v2.1.152 增加 pluginSuggestionMarketplaces 这类托管设置,管理员可以 allowlist 组织市场,控制哪些 marketplace 的插件能被上下文感知提示推荐。
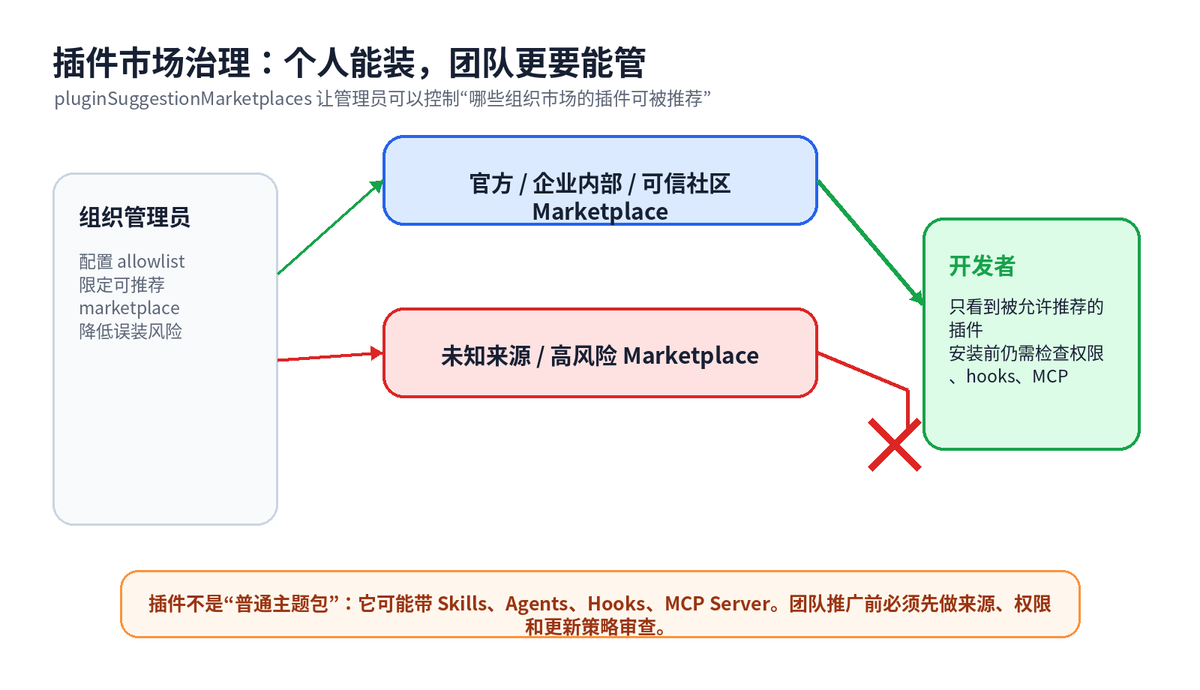
这背后其实是一个信号:AI 编程工具不再只是个人效率工具,它已经开始进入企业标准化分发阶段。公司要沉淀自己的 code-review Skill、部署 Skill、数据库变更 Agent、日志分析 Hook,就需要插件化、版本化和市场化。
建议团队制定三条底线:
所有插件都必须能追溯来源、版本和更新记录。
带 Hook、MCP、Bash 权限的插件必须单独审查。
生产相关插件必须经过灰度试用,不能全员一键铺开。
八、fallback-model、Auto Mode 与长会话体验:让工具“不中断”也很重要
很多人评价 AI 编程工具,只看“生成质量”;但真正天天用的人知道,稳定性也很关键。v2.1.152 里,Claude Code 在主模型未找到时,会切换到配置好的 --fallback-model 并在本会话后续使用,而不是每个请求都失败。
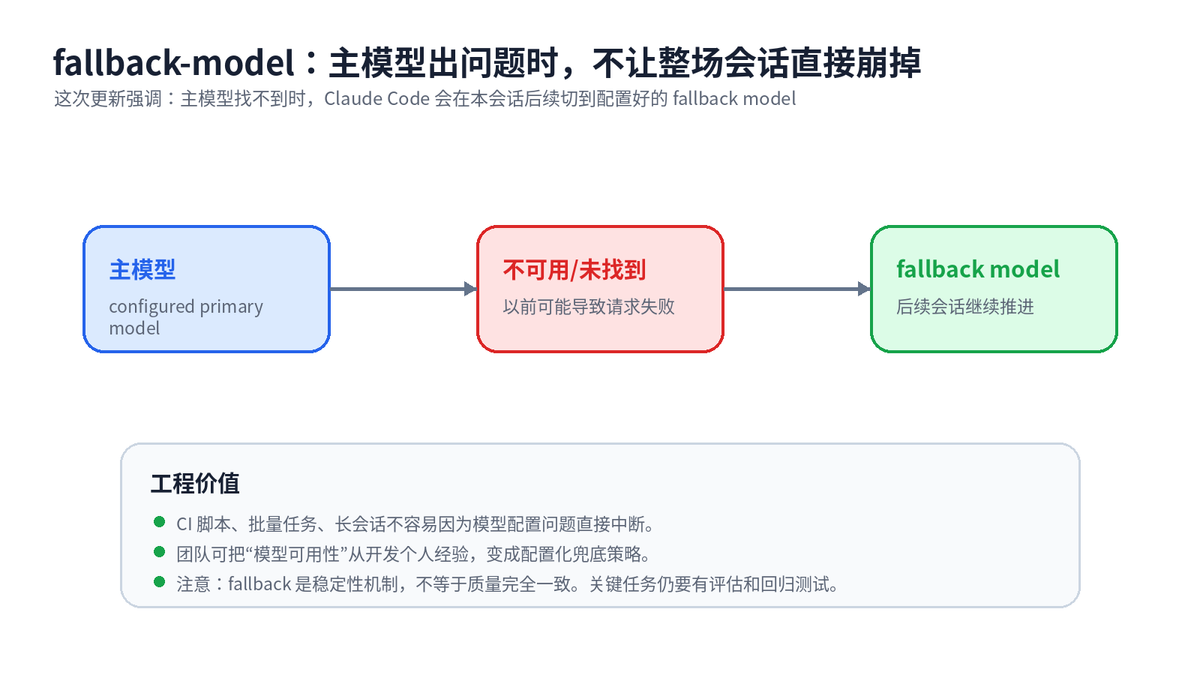
这对长会话、脚本化任务、CI 场景更友好。与此同时,Auto mode 不再要求 opt-in consent,Vim 模式、fullscreen thinking 指示、折叠 thinking 摘要、后台 agent/workflow 计时提示等体验细节也都在修。
这些看起来不是“爆炸性功能”,但它们代表一个产品正在从 Demo 阶段走向日常工作台。越是复杂的 Agent 工具,越需要处理小摩擦:会话长了终端样式崩不崩、后台任务卡在哪里、链接点开会不会误折叠、session 文件大了内存会不会飙升。
九、/usage + OpenTelemetry:AI 编程不能只靠体感,要能算账
这一版 /usage 统计会包含 large session files,并使用 streaming read 保持内存稳定;同时 OpenTelemetry 增加 app.entrypoint 作为指标属性。官方监控文档也说明,Claude Code 可以通过 OTel 导出 metrics、events/logs,并可选导出 traces,用来跟踪成本、工具活动和组织使用情况。
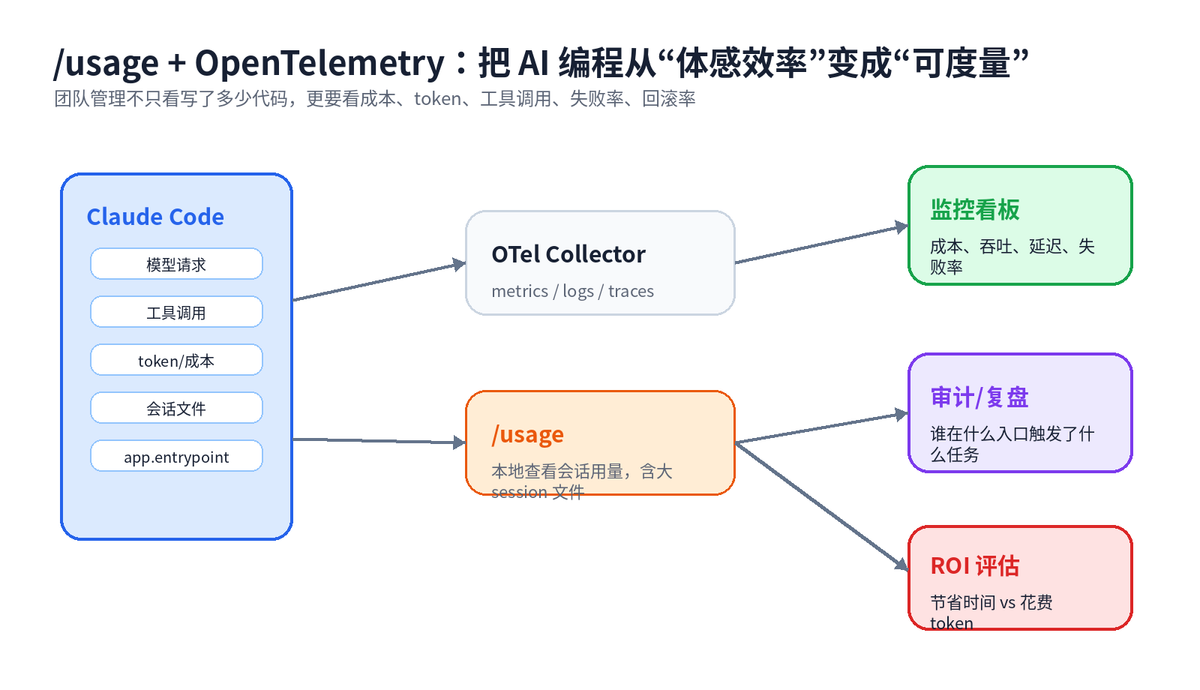
这件事非常关键。团队引入 AI 编程,不应该只问“大家感觉效率变高了吗”,而应该问:
每类任务平均花多少 token、多少钱、多少分钟?
AI 修改后测试通过率是多少?返工率是多少?
哪些命令、技能、插件最常用?哪些最容易失败?
哪个入口触发的任务成本最高?是交互终端、脚本、CI,还是 Web?
只有把 AI 编程纳入监控体系,团队才敢从“少数人试用”推进到“稳定生产力工具”。
十、把这些能力串起来:一个 Java 后端团队可以怎么用?
假设你是一个 Java 后端团队,准备把 Claude Code v2.1.152 用到日常研发。一个可落地的流程可以这样设计:
每个仓库放项目级 .claude/skills:接口变更、单测补全、SQL 检查、日志规范、异常码规范。
把高风险任务设置 disable-model-invocation,必须由开发者手动输入命令触发。
为每个 Skill 设置 allowed-tools / disallowed-tools,避免只读任务误执行命令。
SessionStart Hook 自动读取当前分支、关联 Issue、README、测试命令、运行环境。
PreToolUse Hook 对 rm、curl pipe sh、数据库写入等危险命令做拦截。
MessageDisplay Hook 对内部 token、客户信息、敏感路径做展示层脱敏。
代码完成后执行 /code-review --fix,生成低风险修复,再由开发者看 diff 和跑测试。
所有用量通过 /usage 和 OTel 进入看板,按任务类型评估 ROI。

十一、升级后的检查清单:别只 npm update 就完事
如果你准备在团队里使用 v2.1.152,建议按下面清单推进:
|
检查项 |
怎么做 |
|
版本确认 |
运行 claude --version,确认团队成员版本一致。 |
|
技能梳理 |
把高频提示词整理成 Skills:review、test、commit、api-doc、sql-check。 |
|
权限边界 |
给每个 Skill 标注允许和禁止工具,副作用强的任务禁止模型自动触发。 |
|
Hook 试点 |
先从 SessionStart 和 PreToolUse 开始,不要一口气塞太多自动化。 |
|
插件治理 |
明确团队允许使用哪些 marketplace,插件要有版本和来源审查。 |
|
监控接入 |
接入 /usage 与 OTel,看 token、成本、工具调用、任务失败率。 |
|
回归集 |
准备 20~50 个真实开发任务样本,每次升级跑一遍,避免新版本改变行为。 |
十二、冷静一点:它更自动了,但不能替你负责
最后必须强调:自动修复、热更新技能、Hook、插件市场和 fallback,并不意味着可以把代码控制权完全交给 AI。越是强大的 Agent 工具,越需要工程边界。
AI 可以生成 patch,但代码责任仍然属于提交者。
AI 可以跑命令,但命令权限必须可审计、可回滚。
AI 可以安装插件,但插件来源和权限必须经过团队治理。
AI 可以把信息展示得更干净,但不能用展示层脱敏替代数据安全设计。
AI 可以 fallback 到备用模型,但不同模型的行为差异必须通过评估集发现。
真正成熟的 AI 编程体系,不是“让模型随便干”,而是让模型在明确流程、明确权限、明确验收标准下干活。Claude Code v2.1.152 这次更新的价值,也正是在这里。
十三、总结:Claude Code 的下一阶段,是“可编排、可治理、可观测”
这次 v2.1.152 不是一个只适合发更新日志的版本。它给开发者和团队都提供了一个信号:AI 编程工具正在从“问答式助手”进入“工程化运行时”阶段。
个人开发者看到的是:/code-review --fix 更省事、/reload-skills 更顺手、fallback-model 更稳定。团队负责人看到的应该是:Skills 可以沉淀经验,disallowed-tools 可以约束能力,Hooks 可以嵌入流程,插件市场可以统一分发,OTel 可以衡量成本和效果。
一句话收尾:模型负责能力上限,工程体系负责稳定下限。Claude Code v2.1.152 真正值得关注的地方,不只是它帮你多写几行代码,而是它开始让 AI 编程变得更像一套可持续运转的研发基础设施。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献201条内容
已为社区贡献201条内容

所有评论(0)