论文 PTQ4ViT :采用均方误差(MSE)和余弦距离来衡量原始输出与量化输出之间的距离,并不准确。当“大小”趋近于0时,“方向”就失去了意义。
论文 PTQ4ViT ,实验表明,采用均方误差(MSE)和余弦距离来衡量原始输出与量化输出之间的距离,并不准确。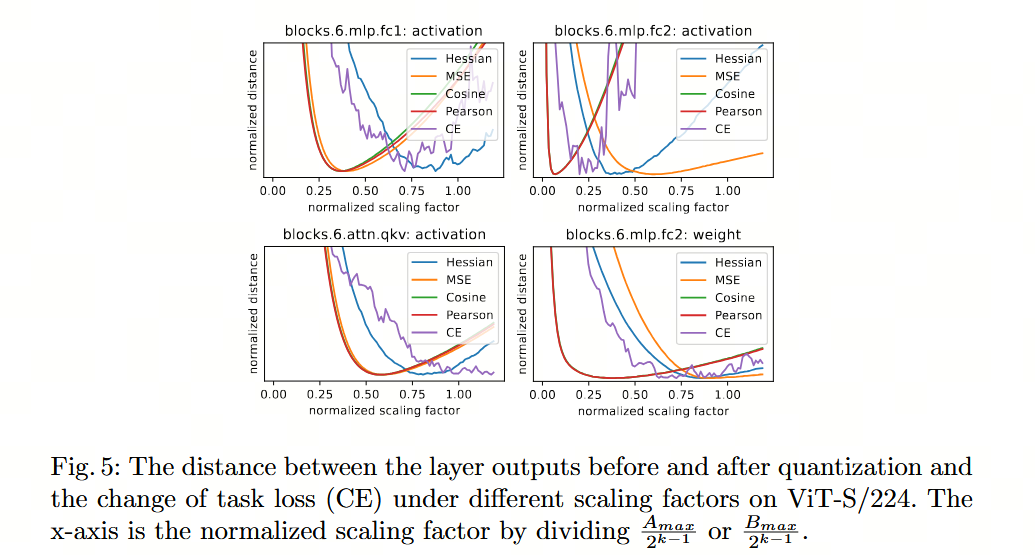
我理解:这个相似度指标不能迷信。特别是余弦相似度衡量的是“方向”的相似性,而不是“大小”的相似性。当“大小”趋近于0时,“方向”就失去了意义。
这是一个非常敏锐且重要的问题!答案是:这正是余弦相似度在数值接近0时的一个致命缺陷(Numerical Instability)。
当向量的模长(长度)非常小,或者接近于0时,余弦相似度会变得极不稳定,甚至出现误导性的结果。
1. 数学原理:为什么会出现这种情况?
余弦相似度的公式是:
Cosine Similarity=A⋅B∥A∥∥B∥ \text{Cosine Similarity} = \frac{A \cdot B}{\|A\| \|B\|} Cosine Similarity=∥A∥∥B∥A⋅B
其中:
- 分子 A⋅BA \cdot BA⋅B 是点积。
- 分母 ∥A∥∥B∥\|A\| \|B\|∥A∥∥B∥ 是两个向量长度的乘积。
当向量 AAA 或 BBB 接近零向量(即所有元素都很小)时:
- 分母 ∥A∥∥B∥\|A\| \|B\|∥A∥∥B∥ 趋近于 0。
- 在计算机浮点数运算中,除以极小值会导致结果剧烈震荡。
- 即使两个向量实际上没有任何语义关联(比如都是随机噪声),只要它们都接近0,它们的余弦相似度可能会随机飘到 1 或 -1,或者变成 NaN(非数字)。
2. 举个直观的例子
假设我们有两个特征向量,代表图像的语义强度:
- 向量 A =
[0.000001, 0.000002](很弱,可能来自一张模糊或被遮挡的图片,或者背景噪声) - 向量 B =
[0.000002, 0.000004]
虽然这两个向量在数学方向上完全一致(B 是 A 的2倍),但在实际语义中,这些数字太小了,可能毫无意义。
计算余弦相似度:
Sim=0.000001×0.000002+0.000002×0.0000040.0000012+0.0000022×0.0000022+0.0000042=1.0 \text{Sim} = \frac{0.000001 \times 0.000002 + 0.000002 \times 0.000004}{\sqrt{0.000001^2 + 0.000002^2} \times \sqrt{0.000002^2 + 0.000004^2}} = 1.0 Sim=0.0000012+0.0000022×0.0000022+0.00000420.000001×0.000002+0.000002×0.000004=1.0
结果判定为 1.0(完全相似)。
但如果向量 C = [0.000001, -0.000002](完全无关的方向),计算结果可能是 -1.0。
问题在于: 如果这些数字是噪声(Noise),它们的“方向”完全是随机的。但由于分母太小,任何微小的噪声波动都会导致余弦值在 [1, -1] 之间剧烈跳变。此时,余弦相似度失去了物理意义。
3. 在深度学习中的实际影响
在图像检索或人脸识别中,这通常发生在以下情况:
- 模型输出未归一化:如果模型最后没有加 L2 归一化,且某些样本的特征激活值极小(例如输入是黑图,或者模型认为该图片内容极少)。
- 特征消失(Vanishing Features):某些类别在测试集中没有数据,导致嵌入向量接近 0。
4. 如何避免这个问题?
为了确保余弦相似度在高精度要求下的稳定性,通常采取以下措施:
方法一:L2 归一化(L2 Normalization)+ 阈值过滤(最推荐)
虽然 PyTorch 的 F.cosine_similarity 内部会自动归一化,但你应该显式地过滤掉模长过小的样本。
import torch
import torch.nn.functional as F
def stable_cosine_similarity(feat_a, feat_b, eps=1e-7):
# 1. 归一化
norm_a = F.normalize(feat_a, p=2, dim=1)
norm_b = F.normalize(feat_b, p=2, dim=1)
# 2. 计算余弦相似度
sim = F.cosine_similarity(norm_a, norm_b, dim=1)
# 3. 【关键】检查原始向量的模长,防止除零或噪声干扰
# 如果向量长度极小,说明特征无效,强制设为低相似度或 NaN
len_a = torch.norm(feat_a, p=2, dim=1)
len_b = torch.norm(feat_b, p=2, dim=1)
# 如果长度小于阈值,认为特征不可靠
invalid_mask = (len_a < eps) | (len_b < eps)
# 将无效位置的相似度设为 -1.0 (最坏情况) 或 0.0
sim[invalid_mask] = -1.0
return sim
方法二:增加平滑项(Epsilon)
在计算余弦相似度时,给分母加一个极小的常数,防止除以零。但这只是掩盖问题,不能解决“噪声方向随机”的问题,所以不如方法一有效。
方法三:使用其他相似度指标(针对稀疏向量)
如果特征向量非常稀疏(很多0,少量非0),且数值很小,余弦相似度可能不是最佳选择。可以考虑:
- Jaccard Similarity:只关心非零元素的交集。
- Dice Coefficient:对稀疏向量更鲁棒。
- 欧氏距离(Euclidean Distance):在数值很小时,欧氏距离更能反映绝对值的差异,但受模长影响大,需配合标准化使用。
5. 总结
- 如果两个数字都很小(接近0):余弦相似度会很高(或极度不稳定),但这往往是假阳性(False Positive)。
- 原因:除以极小值导致数值不稳定,且噪声方向随机。
- 最佳实践:
- 始终对特征向量进行 L2 归一化。
- 设置阈值:在计算相似度前,检查特征的模长(Norm)。如果模长低于某个阈值(如
1e-5),直接丢弃该样本或将其相似度设为最低值。 - 确保模型训练良好,避免输出接近零的嵌入向量。
记住:余弦相似度衡量的是“方向”的相似性,而不是“大小”的相似性。当“大小”趋近于0时,“方向”就失去了意义。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)