Self-Distilled RLVR翻译
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
On-policy distillation(OPD)已成为 LLM 领域中一种流行的训练范式。与仅从环境中可验证结果获取稀疏信号的强化学习(RLVR)不同,OPD 选择一个规模更大的模型作为 teacher,为每个采样轨迹提供密集且细粒度的信号。近年来,该领域探索了 on-policy self-distillation(OPSD),其中同一个模型既作为 teacher 又作为 student,teacher 模型接收额外的特权信息(例如参考答案)以实现自我进化。本文证明,仅从特权 teacher 模型获取的学习信号会导致严重的信息泄露和长期训练的不稳定性。因此,我们确定了自蒸馏的最佳应用场景,并提出了 RLSD (RLVR with Self-Distillation)。具体而言,我们利用 self-distillation 来获取 token 级策略差异,从而确定细粒度的更新幅度;同时继续使用 RLVR 从环境反馈(例如,响应正确性)中导出可靠的更新方向。这使得 RLSD 能够同时发挥 RLVR 和 OPSD 的优势,实现更高的收敛上限和更优异的训练稳定性。
1.介绍
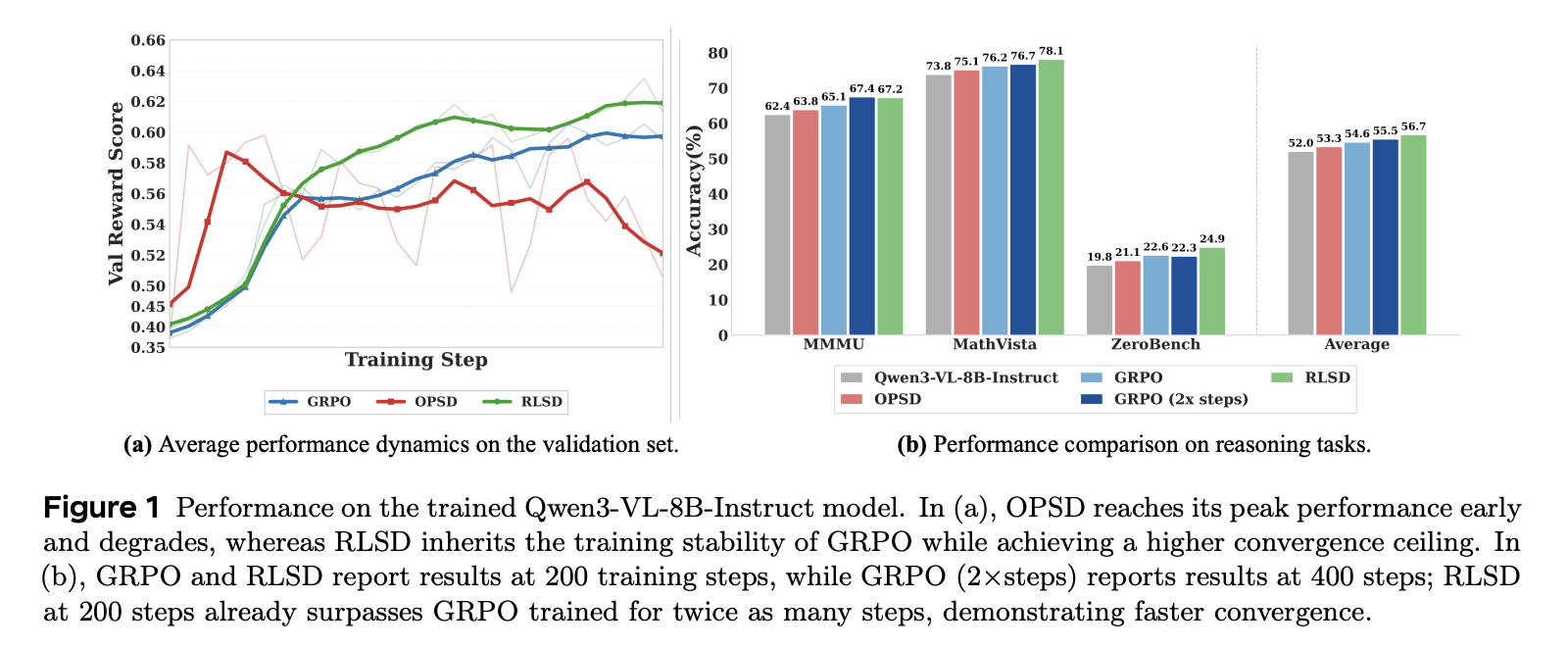
诸如 GRPO 之类的强化学习与可验证奖赏(RLVR)方法已成为训练大型推理模型的核心范式,其中每条轨迹仅接收一个由环境结果决定的标量信号。On-policy distillation(OPD)通过利用更强大的 teacher 模型,为 student 自身采样的轨迹提供密集的、token 级的 logits 作为学习信号,从而对 RLVR 进行补充,将轨迹级的监督信息提升到 token 级,进而实现更快的收敛速度。最近的研究表明,来自高级 teacher 的 OPD 可以达到甚至超越 RLVR 的性能,使其成为一种同样引人注目的范式(详见表1的系统比较)。
尽管 OPD 有效,(1)但它依赖于一个独立的、通常规模更大的 teacher 模型,这会带来巨大的计算开销。(2)此外,由于 OPD 需要计算共享词表上的 token 级分布,teacher 模型和 student 模型必须共享相同的词表,这显著降低了该范式的实际可扩展性。On-policy self-distillation (OPSD) 提供了一种颇具吸引力的替代方案:单个模型同时充当 teacher 和 student,其中 teacher 模型是同一模型,但基于特权信息 rrr(例如已验证的推理轨迹或环境反馈)进行条件判断,而 student 模型仅对输入 query 进行运算。OPSD 在token 效率方面比 GRPO 提高了数倍,且无需任何外部模型。然而,我们证明这种效率提升是脆弱的:如图 1(a) 中的红线所示,性能在早期达到峰值后迅速下降,同时伴随着系统性的特权信息泄露,即模型在推理过程中显式地调用了一个不可见的参考解,尽管它从未真正访问过该参考解(参见图 2 中的代表性示例)。这些现象引出了一个自然的问题:为什么 OPD 有效而 OPSD 失败?

我们发现答案在于两种设置之间的结构性差异。在 OPD 中,teacher 和 student 观察到相同的输入(信息对称),因此 teacher 的密集信号反映了在共享信息访问条件下更优的推理能力。在 OPSD 中,teacher 基于student 无法观察到的特权信息进行条件判断(信息不对称),从而造成了根本性的不匹配。我们证明,这种不对称性使得 OPSD 目标函数不适定:它包含一个不可约的互信息差距 I(Yt;R∣X,Y<t)>0I(Y_t; R | X, Y_{<t}) > 0I(Yt;R∣X,Y<t)>0,无论学生的容量如何,都无法消除该差距(定理 1)。在梯度层面,我们证明,虽然预期的 OPSD 梯度是良性的,但每个样本的梯度都存在一个与 rrr 相关的偏差,其方差与该互信息成正比。这些理论发现与我们的诊断实验直接吻合:在 OPSD 模型下,teacher 和 student 之间的 on-policy KL 偏差停滞不前,没有持续下降;而在 OPD 模型下,该指标则稳步下降,如图 3 所示。在训练初期,有利的梯度分量占主导地位,带来快速提升;随着 student 逐渐接近 teacher 的边缘分布,偏差分量开始占据主导地位,其路径依赖性的累积驱动模型在其参数中编码 x→rx→rx→r 相关性。这种两阶段动态过程精确地解释了观察到的早期提升后逐渐退化的模式。
我们的分析精准地指出了根本原因:在所有分布匹配模型中,teacher 的特权评估 PT(yt∣r)P_T(y_t|r)PT(yt∣r) 都进入了梯度方向,使得无论蒸馏目标如何压缩,泄漏在结构上都不可避免。然而,证据比率 PT(yt)/PS(yt)P_T(y_t)/P_S(y_t)PT(yt)/PS(yt) 也包含一个有用的信号:它衡量了特权信息对模型关于每个 token 的信念修正程度。因此,挑战不在于丢弃这个信号,而在于改变它的使用方式。我们设计的一个关键洞察是,控制更新方向和更新幅度的信号具有不对称的要求:方向信号可以稀疏,但必须可靠,因为错误的方向会损害策略;相比之下,幅度信号则需要尽可能密集,以便对 token 进行细粒度区分。
我们提出了 RLVR with Self-Distillation (RLSD),该算法通过将 teacher 模型从生成目标重新定位为幅度评估器来实现这一原则。具体而言,环境奖赏决定每个 token 更新的方向(强化或惩罚),而 teacher 模型的证据比率仅调节幅度。这种解耦使得梯度方向完全锚定于可靠的环境奖赏,同时保留了 teacher 模型密集的、token 级的评估信息,从而实现跨 token 位置的细粒度信用区分。值得注意的是,以往的 token 级信用分配方法,例如 PPO 中的 value 函数估计和各种信用分配方法,通常需要训练辅助网络或产生大量的额外开销,但仍然会产生噪声估计。相比之下, self-distillation 提供了一种自然且几乎零成本的 token 级信用信息来源,仅需一次额外的前向传播。如表 1 所示,RLSD 是唯一能够同时实现 on-policy 训练、高 token 效率、丰富的更新信号和环境锚定优化的范式,并且无需任何辅助损失或模型即可直接替代标准 GRPO 中的统一优势。我们的贡献如下:
- 我们通过受控实验和正式分析确定了 OPSD 失败的根本原因,证明信息不对称下的分布匹配会导致不可缩小的差距,从而通过梯度结构驱动特权信息泄露。
- 我们提出了 RLSD,一种新的训练范式,它融合了 RLVR 和 OPSD 的优势:可靠的环境奖赏控制更新方向,而特权教师提供丰富的、token 级别的更新幅度调节。
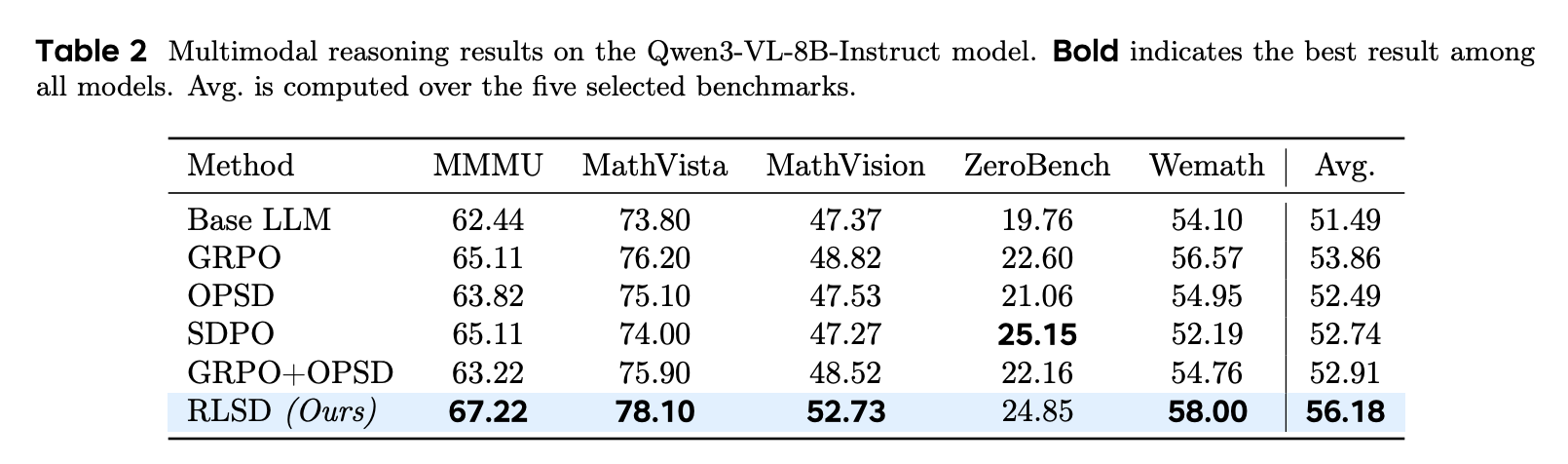
- 大量实验表明,RLSD 在五个多模态推理基准测试中取得了最佳平均准确率,比基础 LLM 高出 4.69%,并且在自蒸馏性能下降之后仍能保持改进。
2.Preliminaries
GRPO。考虑一个用于解决推理任务的语言模型 πθπ_θπθ。给定一个问题 xxx,该模型自回归地生成一个响应 y=(y1,...,yT)y = (y_1, . . . , y_T)y=(y1,...,yT)。在 RLVR 设置中,verifier 提供一个二元奖赏 R(x,y)∈{0,1}R(x, y) ∈ \{0, 1\}R(x,y)∈{0,1},指示响应是否正确。Group Relative Policy Optimization (GRPO) 从当前策略中为每个问题 xxx 抽取一组 GGG 个响应 {y(1),...,y(G)}\{y^{(1)}, . . . , y^{(G)}\}{y(1),...,y(G)},并计算每个响应相对于该组的序列级优势:
A(i)=R(x,y(i))−μGσG,(1)A^{(i)}=\frac{R(x,y^{(i)})-\mu_G}{\sigma_G},\tag{1}A(i)=σGR(x,y(i))−μG,(1)
其中 µGµ_GµG 和 σGσ_GσG 分别是组内奖赏的均值和标准差。然后通过截断的代理目标函数更新策略:
LGRPO(θ)=E[1G∑i=1G1∣y(i)∣∑t=1∣y(i)∣min(ρt(i)A(i),clip(ρt(i),1−ϵ,1+ϵ)A(i))],(2)\mathcal L_{GRPO}(\theta)=\mathbb E\left [\frac{1}{G}\sum^G_{i=1}\frac{1}{|y^{(i)}|}\sum^{|y^{(i)}|}_{t=1}min(ρ^{(i)}_tA^{(i)},clip(ρ^{(i)}_t,1-ϵ,1+ϵ)A^{(i)})\right ],\tag{2}LGRPO(θ)=E G1i=1∑G∣y(i)∣1t=1∑∣y(i)∣min(ρt(i)A(i),clip(ρt(i),1−ϵ,1+ϵ)A(i)) ,(2)
其中 ρt(i)=πθ(yt(i)∣x,y<t(i))/πθold(yt(i)∣x,y<t(i))ρ^{(i)}_t = π_θ(y^{(i)}_t| x, y^{(i)}_{<t})/π_{θ_{old}}(y^{(i)}_t| x, y^{(i)}_{<t})ρt(i)=πθ(yt(i)∣x,y<t(i))/πθold(yt(i)∣x,y<t(i)) 是当前策略和旧策略之间的重要性采样比率。GRPO 的一个关键局限性在于,响应中的所有 token 共享相同的优势 A(i)A^{(i)}A(i),因为奖赏信号仅在序列级别提供。
OPD and OPSD。On-Policy Distillation (OPD) 通过让 student 模型 πθπ_θπθ 对其自身轨迹进行采样,同时由一个独立的、通常更大的 teacher 模型 πθ^π_{\hat θ}πθ^ 提供密集的 token 级监督,来解决稀疏奖赏问题。虽然这种方法有效,但在整个训练过程中维护一个独立的 teacher 模型会带来显著的计算开销。On-Policy Self-Distillation (OPSD) 通过使用单个模型 πθπ_θπθ 实例化 student 和 teacher 的角色来消除这一需求:teacher 的信息优势并非来自更大的容量,而是来自对特权信息 rrr(例如,经过验证的推理轨迹)的条件化。
两种方法采用相同的训练范式。给定一个数据集 S={(xi,ri)}i=1N\mathcal S = \{(x_i, r_i)\}^N_{i=1}S={(xi,ri)}i=1N,学生生成 on-policy rollout y^∼PS(⋅∣x)\hat y ∼ P_S(· | x)y^∼PS(⋅∣x),训练的目标是最小化学生轨迹上每个 token 的 teacher 分布和 student 分布之间的差异。这两个框架的区别仅在于 teacher 的定义方式:
Student:PS(⋅∣y<t)≜πθ(⋅∣x,y<t),(3)\text{Student}: P_S(\cdot|y_{\lt t})≜\pi_{\theta}(\cdot|x,y_{\lt t}),\tag{3}Student:PS(⋅∣y<t)≜πθ(⋅∣x,y<t),(3)
OPD Teacher:PT(⋅∣y<t)≜πθ^(⋅∣x,y<t),(4)\text{OPD Teacher}: P_T(\cdot|y_{\lt t})≜\pi_{\hat \theta}(\cdot|x,y_{\lt t}),\tag{4}OPD Teacher:PT(⋅∣y<t)≜πθ^(⋅∣x,y<t),(4)
OPSD Teacher:PT(⋅∣y<t)≜πθ^(⋅∣x,r,y<t),(5)\text{OPSD Teacher}: P_T(\cdot|y_{\lt t})≜\pi_{\hat \theta}(\cdot|x,r,y_{\lt t}),\tag{5}OPSD Teacher:PT(⋅∣y<t)≜πθ^(⋅∣x,r,y<t),(5)
共同的训练目标是:
LOP(S)D=E(x,r)∼SEy^∼PS(⋅∣x)[1∣y^∣∑t=1∣y^∣D(PT∣∣PS)],(6)\mathcal L_{OP(S)D}=\mathbb E_{(x,r)\sim \mathcal S}\mathbb E_{\hat y\sim P_S(\cdot|x)}\left [\frac{1}{|\hat y|}\sum^{|\hat y|}_{t=1}D(P_T||P_S)\right ],\tag{6}LOP(S)D=E(x,r)∼SEy^∼PS(⋅∣x) ∣y^∣1t=1∑∣y^∣D(PT∣∣PS) ,(6)
其中 DDD 是散度度量,例如广义 Jensen-Shannon 散度。梯度仅通过 PSP_SPS 进行反向传播,而 PTP_TPT 则作为固定目标。OPSD 通过提供密集的 token 监督,无需外部 teacher 模型,从而实现了高 token 效率。
3.Why Does OPD Work While OPSD Fails?
3.1 Empirical Observations: Leakage and Performance Degradation
在第 3.2 节进行正式分析之前,我们记录了促使我们进行分析的经验现象。
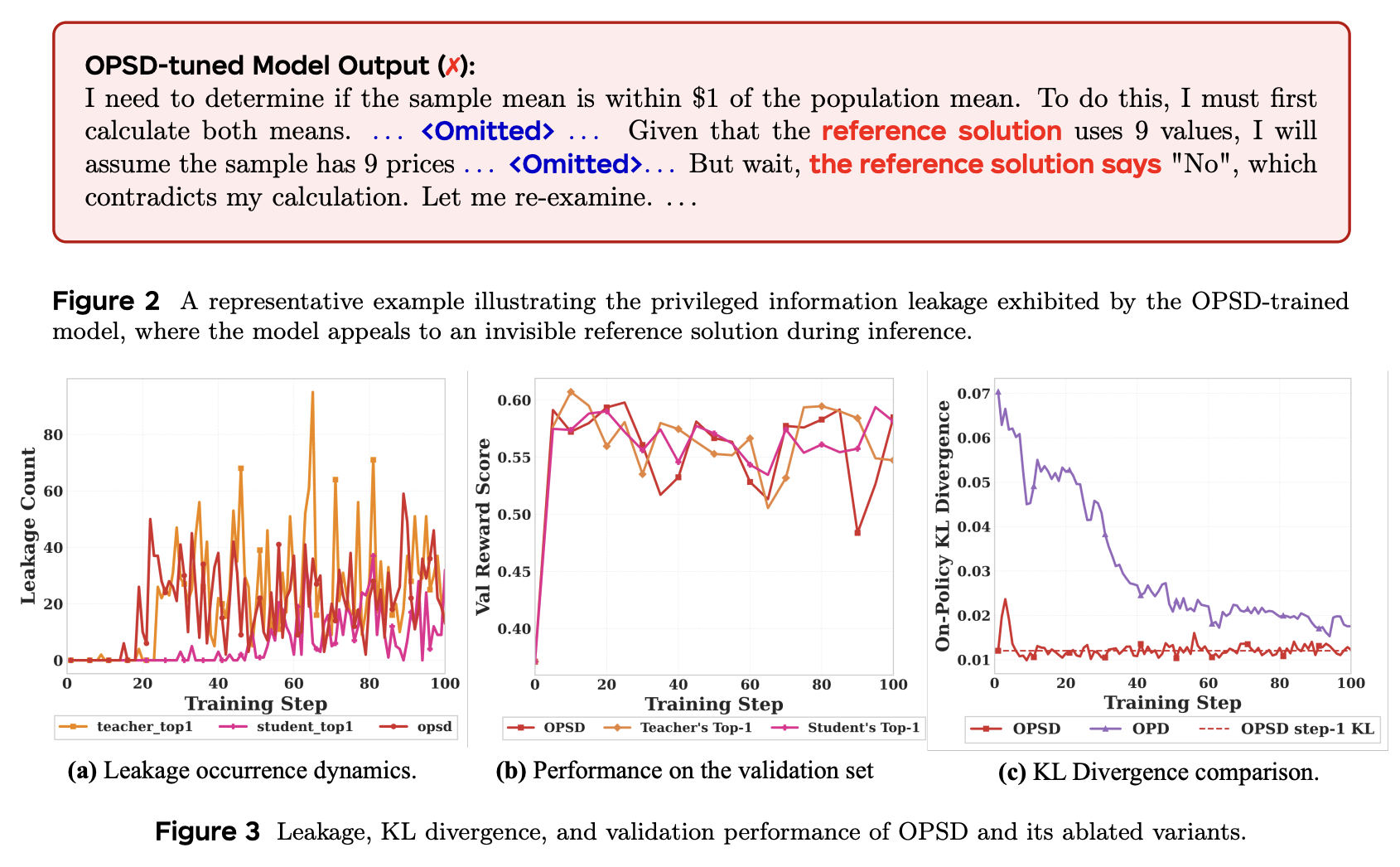
Privileged information leakage。我们首先观察到,使用 OPSD 训练的模型会系统性地引用推理时不可用的特权信息。图 2 展示了一个典型示例,其中模型在生成过程中显式地调用了一个不可见的“参考解”。这种行为并非个例。正如我们在以下分析中所量化的,这种信息泄露会随着训练过程逐渐加剧。
Performance degradation。图 3(a) 追踪了 100 个训练步骤中特权信息泄露的频率,并揭示出一个单调递增的趋势:模型对测试时无法获取的信息的依赖性逐渐增强。图 3(b) 显示了相应的验证准确率,该准确率在前 10-20 个步骤中达到峰值,随后下降,这与泄露频率的增加相一致。
KL divergence stagnation。进一步的诊断对比了 OPD 和 OPSD 两种教学模式下 teacher 与 student 在策略层面上的 KL 差异(图3©)。在 OPD 模式下,KL 差异在整个训练过程中稳步下降,反映了真正的趋同。而在 OPSD 模式下,差异在最初几个步骤中短暂下降,随后稳定在与初始值相当的水平,没有持续下降的趋势。这种停滞表明 OPSD 目标中存在一个无法缩小的差距,阻碍了有意义的趋同,我们将在下一小节中对此假设进行形式化阐述。
3.2 OPSD’s Failure: An Ill-Posed Objective
我们正式阐述了 OPSD 及相关方法所基于的分布匹配范式的结构性缺陷。我们的分析分为两个层面:目标函数(§3.2.1)和梯度动态(§3.2.2)。
3.2.1 The Irreducible Mutual Information Gap
令 rrr 表示特权信息,它从条件分布 P(r∣x)P(r \mid x)P(r∣x) 中采样得到。由于任意给定问题 xxx 都允许存在多条语义上有效的推理路径,P(r∣x)P(r \mid x)P(r∣x) 是一个具有非零熵的非退化分布。即使每个训练样本 xix_ixi 都与一个单一的参考推理轨迹 rir_iri 配对,从 student 模型的认知视角来看,由于它既无法观测 rrr,也无法从 xxx 中确定性地推导出 rrr,特权信息仍然是一个不确定的潜变量。因此,在概率建模框架中,P(r∣x)P(r \mid x)P(r∣x) 应被视为非退化分布。
一个不能以 rrr 为条件的最优 student 策略,应当通过全概率公式恢复边缘 teacher 分布:
PS∗(yt∣x,y<t)=Er∼P(r∣x,y<t)[PT(yt∣x,r,y<t)].(7) P_S^*(y_t \mid x, y_{<t}) = \mathbb{E}_{r \sim P(r \mid x, y_{<t})} \left[ P_T(y_t \mid x, r, y_{<t}) \right]. \tag{7} PS∗(yt∣x,y<t)=Er∼P(r∣x,y<t)[PT(yt∣x,r,y<t)].(7)
令
PˉT(yt)≜Er[PT(yt∣x,r,y<t)] \bar{P}_T(y_t) \triangleq \mathbb{E}_r \left[ P_T(y_t \mid x, r, y_{<t}) \right] PˉT(yt)≜Er[PT(yt∣x,r,y<t)]
表示该边缘分布,则理想蒸馏目标为:
L∗(θ)=Ex[DKL(PˉT(⋅)∣∣PS(⋅∣x))].(8) \mathcal{L}^*(\theta)= \mathbb{E}_x \left[ D_{\mathrm{KL}} \left( \bar{P}_T(\cdot) || P_S(\cdot \mid x) \right) \right]. \tag{8} L∗(θ)=Ex[DKL(PˉT(⋅)∣∣PS(⋅∣x))].(8)
然而,OPSD 目标强制对每一个具体的样本对 ((x, r)) 进行逐样本匹配:
PS(⋅∣x)→PT(⋅∣x,r) P_S(\cdot \mid x) \to P_T(\cdot \mid x, r) PS(⋅∣x)→PT(⋅∣x,r)
其形式为:
LOPSD(θ)=ExEr∼P(r∣x)[DKL(PT(⋅∣x,r)∣∣PS(⋅∣x))].(9) \mathcal{L}_{\mathrm{OPSD}}(\theta)= \mathbb{E}_x \mathbb{E}_{r \sim P(r \mid x)} \left[ D_{\mathrm{KL}} \left( P_T(\cdot \mid x, r) || P_S(\cdot \mid x) \right) \right]. \tag{9} LOPSD(θ)=ExEr∼P(r∣x)[DKL(PT(⋅∣x,r)∣∣PS(⋅∣x))].(9)
这迫使一个条件独立的参数化模型(即 PSP_SPS 不以 rrr 作为输入)去匹配一个条件依赖的目标分布(即 PTP_TPT 依赖于 rrr),从而构成一个根本上病态的要求。
Theorem 1(KL 分解). OPSD 目标与理想目标满足如下恒等式:
LOPSD=L∗+I(Yt;R∣X,Y<t),(10) \mathcal{L}_{\mathrm{OPSD}}= \mathcal{L}^* + I(Y_t; R \mid X, Y_{<t}), \tag{10} LOPSD=L∗+I(Yt;R∣X,Y<t),(10)
其中,I(Yt;R∣X,Y<t)I(Y_t; R \mid X, Y_{<t})I(Yt;R∣X,Y<t) 表示在 teacher 分布下,当前 token YtY_tYt 与特权信息 RRR 之间的条件互信息。
证明见附录 A.1。该互信息项量化了教师在 token 级别的预测对特权信息的依赖程度;而该特权信息在构造上对学生模型是不可访问的。关键在于,I(Yt;R∣X,Y<t)I(Y_t; R \mid X, Y_{<t})I(Yt;R∣X,Y<t) 与 θ\thetaθ 无关:它完全由教师的条件分布以及 P(r∣x)P(r \mid x)P(r∣x) 决定。student 的优化过程无法消除这一差距。在可行集合
F={Q:Q(⋅∣x,y<t) 不以 r 为条件} \mathcal{F}= \left\{ Q : Q(\cdot \mid x, y_{<t}) \text{ 不以 } r \text{ 为条件} \right\} F={Q:Q(⋅∣x,y<t) 不以 r 为条件}
内,全局最优解为
PS∗=PˉT, P_S^* = \bar{P}_T, PS∗=PˉT,
此时残余损失等于
I(Yt;R∣X,Y<t)>0, I(Y_t; R \mid X, Y_{<t}) > 0, I(Yt;R∣X,Y<t)>0,
这是一个严格为正、不可约的下界,并且会随着特权信号信息量的增加而增大。
该结果为图 3© 中观察到的 KL 停滞现象提供了形式化的解释:OPSD 发散趋于平稳,是因为 student 模型迅速接近 PˉT\bar P_TPˉT 附近,此后残差 I(Yt;R∣X,Y<t)>0I(Y_t; R | X, Y_{<t}) > 0I(Yt;R∣X,Y<t)>0 无法通过合理的优化来降低。图 3© 中的虚线标记了步骤 1 时的 OPSD KL 值,直观地证实了该损失底限在最初几个步骤中就已有效达到。更重要的是,这种不可约残差会积极地干扰优化过程。在目标函数存在偏差的情况下,优化器会持续接收到非零损失信号,并被迫将有害噪声吸收到模型参数中。正如我们将在下一节中解释的那样,该残差项会直接污染梯度方向,使参数更新偏离真正的推理改进,转而编码输入和特权信息之间的虚假相关性。由于 student 的学习架构无法直接以 rrr 为条件,唯一可行的方法是将 xxx 和 rrr 之间的统计相关性编码到参数 θ 中,从而有效地学习一个 x→rx → rx→r 的映射。这就是特权信息泄露的数学根源。相比之下,OPD 采用了一位外部 teacher,其预测并不依赖于学生无法获取的特权信息,因此不会出现互信息差距,KL 散度也持续下降。
3.2.2 Gradient Structure: The Mechanism of Leakage
Theorem 1 表明,I(Yt;R∣X)I(Y_t; R \mid X)I(Yt;R∣X) 与 θ\thetaθ 无关,这可能暗示它不会对梯度产生影响。我们证明,尽管这对于期望梯度成立,但逐样本梯度会携带一个偏差项,而该偏差项的方差直接由这一互信息控制。
Benign expected gradient。 由于 I(Yt;R∣X)I(Y_t; R \mid X)I(Yt;R∣X) 不依赖于 θ\thetaθ,我们有 ∇θLOPSD=∇θL∗=−∑vPˉT(v)∇θlogPS(v)\nabla_\theta \mathcal{L}_{\mathrm{OPSD}} = \nabla_\theta \mathcal{L}^* = -\sum_v \bar{P}_T(v)\nabla_{\theta} \log P_S(v)∇θLOPSD=∇θL∗=−∑vPˉT(v)∇θlogPS(v)。在总体层面,OPSD 的梯度与理想边缘匹配目标的梯度完全相同。
Pathological per-sample gradients。在实践中,优化过程作用于具体样本 (x,r)(x, r)(x,r):
g(θ;r)=−∑v∈VPT(v∣r)⋅∇θlogPS(v).(11) g(\theta; r) = - \sum_{v \in \mathcal{V}} P_T(v \mid r) \cdot \nabla_\theta \log P_S(v). \tag{11} g(θ;r)=−v∈V∑PT(v∣r)⋅∇θlogPS(v).(11)
Proposition 1(逐样本梯度分解). 对于 rrr 的任意具体实现,逐样本梯度都可以分解为:
g(θ;r)=−∑vPˉT(v)∇θlogPS(v)⏟g∗(θ): marginal matching+−∑v[PT(v∣r)−PˉT(v)]∇θlogPS(v)⏟δ(θ;r): r-specific deviation.(12) g(\theta; r)= \underbrace{ -\sum_v \bar{P}_T(v)\nabla_\theta \log P_S(v) }_{g^*(\theta):\ \text{marginal matching}} + \underbrace{ -\sum_v \left[ P_T(v \mid r) - \bar{P}_T(v) \right] \nabla_\theta \log P_S(v) }_{\delta(\theta; r):\ r\text{-specific deviation}} . \tag{12} g(θ;r)=g∗(θ): marginal matching −v∑PˉT(v)∇θlogPS(v)+δ(θ;r): r-specific deviation −v∑[PT(v∣r)−PˉT(v)]∇θlogPS(v).(12)
满足:(i)Er[δ(θ;r)]=0\mathbb{E}_r[\delta(\theta; r)] = 0Er[δ(θ;r)]=0,以及(ii)Er[∣δ(θ;r)∣2]=∑vVarr[PT(v∣r)]⋅∣∇θlogPS(v)∣2\mathbb{E}_r[|\delta(\theta; r)|^2] = \sum_v \mathrm{Var}_r[P_T(v \mid r)] \cdot |\nabla_{\theta} \log P_S(v)|^2Er[∣δ(θ;r)∣2]=∑vVarr[PT(v∣r)]⋅∣∇θlogPS(v)∣2。当 I(Yt;R∣X)=0I(Y_t; R \mid X)=0I(Yt;R∣X)=0 时,该偏差会完全消失;并且它的方差会随着互信息的增大而单调增加。
证明见附录 A.2。性质(i)可能让人认为该偏差在平均意义上是无害的;然而,任何基于单个样本或小批量样本计算梯度的优化器,例如 SGD 和 Adam,本质上都是路径依赖的。在非线性优化中,零均值扰动并不一定会在训练过程中相互抵消。
Two-phase training dynamics。Proposition 1 中的分解将逐样本梯度划分为一个有益分量 g∗g^*g∗ 和一个偏差分量 δ\deltaδ。它们的相对大小会在训练过程中发生变化,并产生两个不同的阶段,这两个阶段恰好对应于 §3.1 中报告的经验现象。
在训练早期,student 模型 PSP_SPS 距离 teacher 的边缘分布 PˉT\bar{P}_TPˉT 很远,因此有益分量占主导:∣g∗(θ)∣≫∣δ(θ;r)∣|g^*(\theta)| \gg |\delta(\theta; r)|∣g∗(θ)∣≫∣δ(θ;r)∣。在这一阶段,梯度主要推动边际匹配,student 模型会快速获得通用推理能力。这对应于图 3(b) 中验证准确率在前 10–20 步内的陡峭上升。随着训练推进并且 PSP_SPS 接近 PˉT\bar{P}_TPˉT,有益分量 ∣g∗(θ)∣|g^*(\theta)|∣g∗(θ)∣ 逐渐趋近于零。然而,偏差分量 ∣δ(θ;r)∣|\delta(\theta; r)|∣δ(θ;r)∣ 仍然不会趋近于零:它的方差由 I(Yt;R∣X)I(Y_t; R \mid X)I(Yt;R∣X) 控制,而该项与 θ\thetaθ 无关,因此不会随着优化过程的推进而衰减。于是,参数更新会越来越受到 δ\deltaδ 的支配,并且这些扰动的路径依赖累积会推动模型进入编码 x→rx \to rx→r 相关性的参数空间区域,从而触发一种自我强化的退化过程。这一转变标志着图 3(b) 中性能下降的开始,也对应于图 3(a) 中泄漏计数的单调增加。
Leakage bandwidth: controlled experiments。梯度分解不仅解释了标准 OPSD 的失败,还给出了一个精确预测:任何让教师的特权评估 PT(⋅∣r)P_T(\cdot \mid r)PT(⋅∣r) 进入梯度方向的变体都会遭受泄漏,无论蒸馏目标如何被压缩。为了检验这一预测,我们在标准 OPSD 之外设计了两个消融变体:(i)Teacher’s Top-1,它仅保留教师概率最高的 token argmaxvPT(v∣r)\arg\max_v P_T(v \mid r)argmaxvPT(v∣r) 作为目标;以及(ii)Student’s Top-1,它将目标支撑集限制为学生概率最高的 token argmaxvPS(v)\arg\max_v P_S(v)argmaxvPS(v)。我们在图 3(a,b) 中报告了这三种变体在 100 个训练步内的泄漏计数和验证准确率。
这三种变体都验证了该预测:泄漏在每一种情况下都会增加。梯度框架通过泄漏带宽这一概念解释了泄漏的普遍性以及严重程度的排序。我们将泄漏带宽定义为:rrr-特定信息进入梯度方向的有效 token 位置数量。完整 OPSD 作用于整个词表 V\mathcal{V}V:teacher 的特权偏好 PT(v∣r)P_T(v \mid r)PT(v∣r) 会加权每个 token 的梯度贡献,因此产生最宽的带宽。Teacher’s Top-1 将目标压缩为单个 token argmaxvPT(v∣r)\arg\max_v P_T(v \mid r)argmaxvPT(v∣r),该 token 完全由 rrr 决定,因此虽然带宽变窄,但它产生了最集中的特权信息注入,这解释了为什么它表现出最严重的泄漏。Student’s Top-1 将目标支撑集限制为 argmaxvPS(v)\arg\max_v P_S(v)argmaxvPS(v),因此带宽最窄;然而,被选中 token 上的梯度权重 PT(vS∗∣r)/PS(vS∗)P_T(v_S^* \mid r) / P_S(v_S^*)PT(vS∗∣r)/PS(vS∗) 仍然是 rrr 的函数,所以泄漏依然存在,只是速率最低。在这三种情况下,梯度方向对 rrr 的依赖都是不可约的(证明见附录 A.3),这解释了图 3(a) 中观察到的泄漏普遍发生。图 3(b) 中的性能退化也直接由此推出:更强的泄漏会加速从第一个训练阶段向第二个训练阶段的转变,并导致更快速的性能下降。
我们在附录 A.4 中进一步分析共享参数耦合的影响。在那里,我们证明,在共享参数条件下,梯度级泄漏与教师漂移之间的相互作用会产生一个不可能三难困境:目标稳定性、持续改进以及无泄漏训练,无法在任何参数管理策略下同时成立。
4.RLSD: Self-Distillation as RLVR’s Wingman
前述分析明确指出了根本原因:分布匹配失败是因为特权信息进入了梯度方向,污染了优化轨迹。然而,导致这一失败的核心量——证据比率 PT(yt)/PS(yt)P_T(y_t)/P_S(y_t)PT(yt)/PS(yt)——也蕴含着有用的信号:它衡量了特权信息对模型关于每个 token 信念的修正程度。因此,挑战不在于舍弃这个信号,而在于改变它的使用方式。我们提出了 RLVR with Self-Distillation (RLSD),它彻底改变了 teacher 模型的角色:PTP_TPT 和 PSP_SPS 之间的差异不再作为分布匹配的生成目标,而是被用作策略梯度框架内 token 级的信用分配信号。特权信息仅影响每个 token 获得的权重,而不会影响哪些 token 被强化或惩罚,也不会影响参数更新的方向。
4.1 From Distribution Matching to Credit Assignment
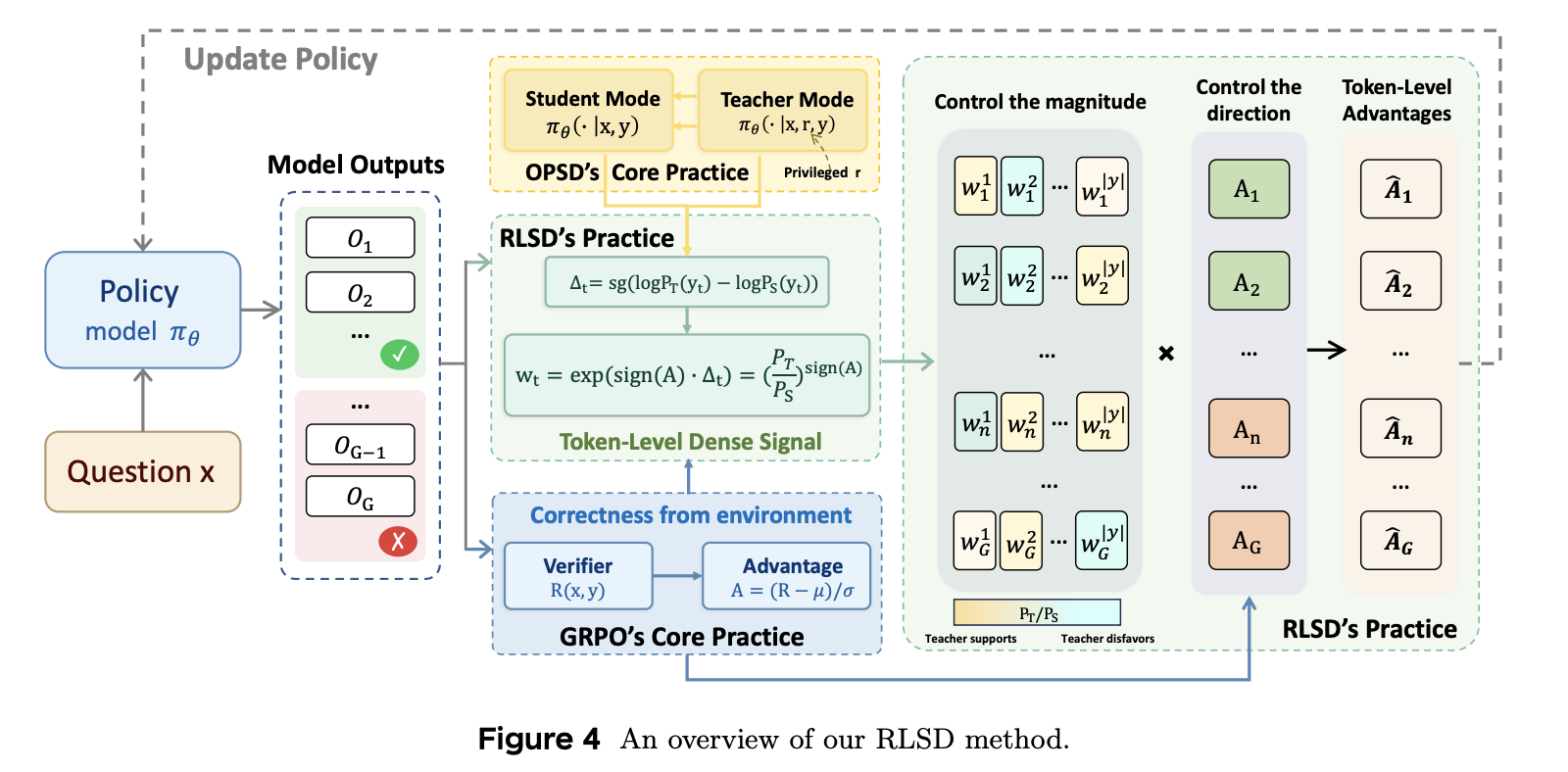
Step 1: Privileged information gain。给定一个学生采样轨迹 y=(y1,...,yT)y = (y_1, . . . , y_T)y=(y1,...,yT),我们计算每个 token 在学生上下文(仅 xxx)和教师上下文(xxx 和 rrr)下的对数概率,并定义每个位置的特权信息增益:
Δt=sg(log PT(yt)−log PS(yt)),(13)\Delta_t=sg(log~P_T(y_t)-log~P_S(y_t)),\tag{13}Δt=sg(log PT(yt)−log PS(yt)),(13)
其中 sgsgsg 表示停止梯度算子。由于 teacher 和 student 共享同一个模型,∆t∆_t∆t 分离出特权信息 r 对 yty_tyt 预测的边际贡献。较大的正值 ∆t∆_t∆t 表示 rrr 强烈支持该 token;负值表示 rrr 不利于该 token。关键在于,∆t∆_t∆t 提供了一个密集的、token 级的信号,自然地反映了每个 token 受特权信息影响的程度,使其成为在轨迹内进行细粒度权重分配的合理且轻量级的基础。停止梯度确保 ∆t∆_t∆t 仅作为权重信号,而不会引入辅助梯度路径。
Step 2: Direction-aware evidence reweighting。我们根据特权信息增益构建每个 token 的权重,并根据序列级优势的符号进行调节:
wt=exp(sign(A)⋅Δt)=(PT(yt)PS(yt))sign(A).(14)w_t=exp(sign(A)\cdot\Delta_t)=\left (\frac{P_T(y_t)}{P_S(y_t)}\right )^{sign(A)}.\tag{14}wt=exp(sign(A)⋅Δt)=(PS(yt)PT(yt))sign(A).(14)
这种表述方式自然而然地可以进行贝叶斯解释。PS(yt)P_S(y_t)PS(yt) 表示模型仅基于问题 xxx 对标记 yty_tyt 的先验评估。PT(yt)P_T(y_t)PT(yt) 表示在观察到特权信息 rrr 后的后验评估。因此,比值 PT(yt)/PS(yt)P_T(y_t)/P_S(y_t)PT(yt)/PS(yt) 是一个证据比率:特权信息修正模型对每个 token 的信念的倍数。在一些温和的建模假设下,可以证明该比率等于贝叶斯信念更新 P(r∣x,y≤t)/P(r∣x,y<t)P(r | x, y_{≤t})/P(r | x, y_{<t})P(r∣x,y≤t)/P(r∣x,y<t),即生成 yty_tyt 使特权信息 rrr 与轨迹一致的后验概率增加的程度(附录 A.5 中的定理 4)。
sign(A)sign(A)sign(A) 指数实现了方向感知的权重分配。当 A>0A > 0A>0 时,wt=PT/PSw_t = P_T / P_Swt=PT/PS:特权信息支持的 token 获得更大的权重,将正向权重集中在与正确推理轨迹最一致的 token 上。当 A<0A < 0A<0 时,wt=PS/PTw_t = P_S/P_Twt=PS/PT:该比率反转,因此特权信息不赞成的 token 受到更大的惩罚,而其支持的 token 受到的惩罚则减弱。由于对于所有输入,exp(⋅)>0exp(·) > 0exp(⋅)>0,因此权重始终为正,从而保证 token 级优势的符号永远不会因重新加权而改变。环境奖赏对轨迹是否得到强化或惩罚拥有完全的控制权;teacher 仅调节轨迹内不同 token 之间的相对大小。
这种设计与 GRPO 中用于策略更新的重要性抽样比率 πθ/πoldπ_θ/π_{old}πθ/πold 类似。GRPO 使用当前策略与旧策略的比率来控制更新的步长;RLSD 使用后验概率与先验概率的比率来控制 token 间的信用分布。两者都是在同一策略梯度框架内运行的重要性比率,从而形成结构统一的公式。
Step 3: Clipped credit assignment。遵循 PPO 和 GRPO 中裁剪代理目标的设计理念,我们对证据权重进行裁剪,以限制任何单个 token 的最大影响:
A^t=A⋅clip(wt,1−ϵw,1+ϵw),(15)\hat A_t=A\cdot clip(w_t,1-ϵ_w, 1 + ϵ_w),\tag{15}A^t=A⋅clip(wt,1−ϵw,1+ϵw),(15)
其中 ϵwϵ_wϵw 限制了每个 token 的信用偏差。公式 (15) 中的裁剪与 GRPO 中的重要性比率裁剪作用类似:GRPO 裁剪策略更新步长,而 RLSD 裁剪信用重新分配的幅度。这两种机制都起到信赖域约束的作用,从而稳定训练过程。实际上,为了避免训练开始时出现突变,我们使用 λ∈[0,1]λ ∈ [0, 1]λ∈[0,1] 在训练步骤中对均匀优势和重加权优势进行线性插值,逐渐过渡到均匀优势。RLSD 的最终目标如下:
LRLSD(θ)=E{1G∑i=1G1∣y(i)∣∑t=1∣y(i)∣min[wtA(i),clip(wt,1−ϵw,1+ϵw)A(i)]},(16)\mathcal L_{RLSD}(\theta)=\mathbb E\left\{\frac{1}{G}\sum^G_{i=1}\frac{1}{|y^{(i)}|}\sum^{|y^{(i)}|}_{t=1}min[w_tA^{(i)},clip(w_t,1-ϵ_w,1+ϵ_w)A^{(i)}]\right\},\tag{16}LRLSD(θ)=E⎩ ⎨ ⎧G1i=1∑G∣y(i)∣1t=1∑∣y(i)∣min[wtA(i),clip(wt,1−ϵw,1+ϵw)A(i)]⎭ ⎬ ⎫,(16)
4.2 Integration with GRPO

修正后的优势函数 A^t\hat A_tA^t 可直接替代标准 GRPO 目标函数中的均匀优势函数。完整的训练过程总结在算法 1 中。
未引入辅助蒸馏损失;对标准 GRPO 流程的唯一修改是在每个轨迹内部重新分配信用。额外的计算成本相当于每个响应一次前向传播以获取 teacher logits,相对于占据大部分运行时间的展开生成过程而言,这可以忽略不计。
4.3 A Unified Token-Level Advantage Perspective
为了将 RLSD 放置在更广泛的方法图景中,我们观察到,GRPO、on-policy self-distillation 以及 RLSD 都可以表示为同一个策略梯度模板的实例:
Δθ∝Ey∼PS(⋅∣x)[∑t=1∣y∣A^t∇θlogPS(yt∣x,y<t)],(17) \Delta \theta \propto \mathbb{E}_{y \sim P_S(\cdot \mid x)} \left[ \sum_{t=1}^{|y|} \hat{A}_t \nabla_\theta \log P_S(y_t \mid x, y_{<t}) \right], \tag{17} Δθ∝Ey∼PS(⋅∣x) t=1∑∣y∣A^t∇θlogPS(yt∣x,y<t) ,(17)
其中,这些方法的差异仅在于它们如何定义 token 级别的优势 A^t\hat{A}_tA^t。
GRPO 为所有 token 分配统一的优势:A^t=A\hat{A}_t = AA^t=A,其中 AAA 是来自验证器的序列级优势。这确保优化方向完全建立在环境奖励之上,但不提供 token 级别的区分能力:一条轨迹中的每个 token 都会获得相同的信用分配,而不考虑它对最终答案的贡献。
On-policy self-distillation 方法用稠密的教师信号替代环境奖励。A^∗t\hat{A}*tA^∗t 的具体形式取决于散度度量:通过对数导数技巧最小化反向 KL D∗KL(PS∣PT)D*{\mathrm{KL}}(P_S | P_T)D∗KL(PS∣PT),会得到 A^t=Δt=logPT(yt)−logPS(yt)\hat{A}_t = \Delta_t = \log P_T(y_t) - \log P_S(y_t)A^t=Δt=logPT(yt)−logPS(yt)。环境奖励 R(x,y)R(x,y)R(x,y) 完全不会出现在 A^t\hat{A}_tA^t 中:即使一条轨迹产生了错误答案((A < 0)),只要教师偏好的 token (Δt>0)(\Delta_t > 0)(Δt>0) 仍会获得正优势,这就使优化方向与可验证的正确性信号发生了解耦。
RLSD 通过结合这两类信息源来解决这一张力。它的优势函数(式 15)使用环境奖励来决定每个 token 更新的方向(符号),同时使用教师的特权评估来决定同一轨迹内部的幅度(相对信用)。我们在附录 A.6 中给出形式化证明,说明这些性质使 RLSD 在结构上免疫于特权信息泄漏;并验证 RLSD 能够同时满足不可能三难困境中的全部三个期望性质(附录 A.4)。
5.Experiment

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)