(Arxiv-2026)超越文本提示:视觉到视觉生成作为统一范式
超越文本提示:视觉到视觉生成作为统一范式
paper title:Beyond Text Prompts- Visual-to-Visual Generation as A Unified Paradigm.pdf
paper是cityu发布在arxiv2026的工作
Code:链接
摘要
人类经常通过视觉工件来理解、指定和创造:字体样式表、草图、参考图像和标注场景。然而现代视觉生成器仍然通常要求用户将这种意图序列化为文本。这种文本优先的接口虽然方便,但也是瓶颈:自然语言大幅压缩了空间结构、精确外观和字形形状等视觉信号。我们提出视觉到视觉(V2V)生成,其中用户用视觉规格页面而非文本提示来条件化生成模型。该页面不是要重建的编辑目标,而是指定期望输出的视觉文档。我们引入V2V-Zero,一个无需训练的框架,通过将现有视觉语言模型(VLM)条件化生成器中的纯文本用户条件替换为从视觉页面提取的最终层隐藏状态来暴露这一接口。关键观察是架构性的:当扩散生成器被训练为消费来自VLM的隐藏状态时,冻结的VLM已经将文本和图像都映射到生成器使用的条件化空间中。
在GenEval上,V2V-Zero使用冻结的Qwen-Image骨干网络达到0.85的总体分数,无需微调即接近该骨干网络优化的文本到图像(T2I)性能。为评估更广泛的V2V空间,我们引入Simple-V2V Bench,一个涵盖七种视觉条件化任务和七个评估模型的新基准,包括GPT Image 2、Nano Banana 2、Seedream 5.0 Lite、开源权重图像模型和视频扩展。V2V-Zero总体得分32.7/100,超越了评估的开源权重图像基线,并揭示了一致的能力层级:视觉属性绑定已经很强,内容生成仍不可靠,即使对评估的最强商业系统,结构控制仍然困难。HunyuanVideo-1.5扩展得分20.2/100,提供了补充证据表明相同的视觉页面接口可以从静态图像迁移到视频。机制分析表明默认推理路径主要是视觉路由的:真实DiT注意力将95.0%的条件化token权重分配给视觉页面隐藏状态,而非生成的推理token状态。总之,这些结果将V2V标识为一个即时可用的零样本接口和一个研究方向,即训练原生生成器将视觉输入作为第一类条件化语言。
1 引言
人类的视觉意图很少以一句话诞生。设计师使用草图、调色板、参考板、字体样式表、姿态图、空间布局和标注图像;普通用户指向示例、颜色、排列和字形。这些工件不是文本提示的辅助说明,而通常是对应该生成什么的最直接表示。然而,现代图像和视频生成器的主导接口仍然是文本:用户必须将视觉意图翻译成离散token序列,而模型必须从该序列化中重建预期的视觉约束。
这种文本优先的惯例越来越与人类沟通和模型架构不匹配。空间关系、计数、颜色绑定、主体外观、字体排版和几何结构本质上都是视觉的。蓝图比段落更直接地指定位置;色卡比颜色名称更精确地指定颜色;渲染的字形无需模型从语言中推断即可指定字符形状和风格;内联缩略图可以在名词本应出现的确切位置绑定物体参考。文本仍然强大,但视觉拓宽了其角色:任何语言指令也可以被渲染为视觉内容,带有字体、风格、颜色、布局和周围参考,使规格比单纯的文本提示更加多样和富有表现力。
因此我们提出视觉到视觉(V2V)生成作为一种范式,其中面向用户的条件化输入是一个结构化的视觉规格页面。V2V页面可以包含渲染文本、草图、色卡、参考图像、空间图表、风格示例或其他定义目标输出的视觉证据。这与图像编辑不同:输入页面不是要重建或修改的图像,而是应被解释为场景规格的条件化文档。V2V也不同于任务特定的控制模块,因为相同的页面接口可以在单一文档中组合异质的视觉线索。
这种范式可以立即测试的原因是,现代文本到视觉系统越来越多地从多模态理解中暴露出一条潜在的生成路径。在Qwen-Image [1]等架构中,多模态VLM条件化编码器读取提示上下文,扩散transformer交叉注意力到结果的最终层隐藏状态[2]。如果条件化编码器原生接受文本和图像,那么视觉输入可以被映射到生成器已经消费的相同隐藏状态空间中。这不需要更改模型权重、添加适配器或训练新的控制器。它改变的是用户侧条件化变量:不是将场景内容作为文本输入,而是将视觉页面通过冻结的VLM传递,并将其隐藏状态暴露给生成器的现有条件化接口。
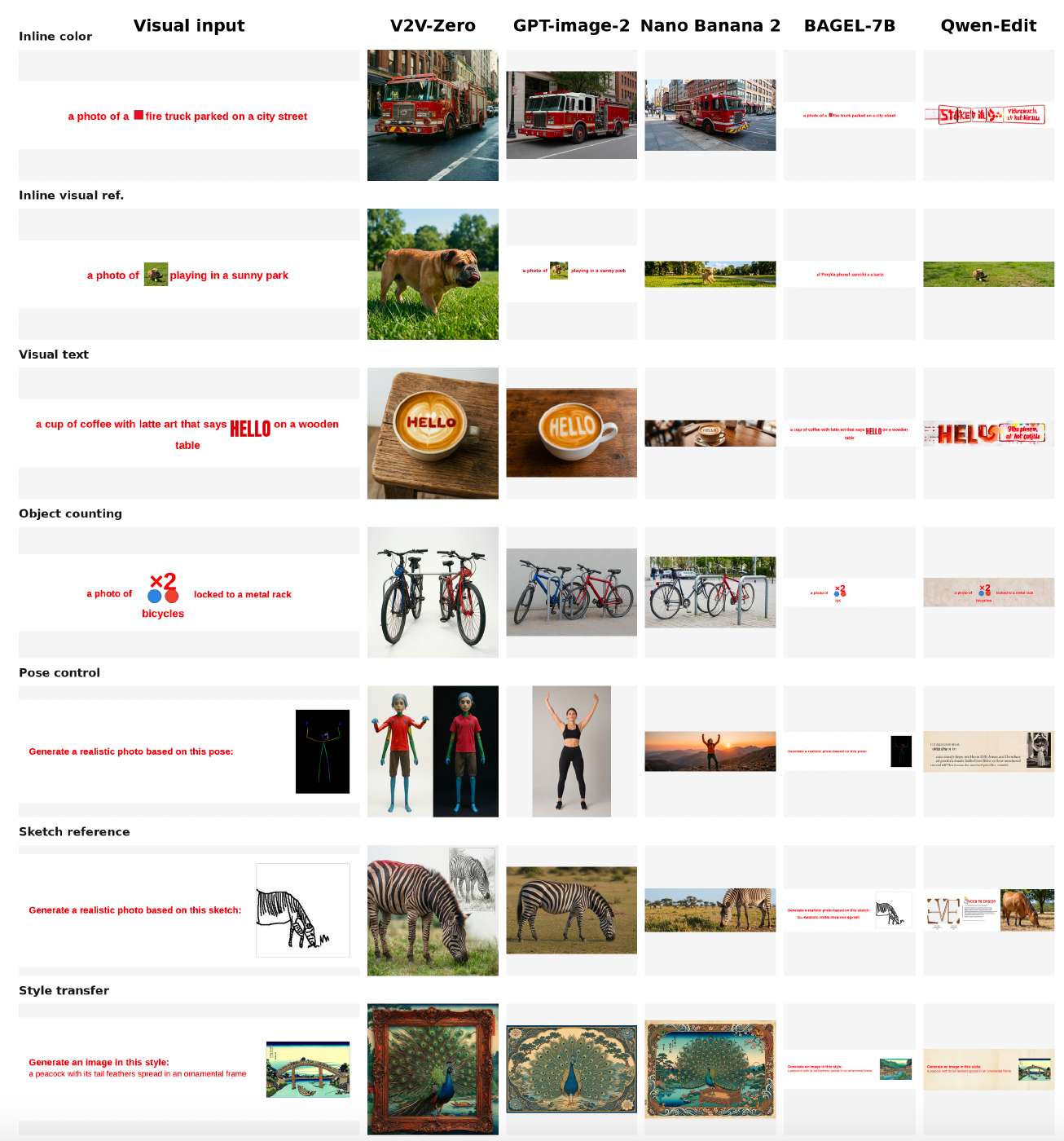
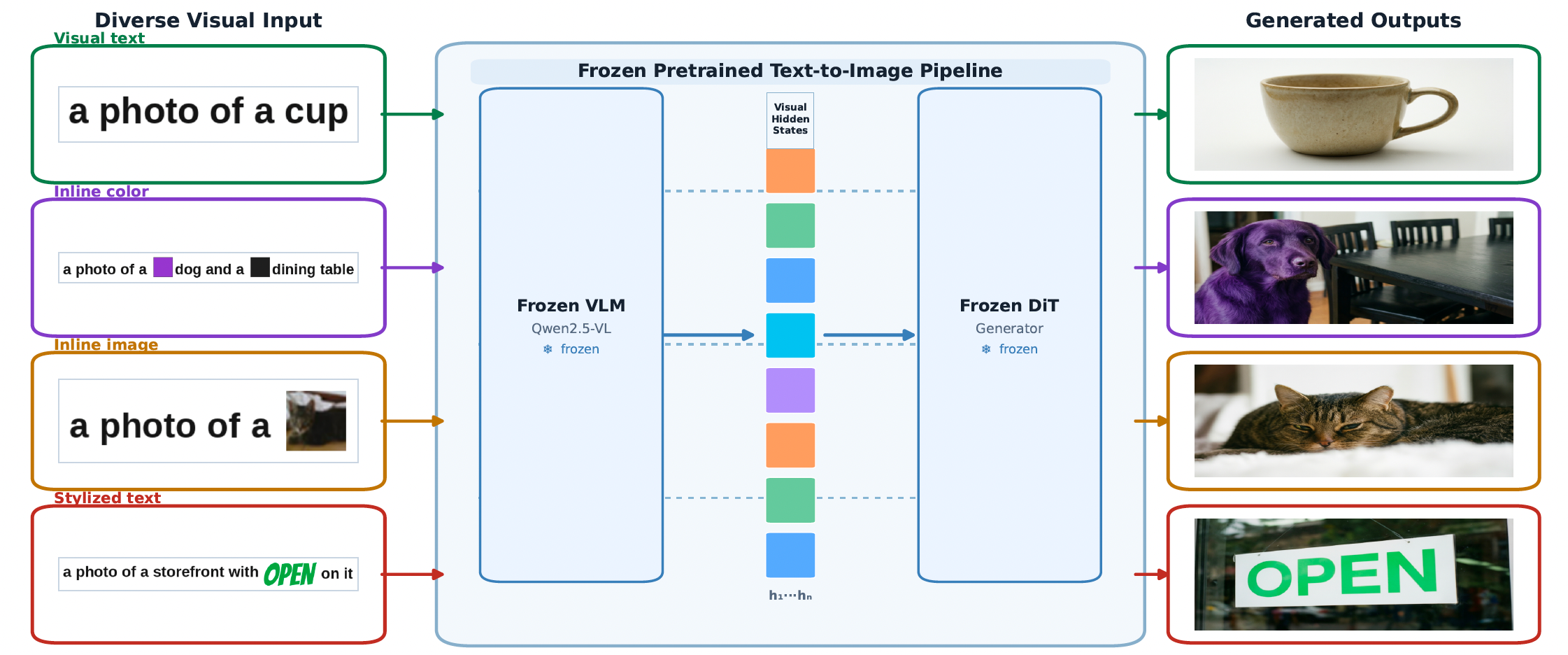
为此,我们引入V2V-Zero,该范式的一个系统性零样本实例化。V2V-Zero构建视觉规格页面,用冻结的VLM编码器处理它们,并通过直接最终层隐藏状态注入来条件化冻结的扩散模型。我们使用两种条件化模式:Image-HS-only作为非推理视觉状态控制,FULL-FINAL作为默认推理路径。图1给出了基准比较的定性预览,而图2展示了核心机制:生成器学习到的条件化接口被复用,但冻结的VLM接收的是用户提供的视觉证据而非仅语言提示。在GenEval基准[3]上,V2V-Zero达到0.85的总体分数,与骨干网络自身优化的T2I性能接近。为评估更广泛的V2V空间,我们引入Simple-V2V Bench,一个涵盖七种视觉条件化任务的新基准,用七个模型评估,包括GPT Image 2、Nano Banana 2和Seedream 5.0 Lite。该基准揭示了三层能力结构:属性绑定已经很强,内容生成仍不可靠,姿态和草图跟随等结构控制即使对最强的评估系统仍然困难。
最后,将相同的V2V-Zero方法应用于HunyuanVideo-1.5 [4]得分20.2/100,提供补充证据表明该框架适用于T2V和T2I。
贡献。
-
我们将V2V作为统一的图像和视频生成范式进行形式化,并提出V2V-Zero,一个通过冻结VLM处理视觉页面并将其隐藏状态注入冻结扩散模型的无训练框架。在GenEval上,V2V-Zero达到0.85总体分数,无需任何微调即与骨干网络自身优化的T2I性能相当。
-
我们引入Simple-V2V Bench,一个涵盖七种视觉条件化任务和七个模型的简单而新颖的基准,映射了能力前沿:属性绑定很强,内容生成仍不可靠,结构控制仍然困难。
-
我们提供T2V验证,将相同的视觉页面条件化路径应用于HunyuanVideo-1.5,得分20.2/100,证明V2V框架可扩展到文本到视频生成。
2 相关工作
T2I和T2V模型通过扩散、transformer和多模态条件化骨干网络[1, 4-16]快速发展,而编辑系统通常将图像或视频视为在文本、反转、注意力控制、指令微调或时间特征传播机制下进行修改的源[19-23]。第二条线路添加任务特定的视觉控制:结构图、边界框、参考图像、草图、运动、一体化控制接口和字形感知文本渲染[24-38]。概念上最接近的工作将图像作为提示、上下文、示例或原生多模态token来研究[39, 50]。V2V的不同之处在于将单个视觉规格页面视为用户界面本身:文本可以被渲染成视觉内容,色卡、字形、缩略图、草图、风格参考、布局和时间线索可以在同一规格页面上共存,而不需要添加任务特定的适配器。更完整的讨论见附录B。
3 方法
V2V-Zero通过在冻结VLM处理的结构化视觉规格页面上条件化冻结扩散生成器来实例化V2V范式。关键洞察是用户提供的视觉输入——空间蓝图、色卡、渲染文本、内联缩略图——携带了文本提示经常压缩的场景信息,而VLM已经将这些输入映射到生成器的条件化空间中。在主要的T2I设置中,生成器直接交叉注意力到最终层VLM视觉隐藏状态。图2展示了这一点:视觉文本、内联颜色块、内联图像块和风格化渲染文本是相同未更改的VLM到DiT条件化路径的不同编码器输入。因为最近的T2I和T2V系统已经收敛到相同的VLM-隐藏状态-到-扩散架构,相同的抽象也适用于VLM条件化的视频生成器:视觉页面由模型的多模态条件化编码器编码,然后结果隐藏状态在时间去噪前替换或增强标准文本提示嵌入。
3.1 问题形式化
设 V ∈ R H × W × 3 V \in \mathbb{R}^{H \times W \times 3} V∈RH×W×3为用户提供的视觉规格页面,通过布局、色卡、缩略图或渲染文本编码目标场景。设 E \mathcal{E} E表示冻结的多模态VLM条件化编码器(不同于视觉输入变量 V V V),设 G \mathcal{G} G表示冻结的扩散生成器。V2V-Zero产生
I = G ( E ( V ) ) , I = \mathcal{G}(\mathcal{E}(V)), I=G(E(V)),
其中 E ( V ) \mathcal{E}(V) E(V)表示生成器直接消费的最终VLM隐藏状态。该方程使用户侧范式转换变得明确:条件化变量是视觉页面 V V V,它替代了文本用户输入,VLM输出本身就是生成器条件化。固定模板、系统指令和提示包装器仍是用于解释页面的普通VLM/T2I脚手架;它们不是公式1中用户控制的输入,也不提供GenEval场景内容。实现细节和伪代码见附录C和附录C.1。
V2V-Zero是严格无训练的:它不执行权重更新,不训练适配器,不添加任何学习模块。唯一的干预是推理时的条件化包装器,它暴露最终层VLM隐藏状态并将其送入生成器的提示条件化槽。视觉页面 V V V仅由VLM视觉编码器作为条件化输入处理。在最强的组合设置中, V V V是一个内联视觉提示页面,其局部色卡或缩略图直接嵌入单行渲染提示中。对于HunyuanVideo-1.5 [4]验证,我们使用相同的原理与视频流水线的多模态VLM编码器:渲染的Simple-V2V Bench页面作为视觉提示上下文编码,填充或截断到模型的条件化长度,然后无需训练即用于完整的T2V采样。该实验测试了相同框架的T2V方向;最广泛的基准证据仍以图像为中心。
3.2 条件化模式
V2V-Zero使用两种条件化模式。Image-HS-only是非推理控制:生成器仅交叉注意力从视觉页面提取的图像token状态,
E IMG ( V ) = [ H img ] . \mathcal{E}_{\text{IMG}}(V) = [H_{\text{img}}]. EIMG(V)=[Himg].
FULL-FINAL是默认推理路径。设固定前缀为
x = [ t sys , ViT ( V ) , t user ( T ) , ⟨ gen ⟩ ] . \mathbf{x} = [t_{\text{sys}}, \text{ViT}(V), t_{\text{user}}(T), \langle\text{gen}\rangle]. x=[tsys,ViT(V),tuser(T),⟨gen⟩].
VLM从 x \mathbf{x} x自回归生成推理token t 1 : N t_{1:N} t1:N。然后我们重新计算最终层隐藏状态在教师强制下,
H ~ ( L ) = E ( L ) ( [ x , t 1 : N ] ) , \widetilde{H}^{(L)} = \mathcal{E}^{(L)}([\mathbf{x}, t_{1:N}]), H (L)=E(L)([x,t1:N]),
并注入
H FULL-FINAL = [ H ~ ViT ( V ) ( L ) ; H ~ t 1 : N ( L ) ] , H_{\text{FULL-FINAL}} = [\widetilde{H}^{(L)}_{\text{ViT}(V)}; \widetilde{H}^{(L)}_{t_{1:N}}], HFULL-FINAL=[H ViT(V)(L);H t1:N(L)],
即视觉状态加上生成token的最终状态,其中 L L L表示最终VLM层索引。重新计算意味着在固定前缀上运行一次前向传播,加上生成的token,使所有注入状态来自相同的最终层上下文。我们默认使用FULL-FINAL,因为它在添加VLM对页面的推理的同时保留了直接视觉状态。生成的推理状态应被理解为条件化序列的一部分,而非解码文本替代视觉页面。第5节显示DiT主要注意力到视觉前缀状态在此路径中。对于Qwen-Image,所有直接注入使用最终VLM层( L = 28 L = 28 L=28);附录A.1显示较早层失败。注意此最终层设置专针对Qwen-Image;对于HunyuanVideo-1.5扩展,我们遵循其默认设置使用倒数第三层(第4.5节)。
3.3 模板和视觉页面
模板是固定的解释器指令,指定VLM应如何读取视觉页面;它们不提供场景内容。我们展示三种视觉页面族:组合页面(用于结构化场景控制的空间图表)、文本页面(渲染的目标字符)和内联视觉页面(在提示文本中嵌入的色卡和缩略图)。完整的八页面分类法、每族构建细节和精确模板文本见附录C.3。
4 实验
4.1 设置
我们主要评估图像生成,其中已建立的基准和基线允许可控测量。GenEval [3]包含553个提示,涵盖六种组合技能,每个提示4个样本。我们的生成器遵循Qwen-Image [1],使用Qwen2.5-VL-7B-Instruct作为条件化骨干[2, 51]。对于V2V-Zero,原始文本提示被渲染为视觉页面;生成器接收从该页面导出的VLM隐藏状态。除非另有说明,解码是贪心的,分数遵循基准的标准聚合。我们还引入Simple-V2V Bench(第4.4节)并在HunyuanVideo-1.5上验证相同的T2V生成路径(第4.5节)。
表1: GenEval [3]上的定量评估(553个提示,每个4个样本)。每列最佳以粗体标示。
| 模型 | 单物体 | 双物体 | 计数 | 颜色 | 位置 | 属性绑定 | 总体↑ |
|---|---|---|---|---|---|---|---|
| Show-o [52] | 0.95 | 0.52 | 0.49 | 0.82 | 0.11 | 0.28 | 0.53 |
| Emu3-Gen [53] | 0.98 | 0.71 | 0.34 | 0.81 | 0.17 | 0.21 | 0.54 |
| PixArt-α [54] | 0.98 | 0.50 | 0.44 | 0.80 | 0.08 | 0.07 | 0.48 |
| SD3 Medium [55] | 0.98 | 0.74 | 0.63 | 0.67 | 0.34 | 0.36 | 0.62 |
| FLUX.1 [Dev] [56] | 0.98 | 0.81 | 0.74 | 0.79 | 0.22 | 0.45 | 0.66 |
| SD3.5 Large [55] | 0.98 | 0.89 | 0.73 | 0.83 | 0.34 | 0.47 | 0.71 |
| JanusFlow [57] | 0.97 | 0.59 | 0.45 | 0.83 | 0.53 | 0.42 | 0.63 |
| Lumina-Image 2.0 [58] | - | 0.87 | 0.67 | - | - | - | 0.62 |
| Janus-Pro-7B [59] | 0.99 | 0.89 | 0.59 | 0.90 | 0.79 | 0.66 | 0.80 |
| HiDream-I1-Full [60] | 1.00 | 0.98 | 0.79 | 0.91 | 0.60 | 0.72 | 0.83 |
| GPT Image 1 [61] | 0.99 | 0.92 | 0.85 | 0.92 | 0.75 | 0.61 | 0.84 |
| Seedream 3.0 [62] | 0.99 | 0.96 | 0.91 | 0.93 | 0.47 | 0.80 | 0.84 |
| Qwen-Image (官方) [1] | 0.99 | 0.92 | 0.89 | 0.88 | 0.76 | 0.77 | 0.87 |
| Qwen-Image (复现) | 0.99 | 0.97 | 0.87 | 0.89 | 0.71 | 0.74 | 0.86 |
| Qwen-Image-V2V-Zero: Full-final | 1.00 | 0.95 | 0.85 | 0.89 | 0.73 | 0.68 | 0.85 |
4.2 主要结果
表1将V2V-Zero与T2I模型在完整GenEval基准上进行比较。使用相同的Qwen-Image-2512骨干,FULL-FINAL无需微调或额外模块即达到0.85。它在使用视觉条件化路径的同时接近官方优化的Qwen-Image结果,而权重完全冻结。
Image-HS-only在消融子集上达到71.57%;FULL-FINAL添加VLM推理token状态,在相同子集上达到86.77%,使其成为默认模式。更多结果见附录E。第5节测量生成器如何使用此路径:真实DiT注意力将95.0%的条件化token权重分配给视觉token状态。
4.3 消融
完整消融结果列于附录E;本节总结关键发现。
4.3.1 条件化模式消融
我们使用两种条件化模式。Image-HS-only隔离视觉隐藏状态而不进行自回归推理。FULL-FINAL保留这些图像状态并附加最终层推理状态,将诊断子集分数从71.57%提高到86.77%(+15.20个百分点)。因此我们将FULL-FINAL作为GenEval、Simple-V2V Bench和视频扩展的默认模式;机制分析显示此默认仍然主要是在DiT内部视觉路由的。
4.3.2 其他消融
Token计数呈非单调变化;最强的完整基准设置使用200个token。模板选择影响VLM如何解释视觉页面,正如VLM条件化系统所预期的:100个token时面向生成的模板达到84.56%,而通用描述模板降至62.01%。固定模板不提供GenEval场景内容。使用最终VLM层至关重要(附录A.1)。
4.4 Simple-V2V Bench
V2V范式打开了比传统T2I或图像编辑更广泛的生成空间。我们引入Simple-V2V Bench,一个七类别基准(每类22个提示),模型必须解释用户提供的视觉规格页面并生成对应图像。
基准设计。每个提示将视觉输入页面与生成目标配对。类别涵盖内联颜色、内联视觉参考、视觉文本、风格迁移、物体计数、草图参考和姿态控制;完整构建细节见附录F。
表2: Simple-V2V Bench: 多模型比较。所有图像模型由相同的Qwen3-VL-32B评判器评估,双维度评分( min ( Q , A ) × 10 \min(Q, A) \times 10 min(Q,A)×10),和四样本均值聚合。HunyuanVideo生成完整视频;报告的分数对生成视频应用相同的VLM评判器。每列最佳以粗体标示。
| 模型 | 视觉文本 | 内联颜色 | 内联视觉参考 | 计数 | 风格 | 姿态 | 草图 | 总体 |
|---|---|---|---|---|---|---|---|---|
| GPT Image 2 [63] | 78.3 | 92.4 | 75.8 | 91.8 | 60.3 | 20.0 | 34.0 | 64.7 |
| Seedream 5.0 Lite [64] | 79.0 | 68.7 | 74.7 | 88.8 | 48.7 | 16.8 | 32.4 | 58.4 |
| Nano Banana 2 [65] | 59.2 | 69.7 | 78.0 | 67.1 | 44.7 | 19.1 | 22.3 | 51.4 |
| V2V-Zero (ours) | 34.8 | 76.9 | 42.8 | 24.0 | 20.3 | 13.3 | 16.6 | 32.7 |
| HunyuanVideo-1.5 (video) [4] | 17.7 | 32.5 | 25.7 | 19.2 | 17.3 | 12.4 | 16.3 | 20.2 |
| Qwen-Image-Edit-2511 [1] | 15.7 | 16.9 | 34.2 | 23.2 | 17.1 | 13.4 | 17.2 | 19.7 |
| BAGEL-7B-MoT [48] | 43.5 | 10.0 | 11.9 | 10.3 | 10.2 | 10.0 | 10.6 | 15.2 |
评估。我们使用Qwen3-VL-32B-Instruct作为直接VLM评判器:它看到输入页面和生成的输出,分别在1-10量表上评分质量和对齐度,并报告 min ( Quality , Alignment ) × 10 \min(\text{Quality}, \text{Alignment}) \times 10 min(Quality,Alignment)×10。分数对每个提示的4个样本取平均;附录G给出评分规则和扣分规则。
结果和分析。表2报告了V2V-Zero在相同协议下与六个基线一起评估的性能(详细V2V-Zero逐类别分数包括Quality和Alignment分解见附录H)。V2V-Zero总体得分32.7/100,揭示了跨任务类型的清晰能力梯度。在基线中,GPT Image 2 [63]以64.7领先,其次是Seedream 5.0 Lite [64] (58.4)和Nano Banana 2 [65] (51.4),而开源权重模型得分明显较低:Qwen-Image-Edit-2511 [1] (19.7)和BAGEL-7B-MoT [48] (15.2)。所有Simple-V2V分数来自我们自己的评估。HunyuanVideo-1.5从相同的视觉页面生成完整视频,当这些视频由相同VLM评判器评估时得分20.2。
比较揭示了两个主要模式。首先,对齐是瓶颈:模型经常产生不遵循视觉页面的合理图像,即使GPT Image 2在姿态控制上也降至20.0。其次,V2V-Zero在属性绑定上最强,内联颜色达到76.9,而结构类别仍然较弱(姿态13.3,草图16.6)。这表明零样本上限更多由视觉结构条件化而非语义属性绑定驱动。
因此该基准暴露了三个视觉条件化难度层级:属性绑定已经有用,内容生成仍不可靠,结构控制仍是最困难的领域。图1(置于论文前部)展示了对应的定性成功和失败案例。
4.5 T2V验证
为测试T2V方向,我们将相同的视觉页面条件化路径移植到HunyuanVideo-1.5 [4]。Simple-V2V Bench页面由视频模型的Qwen2.5-VL多模态编码器编码,填充或截断到流水线的条件化长度,并由冻结的时间去噪器使用。我们评估616个视频(七个类别,每个提示四个样本,33帧480p),用相同的Qwen3-VL-32B评判器直接应用于生成视频。
HunyuanVideo总体得分20.2/100(表2),比V2V-Zero的图像结果低12.5分。内联颜色和内联视觉参考迁移效果最好,而姿态和草图接近底线。图3展示了内联颜色和计数的代表性案例。这支持了架构性声明:VLM条件化的生成器可以无需训练即消费视觉页面,但时间一致性和运动保真度的视频特定评估仍是未来工作;逐类别视频细节见附录I。

5 机制分析
本节隔离了解释V2V路径为何在实践中有效所需的证据。核心问题不是VLM能否从视觉页面生成有用的文本理据,而是冻结的生成器是否确实使用了V2V-Zero注入的视觉页面隐藏状态。
5.1 V2V架构观察
设传统T2I流水线写为 I = G ( E ( p ) ) I = \mathcal{G}(\mathcal{E}(p)) I=G(E(p)),其中 p p p是用户文本提示, E \mathcal{E} E是多模态条件化编码器, G \mathcal{G} G是直接交叉注意力到编码器隐藏状态的扩散模型。如果同一个 E \mathcal{E} E也原生将视觉页面 V V V映射到相同的 D D D维条件化空间中的隐藏状态,那么用 V V V替换 p p p即产生公式1中的V2V-Zero路径:用户输入变为视觉的,而生成器学习到的条件化接口和模型权重不变。
这一观察是架构性的而非形式定理:它陈述V2V路径的存在。实验测试该路径是否在实践中有用,并证明零样本利用它对那些信息保留在最终层VLM隐藏状态中的视觉规格可以产生实质性增益。
5.2 推理路径是视觉路由的
在完整553提示基准上,Qwen-Image-V2V-Zero FULL-FINAL设置达到0.85总体。我们将此模式称为推理路径:VLM首先读取视觉页面并生成场景级推理token,最终条件化序列在生成的推理token位置将视觉前缀隐藏状态与隐藏状态拼接。然而关键的是,这不应被解读为V2V-Zero通过将视觉页面转换为文本理据来工作。推理路径保留了视觉页面隐藏状态本身,生成器可以直接注意力到它们。
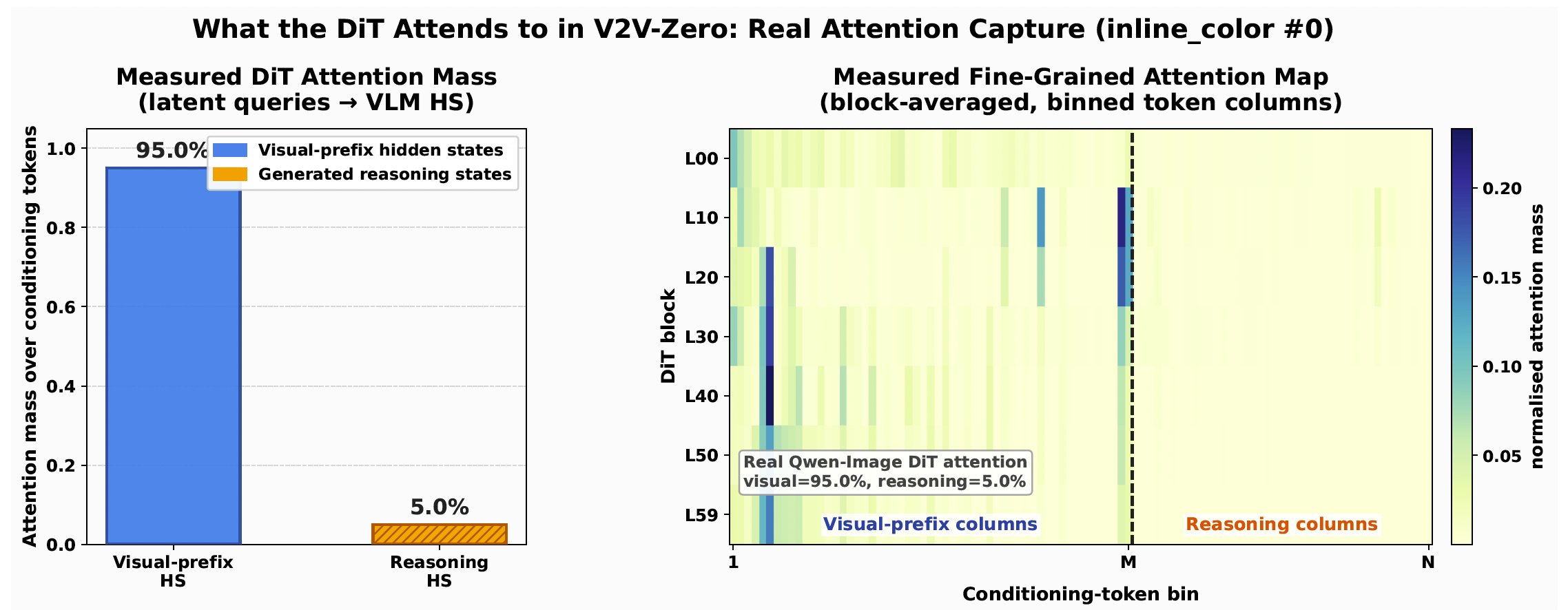
为测试生成器使用的实际路由,我们在真实V2V-Bench运行期间检测Qwen-Image DiT注意力。具体而言,对于选定的DiT块,我们测量从潜变量图像查询到VLM条件化token键列的softmax注意力权重,并将这些条件化列分为视觉前缀隐藏状态和生成的推理token隐藏状态。图4展示了定性比较中使用的内联颜色样本的结果。条件化序列包含266个视觉前缀状态和200个生成推理状态。如果注意力仅与token数量成比例,视觉前缀将接收57.1%的条件化token权重。然而,DiT将95.0%的测量条件化token注意力分配给视觉前缀隐藏状态,仅5.0%给生成的推理状态。这是来自实际零样本V2V路径的直接路由测量:生成器压倒性地从视觉页面表示读取,而非从生成的推理token表示。
这一发现对机制至关重要。V2V-Zero的成功不是因为VLM产生了有用的文本理据来替代视觉输入。它成功是因为预训练的DiT能够消费最终层VLM隐藏状态,其视觉前缀部分即使模型未针对视觉页面提示进行微调,仍然作为有效的生成条件化。生成的推理token使序列与生成器的语言条件化接口兼容,但主导的信息通路是隐藏状态的视觉条件化。固定的解释器指令帮助将页面放入预期的条件化格式,但测量的路由显示DiT主要读取视觉页面隐藏状态而非生成的推理token状态。这支持了论文的主要机制性声明:V2V-Zero暴露了一条已存在于VLM条件化生成器中的潜在视觉到视觉路径,超越了文本重编码。
只有最终VLM层与生成兼容:从层 L − 1 L-1 L−1注入降至5.39%,尽管达到最高的文本-视觉对齐( ρ \rho ρ=0.908 vs. ρ L \rho_L ρL=0.712),因为只有层 L L L匹配DiT训练的条件化分布。生成的推理token补充但不替代视觉前缀状态作为主要条件化源——Image-HS-only已经超越仅推理注入(71.57%)(68.14%),确认视觉状态携带主导信号。扩展的逐层分析、token级对齐诊断和信息论瓶颈分析见附录A。
6 结论
我们提出了视觉到视觉(V2V)生成作为一种范式,其中结构化视觉输入作为生成模型的主要条件化信号。V2V-Zero是其零样本实例化:通过将视觉页面隐藏状态路由通过现有T2I系统的冻结VLM编码器,它在GenEval上达到0.85,无需微调即证明用户提供的视觉证据可以提供文本提示压缩掉的条件化信息。Simple-V2V Bench揭示了三层能力结构——属性绑定接近商业基线,内容生成显示明确差距,结构控制仍然开放——而HunyuanVideo-1.5扩展确认相同的接口可迁移到视频生成。
更广泛地说,V2V将视觉输入重新定义为生成模型的第一类条件化语言。文本扩展推动了近期进展,但视觉规格提供了互补轴:布局、颜色、身份和结构通常作为图像比序列化描述更直接地指定。端到端训练的原生V2V模型、更丰富的规格格式和奖励精确视觉指令跟随的评估框架是沿此轴的自然下一步。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)