万字硬核解析:从零看透 Transformer 与大语言模型(架构、数学与工程实践)
导言:阅读目标与核心认知
在当前 AI 工程落地的浪潮中,大语言模型(LLM)的底层逻辑不仅是算法工程师的专属,更是每一位后端架构师和研发人员必须掌握的工程基础。本文旨在帮助从零开始的技术人员系统入门 LLM 基础架构 Transformer。
通过本文,您将达成以下认知目标:
- 理论穿透:理解为什么是 Transformer 统治了时代,LLM 到底在海量数据中学到了什么。
- 架构拆解:严谨推导 Decoder-only 架构成为主流的数学与工程必然性。
- 知行合一:既能应对高频的技术面试八股,也能将底层原理与长上下文、KV Cache、高并发吞吐量等实际后端工程实践深度绑定。
从应用工程视角看,LLM 最核心的机制可以抽象为一条统一的条件概率分布公式:
P(next_token∣previous_tokens,parameters)P(\text{next\_token} | \text{previous\_tokens}, \text{parameters})P(next_token∣previous_tokens,parameters)
这条公式揭示了三个不可逾越的底层事实:
- 模型能力高度依赖上下文组织方式(Prompt/Context Engineering 的理论根基)。
- 模型输出是概率分布而非唯一绝对真理,因此具备采样随机性。
- 模型参数存储的是高维压缩后的统计规律,而非显式关系数据库,这是其产生“幻觉”的数学根源。
第一部分:语言建模的演化与大语言模型的定义
语言建模的核心任务是估计一个离散 Token 序列出现的概率。在 Transformer 确立统治地位之前,自然语言处理经历了漫长的演进。
传统架构的工程局限
- N-gram:基于马尔可夫假设,仅依赖前 N 个词汇,无法捕捉长距离依赖,存在严重的数据稀疏问题。
- RNN / LSTM:序列建模天然按时间步递归(ht=f(ht−1,xt)h_t = f(h_{t-1}, x_t)ht=f(ht−1,xt))。虽然可以处理变长序列,但训练时时间轴上的硬性串行导致无法大规模并行计算;同时,反向传播时的梯度消失/爆炸使得长距离依赖的捕捉依然受限。
- CNN:并行计算能力极强,但在处理文本序列时,需要通过堆叠极深的网络层来扩大感受野,建模远距离依赖的路径不够直接,工程性价比低。
Transformer 的胜出逻辑
Transformer 的胜出是数学表达力与底层硬件工程的共同胜利。
它用自注意力机制(Self-Attention)彻底废弃了时间步递归,使得序列中任意两个位置的信息交互路径长度缩短为 O(1)O(1)O(1)。更关键的是,其计算图拓扑极其适配 GPU/TPU 这种大规模并行硬件,成为后续 Scaling Laws(缩放定律)的物理前提。其工程代价是注意力机制 O(N2)O(N^2)O(N2) 的时间与空间复杂度,这也直接催生了当前工业界对于 KV Cache、Prefix Caching 等显存优化技术的巨大需求。
大语言模型的三个抽象层级
大语言模型并非参数的简单堆砌,其在工程上分为三个严格的层级:
- Tokenizer(分词器):将离散文本转化为整数 ID。不同策略直接影响上下文显存成本、代码表现与跨语言能力。
- Base Model(基座模型):通过预训练(Pre-training)学习语言分布与世界知识规律,具备极强的无条件续写能力,但缺乏对特定指令的服从性。
- Instruct/Aligned Model(对齐模型):通过监督微调(SFT)、人类反馈强化学习(RLHF)等后训练技术,使模型接口从“概率续写器”转化为“指令遵循系统”。
第二部分:Transformer 核心架构与数学原理解析
Transformer 不是某一个单点机制的胜利,而是一整套高度协同的系统工程。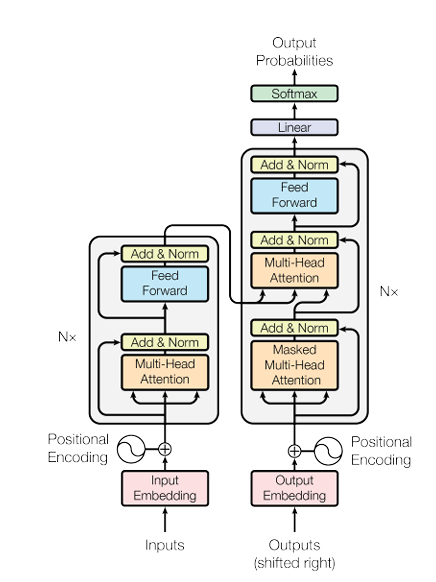
它大致可以理解为:
- Embedding:把离散 Token 变成连续向量;
- 位置编码 RoPE:告诉模型 Token 在序列里的顺序;
- Self-Attention:让每个 Token 去“看”其他 Token;(多投注意力机制就是单自注意机制拼接)
- FFN:对每个 Token 的特征做非线性加工;
- 残差连接和 LayerNorm:保证深层网络稳定训练;
- Causal Mask:阻止模型偷看未来。
下面逐个拆开。
1. Embedding:把离散符号变成连续向量
Tokenizer 输出的是 Token ID。
例如一句话:
我 喜欢 吃 烤肉
经过 Tokenizer 后,可能变成:
我 -> 1024
喜欢 -> 3051
吃 -> 876
烤肉 -> 13920
这些数字本身没有数学意义。1024 不代表“我”比 876 更大,也不代表“我”和“吃”之间有什么数值关系。
所以模型需要一个 Embedding 表。
假设词表大小是 50000,隐藏层维度是 4096,那么 Embedding 矩阵可以写成:
E∈R50000×4096 E \in R^{50000 \times 4096} E∈R50000×4096
其中,每一行都是一个 Token 的向量表示。
如果某个 Token 的 ID 是 1024,那么它的向量就是 Embedding 表的第 1024 行:
x=E[1024] x=E[1024] x=E[1024]
如果输入序列长度是 4:
我 喜欢 吃 烤肉
那么 Embedding 后会得到 4 个向量:
x0,x1,x2,x3 x_0,x_1,x_2,x_3 x0,x1,x2,x3
每个向量都是高维连续向量,例如 4096 维。
可以直观理解为:
Token ID:一个离散编号
Embedding:这个编号对应的一串语义坐标
例如在理想情况下:
“猫” 和 “狗” 的向量距离比较近
“猫” 和 “汽车” 的向量距离比较远
“北京” 和 “上海” 的向量可能具有某种城市语义相似性
常见的相似度可以用点积或余弦相似度衡量:
similarity(x,y)=x⋅y similarity(x,y)=x \cdot y similarity(x,y)=x⋅y
或者:
cos(x,y)=x⋅y∣∣x∣∣ ∣∣y∣∣ cos(x,y)=\frac{x \cdot y}{||x||\ ||y||} cos(x,y)=∣∣x∣∣ ∣∣y∣∣x⋅y
但是,Embedding 只解决了一个问题:
这个 Token 是什么。
它没有解决:
这个 Token 在哪里。
例如:
我 喜欢 你
你 喜欢 我
这两句话 Token 集合相似,但语义完全不同。
如果没有位置编码,Transformer 会更像一个“词袋模型”:它知道有哪些词,但不知道这些词的顺序。
所以必须引入位置编码。
2. RoPE:把位置变成旋转角度
Transformer 的 Self-Attention 本身对顺序不敏感。
如果只看一组 Token:
我 喜欢 你
和:
你 喜欢 我
模型如果没有位置信息,就很难区分谁是主语、谁是宾语。
传统方法会直接给每个位置加一个位置向量:
hm=xm+pm h_m=x_m+p_m hm=xm+pm
其中:
x_m 表示第 m 个 Token 的语义向量
p_m 表示第 m 个位置的位置向量
但现代 LLM 更常用 RoPE,也就是旋转位置编码。
RoPE 的核心思想是:
不把位置向量加进去,而是根据位置编号旋转 Query 和 Key。
假设第 m 个 Token 的 Query 是二维向量:
q=(q1,q2) q=(q_1,q_2) q=(q1,q2)
RoPE 会让它旋转角度:
mθ m\theta mθ
旋转后得到:
qm′=(q1cos(mθ)−q2sin(mθ), q1sin(mθ)+q2cos(mθ)) q'_m=(q_1\cos(m\theta)-q_2\sin(m\theta),\ q_1\sin(m\theta)+q_2\cos(m\theta)) qm′=(q1cos(mθ)−q2sin(mθ), q1sin(mθ)+q2cos(mθ))
同理,第 n 个 Token 的 Key 是:
k=(k1,k2) k=(k_1,k_2) k=(k1,k2)
旋转后得到:
kn′=(k1cos(nθ)−k2sin(nθ), k1sin(nθ)+k2cos(nθ)) k'_n=(k_1\cos(n\theta)-k_2\sin(n\theta),\ k_1\sin(n\theta)+k_2\cos(n\theta)) kn′=(k1cos(nθ)−k2sin(nθ), k1sin(nθ)+k2cos(nθ))
然后做点积:
qm′⋅kn′=(q1k1+q2k2)cos((m−n)θ)+(q1k2−q2k1)sin((m−n)θ) q'_m \cdot k'_n=(q_1k_1+q_2k_2)\cos((m-n)\theta)+(q_1k_2-q_2k_1)\sin((m-n)\theta) qm′⋅kn′=(q1k1+q2k2)cos((m−n)θ)+(q1k2−q2k1)sin((m−n)θ)
注意最终公式里只剩下:
m−n m-n m−n
这说明 RoPE 让注意力分数天然依赖相对位置。
例如:
位置 1 和位置 3 的距离是 2
位置 10001 和位置 10003 的距离也是 2
它们都有:
3−1=10003−10001=2 3-1=10003-10001=2 3−1=10003−10001=2
所以 RoPE 更关心:
两个 Token 相隔多远
而不是:
它们分别坐在第几个绝对座位上
这就是 RoPE 比普通绝对位置编码更适合长序列建模的重要原因。
不过 RoPE 也不是完美的。
当模型从训练时的 2k 长度扩展到 32k、128k 时,会遇到两个问题:
第一,注意力稀释。
Softmax 会把所有可见 Token 的注意力权重加起来归一化为 1。
如果上下文很短,比如 10 个 Token,模型只需要在 10 个位置里分配注意力。
如果上下文变成 32000 个 Token,模型就要在 32000 个位置里分配注意力。
大量远距离 Token 虽然每个权重很小,但加起来可能会稀释真正重要的近距离 Token。
第二,相位混叠。
RoPE 本质是旋转。旋转角度太大时,高频维度可能转了很多圈。
比如:
370∘=10∘ 370^\circ=10^\circ 370∘=10∘
这意味着某些远距离位置可能在高频维度上出现相似角度,导致位置区分变困难。
同时,低频维度虽然转得慢,但在超长上下文中也可能进入模型预训练时没见过的角度范围,这就是 OOD,也就是分布外问题。
所以长上下文模型通常还需要 NTK-Aware、位置插值、YaRN 等工程方法来缓解 RoPE 外推问题。
详细见:从旋转矩阵到 RoPE:为什么旋转位置编码天然表达相对位置
https://blog.csdn.net/2303_79278759/article/details/161453860
3. Self-Attention:让每个 Token 去看其他 Token
Self-Attention 是 Transformer 的核心。
它解决的问题是:
当前 Token 应该关注上下文中的哪些 Token?
例如句子:
小明 把 苹果 放进 书包,因为 它 很重
这里的“它”到底指什么?
可能需要看前面的“苹果”或“书包”。
Self-Attention 的作用,就是让“它”这个 Token 根据上下文去寻找相关 Token。
每个 Token 会生成三种向量:
Q:Query,表示我想找什么信息
K:Key,表示我能提供什么索引
V:Value,表示我真正携带的内容
可以类比成数据库检索:
Q:搜索请求
K:每条记录的标签
V:每条记录的内容
数学上,输入向量是 x,通过三个矩阵变换得到:
Q=XWq Q=XW_q Q=XWq
K=XWk K=XW_k K=XWk
V=XWv V=XW_v V=XWv
然后计算注意力:
Attention(Q,K,V)=softmax(QKTdk)V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
这里的 QK^T 表示每个 Query 和所有 Key 做点积。
点积越大,说明当前 Token 越应该关注那个位置。
举个简单例子,假设当前 Token 是“它”,它对前面几个词的注意力分数是:
小明:0.1
苹果:3.2
书包:1.5
因为:0.2
经过 Softmax 后,可能变成:
小明:0.03
苹果:0.75
书包:0.18
因为:0.04
然后模型会用这些权重对 Value 加权求和:
output=0.03V小明+0.75V苹果+0.18V书包+0.04V因为 output=0.03V_{小明}+0.75V_{苹果}+0.18V_{书包}+0.04V_{因为} output=0.03V小明+0.75V苹果+0.18V书包+0.04V因为
于是“它”的新表示中,就混入了大量“苹果”的信息。
这就是 Self-Attention 的本质:
每个 Token 根据相关性,从全局上下文中取回自己需要的信息。
为什么要除以 sqrt(d_k)
注意力公式里有一项:
QKTdk \frac{QK^T}{\sqrt{d_k}} dkQKT
为什么不能直接用:
QKT QK^T QKT
原因是维度越高,点积的数值方差越大。
假设:
q 和 k 的每个元素均值为 0
q 和 k 的每个元素方差为 1
q 和 k 的维度是 d_k
点积为:
q⋅k=q1k1+q2k2+⋯+qdkkdk q \cdot k=q_1k_1+q_2k_2+\cdots+q_{d_k}k_{d_k} q⋅k=q1k1+q2k2+⋯+qdkkdk
每一项的方差大约是 1,总共有 d_k 项,所以:
Var(q⋅k)=dk Var(q \cdot k)=d_k Var(q⋅k)=dk
这意味着 d_k 越大,点积数值越容易变得很大或很小。
比如:
未缩放分数:[1, 2, 10]
经过 Softmax 后,10 会压倒其他值,输出接近:
[0, 0, 1]
这会导致注意力过早变成 One-hot,也就是赢者通吃。
问题是,Softmax 一旦饱和,梯度就会变得很小,训练会变困难。
所以除以:
dk \sqrt{d_k} dk
可以把方差从 d_k 拉回到 1:
Var(q⋅kdk)=1 Var(\frac{q \cdot k}{\sqrt{d_k}})=1 Var(dkq⋅k)=1
这就是缩放点积注意力中的“缩放”含义。
它不是装饰,而是保证深层网络数值稳定的关键设计。
4.MHA:多头注意力机制
这里给你整理成适配CSDN、排版工整、可直接发布的版本,分纯文本排版、分段优化版,同时保留原有语义与比喻,也补充了可搭配公式/表格的精简版,按需选用。
版本一:原文优化排版(推荐,阅读流畅,直接复制)
可以把 Multi-Head Attention(多头注意力)理解为如下过程:
同一个 Token
↓
被投影到多个不同的特征子空间
↓
每个子空间独立执行注意力计算
↓
每个注意力头(Head)学习一种特定的上下文关系
↓
最终将所有头的输出拼接融合
举个例子,针对句子中的代词它,不同注意力头会自主习得不同关注逻辑:
- Head 1:侧重关联距离最近的名词
- Head 2:聚焦语义上可被指代的目标对象
- Head 3:捕捉句子的句法主干结构
- Head 4:识别逗号、连接词、因果词等文本结构信号
- Head 5:挖掘长距离的语义依赖
整理成适配 CSDN、格式规范、公式正常渲染的完整版本,分段排版+标注维度,直接复制使用:
然后把所有 head 拼接起来:
H=Concat(head1,head2,…,headh) H=\text{Concat}(head_1,head_2,\dots,head_h) H=Concat(head1,head2,…,headh)
拼接后张量形状恢复为:
H∈RN×dmodel H \in \mathbb{R}^{N \times d_{\text{model}}} H∈RN×dmodel
举例说明:
一共 32 个 head,每个 head 输出维度为 128 维
拼接后总维度:32×128=409632 \times 128 = 409632×128=4096 维
拼接完成后,再经过一层输出投影矩阵做特征融合:
O=HWo O=HW_o O=HWo
其中 WoW_oWo 为输出权重矩阵,作用是对多个注意力头的结果进行重新混合与整合。
多头注意力的本质:
将单次注意力运算,拆解为多个子空间下的并行注意力计算,让模型能够同时捕捉多种不同类型的上下文关系。
形象比喻:单头注意力好比只用一盏灯照射整段文本;多头注意力则是从多个角度同时打光,每个角度能观察到不一样的语言结构,最后再把所有视角的信息整合到一起。
5. FFN:对每个 Token 做非线性加工
Attention 负责让 Token 之间交换信息。
但交换完信息之后,每个 Token 还需要进一步加工自己的特征。
这就是 FFN,也叫前馈神经网络。
一个标准 FFN 可以写成:
FFN(x)=W2σ(W1x+b1)+b2 FFN(x)=W_2\sigma(W_1x+b_1)+b_2 FFN(x)=W2σ(W1x+b1)+b2
其中:
W1:升维矩阵
σ:非线性激活函数
W2:降维矩阵
例如隐藏维度是 4096,FFN 中间层可能升到 11008 或更高。
流程大致是:
4096 维 -> 11008 维 -> 激活函数 -> 4096 维
Attention 像是在做“信息路由”:
我应该从哪些 Token 拿信息?
FFN 像是在做“局部思考”:
拿到这些信息后,我应该如何重新理解当前 Token?
举个直观例子:
苹果 很 甜
苹果 手机 发布 新款
“苹果”这个 Token 在不同上下文中含义不同。
Attention 会先让“苹果”看到“甜”或“手机”等上下文。
FFN 再根据这些上下文,对“苹果”的内部语义表示做非线性加工,使它更像“水果苹果”或“苹果公司”。
所以 FFN 不是可有可无的附属模块,而是 Transformer 表达复杂语义的重要来源。
6. 残差连接:给深层网络留一条直通路
Transformer 通常有很多层。
如果一层一层连续变换,深层网络容易出现两个问题:
梯度消失
网络退化
残差连接的形式很简单:
y=x+F(x) y=x+F(x) y=x+F(x)
其中:
x 是原始输入
F(x) 是某个子模块的输出,比如 Attention 或 FFN
这意味着,即使 F(x) 暂时学得不好,模型至少还能保留原来的 x。
直观理解:
没有残差:每一层都必须完全重写信息
有残差:每一层只需要在原信息基础上做增量修改
例如:
x 表示当前 Token 已经知道的信息
F(x) 表示这一层新增的信息
x + F(x) 表示保留旧知识,同时加入新知识
这对深层 Transformer 非常重要。
如果没有残差连接,几十层甚至上百层网络会非常难训练。
7. LayerNorm:稳定每一层的数值分布
LayerNorm 的作用是稳定激活值。
对于一个 Token 的隐藏向量:
x=(x1,x2,…,xd) x=(x_1,x_2,\dots,x_d) x=(x1,x2,…,xd)
LayerNorm 会先计算均值:
μ=1d∑i=1dxi \mu=\frac{1}{d}\sum_{i=1}^{d}x_i μ=d1i=1∑dxi
再计算方差:
σ2=1d∑i=1d(xi−μ)2 \sigma^2=\frac{1}{d}\sum_{i=1}^{d}(x_i-\mu)^2 σ2=d1i=1∑d(xi−μ)2
然后归一化:
x^i=xi−μσ2+ϵ \hat{x}_i=\frac{x_i-\mu}{\sqrt{\sigma^2+\epsilon}} x^i=σ2+ϵxi−μ
最后再乘上可学习缩放参数和偏置:
yi=γx^i+β y_i=\gamma \hat{x}_i+\beta yi=γx^i+β
直观理解,LayerNorm 做的是:
把每个 Token 的特征拉回到一个稳定的数值范围
如果没有 LayerNorm,随着层数加深,激活值可能越来越大或越来越小,导致训练不稳定。
在现代 LLM 中,常见结构是 Pre-LN:
x -> LayerNorm -> Attention -> Residual
x -> LayerNorm -> FFN -> Residual
也就是先归一化,再进入子模块。
这种结构通常比 Post-LN 更适合训练深层模型。
8. Causal Mask:从计算过程看它如何阻止偷看未来
假设训练序列是:
我 喜欢 吃 烤肉
位置编号:
0 1 2 3
训练目标是整体右移一位:
输入:我 喜欢 吃 烤肉
目标:喜欢 吃 烤肉 <next>
也就是说,位置 0 预测位置 1,位置 1 预测位置 2,位置 2 预测位置 3。
训练时怎么计算
训练时不是一个词一个词算,而是整段序列一次性输入:
X=[x0,x1,x2,x3] X=[x_0,x_1,x_2,x_3] X=[x0,x1,x2,x3]
然后一次性算出:
Q=XWq,K=XWk,V=XWv Q=XW_q,\quad K=XW_k,\quad V=XW_v Q=XWq,K=XWk,V=XWv
接着计算所有位置之间的注意力分数:
Z=QKTdk Z=\frac{QK^T}{\sqrt{d_k}} Z=dkQKT
如果序列长度是 4,那么 Z 是一个 4 × 4 矩阵:
k0 k1 k2 k3
q0 z00 z01 z02 z03
q1 z10 z11 z12 z13
q2 z20 z21 z22 z23
q3 z30 z31 z32 z33
其中 zij 表示:
第 i 个位置的 Query 看第 j 个位置的 Key 的分数
如果不加 Mask,位置 1 的“喜欢”可以看到位置 2 的“吃”和位置 3 的“烤肉”。这就泄露了未来信息。
加 Causal Mask
Causal Mask 的规则是:
j <= i:可以看
j > i:不能看
对应矩阵:
k0 k1 k2 k3
q0 0 -∞ -∞ -∞
q1 0 0 -∞ -∞
q2 0 0 0 -∞
q3 0 0 0 0
把它加到注意力分数上:
Z′=Z+M Z'=Z+M Z′=Z+M
得到:
k0 k1 k2 k3
q0 z00 -∞ -∞ -∞
q1 z10 z11 -∞ -∞
q2 z20 z21 z22 -∞
q3 z30 z31 z32 z33
然后对每一行做 Softmax:
A=softmax(Z′) A=softmax(Z') A=softmax(Z′)
因为:
e−∞=0 e^{-\infty}=0 e−∞=0
所以未来位置的注意力权重变成 0:
v0 v1 v2 v3
q0 1 0 0 0
q1 a10 a11 0 0
q2 a20 a21 a22 0
q3 a30 a31 a32 a33
最后输出:
O=AV O=AV O=AV
例如位置 2 的输出是:
o2=a20v0+a21v1+a22v2+0⋅v3 o_2=a_{20}v_0+a_{21}v_1+a_{22}v_2+0\cdot v_3 o2=a20v0+a21v1+a22v2+0⋅v3
所以位置 2 不能读取位置 3 的信息。
这就是 Causal Mask 的全部作用:
矩阵可以并行算,但未来位置的 Value 权重被强制压成 0。
训练阶段:并行预测
经过多层 Transformer 后,每个位置都会得到一个输出向量:
o0, o1, o2, o3
再经过 LM Head 投影到词表:
logitsi=oiWvocab logits_i=o_iW_{vocab} logitsi=oiWvocab
假设词表大小是 |V|,那么每个位置都会输出一个长度为 |V| 的 logits:
位置0 -> 预测“喜欢”
位置1 -> 预测“吃”
位置2 -> 预测“烤肉”
位置3 -> 预测下一个 Token
训练损失是所有位置的交叉熵平均:
Loss=1N∑i=0N−1CE(logitsi,targeti) Loss=\frac{1}{N}\sum_{i=0}^{N-1}CE(logits_i,target_i) Loss=N1i=0∑N−1CE(logitsi,targeti)
所以训练阶段是:
一次输入 N 个 Token
一次计算 N 个位置的 logits
一次计算 N 个位置的 loss
这是全并行的。
推理阶段:串行生成
推理时没有完整答案,不能一次性知道未来 Token。
假设当前输入是:
我 喜欢 吃
模型先计算最后一个位置的 logits:
logits -> 全词表概率分布
例如:
烤肉:0.45
苹果:0.18
米饭:0.12
电影:0.03
...
通过 argmax 或采样选出:
烤肉
然后把它拼回序列:
我 喜欢 吃 烤肉
再继续预测下一个 Token。
所以推理阶段是:
第 1 步:输入已有上下文,生成 token_1
第 2 步:把 token_1 拼回去,生成 token_2
第 3 步:把 token_2 拼回去,生成 token_3
...
这是自回归串行生成。
KV Cache:避免重复计算历史
如果每生成一个 Token 都重新计算全部历史,成本很高。
所以推理时会缓存历史 Token 的 Key 和 Value。
第 t 步只需要计算最新 Token 的:
q_t, k_t, v_t
然后用:
q_t
去和缓存里的所有历史 Key 做注意力:
score=qtKcacheT score=q_tK_{cache}^T score=qtKcacheT
| k0 | k1 | k2 | k3 | k4 | |
|---|---|---|---|---|---|
| q0 | old | -∞ | -∞ | -∞ | -∞ |
| q1 | old | old | -∞ | -∞ | -∞ |
| q2 | old | old | old | -∞ | -∞ |
| q3 | old | old | old | old | -∞ |
| q4 | new(a40a_{40}a40) | new | new | new | new |
ot=softmax(score)Vcache o_t=softmax(score)V_{cache} ot=softmax(score)Vcache
| 输出 | 计算 |
|---|---|
| o0 | old |
| o1 | old |
| o2 | old |
| o3 | old |
| o4 | a40v0+a41v1+a42v2+a43v3+a44v4a_{40}v_0 + a_{41}v_1 + a_{42}v_2 + a_{43}v_3 + a_{44}v_4a40v0+a41v1+a42v2+a43v3+a44v4 |
最后把新的 k_t,v_t 追加进缓存:
K_cache = [K_cache, k_t]
V_cache = [V_cache, v_t]
所以推理阶段的核心是:
每步只算最新 Token
历史 K、V 从缓存读
这节的结论可以压缩成一句:
训练时用 Causal Mask 实现整段并行预测但不偷看未来;推理时没有未来可看,只能自回归串行生成,并用 KV Cache 避免重复计算历史。
小结
Transformer 的每个模块都有明确分工:
Embedding:把 Token ID 变成语义向量
RoPE:把位置编号变成旋转角度
Self-Attention:让 Token 从上下文中取信息
sqrt(d_k) 缩放:防止 Softmax 饱和
FFN:对每个 Token 做非线性语义加工
Residual:保留原信息,缓解深层训练困难
LayerNorm:稳定数值分布
Causal Mask:阻止模型看到未来
整体来看,Transformer 的真正强大之处不在于某一个单独公式,而在于这些模块组合起来形成了一个稳定、高效、可扩展的序列建模系统。
第三部分:前沿探索——离散限制与 ELF 连续生成模型
探讨 Transformer 时,无法回避文本数据天生的“离散符号”属性。传统自回归模型正是为了处理离散 Token 逐字分类而设计的。
近年来,何恺明团队提出的 ELF(Embedded Language Flows) 等连续空间生成模型,试图打破这一范式。
- 核心机制:将离散 Token 一次性映射为连续的 Embedding,并利用纯视觉图像领域成熟的流匹配(Flow Matching)与扩散去噪技术,在纯连续的高斯流空间中进行全并行演化。最后一步才通过共享网络投影回离散符号。
- 与 Transformer 的差异:废弃了时间轴的自回归串行,改为空间维度的整体渐变;废弃了单向因果掩码,采用全局双向注意力。
- 工程挑战:尽管 ELF 在极少数据量下展现了惊人的效率,避免了一步错步步错的误差累积,但将离散的绝对语义(如逻辑词、标点)强行压缩至平滑的连续空间中,其微观表达的精准度仍面临极大考验。目前,工业界的主干生产力依然被离散的自回归 Transformer 牢牢占据。
第四部分:Decoder-Only 架构的统治与进阶演化
在 Encoder-only(如 BERT)和 Encoder-Decoder(如 T5)共存的早期,Decoder-only 架构最终在生成式产品中占据统治地位,其工程与产品逻辑如下:
- 训练目标统一:Next-token prediction 直接等价于自回归语言建模,无需拆分复杂的多任务形式,预训练与部署链路高度一致。
- 扩展性(Scaling):随着参数和数据的增加,Decoder-only 在通用能力、Few-shot/In-context learning 上的边际收益呈现出压倒性优势。
- 接口标准化:对于上层应用,“提供上下文 →\rightarrow→ 继续生成”成为统一接口,无缝覆盖问答、规划、JSON 抽取与函数调用。
- 工程生态闭环:当前工业界的 KV Cache 优化、流式输出、投机采样(Speculative Decoding)等底层基建,均高度适配 Decoder-only 的拓扑结构。
规模扩展与能力涌现的底层逻辑
Next-token prediction 之所以强大,是因为海量语料本身隐含了人类世界的因果律、逻辑痕迹与程序模板。模型在压缩这些高维分布时,提取了任务间共享的统计结构。
根据 Scaling Laws,模型的交叉熵 Loss 会随参数、数据和算力的扩展按幂律下降。但能力提升不仅依赖单一参数堆砌,更依赖 Compute-optimal 的数据配比(如 Chinchilla 定律所揭示的参数量与训练 Token 数的协同扩展)。
运行时编程:In-Context Learning
GPT-3 确认了模型能够在不更新底层权重的情况下,仅凭上下文中的示例快速适应新任务(In-Context Learning)。其本质是模型利用 Transformer 的注意力机制,在运行时临时模拟某种任务分布。这是当前所有 Prompt Engineering、RAG(检索增强生成)与 Agent 规划的工作基石。
第五部分:2026 视角下的主流大语言模型版图
截至当前,业界模型分类矩阵已高度分化与成熟:
- 按架构切分:Decoder-only 作为通用主底座;Encoder-only 退居 Embedding、Rerank 与特定分类路由任务。
- 按参数激活方式切分:Dense 模型全量激活;MoE(混合专家模型)通过路由网络实现稀疏激活,在降低推理延迟的同时大幅推高了系统的总参数容量极限。
- 按产品范式切分:普通基础大模型与主打 System-2 慢思考的 Reasoning 模型(引入强化学习进行隐式思维链搜索);纯文本生成拓展至原生多模态结构化输入输出引擎。
第六部分:后端与工程视角的面试核心要点(Q&A)
在全栈开发与架构设计的面试中,面试官关注的绝非简单的论文复述,而是架构决策与底层工程瓶颈的连接能力。
Q1:Transformer 为什么比 RNN 更适合大模型时代?
核心在于算力硬件的适配性。Transformer 废弃了序列依赖,使得在海量数据预训练时,整个序列的矩阵乘法能够完美映射到 GPU/TPU 的并行流处理器上。但需补充,其代价是长序列 O(N2)O(N^2)O(N2) 的复杂度成本,引发了对显存架构的极高要求。
Q2:为什么要多头注意力(Multi-Head Attention)?
单一特征子空间无法解耦复杂的语言结构。多头机制通过并行的线性投影,强制模型从不同的表示子空间(如语法依赖、时态共指、长短程模式)中提取独立特征,随后拼接融合,提升了表征的稳健性与模型宽度的利用率。
Q3:参数越大越好吗?
并非线性正相关。模型能力的释放受限于训练数据质量是否饱和(Compute-optimal)。在生产环境中,大参数意味着极高的 KV Cache 占用与 TTFT(首字延迟)。工程决策追求的是质量、成本与延迟的 Pareto 最优,而非盲目追逐参数榜单。
Q4:LLM 里的知识是怎么存的?
知识以高度抽象的浮点数形式压缩在极高维的参数矩阵中,是一种条件概率分布,绝非关系型数据库的键值对。由于缺乏外部事实校验锚点,必然存在知识过时与“幻觉”碰撞。这是后端架构必须引入 RAG 与外部工具调用的根源。
Q5:为什么说 Transformer 是基础,但不是全部?
在当下的 AI 系统架构中,模型自身仅占 20% 的比重。剩余 80% 的工程挑战集中在 Tokenizer 的边界截断、分布式训练的数据流转、推理层的 vLLM/PagedAttention 显存分页管理、后训练的偏好对齐,以及顶层 Agent 的状态机调度与容错隔离。
结语:从算法底层走向工程全景
从最初的 Attention Is All You Need 到如今的 Agent 复杂系统,大语言模型的关注点已从单一的“参数是否智能”转向了“如何以最低的工程代价、在有限的上下文预算内、通过严谨的工具链完成复杂闭环”。
理解 Token 级的工作原理、掌握自回归机制的性能边界、洞悉概率采样的数学本质,是所有后端工程师与技术从业者在这个大模型时代,构建高可用、高吞吐 AI 原生应用的基础必修课。
参考资料与延伸阅读
[1] Vaswani A, et al. Attention Is All You Need[C]. NeurIPS, 2017.
[2] Brown T B, et al. Language Models are Few-Shot Learners[R]. 2020.
[3] Kaplan J, et al. Scaling Laws for Neural Language Models[R]. 2020.
[4] Hoffmann J, et al. Training Compute-Optimal Large Language Models[C]. ICML, 2022.
[5] OpenAI. Reasoning Best Practices[EB/OL]. 2026.
[6] Anthropic. Models Overview[EB/OL]. 2026.
[7] Google. Gemini API Docs[EB/OL]. 2026.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)