Linux IO模型与并发服务器 学习笔记
阻塞IO
用户层:
char buf[1024];
recv(fd, buf, sizeof(buf), 0);// 程序卡在这里等待数据内核
1、检查socket接收缓冲区是否有数据
2、若无数据:
•将进程状态设为TASK_INTERRUPTIBLE(可中断睡眠)
•进程从CPU运行队列移出,触发调度器切换其他进程运行
3、数据到达:
•网卡触发硬件中断→ 内核将数据拷贝到接收缓冲区
•唤醒进程(状态改为TASK_RUNNING),重新加入运行队列
非阻塞IO
函数原型:int fcntl(int fd, int cmd, ... /* arg*/ );
用户层:
fcntl(fd, F_SETFL, O_NONBLOCK); // 设置非阻塞标志
while (1) {
int n = recv(fd, buf, sizeof(buf), 0);
if (n >= 0) break; // 数据就绪
if (errno != EAGAIN) exit(1); // 错误处理
usleep(1000); // 避免CPU占满
}1、检查接收缓冲区,无论是否就绪都立即返回结果
2、无数据时:返回EAGAIN错误码,进程继续执行(不进入睡眠)
在非阻塞 I/O 模式下,如果数据未就绪,系统调用(如 read/write)会立即返回错误(如 EAGAIN)。如果不加处理而使用一个死循环不断轮询,CPU 会被占满(称为“忙等待”)。
为了避免这种情况,常见的方法是在循环中加入短暂的延迟(如调用 sleep、usleep 或 nanosleep),让出 CPU 给其他进程或线程,从而降低占用率。更高级的做法是配合 I/O 多路复用(如 select、poll、epoll)实现事件驱动,这比简单的 sleep 更高效,但不在选项内。
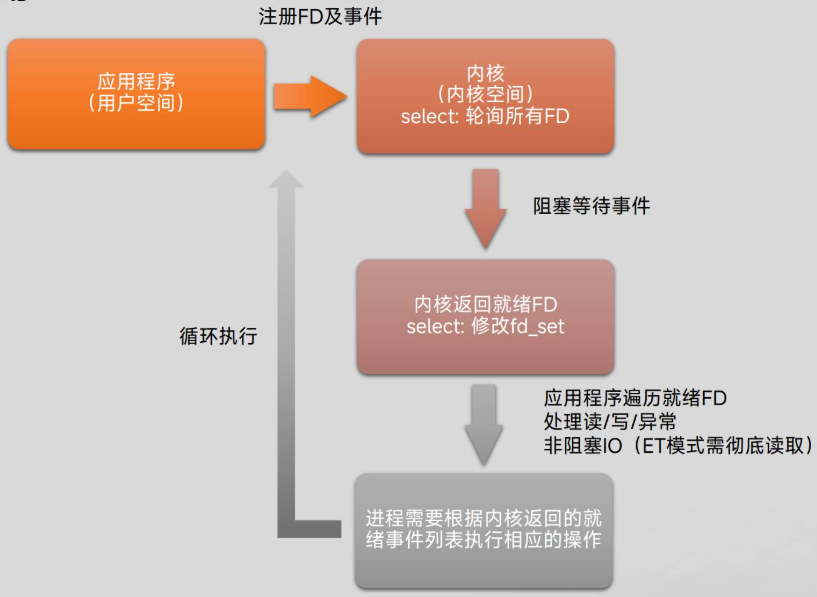
IO多路复用
IO多路复用是一种单线程或单进程管理多个文件描述符(如套接字)的技术,核心是通过系统调用监视多个IO操作的状态,当某个IO操作就绪(可读、可写或发生异常)时,通知应用程序进行处理
select
select函数
头文件:#include <sys/socket.h> #include <sys/types.h>
函数原型:int select(int nfds, fd_set*readfds, fd_set*writefds,fd_set*exceptfds, struct timeval*timeout);
参数:
•nfds要监视的最大的文件描述符+1
•readfds要监视的读文件描述符集合,如果不关心,可以传NULL
•writefds要监视的写文件描述符集合,如果不关心,可以传NULL
•exceptfds要监视的异常文件描述符集合,如果不关心,可以传NULL
•timeout超时时间如果是NULL表示永久阻塞
返回值:成功返回返回就绪的文件描述符的个数,失败返回-1(并重置错误码)
poll
poll函数
头文件:#include <sys/socket.h> #include <sys/types.h>
函数原型:int poll(struct pollfd*fds, nfds_tnfds, int timeout);
参数:
•fds一个指向pollfd结构体数组的指针,它描述了要监视的文件描述符及其事件
•nfdsfds数组中有效描述符元素的数量
•timeout是等待时间,单位为毫秒
返回值:成功返回结构体中revents域不为0的文件描述符个数;如果在超时前没有任何事件发生,poll()返回0,失败返回-1(并重置错误码)
IO多路复用
就绪事件通常包括以下三类:
可读:表示有数据可读,或者连接已关闭/出错(此时读操作会返回 0 或 -1)。
可写:表示可以写入数据(发送缓冲区未满)。
异常:表示发生异常事件,如带外数据(OOB)到达。
并发服务器
服务器模型
服务器模型有两种:循环服务器、并发服务器
循环服务器:循环服务器在同一个时刻只能响应一个客户端的请求
并发服务器:并发服务器在同一个时刻可以响应多个客户端的请求
TCP服务器默认的就是一个循环服务器,因为有两个阻塞的函数accept和recv之间相互影响
UDP服务器默认的就是一个并发服务器,因为只有一个阻塞的函数recvfrom
-
循环服务器(Iterative Server)在一个时间点只能处理一个客户端请求,必须完成当前客户端的服务后,才能接受并处理下一个客户端的连接或请求。它通常采用单线程/单进程模型,实现简单但并发能力差。
-
并发服务器(Concurrent Server)可以同时处理多个客户端的请求,通过多进程、多线程或 I/O 多路复用(如
select/epoll)实现。每个客户端连接可由独立的进程或线程处理,从而显著提高并发性能。
多线程并发服务器
实现原理:

流程:

主线程
创建监听Socket → bind() → listen()
while (1) {accept()接收新连接→ 创建子线程处理连接}
子线程
recv()/send()处理客户端请求
close()关闭连接
实现原理:
fork()模型:
•主进程监听连接,子进程处理请求
•父子进程完全独立,崩溃互不影响
预fork优化:
•启动时预先创建多个子进程(类似Apache)
•通过共享监听socket(SO_REUSEPORT)实现负载均衡
主进程:
•1.创建监听Socket → bind() → listen()
•2. while (1) {accept()接收新连接→ fork()创建子进程处理连接}
子进程:
•1. close()关闭监听Socket(继承自父进程)
•2. recv()/send()处理客户端请求
•3. exit()退出
IO多路复用并发服务器
| 主线程 | ||
| 1.创建监听Socket → bind() →listen() | 2.初始化fd_set集合,将监听Socket加入集合 |
3. while (1) { select()监听所有fd →返回就绪的fd数量 for (每个就绪的fd) { if (是监听Socket) →accept()新连接并加入fd_set else → recv()/send()处理数据 } } |
pollfd结构体
struct pollfd {
int fd; // 文件描述符
short events; // 等待的事件
short revents; // 实际发生的事件
};| 事件类型 | 常值 | 说明 |
|---|---|---|
| 读事件 | POLLIN | 普通或优先带数据可读 |
| POLLPRI | 高优先级数据可读 | |
| 写事件 | POLLOUT | 普通或优先带数据可写 |
| POLLWRNORM | 普通数据可写 | |
| 错误事件 | POLLERR | 发生错误 |
| POLLHUP | 发生挂起 | |
| POLLNVAL | 描述符不是打开的文件 |
TCP/IP协议
常见协议头分析
TCP/IP协议网络封包格式
| 源端口(16bit) | 目的端口(16bit) | |||||||
| 序号(32bit) | ||||||||
| 确认号(32bit) | ||||||||
| 源IP地址(32bit) | ||||||||
| 数据偏移(4bit) | 保留(6bit) | URG | ACK | PSH | PSH | SYN | FIN | 窗口(16bit) |
| 校验和(16bit) | 紧急指针(16bit) | |||||||
| 选项(长度可变) | 填充 | |||||||

TCP首部:
源端口和目的端口:TCP首部前两个字段,各占16位,用于标识发送和接收的应用进程。
序号和确认号:序号(32位)用于字节流编号,确认号(32位)用于告诉对方期望收到的下一个字节序号,仅在ACK标志位为1时有效。
窗口大小:16位字段,用于流量控制,告知对方自己的接收窗口大小。
| 版本号 | 首部长度 | 服务类型(TOS) | 总长度 | |
| 标识 | 标志位 | 片偏移 | ||
| 生存时间(TTL) | 协议 | 首部检验和 | ||
| 源IP地址 | ||||
| 目的IP地址 | ||||
| 选项字段(长度可变) | 填充 | |||
| 数据 | ||||

IP首部中,与分片直接相关的字段包括:
标识:用于标识同一原始数据报的不同分片,便于接收端重组。
标志位:包含 DF(不分片)和 MF(更多分片),控制是否允许分片及指示是否为最后一个分片。
片偏移:表示该分片在原数据报中的位置(以8字节为单位),用于正确重组。
标志位字段共 3 位,包含以下标志:
保留位:必须为 0(目前未使用)。
不分片(DF, Don't Fragment):置 1 表示不允许分片。
更多分片(MF, More Fragments):置 1 表示后续还有分片。
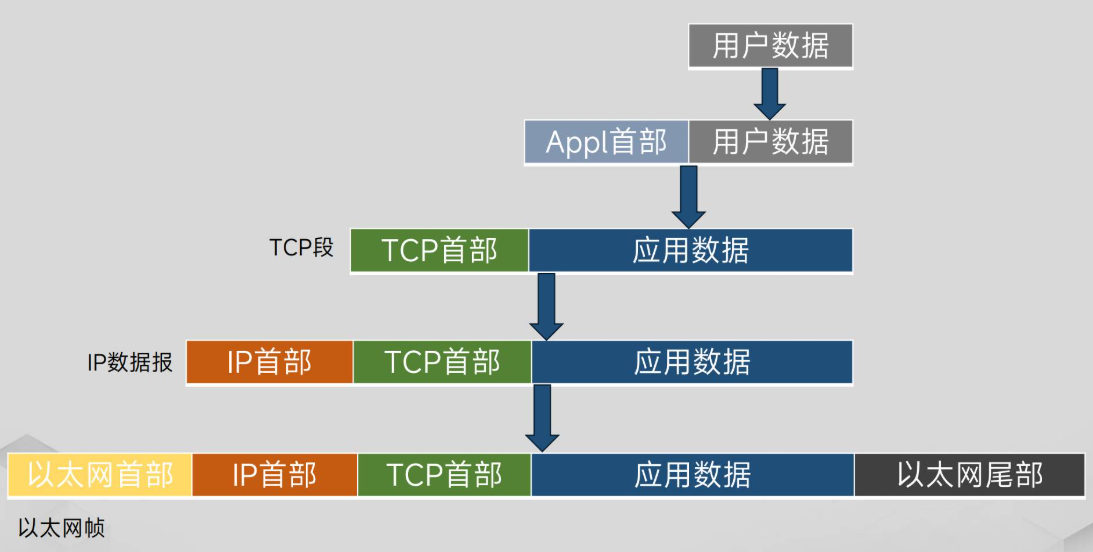
TCP/IP协议数据封装过程
抓包工具wireshark的使用
TCP沾包问题及解决方案
TCP沾包问题
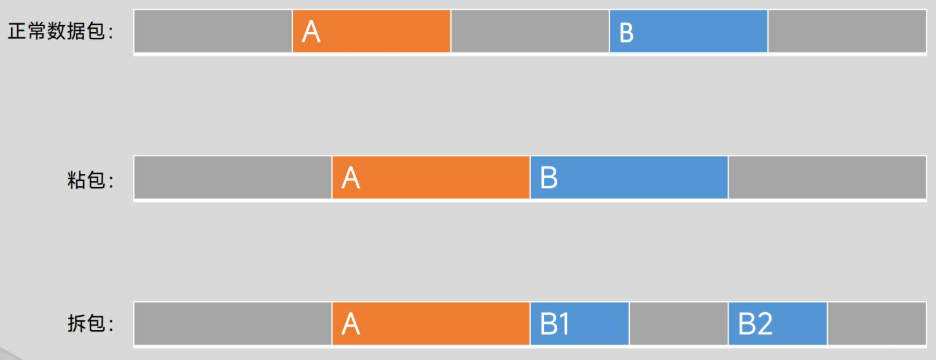

TCP 是面向字节流的协议:它不维护应用层消息的边界,只是将数据看作一串连续的字节序列。发送方可能将多个小数据块合并发送(例如 Nagle 算法),接收方也可能一次读取到多个消息的数据,导致应用层分不清哪里是一条消息的结束和下一条消息的开始,从而产生“粘包”。
TFTP协议
TFTP协议格式

根据不同的报文类型(RRQ、WRQ、DATA、ACK、ERROR),包含以下字段:
操作码:所有报文都必须包含的公共头部,用于区分报文类型。
块编号:出现在DATA和ACK报文中,用于标识数据块序号。
文件名:出现在RRQ和WRQ报文中,用于指定要读写的文件。
数据:出现在DATA报文中,用于承载文件内容(最多512字节)。
TFTP通讯流程
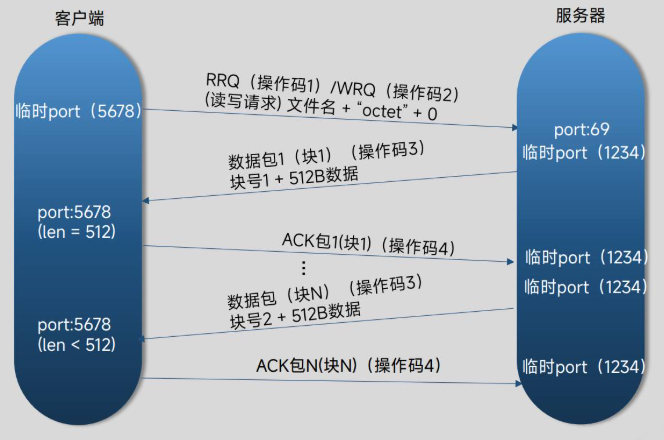
| 选项 | 与 TFTP 的关系 | 简要说明 |
|---|---|---|
| 块(Block) | 核心单元 | TFTP 协议传输的文件数据被分割成块。这是TFTP协议层面的逻辑单位,传输时每个数据包都包含一个块的数据。 |
| 帧(Frame) | 底层载体 | 指数据链路层的传输单元。TFTP 的数据包最终会被封装在以太网帧中进行物理传输。 |
| 包(Packet) | 同层概念 | 在大多数网络上下文中,packet 是对网络层(IP)PDU的泛指。同时,TFTP也可以被视为构建在 UDP 数据报 (datagram) 之上的应用层协议。 |
| 段(Segment) | 不同协议 | 通常指传输控制协议(TCP)的协议数据单元,而TFTP使用的是UDP(无连接的传输层协议) |
TFTP文本传输
根据 TFTP 的正式规范 RFC 1350 定义,每个 DATA(数据包)的结构中,用于标识块编号(Block Number)的字段长度为 16 位(16-bit)
一个 16 位的无符号整数,其可表示的数值范围是 0 到 65535。然而,协议规定 DATA 包的块编号必须从 1 开始编号,因此,块编号的最大值就是 65535
TFTP协议共有五种报文,其操作码值如下:
| 类型 | 操作码 | 功能描述 | 关键字段 |
|---|---|---|---|
| 读请求 (RRQ) | 1 | 客户端向服务器请求下载文件。 | 文件名、传输模式 |
| 写请求 (WRQ) | 2 | 客户端请求向服务器上传文件。 | 文件名、传输模式 |
| 数据包 (DATA) | 3 | 用于实际传输文件数据,每包数据大小固定为512字节。 | 块编号、文件数据 |
| 确认包 (ACK) | 4 | 用于确认已成功接收到一个数据块,告知发送方可以发送下一个。 | 确认的块编号 |
| 错误包 (ERROR) | 5 | 当发生错误时(如文件未找到),用于通知对方终止传输。 | 差错码、差错信息 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)