NexKnit:无公网 IP\穿透\中转服务器的轻量免费个人节点集群监控方案
企业级可观测性有 Prometheus,轻量化运维有哪吒。NexKnit 探索的是一个更窄、也更极端的问题:在你完全不能暴露任何入站网络访问、没有公网 IP和中转机、也不想花钱的前提下,怎么安全地看到设备的运行状态?
NexKnit 是一款基于约束开发的、完全开源免费的内网设备监控系统。它的网关只有 Python 标准库,单文件部署,零依赖,极易审查和集成。采集器和网关之间通过 TCP 环回通信,任何语言、任何工具,只要能在本地发一行文本,就能完成一次指标上报。云端寄生在 Cloudflare Workers 的免费额度上,全程无需信用卡,同时支持一键部署。
一、被网络限制逼出来的问题
在校园网、企业内网、或者没有公网 IP 的托管机房里,安全策略往往非常严格:不允许开放入站端口,也没有闲置的 VPS 可以当中转。传统的监控方案几乎都假设你至少有一个公网可达的服务端,或者依赖客户端和服务端之间的长连接。当这两个前提都不成立时,问题就变得很简单也很棘手:怎么在不破坏网络封闭性的前提下,把一份设备的实时健康快照安全地送出去?
二、从限制出发,而不是从功能出发
大多数项目是从"要做什么"开始设计的,NexKnit 是被"不能做什么"逼出来的。
它不能有入站连接。网关不监听任何对外端口,只主动往外发 HTTPS 请求,数据发完就关连接。它不能污染宿主机。很多跑着复杂深度学习环境的服务器非常脆弱,为了监控再装一堆守护进程和第三方依赖,很容易把环境搞崩。所以 NexKnit 的网关只有 Python 标准库,零依赖,一行命令就能启动。它不能花钱。整套系统寄生在 Cloudflare Workers 的免费计划上,推送间隔和存储策略都是精确算过的,保证每天消耗的请求数远低于免费额度。不是非得绑在 Cloudflare 上,只是它给的免费额度实在太多了。
三、不做管道,做邮筒
传统监控的思路是建一根管道——Agent 和服务端保持长连接,数据实时双向流动。这需要服务端公网可达,或者在内网防火墙上开一个口子。
NexKnit 换了个思路:不建管道,放个邮筒。
内网服务器上的网关定时把数据推到 Cloudflare Worker,Worker 只存最新一份,前端轮询 Worker 拉取数据。整个链路里,没有任何环节需要入站连接,数据只从内网往外流。这带来的安全模型很简单:内网和公网之间没有网络管道,只有一个单向的邮筒。就算云端接口地址暴露了,攻击者最多只能看到当前的仪表盘快照,不可能反向触达你的内网设备。
关于为什么全栈都用短连接:我们当然知道长连接在实时性和带宽控制上更好,但现实是几乎所有云厂商的免费计划都不支持无限制的长连接。在零预算这个硬约束下,全栈短连接不是技术倒退,是向商业现实低头后算出来的最优方案。
四、公网不稳定,所以每份数据发三遍
系统完全依赖公网 HTTPS 短连接推送,数据送达率不可能是 100%。我们在真实跨国网络上跑了 12,223 个包的压测,物理连接失败率大约 15.05%——每 100 次推送里差不多 15 次会丢。
为了解决这个问题,NexKnit 做了一个滑动窗口冗余策略:每次推送不只带当前批次的数据,还把前两次的旧数据也带上。在 15.05% 的失败率下,三次独立窗口都失败的概率降到 0.34%,最终数据存活率 98.25%。
五、仪表盘为什么看起来是流畅的
这里有一个需要诚实交代的设计细节:NexKnit 的仪表盘不是实时的,它有大约 13 秒的固定延迟。
原因很简单:前端内置了一个 Jitter Buffer,数据到达后不会立刻显示,而是先放进缓冲区。一个虚拟时钟按照原始时间戳的顺序,逐点把数据推出来。如果中间某个时间点的数据还没到——因为它还在公网上漂着——时钟就跳过它,不影响后面的点。这个 13 秒的窗口恰好覆盖了滑动窗口的冗余等待时间,给了迟到的数据一个补救的机会。
代价是你看到的永远是十几秒前的状态。回报是折线图不会断、状态灯不会莫名闪,整个仪表盘看起来是连续平滑的。这个取舍是否划算,取决于你的实际场景:如果你在看 GPU 温度或者训练进度,十几秒的延迟几乎无感;如果你在做秒级实时监控,NexKnit 确实不适合。
六、明确说清楚不做的事
不做生产级全量监控,这是 NexKnit 最核心的取舍。
但这不代表功能被锁死了。如果你需要本地持久化日志或者资源超限告警,完全可以在网关发数据之前,在本地侧自己拦截和处理。用本地脚本扩展网关成本很低,也是大语言模型很擅长生成的逻辑。在V0.2中,我们提供了完善的采集器矩阵,包含了告警和持久化等。而下一个版本,我们计划在云端加入对于节点服务的拨测告警。
七、协议:一行文本就是一次上报
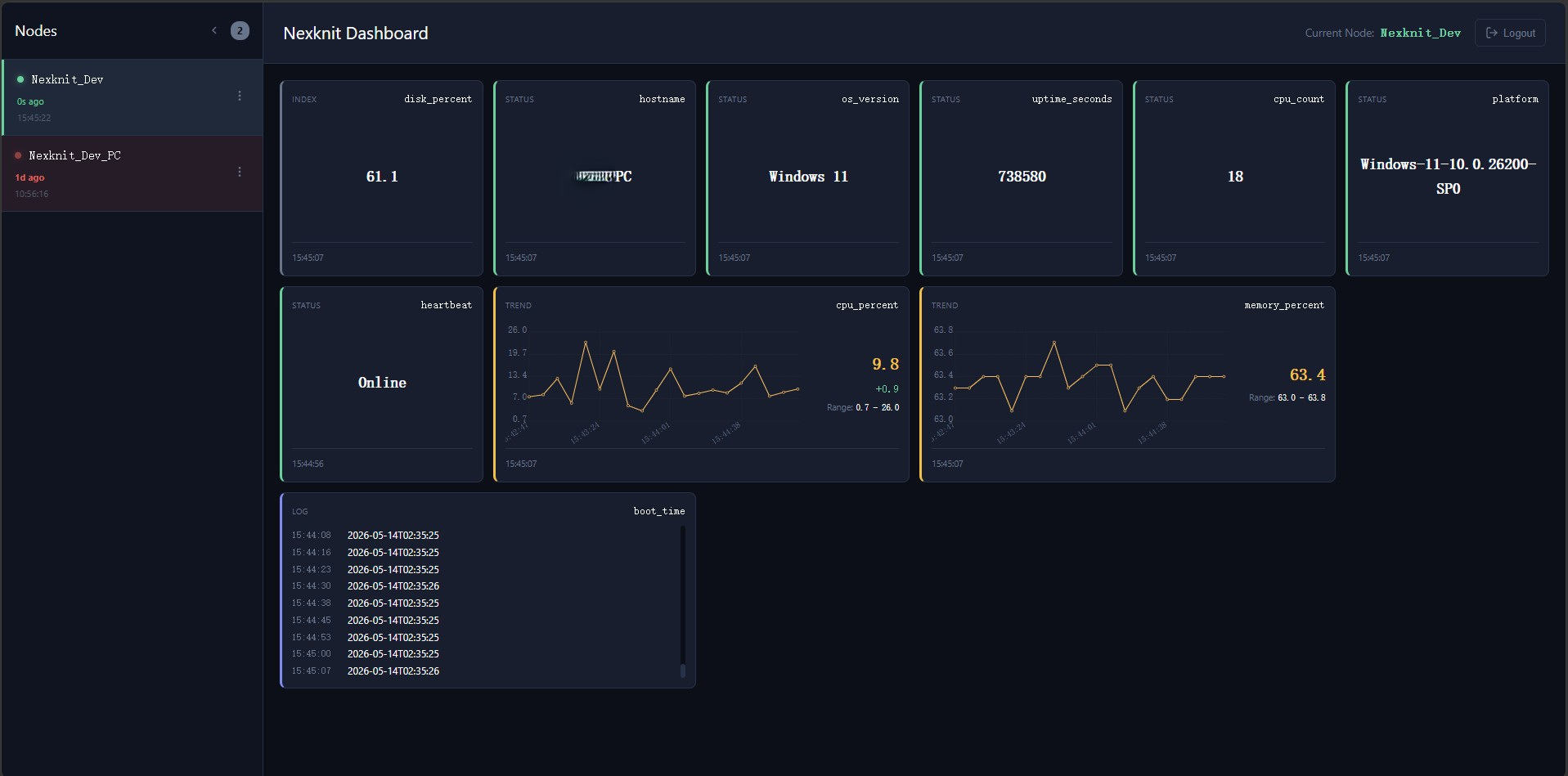
系统支持四种数据类型,覆盖了日常监控的大多数需求:覆盖型数值,比如 CPU 温度、GPU 利用率,只保留最新值;追加型数值,比如 loss 曲线、接口流量趋势,保留时间序列;覆盖型字符串,比如服务运行状态、Docker 容器生命周期;追加型字符串,比如流式控制台日志。
网关和采集器之间用的是纯文本的按行传输协议,没有任何 SDK 和语言壁垒。一行文本就是一次标准上报:
I|GpuTemp|67.2
S|ServiceA|running
T|TrainLoss|0.124你不需要引入任何外部依赖,用最简单的 Shell 脚本或者底层打印命令,就能把任意自定义指标打到云端仪表盘上。
八、版本不是按功能分,而是按约束分
目前发布的是内核分支 Core,但这不是项目的全貌。后续会并行开发一个插件分支 Plug。两个版本的区别不在于功能多少,而在于约束的松紧。
Core 死守无入站连接、环境零侵入、零成本对齐这三条铁律,在极端受限的环境下追求纯粹的安全。Plug 会适度放宽约束,引入重型插件框架,提供生命周期钩子和挂载点,容纳更复杂的本地定制。
我不敢说 Core 目前做的权衡是最优的,但在我现阶段面对的约束条件下,它已经是我能做到的极限了。关于告警功能:通过 Corn 任务每分钟检查一次节点存活状态、通过 Webhook 发告警,这个在 Core 分支上是可以做的。但告警往往和历史回溯绑在一起,而 NexKnit 完全没有提供历史数据能力。同时这个功能会占掉大约百分之三的配额,极端情况下可能导致超额。所以评估之后我暂时搁置了。如果你确实需要,可以在 GitHub 上提 Issue,我会认真考虑。
部署教程
部署教程现已发布在CSDN,请访问以获得更加详细的指引。Nexknit急速部署指南![]() https://blog.csdn.net/m0_49522240/article/details/161542534?spm=1011.2415.3001.5331
https://blog.csdn.net/m0_49522240/article/details/161542534?spm=1011.2415.3001.5331
现状和社区
NexKnit 刚发布 v0.2,核心链路已经跑通,代码完全开源,部署三分钟就能完成,README 里也提供了快速 Demo,同样基于 Cloudflare 免费额度。关于短连接权衡、滑动窗口算法这些技术细节,可以去看仓库里的架构设计章节。
项目仓库:https://github.com/nexknit-dev/nexknit-gateway
如果你手头也有一台不想暴露端口的内网设备,或者角落里的 Homelab NAS,想在手机上随时瞥一眼运行状态,NexKnit 也许刚好够用。
关于故障处理、中继设计模式这些工程问题,欢迎任何批评和反馈。目前的 UI 界面确实比较朴素,前端同好愿意帮忙改善仪表盘的话,非常欢迎提 PR。开屏语料库也接受带署名的合并请求。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)