AI 时代的统计学:去向何方?
温馨提示:若页面不能正常显示数学公式和代码,请阅读原文获得更好的阅读体验。
作者: 丁星星 (连享会)
邮箱: lianxhcn@163.com
- 分类:AI 专题
- Title: AI 时代的统计学:去向何方?
- Keywords: 数据科学, 数据库构建, Rebuilding Statistics in the Age of AI
- 提要:本文介绍了 Donoho 等 (2026) 的《"Rebuilding" Statistics in the Age of AI》,这篇文章记录了 2024 年 JSM 上一场关于「AI 时代统计学」的圆桌讨论。文章围绕统计文化、数据整理、现代经验建模、AI 时代人才培养,以及统计学如何与 AI 生态中各方合作展开,提出了许多重要的观点和启示。
原文:Donoho, D. L., Kang, J., Lin, X., Mukherjee, B., Nettleton, D., Nugent, R., Rodriguez, A., Xing, E. P., Zheng, T., & Zhu, H. (2026). "Rebuilding" Statistics in the Age of AI: A Town Hall Discussion on Culture, Infrastructure, and Training (Version 1). arXiv. Link, PDF, Google

「AI 会不会替代统计学?」很多人都有类似的疑问,但这篇文章给出的答案不是会或不会。它要讨论的是:当数据规模、模型结构、计算基础设施和知识生产方式都在变,统计学靠原来的课程体系、论文范式和学科边界,是否需要重建?如果需要重建,重建的内容是什么?重建的方式是什么?
2024 年 JSM(Joint Statistical Meetings)期间,统计学界和机器学习界的一批重要学者围坐在一起,开了一场圆桌讨论,话题是:AI 时代,统计学该怎么办?参与者包括 David Donoho、Xihong Lin、Bhramar Mukherjee、Eric Xing、Hongtu Zhu 等人,横跨统计学、生物统计和机器学习。大家没有回避分歧,也没有给出整齐划一的答案,而是把各自的判断和困惑都摆了出来。
Donoho 等 (2026) 的《"Rebuilding" Statistics in the Age of AI》是这次圆桌讨论的整理稿。文章有意保留了现场讨论和问答的语气,围绕统计文化、数据整理、现代经验建模、AI 时代人才培养,以及统计学如何与 AI 生态中各方合作展开。(arXiv)
本文介绍这篇文章的主要观点,为研究者和学生提供一些思考的视角。
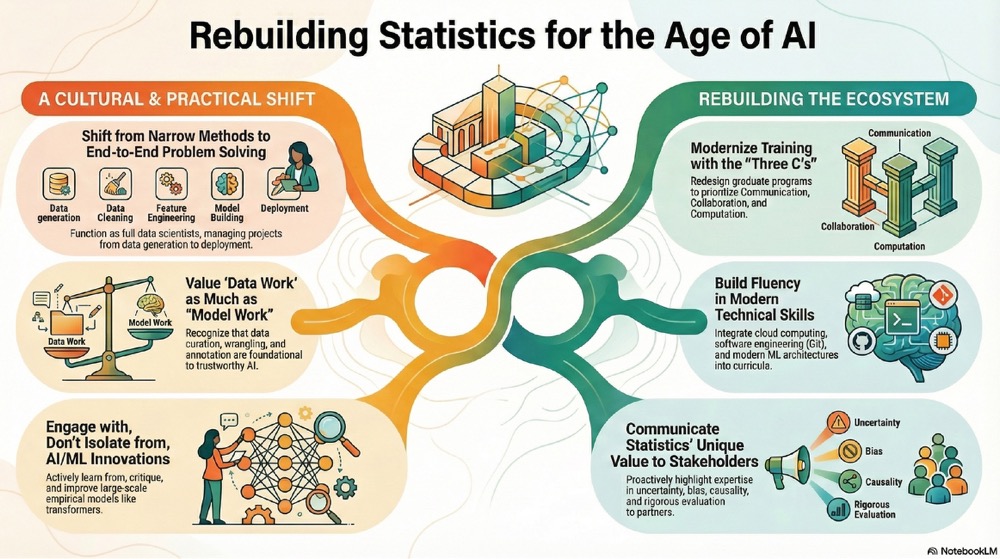
图 1:AI 时代统计学重建的核心议题:文化、数据、模型、训练与基础设施。
1. 冲击不只来自技术层面
谈 AI 对统计学的冲击,很多人容易把问题理解成工具更新:是否熟悉 Transformer,是否会用大语言模型,是否掌握扩散模型。
但这篇文章提出的问题更深:统计学的工作方式是否仍停留在「提出方法、证明性质、跑几个例子、发表论文」这个相对封闭的循环里?如果是,工具学再多也填不上这个缺口。
Xihong Lin 在讨论中提出,统计学需要从单点方法转向端到端的数据科学生态系统,至少包括三部分:公平而多样的数据、统计机器学习和 AI 方法及基础设施、可解释的数据分析结果。她还特别强调,大数据环境下数据公平性往往比数据规模更重要,偏差问题可能比方差问题更关键。
这对实证研究者是直接的提醒。很多论文把大量精力放在回归表和稳健性检验上,却没有充分交代数据是如何生成的、样本为何会进入观察范围、缺失值如何产生、结果能否外推。AI 时代只是把这个老问题放大了——模型越复杂,数据生成机制越不能被忽略。
用企业年报文本研究数字化转型时,年报文本是否真的反映了企业能力?用招聘文本研究 AI 暴露度时,岗位描述由谁写、怎么写?用平台数据研究消费行为时,谁被系统性排除在数据之外?这些不是模型之后的细节,而是研究设计本身的一部分。
2. 数据工作不是脏活
文章中最值得重视的一点,是重新评价 data work。
这里的 data work 不只是清洗数据,而包括收集、标注、整理、索引、接口、管道、复用、部署和维护。很多人愿意做模型,不愿意做数据。但 AI 系统里,数据标注和数据整理决定了偏差、鲁棒性和可信度——这个链条绕不开。
Xihong Lin 提到,真正的端到端数据科学生态需要更深地进入数据工程,包括分析管道构建、自动化和云端部署。她以全基因组测序数据为例说明,当数据规模足够大时,「把数据下载到本地」已经行不通,新的模式是把研究者带到数据所在的平台上。
对中文实证研究来说,这一点尤其扎心。我们常见的倾向是:数据整理是论文前期的「脏活」,只有模型设定、识别策略和估计结果才算真正的学术贡献。但一个高质量的企业供应链数据库、政策文本库、地方财政数据库,往往比一个边际上更复杂的回归规格更有长期价值。
遗憾的是,现有评价体系更容易奖励方法包装,而不是奖励可复用的数据基础设施。AI 系统并不会自动消除数据偏差,反而会把偏差以更隐蔽、更大规模的方式扩散出去。统计学长期关心抽样、代表性、缺失、测量误差和混杂因素,这些优势是真实存在的——问题是,它们必须进入数据生产和系统构建过程,而不能只在审稿意见里才露面。
3. 不能只站在 AI 外面批评
文章并不主张放弃统计学传统。相反,它反复强调不确定性量化、偏差识别、抽样设计、因果推断、可解释性的独特价值。
但强调归强调,这些价值必须进入 AI 系统内部,而不是只停留在外部评论。
Abel Rodriguez 指出,统计学者的优势在于不只关心点预测,也关心区间预测、估计不确定性、数据收集过程和数据偏差。但统计学训练中还缺少「中等水平的计算素养」:Git、基本软件工程、API 数据访问,以及把大语言模型纳入统计工作流的能力。
这句话对经管类研究训练同样适用。学生可能能熟练解释固定效应和工具变量,但未必能规范管理一个项目文件夹,未必会用 Git 记录代码变化,也未必能把论文、代码、图表、日志和复现说明组织成一个可交付的研究项目。
Eric Xing 的观点更直接。他认为,现代 AI 系统并不总是从概率模型和似然函数出发,而是依赖海量数据、通用架构、工程优化、分布式计算、后训练、检索增强和用户反馈。大语言模型的成功迫使统计学重新回答:什么是理解?什么是严谨?什么样的证据足以说明一个系统有效?
这不是说理论不重要,而是说理论需要解释新的重要现象——大语言模型的不确定性如何度量?合成数据能否进入统计推断?没有传统抽样框的互联网数据如何定义总体?一个 AI 系统部署之后如何持续监测和校准?这些问题都需要统计学参与,但参与方式不能只是把旧公式套到新对象上。真正的问题是:统计学能否提出一套让 AI 系统更可靠、更可解释的知识框架和工作流程。
4. 课程改革不只是加课
文章对统计学教育的反思很具体,也很有意思。
Dan Nettleton 提出,统计学界不能把所有学生训练成同一种人。他用了一个比喻:随机森林之所以有效,恰恰是因为每棵树不完全相同;如果所有树都一样,随机森林就退化成一棵树。统计学界也是如此——如果所有学生都接受高度同质化的训练,整个学科的适应能力就会下降。
Bhramar Mukherjee 指出,统计学教育需要更强调三个 C:communication、collaboration 和 computation,同时要把 AI 数学基础、图与网络随机建模、Transformer 和自编码器纳入课程,而不是长期停留在选修课层面。
Eric Xing 的提法更直白:不应只是往学生身上继续堆工具,而要让他们面对真实问题,培养好奇心,并判断现有课程中哪些内容应该删掉。课程改革不只是「加课」,也包括「删课」——旧课程中有些内容已经很少服务于学生未来面对的问题,就必须重新评估它们的位置。
对经管类实证研究训练而言,这一点同样关键。学生光熟悉固定效应、断点回归和 DID 还不够,还需要知道如何组织一个可复现的研究项目:版本控制和协作写作、数据 API 与数据库访问、文本与网络数据处理、AI 辅助编程、模型评估与可视化、数据伦理和算法偏差分析。
这不是降低统计推断的重要性,恰恰相反——只有当学生能把统计推断放到完整数据流程中理解,他们才更能体会识别假设、样本选择和因果解释为什么重要。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)