商汤日日新 SenseNova U1 系列原生理解生成统一模型全面开源实战评测
一、写在前面:为什么这次开源让我格外关注
做AI这行久了,我对"理解模型看不懂图、生成模型画不对意思"这种割裂早就见怪不怪了。视觉理解模型(比如CLIP、传统VLM)看图说话一把好手,但让它画张图就歇菜;图像生成模型(比如Stable Diffusion)画出来的东西确实漂亮,可你让它理解复杂语义,它就抓瞎。"理解"和"生成"之间这道鸿沟,一直是多模态AI最头疼的问题。
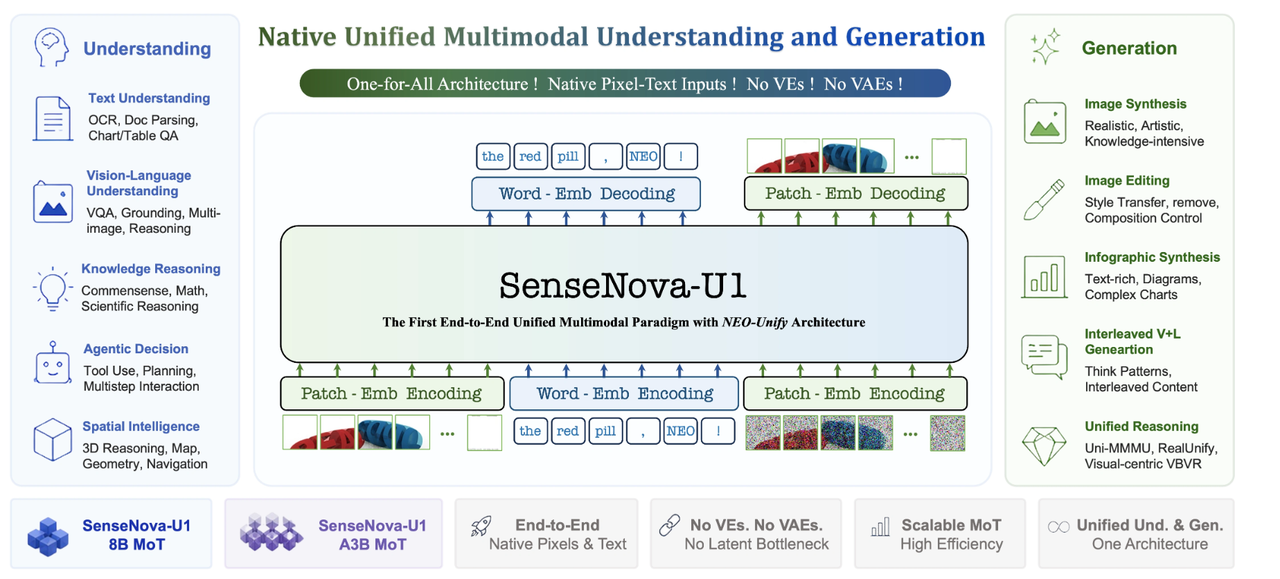
所以商汤宣布开源基于NEO-unify架构的SenseNova U1系列模型时,我第一反应是——终于有人认真做"统一"了。它从架构层面就把语言和视觉信息当作一个整体来建模,理解和生成之间没有边界。光这个思路就值得好好试试。
本次开源发布的是SenseNova U1的轻量版系列SenseNova U1Lite,共包含 6 个版本,覆盖了两种骨干架构(稠密网络与混合专家MoE),并提供多种训练阶段的权重:
| 模型 | 参数量 | Hugging Face 模型权重 |
|---|---|---|
| SenseNova-U1-8B-MoT | 8B MoT | 🤗 链接 |
| SenseNova-U1-8B-MoT-SFT | 8B MoT | 🤗 链接 |
| SenseNova-U1-8B-MoT-Infographic | 8B MoT | 🤗 链接 |
| SenseNova-U1-8B-MoT-LoRA-8step-V1.0 | 0.4B | 🤗 链接 |
| SenseNova-U1-A3B-MoT | A3B MoT | 🤗 链接 |
| SenseNova-U1-A3B-MoT-SFT | A3B MoT | 🤗 链接 |
在官方正式发布产品后,我第一时间进行了全面体验,接下来为大家详细测评这款理解与生成能力兼备的 SenseNova U1,感受它的出色实力。
开源地址:
- GitHub:https://github.com/OpenSenseNova/SenseNova-U1
- HuggingFace:https://huggingface.co/collections/sensenova/sensenova-u1
二、技术理解:NEO-unify架构到底"统一"了什么
动手之前,先说说我对NEO-unify架构的理解,这关系到后面测评怎么看、看什么。
传统多模态AI大致有两条路线:
路线一:理解优先。 用视觉编码器(比如ViT)提取图像特征,再映射到语言空间,交给LLM做推理。这类模型看图问答、OCR、图像描述都很强,但完全没有图像生成能力。
路线二:生成优先。 以扩散模型(Diffusion)为核心,从噪声开始逐步去噪生成图像。文生图、图像编辑这类创作任务做得漂亮,但对图像内容的深层语义理解跟不上。
两条路线各自发展得都不错,但有一个绕不开的矛盾:理解模型"只看不画",生成模型"只画不看"。 想要一个既能看懂图片、又能基于理解来修改和创作图片的AI?那就得在两个模型之间来回切换,中间的信息损失避免不了。
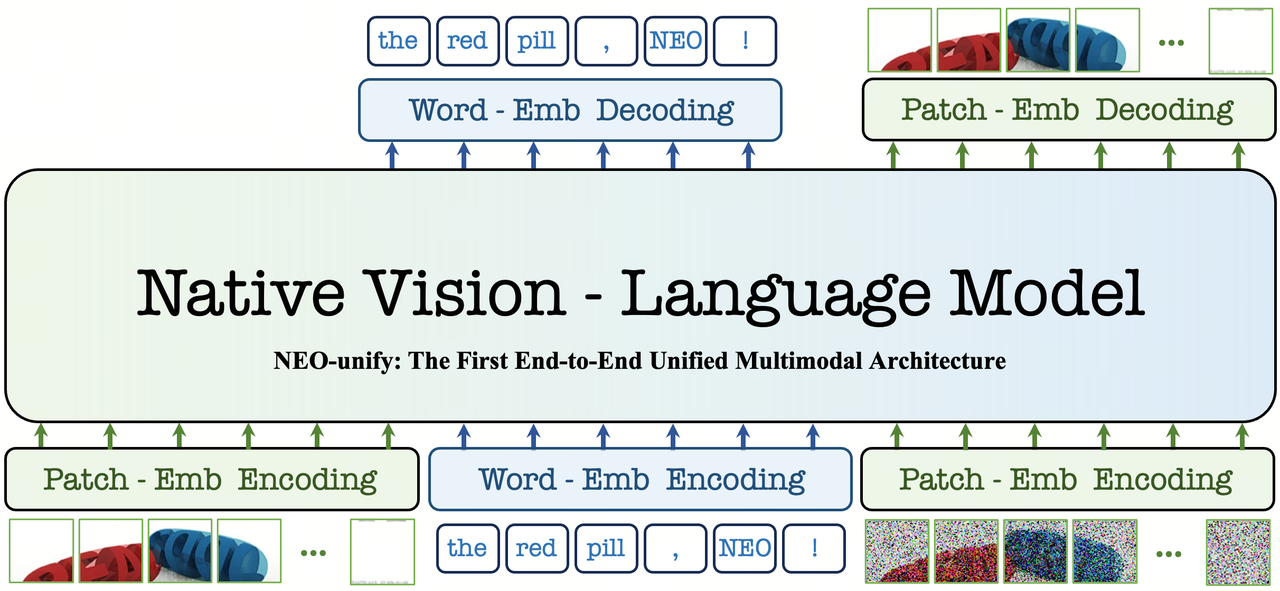
NEO-unify的核心思路,就是打破这种割裂。 它将语言token和视觉token放入同一个模型中联合处理,理解和生成共享同一套视觉表征。也就是说:
- 模型"看"图片时学到的视觉知识,可以直接用来"画"图片
- 生成图像时,模型天生就懂语义约束,不用额外加控制模块
- 理解任务里练出来的细节感知能力,反过来也提升了生成的像素级精度
简单说:从底层打通了理解和生成,两者共享同一套视觉表征。
实际用起来,这种统一架构最直接的好处就是——一个模型就能搞定从理解图片到创作图片的完整流程,不用来回切工具,信息传递零损耗。
基于这个核心架构,SenseNova U1在多模态学习上的效率表现也很亮眼:
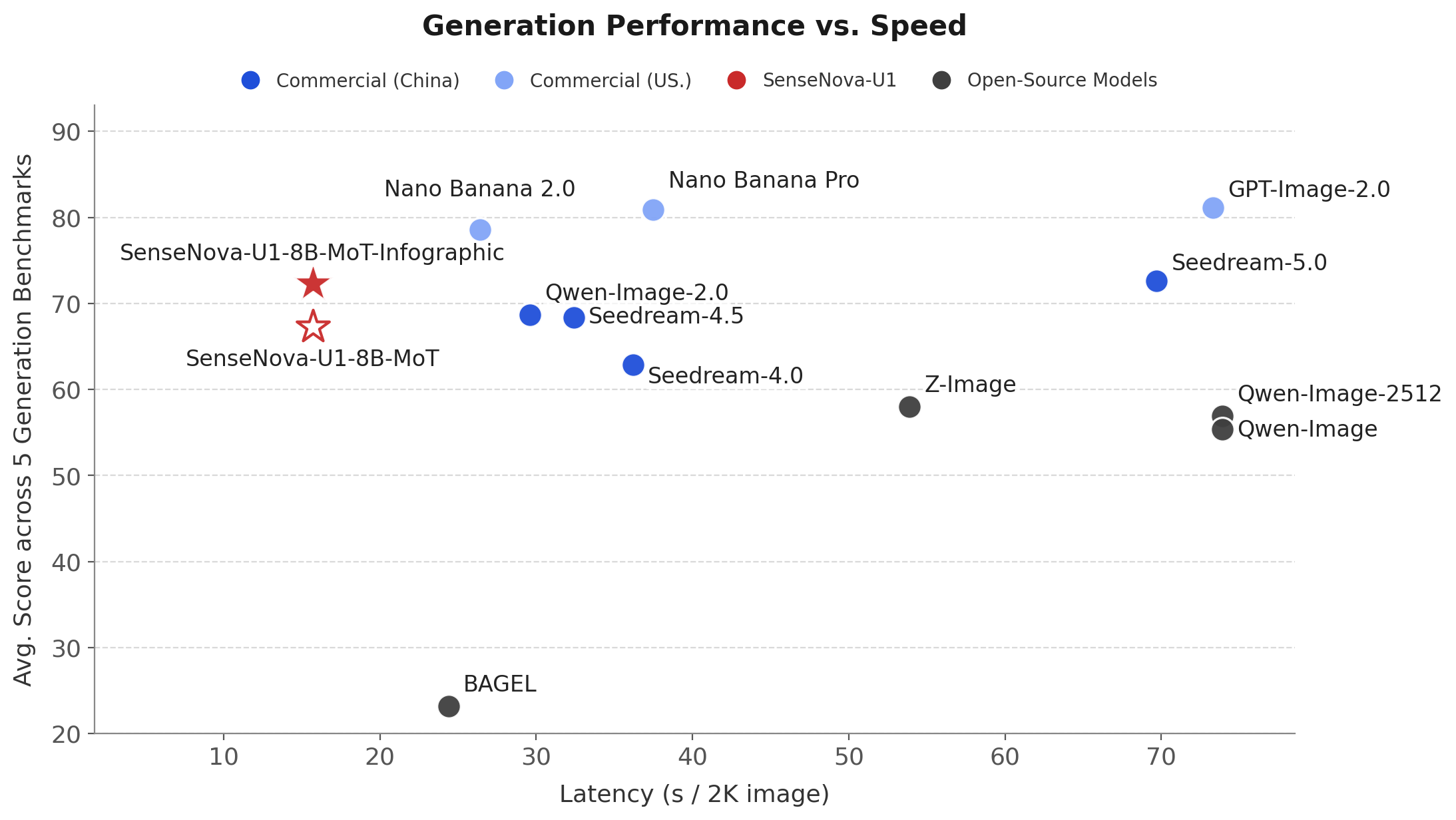
- 🏆 理解与生成均达到开源 SoTA:SenseNova U1 在统一多模态理解与生成上树立了新的标杆,在多种理解、推理与生成基准上均达到开源模型中最先进的水平,比肩商用大模型。
- 📖 原生图文交错生成:SenseNova U1 可以用单一模型在单次生成流程中连贯产出图文交错内容,支持生活指南、旅行日记等既需要清晰表达又富有叙事性与表现力的场景,把复杂信息浓缩为直观的图示。
- 📰 高密度信息呈现:SenseNova U1 在高密度视觉信息表达上展现出强大能力,能够生成结构丰富、排版复杂的内容,适用于知识图解、海报、PPT、漫画、简历等多种信息密集型场景。
这三个亮点里,我最关注的是第二个——“原生图文交错生成”。市面上绝大多数模型要么只生成文字,要么只生成图片,能做到文字和图片穿插输出的少之又少。更关键的是,SenseNova U1在单次生成流程里就把文字和图片穿插着输出了,说明模型内部确实在同时规划文字叙事和视觉表达。如果这个能力够成熟,它改变的就不只是"画图效率"了——从"先写文再配图"变成"图文一体、一口气出来",这是创作方式上的变化。
三、实测环境准备
3.1 在线体验与接入
由于本地部署对硬件有一定要求,我选择使用 SenseNova-Studio 来体验 SenseNova-U1。SenseNova-Studio 是官方提供的免费在线体验平台,不用装任何东西,不用GPU,打开浏览器就能试。

四、核心能力实测
接下来进入本文的核心环节——实测。我设计了4个递进式的测试场景,从高密度信息图渲染到链式推理生成,一步步验证SenseNova U1的"理解+生成"统一能力。
4.1 测试1:高密度信息图渲染(结构化内容能力)
测试目标: 看模型生成知识图谱/信息图的布局逻辑和文字渲染精度。
信息图生成是我认为最能体现"统一架构"价值的场景。它同时考验三样东西:语义理解(搞懂复杂的时间线逻辑)、视觉规划(合理布局多个信息节点)、文字渲染(在图像里把字写清楚)。传统文生图模型遇到这种"高密度+强逻辑+多文字"的需求,经常翻车——要么文字糊成一团,要么布局乱七八糟。
测试提示词:
帮我生成一份汽车制动系统的各个组成部分及其工作原理的高密度信息图,背景为深蓝色网格,汽车部件以白色线条勾勒。围绕核心的制动盘和卡钳展开多个子图和标注区域详细解释关键部件与技术参数。
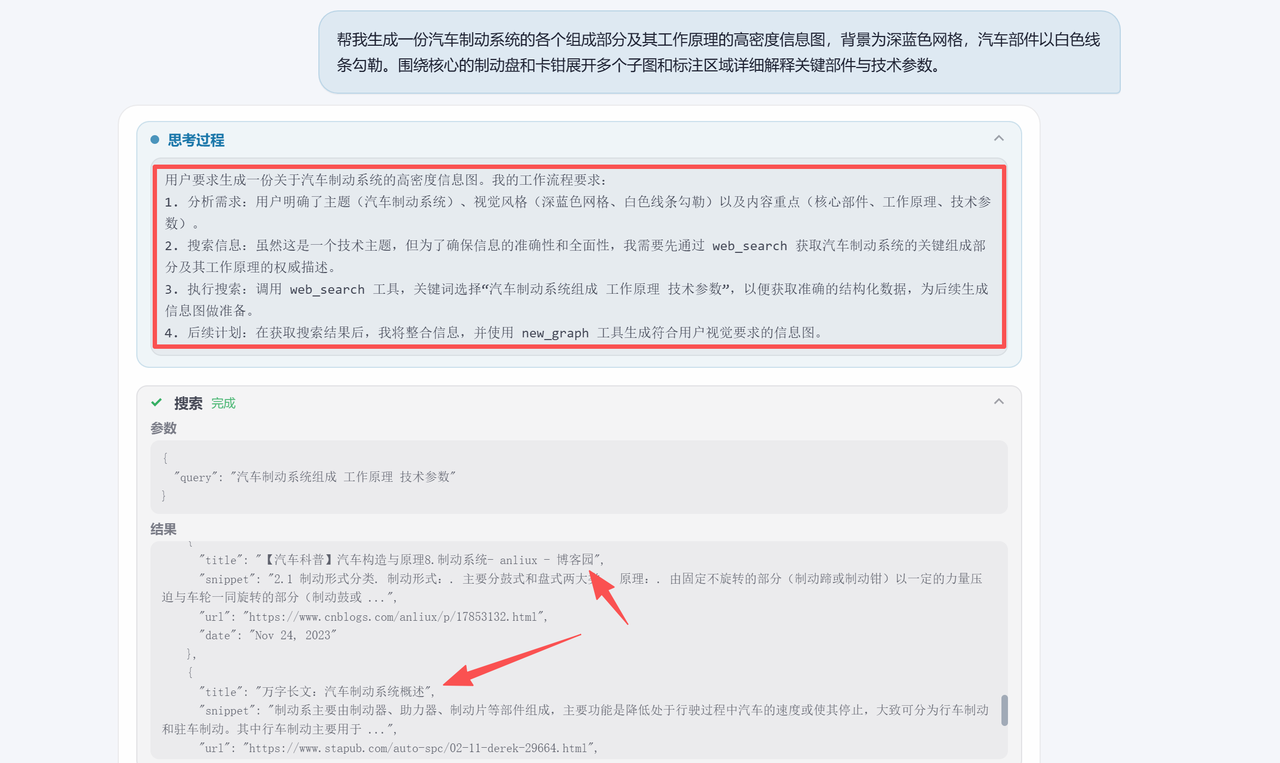
从截图可以清晰看到,SenseNova U1拿到提示词后并没有急着开画。它先梳理了一下逻辑,规划好工作流程,然后调用web_search工具,用"汽车制动系统组成"“工作原理”"技术参数"这几个关键词去搜,抓取结构化数据,给后面的信息图打好数据基础。
这一步挺让我意外的——我原以为模型会直接用内置知识生成,但它主动去搜了最新的技术参数,"生成之前先验证"这一点做得不错。

搜完资料后,SenseNova U1又把搜集到的数据整合了一遍,同时对原始提示词做了细化调整。它给每个子图都定了具体的创作要求和尺寸格式,然后按规范一个个生成。

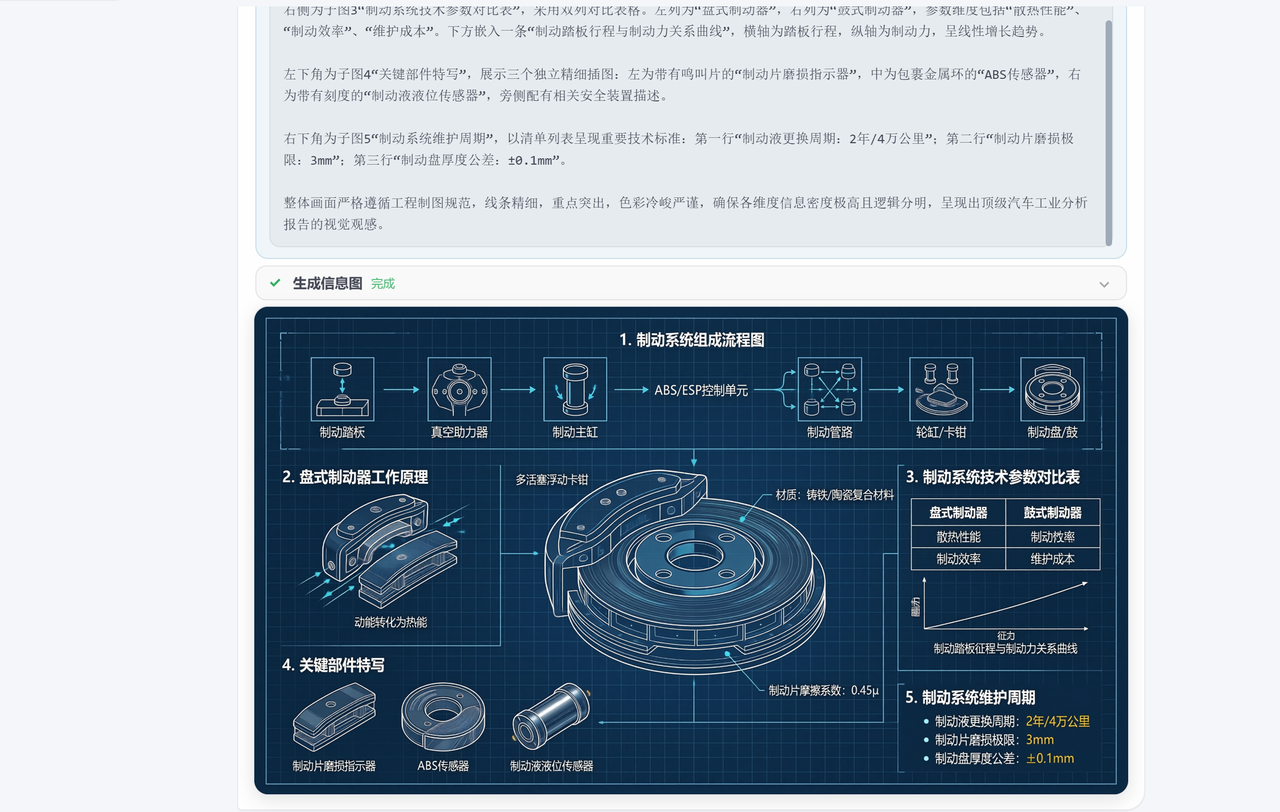
这次测试下来,SenseNova U1整个过程让我印象最深的是它的"工作节奏感"。它有一个很清晰的创作流程:先理解需求→再搜集数据→然后规划子图→最后逐一渲染。这种"先想后画"的方式,传统文生图模型基本做不到。更有意思的是它对制动系统各子图的拆分逻辑——制动盘、卡钳、刹车片、液压系统,每个模块都有独立的标注和技术参数,布局合理不拥挤。模型确实理解了汽车制动系统的结构原理,然后把它视觉化了。对于做技术文档、教学课件的朋友来说,这个能力很实用。
4.2 测试2:图文交错内容生成
测试目标: 验证SenseNova U1最核心的差异化能力——原生图文交错生成。
这个测试在我看来是最具"含金量"的一个。它不仅要求模型能生成多张图片,还要求每张图片的风格跟对应文字的意境对得上。
测试提示词:
用漫画记录亚洲象一家的北迁记。
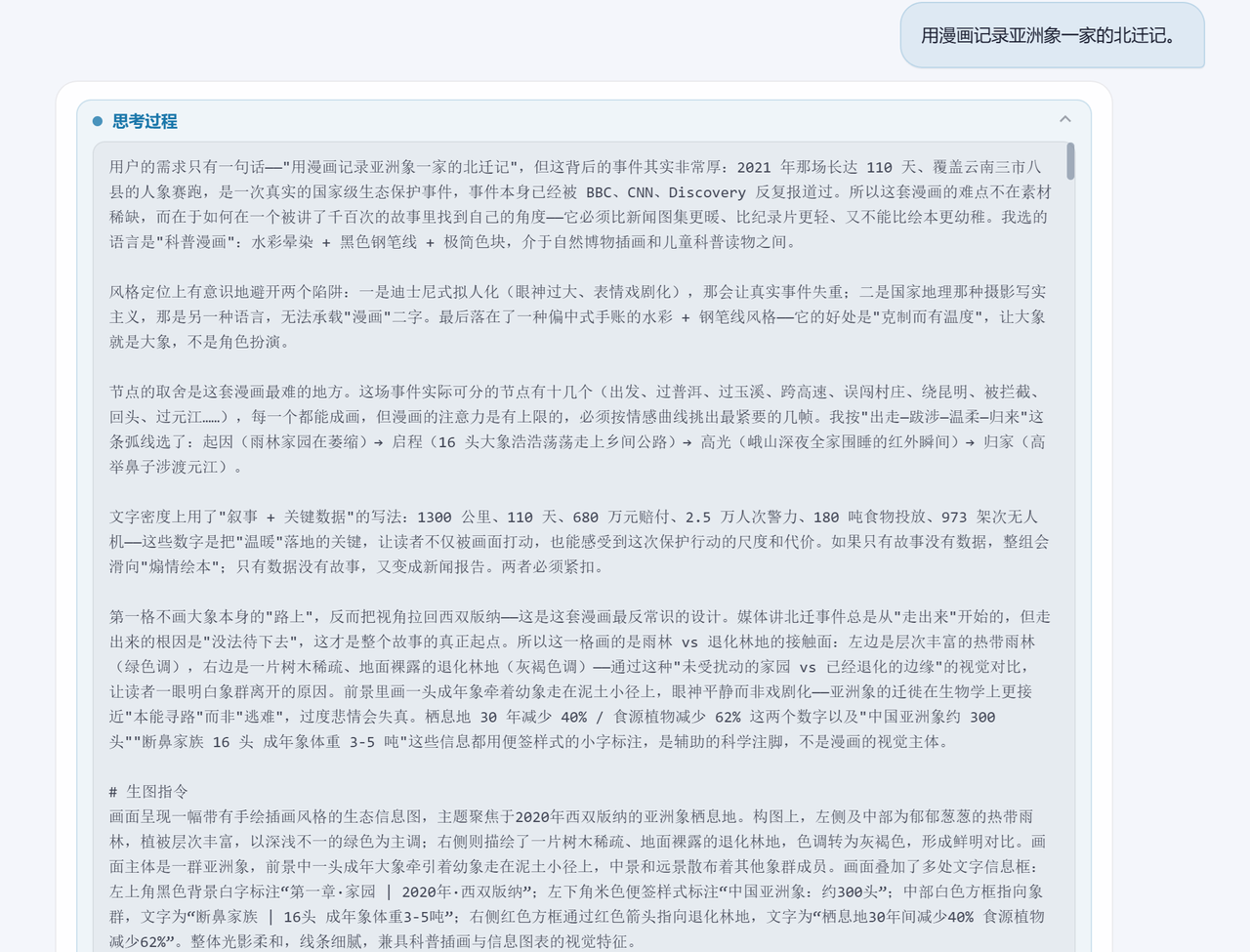
注意看——我只给了一句话,SenseNova U1就自动搭出了完整的故事框架。它选了4个关键画面做图文交错生成,每个画面都自动生成了完整的生图指令,包括场景描述、角色设定、画面风格,一口气搞定。
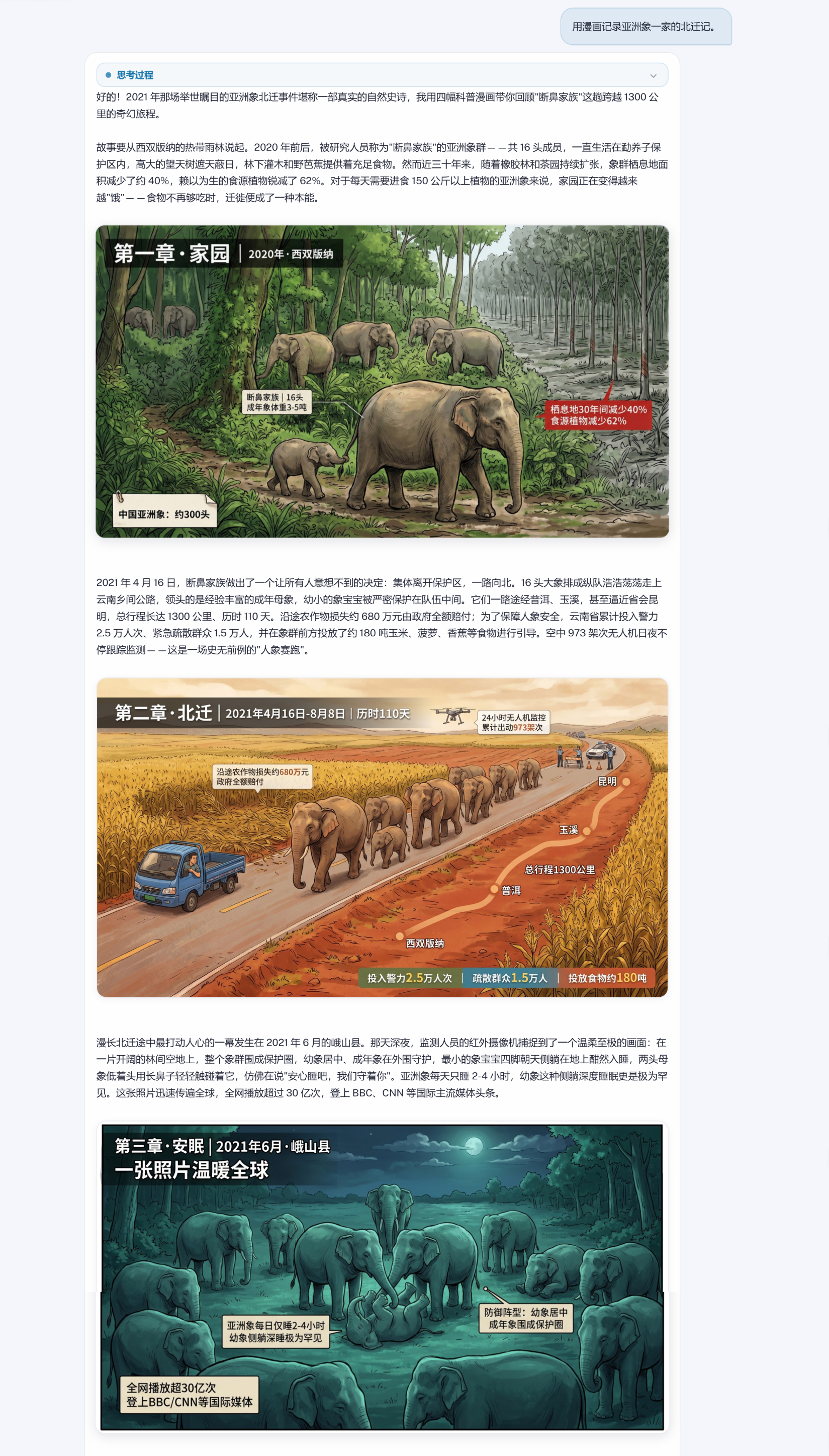
最终结果完成度不错。文字有叙事节奏,图片有场景变化,两者配合得挺自然。
个结果一下子让我想到好几个实际场景。写公众号推文——以前得先码字、再找配图、最后排版,现在一句话丢给模型,图文内容直接出来,稍作调整就能发。做儿童绘本也一样,把故事梗概喂进去,模型自动帮你拆场景、画插画、配文字,效率提升很大。"一键图文"离我们真的不远了。
4.3 测试3:复杂场景视觉保真能力测试
测试目标: 看模型在极端细节要求下的视觉生成精度。
前两个测试看的是"宏观能力"——信息结构、图文协同。这个测试我决定啃硬骨头,用极致的细节描述来压测模型的视觉保真度。选了中式茶席场景,因为茶具的材质质感(紫砂的颗粒感、青瓷的冰裂纹)和光影效果(丁达尔光效、水滴折射)都是视觉生成里最难搞定的元素。
测试提示词:
生成一张超写实静物摄影:中式茶席特写
主体:紫砂壶(表面颗粒质感 + 茶渍包浆)+ 青瓷茶杯(冰裂纹釉面反光) 桌面:老榆木纹理 + 自然磨损痕迹 + 茶水滴落的水渍 背景:虚化的竹帘 + 斜射的午后阳光(丁达尔光效) 细节:壶嘴滴落的一滴茶水(透明折射 + 动态模糊)、茶杯边缘的茶沫 色调:暖棕 + 墨绿,电影感低饱和

选这个测试是因为"超写实静物"是检验视觉生成模型实力的试金石。很多模型画风景、画人物都不错,但遇到静物微距——要精确呈现材质纹理、光线折射、液体动态——就容易露馅。关键不在"画面好不好看",在于每个细节经不经得起放大:紫砂壶的颗粒质感糊不糊?冰裂纹釉面有没有真实的折射光?壶嘴那滴茶水的透明度和动态模糊自不自然?

结果确实让我眼前一亮——壶面的磨砂感清晰可辨,青瓷茶杯的冰裂纹釉面很完整,连桌面上的老榆木纹理都做出来了。虽然这里水滴有一些不够完美不过一个8B级别的轻量模型能做到这个细节表现力,真的超出预期。
4.4 测试4:多模态推理链式生成
测试目标: 验证模型的"理解→推理→生成"链式能力。
前三个测试分别看了信息密度、图文交错和视觉保真。这个测试换个角度——看SenseNova U1能不能"先想再画"。我给它一个逻辑性很强的连环脑筋急转弯场景,5个节点、多米诺骨牌式的因果链,看它能不能一次搞定。
测试提示词:
帮我生成一个"连环脑筋急转弯",采用明亮高对比度色彩的扁平化卡通趣味风格。整体布局为从左到右的时间顺序时间轴,体现多米诺骨牌效应,背景为米白色带有浅灰色波点纹理的纸张质感。主标题使用粗体黑体,技术数据与正文使用紧凑的无衬线字体。
画面左上角为起始事件。一架白色卡通飞机图标旁标注文字"飞机上有5000块砖"。飞机下方绘制了一块掉落的红色砖块,旁边附带文字"掉下一块→剩余4999块"。
向右为节点1。一台蓝色冰箱与一头灰色大象图标旁带有文字"把大象关进冰箱"。下方排列三个步骤图标:一扇开启的门图标配文字"打开门",冰箱内装着大象的图标配文字"放入大象",一扇关闭的门图标配文字"关门"。
继续向右为节点2。一只黄色长颈鹿与蓝色冰箱图标旁标注文字"把长颈鹿关进冰箱"。下方排列四个步骤图标:开启的门图标配文字"打开门",向外移动的灰色大象图标配文字"拿出大象",冰箱内装着长颈鹿的图标配文字"放入长颈鹿",关闭的门图标配文字"关门"。
右侧居中为节点3。木制动物园大门前聚集着猴子和狮子等动物图标,标注文字"动物园开会"。紧邻此处有一个红色感叹号图标,并在一台关闭的冰箱图标旁标注文字"长颈鹿在冰箱中缺席"。
向右下方为节点4。一个干涸空荡的石头水池,水池内站着一位白胡子卡通老人图标。旁边带有文字"老人掉进鳄鱼池"以及"空鳄鱼池,鳄鱼去开会了"。
最右侧为节点5。倒在石头上的老人图标上方,悬浮着巨大的黄色问号图标与橙色爆炸底纹图标。旁边标注文字"老人爬出后又死了"。
最终因果揭示:一条夸张的红色弧线箭头直接从左上角起点的掉落红色砖块出发,跨越整幅画面,精确指向右下角倒地老人的头部。箭头终点处标注文字"被第1问中掉下的砖块砸死"。
画面最底部居中,放置一行醒目的深蓝色大号文字"逻辑的蝴蝶效应:一个荒诞的因果链条"。
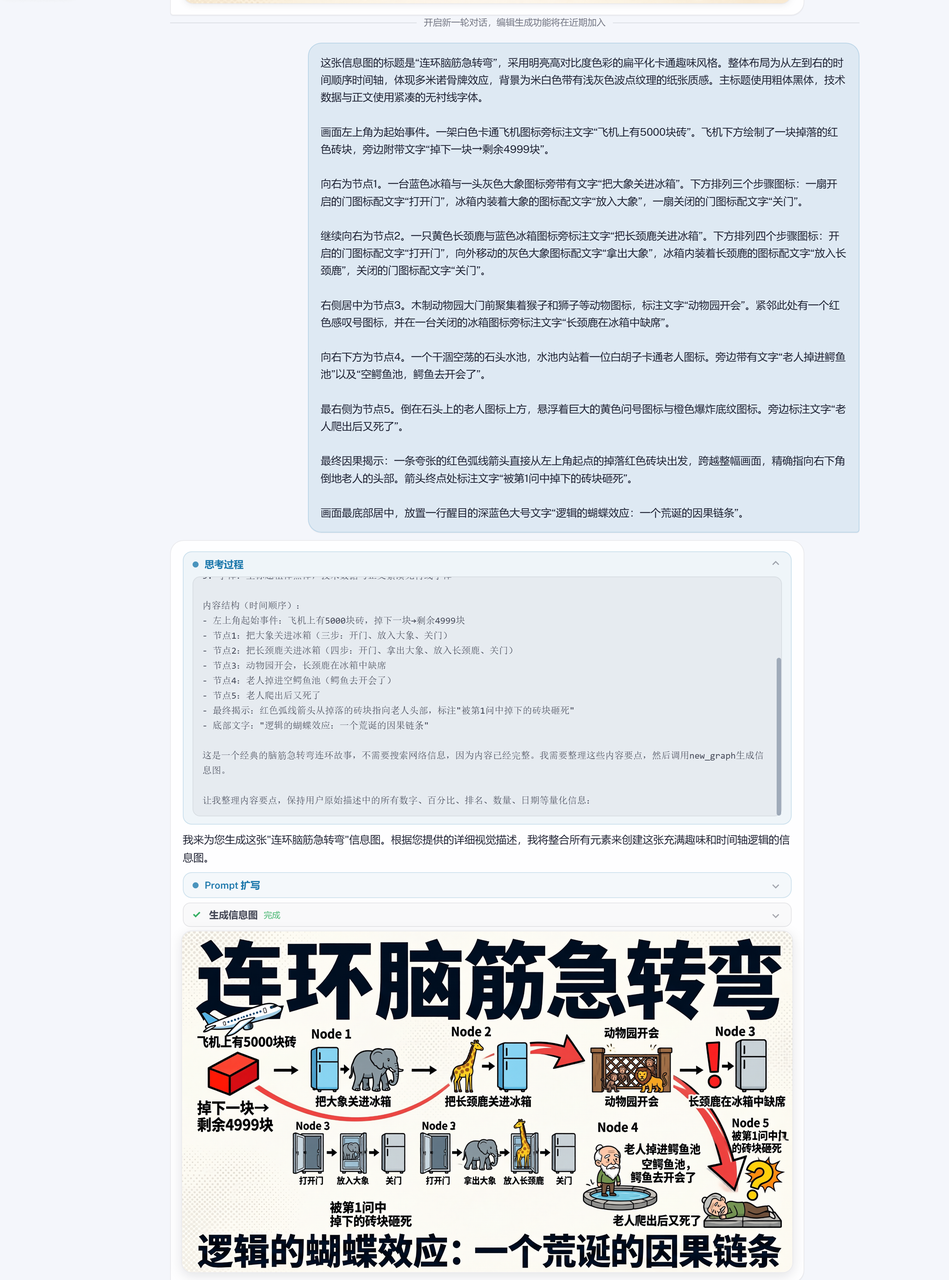
这大概是本轮测试里提示词最长、逻辑最复杂的一个。5个节点、多米诺骨牌式的因果链、横跨整个画面的红色箭头……我就是在用极端的复杂度来"为难"模型。我想验证的是SenseNova U1的链式推理能力——它能不能在理解完所有节点的逻辑关系后,再把它们合理编排到一个画面里。结果来看,5个场景节点都正确解读了,链式结构的因果关系也体现出来了。能把这个"脑筋急转弯"完整跑通的模型,需要一定的能力。
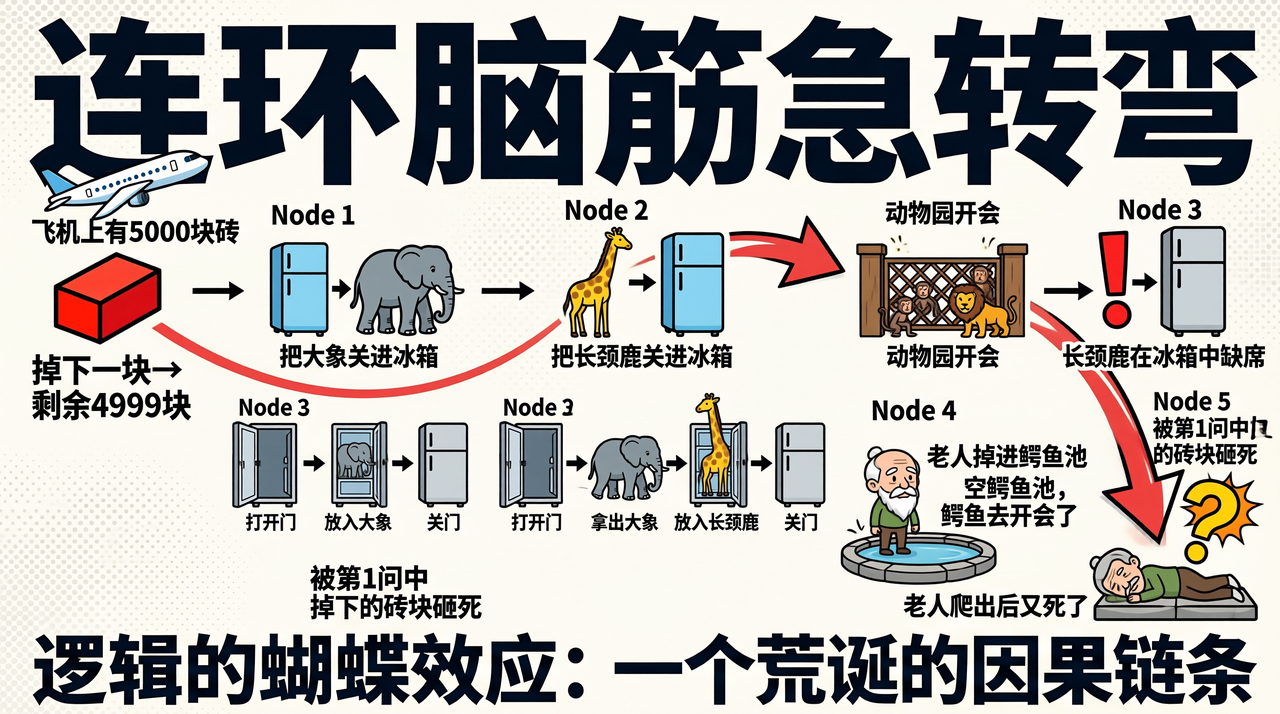
从最终输出看,虽然结构非常复杂,但SenseNova U1还是准确识别了所有需求,5个图片场景和它们之间的因果链条都呈现出来了。
五、ComfyUI 接入体验
除了在线体验,SenseNova U1 也支持通过 ComfyUI 进行本地部署和可视化工作流编排。这意味着什么?更灵活的参数调节、更自由的工作流定制——对有本地 GPU 资源的开发者和创作者来说,体验完全不一样。
想本地部署的朋友,可以看看 smthemex 大佬前几天做的 ComfyUI 节点,已经可以正常生成了:
https://github.com/smthemex/ComfyUI_SenseNova_U1
这里采用的是 SenseNova-U1-A3B 模型,最低 8G 显存 + 36G 内存就能跑,不过速度会比较慢。想流畅体验的话,建议 16G 显存起步。
由于博主手边没有 16G 显存的环境,所以这次直接上云端 ComfyUI 平台 runninghub 来做测试。
5.1 快速体验
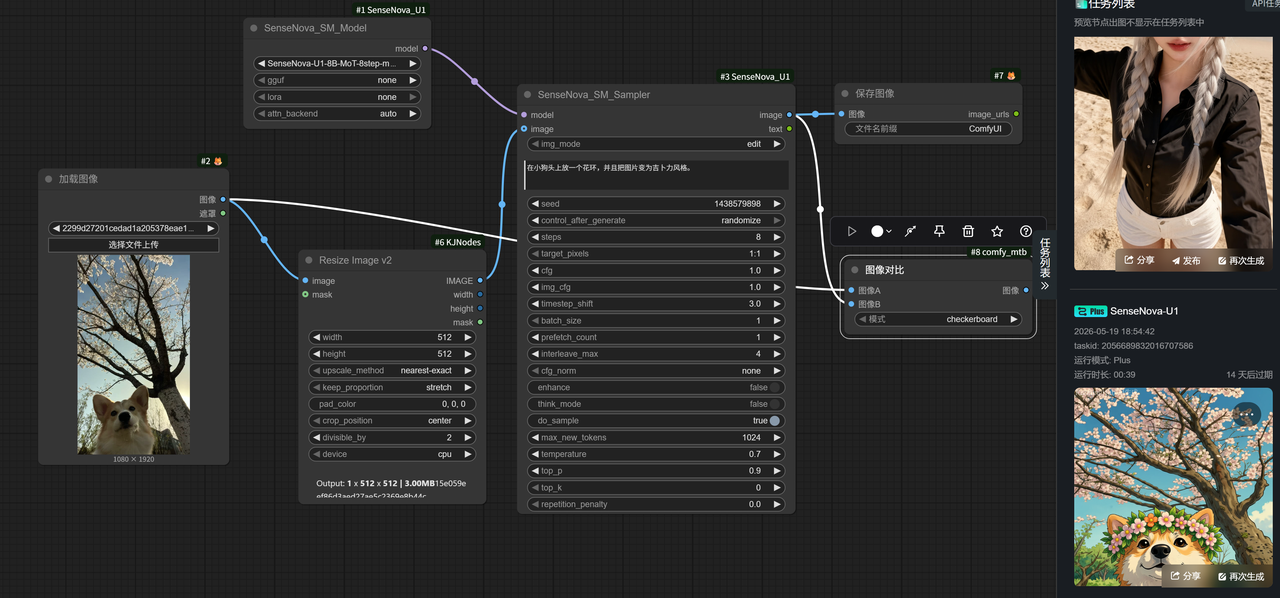
工作流搭建很简单,把几个必要的节点连起来就行。我额外加了一个图像对比节点,方便后面直观地比较生成效果。
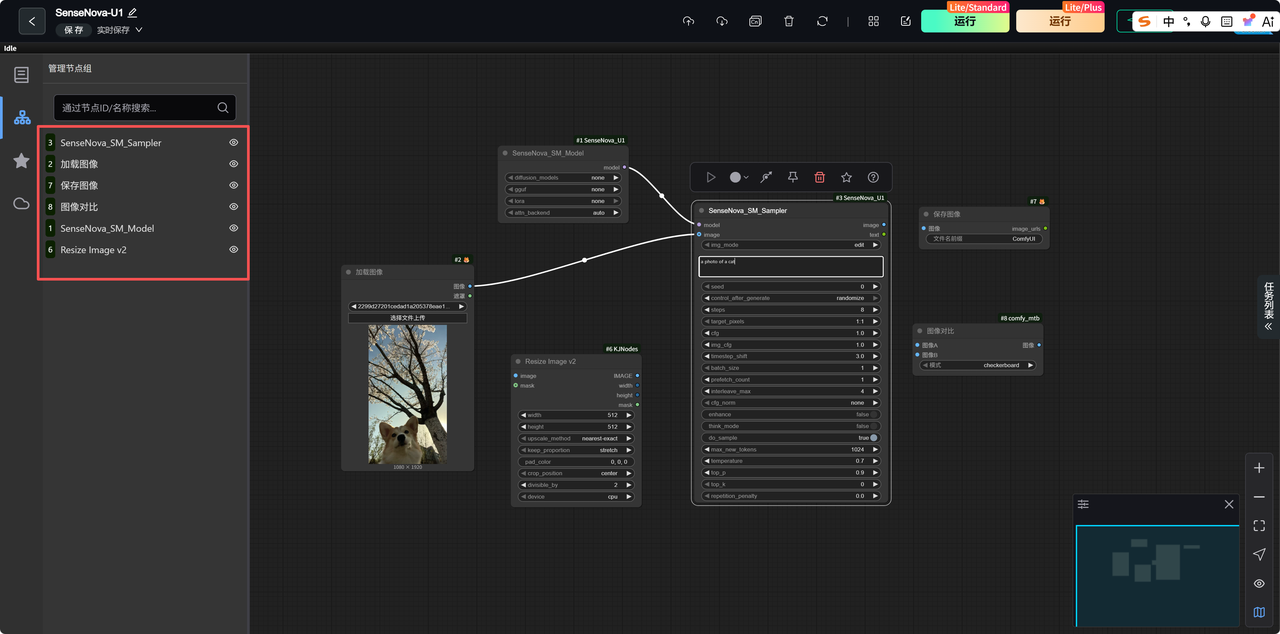
模型选的是 SenseNova-U1-8B-MoT-8step。
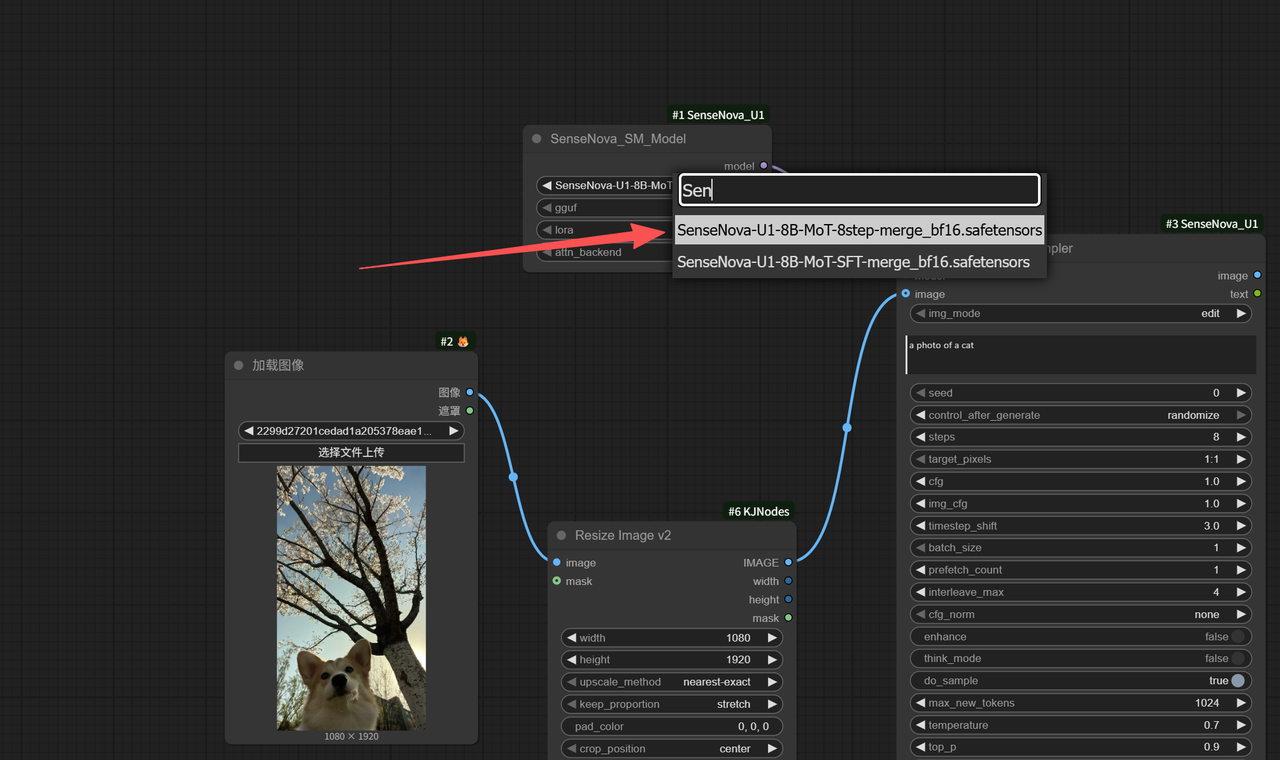
然后输入提示词我们运行Plus模式(这个模式将调用48G显存机器运行任务)来简单看下效果,可以看到生成的速度还是很不错的在一分钟以内就完成图片的输出。
5.2 图像编辑能力测试
前面测试跑通之后,我又重点试了一下图像编辑。给了模型一张人物照片,让它把衣服换成黑色衬衫,同时保持光影和人物姿态不变。
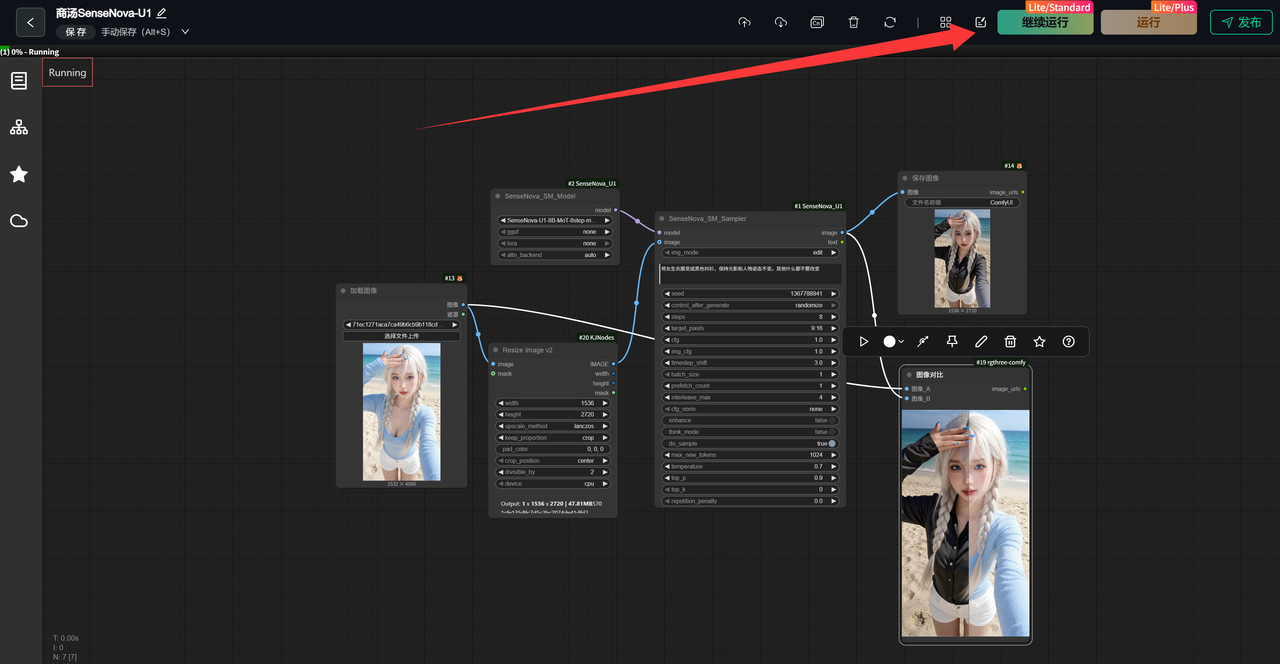
提示词: 将女衣服变成黑色衬衫,保持光影和人物姿态不变
这次切换到 Standard 模式(调用 24G 显存机器)看看这个配置下速度怎么样。可以看到本次生成时间大概 1 分钟左右,还是蛮不错的。
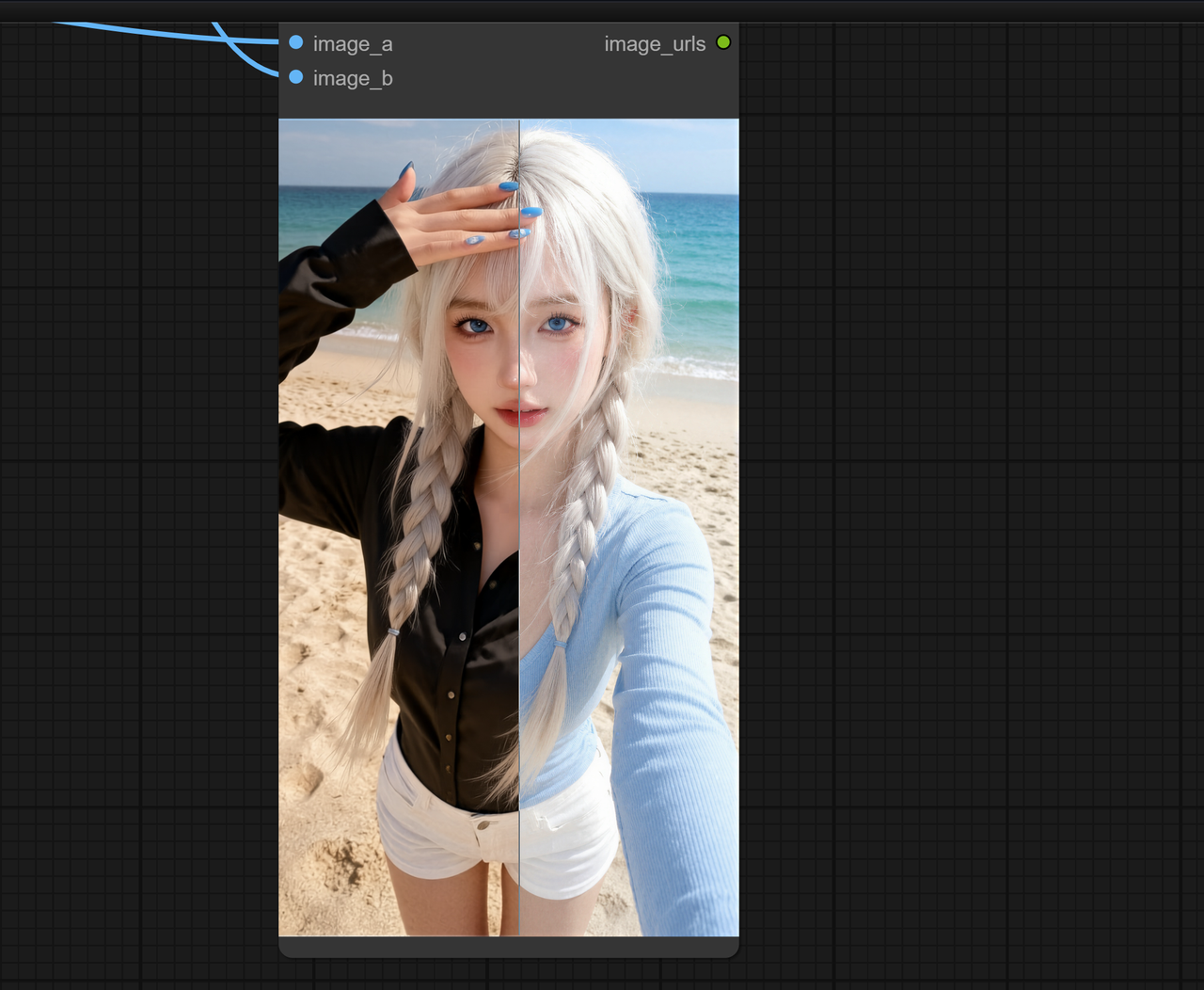
对比原图和生成图可以看到,像素偏移非常小。人物的面部特征、姿态、都几乎没有变化,只有衣服区域被精准地替换成了黑色衬衫。
本次测试的工作流我已经发布到了 RunningHub 平台,感兴趣的朋友可以直接点链接体验:https://www.runninghub.cn/post/2056611909402714114/?inviteCode=leuipuuc
六、深度思考:统一架构带来的真正改变
跑完上面这些测试,我想跳出具体的用例,聊聊这次体验下来的一些感受。
6.1 对国内多模态开源生态的意义
国内开源AI生态过去一年发展很快,但说实话,很多模型走的是"复现海外模型+堆大参数"的路子。SenseNova U1走了一条不一样的路——NEO-unify是个原创架构,直接从"理解与生成统一"这个根本问题出发重新设计。这种从0到1的架构创新,对国内AI社区的意义可能比参数竞赛更深远。国产开源模型正在从"追参数"转向"做架构",从底层重新想多模态AI该怎么做。
6.2 轻量化的务实选择
开源SenseNova U1Lite而非完整版,我觉得是个很务实的选择。
8B和A3B两个规格,消费级显卡就能部署和微调。这对开发者来说门槛低了很多,与其追求"最强模型",不如用"够用且好部署"的模型快速把业务跑通。
从SenseNova-Studio的体验来看,SenseNova U1Lite的表现挺扎实的——虽然不是每个场景都能惊艳到你,但关键时刻不会掉链子。对企业级应用来说,"稳定且实用"往往比"偶尔惊艳"更重要。
6.3 当前局限与期待
话说回来,SenseNova U1Lite也有一些"还可以更好"的地方:
- 复杂文字渲染:高密度信息图里,部分小字号文字偶尔会模糊或变形。
- 超长提示词的细节保持:图文交错生成中,提示词里图片描述段落太多时,模型偶尔会漏掉末尾的细节要求。
不过这些问题也都在情理之中,毕竟这是轻量级开源模型。后续的版本将会不断进行改进。
官方对其中的问题也已经给出了应对方案——通过提示词增强来优化生成效果,后续版本也会持续改进这些不足。

遇到上面这些问题时,可以试试官方提供的提示词增强方法:https://github.com/OpenSenseNova/SenseNova-U1/blob/main/docs/prompt_enhancement_CN.md
主要是提升生成图像的结构性、排版质量和信息密度,下面是一些优化后的效果对比。
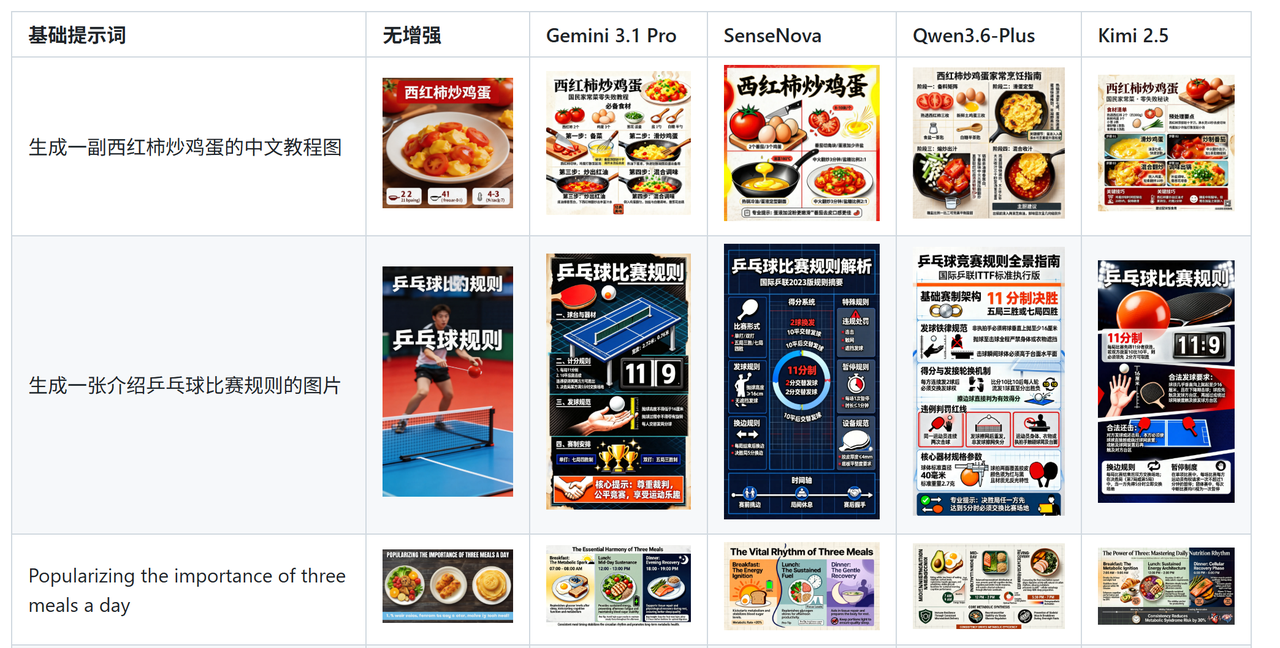
七、总结
以上就是我们的全部测试,下面我说几点实在的感受。最直接的感受是惊艳,一个8B的模型居然能把汽车制动系统这种高密度信息图画出来,各个零部件的细节都还原得挺完整。这一点已经比很多参数更多的模型要强了,SenseNova U1把理解和生成放在同一套建模体系里,它是真的先理解了内容,再去创作。
如果你是一名对多模态AI感兴趣的开发者或创作者,我建议你亲自上手体验一下——可以打开 SenseNova-Studio 在线试用,也可以直接从 GitHub 或 HuggingFace 下载模型本地部署。与其听别人描述"统一架构"有多好,不如自己跑一组测试用例,感受一下"理解即生成"的真正含义。
更多资料:
- GitHub开源仓库:https://github.com/OpenSenseNova/SenseNova-U1
- HuggingFace模型集合:https://huggingface.co/collections/sensenova/sensenova-u1
- SenseNova-Studio在线体验:https://unify.light-ai.top/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)