MRC很强,但灵衢UB更完整:AI超节点互联的两条技术路线
从多路径可靠连接,到全栈资源池化与系统级统一互联
作者: 陈卫荣 周朋 (方宜万强)
阅读导图:先抓住 4 个判

核心观点
MRC和UB不是同一层级的“协议对协议”竞争。MRC是开放Ethernet/RoCE AI Fabric在训练网络传输层的关键增强,重点提升超大训练网络的多路径利用、拥塞控制和故障绕行能力;UB则把问题上移到超节点系统,把互联协议、内存语义、事务模型、OS、虚拟化和资源池化放在同一套架构里设计。判断二者时,关键不是简单比较“谁已有落地”,而是区分验证层级:MRC的公开案例主要验证训练网络连接可靠性,UB的公开案例主要验证超节点产品化和系统级资源组织能力。
大模型训练进入十万卡时代后,算力竞争已经不只是GPU数量的竞赛。
真正决定训练效率的,是这些GPU能不能稳定、高效地协同工作。当集群从千卡、万卡走向十万卡,网络就从“基础设施”变成了“系统瓶颈”。一次链路抖动、一次交换机异常、一条拥塞路径,都可能被同步训练放大成整个任务的尾延迟。
这正是MRC出现的背景。
2026年5月,OpenAI联合AMD、Broadcom、Intel、Microsoft、NVIDIA发布MRC(Multipath Reliable Connection),并通过OCP开放规范。它针对的是一个很具体的问题:传统RoCE/RC单路径连接,难以支撑十万卡级AI训练网络对吞吐、尾延迟和故障韧性的要求。
把MRC和华为UB放在同一张图里看,最容易犯的错误,是把它们当成“协议对协议”的竞争。
MRC是开放Ethernet/RoCE AI Fabric的多路径可靠连接方案;UB是面向AI超节点的全栈互联和资源池化体系。二者处在不同层级,定位差异见图1。
MRC关注“数据怎么更稳地到达”。UB关注“计算、内存、设备和通信怎么被统一组织”。
所以,MRC更像现有以太训练网络的增强件;UB更像面向未来超节点的系统底座。如果只看现有以太训练网络的传输增强,MRC非常强;如果从系统覆盖面、资源池化和跨层语义看,UB的架构覆盖更完整。
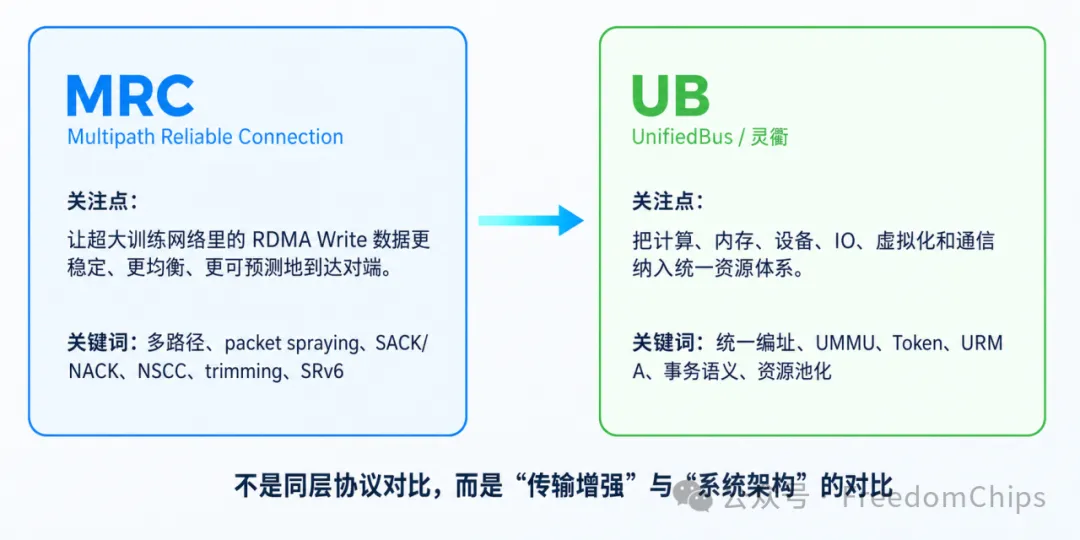
图1 两条技术路线的定位差异
一、先看 MRC:把以太训练网络从单路径推向多路径
先说结论:MRC的价值,不是把链路做得“更快”这么简单,而是让一个RDMA transfer不再被单一路径绑死。
传统RoCE/RC中,单个RDMA连接通常会被哈希到一条路径。对普通业务,这未必是核心矛盾;但对同步训练,AllReduce、All-to-All、MoE等通信高度同步,一个慢包、一条拥塞路径、一次链路flap,都可能拖慢整个训练step。
MRC的思路很直接:把同一个transfer的包分散到多个plane、多条path上,再用SACK/NACK、选择性重传、packet trimming、NSCC拥塞控制和源路由等机制兜住可靠性。
OpenAI官方博客强调,MRC的目标是在故障存在时仍提供可预测性能;OCP MRC规范也定义了ECMP Hash-based、Structured EV和SRv6等forwarding model。OpenAI还披露,MRC已部署在大型NVIDIA GB200超算、OCI Abilene和Microsoft Fairwater等环境。
- 多平面网络:例如将800G NIC拆成8×100G,连接到多个独立plane。
- 两级Clos:OpenAI官方材料提到可用两级交换连接约131,000 GPU。
- 单连接packet spraying:一个RDMA transfer的包可喷洒到数百条路径。
- SACK/NACK与选择性重传:快速发现丢包并只重传缺失包。
- packet trimming:拥塞时交换机裁剪payload,仅转发header触发显式重传。
- NSCC拥塞控制:基于网络和接收端反馈调节发送。
- 路径模型:OCP规范支持ECMP Hash-based、Structured EV和SRv6;OpenAI生产实践重点强调静态SRv6源路由。
用一句话概括:MRC把开放以太训练网络从“单路径RDMA连接”,推进到“多路径可靠连接”。这是一个非常务实、也非常重要的工程进步。
二、MRC的边界:强在传输层,不负责系统重构
但MRC不是“万能互联底座”。它很强,也很克制。
OCP MRC1.0规范说明,MRC主要支持RDMA Write和Write-with-Immediate,不支持RDMA Read、Send、Atomic。它的重点是work request spraying、SACK/NACK、NSCC、选择性重传、Trim NACK等传输机制。
这不是缺陷,而是取舍。
AI collective中大量关键数据通路本来就是写入型流量。MRC把复杂度集中在训练最关键、最高频的数据传输路径上,因此更容易兼容Ethernet、RoCE、NCCL、verbs等既有生态。
边界也因此很清楚:MRC不负责统一编址、跨节点Load/Store、内存池化、共享内存、远端内存一致性、DPU/SSU资源池化、事务语义、OS级资源管理和虚拟化池化。
换句话说,MRC解决的是AI训练网络里的连接和传输问题,不是AI超节点的系统重构问题。
三、再看UB:它的目标不是一张更强的网卡
UB的出发点明显不同。
根据《灵衢基础规范2.0.1》《灵衢使能操作系统参考设计》《灵衢系统高阶服务软件架构参考设计》《基于灵衢的超节点参考架构白皮书》,UB并不是一个单独的网卡传输协议,而是一套面向超节点的全栈互联体系。它要解决的不是某条链路、某个连接或某类报文的效率问题,而是超节点内部资源如何被统一连接、统一编址、统一访问和统一调度的问题。

表1 UB 不是单一传输协议,而是全栈超节点体系
UB SuperPoD白皮书把它总结为六个关键词:总线级互联、协议归一、平等协同、全量池化、大规模组网和高可用性。
其中比较关键的目标包括:百ns级同步内存语义访问、2~5us异步内存语义访问、组件间TB/s级带宽、从单节点扩展到8192卡,并规划提升到15488卡甚至更大,以及通过UBoE构建百万卡规模集群,兼容以太组网。这些指标解释了为什么UB更适合被理解为系统架构,而不是传输协议。对应到公开产品形态,Atlas 900 A3 SuperPoD通过灵衢高速互联支撑384卡NPU像一台计算机一样工作,CloudMatrix384也把类似超节点组织方式推进到大模型服务实践中。
这说明,UB不是要做一个“更可靠的RoCE替代品”。
它更像是在回答另一个问题:能不能把CPU、NPU/GPU、Memory、DPU、SSU、Switch等资源,组织成逻辑上的一台计算机?MRC强在传输路径、开放规范和现有生态落地,UB强在系统组织、资源池化抽象和超节点产品形态。
四、多路径:MRC优化连接,UB组织资源
多路径是二者都谈的能力,但抽象层级不同。
MRC的多路径非常聚焦:让单个RDMA connection/transfer跨多路径发包。它通过EV、Structured EV、ECMP或SRv6源路由,把包喷洒到多个plane、多条path上。某条路径异常时,端点可以停用对应路径,并通过probe判断是否恢复。
UB也具备scale-out多路径能力,但它不是只优化“一个连接”。
UB在网络层支持逐包和逐流负载均衡,传输层支持多TP Channel和TPG,事务层还可以根据ROI、ROT、ROL、UNO等模式决定是否允许乱序、多路径和保序卸载。
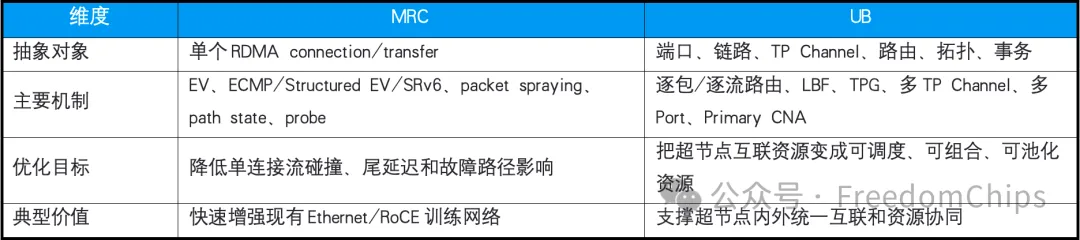
表2 多路径能力对比:MRC优化连接,UB池化互联资源
所以,MRC的多路径是连接级packet spraying;UB的多路径是端口、链路、通道、路由和拓扑的系统级资源组织。
一个让单个连接更好地使用多路径,另一个让整个超节点的互联资源成为可调度资源。
五、可靠性:MRC快速绕障,UB分层兜底
可靠性是MRC最亮眼的部分。
它在lossy Ethernet上通过SACK/NACK、选择性重传、packet trimming、EV/path状态、NSCC拥塞控制,以及ECMP/StructuredEV/SRv6等路径模型,让端点快速识别异常路径并绕开。OpenAI公开生产实践中,重点采用静态SRv6源路由。
UB的思路更像“分层兜底”:尽量在故障刚出现的层级就处理掉,而不是都推到端到端传输层。图2展示了二者在可靠性处理层级上的差异。
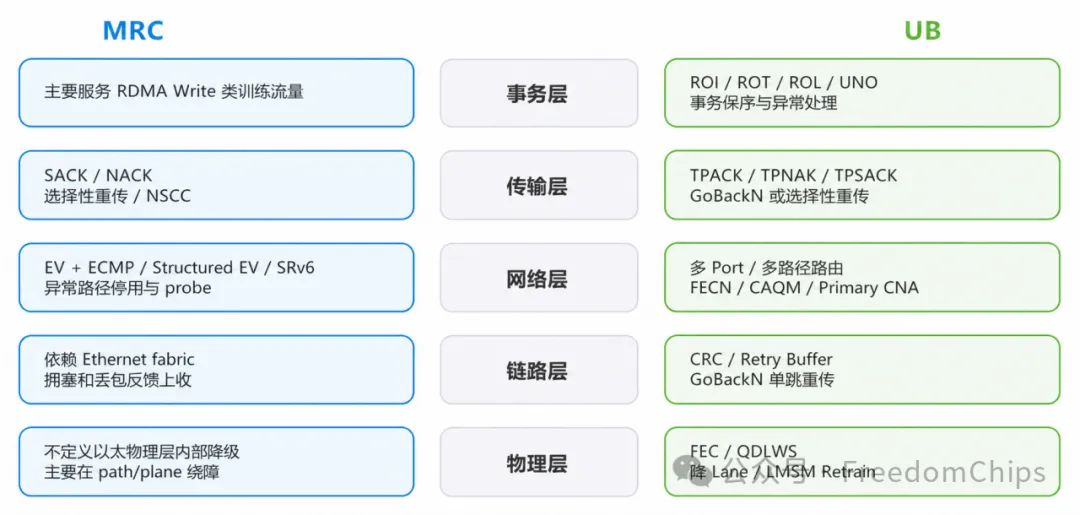
图2 可靠性机制:MRC快速绕障,UB分层兜底
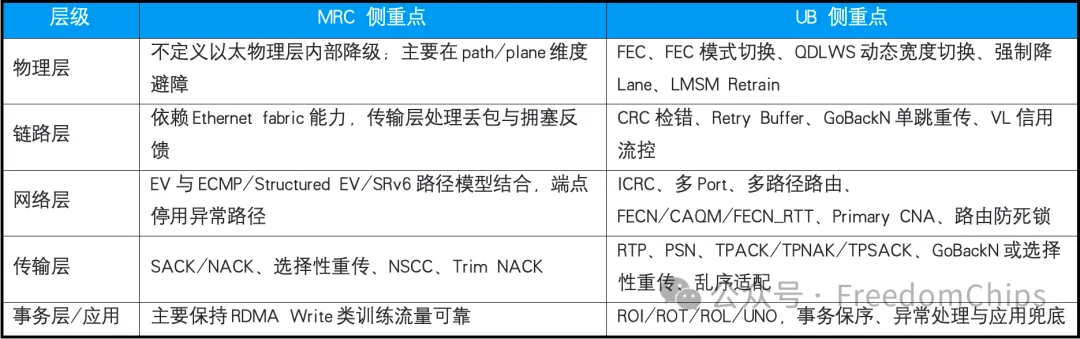
表3 可靠性分层对比:MRC端到端绕障,UB全栈分层兜底
这里UB的优势在于粒度更细、层次更多。
MRC通常在path、plane、port维度绕障;UB可以在Lane、链路、端口、路径、传输通道和事务语义多个层级处理异常。如果只是部分Lane退出传输承载,UB的降Lane机制理论上可以把影响范围控制得更小。
因此,比较可靠性时,需要把“机制覆盖范围”和“公开验证对象”分开看。
MRC的公开生产材料直接指向训练网络里的连接可靠性:多路径喷洒、异常路径绕行、拥塞反馈和选择性重传。UB的文档则展示了从Lane、链路、端口、路径、传输通道到事务语义的分层可靠性框架;Atlas 900 A3和CloudMatrix384的意义,是说明这套框架所在的超节点系统形态已经进入产品化实践。换句话说,MRC验证的是连接级可靠性路径,UB展示的是系统级可靠性框架及其产品化承载。
六、通信语义:MRC聚焦Write,UB覆盖内存与事务
如果只看多路径和重传,MRC已经很强。但真正拉开层级差异的,是通信语义。
MRC聚焦RDMA Write和Write-with-Immediate。它的目标,是让训练数据在Ethernet/RoCE网络中更可靠、更均衡、更可预测地到达对端。
UB覆盖的语义更宽:Load/Store同步访问、DMA/URMA异步访问、Read、Write、Atomic、Send、Write_with_notify、Write_with_immediate、维护事务和管理事务。
在OS参考设计中,URMA支持单边、双边、原子操作,并具备平等访问、无连接、弱事务序和多路径能力。UMDK还提供read/write、CAS、FAA等远端访问语义。
这意味着,MRC优化的是“训练数据怎么写到对端”;UB进一步关心“远端内存和设备怎么像本地资源一样被编址、访问、授权、同步和管理”。
这里的关键不是单点性能结论,而是系统语义覆盖更完整。
七、资源池化:这是UB超出MRC的部分
资源池化,是MRC和UB差异最明显的地方。
MRC不负责统一编址、内存借用、共享内存、DPU/SSU/设备池化、虚拟化池化,也不负责OS级资源调度。它的任务,是把训练网络里的关键传输路径做好。
UB则把这些问题纳入系统设计。
通过Entity、EID、UMMU、Token、UBFM、UB OS Component,UB将跨节点资源纳入统一管理。OS参考设计中的Memory Mgmt支持跨计算节点、跨设备的内存借用和共享;Communication提供URMA、UBComm和Socket兼容;Virtualization扩展qemu、vfio-ub和UMMU虚拟化,支持池化UB设备直通访问。
需要注意的是,UB的共享内存并不等同于天然硬件全一致。在节点间硬件不具备缓存一致性时,文档要求通过ownership、fence等软件机制约束并维护一致性。

表4 UB Service Core:把底层互联能力封装成集群级系统服务
这些能力对未来AI业务很关键。
长序列推理需要KV Cache扩展,MoE需要跨设备专家访问,AI Agent和多模态场景需要CPU、GPU/NPU、DPU、存储之间更高效协同。MRC解决的是训练网络的传输效率;UB解决的是AI数据中心资源组织方式。
八、工程落地:成熟度不能只按一条时间线排序
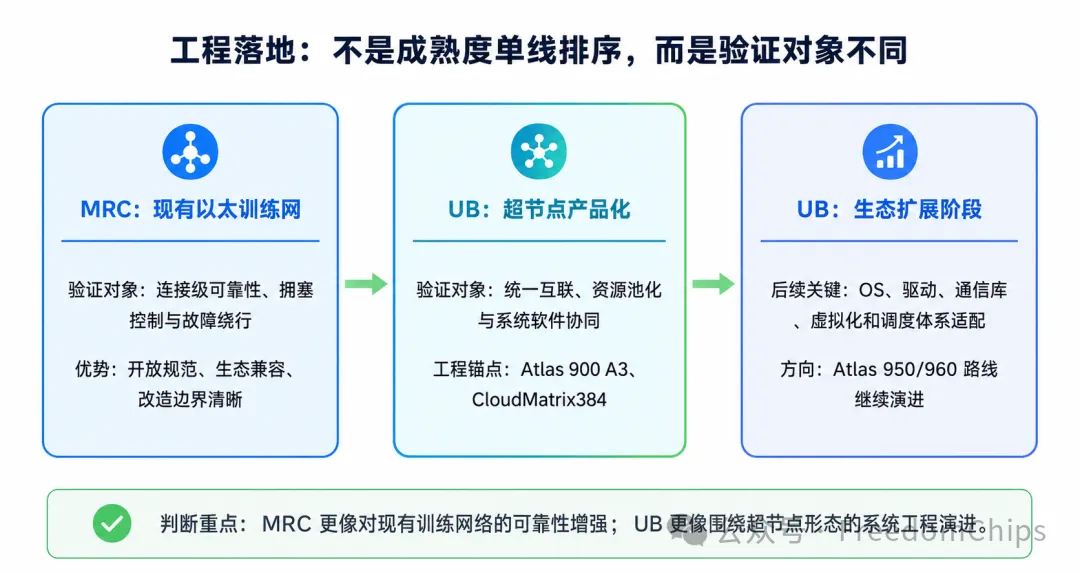
图3 工程落地:MRC和UB的验证对象不同
最后要回到工程现实。
最后要回到工程现实。但这里不宜把MRC和UB排成一条“谁更成熟”的单线时间轴。MRC的落点是现有以太训练网络:OCP开放规范,OpenAI、Microsoft、NVIDIA、AMD、Broadcom、Intel等参与,兼容Ethernet/RoCE/NCCL/verbs/SRv6生态,OpenAI披露已有大规模生产部署。对现有GPU以太训练集群来说,它的优势是升级路径清晰、改造边界明确、生态摩擦较小。
UB的落点则是超节点系统。Atlas 900 A3 SuperPoD、CloudMatrix384和Atlas950/960路线说明,UB已经有围绕超节点产品形态的公开产业化实践;它要验证的不是单个连接是否更稳,而是CPU/NPU、内存、DPU/SSU、交换和系统软件能否被组织成更完整的资源体系。
所以,UB的挑战不是从零落地,而是从特定超节点产品走向更广泛的产业生态。它需要UB Controller、UB Switch、UMMU、UBFM协同,需要OS、驱动、通信库、虚拟化栈适配,也需要应用和调度系统理解新的资源模型。这比升级一个训练网络传输机制更重,但一旦形成规模,收益也不只停留在训练网络。
这也是为什么UB的工程节奏应被理解为“系统化演进”,而不是简单的“长期概念”。
短期看,MRC在开放以太训练网络的兼容性、标准协同和部署边界上更直接;从系统级产品化和资源池化验证看,UB已经通过Atlas 900 A3、CloudMatrix384以及Atlas 950/960路线展示了更完整的超节点演进路径。二者不是一条路上的前后阶段,而是分别服务于连接增强和系统重构这两个不同层级。
结语:一个解决当下网络,一个指向未来系统
AI基础设施正在经历一个关键转折。
过去我们问的是“网络够不够快”。现在真正的问题变成了:“系统能不能作为一个整体高效协同?”
MRC的贡献,是让开放以太训练网络从单路径RDMA连接走向多路径可靠连接。它是现有生态下非常务实的工程答案。
UB的贡献,是把问题继续向上推进:不只让包更可靠地到达,而是让跨节点的计算、内存、设备、IO、虚拟化和通信都进入统一资源体系。
如果问题是:如何快速提升现有Ethernet/RoCE GPU训练集群的可靠性、吞吐和尾延迟表现?MRC是非常强的答案。
如果问题是:未来AI数据中心如何把计算、内存、设备、IO、虚拟化和通信统一组织成一个高效超节点系统?UB提供的是更高阶、更系统化的架构答案。
MRC发生在连接和训练网络层,证明现有以太训练网络可以通过多路径可靠连接获得更好的韧性;
UB让系统更像一台计算机,在系统覆盖面和资源池化抽象上更完整。同时,资源池化、统一互联和系统软件协同可以被产品化承载。
未来AI高速互联的竞争,不会只停留在“谁的链路更快、谁的重传更好”。
真正的竞争,会走向更深层的系统架构:谁能把算力、内存、网络、存储和软件栈组织成一个更高效的整体,谁就更接近下一代AI数据中心的答案。
参考资料
- OpenAI官方博客
- Supercomputer networking to accelerate large scale AI training,
https://openai.com/index/mrc-supercomputer-networking/
- Supercomputer networking to accelerate large scale AI training,
- OCP
- Multipath Reliable Connection Specification 1.0,
https://www.opencompute.org/documents/ocp-mrc-1-0-pdf
- Multipath Reliable Connection Specification 1.0,
- 论文
- Resilient AI Supercomputer Networking using MRC and SRv6,
https://arxiv.org/abs/2605.04333 - Serving Large Language Models on Huawei Cloud Matrix384,
https://arxiv.org/abs/2506.12708
- Resilient AI Supercomputer Networking using MRC and SRv6,
- 华为官方
- Groundbreaking SuperPoD Interconnect:Leading a New Paradigm for AI Infrastructure, https://www.huawei.com/en/news/2025/9/hc-xu-keynote-speech
- Huawei Launches Open-Access SuperPoD Architecture for All-Scenario Computing, https://www.huawei.com/en/news/2025/9/hc-superpod-innovation
- Huawei's SuperPoD Portfolio Creates New Option for Global Computing at MWC Barcelona2026, https://www.huawei.com/en/news/2026/3/mwc-superpod-computing
- 华为企业业务
- Atlas 900 A3 SuperPoD,
https://e.huawei.com/cn/products/computing/ascend/atlas-900-a3-superpod
- Atlas 900 A3 SuperPoD,
- 《灵衢基础规范2.0.1》
- 《灵衢使能操作系统参考设计》
- 《灵衢系统高阶服务软件架构参考设计》
- 《基于灵衢的超节点参考架构白皮书》
----
了解更多资讯,关注方宜万强


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)