收藏必备!小白程序员轻松入门大模型Agent(附7天实战路径)
本文指出,学习大模型Agent的关键在于掌握harness工程而非简单的API调用和prompt编写。harness是围绕模型的一整套工程外壳,包括循环、工具、记忆、通道等。文章以实习生比喻,说明同样智能的模型在不同harness下表现迥异。作者提出harness的七层结构,建议新手先掌握模型层、循环层和工具层。文章还提供7天实战路径,帮助新手搭建一个实用的Agent,并强调反馈密集型项目的特点,建议先跑后优,避免过早追求复杂架构。
大部分Agent教程,第一节课都在教你"怎么调LLM API"、“怎么写prompt”、“怎么function calling”。
这是教错地方了。
调API是5行代码的事。写prompt是LLM自己就能教你的事。function calling文档官网就有。这些都不难,也不是搭Agent真正卡住人的地方。
真正卡住人的,是一件大多数教程根本没提过的事——harness工程。
harness是什么?先用一个比喻讲透
harness这个词,直译是"马具、挽具",就是套在马身上让你能驾驭它干活的那套皮带、嚼子、缰绳。在AI Agent圈,它指的是围绕模型的那一整圈工程外壳——loop、tools、memory、channels、cron、permission、sandbox、provider抽象层。
Andrej Karpathy说过一句很到位的话:“Agency comes from the model. The harness makes agency real.”(智能来自模型,harness让智能落地。)你买的Claude/GPT订阅是引擎,harness是车架、变速箱、方向盘、油门刹车。光有引擎你只能盯着它转,套上harness它才能拉你去任何地方。
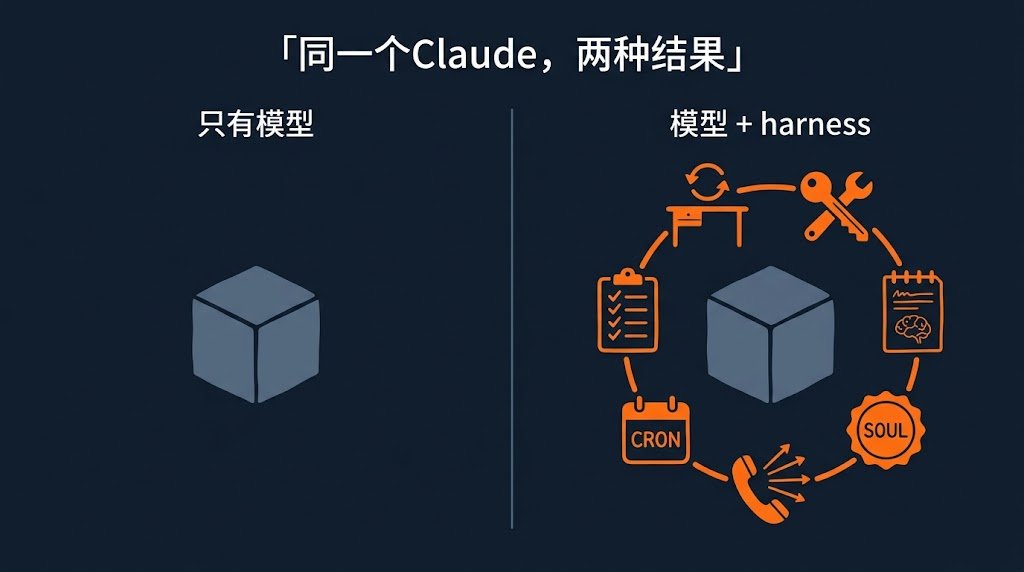
把Agent想成一只新来的实习生。
 ]()
]()
模型本身(Claude/GPT-5/DeepSeek)相当于这个实习生的智商。智商在哪个公司都一样——他记性好不好、推理强不强,是天生的。
但同一个智商的实习生,在A公司一周搞瘫一个项目,在B公司一个月独立带项目跑——区别在哪?
区别在公司给他配的工具:
- 是不是有工位(loop):他有没有一个稳定的"上班"状态,每天来、每天走、每天能继续昨天的事
- 是不是有权限(tools):他能不能开公司邮箱、查内部数据库、订机票
- 是不是有记事本(memory):他记不记得"上周这个客户已经被王哥跟了"
- 是不是有名片(SOUL):他对外是不是稳定的"我们公司的人",而不是今天像销售、明天像客服
- 是不是有手机(channels):客户能不能在微信、飞书、邮件任意一个地方找到他
- 是不是有日程表(cron):他能不能自己安排"明天早上9点提醒我开会"
- 是不是有审批流程(permission):他能不能自己花10万块?还是必须先报备?
这一整套东西就是harness。 同样一个Claude模型,套上一套好harness,就是你每天都在用的系统;不套harness,就只是个聊天窗口。
你不会训练模型没关系,你也不需要训练模型。模型是Anthropic/OpenAI帮你养好的。你要做的,是给这个已经很聪明的实习生配一套合身的harness。
harness的七层(小白只需要先搞前三层)
我把harness拆成七层,从底到顶: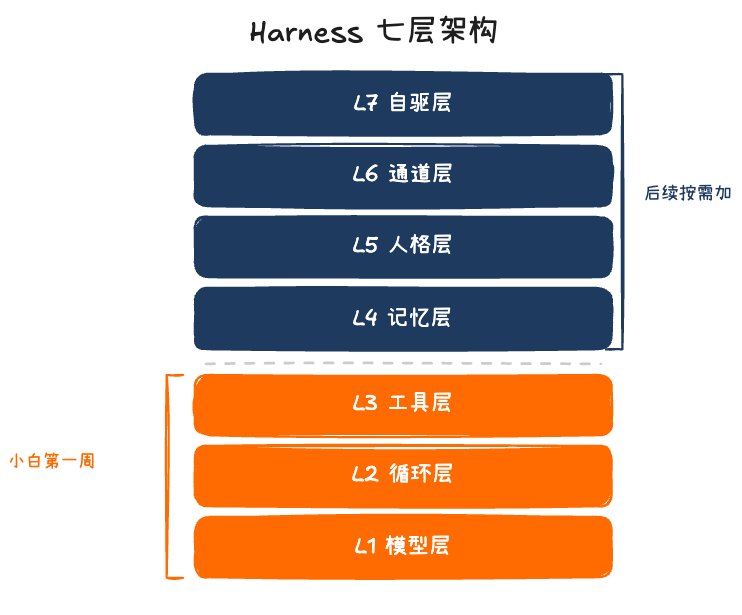
L7 自驱层(heartbeat/cron)── 让Agent自己找活干
L6 通道层(IM/Web/邮件)── 让Agent在你日常入口里
L5 人格层(SOUL.md)────── 让Agent跨模型不漂移
L4 记忆层(JSONL/向量)── 让Agent记得昨天发生了什么
L3 工具层(tools/skills)── 让Agent真的能干活
L2 循环层(agent loop)── 让Agent能持续工作
L1 模型层(provider抽象)── 让Agent不绑死任何一家
好消息是:小白第一周只需要把L1+L2+L3跑通。 L4–L7等你真的开始用、真的有需求了再加。一开始就想搭七层是新手最大的陷阱。
L1 模型层:永远写provider抽象
今天用Claude,明天OpenAI出GPT-6你想换,后天某家API涨价你想切到DeepSeek。如果代码里到处写死anthropic.messages.create(...),每次切换都是地狱。
最佳实践:所有LLM调用过一个统一的call_model(messages, tools)函数,具体哪家由配置文件决定。新手做法:找一个内置multi-provider的Agent基座,就直接送你这一层。
L2 循环层:一个while + 一个stop_reason
单次问答只能干一步事,Agent之所以是Agent,就是因为它能"想一下→动一下→看结果→再想一下"。核心循环就这么短:
while True:
response = call_model(messages, tools)
if response.stop_reason == "end_turn":
break
if response.stop_reason == "tool_use":
result = run_tool(response.tool_call)
messages.append(result)
continue
所有看起来很玄乎的ReAct、Plan-and-Execute、Reflexion,说到底都是这个循环加点装饰。新手能在自己项目里指着agent loop说"就是这一段",你已经超过80%写过Agent的人了。
L3 工具层:dispatch表 + 默认沙箱
让Agent不只能聊天,还能搜网页、读文件、改代码、发消息。两个最佳实践:
第一,用dispatch表,不要用if-elif长链。每个工具是一个{name, description, schema, handler}的字典,注册到一张表里,新增工具是加一行,不是改一坨。
第二,高风险工具默认走沙箱或者审批。读文件OK,写文件最好限定在某个工作目录,删文件、发邮件、调外部API这种应该走"先dry-run给你看一眼,你点头才执行"的流程。这是新手最容易出事的一层——千万别给一个刚跑通的Agent直接rm -rf权限。
L4–L7 先不用管
记忆层:第一版用sessions/{user_id}.jsonl,每次对话末尾追加一条,下次启动读最近N条塞回context,能解决90%的需求。Pinecone、Weaviate这些向量库都很好,但新手过早引入带来的复杂度会让迭代速度立刻降一半。
人格层:写一个SOUL.md文件,定义Agent的人格、说话风格、价值观。每次调模型时把它注入system prompt的第一段。模型切换之后回答风格的稳定性立刻上一个档次。
通道层和自驱层:等你真的在用Agent了再加。
7天最小可用harness的实战路径
目标是7天后你有一个真的能用、真的进入你日常的Agent。不是demo,是工具。
Day 1:准备 + 选基座
装Claude Code(npm install -g @anthropic-ai/claude-code)。注册Anthropic账号,订阅Pro或者去console.anthropic.com拿API Key。
挑一个Agent基座,给小白推荐两个:
- Nanobot(github.com/HKUDS/nanobot):内置multi-provider、memory、skills、IM通道,直接送你L1+L4+L6,新手最省心
- pi-mono(github.com/badlogic/pi-mono):极简风格,几百行能看懂全部,适合想从底层理解的程序员
不会写Python的选Nanobot。
Day 2:跑通安装
把基座的GitHub链接直接丢给Claude Code:“请帮我把这个项目fork到本地,安装好,要求能正常运行。一步步告诉我每一步要做什么,遇到报错继续帮我排查。”
⚠️ API Key安全提醒:永远不要直接在命令行里贴API Key。命令行会留history,截图、屏幕分享都可能泄露。让Claude Code告诉你"应该写在哪个文件、什么格式"(通常是.env),自己用编辑器手动填。
Day 3:接通第一个IM通道
海外用Telegram最快:找@BotFather发/newbot,给bot起名字,拿到Token填进nanobot配置文件,5分钟搞定。
国内用飞书:去open.feishu.cn/app创建企业自建应用,启用"机器人"能力,申请im:message等权限。事件订阅一定要选"长连接模式"——不需要公网IP、不用配webhook。最后一步——点"版本管理与发布"把应用真的发版,不发版权限不生效。这是90%新手卡住的地方。
Day 4:建脚手架文件
不要急着加新功能。今天花一小时建脚手架文件——它是后面所有迭代速度的地基。
项目根建一个CLAUDE.md(< 200行)。里面写四块:WHAT(项目一句话讲清)、WHY(哪些设计选择不能动)、HOW(怎么build、怎么test)、个人偏好(用中文回复/commit前先问)。
再建一个SOUL.md:定义Agent的人格。这是L5的全部——一个文件,几百字,模型切换之后风格不漂移。
Day 5:加第一个真的有用的功能
关键的反直觉点:不要从"我想要什么"开始,要从"我每天最烦的一件事"开始。
“我想要它能联网搜索”——错。这是大模型客户端都有的功能。“我每天早上要花20分钟看GitHub trending、Hacker News和X的AI推文”——对。这是你的真实痛点,自动化它一次性省回30小时。
挑一个,然后跟Claude Code进入plan mode(按Shift+Tab或者输入/plan),告诉它你的需求,让它反复追问你直到把触发方式、抓取范围、推送格式、失败处理都问清楚,最后写到docs/spec.md。
Plan mode是Claude Code内置的"只规划不写代码"模式。它会一轮轮问你,问到你自己脑子里都没想清楚的细节。花30分钟brainstorm,能省后面两周的乱改。这是整套流程里性价比最高的一步。
Day 6:让它真的进入你的日常
今天的目标不是写代码,是用。把昨天加的功能跑起来,连续用一整天。关键是发现两类问题:它哪里做错了,以及它哪里做对了你没想到。
Day 7:开始建第二个能力,并复盘
到这一天,你已经有一个跑得通、每天在用的Agent了。这本身已经超过95%看过Agent教程的人——他们停在了demo,你已经进了生产。
新手最常见的四个误判
误判一:先选最强的模型。 错。模型差异在Agent工程里其实很小——同一套harness套Claude Sonnet 4.5和GPT-5,体验差异远小于你套了好harness和坏harness的差异。先把harness搭好,模型这一层后面5分钟就能换。
误判二:先想清楚架构再动手。 错。Agent是一个反馈密集型项目,你想清楚的80%在你真用起来后会被推翻。先丑后美,先跑后优。
误判三:找最好的框架。 错。LangChain的抽象是为了支持上百种LLM、上百种向量库,对你一个人完全是冗余。轻量基座 + 自己长的能力 = 长期最舒服。
误判四:上来就追多模型/多通道/多功能。 错。一个模型 + 一个通道 + 一个真的有用的功能,跑顺一个月,你学到的东西比横跨5个模型的人多10倍。
经常有人问我:“我不会写代码,搭Agent是不是太难了?”
我的回答每次都一样:搭Agent不是写代码,是搭harness。模型的智能不是你能造的,但harness是。说到底这是工程审美——什么放哪一层、什么用配置、什么用代码、什么先做、什么后做。跟你会不会Python关系不大,跟你愿不愿意每天跟它对话、每天调一调有关。
"Agent"这个词不神秘。它就是一个套了harness的LLM。
七天后,你会有一个真的进入你日常的工具。不是demo,是工具。
最后
2026年技术圈的分化愈发明显:降薪裁员潮持续蔓延,传统开发、测试等岗位大批缩水,不少从业者陷入职业焦虑;与之形成鲜明对比的是,AI大模型相关岗位迎来疯狂扩招,薪资逆势飙升150%,大厂更是直接开出70-100W年薪,疯抢具备实战能力的大模型人才,甚至放宽年龄限制,只求能快速落地技术、创造价值!
很多程序员、职场新人纷纷入局大模型领域,绝非盲目跟风,而是实实在在看到了不可替代的价值优势,这也是2026年最值得抓住的职业风口:
1、窗口期红利,入门门槛友好:不同于成熟赛道的“内卷式招聘”,2026年大模型人才缺口巨大,简历只要达标(掌握基础AI应用+具备简单项目经验),年龄、学历均非硬性要求,小白可快速入门,转行程序员也能无缝衔接;
2、技术可复用,上手速度翻倍:如果你有前后端开发、测试、数据分析等基础,在大模型落地、系统部署、Prompt工程等环节会更具优势,无需从零开始,复用原有技术能力就能快速进阶;
3、懂业务更吃香,竞争力翻倍:单纯懂技术已不够,2026年大厂更看重“技术+业务”的复合型人才,有垂直领域(金融、医疗、工业等)经验者,能精准定位模型落地痛点,薪资比纯技术岗高出30%以上;
更重要的是,即便没有转型需求,用AI大模型工具为工作赋能、提升效率,也已经成为80%企业的硬性要求——不会用大模型提效,未来很可能被行业淘汰!
那么2026年,小白/程序员该如何高效学习大模型?
很多人想入门大模型,却陷入两大困境:要么到处搜集零散资料,不成体系,越学越懵;要么被收费高昂的课程割韭菜,花了钱却学不到实战技能,白白浪费时间走弯路。
今天就给大家精心整理了一份2026年最新、免费、系统化的AI大模型学习资源包,覆盖从零基础入门到商业实战、从理论沉淀到面试通关的全流程,所有资料均已整理归档,无需拼凑,直接领取就能上手学习,小白可照做,程序员可进阶!

👇👇扫码免费领取全部内容👇👇

1、大模型系统化学习路线
这份学习路线结合2026年行业趋势和新手学习规律,由行业专家精心设计,从零基础到精通,每一步都有明确指引,帮你节省80%的无效学习时间,少走弯路、高效进阶,避免踩坑。
2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、大模型学习书籍&电子文档
涵盖2026年最新技术要点,包括基础入门、Transformer核心原理、Prompt工程、RAG实战、模型微调与部署等内容

4、AI大模型最新行业报告
报告包含腾讯、阿里、甲子光年等权威机构发布的核心内容,还有2026年中文大模型基准测评报告、AI Agent行业研究报告等,帮你站在行业前沿,把握技术风口。

5、大模型项目实战&配套源码
项目包含Deepseek R1、GPT项目、MCP项目、RAG实战等热门方向,还有视频配套代码,手把手教你从0到1完成项目开发,既能练手提升技术,又能丰富简历,为求职和职业发展加分。

6、2026大模型大厂面试真题
2026年大模型面试已全面升级,不再单纯考察基础原理,而是转向侧重技术落地和业务结合的综合考察,很多程序员和新手因为缺乏针对性准备,明明技术不错,却在面试中失利。

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
7、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献255条内容
已为社区贡献255条内容

所有评论(0)