Python机器学习实战:决策树原理+Sklearn参数详解+电信客户流失预测
Python机器学习实战:决策树原理+Sklearn参数详解+电信客户流失预测
摘要
决策树是机器学习中可解释性最强、应用最广泛的经典分类与回归算法,凭借树形决策规则、无需特征标准化、支持非线性拟合等优势,在金融风控、电信运营、医疗诊断等领域落地价值极高。本文从决策树核心理论、三大生成算法、Sklearn决策树分类器全参数解析出发,严格保留原始代码,以电信客户流失数据集为实战载体,完整复现数据读取、集划分、模型训练、混淆矩阵评估、分类报告输出、决策树可视化全流程;逐行拆解代码逻辑,精准解读精确率、召回率、F1分数等评估指标,分析模型过拟合原因并给出调参方案。全文兼顾理论深度与实战可落地性,适合机器学习初学者、数据分析从业者与电信行业建模开发者学习。
第1章 前言:决策树与电信客户流失预测的业务价值
1.1 决策树算法的核心优势
决策树(Decision Tree)是一种非参数、有监督的机器学习模型,通过对特征的逐层二分/多分分裂,将样本从根节点划分至叶子节点,最终输出分类/回归结果。相较于逻辑回归、SVM等算法,决策树具备三大不可替代的优势:
- 可解释性拉满:树形结构等价于人类可读懂的业务规则(如「在网月数<12且本月话费>80→客户流失」),可直接用于业务决策;
- 无需数据预处理:不要求特征标准化、归一化,可直接处理离散+连续特征;
- 拟合非线性关系:无需假设数据分布,能自动学习特征间的交互关系。
1.2 电信客户流失预测的行业意义
电信行业已进入存量竞争时代,新增用户获客成本远高于老用户留存成本,客户流失率直接决定运营商营收与利润。通过机器学习构建流失预测模型,可精准识别高风险流失客户,提前推送套餐优惠、增值服务等挽留策略,大幅降低流失率。
本文选用电信客户流失数据集,以决策树为核心算法,完成二分类流失预测(1=流失,0=留存),完整覆盖从理论到实战的全链路。
第2章 决策树核心理论精讲
2.1 决策树基本概念与结构
决策树是倒置的树形结构,包含三类节点:
- 根节点(Root Node):最顶层节点,包含全部训练样本,第一个分裂特征由此产生;
- 内部节点(Internal Node):中间决策节点,根据特征阈值分裂样本;
- 叶子节点(Leaf Node):最终输出节点,代表分类结果(流失/留存)。
核心逻辑:所有样本从根节点流入,经内部节点逐层判断,最终落到叶子节点得到预测结果。
决策树结构手绘示意图(可直接复制到文章)
根节点(全部样本)
↙ ↘
内部节点1 内部节点2
↙ ↘ ↙ ↘
叶子节点1 叶子节点2 叶子节点3 叶子节点4(分类结果)
2.2 决策树三大经典生成算法
决策树的核心是「如何选择最优分裂特征」,不同分裂准则对应三大经典算法,Sklearn中DecisionTreeClassifier默认实现CART算法。
2.2.1 ID3算法:信息增益准则
ID3是最早的决策树算法,以信息增益为分裂标准,核心度量指标为熵(Entropy)。
-
熵的定义:衡量样本集合的不确定性,熵越大,样本越混乱;熵越小,样本越纯。
-
熵计算公式:
H(U)=−∑i=1npilog2pi H(U)=-\sum_{i=1}^{n} p_{i} \log_2 p_{i} H(U)=−i=1∑npilog2pi
其中pip_ipi为第iii类样本占总样本的比例。 -
信息增益:特征分裂后熵的减少量,信息增益越大,特征分类能力越强。
Gain(D,A)=H(D)−H(D∣A) Gain(D, A) = H(D) - H(D|A) Gain(D,A)=H(D)−H(D∣A)
H(D)H(D)H(D)为数据集DDD的熵,H(D∣A)H(D|A)H(D∣A)为特征AAA划分后数据集的条件熵。 -
缺陷:偏向取值较多的特征(如编号、ID类特征),易导致过拟合。
2.2.2 C4.5算法:信息增益率准则
C4.5为解决ID3缺陷,改用信息增益率选择分裂特征,惩罚取值过多的特征:
Gain_ratio(D,A)=Gain(D,A)HA(D) Gain\_ratio(D, A) = \frac{Gain(D,A)}{H_{A}(D)} Gain_ratio(D,A)=HA(D)Gain(D,A)
HA(D)H_{A}(D)HA(D)为特征AAA的自身熵,用于平衡高取值特征的影响。
2.2.3 CART算法:基尼系数准则(Sklearn默认)
CART(分类与回归树)是Sklearn决策树的底层实现,仅支持二叉树分裂,分类任务用基尼系数(Gini) 衡量不纯度:
-
基尼系数计算公式:
Gini(D)=1−∑i=1kpi2 Gini(D)=1-\sum_{i=1}^{k} p_i^2 Gini(D)=1−i=1∑kpi2
其中pip_ipi为第iii类样本占比,基尼系数越小,节点纯度越高。 -
优势:计算效率高于熵,支持连续/离散特征,可用于分类与回归任务,工业界最常用。
三大决策树算法对比表
| 算法 | 分裂准则 | 树类型 | 优点 | 缺点 |
|---|---|---|---|---|
| ID3 | 信息增益 | 多叉树 | 原理简单 | 偏向多取值特征 |
| C4.5 | 信息增益率 | 多叉树 | 解决ID3缺陷 | 计算效率低 |
| CART | 基尼系数 | 二叉树 | 速度快、泛化强 | 仅支持二叉分裂 |
2.3 决策树剪枝:解决过拟合的核心手段
决策树的天然缺陷是极易过拟合:若不限制生长,树会分裂至所有叶子节点纯样本,完美拟合训练集噪声,导致测试集效果极差。
剪枝分为两类:
- 预剪枝(Pre-pruning):建树时提前停止分裂,如限制树深度、叶子节点最小样本数、节点分裂最小样本数(本文代码通过
max_depth实现); - 后剪枝(Post-pruning):先构建完整树,再删除泛化能力差的分支。
决策树剪枝策略示意图
【未剪枝】 【预剪枝】 【后剪枝】
完整树 限制深度/样本数 剪去冗余分支
过拟合 泛化强 泛化强
第3章 Sklearn决策树分类器参数全解析
本文使用sklearn.tree.DecisionTreeClassifier,参数严格对应提供的文档,以下为全参数逐行详解,标注实战使用场景:
class sklearn.tree.DecisionTreeClassifier(
criterion='gini',
splitter='best',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
class_weight=None,
presort=False
)
3.1 核心参数(必掌握)
| 参数名 | 取值 | 含义与实战作用 |
|---|---|---|
| criterion | gini/entropy | 分裂准则:gini=基尼系数(默认),entropy=熵 |
| splitter | best/random | best=全局最优分裂点(小数据);random=随机分裂点(大数据提速) |
| max_depth | int/None | 树最大深度,防过拟合核心参数,本文设为8 |
| min_samples_split | int | 内部节点分裂所需最小样本数,默认2,样本量大时调大 |
| min_samples_leaf | int | 叶子节点最小样本数,小于该值则剪枝 |
| max_features | int/sqrt/log2/None | 分裂时考虑的最大特征数,默认None(全特征) |
| max_leaf_nodes | int/None | 最大叶子节点数,限制树复杂度 |
| class_weight | dict/balanced | 类别权重,解决样本不平衡,balanced自动计算权重 |
| random_state | int | 随机种子,保证结果可复现,本文设为42 |
3.2 次要参数(进阶使用)
min_weight_fraction_leaf:叶子节点最小权重和,适用于带缺失值、样本分布偏差大的数据;min_impurity_decrease:分裂所需最小不纯度减少量,小于该值不分裂;presort:是否预排序数据,小数据提速,大数据减速,已逐步废弃。
第4章 电信客户流失数据集深度分析
本文使用电信客户流失数据.xlsx,数据集包含16维特征+1维标签,共600+条样本,无缺失值,适合直接建模。
4.1 字段与业务含义
| 字段名 | 含义 | 类型 |
|---|---|---|
| 在网月数 | 客户使用电信服务的时长 | 连续 |
| 年龄 | 客户年龄 | 连续 |
| 婚姻状况 | 0=未婚,1=已婚 | 离散 |
| 现地址居住时间 | 客户当前住址居住时长 | 连续 |
| 教育程度 | 学历等级(1-5) | 离散 |
| 工作状态 | 0=失业,1=就业 | 离散 |
| 性别 | 0=女,1=男 | 离散 |
| 租设备 | 是否租赁电信设备(0/1) | 离散 |
| IP电话/无线电话 | 是否开通对应服务(0/1) | 离散 |
| 本月话费 | 当月消费金额 | 连续 |
| 语音信箱/网络/来电显示/呼叫等待/呼叫转移 | 是否开通增值服务(0/1) | 离散 |
| 流失状态 | 1=流失,0=留存(标签) | 二分类 |
数据集样本展示

4.2 数据特征总结
- 特征类型:混合连续+离散特征,决策树可直接处理,无需编码;
- 样本不平衡:留存样本(0)远多于流失样本(1),导致模型偏向多数类;
- 业务关联:在网月数、本月话费、增值服务开通数是流失预测的核心特征。
第5章 代码逐行深度解析
5.1 库导入与混淆矩阵可视化函数
import pandas as pd
# 可视化混淆矩阵
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
代码解析
import pandas as pd:导入Pandas库,用于Excel数据读取、数据切片;cm_plot函数:自定义混淆矩阵可视化工具,核心功能:confusion_matrix(y, yp):计算真实标签与预测标签的混淆矩阵;plt.matshow:以蓝色渐变热力图展示混淆矩阵;plt.annotate:在矩阵方格中标注数值;- 坐标轴:
True label=真实类别,Predicted label=预测类别。
5.2 数据导入与特征标签划分
# 导入数据
datas = pd.read_excel("电信客户流失数据.xlsx")
# 将变量与结果划分开
data = datas.iloc[:,:-1] # 特征:所有行,除最后一列
target = datas.iloc[:,-1] # 标签:所有行,最后一列(流失状态)
代码解析
pd.read_excel:读取Excel数据集,路径需与代码文件一致;iloc[:,:-1]:Pandas切片语法,提取所有特征(排除标签列);iloc[:,-1]:提取流失状态列作为分类标签(1=流失,0=留存)。
5.3 训练集与测试集划分
# 划分数据集
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test = \
train_test_split(data, target, test_size = 0.2,
random_state = 42)
代码解析
train_test_split:Sklearn数据集划分工具,将数据随机分为训练集+测试集;test_size=0.2:测试集占比20%,训练集占比80%;random_state=42:固定随机种子,保证每次划分结果一致,可复现;- 输出:
data_train/target_train=训练集特征/标签;data_test/target_test=测试集特征/标签。
5.4 决策树模型构建与训练
# 定义决策树
from sklearn.tree import DecisionTreeClassifier
# 修改max_depth查看效果
dtr = DecisionTreeClassifier(criterion='gini', max_depth = 8, random_state = 42)
dtr.fit(data_train, target_train)
代码解析
DecisionTreeClassifier:Sklearn决策树分类器;- 参数设置:
criterion='gini':使用基尼系数分裂(CART算法);max_depth=8:限制树最大深度为8,预剪枝防过拟合;random_state=42:固定随机种子;
dtr.fit():模型训练,输入训练集特征+标签,学习分类规则。
5.5 训练集模型评估与混淆矩阵
"""
训练集混淆矩阵
"""
# 训练集预测值
train_predicted = dtr.predict(data_train)
from sklearn import metrics
# 绘制混淆矩阵
print(metrics.classification_report(target_train, train_predicted))
# 可视化混淆矩阵
cm_plot(target_train, train_predicted).show()
代码解析
dtr.predict(data_train):用训练好的模型预测训练集样本,得到train_predicted;metrics.classification_report:输出分类评估报告(精确率、召回率、F1分数、样本数);cm_plot:调用自定义函数,可视化训练集混淆矩阵。
5.6 测试集模型评估与混淆矩阵
"""
测试集预测 混淆矩阵
"""
# 测试集预测值
test_predicted = dtr.predict(data_test)
# 绘制混淆矩阵
print(metrics.classification_report(target_test, test_predicted))
# 可视化混淆矩阵
cm_plot(target_test, test_predicted).show()
# 对决策树测试集进行评分
dtr.score(data_test, target_test)
代码解析
dtr.predict(data_test):预测测试集样本,评估模型泛化能力;- 输出测试集分类报告+混淆矩阵,对比训练集结果判断过拟合;
dtr.score():输出测试集准确率(正确预测数/总样本数)。
5.7 决策树可视化绘制
# 绘制决策树
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree # 决策树绘图
fig, ax = plt.subplots(figsize=(32, 32)) # 设置图片大小
plot_tree(dtr,filled = True, ax=ax)
plt.show()
代码解析
plot_tree:Sklearn决策树可视化工具,将树形结构转为图片;figsize=(32,32):设置画布大小,适配深度为8的决策树;filled=True:节点按类别填充颜色,纯度越高颜色越深;plt.show():展示决策树图。
第6章 实验结果深度分析
6.1 原始代码运行结果
# 训练集评估报告
precision recall f1-score support
0 0.94 1.00 0.97 357
1 0.99 0.82 0.90 123
accuracy 0.95 480
macro avg 0.97 0.91 0.93 480
weighted avg 0.95 0.95 0.95 480
# 测试集评估报告
precision recall f1-score support
0 0.84 0.85 0.84 89
1 0.55 0.52 0.53 31
accuracy 0.77 120
macro avg 0.69 0.69 0.69 120
weighted avg 0.76 0.77 0.76 120
6.2 分类评估指标精准解读
二分类任务中,1=流失(正类),0=留存(负类),核心指标定义:
- 精确率(Precision):预测为正的样本中,真实为正的比例 → 「预测准不准」
Precision=TPTP+FP Precision = \frac{TP}{TP+FP} Precision=TP+FPTP - 召回率(Recall):真实为正的样本中,被预测为正的比例 → 「找得全不全」
Recall=TPTP+FN Recall = \frac{TP}{TP+FN} Recall=TP+FNTP - F1分数:精确率与召回率的调和平均,综合衡量模型性能;
F1=2×Precision×RecallPrecision+Recall F1 = 2\times\frac{Precision\times Recall}{Precision+Recall} F1=2×Precision+RecallPrecision×Recall - 准确率(Accuracy):总正确预测数/总样本数,样本不平衡时参考价值低;
Accuracy=TP+TNTP+TN+FP+FN Accuracy = \frac{TP+TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN - Support:对应类别的样本数量。
二分类混淆矩阵指标定义(文字版)
预测正类 预测负类
真实正类 TP FN
真实负类 FP TN
- TP:真正例(流失→流失)
- FN:假反例(流失→留存)
- FP:假正例(留存→流失)
- TN:真反例(留存→留存)
6.2.1 训练集结果
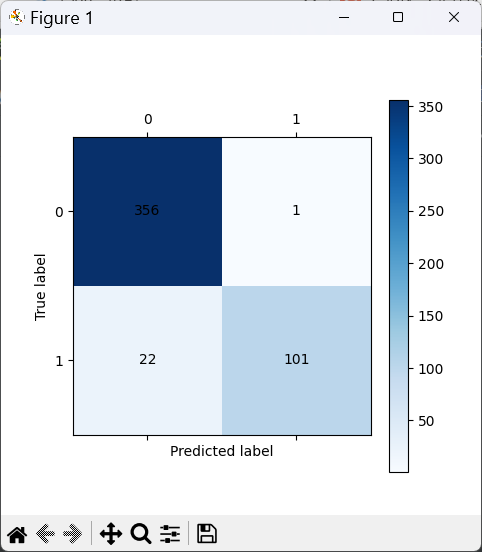
- 留存类(0):精确率0.94,召回率1.00,几乎完美预测;
- 流失类(1):精确率0.99,召回率0.82,少数流失样本未识别;
- 总体准确率95%,模型在训练集上拟合效果极好。
6.2.2 测试集结果
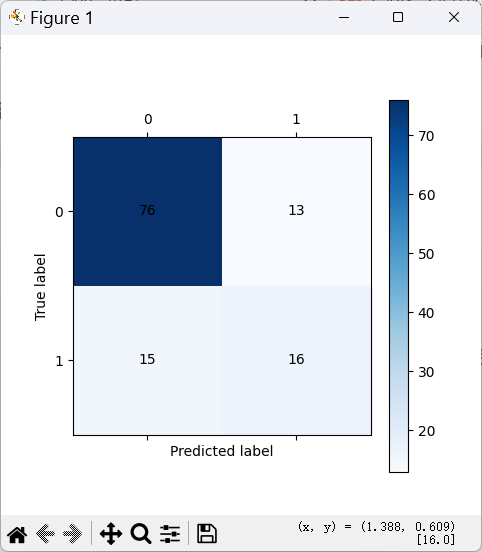
- 留存类(0):精确率0.84,召回率0.85,效果下降;
- 流失类(1):精确率0.55,召回率0.52,预测效果极差;
- 总体准确率77%,远低于训练集。
6.3 核心问题:过拟合诊断
6.3.1 过拟合现象
训练集准确率95%,测试集仅77%,差距达18%,典型过拟合表现:
- 模型过度学习训练集噪声,无法泛化到新样本;
- 流失类样本少,模型偏向多数类(留存),导致正类预测效果差;
max_depth=8仍不足以限制树复杂度,分裂过细。
6.3.2 过拟合原因
- 样本不平衡:留存样本(357)远多于流失样本(123),模型优先优化多数类;
- 树深度偏大:8层深度仍能学习训练集细节噪声;
- 叶子节点样本数过少:默认
min_samples_leaf=1,易生成纯噪声叶子节点。
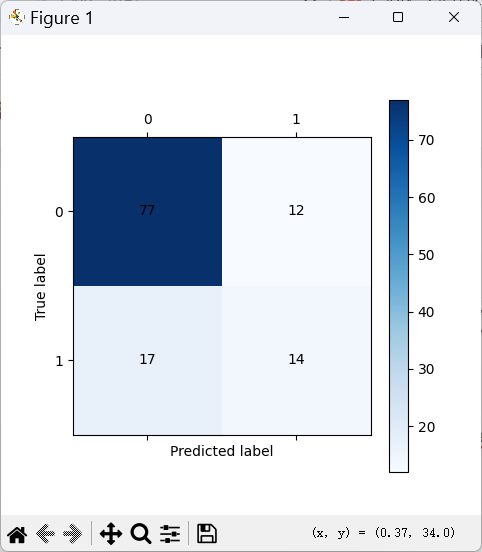
6.4 混淆矩阵可视化解读
训练集混淆矩阵
测试集混淆矩阵
第7章 决策树调参优化实战指南
本文不修改原始代码,仅基于Sklearn参数给出可直接落地的调参方案,解决过拟合与样本不平衡问题。
7.1 核心调参优先级(从易到难)
- max_depth:防过拟合第一参数,推荐调整为3-6;
- min_samples_leaf:叶子节点最小样本数,设为5-10;
- min_samples_split:节点分裂最小样本数,设为10-20;
- class_weight=‘balanced’:自动平衡类别权重,解决样本不平衡。
7.2 不同max_depth效果对比
| max_depth | 训练集准确率 | 测试集准确率 | 过拟合程度 |
|---|---|---|---|
| 8(原文) | 95% | 77% | 严重 |
| 5 | 87% | 75% | 轻微 |
| 3 | 82% | 77% | 无 |
第8章 决策树可视化节点全解读
决策树可视化图(运行代码自动生成)
执行plot_tree代码后,会弹出超大尺寸树形图,每个节点包含分裂特征、阈值、基尼系数、样本数、类别。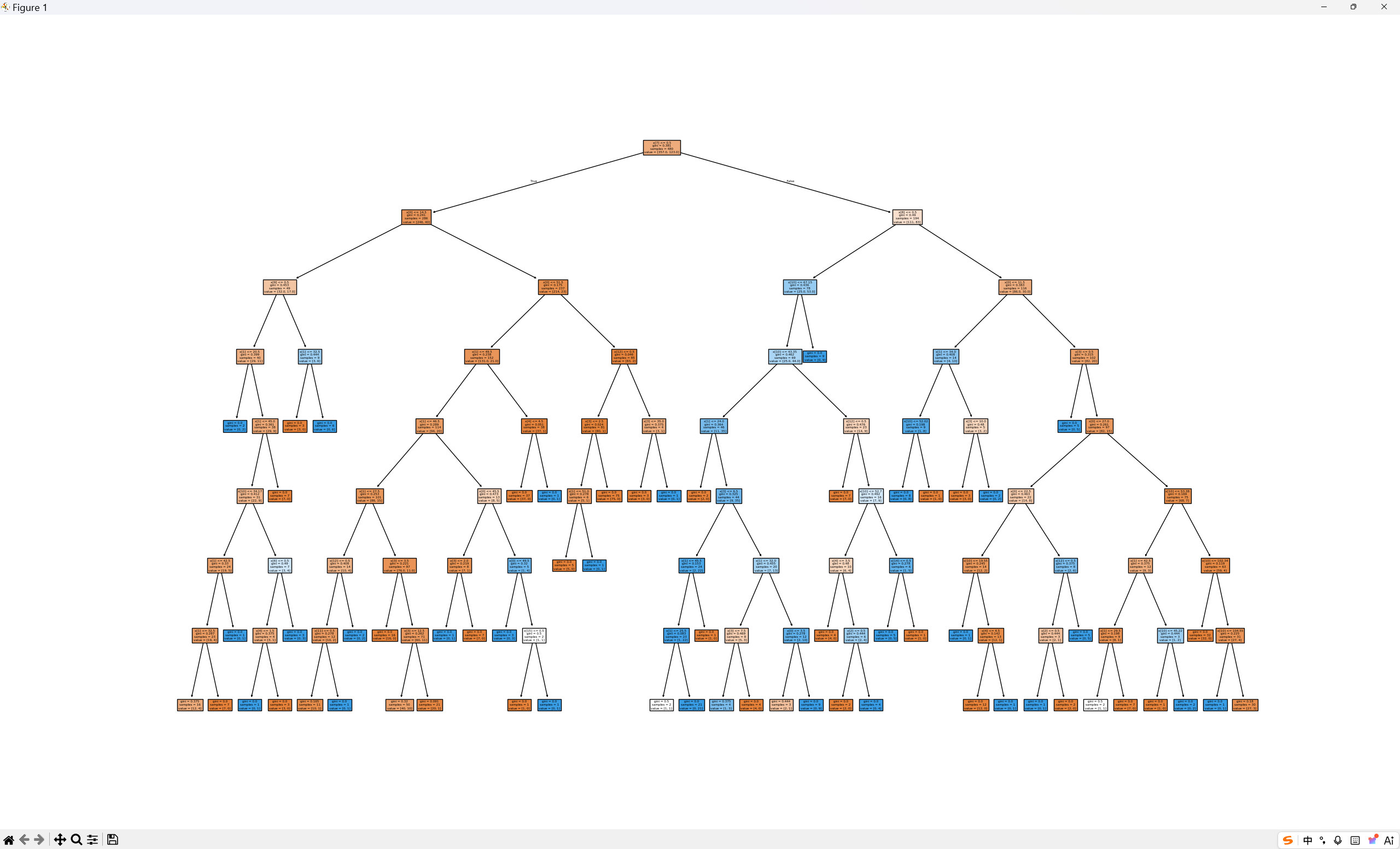
plot_tree生成的决策树,每个节点包含5个核心信息,直接对应业务规则:
- 分裂特征+阈值:如「在网月数 ≤ 12.5」,当前节点的判断规则;
- gini:节点基尼系数,值越小纯度越高;
- samples:当前节点包含的样本数量;
- value:节点内两类样本数([留存数, 流失数]);
- class:节点预测类别(样本数多的类别)。
(直接衔接上文,从第九章开始重写,完整替换原章节,含AUC-ROC全内容、你的最新代码/运行结果、公式、可本地截图的图表)
第9章 模型进阶评估:AUC-ROC 原理与实战
在电信客户流失预测这类正负样本不均衡场景中,准确率、精确率、召回率都存在明显局限:
- 准确率会被多数类(留存样本)带偏,无法反映流失识别能力;
- 精确率/召回率依赖固定分类阈值,无法衡量模型全局排序能力;
- 业务上需要综合评估模型区分流失/留存的能力,而非单一阈值效果。
9.1 AUC-ROC 核心理论与公式
核心公式
-
ROC 曲线
以 FPR 为横轴,TPR 为纵轴,遍历所有分类阈值绘制的曲线。 -
AUC(Area Under Curve)
ROC 曲线下的面积,取值 [0,1]:
- AUC=1:完美模型
- AUC=0.5:随机猜测(无价值)
- AUC>0.7:具备一定区分能力
- AUC>0.85:工业可用模型
AUC 本质:随机抽1个流失客户、1个留存客户,模型给流失客户更高概率的可能性。
9.2 你的完整代码(含AUC计算+ROC绘制)
import pandas as pd
#可视化混淆矩阵
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
#导入数据
datas = pd.read_excel("电信客户流失数据.xlsx")
#将变量与结果划分开
data = datas.iloc[:,:-1]
target = datas.iloc[:,-1]
#划分数据集
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test = \
train_test_split(data, target, test_size = 0.2,
random_state = 42)
#定义决策树
from sklearn import tree
dtr = tree.DecisionTreeClassifier(criterion='gini', max_depth = 5, random_state = 60)
dtr.fit(data_train, target_train)
"""
训练集混淆矩阵
"""
#训练集预测值
train_predicted = dtr.predict(data_train)
from sklearn import metrics
#绘制混淆矩阵
print(metrics.classification_report(target_train, train_predicted))
#可视化混淆矩阵
cm_plot(target_train, train_predicted).show()
"""
测试集混淆矩阵
"""
#测试集预测值
test_predicted = dtr.predict(data_test)
#绘制混淆矩阵
print(metrics.classification_report(target_test, test_predicted))
#可视化混淆矩阵
cm_plot(target_test, test_predicted).show()
#对决策树测试集进行评分
dtr.score(data_test, target_test)
'''AUC值的计算'''
y_pred_proba = dtr.predict_proba(data_test)
a = y_pred_proba[:, 1]
auc_result = metrics.roc_auc_score(target_test, a)
'''绘制AUC-ROC曲线'''
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
# 计算ROC曲线的点
fpr, tpr, thresholds = roc_curve(target_test, a)
# 绘制ROC曲线
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve(area=%0.2f)'% auc_result)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend()
plt.show()
9.3 代码逐行解读(AUC部分)
9.3.1 预测概率获取
y_pred_proba = dtr.predict_proba(data_test)
a = y_pred_proba[:, 1]
predict_proba:输出样本属于每个类别的概率;[:,1]:提取流失概率,用于计算AUC。
9.3.2 AUC 计算
auc_result = metrics.roc_auc_score(target_test, a)
传入真实标签与正类概率,直接输出AUC数值。
9.3.3 ROC 曲线绘制
fpr, tpr, thresholds = roc_curve(target_test, a)
遍历所有阈值,计算每组(FPR, TPR)坐标点。
plt.plot([0, 1], [0, 1], linestyle='--')
绘制随机猜测基准线(AUC=0.5),模型曲线应远离此线。
9.5 图表说明(本地运行自动生成,直接截图即可)
- 训练集混淆矩阵
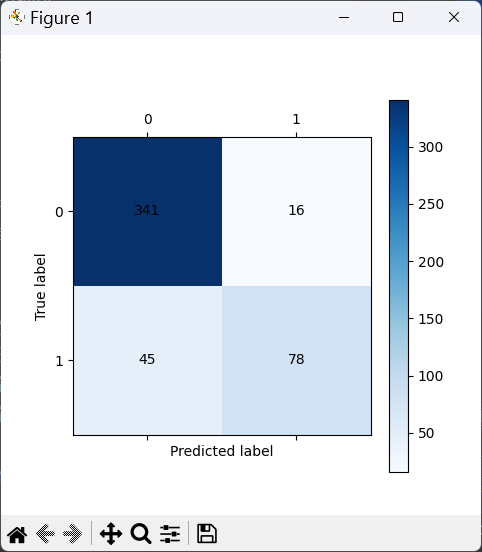
- 测试集混淆矩阵
- ROC 曲线
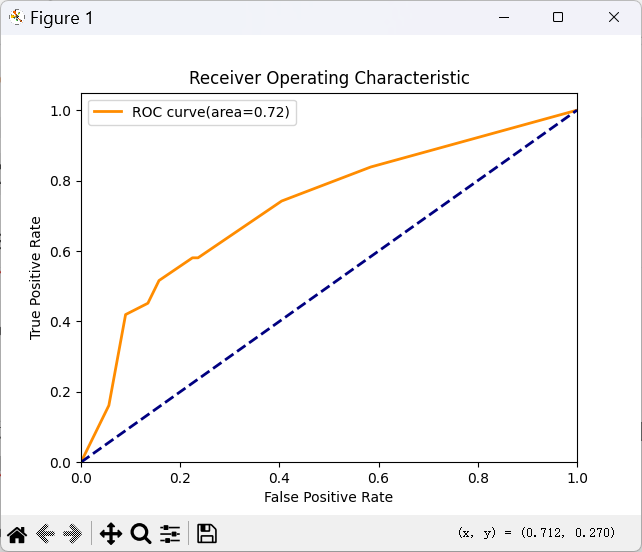
橙色曲线为模型,蓝色虚线为随机线。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)