Prompt Optimizer 安装部署教程:用 Docker 快速搭建本地提示词优化工具
这类项目我一般会先看两件事:一是有没有明确的使用场景,二是能不能在一篇文章里真跑通。
Prompt Optimizer 属于那种比较省心的类型——定位清楚,部署不重,跑起来之后也能立刻看到结果。对普通开发者来说,它很适合拿来做一个“先上手、再深入”的 AI 工具项目。
一、项目背景
Prompt Optimizer 是一个面向大模型提示词优化场景的开源工具。你可以把它理解成一个专门“帮你改 Prompt”的应用:把原始提示词丢进去,它帮你整理结构、补全约束、优化表达,让模型更容易理解你的真实意图。
官方GitHub的项目地址:
https://github.com/linshenkx/prompt-optimizer
这个项目适合的场景其实挺多:
- 写提示词总感觉“不够稳”,输出忽好忽坏
- 做 AI 应用开发,想把 Prompt 再打磨一下
- 团队里需要一个统一的提示词优化入口
- 想自己搭一个本地可用的 Prompt 工具,而不是完全依赖在线网页
从仓库说明来看,Prompt Optimizer 支持 Web、桌面端、Chrome 插件、Docker 以及 MCP 等多种使用方式。
有些项目看着很热,真写起来全是环境细节和版本大战。
二、本文环境说明
这篇文章采用的是尽量保守的方案,目标不是把所有高级玩法一次讲完,而是先把最小可用链路跑通。
环境信息
- 操作系统:Ubuntu 22.04 / 24.04
- Docker:24.x 及以上
- Docker Compose:
docker compose插件版本 - 部署方式:Docker 单容器部署
- 浏览器:Chrome / Edge 均可
- 硬件要求:
- 2 核 CPU
- 2GB 内存
- 1GB 可用磁盘空间
- 网络要求:
- 能正常拉取 Docker 镜像
- 如果要调用 OpenAI、DeepSeek、Gemini 等模型,需要保证对应 API 可访问
说明一下这次的部署思路
Prompt Optimizer 本身更像一个前端工具界面,它不是本地大模型推理服务。
换句话说,这个项目部署起来不算吃机器,真正决定你“能不能出结果”的,主要还是:
- API Key 有没有配对
- 模型服务能不能访问
- 网络和跨域有没有拦住
所以这篇文章重点:
- 把服务先启动起来
- 把页面先打开
- 把一条真实优化请求跑通
三、安装前准备
1. 检查 Docker 环境
先确认 Docker 和 Compose 都可用:
docker -v
docker compose version
如果命令有输出版本号,说明环境正常。
如果还没安装,可以直接在 Ubuntu 上执行:
sudo apt update
sudo apt install -y docker.io docker-compose-plugin
sudo systemctl enable docker
sudo systemctl start docker
为了后面使用方便,建议把当前用户加入 docker 用户组:
sudo usermod -aG docker $USER
newgrp docker
再测试一下:
docker ps
如果没有报权限错误,这一步就算过了。
2. 准备一个可用的模型 API Key
Prompt Optimizer 自己不生产模型能力,它只是把请求转发给你配置的模型服务。所以你至少得准备一个能用的 Key,比如:
- OpenAI
- Gemini
- DeepSeek
- 智谱 AI
- SiliconFlow
- 自定义 OpenAI 兼容接口
如果你暂时没有 Key,也可以先把页面部署出来,后面再补配置。
但要注意,页面能打开不等于功能已经可用,真正要验证,还是得发一次实际请求。
3. 确认本机端口没冲突
本文用宿主机 8081 端口映射容器 80 端口。
先检查 8081 有没有被占用:
ss -lntp | grep 8081
如果有输出,说明端口已经有人在用了。那就换一个,比如 8090、8888 都行。
4. 是否需要先拉代码?
如果你只是走最简单的 Docker 启动,其实不需要先 clone 仓库。
如果你后续想用 Compose、看配置文件或者研究源码,再拉仓库也不迟。
当然,如果你习惯先把代码放本地,也可以执行:
git clone https://github.com/linshenkx/prompt-optimizer.git
cd prompt-optimizer
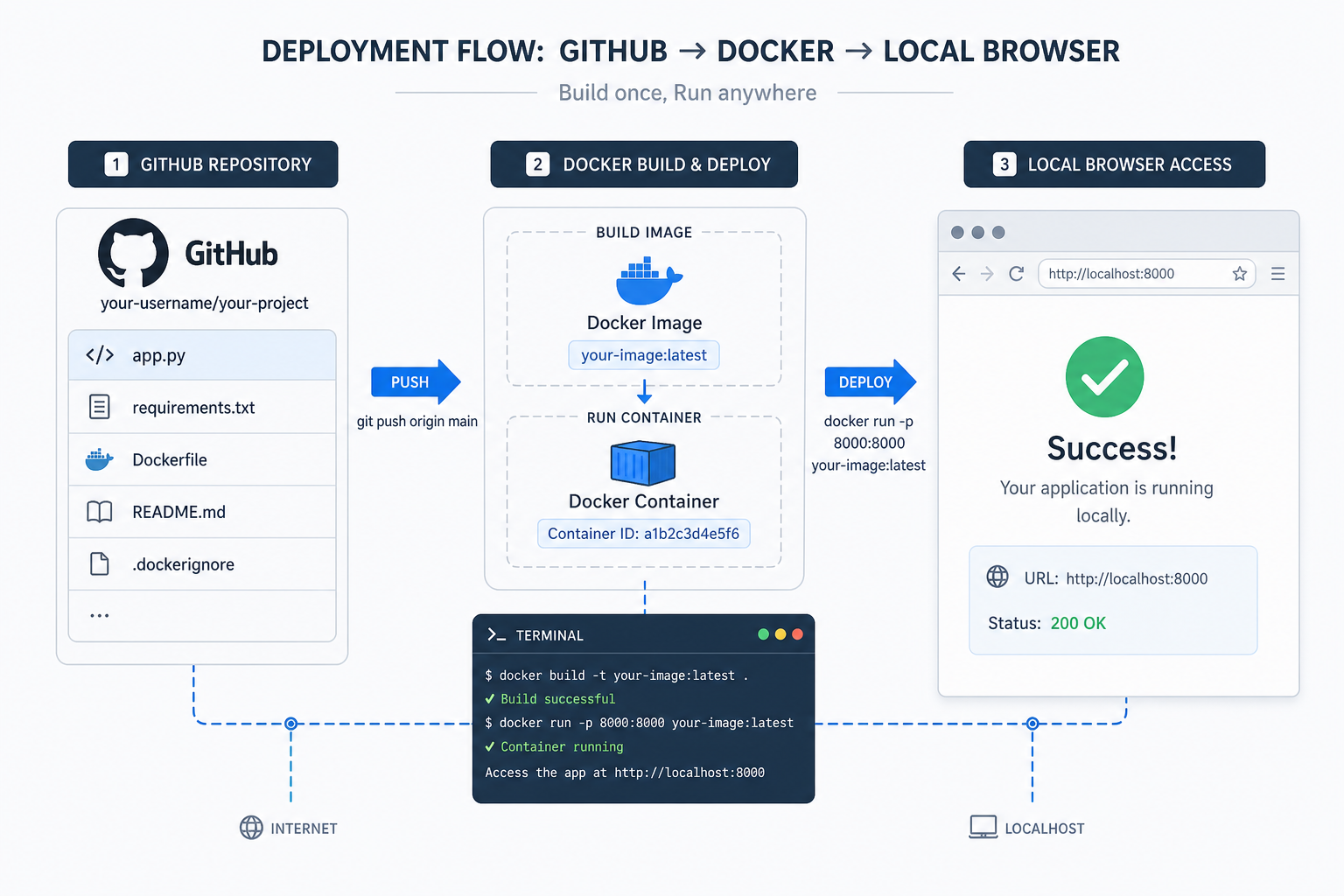
四、安装与部署
这一节我们先走最稳的路线:直接用 Docker 跑官方镜像。
1. 拉起容器
先执行下面这条命令:
docker run -d \
-p 8081:80 \
--restart unless-stopped \
--name prompt-optimizer \
linshen/prompt-optimizer
如果你的环境拉 Docker Hub 比较慢,也可以用 README 提到的镜像地址:
docker run -d \
-p 8081:80 \
--restart unless-stopped \
--name prompt-optimizer \
registry.cn-guangzhou.aliyuncs.com/prompt-optimizer/prompt-optimizer
这里几个关键参数简单说一下:
-d:后台运行-p 8081:80:把宿主机 8081 映射到容器 80 端口--restart unless-stopped:机器重启后自动拉起--name prompt-optimizer:给容器起个固定名字,后面看日志方便
2. 查看容器状态
容器启动后,先别急着打开浏览器,先看看它到底起来没有:
docker ps
正常情况下你能看到类似输出:
CONTAINER ID IMAGE PORTS NAMES
xxxxxx linshen/prompt-optimizer 0.0.0.0:8081->80/tcp prompt-optimizer
这说明容器已经在跑了。
3. 查看运行日志
再看一下日志有没有明显报错:
docker logs -f prompt-optimizer
如果只是正常启动信息,没有持续报错,这一步基本就稳了。
有些人习惯部署完直接刷新浏览器,结果页面没开出来就开始怀疑项目。
其实大多数时候,问题不是项目,是容器压根没起来,或者端口映射打错了。先看 docker ps 和 docker logs,能省掉很多无效折腾。
4. 打开页面
浏览器访问:
http://localhost:8081
如果你是远程服务器部署,把 localhost 换成服务器 IP 即可:
http://你的服务器IP:8081
能看到 Prompt Optimizer 页面,说明部署这一步已经完成了。
五、配置说明
页面打开之后,下一步就是让它真正“会干活”。
这一节主要讲最关键的配置:模型提供商和 API Key。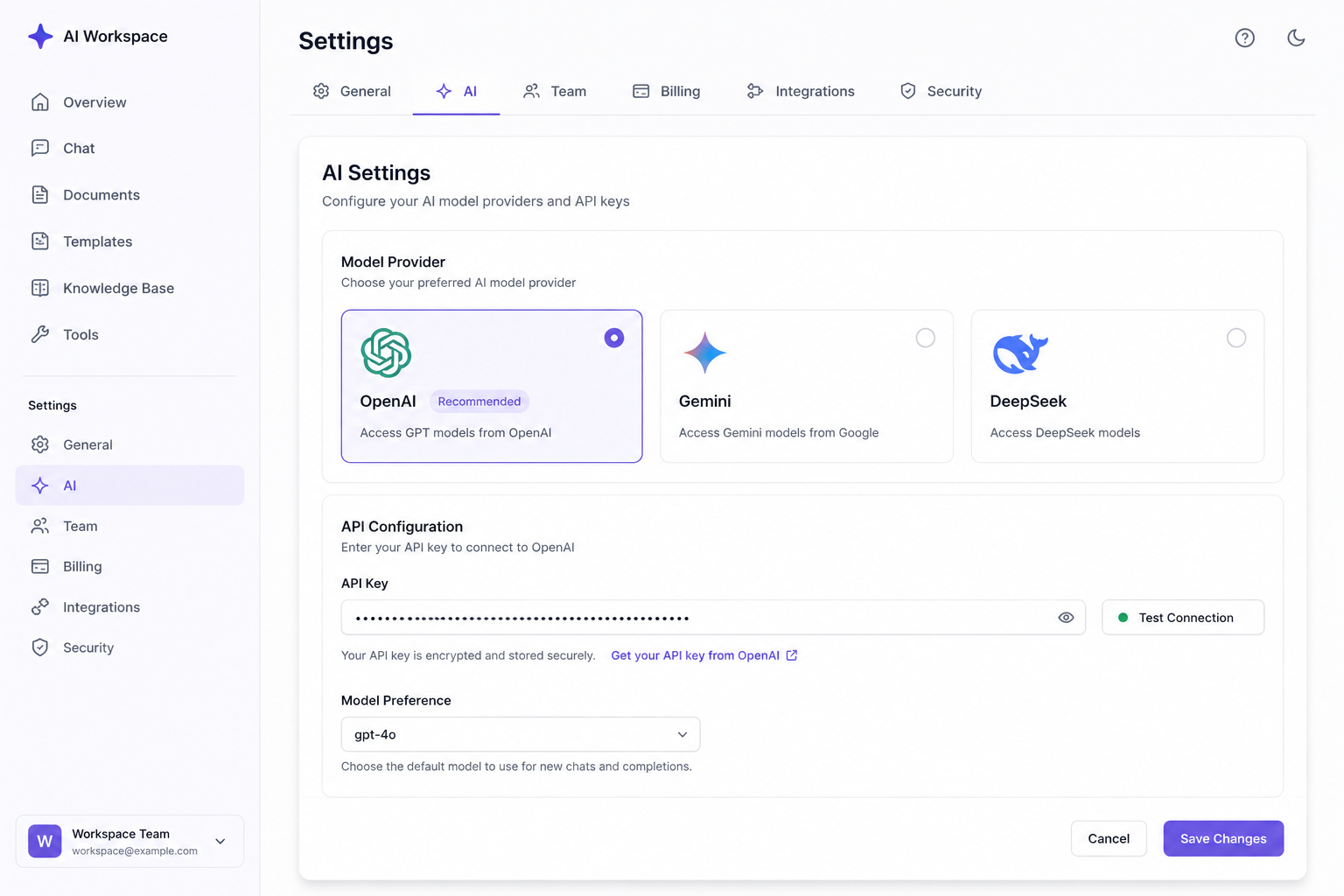
1. 页面内配置模型
根据项目 README,可以直接在页面右上角进入设置界面:
- 点击右上角 设置
- 打开 模型管理
- 选择你要使用的模型服务商
- 填入 API Key
- 保存配置
目前支持的模型类型包括:
- OpenAI
- Gemini
- DeepSeek
- 智谱
- SiliconFlow
- 自定义 OpenAI 兼容接口
如果你已经有某个平台的 Key,优先用自己最熟悉的那个,别一上来同时接五六个。
先跑通一个,再谈多模型切换,不然排错的时候自己都分不清到底是谁在掉链子。
2. 如果想用环境变量注入配置
除了在页面里手动配置,也可以在 Docker 启动时直接传环境变量。
例如:
docker run -d \
-p 8081:80 \
-e VITE_OPENAI_API_KEY=your_openai_key \
-e ACCESS_USERNAME=admin \
-e ACCESS_PASSWORD=your_password \
--restart unless-stopped \
--name prompt-optimizer \
linshen/prompt-optimizer
常见环境变量包括:
VITE_OPENAI_API_KEY
VITE_GEMINI_API_KEY
VITE_DEEPSEEK_API_KEY
VITE_ZHIPU_API_KEY
VITE_SILICONFLOW_API_KEY
VITE_CUSTOM_API_KEY
VITE_CUSTOM_API_BASE_URL
VITE_CUSTOM_API_MODEL
ACCESS_USERNAME
ACCESS_PASSWORD
MCP_DEFAULT_MODEL_PROVIDER
MCP_LOG_LEVEL
最小配置建议
如果只是先验证功能,推荐保留最小配置:
VITE_OPENAI_API_KEY=your_openai_key
ACCESS_USERNAME=admin
ACCESS_PASSWORD=your_password
这样做的好处是简单,排错也容易。
3. 访问保护建议
如果你打算把这个工具部署到云服务器,或者至少不是“只给自己电脑本机访问”,建议把访问控制顺手加上:
ACCESS_USERNAME=admin
ACCESS_PASSWORD=your_password
因为很多人部署 AI 工具时最容易忽略的一点就是:API Key 其实也是成本入口。
页面一旦裸奔,别人不一定看得上你的服务器,但很可能觊觎你的调用额度。
六、跑通第一个 Demo
部署成功之后,最重要的不是截图,而是跑通一次真实请求。
做一个最小 Demo,不搞复杂业务,就验证最核心的能力:提示词优化。
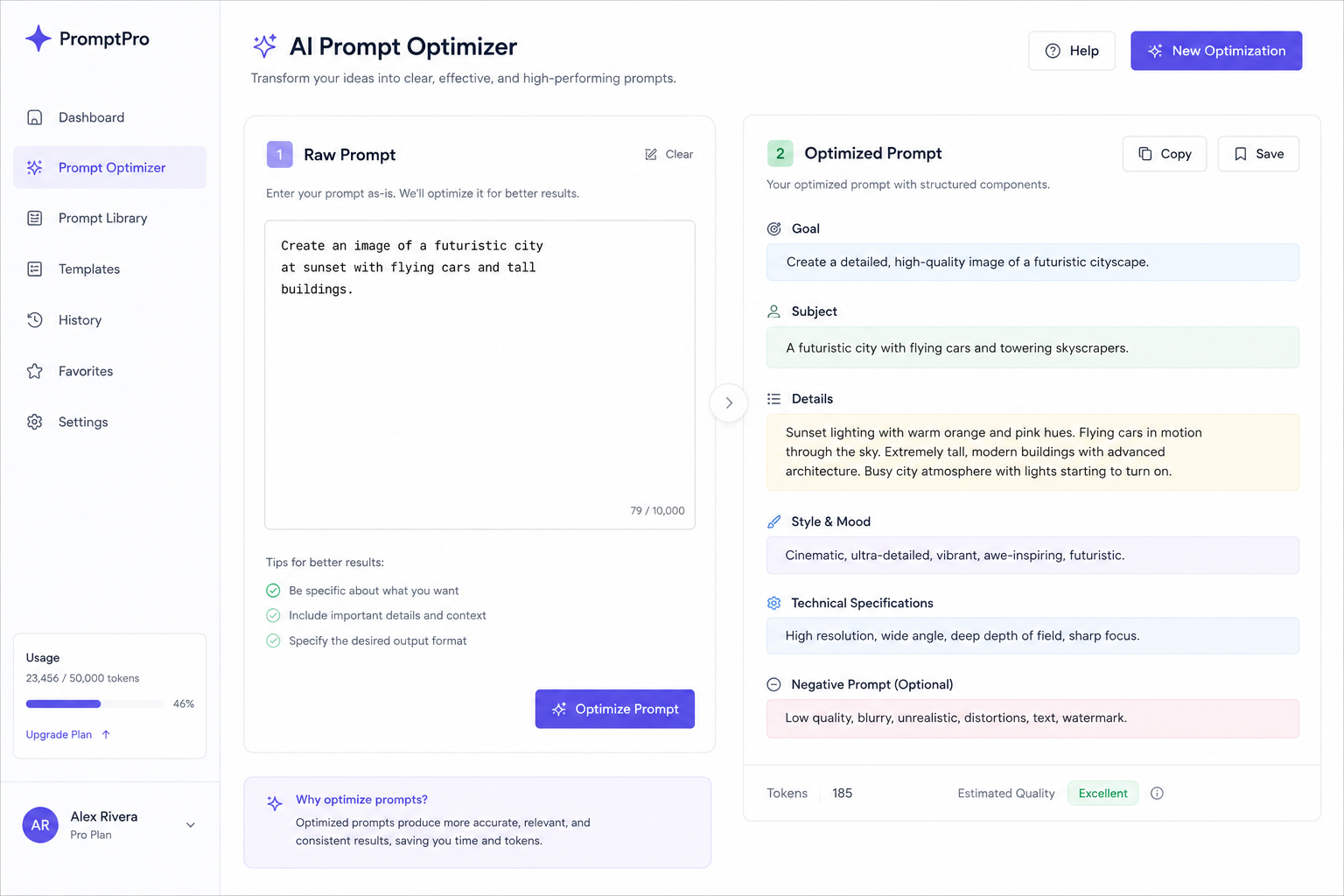
1. 准备一条原始提示词
比如下面这一句:
帮我写一篇介绍 Python 学习方法的文章
这条提示词当然不是不能用,但它太宽了:
- 面向谁,不明确
- 写多长,不明确
- 什么结构,不明确
- 语气风格,不明确
这也是很多 Prompt 用起来“忽灵忽不灵”的根源。
2. 在页面中发起优化请求
操作流程很简单:
- 打开 Prompt Optimizer 页面
- 确认模型和 Key 已配置好
- 把原始提示词粘贴进去
- 执行优化
3. 成功后应该看到什么
如果链路正常,页面会返回一条更结构化的提示词,大致会补充这些内容:
- 目标读者
- 输出形式
- 文章结构
- 字数要求
- 风格要求
- 可选示例
例如可能得到类似结果:
请面向 Python 初学者撰写一篇学习方法指南,内容包括学习路线、常见误区、推荐资源与练习建议,语言通俗,结构清晰,分小节输出,控制在 1000 字左右。
到这一步,说明三件事都成立了:
- 页面是正常的
- 模型请求是通的
- 项目的核心功能可以用了
这才叫真正部署成功。
不是“我页面打开了”,而是“我能用它干活了”。
七、效果验证
为了避免“看起来好像行,实际上没跑通”的情况,建议至少做下面 3 组验证。
1. 验证容器状态
docker ps | grep prompt-optimizer
如果状态是 Up,说明服务没有直接退出。
2. 验证 Web 页面可访问
浏览器打开:
http://localhost:8081
如果能正常加载首页,就说明 Web 服务可访问。
3. 验证真实请求可返回结果
在页面里执行一次提示词优化请求。
成功标志包括:
- 页面无报错
- 请求能返回内容
- 优化后的 Prompt 能正常显示
4. 验证日志是否稳定
在执行页面操作时,另开一个终端查看日志:
docker logs -f prompt-optimizer
如果没有持续报错、容器没有反复重启,说明服务基本稳定。
5. MCP 路径验证(可选)
如果你后续想把它接入 Claude Desktop 等工具,可以测试:
http://localhost:8081/mcp
只要不是直接 404,就说明相关路径基本存在。
更完整的 MCP 接入配置,建议后续再单独研究,不建议第一次部署时一起折腾,容易把简单问题搞复杂。
八、常见报错与解决方案
很多部署问题真不神秘,来来回回就那几类:端口、镜像、网络、Key、跨域。
遇到问题先定位,不要一上来就删容器重装,重装有时候只是把同一个坑再踩一遍。
1. Docker 镜像拉取失败
现象
执行 docker run 时一直卡住,或者直接提示拉取镜像失败。
常见原因
- Docker Hub 网络慢
- 当前网络访问受限
- 镜像源不稳定
解决办法
优先换 README 提到的镜像地址:
docker run -d \
-p 8081:80 \
--restart unless-stopped \
--name prompt-optimizer \
registry.cn-guangzhou.aliyuncs.com/prompt-optimizer/prompt-optimizer
也可以先单独拉镜像测试:
docker pull registry.cn-guangzhou.aliyuncs.com/prompt-optimizer/prompt-optimizer
如果这一步都不通,那就先解决 Docker 网络问题,别急着怀疑项目。
2. 端口占用
现象
启动时报错:
Bind for 0.0.0.0:8081 failed: port is already allocated
解决办法
先查一下是谁占了端口:
ss -lntp | grep 8081
然后换个端口重新启动,比如改成 8090:
docker run -d \
-p 8090:80 \
--restart unless-stopped \
--name prompt-optimizer \
linshen/prompt-optimizer
访问时记得同步改成:
http://localhost:8090
3. 页面能打开,但调用模型失败
现象
前端页面正常,点了优化之后报错、无响应、超时或者返回失败。
常见原因
- API Key 填错
- 模型服务商接口不可达
- Base URL 配置不对
- 自定义模型名写错
- 浏览器跨域拦截
解决办法
建议按这个顺序排查:
- 检查 API Key 是否有效
- 检查模型服务是否能访问
- 如果是自定义兼容接口,检查 Base URL 是否完整
- 检查模型名是否和服务端支持的一致
- 打开浏览器开发者工具,看 Network / Console 是否有跨域错误
这里面最容易忽略的是跨域。
很多人看到页面正常,就默认后端一定通了。其实浏览器拦请求的时候,它不会提前跟你商量。
4. 接本地 Ollama 失败
现象
本机 Ollama 明明装好了,但在 Prompt Optimizer 页面里调用失败。
解决办法
根据 README,可以尝试给 Ollama 配置:
OLLAMA_ORIGINS=*
OLLAMA_HOST=0.0.0.0:11434
如果你是 systemd 方式管理 Ollama,修改后记得重启服务。
另外再注意这几点:
- 浏览器访问本地服务可能触发 CORS 问题
- HTTPS 页面调用 HTTP 本地 API 会被 Mixed Content 拦截
- 如果只是临时体验,本地 Web 页面接 Ollama 有时不如桌面端稳
这个锅很多时候不是 Prompt Optimizer 的,是浏览器安全策略的常规发挥。
5. 页面空白或静态资源加载异常
常见原因
- 容器没启动成功
- 端口映射错误
- 浏览器缓存导致加载异常
- 反向代理配置不对
排查方式
先做这三步:
docker ps
docker logs prompt-optimizer
curl http://localhost:8081
如果 curl 都拿不到内容,那就先别折腾前端缓存了,问题根本不在浏览器。
6. Docker 权限不足
现象
执行 Docker 命令时报权限错误,例如:
permission denied while trying to connect to the Docker daemon socket
解决办法
把当前用户加入 docker 组:
sudo usermod -aG docker $USER
newgrp docker
或者临时先用:
sudo docker ps
不过从长期来看,还是把权限配好更省事。
7. 容器反复重启
现象
docker ps 里容器状态不稳定,或者一会儿就退出。
解决办法
先看详细日志:
docker logs prompt-optimizer
再看容器状态:
docker inspect prompt-optimizer
常见原因一般是:
- 镜像没有完整拉取成功
- 容器内部启动失败
- 端口冲突
- 启动参数写错
先把启动命令缩到最小,不要一开始就带一堆环境变量。
排错的时候,配置越少,真相越快出现。
九、进阶说明
如果你已经把 Prompt Optimizer 跑通了,后面可以继续看这几个方向。
1. 多模型接入
把 OpenAI 跑通之后,可以继续尝试:
- Gemini
- DeepSeek
- 智谱
- SiliconFlow
- 自定义 OpenAI 兼容接口
这样可以做不同模型的效果对比。
2. 通过 Docker Compose 管理部署
如果后续你希望把配置长期保留下来,建议改成 Compose 管理。
这样环境变量、镜像版本、端口映射都能写进配置文件,后面维护更舒服。
3. 接入 MCP
如果你有 Claude Desktop 等客户端使用需求,可以继续研究项目的 /mcp 路径和服务配置方式,把 Prompt Optimizer 当成一个 MCP 服务来接。
4. 本地源码开发
如果你想看项目结构或者做二次开发,可以进一步走源码方式:
pnpm install
pnpm dev
不过这是下一阶段的事情。
我还是那句话:先跑通,再研究。别在第一天就同时挑战部署、源码、构建链、模型接入四件事,那样文章还没写完,人已经有点想关电脑了。
十、总结
Prompt Optimizer 这个项目挺适合拿来做一篇“能落地的 AI 工具部署教程”。
它的优点不在于功能有多夸张,而在于:
- 目标明确
- 部署成本不高
- 跑通后反馈直接
- 很适合普通开发者快速上手
这篇文章走的是最稳的一条路:
- 用 Docker 启动服务
- 用浏览器访问页面
- 配置模型 API Key
- 跑通一次真实的提示词优化请求
如果你能顺利完成这几步,其实已经够用了。
后续要不要上云、要不要接 MCP、要不要做团队共用,那都是建立在“本地已经能跑”的前提上。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)