小白程序员必看:AI 大模型从入门到精通,收藏学习路径!
本文从 AI 发展历程、核心概念入手,详细解析了 AI 如何重塑软件开发流程,并以请假审批系统为例,展示了 AI 在实际工作中的应用。最后,文章提供了三步走策略,帮助读者用好 AI,并强调了工程思维在 AI 时代的重要性。
开篇:这篇到底想解决什么
-
建立概念:Prompt / Agent / Skill / MCP / Command / Rules / Hook 到底是什么。
-
对齐认知:AI 会在我们研发流程里替换掉什么、留下什么。
-
看完整案例:请假审批系统五阶段全链路 showcase。
-
学会落地:三团队实战教程 + 反向思考如何产出产品级交付物。
Part 1:AI 发展历程与核心概念
1.1 三代协作界面的演进
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
timeline
title AI 协作界面三代演进
第一代 Web Chat : ChatGPT / Gemini / DeepSeek
: 核心 = Prompt
: 边界 = 单轮对话,无工具
第二代 Agent : Claude Code CLI / Cursor
: 核心 = Skills / MCP / Command
: 边界 = 可调用工具,进入文件系统
第三代 Gateway : OpenClaw / Hermes
: 核心 = 多 Agent 协同
: 边界 = 安全+复杂任务质量待解
| 代际 | 擅长 | 不擅长 | 最适合场景 |
|---|---|---|---|
| 第一代 Web Chat | 单点问答、文案润色、知识检索 | 读你的代码、跑你的测试、改你的文件 | 不在开发环境里的杂活 |
| 第二代 Agent | 读 / 写文件、跑命令、串工作流 | 多人协作、权限隔离 | 研发全流程 |
| 第三代 Gateway | 多 Agent 协同、自动分派 | 复杂任务质量、安全边界 | 批处理、运维自动化 |
本文的重点在第二代。 第一代门槛已经没有、第三代还在成熟。第二代是当下投入产出比最高的一代。
1.2 基础概念扫盲
下图是 Agent 执行的一个循环:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
flowchart LR
Perception[输入] --> |制定计划| Reasoning[思考]
Reasoning --> |调用工具| Action[行动]
Action --> |获得反馈| Observation[观察]
Observation --> |调整并输出| Refining[迭代]
Refining --> |接收上下文| Perception
7 个概念在循环的不同位置介入:
| 概念 | 一句话定义 | 介入时机 | 类比 |
|---|---|---|---|
| Prompt | 你给 AI 的那段话 | 每次对话 | 把想法翻译给 AI 听 |
| Agent | 能自主调用工具的 AI | 整条任务 | 会用工具的实习生 |
| Rules | 全局约束 | 全程生效 | 员工手册 |
| Command | 显式触发的剧本 | 单次调用 | 一张工单 |
| Skill | 可复用的方法论 | 模型按需匹配 | 员工的技能树 |
| MCP | 外部系统接口协议 | 需要事实时 | 外设 / USB-C |
| Hook | 流程中的确定性卡点 | 指定节点 | 签字审批 |
三个常被搞混的区别:
-
Prompt vs Agent:Prompt 是"你说的话";Agent 是"说话之外还能动手的那个家伙"。
-
Skill vs Command:Skill 是 AI 自己按需调用的方法论(肌肉记忆);Command 是你手动触发的流程(按钮)。
-
MCP vs Hook:MCP 是"让 AI 能看到/改到外部世界";Hook 是"在某一步强制执行逻辑,不给 AI 犹豫空间"。
Part 2:AI 如何重塑我们的工作流程
2.1 现状:软件开发四阶段 × 四角色
当前研发流程粗分四个阶段,每个阶段有主角色、任务、交付物:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
timeline
title 软件开发流程:阶段 × 角色 × 交付物
section 需求期
产品 : 需求沟通与整理 : 产出 PRD / 原型 / 交互文档
研发&测试 : 参与需求评审 : 产出评审意见
section 研发期
研发 : 技术方案调研与编写 : 产出技术方案 / 代码
测试 : 测试用例编写与评审 : 产出用例矩阵 / 评审意见
section 测试期
研发 : 编写提测文档 / 通过冒烟 / 修复 bug : 产出提测报告 / 修复记录
测试 : 黑盒 / 白盒 / 性能测试 : 产出缺陷单 / 测试报告
section 发布期
研发 : 编写上线文档 : 产出上线文档 / 变更记录
运维 : 部署 / 监控 / 回滚 : 产出发布记录 / 监控仪表盘
我认为,这套流程最大的熵,是上下文的丢失。
三种形态:
-
信息本身的模糊——PRD 一句"应该支持批量操作",不同研发理解出三种实现。靠人脑补缺失信息时,质量必然参差。
-
信息同步时的损耗——传统靠会议一轮轮对齐。研发 / 测试过程中发现的漏洞,又得拉一轮会议同步。每次传递都丢精度。
-
信息的遗漏——数据库变更、代码改动涉及的业务板块,容易在技术方案 / 提测 / 上线文档中漏写一两项。二期需求时,上一次上下文散落在个人大脑里——接手的人只能从头再来。
共同指向一件事:信息每经过一次人,就损耗一次。一次完整流程少说过七八手。
如何利用 AI,来减轻流程中的熵?
- 模糊 → AI 帮你逼问到明确
- 同步损耗 → AI 让上下文结构化、可机读、不依赖开会
- 遗漏 → AI 自动归档变更面与关联上下文,二期可直接消费一期
2.2 每个角色在做什么,AI 能做 / 不能做
| 角色 | 核心工作 | AI 能做的部分 | AI 做不了(仍需要人) |
|---|---|---|---|
| 产品 | 需求挖掘、PRD 编写、原型设计、跨方沟通 | 穷举边界场景、生成用户故事、逆向验收标准、Figma MCP 出原型 | 业务取舍 :老板要 A、销售想 B、客户要 C,先做哪个——AI 给不出"这次就不做 B"的决定。跨方对齐:口径冲突时拍板——AI 整理得了纪要,背不了锅。隐性业务规则:只存在于 CEO / 客户对话里的"行规"——AI 无从知晓。 |
| 前端 | 交互实现、页面开发、联调 | 骨架代码、样式还原(Figma MCP)、组件测试、风格对齐 | 架构决策 :Vuex 还是 Pinia、SSR 还是 CSR——需结合团队能力和项目生命周期。性能瓶颈定位:真机卡顿到底是首屏资源大还是主线程阻塞——看火焰图。交互手感:动画 250ms 还是 300ms、按钮要不要震动——要亲手试。 |
| 后端 | 接口设计、业务逻辑、数据建模、性能优化 | 接口骨架、数据校验、错误分类、单元测试、迁移脚本 | 领域建模 :订单是"交易凭证"还是"生产工单"——边界定错整个系统重构。一致性 / 事务权衡:“强一致但慢” vs “最终一致但快”——看业务容忍度。历史债务判断:旧代码动还是不动、重构到什么程度收手——结合线上流量和排期。 |
| 测试 | 用例设计、执行、缺陷跟踪、回归 | 用例矩阵生成、自动化巡检、回归覆盖补全、缺陷归类 | 探索式测试 :凭经验踩"连点三次会不会崩"、“断网重连会不会丢数据”——靠直觉。真机 / 真实环境验证:低端安卓、3G 网络、海外 VPN——AI 和模拟器看不全。风险分级:bug 是"阻塞发布"还是"下版本修"——结合用户量 / 业务容忍度 / 发版节奏。 |
| 运维 | 部署、监控、告警、故障恢复 | 部署脚本、日志聚合、异常检测、SOP 生成 | 线上止损动作 :告警响了先回滚还是先加机器——结合业务重要性人判。容量规划:下季度是否扩容、长包还是按量——结合财务和业务预测。故障最终授权:重启数据库、切流量——必须人确认。 |
- AI 擅长:可描述、可重复、有模板、有标注数据的工作。
- AI 不擅长:需要口味、需要直觉、需要跨人协商、需要对后果负责的工作。
延伸阅读:Taste in the Age of AI and LLMs——未来高质量产出的成本很低,真正决定差异的,是使用 AI 的人的品味。
2.3 有了 AI 之后的新协作流程
把 2.1 的时间线升级:每个阶段加入 AI 协作角色,但每个阶段保留一个"人工闸门"。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
timeline
title 有 AI 之后的流程:阶段 × 角色 × 交付物
section 需求期 (新)
产品 + AI : AI 穷举边界 / 用户故事 / Figma MCP 出原型 : 产出结构化 PRD + 可点原型
人工闸门 🔴 : 产品拍板业务取舍 + 需求评审
section 研发期 (新)
研发 + AI : AI 出方案草案 / TDD 骨架 / 多模型对抗 review : 产出技术方案 + 可编译代码
测试 + AI : AI 基于 PRD+代码 生成用例矩阵 : 产出正常 / 异常 / 边界三类用例
人工闸门 🔴 : 架构决策 + 用例优先级 + 评审
section 测试期 (新)
研发 + AI : AI 自动生成提测文档 + 冒烟自动化 : 产出提测报告
测试 + AI : AI 黑盒巡检 / 性能基线 / 缺陷闭环 : 产出缺陷单 + 测试报告
人工闸门 🔴 : 探索式测试 + 上线风险评估
section 发布期 (新)
研发 + AI : AI 自动 changelog / 上线文档 : 产出发布包 + 上线文档
运维 + AI : AI 金丝雀监控 / 异常检测 / 回滚建议 : 产出监控仪表盘 + 回滚预案
人工闸门 🔴 : 发布授权 + 回滚决策
对比 2.1,变化在三处:
-
每阶段都加入 AI——但是"和角色并排",不是"替代角色"。
-
每阶段保留一个 🔴 人工闸门——评审 / 架构 / 探索测试 / 授权回滚。
-
跨阶段交付物更结构化——PRD → 用户故事 → 测试矩阵 → 缺陷单可以通过 AI 双向追溯。
AI 不是进来接管流程的,它是进来降低熵、把人的精力抬到决策层的。
Part 3:全链路 Showcase——请假审批系统
理论铺完,上干货。以下是一个完整跑通的 showcase:从一句话需求到可运行 Demo,共 5 个阶段,每一步都有交付物。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
flowchart LR
A[一句话需求] -->|Stage 1| B[PRD]
B -->|Stage 2| C[Figma 设计]
D[PRD + 设计] -->|Stage 3| E[前后端代码]
F[PRD + 代码] -->|Stage 4| G[38 个测试用例]
E -->|Stage 5| H[可运行 Demo]
Stage 1:一句话 → PRD
- 输入:一句话——“做一个公司内部请假审批系统”。
- 输出:结构化 PRD 文档,包含 7 个用户故事、10 个边界场景、4 类业务规则、完整验收标准。
- 工具链:
brainstormingskill +/plan-ceo-reviewcommand。 - AI 发现的传统 PRD 容易漏的:
- 并发场景:两个审批人同时操作同一条申请
- 审批人自己请假:谁审批
- 两级审批:直接主管 → 部门总监串联
- 跨月请假:天数怎么算、配额在哪月扣
- 撤回时机:待审批可撤、已通过走另一个流程
收获:AI 2 分钟穷举的边界,比人坐一下午还多。列的不一定都对——这就是人工 Check 的价值。
Stage 2:PRD → Figma 设计
- 输入:Stage 1 的 PRD。
- 输出:3 个页面原型(申请 / 我的请假 / 审批列表)。
- 工具链:Figma MCP。
坦白:Figma MCP 当前出的图离生产级有距离。它解决"有没有",不解决"美不美"。
Stage 3:PRD + 设计 → 前后端代码
- 输入:Stage 1 PRD + Stage 2 设计。
- 输出:
- 前端 Vue 3 + TypeScript:3 页面、9 个 API 接口、类型定义、状态管理骨架
- 后端 Go:model + service + handler 三层,8 步校验、两级审批流转、11 个具名错误类
- 工具链:
figma-implement-design+test-driven-development+/plan-eng-review。 - AI 覆盖 10 个边界中的 8 个。剩下 2 个明确标"需要人确认",没硬编。
Stage 4:PRD + 代码 → 38 个测试用例
- 输入:Stage 1 PRD + Stage 3 代码。
- 输出:用例矩阵文档,38 个用例——8 正向 + 11 异常 + 14 边界 + 5 列表。覆盖率 86%。
- 工具链:
qaskill。 - AI 发现的传统 QA 容易漏的:并发竞争、状态机非法迁移、跨月天数、审批人角色切换。
Stage 5:代码 → 可运行 Demo
- 输入:Stage 3 代码。
- 输出:3 页面可交互运行。QA 健康度 85/100,0 JS 错误。
- 工具链:
/qa+ 浏览器 MCP 自动点击巡检。
Part 4:如何用好 AI
三步走:用好 Prompt → 升级到 Agent → 沉淀成工作流。
4.1 Prompt 五条基本功
-
角色设定:一句话把 AI 放进角色——“你是有 10 年经验的 Go 后端工程师”。
-
结构化输入输出:给模板 / JSON schema / 示例格式。
-
清晰上下文:让 AI 读代码 / 读文档,而不是猜。
-
分步思考:复杂任务先规划后执行。
-
自动询问:不确定时让 AI 反问,别瞎猜。
对比例子——
❌ 差:
帮我写个登录接口。
✅ 好:
你是我们项目的 Go 后端工程师。项目结构参考
backend/internal/目录。实现基于手机号+验证码的登录接口:
- 输入:
phone,code- 输出:JWT token
- 约束:验证码 5 分钟有效、3 次失败锁定 10 分钟
- 需要:接口定义 + service 实现 + 单元测试 不清楚的地方先问我。
4.2 两个工程师的故事:为什么必须升级到 Agent
工程师 A:打开 ChatGPT,复制粘贴,改改命名,提 MR,合并。
工程师 B:跑 /brainstorming → 把 PRD 丢给 Figma MCP → Claude Code 跑 TDD → Codex 对抗 review → /ship 上线。
一个月后:看不出差别。半年后:B 有 20 个可复用 Skill + 研发生命周期 Command 剧本;A 还在重复解释"请用我们项目的风格"。一年后:A 的产能被专注力封顶;B 能同时编排三个 Agent。
差距在哪?
- A 的 AI 只有 Prompt:单轮、无工具、无记忆、无沉淀。
- B 的 AI 是 Agent:读代码、跑测试、调 MCP、触发 Command、匹配 Skill,并把经验沉淀回工作流。
4.3 如何用好 Agent:Skills / MCP / Command 三件套
Skills:给 Agent 装上肌肉记忆
什么时候用:一件事做过三次以上,就该沉淀成 Skill。
按角色推荐:
- 通用(superpowers):
brainstorming、verification-before-completion、systematic-debugging、` - 测试(gstack):
qa、qa-only、investigate、benchmark
三件事:找(skills.sh)/ 用(显式或自动匹配)/ 写(用 writing-skills meta skill)。
MCP:给 Agent 装上感官
典型家族:Figma MCP、数据库 MCP、浏览器 MCP、Jira / Meegle MCP、Slack MCP。
Figma MCP 示例:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
sequenceDiagram
设计师->>Figma: 出图
前端->>Claude: "按这个 Frame 写 Vue 组件"
Claude->>Figma: 通过 MCP 读取节点 + 设计 token
Figma-->>Claude: MCP 返回结构化的数据 JSON(layout/color/text)
Claude-->>前端: 生成组件 + 样式 + 类型
Command:把团队 SOP 变成一条斜杠命令
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
flowchart LR
A["需求<br/>/office-hours"] --> B["规划<br/>/plan-ceo-review<br/>/plan-eng-review"]
B --> C["编码"]
C --> D["自测<br/>/qa"]
D --> E["审查<br/>/codex review<br/>/review"]
E --> F["发布<br/>/ship"]
F --> G["监控<br/>/canary"]
G --> H["复盘<br/>/retro"]
自己写 Command 的时机:一个操作手动做了三次以上。
4.4 工程思维:构建自己的工作流才是终极护城河
Skill / MCP / Command 都是零件。零件背后是工作流,工作流背后是工程思维。
角色演变:过去是"实现者"——把需求变成代码;现在是"编排者 + 把关者"——拆任务、给工具、管 Agent、验产出。
AI 会放大你的失误:每个环节的质量问题,都会放大下一个环节的错误。
- 模糊的需求 → 错误的代码(更快)
- 薄弱的测试 → 漏洞的上线(更快)
- 浅层的 review → bug 的传播(更快)
如何从零构建自己的工作流?
社区已经有非常成熟的 Skill / Command 套件,先装上、跑起来、有不爽再改。半天就能搭完工作台。
-
装通用方法论:superpowers——一次性获得 brainstorming、TDD、systematic-debugging、verification-before-completion、writing-plans、requesting-code-review 等高频 skill。
-
装研发生命周期 Command:gstack——一次性获得
/office-hours``/plan-eng-review``/qa``/codex``/review``/ship``/canary``/retro``/health等覆盖全链路的 Command,本文 Part 5 就是它的教程。 -
装 1-2 个 MCP:按岗位选——前端装 Figma MCP、测试装浏览器 MCP、后端装数据库 MCP。
-
写 1 个项目级 Rules:在 repo 里放一份 AI 工作手册(如
CLAUDE.md或AGENTS.md),告诉 Agent 你项目的代码风格、禁用 API、命名约定——这是少数必须自己写的东西,因为它和项目强绑定。 -
遇到第三次重复才自定义:不要一上来就写自己的 Skill / Command。等社区方案明显不够用、你已经手动做了三次同样的事,再用
writing-skillsskill 把它沉淀下来。
Part 5:三团队实战教程(以 gstack 为骨架)
前面讲的是心智和方法论。这节上手教学——用 gstack 作为骨架,把每个团队日常最常用的命令拆开讲清楚:它到底做了什么、什么场景用、产出长什么样。读完你就能上手复现。
gstack 是一套社区开源的 Command 套件,按研发生命周期组织。下面命令描述翻译并浓缩自 gstack 仓库里的 skills 说明。
5.1 产品团队:从一句话到可点原型
目标工作流:一句话想法 → 验证是否值得做 → 写 PRD → CEO / 设计 / DX 三轮 plan review → Figma 原型。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
flowchart LR
A[一句话想法] --> B["/office-hours<br/>值不值得做"]
B --> C[写 PRD 草稿]
C --> D["/plan-ceo-review<br/>战略视角"]
D --> E["/plan-design-review<br/>设计视角"]
E --> F["/plan-devex-review<br/>(若涉及开发者体验)"]
F --> G[Figma MCP 出原型]
命令详解
/office-hours —— YC Office Hours 模式
两种子模式:
- Startup 模式:用 6 个追问问题暴露真实需求——demand reality(真的有人要吗)/ status quo(现在他们怎么凑合的)/ desperate specificity(具体到绝望的场景是什么)/ narrowest wedge(最窄的切入口)/ observation(你观察到了什么)/ future-fit(未来是否契合)。
- Builder 模式:副项目 / 黑客松 / 学习 / 开源的设计思维头脑风暴。
用法:/office-hours 我想做一个员工内部请假审批系统
输出:一份 design doc,包含"是否值得做"的结构化判断、候选切入点、风险清单。
/plan-ceo-review —— CEO / 创始人视角 plan 评审
四种模式(自动根据 plan 选):
-
SCOPE EXPANSION(大胆想):找"十星级产品",挑战前提,扩展范围
-
SELECTIVE EXPANSION(守住范围 + 挑选扩展):主干不动,挑能放大价值的扩展点
-
HOLD SCOPE(极致严谨):不扩不减,把每个点打磨到位
-
SCOPE REDUCTION(砍到核心):剥掉所有非必要,只留最小可行
用法:先写一份 plan 草稿,然后 /plan-ceo-review
输出:带分模式讨论的 plan 修订版 + 每个决策的理由。
/plan-design-review —— 设计师视角 plan 评审
对 plan 里的每个设计维度打 0-10 分(视觉一致性、层级、间距、动效、可访问性……),解释"变成 10 分需要什么",然后修改 plan 推到 10 分。
输出:维度打分表 + 改进后的 plan。
/plan-devex-review —— 开发者体验视角 plan 评审(如果你做的是面向开发者的产品)
探索开发者画像、对标竞品、设计魔法时刻、追踪摩擦点再打分。三种模式:DX EXPANSION(做竞争优势)/ DX POLISH(打磨每个触点)/ DX TRIAGE(只修关键缺口)。
产品团队一页纸 SOP
-
任何需求进来,先
/office-hours跑一遍(10 分钟) -
值得做 → 写 PRD 草稿(包含用户故事 / 边界 / 验收 / 非目标)
-
/plan-ceo-review+/plan-design-review双轮评审 -
用 Figma MCP 基于 PRD 出原型,反向丢给 Claude 检查一致性
-
沉淀:把本次评审里反复出现的"漏项"写进项目的 PRD 模板,下次起点就高一格
5.2 研发团队:从需求到可上线代码
目标工作流:读 PRD → 锁架构 → TDD 写代码 → 多模型对抗 review → 预合并校验 → ship → 监控 → 复盘。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
flowchart LR
A[PRD] --> B["/plan-eng-review<br/>锁架构"]
B --> C[TDD 实现]
C --> D["/codex review<br/>多模型对抗"]
D --> E["/review<br/>预合并扫描"]
E --> F["/ship<br/>一键发 PR"]
F --> G["/land-and-deploy<br/>合并+部署+验证"]
G --> H["/canary<br/>发布后金丝雀"]
H --> I["/retro<br/>周度复盘"]
I --> J["/health<br/>质量仪表盘"]
命令详解
/plan-eng-review —— 工程经理模式 plan 评审
锁定执行计划:架构、数据流、图表、边界场景、测试覆盖、性能。交互式走过每个问题并给出意见。适合"动手写代码前的最后一道闸"。
输出:按维度的 issue 列表 + 推荐修订。
/codex review | challenge | consult —— OpenAI Codex CLI 三模式
把 Claude 和 Codex 放一起互相挑刺。三种子模式:
- review:独立 diff 评审,给 pass / fail 闸门
- challenge:对抗模式,Codex 尝试打破你的代码
- consult:问 Codex 任何事,会话延续
核心思想:不同模型盲区不一样,交叉火力逼出真问题。
/review —— 预合并 PR 评审
分析 diff 对比基础分支,专挑结构性问题:SQL 注入 / 安全边界、LLM 信任边界违反、条件副作用、隐藏状态变更。
输出:按严重度排序的 issue 列表,建议在合并前修掉哪些。
/ship —— 一键发 PR
自动检测并合并基础分支 → 跑测试 → review diff → bump VERSION → 更新 CHANGELOG → commit → push → create PR。一条命令搞定。
/land-and-deploy —— 合并 + 部署 + 验证
接在 /ship 后面:合并 PR → 等 CI 和部署 → 通过金丝雀检查验证生产环境健康。
/canary —— 发布后金丝雀监控
用无头浏览器守护进程监视线上 app 的控制台错误、性能回归、页面失败。周期截图对比发布前基线。
/investigate —— 系统性调试(带根因调查)
四阶段:investigate → analyze → hypothesize → implement。铁律:没有根因不修。
用法:/investigate 生产环境登录接口偶发 500
/retro —— 每周工程复盘
分析提交历史、工作模式、代码质量指标,按人分解贡献(赞扬 + 待成长点)。持久化历史和趋势。
/health —— 代码质量仪表盘
封装现有项目工具(类型检查 / linter / 测试 / 死代码 / shell lint),计算加权复合 0-10 分数,跟踪趋势。
/simplify —— 代码简化
审查已变更代码的复用、质量、效率,然后修复发现的问题。适合 PR 合并前的最后一遍自清理。
/document-release —— 上线后文档更新
读所有项目文档、交叉引用 diff,更新 README / ARCHITECTURE / CONTRIBUTING 等文档使其匹配已发布内容。
研发团队一页纸 SOP
-
拿到 PRD →
/plan-eng-review锁架构 -
写代码走 TDD(用
test-driven-developmentskill) -
完成后
/codex challenge+/review双层扫描 -
/ship出 PR →/land-and-deploy合并部署 →/canary盯一小时 -
出 bug →
/investigate走根因四阶段 -
每周
/retro+/health看趋势 -
上线后
/document-release同步文档
5.3 测试团队:从用例矩阵到缺陷闭环
目标工作流:读 PRD+代码 → 生成用例矩阵 → 浏览器 MCP 跑自动化 → 缺陷报告 → 回归。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
flowchart LR
A[PRD + 代码] --> B["/qa-only<br/>生成用例 & 报告"]
B --> C["/setup-browser-cookies<br/>浏览器上下文"]
C --> D["/qa<br/>测试+修 bug"]
D --> E["/design-review<br/>视觉一致性"]
E --> F["/benchmark<br/>性能基线"]
F --> G["缺陷闭环同步<br/>(Meegle MCP)"]
命令详解
/qa —— 系统性 QA 测试 + 修 bug
跑 QA → 迭代修 bug → 每个修复 atomic commit → 重新验证。三档:
- Quick:只看严重 / 高风险
- Standard:+ 中风险
- Exhaustive:+ 外观 / 细节
输出:发布前 / 发布后健康分数、修复证据、可发布就绪摘要。
/qa-only —— 仅报告 QA
只产出结构化报告(健康分 + 截图 + 复现步骤),绝不修改任何代码。适合测试同学独立评估。
用法:/qa-only https://staging.example.com
/browse —— 快速无头浏览器
导航 URL、点击元素、验证状态、前后对比、截图、测试响应式、表单、上传、对话框、断言状态。约 100ms 每命令。
/setup-browser-cookies —— 导入浏览器 cookie
从真实 Chromium 浏览器导入 cookie 到无头 browse 会话。测试登录态场景前必跑。
/design-review —— 设计师视角 QA
找视觉不一致、间距、层级、AI slop 模式、慢交互,然后迭代修复并附前后截图。
/benchmark —— 性能回归检测
建立页面加载、Core Web Vitals、资源大小基线。每次 PR 对比前后,跟踪趋势。
/investigate —— 根因调查
测试团队用它处理"重现不稳定"的 bug:走 investigate → analyze → hypothesize → implement 四步,不靠猜。
测试团队一页纸 SOP
-
提测前拿到 PRD + 代码 →
/qa-only生成初步用例 + 报告 -
跑全量前先
/setup-browser-cookies导登录态 -
/qa标准档或详尽档执行 + 自动修可修的问题 -
上线前
/design-review+/benchmark过视觉和性能闸 -
缺陷 → 通过 Meegle MCP(如果接入)双向同步到用例矩阵
-
线上侧
/canary配合盯稳定性
Part 6:反向思考——如何让每个阶段产出产品级交付物
前面讲了方法和工具。最后一章做反向工程:如果目标是"交付产品级"(不是"能跑就行"),每个阶段到底要固化什么?
每个阶段同时回答三个问题:
-
交付产物必须包含哪些项——列出清单,勾够才算过
-
需要固定哪些上下文——放哪些文件 / 文档在项目里,让 AI 每次都能读到
-
Prompt 如何引导——用什么样的模板让 AI 直接产出合格品
元规则(贯穿四个阶段):
每个交付物都要问自己——下一个环节的人和下一个环节的 AI,能不能不问我,直接消费它?
6.1 需求期
必须交付的项:
- 用户故事:
As a <角色> I want <动作> So that <价值>,至少 5 条 - 边界场景清单:并发 / 空值 / 极限 / 权限 / 跨时区跨月等,至少 5 条
- 异常流程 + 兜底策略:每条至少有一级兜底
- 验收标准:可测、可量化,每条绑定到对应用户故事 ID
- 非目标声明:明确本期不做什么,避免实现走偏
- 可点击原型:覆盖主流程,每页标注对应用户故事 ID
需要固定的上下文(放在项目根目录,AI 每次能读到):
docs/domain-glossary.md——领域术语表(订单 / 工单 / 交易凭证等边界定义)docs/business-rules.md——隐性业务规则沉淀(“客户在某某场景下不能 xx”)docs/PRD-template.md——PRD 模板,含上面 6 项空白项docs/past-decisions/——历史决策归档(为什么当时选 A 而不是 B)docs/users/——用户画像 / 场景档案
Prompt 引导模板:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
角色:你是我们项目的高级产品经理,了解 docs/domain-glossary.md 里的术语边界。
任务:基于下面一句话需求,产出一份结构化 PRD 草稿。
约束:
- 必须使用 docs/PRD-template.md 的模板
- 至少穷举 5 个边界场景,每个边界场景标注触发条件和期望行为
- 验收标准与用户故事双向绑定
- 所有业务规则都要引用 docs/business-rules.md 里的对应条款
- 不清楚的地方列在"待澄清"章节,不要硬编
一句话需求:{NEED}
6.2 研发期
必须交付的项:
- 技术方案文档:数据模型、关键接口契约、错误码表、三方依赖清单
- 关键决策记录:为什么选这个方案、放弃了哪些方案、权衡理由(ADR 形式)
- 可编译通过的代码:主干 CI 绿灯,关键路径单测覆盖
- 提测说明书:影响范围(改了哪些接口 / 页面 / 数据表)、迁移脚本、开关 / 灰度、已知限制
- 冒烟通过证据:自动化冒烟报告
- AI 可读契约:OpenAPI / JSON schema / TypeScript 类型导出
需要固定的上下文:
- AI 工作手册(如
CLAUDE.md或AGENTS.md)——项目的代码风格、禁用 API、命名约定 docs/architecture.md——系统架构、模块边界docs/adr/——架构决策记录docs/api-contracts/——接口契约导出- 强制规则文件(如
.cursor/rules/或.claude/rules/) examples/——团队范例代码(AI 模仿的基准)
Prompt 引导模板:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
角色:你是我们项目的资深工程师,熟悉 AI 工作手册里的代码规范和 docs/architecture.md 里的模块边界。
任务:基于 PRD 实现 <功能模块>。
约束:
- 先读 docs/architecture.md 和 examples/ 对齐风格
- 走 TDD:先写测试(引用验收标准里的场景)再写实现
- 所有新接口必须同步更新 docs/api-contracts/
- 每个关键决策写一条 ADR 放到 docs/adr/
- 完成前必须通过 verification-before-completion skill(跑 build/test/lint)
- 改了数据库结构必须同步生成迁移脚本,并在提测说明书里列出
PRD:{PRD_PATH}
6.3 测试期
必须交付的项:
- 用例矩阵:正常 / 异常 / 边界三分,每条带覆盖率和未覆盖原因
- 缺陷闭环表:每个 bug 对应用例 ID + 修复 commit + 回归结果
- 性能基线:关键接口 P95 / P99、前端关键页面 FCP / LCP
- 风险评估报告:剩余风险分级(高 / 中 / 低)+ 线上应对预案
- 真机测试记录:低端机 / 弱网 / 边缘环境的实测数据
- 探索式测试摘要:AI 未覆盖但值得报的发现
需要固定的上下文:
docs/test-strategy.md——测试策略(按业务模块定的测试密度)docs/test-templates/——用例模板(三分法 / 状态机 / 等价类)docs/defect-categorization.md——缺陷分级规则test-matrix/——历史用例矩阵(供 AI 参考扩展)benchmarks/——性能基线历史数据
Prompt 引导模板:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
角色:你是我们项目的测试架构师,熟悉 docs/test-strategy.md 的分级规则。
任务:基于 PRD 和代码 diff,生成用例矩阵并执行。
约束:
- 按三分法组织:正常流 / 异常流 / 边界流
- 每条用例标注:优先级、预期结果、关联用户故事 ID、自动化可达性
- 边界场景必须覆盖 PRD 里列出的全部 N 条
- 用 docs/test-templates/state-machine.md 穷举状态迁移
- 先出矩阵让我 review 再执行
- 缺陷按 docs/defect-categorization.md 分级
PRD:{PRD_PATH}
代码 diff:{DIFF_PATH}
6.4 发布期
必须交付的项:
- 上线文档:变更摘要、回滚命令、影响用户范围、公告文案
- 监控看板配置:业务指标 + 系统指标 + 告警阈值
- 回滚预案:回滚条件、触发人、操作步骤,发布前必须演练一次
- 金丝雀策略:灰度比例、观察指标、收敛条件
- 复盘模板:发布后 N 天内自动收集指标变化
需要固定的上下文:
docs/release-playbook.md——发布 playbookdocs/rollback-scenarios.md——历史回滚案例库docs/monitoring-baseline.md——关键指标基线ops/runbooks/——运维 SOPops/alert-rules/——告警阈值配置
Prompt 引导模板:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
角色:你是我们项目的发布负责人,熟悉 docs/release-playbook.md 和历史回滚案例。
任务:基于本次 PR 的 diff,生成上线文档和回滚预案。
约束:
- 变更摘要要能让非本次参与人 2 分钟看懂影响范围
- 回滚命令必须可直接执行(不是"回滚到上个版本"这种模糊描述)
- 比对 docs/monitoring-baseline.md,列出需要额外盯的新指标
- 参考 docs/rollback-scenarios.md,评估本次变更的回滚复杂度(简单/复杂/不可回滚)
- 如果判定"不可回滚",必须给出前向修复预案
- 发布后 3 天的自动复盘要关注哪些指标
PR:{PR_URL}
贯穿四阶段的 Context Pack
上面每个阶段的"固定上下文"汇总起来,就是一个团队级的 Context Pack——AI 时代团队知识沉淀的新形态。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
repo-root/
├── CLAUDE.md / AGENTS.md # AI 工作手册
├── docs/
│ ├── domain-glossary.md # 领域术语
│ ├── business-rules.md # 隐性业务规则
│ ├── architecture.md # 系统架构
│ ├── PRD-template.md # PRD 模板
│ ├── test-strategy.md # 测试策略
│ ├── release-playbook.md # 发布 playbook
│ ├── monitoring-baseline.md # 指标基线
│ ├── adr/ # 架构决策记录
│ ├── api-contracts/ # 接口契约
│ ├── test-templates/ # 测试模板
│ └── past-decisions/ # 历史决策
├── examples/ # 团队范例代码
├── test-matrix/ # 历史用例矩阵
├── benchmarks/ # 性能基线历史
└── ops/
├── runbooks/ # 运维 SOP
└── alert-rules/ # 告警阈值
一次性建立,持续复利。二期需求来的时候,AI 能直接消费这些上下文,不必每次重头解释。
结语:复利曲线
回到 Part 4.2 的两个工程师。一年之后:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
xychart-beta
title "工程师 A vs 工程师 B 产能曲线(示意)"
x-axis ["1月", "3月", "6月", "12月"]
y-axis "相对产能" 0 --> 100
line [10, 15, 20, 25]
line [12, 30, 55, 90]
A 的曲线是平的。B 的曲线在抬升——每一份沉淀都在给未来打折扣。
差距不是天赋,是方法论。
工具不重要,工作流才重要。
AI 时代,提示词工程已经退居二线。工程化思维才是新的护城河。
如果这篇只记住一件事:
你不是在跟 AI 比谁写得快。你是在设计一套系统,让 AI 的聪明被你的纪律放大,而不是被你的混乱放大。
最后
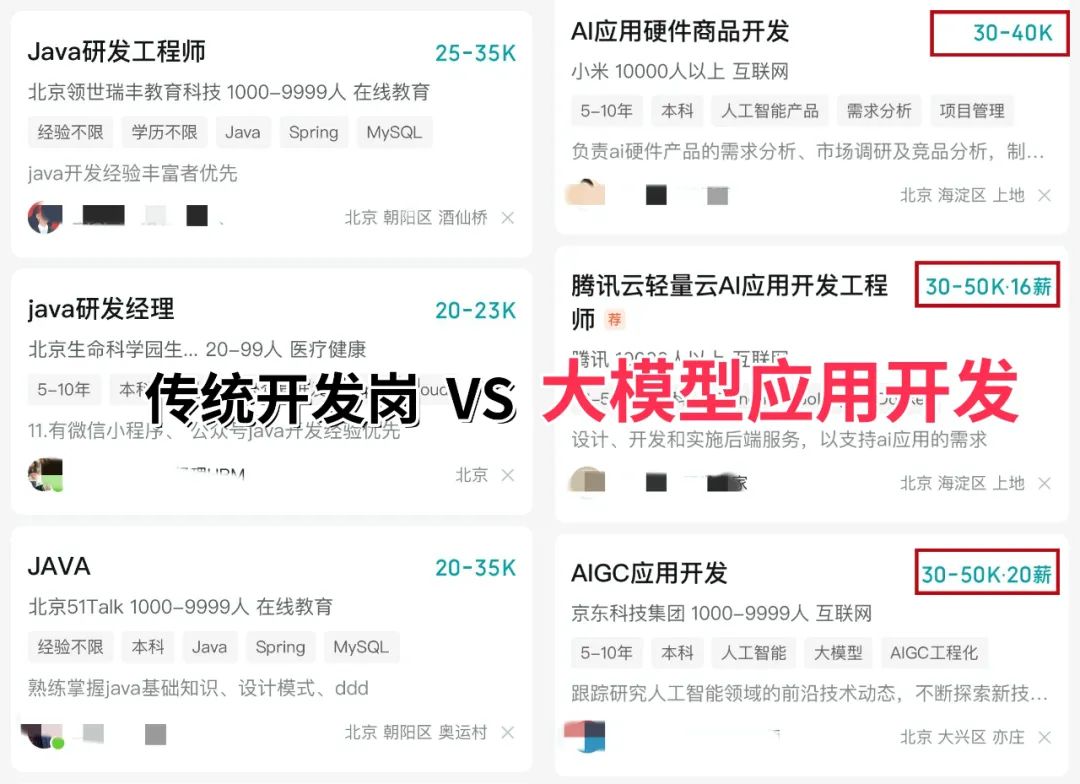
2026年技术圈的分化愈发明显:降薪裁员潮持续蔓延,传统开发、测试等岗位大批缩水,不少从业者陷入职业焦虑;与之形成鲜明对比的是,AI大模型相关岗位迎来疯狂扩招,薪资逆势飙升150%,大厂更是直接开出70-100W年薪,疯抢具备实战能力的大模型人才,甚至放宽年龄限制,只求能快速落地技术、创造价值!
很多程序员、职场新人纷纷入局大模型领域,绝非盲目跟风,而是实实在在看到了不可替代的价值优势,这也是2026年最值得抓住的职业风口:
1、窗口期红利,入门门槛友好:不同于成熟赛道的“内卷式招聘”,2026年大模型人才缺口巨大,简历只要达标(掌握基础AI应用+具备简单项目经验),年龄、学历均非硬性要求,小白可快速入门,转行程序员也能无缝衔接;
2、技术可复用,上手速度翻倍:如果你有前后端开发、测试、数据分析等基础,在大模型落地、系统部署、Prompt工程等环节会更具优势,无需从零开始,复用原有技术能力就能快速进阶;
3、懂业务更吃香,竞争力翻倍:单纯懂技术已不够,2026年大厂更看重“技术+业务”的复合型人才,有垂直领域(金融、医疗、工业等)经验者,能精准定位模型落地痛点,薪资比纯技术岗高出30%以上;
更重要的是,即便没有转型需求,用AI大模型工具为工作赋能、提升效率,也已经成为80%企业的硬性要求——不会用大模型提效,未来很可能被行业淘汰!
那么2026年,小白/程序员该如何高效学习大模型?
很多人想入门大模型,却陷入两大困境:要么到处搜集零散资料,不成体系,越学越懵;要么被收费高昂的课程割韭菜,花了钱却学不到实战技能,白白浪费时间走弯路。
今天就给大家精心整理了一份2026年最新、免费、系统化的AI大模型学习资源包,覆盖从零基础入门到商业实战、从理论沉淀到面试通关的全流程,所有资料均已整理归档,无需拼凑,直接领取就能上手学习,小白可照做,程序员可进阶!

👇👇扫码免费领取全部内容👇👇

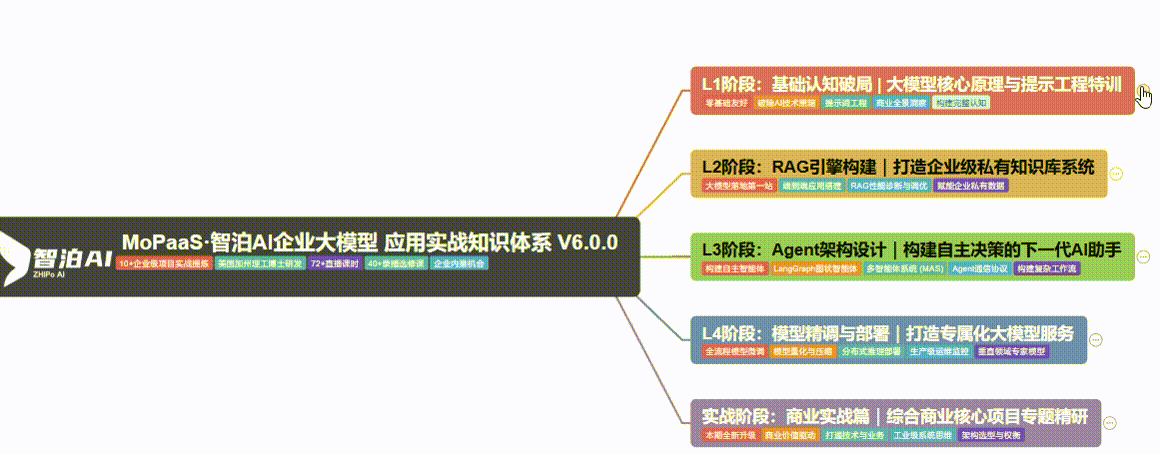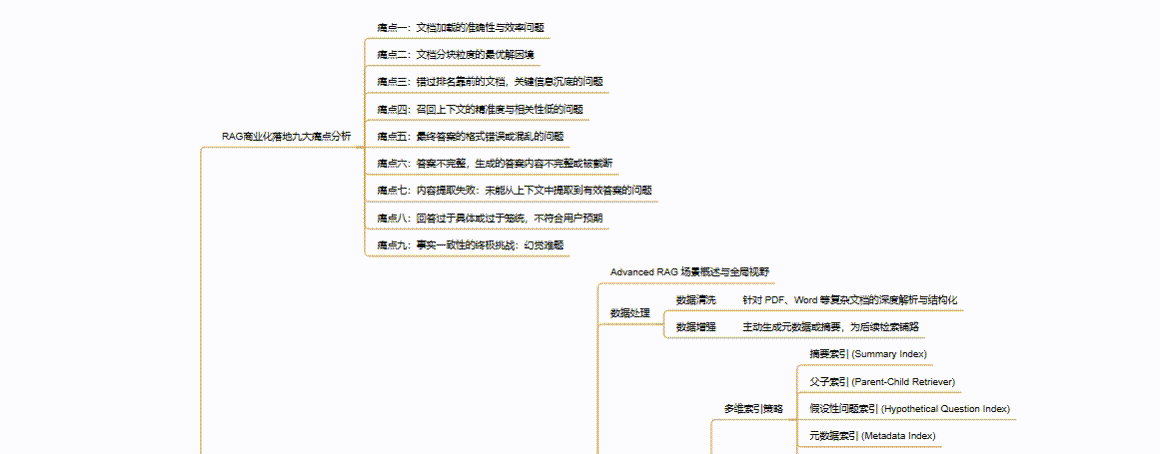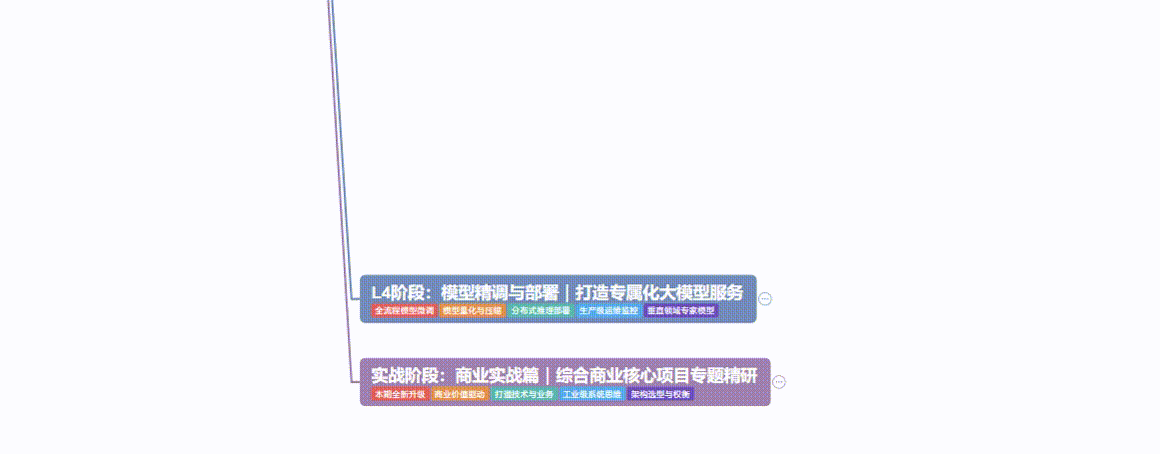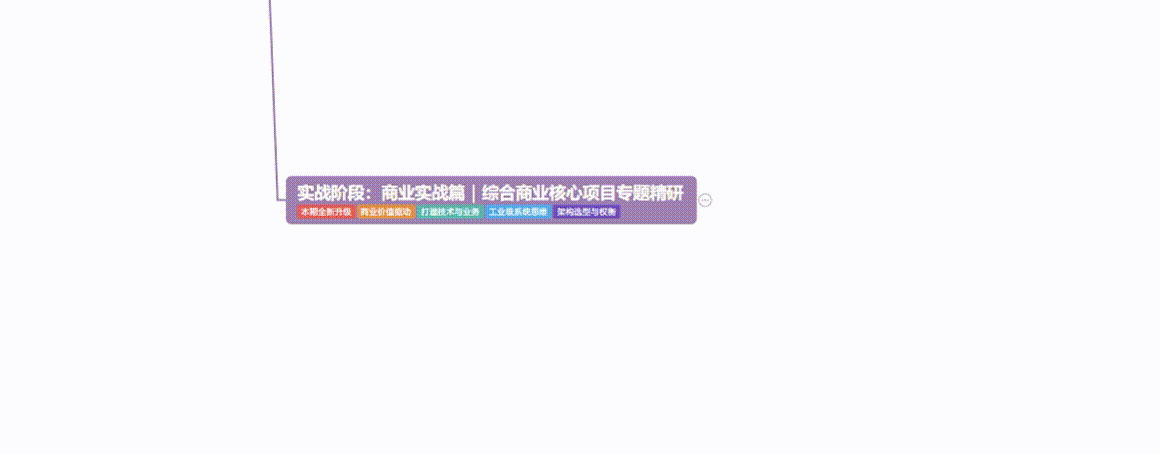
1、大模型系统化学习路线
这份学习路线结合2026年行业趋势和新手学习规律,由行业专家精心设计,从零基础到精通,每一步都有明确指引,帮你节省80%的无效学习时间,少走弯路、高效进阶,避免踩坑。
2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、大模型学习书籍&电子文档
涵盖2026年最新技术要点,包括基础入门、Transformer核心原理、Prompt工程、RAG实战、模型微调与部署等内容

4、AI大模型最新行业报告
报告包含腾讯、阿里、甲子光年等权威机构发布的核心内容,还有2026年中文大模型基准测评报告、AI Agent行业研究报告等,帮你站在行业前沿,把握技术风口。

5、大模型项目实战&配套源码
项目包含Deepseek R1、GPT项目、MCP项目、RAG实战等热门方向,还有视频配套代码,手把手教你从0到1完成项目开发,既能练手提升技术,又能丰富简历,为求职和职业发展加分。

6、2026大模型大厂面试真题
2026年大模型面试已全面升级,不再单纯考察基础原理,而是转向侧重技术落地和业务结合的综合考察,很多程序员和新手因为缺乏针对性准备,明明技术不错,却在面试中失利。

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
7、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献260条内容
已为社区贡献260条内容

所有评论(0)