Attention机制
Attention机制
传统的 Seq2Seq 模型中,编码器在处理源句时,无论其长度如何,最终都只能将整句信息压缩为一个固定长度的上下文向量,用作解码器的唯一参考。这种设计存在两个显著问题:
- 信息压缩困难
- 缺乏动态感知
为了解决这些问题,引入了 Attention 机制:
解码器在生成目标序列的每一步时,不再依赖静态的上下文向量,而是根据当前的解码状态,动态地从编码器各时间步的隐藏状态中选取最相关的信息,以辅助当前步的生成。这种机制赋予模型“对齐”能力,使其能够自动判断源句中哪些位置对当前的目标词更为重要,从而有效缓解信息瓶颈问题,提升生成质量与表达能力。
工作原理
注意力机制的核心思想是,解码器在生成目标序列的每一步,动态地从编码器的各个时间步的隐藏状态中提取当前的所需信息,而不再只依赖一个固定的上下文向量。
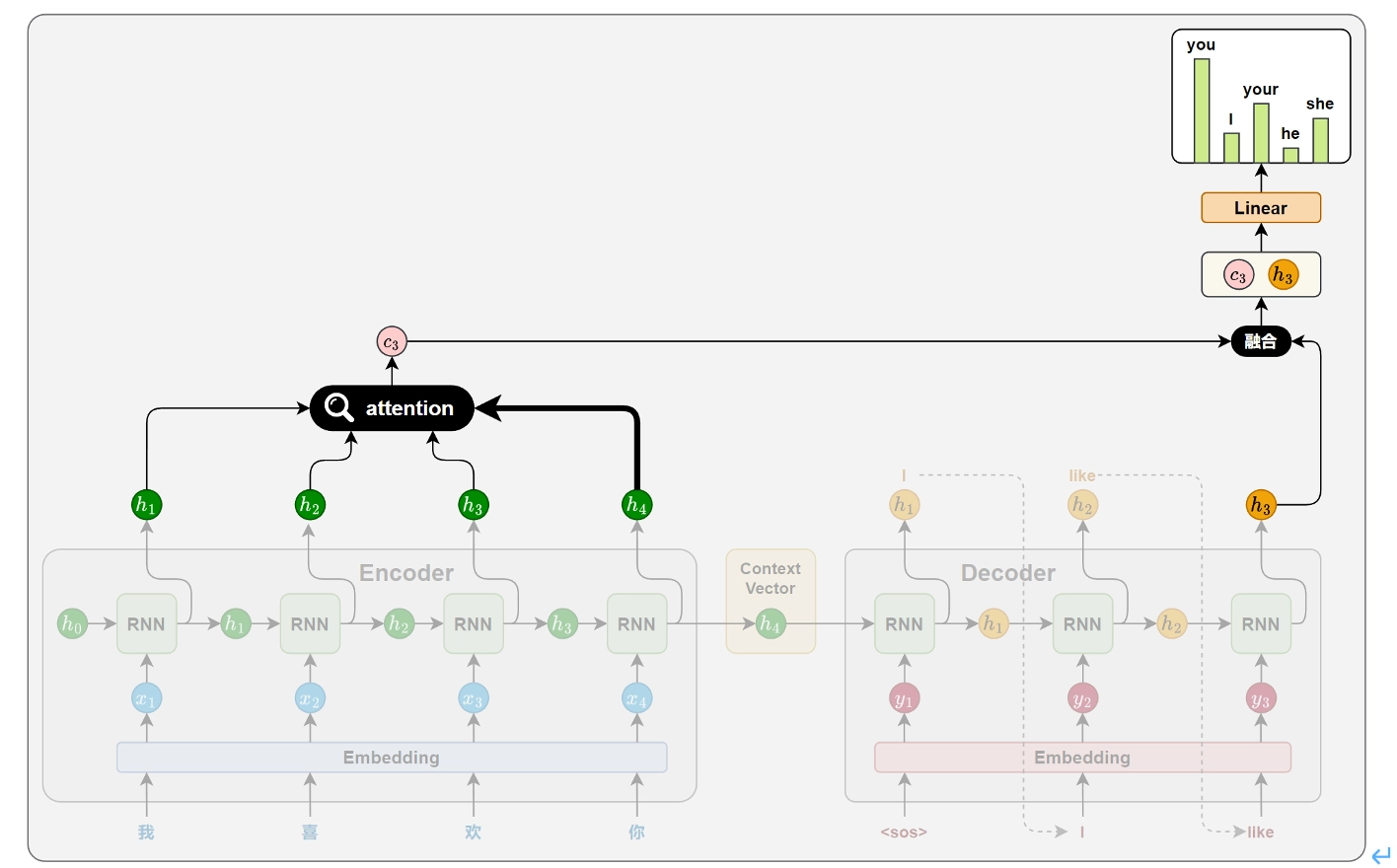
相关性计算
在目标序列生成的每步,解码器都会计算当前步的隐藏状态与编码器各个时间步输出之间的相关性,这些相关性它衡量了原句中每个位置对当前生成内容重要程度,从而决定模型应当多少注意力分配给不同的源位置,相关性的计算依赖于特定的函数,通常被称为注意力评分函数。
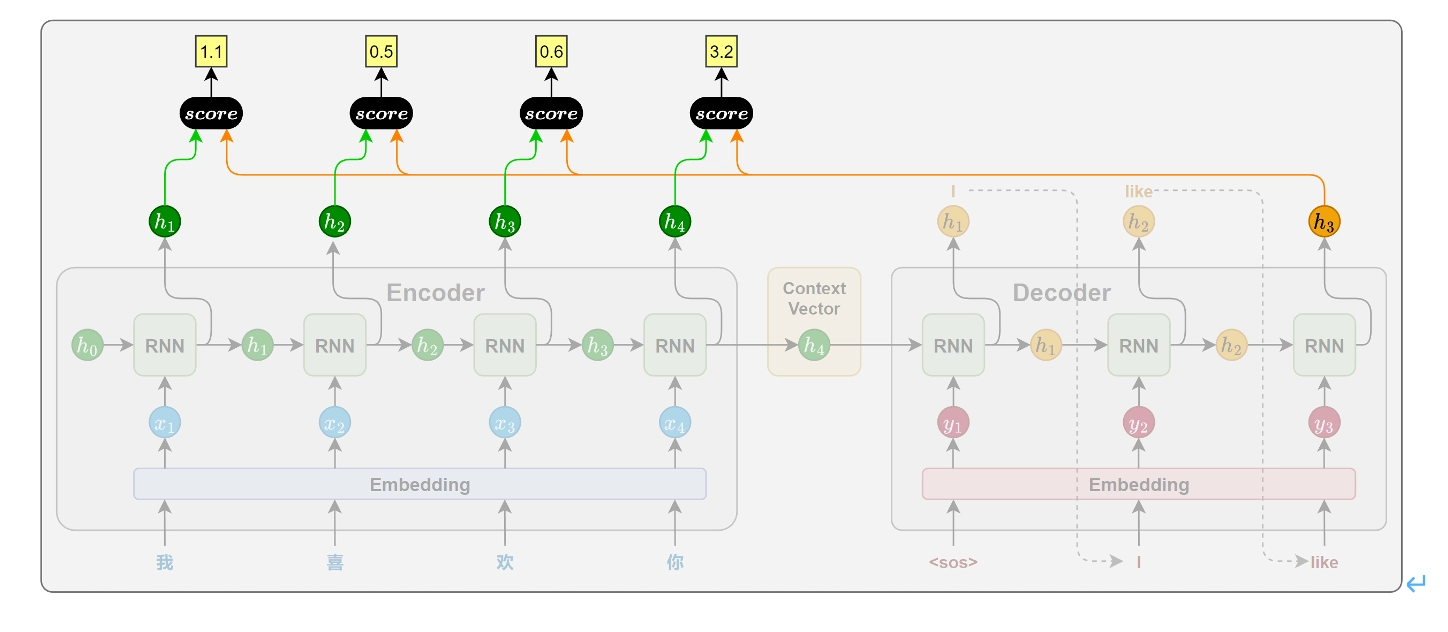
注意力评分函数的计算方法
- 缩放点积注意力(Scaled Dot-Product Attention)
Transformer / GPT / BERT 等几乎所有现代大模型的标配
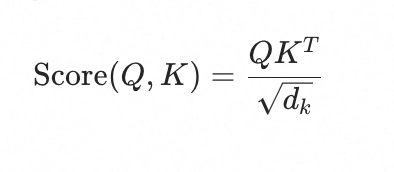
- 计算过程:Query 和 Key 做矩阵乘法(点积),然后除以 dk (Key 的维度开根号)
- 为什么要缩放? 当 dk 较大时,点积结果的方差会变大,导致 softmax 进入梯度极小的饱和区,反向传播时梯度消失。除以 dk 使方差回到稳定范围
- 优点:计算高效,可完全并行化(矩阵乘法),GPU 友好
- 直觉:两个向量方向越一致、模长越大,点积越大 → 相关性越高
- 加性注意力(Additive / Bahdanau Attention)
原始 Seq2Seq with Attention (2014) 使用,RNN 时代的经典
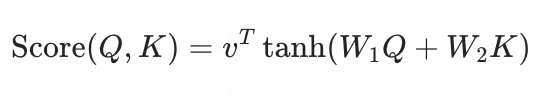
- 计算过程:将 Q 和 K 分别线性变换后相加,过 tanh 激活,再用一个可学习向量 v 做内积得到标量分数
- 优点:不要求 Q 和 K 维度相同;非线性变换可以捕捉更复杂的匹配模式
- 缺点:无法用矩阵乘法批量并行计算,速度远慢于点积
- 直觉:通过一个小型前馈网络来"学习"如何判断 Q 和 K 的相关性,而非简单的几何相似度
注意力权重计算
得到所有源位置的注意力评分后,用 softmax 函数将其归一化为概率分布,作为注意力权重。得分越高的位置,其对应的权重越大,代表模型在当前生成中更关注该位置的信息
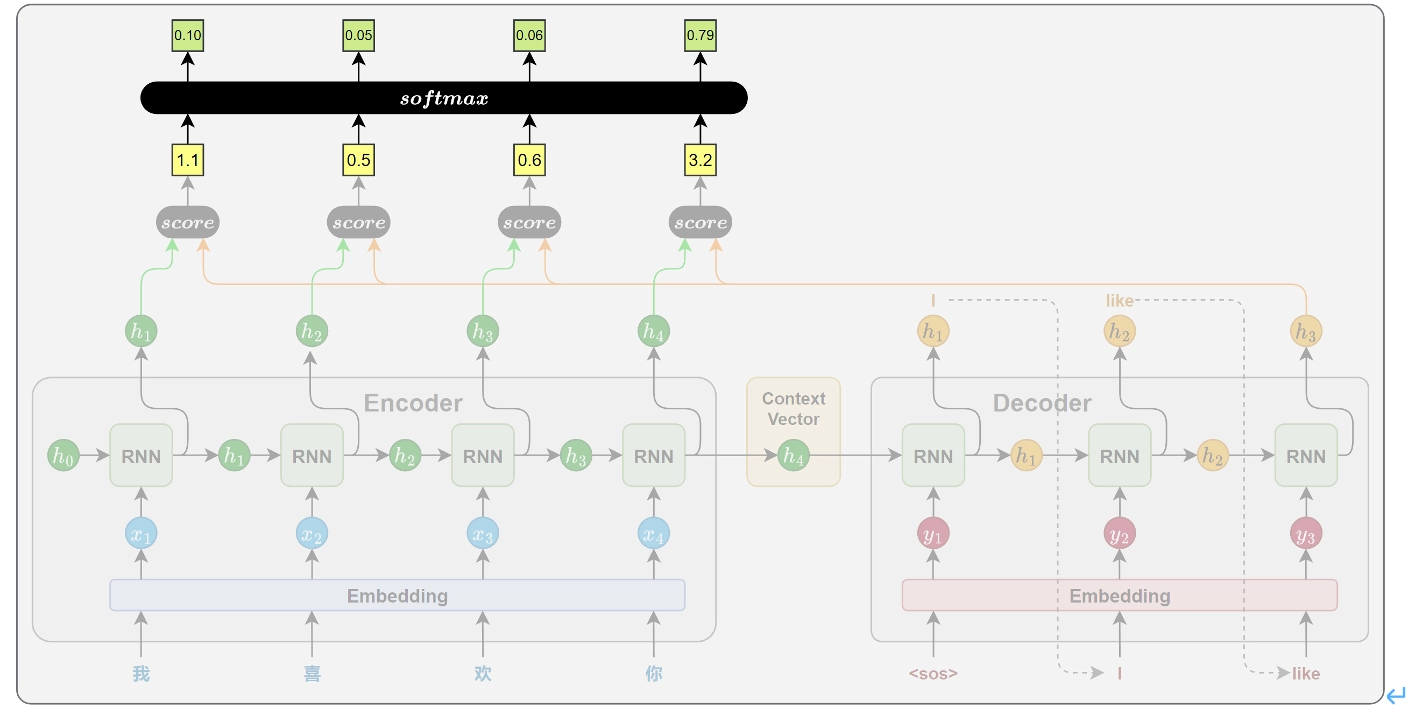
上下文向量计算
将所有编码器输出按照注意力权重进行加权求和,得到一个上下文向量,这个向量就表示当前时间步,模型从源句中提取出的关键信息。
注意力机制的具体计算过程
目标设定
我们要翻译一句话:
英文源句:I love cats(3个词)
目标译文:我喜欢猫(3个汉字)
模型结构:
- Encoder:处理输入
"I love cats"→ 输出 3 个向量(对应每个词) - Decoder:逐词生成
"我"→"喜"→"欢"→"猫"(实际是<s> 我 喜 欢 猫 </s>,但为简化,我们聚焦第2步生成“喜”)
我们重点讲解 Decoder 在生成第2个词“喜”时,如何通过注意力机制决定“看源句哪部分”。
第一步:准备数据 —— 向量化表示
1.1 输入嵌入(Embedding)
每个词被映射为一个固定维度的向量(比如维度 d=4d=4d=4,为便于计算,我们用小数字演示):
| 词 | Embedding(简化为 2D) |
|---|---|
| I | e1=[1.0,0.0]e_1 = [1.0, 0.0]e1=[1.0,0.0] |
| love | e2=[0.5,0.8]e_2 = [0.5, 0.8]e2=[0.5,0.8] |
| cats | e3=[0.2,1.0]e_3 = [0.2, 1.0]e3=[0.2,1.0] |
✅ 实际中是高维(如 512/768),这里用 2D 便于手算。
1.2 Encoder 编码
Encoder(多层 Transformer Encoder)对输入序列进行处理,输出上下文感知的隐藏状态:
假设 Encoder 最终输出(已含上下文信息):
- h1enc=[0.9,0.1]h_1^{\text{enc}} = [0.9, 0.1]h1enc=[0.9,0.1] ← “I” 的编码(受全句影响)
- h2enc=[0.3,0.7]h_2^{\text{enc}} = [0.3, 0.7]h2enc=[0.3,0.7] ← “love” 的编码
- h3enc=[0.1,0.9]h_3^{\text{enc}} = [0.1, 0.9]h3enc=[0.1,0.9] ← “cats” 的编码
💡 注意:这些不是原始 embedding,而是经过 Encoder 多层自注意力后得到的、融合了整句语义的表示。
第二步:构建 Query、Key、Value
注意力机制的核心是三元组:Query (Q)、Key (K)、Value (V)
在 Cross-Attention 中:
- Query 来自 Decoder 当前状态
- Key 和 Value 来自 Encoder 输出
2.1 Decoder 当前状态(生成第2个词“喜”时)
Decoder 已生成第一个词 <s> 和 "我",其当前隐藏状态为 s2=[0.6,0.4]s_2 = [0.6, 0.4]s2=[0.6,0.4]
→ 将 s2s_2s2通过一个线性变换(权重矩阵 WQW_QWQ)得到 Query:
Q=s2WQ=[0.6,0.4]⋅[10 01]=[0.6,0.4]Q = s_2 W_Q = [0.6, 0.4] \cdot \begin{bmatrix} 1 & 0 \ 0 & 1 \end{bmatrix} = [0.6, 0.4]Q=s2WQ=[0.6,0.4]⋅[10 01]=[0.6,0.4]
(为简化,设 WQ=IW_Q = IWQ=I,即恒等变换)
2.2 Key 和 Value 来自 Encoder 输出
对每个编码器输出 hiench_i^{\text{enc}}hienc,分别用两个线性变换得到 K 和 V:
设:
- WK=[10 01]W_K = \begin{bmatrix} 1 & 0 \ 0 & 1 \end{bmatrix}WK=[10 01](同样恒等)
- WV=[10 01]W_V = \begin{bmatrix} 1 & 0 \ 0 & 1 \end{bmatrix}WV=[10 01]
所以:K 和 V 在此例中与 Encoder 输出相同(仅为简化;实际中通常不同)
第三步:计算注意力评分(Score)
使用 缩放点积注意力(标准做法):
scorei=Q⋅Kidk\text{score}_i = \frac{Q \cdot K_i}{\sqrt{d_k}}scorei=dkQ⋅Ki
其中:
- dk=2d_k = 2dk=2(Key 维度)
- dk=2≈1.414\sqrt{d_k} = \sqrt{2} \approx 1.414dk=2≈1.414
计算每个位置的分数:
| i | Q⋅KiQ \cdot K_iQ⋅Ki | scorei=Q⋅Ki2\text{score}_i = \frac{Q \cdot K_i}{\sqrt{2}}scorei=2Q⋅Ki |
|---|---|---|
| 1 | 0.6×0.9+0.4×0.1=0.54+0.04=0.580.6×0.9 + 0.4×0.1 = 0.54 + 0.04 = 0.580.6×0.9+0.4×0.1=0.54+0.04=0.58 | 0.58/1.414≈0.4100.58 / 1.414 ≈ 0.4100.58/1.414≈0.410 |
| 2 | 0.6×0.3+0.4×0.7=0.18+0.28=0.460.6×0.3 + 0.4×0.7 = 0.18 + 0.28 = 0.460.6×0.3+0.4×0.7=0.18+0.28=0.46 | 0.46/1.414≈0.3250.46 / 1.414 ≈ 0.3250.46/1.414≈0.325 |
| 3 | 0.6×0.1+0.4×0.9=0.06+0.36=0.420.6×0.1 + 0.4×0.9 = 0.06 + 0.36 = 0.420.6×0.1+0.4×0.9=0.06+0.36=0.42 | 0.42/1.414≈0.2970.42 / 1.414 ≈ 0.2970.42/1.414≈0.297 |
✅ 得到未归一化的评分向量:
Scores=[0.410, 0.325, 0.297] \text{Scores} = [0.410,\ 0.325,\ 0.297] Scores=[0.410, 0.325, 0.297]
🔍 观察:位置1(“I”)得分最高 → 因为 Query
[0.6,0.4]更接近 Key1[0.9,0.1](x轴大,y轴小),几何上夹角小。
第四步:Softmax 归一化 → 注意力权重
将 scores 输入 softmax,得到概率分布(权重):
αi=escorei∑jescorej \alpha_i = \frac{e^{\text{score}_i}}{\sum_j e^{\text{score}_j}} αi=∑jescorejescorei
先计算指数:
- e0.410≈1.507e^{0.410} ≈ 1.507e0.410≈1.507
- e0.325≈1.384e^{0.325} ≈ 1.384e0.325≈1.384
- e0.297≈1.346e^{0.297} ≈ 1.346e0.297≈1.346
分母:1.507+1.384+1.346=4.2371.507 + 1.384 + 1.346 = 4.2371.507+1.384+1.346=4.237
所以权重:
| i | αi\alpha_iαi |
|---|---|
| 1 | 1.507/4.237≈0.3561.507 / 4.237 ≈ 0.3561.507/4.237≈0.356 |
| 2 | 1.384/4.237≈0.3271.384 / 4.237 ≈ 0.3271.384/4.237≈0.327 |
| 3 | 1.346/4.237≈0.3181.346 / 4.237 ≈ 0.3181.346/4.237≈0.318 |
✅ 注意力权重:
α=[0.356, 0.327, 0.318] \boldsymbol{\alpha} = [0.356,\ 0.327,\ 0.318] α=[0.356, 0.327, 0.318]
→ 模型在生成“喜”时,最关注源句第1个词“I”(35.6%),其次“love”,最后“cats”。
为什么不是“love”最重要?因为当前 Decoder 状态 s2=[0.6,0.4]s_2=[0.6,0.4]s2=[0.6,0.4] 更偏向主语“I”,可能还在构建主谓结构(如“我…”),尚未聚焦动词。
第五步:加权求和 → 上下文向量
用权重 αi\alpha_iαi 对 Value 向量加权求和:
c2=∑i=13αi⋅Vi c_2 = \sum_{i=1}^3 \alpha_i \cdot V_i c2=i=1∑3αi⋅Vi
计算:
- α1V1=0.356×[0.9,0.1]=[0.320,0.036]\alpha_1 V_1 = 0.356 × [0.9, 0.1] = [0.320, 0.036]α1V1=0.356×[0.9,0.1]=[0.320,0.036]
- α2V2=0.327×[0.3,0.7]=[0.098,0.229]\alpha_2 V_2 = 0.327 × [0.3, 0.7] = [0.098, 0.229]α2V2=0.327×[0.3,0.7]=[0.098,0.229]
- α3V3=0.318×[0.1,0.9]=[0.032,0.286]\alpha_3 V_3 = 0.318 × [0.1, 0.9] = [0.032, 0.286]α3V3=0.318×[0.1,0.9]=[0.032,0.286]
相加:
c2=[0.320+0.098+0.032, 0.036+0.229+0.286]=[0.450, 0.551] c_2 = [0.320+0.098+0.032,\ 0.036+0.229+0.286] = [0.450,\ 0.551] c2=[0.320+0.098+0.032, 0.036+0.229+0.286]=[0.450, 0.551]
最终上下文向量:
c2=[0.45, 0.55] \boxed{c_2 = [0.45,\ 0.55]} c2=[0.45, 0.55]
这个向量就是 Decoder 在生成“喜”时,从源句中提炼出的核心信息摘要。
第六步:上下文向量如何参与预测?
Decoder 将 c2c_2c2 与自身当前状态 s2=[0.6,0.4]s_2 = [0.6, 0.4]s2=[0.6,0.4] 结合,常见方式有:
- 拼接:[s2;c2]=[0.6,0.4,0.45,0.55][s_2; c_2] = [0.6, 0.4, 0.45, 0.55][s2;c2]=[0.6,0.4,0.45,0.55]
- 相加:s2+c2=[1.05,0.95]s_2 + c_2 = [1.05, 0.95]s2+c2=[1.05,0.95]
- 门控融合(如 LSTM 风格)
然后输入一个前馈网络 + softmax,预测下一个 token 的概率分布:
例如:
KaTeX parse error: Expected 'EOF', got '_' at position 74: … \text{combined_̲state})
训练时,若真实词是“喜”,就用交叉熵损失优化整个链路(包括 Q/K/V 的线性变换矩阵)。
全流程图解
源句: I love cats
↓ ↓ ↓
Encoder → h₁=[0.9,0.1] h₂=[0.3,0.7] h₃=[0.1,0.9]
│ │ │
├─K₁,V₁ ├─K₂,V₂ ├─K₃,V₃
│ │ │
Decoder 当前状态 s₂ = [0.6,0.4] → Q = [0.6,0.4]
计算 Score:
Q·K₁/√2 ≈ 0.410 → α₁ = 0.356
Q·K₂/√2 ≈ 0.325 → α₂ = 0.327
Q·K₃/√2 ≈ 0.297 → α₃ = 0.318
上下文向量 c₂ = 0.356·V₁ + 0.327·V₂ + 0.318·V₃ = [0.45, 0.55]
→ 送入 Decoder 输出层 → 预测 "喜"
关键总结
-
注意力 = Q-K 匹配 + V 加权
不是“修改信息”,而是“选择并组合已有信息”。
-
Query 是“我在问什么”(Decoder 当前需求)
Key 是“你能回答什么”(Encoder 各位置能力)
Value 是“答案内容”(真正要取的信息)
-
Softmax 是归一化工具,让权重可解释为“关注比例”。
-
缩放(/√dₖ)不是可选项——它是稳定训练的关键技巧。
-
多头注意力 = 多组独立 QKV → 让模型同时关注语法、语义、指代等不同维度。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)