告别“大海捞针”:OSS Vector Bucket 如何赋能媒资管理平台
在内容创作领域,数据就是生产力。一个成熟的媒资平台需要管理海量的多模态素材:图像、视频、音频、文本……这些素材不仅是内容创作者的核心资源,更是平台后续进行模型训练的基础资源。然而,随着数据规模的指数级增长,传统的数据管理方式正面临前所未有的挑战。
想象一个场景:
设计师小张需要为某科技产品发布会找一张背景图。他的需求很明确——“科技感强、色调偏蓝、适合舞台展示”。
但在一个存储了 30 亿条素材的平台上,这个看似简单的需求,却让小张花了整整 2 个小时,翻看了上百张图片,最终还是没有找到完全满意的。
这不是虚构的故事,而是某个媒资平台的真实困境。
客户场景:某媒资平台的数据困境
某媒资内容创作平台,为创作者提供 AI 驱动的内容生成服务。平台需要管理近 10 PB 的多模态数据集,包含超过 30 亿条素材记录,每条记录携带约 30 KB 的多模态元数据,例如素材标签(背景图/壁纸/电影片段/长短剧片段/用户上传素材等)、风格特征、版权信息、质量评分等。
平台初期,数据量较小,传统的数据库加文件存储方案尚能应对。但随着用户规模快速增长,数据量突破 PB 级别,素材数量从千万突破到亿级别,问题开始集中爆发:
-
数据分散,管理混乱。不同类型的素材存储在不同的系统中,原始的图片和视频等数据存在对象存储中,字幕和弹幕等文本数据存在数据库中,版权信息存在客户线下的Excel表格中。元数据分散管理,导致数据难以统一检索和有效复用。
-
检索能力受限。平台最初采用关键词检索,但关键词匹配无法理解语义,更无法处理多模态数据的复杂查询。比如,用户输入“科技感强、适合科技产品发布会的背景图”,传统检索系统根本无法理解这种语义化的需求,只能返回零散的结果。
-
相似素材匹配难。平台积累了海量素材,但创作者经常遇到这样的困境:找到了一张满意的参考图,却找不到风格相似、构图相近的其他素材。传统系统无法理解素材的视觉特征和风格属性,设计师想要找“与这张图风格相似的背景素材”,只能人工逐张浏览筛选,在上亿条素材中犹如大海捞针。
-
扩展成本居高不下。随着数据量从 TB 级增长到 PB 级,客户的系统扩容需要不断投入硬件资源和人力成本。同时,由于数据分散,跨系统的数据流转和共享变得异常复杂,进一步推高了运维成本。
破局方案:OSS Vector Bucket 构建媒资内容管理平台
面对这些挑战,该平台决定引入阿里云 OSS Vector Bucket。通过 Vector Bucket 的向量存储和检索能力来构建统一的多模态数据集管理和智能检索平台。
方案架构:一体化数据管理
该媒资平台基于阿里云百炼的向量模型将所有多模态素材向量化,并将向量结果和相关的标量元数据统一存储到阿里云 OSS Vector Bucket 中,为每条素材自动生成向量索引,同时将元数据与向量数据映射到原始文件。通过 OSS Vector Bucket 的能力,平台构建了一个集数据存储、元数据管理、智能检索于一体的数据集智能管理平台。
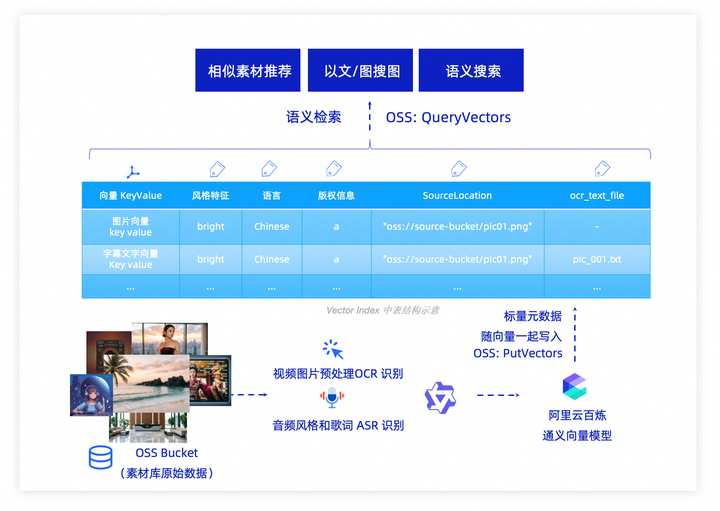
产品能力:四大核心优势
-
统一数据管理,打破数据孤岛。 平台将 Vector Bucket 和存储海量原始数据的 Object Bucket 通过相同的方式进行管理,将原本分散在对象存储、数据库、Excel 中的素材数据全部整合到统一平台,为每条素材建立丰富的元数据标签(素材类型、风格特征、版权状态、质量评分等),并实现跨业务线的数据共享。图像生成、视频剪辑、文案创作等多个业务线,以及多模态大模型训练业务,都可以基于统一的数据平台高效流转和复用素材,彻底告别“数据分散、管理混乱”的困境。
-
向量搜索与语义理解,让系统“听懂人话”。 从关键词匹配升级为向量语义检索。通过使用阿里云百炼的多模态向量模型对原始数据进行向量化处理,OSS Vector Bucket 能够理解自然语言背后的真实意图。当创作者输入“科技感强、适合科技产品发布会的背景图”时,系统不再机械匹配关键词,而是深度理解语义,从海量素材库中精准匹配相关内容。检索结果从“形似”升级为“意似”,命中率大幅提升。
-
简单易用,降低系统复杂度:通过该方案,平台方可以将原始数据存储、向量索引构建、语义检索能力集成于一体,无需额外部署向量数据库或检索引擎。通过简洁的 API/SDK 或 CLI 工具即可完成从数据上传到智能检索的全流程,将原始文件与向量数据统一管理,大幅降低系统复杂度。
-
大规模存储,极致低成本。OSS Vector Bucket 采用 Serverless 架构,可轻松支撑海量数据规模。单个向量 Bucket 默认支持 100 张向量索引表,单向量索引表最多可存储 20 亿行向量数据。传统方案中,客户需要单独采购向量数据库、搜索引擎和存储介质,硬件投入和运维成本高昂。Vector Bucket 将多项能力融合,按需使用、自动扩容。平台无需担心容量瓶颈,也无需为扩容投入大量硬件和人力,真正实现“让企业专注于业务创新,而非基础设施运维”。
客户价值:效率与成本的双重优化
引入 OSS Vector Bucket 后,该平台取得了显著成效:
-
数据集统一管理:平台实现了多模态数据的统一管理,打破了数据孤岛。不同业务线的创作者可以在一个平台上便捷地访问和使用各类素材资源,极大地提升了内容创作的效率和质量
-
检索效率全面提速:通过向量检索和语义理解,系统能够快速理解创作者的意图,从 30 亿条素材中精准匹配相关内容,检索时间大幅缩短。
-
检索结果精准匹配:语义级别的检索替代了传统的关键词匹配,让检索结果更加精准,检索结果从“形似”转向“意似”,创作者找到满意素材的成功率大幅提升。比如“创作者搜'科技感背景”,不会只返回标签含“科技”的图片,而是理解视觉风格。
-
平台成本降低 95%: OSS Vector Bucket 只根据容量和检索扫描量进行收费,相较于传统的自建向量数据库,存储和检索的成本大幅降低。同时通过serverless化的弹性扩容能力,平台可以轻松应对数据规模的增长,无需投入大量硬件资源和运维人力。
结语:数据集智能管理的未来
在 AI 时代,数据管理能力直接决定了平台的竞争力。如何高效地存储、管理和检索海量多模态数据,是每个媒资平台必须面对的核心课题。
OSS Vector Bucket 以其强大的元数据管理能力、高效的向量检索性能和简单易用的接口,为媒资平台提供了一个理想的数据管理方案。从 PB 级数据存储到智能语义检索,从跨域数据共享到高并发处理,OSS Vector Bucket 让数据集管理变得简单而高效。
未来,随着 AIGC 技术的不断发展,多模态数据管理将迎来更多的机遇和挑战。而 OSS Vector Bucket 将继续为内容创作者赋能,助力更多的平台在竞争中脱颖而出。
欢迎试用阿里云 OSS Vector Bucket,让数据集管理更简单、更高效,开启智能数据管理之旅。
更多代码和最佳实践,请参考OSS Vector Bucket官方文档

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)