人工智能(三)— 神经网络的训练
大模型的本质就是,一个经过大规模数据训练、参数固定(推理阶段)的深度神经网络,它学习到了语言中的统计规律与结构表示。
想知道神经网络是如何训练的吗?那首先得弄清楚下面几个概念,看完,你一定会有所收获的。
一、拟合函数
在AI和机器学习领域,拟合函数是指模型通过学习训练数据,找到一个数学函数来描述输入与输出之间关系的过程或结果。
1.1、核心概念
简单来说,给定一组数据点 (x1,y1),(x2,y2),...,(xn,yn)(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)(x1,y1),(x2,y2),...,(xn,yn),拟合的目标是找到一个函数 f(x)f(x)f(x),使得:
f(xi)≈yif(x_i) \approx y_if(xi)≈yi
1.2、常见类型
线性拟合:用直线拟合数据,如线性回归
f(x)=wx+bf(x) = wx + bf(x)=wx+b
多项式拟合:用多项式曲线拟合
f(x)=w0+w1x+w2x2+...+wnxnf(x) = w_0 + w_1x + w_2x^2 + ... + w_nx^nf(x)=w0+w1x+w2x2+...+wnxn
神经网络拟合:用多层非线性函数组合拟合复杂关系,是深度学习的核心
非线性函数(Non-linear function)是指其输出的变化与输入的变化不成正比的数学函数。如果将它的图像绘制在坐标系中,它呈现的不是一条笔直的直线,而可能是曲线、折线、波浪线或更复杂的形状;
1.3、拟合的关键问题
| 问题 | 描述 | 后果 |
|---|---|---|
| 欠拟合 | 模型过于简单,无法捕捉数据规律 | 训练集和测试集表现都差 |
| 过拟合 | 模型过于复杂,记住了噪声 | 训练集好,测试集差 |
| 良好拟合 | 模型恰当地学到了数据的真实规律 | 泛化能力强 |
1.4、如何衡量拟合质量
常用损失函数来衡量,例如均方误差(MSE):
MSE=1n∑i=1n(f(xi)−yi)2\text{MSE} = \frac{1}{n}\sum_{i=1}^{n}(f(x_i) - y_i)^2MSE=n1i=1∑n(f(xi)−yi)2
训练过程就是通过优化算法(如梯度下降)不断最小化损失函数,让拟合函数尽可能准确。
1.5、在AI中的意义
整个机器学习的本质,可以理解为用参数化函数拟合数据分布——无论是图像分类、语言生成还是强化学习,都是在寻找最优的拟合函数。
二、损失函数
损失函数是用来衡量模型预测值与真实值之间差距的函数。它是AI训练的"指挥棒"——告诉模型"你现在差多远,该往哪个方向改进"。
2.1、直观理解
想象你在练习投篮:
- 预测值 = 你投出的落点
- 真实值 = 篮筐位置
- 损失函数 = 偏差距离
损失值越小 → 模型越准确。训练的目标就是最小化损失函数。
2.2、常见损失函数
回归任务(预测连续值)
均方误差 MSE:
L=1n∑i=1n(y^i−yi)2L = \frac{1}{n}\sum_{i=1}^{n}({\hat{y}_i - y_i})^2L=n1i=1∑n(y^i−yi)2
平均绝对误差 MAE:
L=1n∑i=1n∣y^i−yi∣L = \frac{1}{n}\sum_{i=1}^{n}|\hat{y}_i - y_i|L=n1i=1∑n∣y^i−yi∣
分类任务(预测类别)
交叉熵损失(Cross-Entropy):
L=−∑iyilog(y^i)L = -\sum_{i} y_i \log(\hat{y}_i)L=−i∑yilog(y^i)
这是最常用的分类损失,衡量预测概率分布与真实分布的差距。
2.3、损失函数如何驱动训练
初始化模型参数
↓
前向传播:输入数据 → 得到预测值
↓
计算损失:Loss = f(预测值, 真实值)
↓
反向传播:计算梯度(损失对参数的导数)
↓
梯度下降:更新参数,让 Loss 减小
↓
重复迭代,直到收敛
2.4、不同任务选择不同损失函数
| 任务类型 | 常用损失函数 |
|---|---|
| 线性回归 | MSE、MAE |
| 二分类 | 二元交叉熵 |
| 多分类 | 交叉熵(Softmax) |
| 生成模型(如ChatGPT) | 交叉熵(预测下一个token) |
| 目标检测 | 分类损失 + 位置回归损失 |
2.5、一句话总结
损失函数 = 模型的"错误度量尺",训练过程就是不断调整参数,让这把尺子的读数趋近于零。
三、梯度下降(Gradient Descent)
梯度下降是AI训练中最核心的优化算法,用来自动调整模型参数,使损失函数不断减小。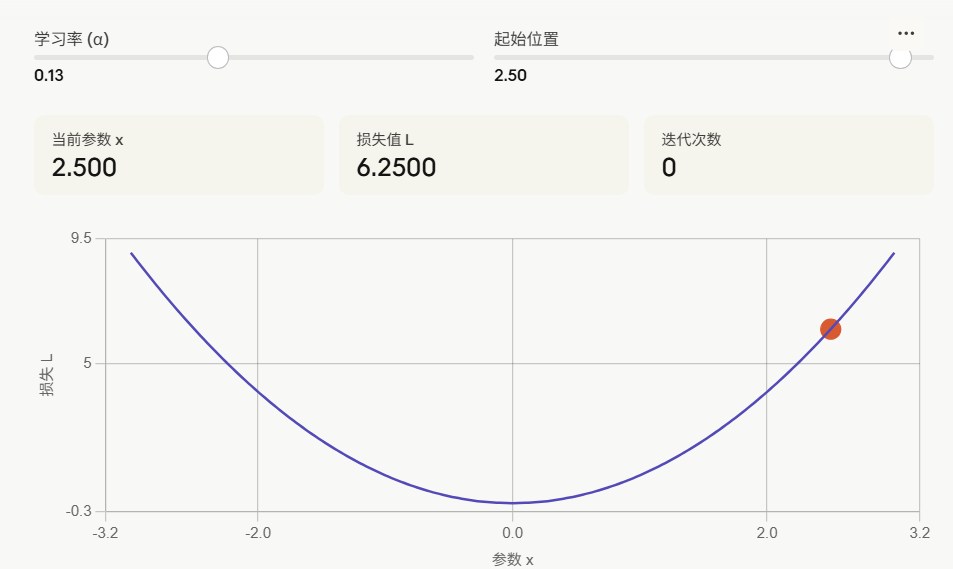
3.1、核心思想:下山法则
想象你站在一座山上,想找到最低点(最小损失),但浓雾中看不远,只能感受脚下地面的坡度(梯度),然后往下坡方向迈一步。重复这个过程,就会逐渐走到谷底。
这就是梯度下降的本质:
x新=x旧−α⋅∇L(x)x_{\text{新}} = x_{\text{旧}} - \alpha \cdot \nabla L(x)x新=x旧−α⋅∇L(x)
- ∇L(x)\nabla L(x)∇L(x) = 梯度(坡度方向)
- α\alphaα = 学习率(每步步长)
- 负号 = 往梯度反方向走(下坡)
3.2、学习率的影响
| 学习率 | 效果 |
|---|---|
| 太小 | 收敛极慢,需要很多步 |
| 适中 | 稳步下降,顺利到达最低点 |
| 太大 | 步子过大,来回"震荡"甚至发散 |
3.3、三种常见变体
批量梯度下降(BGD):用全部数据计算梯度,稳定但慢。
随机梯度下降(SGD):每次只用一个样本,快但抖动大。
小批量梯度下降(Mini-batch GD):两者折中,实际训练神经网络最常用。
3.4、当“山峰”不是漏斗形,而是连绵起伏的“山峰”,如何确定不选错“谷底”呢
"山"的形状由具体问题决定,没有办法提前看清全貌。梯度下降只能感受脚下的坡度,完全不知道远处有没有更深的谷。
简单的线性模型(如线性回归)损失曲面是漏斗形,只有唯一全局最优解。但神经网络参数动辄百万甚至千亿,其损失曲面是极高维的复杂地形,局部最优、鞍点、平坦区大量存在。
3.4.1、应对方法
随机性(SGD):每次只用一小批数据计算梯度,引入噪声(干扰原本的梯度方向),像一个"走路不稳的人",反而能从浅坑里抖出来,跳到更好的位置。
动量(Momentum):给小球加上"惯性",不只看当前坡度,还带着之前方向的速度,能越过浅坑继续滚。
自适应学习率(Adam):根据历史梯度自动调整每个参数的步长,在平坦区走快一点,在陡峭区走慢一点。
多次随机重启:从不同起点出发,跑多次训练,取结果最好的那次。
学习率调度(Warmup + 退火):开始时学习率大,敢于跳出局部坑;后期学习率变小,精细收敛。
四、反向传播算法
反向传播是神经网络训练的核心算法,解决了一个关键问题:如何高效计算网络中每个参数对损失的贡献?
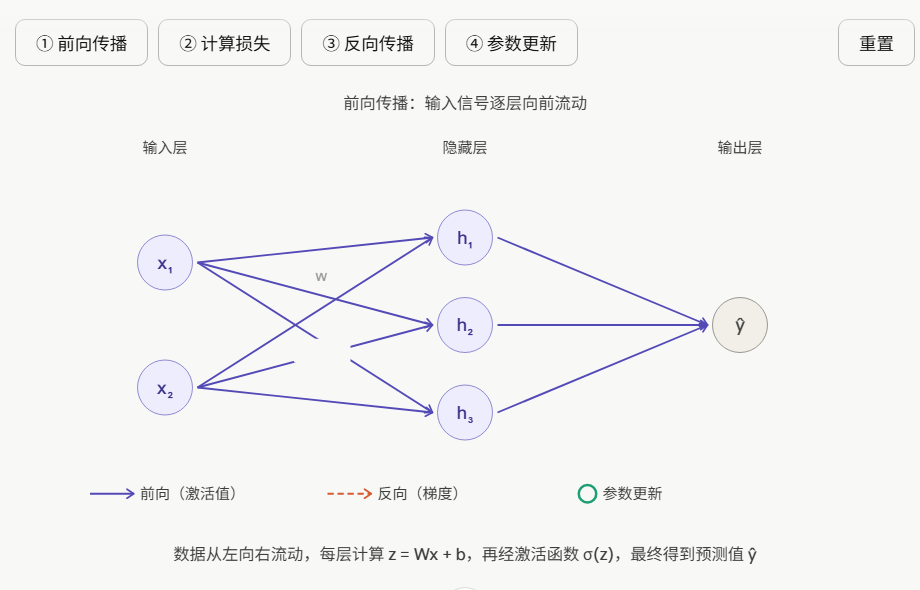
4.1、核心思想:链式法则
反向传播本质上是对微积分中"链式法则"的工程化应用。
假设网络是 L=f(g(h(x)))L = f(g(h(x)))L=f(g(h(x))) 这样的复合函数,那么:
∂L∂w=∂L∂y^⋅∂y^∂z⋅∂z∂w\frac{\partial L}{\partial w} = \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z} \cdot \frac{\partial z}{\partial w}∂w∂L=∂y^∂L⋅∂z∂y^⋅∂w∂z
每一项都是相邻两层之间的局部梯度,把它们连乘起来,就得到了参数 www 对最终损失的贡献度。
4.2、为什么叫"反向"传播?
| 阶段 | 方向 | 传递的东西 |
|---|---|---|
| 前向传播 | 输入 → 输出 | 激活值(数据信号) |
| 反向传播 | 输出 → 输入 | 梯度(误差信号) |
正向算出预测结果,反向算出"每个参数该负多少责任",再用梯度下降来更新参数——三者缺一不可,构成完整的训练循环。
4.3、举个栗子
把神经网络想象成一条流水线,每个工人(神经元)负责一道工序。产品出来有缺陷(损失),工厂主管(反向传播)从最后一道工序开始,逐级追责,告诉每个工人"你的操作偏差了多少、该怎么调整",最终所有人同步改进——下一轮生产就会更准确。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)