Linux线程互斥与互斥锁:从抢票Demo到RAII锁的硬核封装
上篇热文:Linux线程:核心机制与优雅的 C++ 封装实践|附源码
目录
5.1 Swap/Exchange 的核心物理本质:共享变私有
1. 多线程并发的安全隐患
在多线程编程中,多线程能够共享进程的大部分资源,这为线程间交互提供了极大的便利。然而,当多个执行流在没有保护的情况下并发访问同一个共享变量时,灾难也就随之降临了。
为了直观地感受多线程并发带来的数据安全问题,我们先来看一个经典的多线程抢票 Demo。
1.1 抢票 Bug 现场重现
我们通过一个全局变量 tickets 模拟 1000 张待售的门票,创建 4 个线程并发执行抢票逻辑。
Thread.hpp:代码见上篇热文
main.cc:
#include <iostream>
#include <vector>
#include "Thread.hpp"
int tickets = 1000; // 共享资源
void route()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
while (1)
{
// 临界区
if (tickets > 0)
{
usleep(1000);
printf("%s sells ticket:%d\n", name, tickets);
tickets--;
}
else
{
break;
}
}
}
int main()
{
std::vector<Thread> threads;
for (int i = 0; i < 4; i++)
{
threads.emplace_back(route);
}
for (auto &thread : threads)
{
thread.start();
}
for (auto &thread : threads)
{
thread.join();
}
return 0;
}最终问题是,出现了负数:
thread-2 sells ticket:-1
thread-1 sells ticket:-2
lwp: 553650, name: thread-1, join success
lwp: 553651, name: thread-2, join success
lwp: 553652, name: thread-3, join success
lwp: 553653, name: thread-4, join success为什么票数会出现
0、-1、-2这样的负数?
if条件判断的并发切换: 当tickets的值为1时,四个线程都可能刚好通过了tickets > 0的判断。
usleep模拟业务耗时: 在usleep的这 1 毫秒内,多个线程都在此等待。当它们被唤醒并继续执行时,都会傻乎乎地去执行tickets--,从而将票数扣成了负数。
tickets--操作本身并不是原子的!
2. 刨根问底:对 tickets-- 的汇编级解剖
很多初学者认为 tickets-- 只有一行代码,因而是“一步到位”的安全操作。其实不然!我们通过 objdump -d a.out 反汇编抢票的可执行程序,提取出 tickets-- 对应的汇编指令:
# 将共享变量 ticket 从内存加载到寄存器 eax 中 (Load)
mov 0x2004e3(%rip), %eax # eax = tickets
# 更新寄存器里面的值,执行 -1 操作 (Update)
sub $0x1, %eax # eax = eax - 1
# 将新值从寄存器写回到共享变量 ticket 的内存地址中 (Store)
mov %eax, 0x2004da(%rip) # tickets = eax
从汇编层面看,一行简单的 tickets-- 实际上被拆分成了 三步操作:
-
Load:把内存中的数据读入 CPU 寄存器。
-
Update:在 CPU 内部完成减一运算。
-
Store:将计算结果写回内存。
2.1 寄存器(物理独占)与 内存(共享资源)的冲突本质
要理解多线程冲突,首先必须搞清楚 CPU 寄存器和物理内存的关系:
-
CPU 内的寄存器只有一套。寄存器内存储的内容,本质上是当前正在运行线程的硬件上下文(Thread Hardware Context)。这个上下文是线程独占的。当线程被切走时,它会带走并保存自己的这套上下文数据。
-
物理内存中的数据则是多线程共享的。比如全局变量、静态变量等统统存放在物理内存中。
多线程冲突演练:
-
线程 A 将
tickets = 100加载到自己的寄存器eax中,准备执行-1运算。 -
此时时钟中断触发,线程 A 被剥夺 CPU。线程 A 带着自己的硬件上下文(
eax = 100)被挂起。 -
线程 B 登场,疯狂抢票,一路将内存中的
tickets从100扣减到了10,并成功写回物理内存。 -
线程 A 重新获得 CPU 调度,恢复上下文:它把尘封的
eax = 100重新读回 CPU,继续执行sub得到99,然后一纸诉状将99写回内存。 -
灾难发生:线程 B 辛辛苦苦抢掉的 90 张票凭空消失了!内存中的
tickets重新变回了99。
要解决以上问题,需要做到三点:
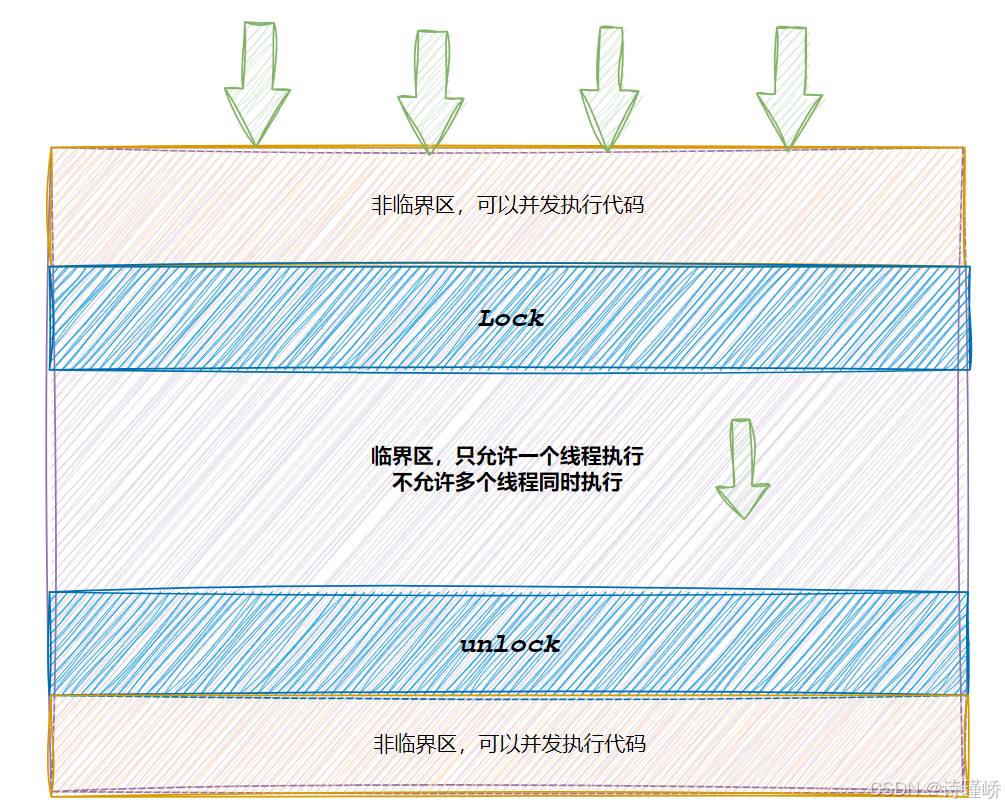
- 代码必须要有互斥行为:当代码进入临界区执行时,不允许其他线程进入该临界区。
- 如果多个线程同时要求执行临界区的代码,并且临界区没有线程在执行,那么只能允许一个线程进入该临界区。
- 如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区。
2.2 核心背景概念厘清
为了彻底解决这类问题,我们必须理解以下四个操作系统级的核心概念:
-
共享资源:多个执行流共同访问的资源(如全局变量
tickets)。 -
临界资源:任何时候只允许一个执行流访问的资源。
-
临界区:每个线程内部,直接访问临界资源的代码段(如
route函数中对tickets进行判断和扣减的代码)。 -
原子性:一项操作要么已经做完,要么完全没做,中间状态不会被任何调度机制打断。只有一条汇编指令的操作才具备天然的原子性。
-
互斥(Mutual Exclusion):在任何时刻,保证有且只有一个执行流进入临界区访问临界资源,通常用于对临界资源起保护作用。
3. 互斥锁(Mutex)
解决并发安全问题的核心思路就是变并行、并发为串行。 Linux 系统提供了一把金钥匙——互斥量(mutex,俗称互斥锁)。
3.1 互斥锁的核心接口
-
静态分配初始化:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; -
动态分配初始化:
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr); 参数: mutex:要初始化的互斥量 attr: NULL -
销毁互斥锁(注意:静态初始化的锁不需要销毁,且不能销毁一个处于加锁状态的锁,已经销毁的互斥量,要确保后面不会有线程再尝试加锁):
int pthread_mutex_destroy(pthread_mutex_t *mutex); -
加锁与解锁:
int pthread_mutex_lock(pthread_mutex_t *mutex); // 申请锁,不成功则阻塞挂起 int pthread_mutex_unlock(pthread_mutex_t *mutex); // 释放锁,唤醒等待队列中的线程
3.2 锁的本质是什么?
-
锁本身也是共享资源:如果锁本身不是共享的,线程怎么去共同竞争它呢?既然锁也是共享资源,那么申请锁的过程,必须是原子的。
-
申请锁的本质,是申请“执行许可”:锁就像是临界区的绿色通行证。只有抢到这张通行证的线程,才被允许执行临界区代码;没有抢到的,就必须在安全区外面排队挂起。
-
申请锁必须一视同仁:绝对不可以让线程一部分加锁申请,另一部分不申请直接硬闯临界区! 如果一个线程在不申请锁的情况下直接去访问临界资源,那这就是在亲手写 Bug,锁的保护屏障将瞬间形同虚设。
3.3 改进后的抢票程序
我们在临界区的前后分别加入 pthread_mutex_lock 和 pthread_mutex_unlock。
#include <iostream>
#include <vector>
#include <unistd.h>
#include "Thread.hpp"
int tickets = 1000; // 共享资源
pthread_mutex_t glock = PTHREAD_MUTEX_INITIALIZER; // 静态初始化全局锁
void route()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
while (true)
{
// 1. 申请锁(加锁必须在 if 判断之前!)
pthread_mutex_lock(&glock);
if (tickets > 0)
{
usleep(1000); // 即使在这里被切走,其他线程也无法获取锁进入临界区
printf("%s sells ticket: %d\n", name, tickets);
tickets--;
// 2. 抢票成功,释放锁
pthread_mutex_unlock(&glock);
}
else
{
// 3. 没票了,在退出循环前务必释放锁!否则会导致死锁!
pthread_mutex_unlock(&glock);
break;
}
}
}
int main()
{
std::vector<Thread> threads;
for (int i = 0; i < 4; i++)
{
threads.emplace_back(route);
}
for (auto &thread : threads)
{
thread.start();
}
for (auto &thread : threads)
{
thread.join();
}
return 0;
}思考:加锁会带来什么开销?该如何优化?加锁会把并发执行退化位串行执行,导致程序执行效率大幅降低。因此,我们在设计多线程代码时,必须要保证临界区范围缩到最小!只保护那些访问临界资源的核心代码。
4. 锁的实现原理:硬件方案 vs 软件方案
在计算机发展史上,要实现“原子性”和“互斥锁”,通常有两种截然不同的路线:一种是在内核实现的纯硬件方案,另一种是软硬结合的互斥量方案。
4.1 方案一:通过硬件实现锁(只在内核中实现)
在早期的单 CPU 操作系统或在操作系统内核的某些极限制场景下,硬件实现锁的逻辑非常简单粗暴:
核心思想:让线程在执行关键代码时不做任何切换。
-
物理手段:关闭 CPU 的时钟中断(Disable Interrupts)。
-
执行流程:当线程准备进入临界区时,直接发出硬件指令关闭时钟中断。由于时钟中断被屏蔽,CPU 无法再通过调度机制切换到其他线程。该线程在临界区内跑完关键代码后,再重新打开时钟中断(Enable Interrupts)。
-
结果:在这段“无中断”的黄金时间内,线程的执行绝对不会受到任何外界打扰,天然拥有了无可匹敌的原子性。
-
劣势:这种方法只适用于单核 CPU 的内核态,不能暴露给用户态,否则用户线程一旦恶意关中断不开启,整个系统将陷入死机。
4.2 方案二:通过软件(系统库)结合硬件原子指令实现锁
为了给用户态多线程提供安全的互斥保护,现代计算机体系结构在芯片中设计了专用的原子交换指令(如 swap 或 exchange)。基于这些指令,操作系统和 pthread 库在应用层实现了我们常用的 互斥量 (Mutex)。
5. 互斥锁的底层实现原理
为什么互斥锁的申请是绝对安全的?让我们来看看 pthread_mutex_lock 和 pthread_mutex_unlock 对应到 CPU 内部的底层伪代码:
申请锁(lock)的汇编伪代码:
lock:
movb $0, %al # 1. 将线程独占的寄存器 al 内部置为 0 (al = 0)
xchgb %al, mutex # 2. 【核心!】原子交换指令,将寄存器 al 的值与物理内存中的 mutex 变量进行交换
if(al 寄存器的内容 > 0){
return 0; # 3. 成功申请到锁,获得执行许可,进入临界区
} else {
挂起等待; # 4. 没抢到通行证,挂起等待被唤醒
goto lock; # 5. 被唤醒后重新返回起点竞争
}
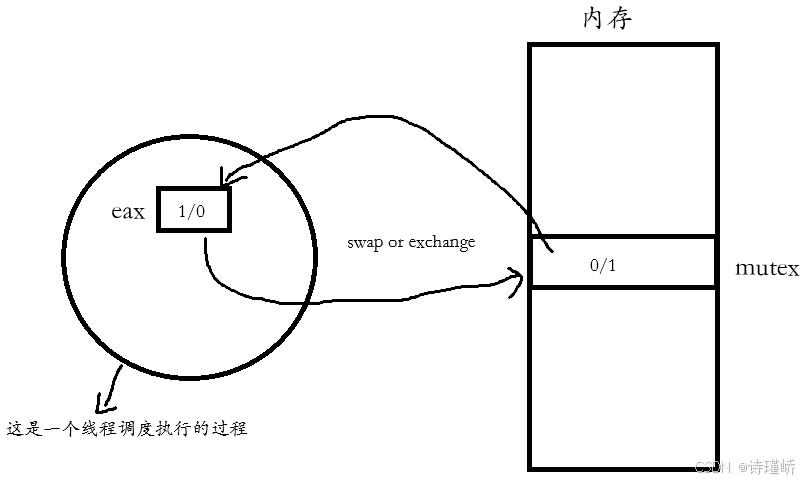
5.1 Swap/Exchange 的核心物理本质:共享变私有
-
物理内存中的
mutex在初始化时被置为1。这个1,就是全系统唯一的“通行证”。 -
当线程 A 执行
xchgb %al, mutex时,只用了一条汇编指令,就把寄存器al的0和内存中mutex的1进行了原子交换。 -
本质:它把一个原本存放在公共内存、被大家共享的数据内容(1),瞬间变成了一个线程私有的寄存器内容(1)。
-
由于寄存器内容由当前线程独占,这就意味着,一旦线程 A 把这个
1换到了自己的寄存器里,其他线程不管怎么执行交换,交换得到的永远只能是 0!除非线程 A 主动归还(即释放锁),否则谁也别想得到这个1。 -
这个私有化后的“1”就是锁!这种设计妙就妙在:不需要多次判断,用一条原子交换指令,就完美完成了“所有权”的转移。
释放锁(unlock)的汇编伪代码:
unlock:
movb $1, mutex # 1. 把私有的 "1" 重新放回共享内存,归还通行证
唤醒等待 Mutex 的线程; # 2. 唤醒在等待队列中阻塞挂起的线程
return 0;
6. 优雅设计:RAII 风格的互斥锁硬核封装
在实际的项目开发中,直接调用 lock 和 unlock 非常容易因为分支遗漏(如 break、return)或程序异常而漏掉解锁,导致系统瞬间陷入死锁。
为此,我们可以利用 C++ 的 RAII(Resource Acquisition Is Initialization) 机制,在对象的生命周期构造函数中加锁,析构函数中自动解锁,打造一个永不漏锁的安全守卫。
6.1 封装核心代码 Mutex.hpp
#ifndef __MUTEX_HPP
#define __MUTEX_HPP
#include <iostream>
#include <pthread.h>
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&_lock, nullptr);
}
void Lock()
{
pthread_mutex_lock(&_lock);
}
void Unlock()
{
pthread_mutex_unlock(&_lock);
}
~Mutex()
{
pthread_mutex_destroy(&_lock);
}
private:
pthread_mutex_t _lock;
};
class LockGuard
{
public:
LockGuard(Mutex *lockp): _lockp(lockp)
{
_lockp->Lock();
}
~LockGuard()
{
_lockp->Unlock();
}
private:
Mutex *_lockp;
};
#endif6.2 使用 RAII 锁守卫优雅抢票 main.cc
有了 LockGuard,即使我们在 if-else 分支中直接 break 退出循环,在退出作用域的一瞬间,局部变量 lockguard 的析构函数就会雷打不动地执行解锁,彻底规避了死锁隐患:
#include <iostream>
#include <thread>
#include <mutex>
#include <unistd.h>
#include "Mutex.hpp"
int tickets = 1000;
Mutex lock;
// std::mutex lock;
void buyTicket(int id)
{
while (true)
{
// lock.lock();
// lock.Lock();
// 临界区
LockGuard lockguard(&lock); // RAII风格的加锁逻辑
if (tickets > 0)
{
usleep(1000);
std::cout << "Thread " << id << " bought ticket, remaining: " << --tickets << std::endl;
// lock.Unlock();
// lock.unlock();
}
else
{
// lock.unlock();
// lock.Unlock();
break;
}
}
}
int main()
{
std::thread threads[4];
for (int i = 0; i < 4; ++i)
{
threads[i] = std::thread(buyTicket, i + 1);
}
for (auto& t : threads)
{
t.join();
}
std::cout << " " << std::endl;
return 0;
}
7. 总结
本文从物理硬件和底层汇编的维度,深度剖析了线程互斥的完整面貌:
-
冲突的根源:CPU 物理寄存器只有一套(作为线程独占的硬件上下文),而内存中的全局/静态变量是多线程共享的。并发切换时,上下文的覆盖机制导致了多线程冲突。
-
锁的本质:锁本身是共享资源,申请锁即是申请“执行许可”。所有线程必须统一守规矩申请锁,否则就是在写 Bug。
-
硬件关中断方案:通过物理“屏蔽时钟中断”让进程不发生任何切换,从而在多核之前或内核级实现了硬原子性。
-
软件 Swap 指令方案:利用芯片的
swap/xchgb指令,通过一步原子的交换操作,将原本物理共享的“1”(内存值)转化为了线程独占的“1”(寄存器值),完成了天衣无缝的所有权转移。 -
现代 C++ 最佳实践:采用 RAII 设计模式对锁进行
LockGuard封装,依靠其声明周期作用域,让系统自动在出临界区时解锁,优雅消除了死锁可能。
下一篇硬核预告: 有了互斥锁,多线程虽然安全了,但常常会带来“饥饿问题”(某个线程抢锁能力极强,导致其他线程干等挂起)。
在下一篇文章中,我们将引入 条件变量 与 线程同步,并在此基础上,亲手带大家手撕基于固定大小环形队列的 生产者-消费者模型(Producer-Consumer Model)!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 28
28 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)