贝叶斯网络中精确推理方法--变量消除法 CS188 Note14 学习笔记
强烈推荐的更好的阅读体验
Inference
在Bayes Net中,Inference的目标是求解一个条件概率 P ( Q 1 … Q k ∣ e 1 … e k ) P\big(Q_1 \ldots Q_k \mid e_1 \ldots e_k\big) P(Q1…Qk∣e1…ek),也就是给出一些观测的变量( evidence ),计算查询变量( query variables ) 的后验概率
比如 P ( T ∣ + e ) P(T \mid +e) P(T∣+e)就表示着我们要求解当我们已经观察到事件e为真时,T为真的概率是多少?
我们首先能想到的最基础的方法就是,直接构造一个完整的概率联合表,然后我们用在Note11中提及到的Inference by Enumeration方法,先选择与evidence一致的行再求和最后归一化。但是这样做的问题也很明显,问题就在于第一步构造完整概率联合表上,假设每个变量都是binary,如果有n个变量那么就会有 2 n 2^n 2n个rows,构造这样大的表很有难度。这就引出来了我们解决问题的方法Variable Elimination。我们在本讲引入的方法就是 #Exact_Inference
Variable Elimination
首先我们需要定义Factor为一个未归一化的概率表,比如 P ( A ∣ B ) P(A \mid B) P(A∣B)或者 P ( A , B ) P(A, B) P(A,B)
Variable Elimination实例
模型结构:
- T:是否拿宝藏
- C:是否触发陷阱
- S:是否触发蛇
- E:是否能逃脱
求 P ( T ∣ + e ) P(T \mid +e) P(T∣+e),即已知逃脱成功,求拿到宝藏的概率
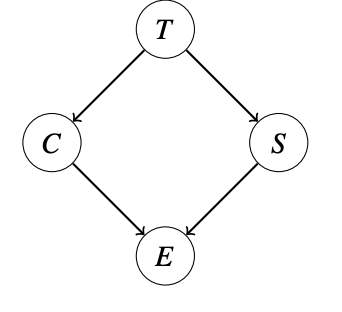
Step1:首先列出所有因子
- P ( T ) P(T) P(T)
- P ( C ∣ T ) P(C \mid T) P(C∣T)
- P ( S ∣ T ) P(S \mid T) P(S∣T)
- P ( + e ∣ C , S ) P(+e \mid C, S) P(+e∣C,S)
Step2:Join所有包含C的factors以便下一步求和消除C
包含C的因子有:
- P ( C ∣ T ) P(C \mid T) P(C∣T)
- P ( + e ∣ C , S ) P(+e \mid C, S) P(+e∣C,S)
Join后得到新的factor:
f 1 ( C , + e , T , S ) f_1(C, +e, T, S) f1(C,+e,T,S)
也可以写成
P ( C , + e ∣ T , S ) P(C, +e \mid T, S) P(C,+e∣T,S)
Step3:消除C
f 2 ( + e , T , S ) = ∑ c P ( C ∣ T ) P ( + e ∣ C , S ) = ∑ c f 1 ( C , + e , T , S ) \begin{align*} f_2(+e, T, S) &= \sum_{c} P(C \mid T)\,P(+e \mid C, S) = \sum_{c}f_1(C, +e, T, S) \end{align*} f2(+e,T,S)=c∑P(C∣T)P(+e∣C,S)=c∑f1(C,+e,T,S)
用求和公式把C消除
Step4:Join所有包含S的factors以便下一步求和消除S
包含S的因子有:
- P ( S ∣ T ) P(S \mid T) P(S∣T)
- f 2 ( + e , T , S ) f_2(+e, T, S) f2(+e,T,S)
Join后得到新的factor
f 3 ( + e , S , T ) f_3(+e, S, T) f3(+e,S,T)
Step5:消除S
f 4 ( + e , T ) = ∑ s f 3 ( + e , S , T ) \begin{align*} f_4(+e, T) &= \sum_sf_3(+e, S, T) \end{align*} f4(+e,T)=s∑f3(+e,S,T)
Step6:乘上剩余因子
还剩下一个 P ( T ) P(T) P(T),就可以得到
f 5 ( + e , T ) = P ( T ) f 4 ( + e , T ) \begin{align*} f_5(+e, T) &= P(T)f_4(+e, T) \end{align*} f5(+e,T)=P(T)f4(+e,T)
Step7:归一化
伪代码实现

与Enumeration的本质区别
Enumeration:
α ∑ s ∑ c P ( T ) P ( s ∣ T ) P ( c ∣ T ) P ( + e ∣ c , s ) \begin{align*} \alpha\sum_s\sum_cP(T)\,P(s \mid T)\,P(c \mid T)\,P(+e \mid c, s) \end{align*} αs∑c∑P(T)P(s∣T)P(c∣T)P(+e∣c,s)
Variable Elimination:
α P ( T ) ∑ s P ( s ∣ T ) ∑ c P ( c ∣ T ) P ( + e ∣ c , s ) \begin{align*} \alpha P(T)\sum_{s}P(s\mid T)\sum_{c}P(c\mid T)\,P(+e\mid c,s) \end{align*} αP(T)s∑P(s∣T)c∑P(c∣T)P(+e∣c,s)
Variable Elimination 把:
与求和无关的项提前移出求和符号
这大大减少了中间表的大小。
同时需要注意的是如果先消除 S,可能中间因子大小会不同。通过合理选择消除顺序,可以使最大因子尽可能小,从而降低计算复杂度。通常我们会采用贪心策略:每次选择“最小规模”的变量进行消除,其中规模可定义为当前涉及该变量的因子合并后的大小。这被称为“最小缺陷”或“最小边”启发式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)