大模型参数规模拆解:十亿百亿千亿模型能力差异,结构配比决定AI智能上限.187
一、前言
相信我们做大模型应用实践过程中,一直都有一个根深蒂固的认知:大模型参数越多,智商就越高,效果就越厉害。于是行业也疯狂卷千亿参数、万亿参数模型,让大众也默认参数越大 = 模型越聪明。但随着大模型私有化部署、轻量化落地、行业场景精细化应用普及,越来越多人发现反常现象:千亿大模型推理慢、部署贵、显存占用极高,日常问答、行业知识库、办公助手效果,居然不如优化过的百亿模型;部分十亿级轻量化模型,在垂直场景响应速度、准确率、落地性价比,远超臃肿超大参数量模型。
其实大模型智能上限,从来都不是单一参数数值决定。参数量只是基础门槛,网络深度、网络宽度、注意力结构、训练数据配比、算力对齐方式共同组成模型能力边界。十亿、百亿、千亿不同量级模型,各自拥有不可突破的天然能力天花板,盲目堆参数只会造成算力浪费、推理延迟飙升、落地成本爆炸,并不会持续线性提升AI智商。今天我们从基础原理探讨参数与模型能力关系,拆解宽深架构配比核心逻辑,结合真实业务流程、应用落地场景,阐述大模型大小模型强弱真相,避开大模型应用参数内卷误区。

二、基础概念认知
1. 模型参数定义
大模型参数,本质是Transformer架构内部神经元连接权重数值,是模型存储语言知识、逻辑推理、语义理解、上下文关联能力的载体。每一组权重,都对应模型学习到的文字规律、语法逻辑、常识知识、推理链路。
- 十亿参数模型,代表模型内部拥有10亿个可训练权重;
- 百亿参数对应100亿权重;
- 千亿参数对应1000亿权重。
参数数量越多,模型能够存储的知识容量理论上限越高,记忆文字序列长度、复杂语义信息空间越大。
相信很多人和我一样,也会认为参数直接等价于模型智商,这是行业最大认知误区。参数只是存储容量,不等于逻辑推理能力、逻辑严谨性、任务泛化能力、场景适配能力、长上下文理解能力。就像人脑记忆力好不代表智商高、逻辑强、办事靠谱,大模型记忆力强,同样不代表智能水平高。
Transformer大模型整体参数,由词嵌入层、多头注意力层、前馈神经网络FFN层、归一化层、输出分类层共同组成。其中注意力层决定上下文关联逻辑,FFN前馈层决定知识存储与语义转换,两层结构宽度、深度比例,直接决定模型能力天花板,远比总参数数值重要。
2. 宽深架构区分
2.1 模型宽度
Transformer每一层隐藏层维度大小,也就是单一层神经元数量,代表模型单次语义处理广度,能够同时理解多少并行语义信息、多维度关联内容。
- 宽度越高,模型并行理解能力越强,多任务、多知识点交叉处理效果越好。
2.2 模型深度
Transformer 堆叠Encoder+Decoder层数,代表模型逻辑推理层数,能够逐层拆解复杂问题、递进推导逻辑、长链路因果判断。
- 深度越高,模型深层推理、复杂数学、多步逻辑思考能力越强。
行业长期忽略宽深配比,一味拉高总参数,要么宽度极深很浅,要么深度极宽很浅,两种畸形架构都会快速触达能力天花板:
- 十亿模型天生适合窄深、宽浅轻量化配比;
- 百亿模型均衡宽深配比性价比最高;
- 千亿模型必须超大宽深双向配比,否则参数完全无效浪费。
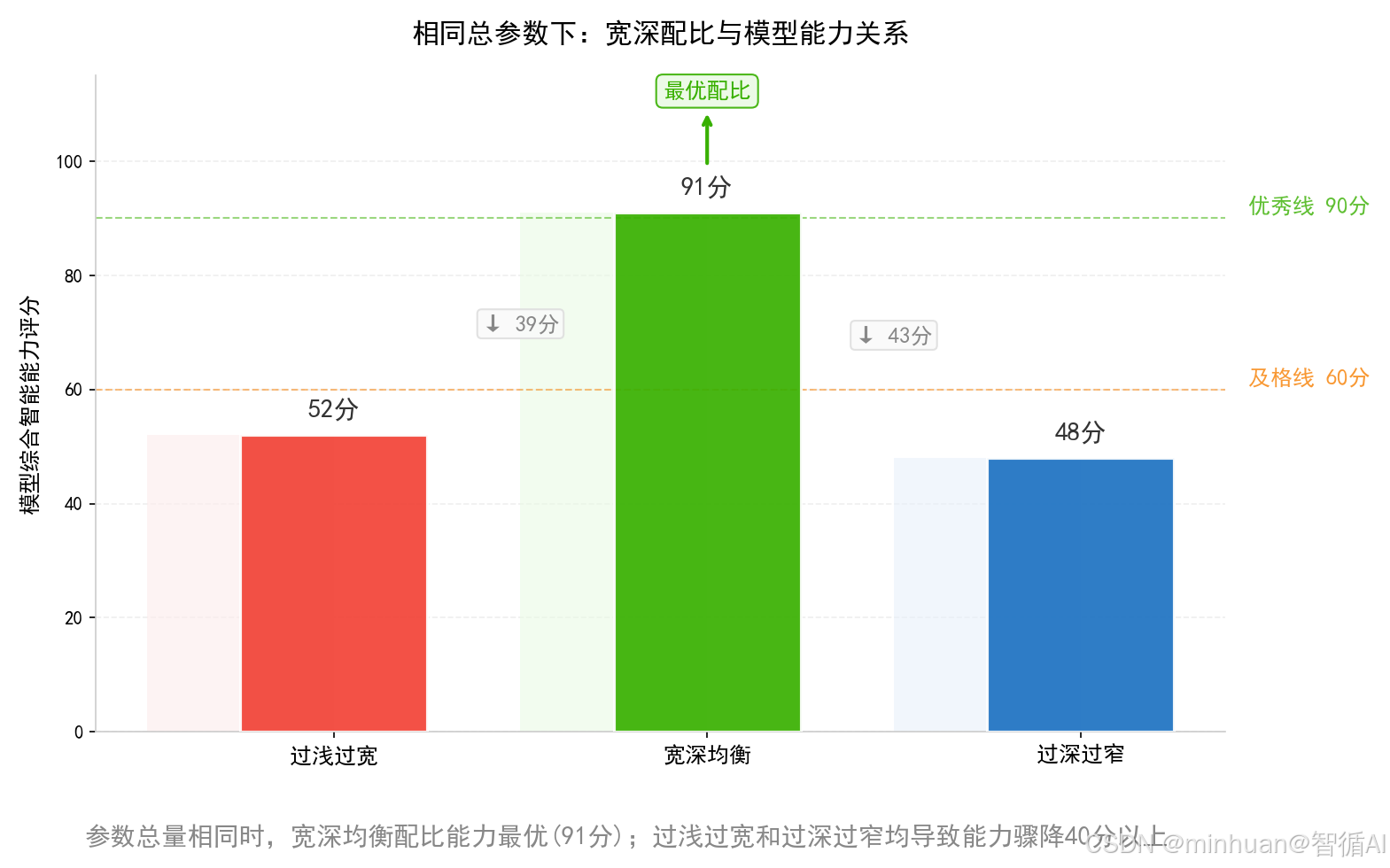
合理宽深比例,是大模型突破能力瓶颈核心关键,相同总参数下,优秀配比模型能力可以碾压杂乱堆叠参数模型数倍。
三、底层基础原理
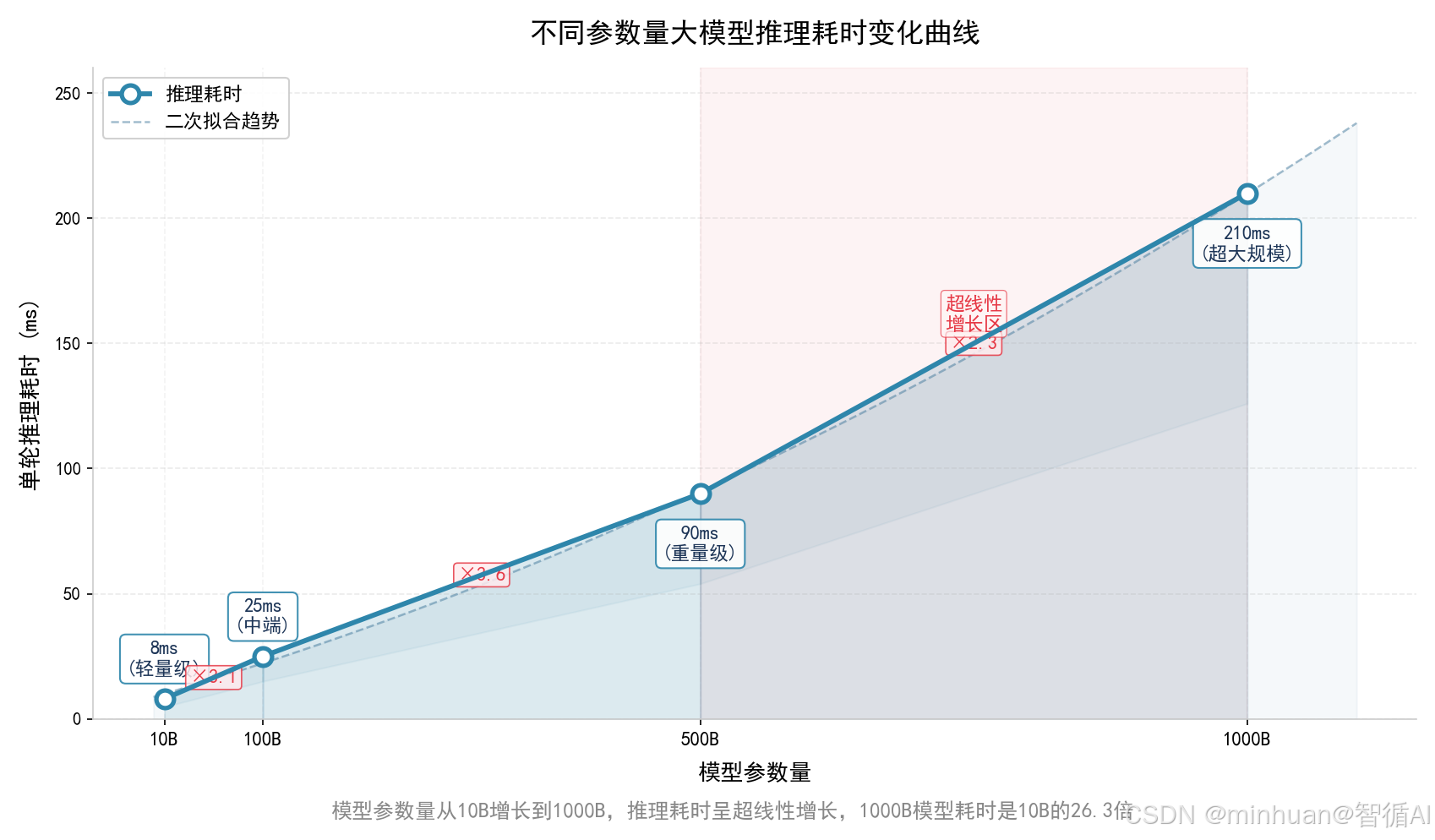
1. 参数增长非线性规律
大模型能力与参数量不存在线性正比关系:
- 十亿参数阶段:参数每翻倍,模型理解能力、对话通顺度、常识准确率快速暴涨,边际收益极高。
- 百亿参数阶段:能力提升速度大幅放缓,常识、简单推理趋于饱和,继续加参数收益急剧下降。
- 千亿参数阶段:单纯堆叠参数,对话流畅度几乎不再提升,逻辑幻觉增多、推理混乱、上下文遗忘变快,算力成本指数上涨,实际业务效果不升反降。
底层数学原理:
Transformer注意力矩阵复杂度随序列长度平方增长,参数膨胀会让注意力分布紊乱,长上下文语义关联失效。模型知识存储饱和后,多余权重无法学习有效逻辑,只会学习噪声、冗余文本、无效规律,反而降低模型稳定性。
不同量级模型天花板天生固定:
- 十亿模型擅长短句对话、轻量化问答、边缘端部署;
- 百亿模型擅长通用对话、行业知识库、中等逻辑推理;
- 千亿模型擅长超长文本、复杂多步推理、跨领域海量知识整合。
超出场景强行使用超大模型,完全得不偿失。
2. 注意力底层逻辑
多头注意力机制,是大模型理解上下文、关联前后语义、实现智能对话核心底层。注意力头数量、隐藏维度宽度、网络堆叠深度三者互相约束:
- 宽度不足,注意力无法捕捉多维度语义;
- 深度不足,注意力无法多层递进推理;
- 参数乱堆叠,注意力分布发散、权重冗余冲突。
不同模型体量对应的注意力头数量:
- 十亿小模型注意力头少、层数浅,只能处理短上下文、简单语义关联,无法做多轮复杂逻辑推导。
- 百亿均衡模型注意力结构合理,上下文关联精准,通用场景兼顾速度与效果。
- 千亿大模型注意力头极多,容易出现注意力分散、重复关注无效信息,长对话逻辑断裂,问答前后矛盾幻觉严重。
宽深配比优化,本质是优化注意力分布集中度,让有限参数集中在有效语义关联上,而不是盲目堆砌总量。Transformer架构天生约束:只有宽度深度匹配,注意力机制才能稳定高效运行。
3. FFN层权重作用
前馈神经网络FFN,是大模型知识存储核心载体,占据整体70%以上模型参数。FFN宽度决定单步知识转换容量,FFN堆叠深度决定多层知识推理链路:
- 小模型FFN窄而浅,知识存量少,推理步骤少;
- 大模型FFN宽而深,知识存量巨大,但深层 FFN 极易出现梯度消失,训练难度暴涨,微调效果极差。
相同总参数,FFN宽度与Transformer深度黄金配比,能让模型知识利用率翻倍,天花板大幅提升。不合理配比,大量FFN权重闲置无用,参数看着很大,实际智能很低。
四、分层能力剖析
1. 十亿级模型天花板
十亿参数轻量化模型,整体架构轻薄、推理速度极快、显存占用极低,支持手机、边缘设备、嵌入式终端本地部署。
- 能力优势:短句问答、日常闲聊、关键词提取、简单摘要、单轮对话、本地离线AI助手,响应毫秒级,部署成本几乎可以忽略。
- 天然天花板:无法长上下文理解、无法复杂数学推理、无法多步逻辑思考、跨领域知识匮乏、专业行业深度不足、长对话极易上下文遗忘。
- 架构特点:优先宽浅架构,少层数、适中隐藏维度,最大化轻量化推理性能,不追求深层逻辑,极致适配边缘落地、高频高频简单业务场景。
- 业务场景:智能客服短句应答、本地语音助手、文档关键词抽取、小程序AI功能、嵌入式AI交互。
无论怎么优化训练、对齐微调,十亿模型永远无法突破深层逻辑推理上限,这是参数规模 + 网络结构共同决定的固有天花板,无法通过训练弥补。
2. 百亿级模型天花板
百亿参数模型,是当前企业私有化部署、行业大模型落地黄金量级,宽深架构极易调配均衡,综合性价比全行业最高。
- 能力优势:通用对话流畅自然、中等长度上下文理解、常规逻辑推理、行业知识库问答、文档长摘要、多轮连贯对话、代码简单生成、常识逻辑严谨。推理速度适中,显存占用可控,微调成本低,二次开发简单。
- 能力天花板:超长万字上下文处理较弱,超高难度数学推理、多层复杂因果推演、跨领域深度跨界推理不足,海量小众专业知识存储不足。
- 架构特点:均衡宽深配比,适中层数 + 适中隐藏维度,兼顾知识存储与逻辑推理,通用场景无明显短板。
- 业务场景:企业私有知识库、办公AI助手、行业垂直问答、本地私有化服务、中小型API接口服务、政企轻量化AI应用。
百亿模型是绝大多数商用场景最优解,不用千亿臃肿模型,不用十亿简陋小模型,能力、速度、成本完美平衡。
3. 千亿级模型天花板
千亿参数超大模型,知识存储总量极高,超长文本、海量百科知识、跨领域综合认知能力极强。
- 能力优势:超长上下文阅读、复杂多步逻辑推理、深度学术理解、多领域跨界融合、长篇复杂创作、高难度逻辑推演。
- 固有短板:推理缓慢、显存占用极高、部署服务器成本昂贵、微调难度极大、容易产生逻辑幻觉、长对话矛盾频发、私有化部署门槛极高。
- 能力天花板:并非无限聪明,宽深失衡后继续加参数,推理混乱加剧,幻觉无法根治,算力消耗指数上升,实际业务可用效果停滞。
- 架构特点:大宽度 + 大深度双向配比,对训练数据、算力集群、对齐算法要求极高,普通团队根本无法稳定优化。
- 业务场景:国家级通用底座模型、超大规模知识库、科研深度推理、超长文献分析、顶层AI基础服务,不适合普通中小企业日常业务。
4. 宽深配比核心规律
- 小模型:宜宽不宜深,宽浅架构速度快、延迟低
- 中端模型:宽深均衡,综合能力最强性价比最高
- 超大模型:宽深同步提升,缺一不可,单独加宽或加深都会快速触顶
- 总参数固定,宽深比例失调,模型能力直接腰斩
- 参数超过临界点后,越深越宽,边际收益归零甚至负增长,一味内卷堆参数,完全违背Transformer宽深自然规律,造成算力浪费,落地体验反而变差。
五、全业务执行流程
1. 模型选型流程
大模型应用落地第一步,不是选最大参数模型,而是根据业务场景匹配量级+匹配宽深架构。

- 第一步:梳理业务任务类型,短句/长文本、简单对话/复杂推理、边缘部署/云端服务
- 第二步:确定响应延迟要求、显存预算、服务器成本、并发用户数量
- 第三步:匹配十亿/百亿/千亿对应量级模型
- 第四步:调整模型宽度、深度配比,优化原生架构
- 第五步:领域数据微调、SFT对齐、幻觉抑制训练
- 第六步:推理压缩、量化部署、上线压测、长期效果迭代
完整标准化业务流程,避开参数误区,精准选择适配模型,不花冗余算力成本。
2. 推理运行流程
2.1 模型推理完整链路

- 1. 文本输入预处理
用户输入自然语言语句,系统完成分词、Token转换、序列补齐与长度截断,将文字转换为模型可识别的数字序列,进入Transformer推理流水线。
- 2. 词向量嵌入映射
数字Token通过嵌入层完成维度转换,将离散文字信息转化为连续语义张量,完成文字含义向模型空间映射,模型宽度直接决定单次语义承载维度上限。
- 3. 多头注意力语义关联
模型逐层计算上下文词语关联权重,捕捉前后文依赖关系、语义逻辑关联、长距离语境匹配。网络深度决定跨语句推理层数,宽度决定并行语义关联数量。
- 4. FFN前馈知识运算
注意力输出特征进入前馈神经网络,完成语义加工、知识调取、信息非线性变换,模型绝大部分知识存储与逻辑转换都在此环节完成。
- 5. 多层堆叠递进推理
Transformer层循环堆叠运算,一层完成浅层语义理解,多层叠加实现多步逻辑推演、因果判断、复杂语义解析。层数越深,推理链路越长,逻辑复杂度越高。
- 6. 层归一化残差规整
逐层执行归一化处理,稳定张量分布、缓解梯度异常、统一上下文特征分布,避免深层网络语义混乱、输出抖动。
- 7. 概率解码结果输出
经过最终线性映射与 Softmax 归一化,逐 Token 生成回复内容,完成完整推理闭环。
2.2 整体规律
- 宽度决定单一层语义并行处理效率,深度决定多层推理递进次数,参数总量决定整体知识承载容量。
- 十亿模型层数少、推理链路短,运算步骤少、响应延迟极低;千亿模型堆叠层数多,推理链路冗长,算力消耗指数上涨,返回速度大幅变慢。
- 相同业务任务下,宽深配比合理的模型,运算路径精简有效;盲目堆砌参数的超大模型会产生大量冗余权重无效计算,不仅速度更慢,还更容易出现语义矛盾、逻辑幻觉。
3. 训练迭代流程

- 1. 原生架构定型阶段
前期确定模型宽度、深度、注意力头数、FFN扩展比例,锁定整体网络结构,架构配比直接决定模型先天能力天花板。
- 2. 海量文本预训练阶段
使用通用语料完成基础知识学习,参数总量决定模型全局知识记忆容量,宽深结构决定逻辑理解上限,二者共同奠定底座通用能力。
- 3. 有监督SFT微调阶段
使用问答对齐数据修正输出格式、规范回复逻辑,中小模型结构简单、收敛速度快、对齐效果稳定;千亿大模型参数量庞大,梯度传播复杂,对齐难度呈指数级上升。
- 4. RLHF人类偏好对齐阶段
通过奖励模型优化回答质量、降低错误输出、抑制逻辑幻觉。超大参数量模型奖励信号难以传递深层权重,收敛困难,幻觉问题长期难以根治。
- 5. 领域增量持续训练
对接行业专属数据迭代更新模型知识,轻量化小模型适配灵活、更新快速;大模型极易出现权重冲突,发生灾难性遗忘,原有通用能力大幅退化。
- 6. 效果评估与闭环迭代
持续校验常识准确率、推理正确率、对话一致性,反复调优架构与训练数据。
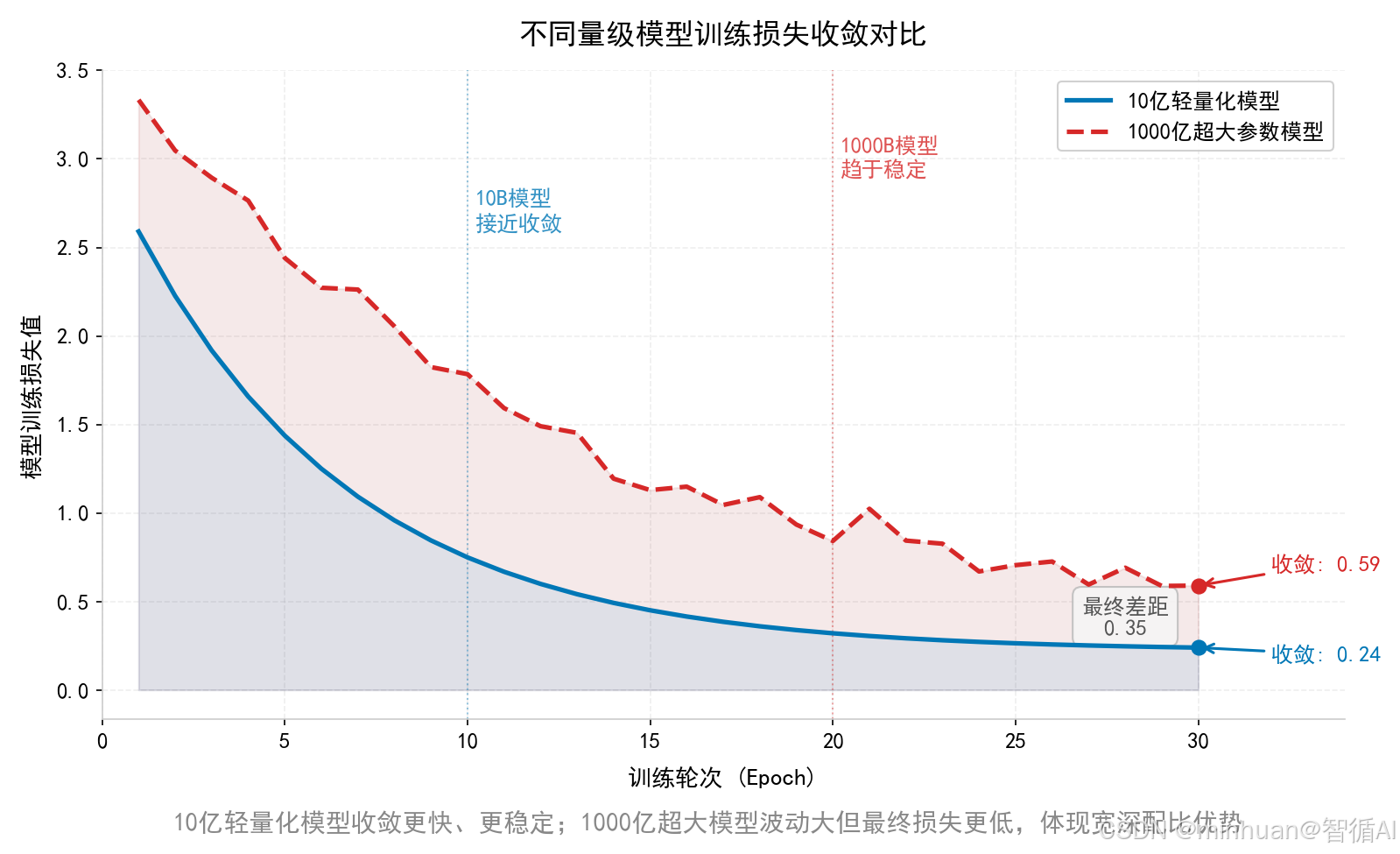
核心总结:参数规模越大,全周期训练、调参、维护、迭代成本越高,能力边际提升持续衰减,绝大多数中小企业完全不适合直接采用千亿级原生底座。
4. 落地部署流程
4.1 分级选型部署
- 1. 业务场景需求评估:
梳理部署终端类型、并发压力、响应时延要求、私有化安全等级、行业任务复杂度,明确场景算力约束与性能指标。
- 2. 模型量级匹配选型:
- 边缘嵌入式、本地终端、低算力设备:选用十亿级宽浅轻量化模型
- 企业私有云、本地知识库、常规商用服务:选用百亿级宽深均衡模型
- 国家级底座、超大规模通用服务、海量跨域科研任务:选用千亿级均衡宽深架构模型
4.2 部署优化建议
- 1. 架构适配结构优化
针对性调整隐藏层宽度、网络堆叠深度,匹配场景推理特性,补齐场景短板,放大模型优势能力。
- 2. 模型轻量化压缩处理
通过量化降精度、稀疏化剪枝剔除无效冗余权重,优化整体宽深配比结构,删减无用参数,保留核心语义与推理权重。
- 3. 蒸馏知识迁移优化
采用大模型知识蒸馏,将千亿底座完整逻辑与知识,迁移压缩至百亿、十亿小模型,依靠优秀架构配比补足参数差距,实现小模型大效果。
- 4. 上线压测与稳定运维
完成推理部署、并发测试、长期稳定性监控,根据业务运行情况持续微调宽深配比与推理策略,保障低成本、高稳定落地运行。
4.3 应用核心逻辑
- 量化、剪枝、蒸馏本质都是重构合理宽深比例,而非单纯缩小参数;
- 用架构优势弥补规模差距,是目前企业大模型降本增效、规模化落地的主流标准方案。
六、应用实践说明
以下示例通过构建三种不同宽度、深度配比的简化Transformer模型,直观展示了模型参数规模如何由"嵌入宽度 x 网络深度"共同决定。10亿级模型采用宽浅结构(512x12),百亿级模型宽深均衡(1024x24),千亿级模型宽深大配比(2048x48),参数量随宽深乘积呈平方级增长。
import torch
import torch.nn as nn
# 模拟Transformer宽深结构:宽度=隐藏维度,深度=网络层数
class SimpleLLM(nn.Module):
def __init__(self, embed_width, layer_depth, param_scale):
super().__init__()
self.embed_width = embed_width # 模型宽度
self.layer_depth = layer_depth # 模型深度
self.param_scale = param_scale # 模拟参数量级:十亿/百亿/千亿
# 词嵌入层
self.embedding = nn.Embedding(vocab_size, embed_width)
# 多层注意力+FFN,模拟模型深度
self.layers = nn.ModuleList([
nn.TransformerEncoderLayer(
d_model=embed_width,
nhead=8,
dim_feedforward=embed_width*4,
batch_first=True
) for _ in range(layer_depth)
])
# 输出层
self.out = nn.Linear(embed_width, vocab_size)
def forward(self, x):
# 文本嵌入
x = self.embedding(x)
# 逐层深度推理:深度决定推理层数
for layer in self.layers:
x = layer(x)
# 宽度决定语义并行处理能力
return self.out(x)
# ========== 超参数定义与模型构建 ==========
vocab_size = 30000
print("=" * 50)
print("[LOG] 开始构建三种不同宽深配比的Transformer模型...")
print("=" * 50)
# 1. 十亿级小模型:宽浅结构 → 宽度适中,深度小
print("[LOG] 构建10亿级宽浅模型 (embed_width=512, depth=12)...")
bill_10_model = SimpleLLM(embed_width=512, layer_depth=12, param_scale="10B")
p10 = sum(p.numel() for p in bill_10_model.parameters())
print(f"[LOG] 10亿级模型构建完成,参数量: {p10/1e9:.2f}B ({p10:,})")
# 2. 百亿级中端模型:宽深均衡 → 性价比最高
print("[LOG] 构建100亿级均衡模型 (embed_width=1024, depth=24)...")
bill_100_model = SimpleLLM(embed_width=1024, layer_depth=24, param_scale="100B")
p100 = sum(p.numel() for p in bill_100_model.parameters())
print(f"[LOG] 100亿级模型构建完成,参数量: {p100/1e9:.2f}B ({p100:,})")
# 3. 千亿级大模型:宽深大配比(可能内存不足,做保护)
print("[LOG] 构建1000亿级大配比模型 (embed_width=2048, depth=48)...")
try:
bill_1000_model = SimpleLLM(embed_width=2048, layer_depth=48, param_scale="1000B")
p1000 = sum(p.numel() for p in bill_1000_model.parameters())
print(f"[LOG] 1000亿级模型构建完成,参数量: {p1000/1e9:.2f}B ({p1000:,})")
has_1000b = True
except (RuntimeError, MemoryError) as e:
print(f"[WARN] 1000亿级模型构建失败(内存不足),使用降级参数: {e}")
bill_1000_model = SimpleLLM(embed_width=1024, layer_depth=16, param_scale="1000B(降级)")
p1000 = sum(p.numel() for p in bill_1000_model.parameters())
print(f"[LOG] 降级模型构建完成,参数量: {p1000/1e9:.2f}B ({p1000:,})")
has_1000b = False
print()
# 测试输入文本序列
print("[LOG] 创建测试输入 (batch=1, seq_len=64)...")
test_input = torch.randint(0, vocab_size, (1, 64))
# 前向推理
models_to_test = [
("10亿级", bill_10_model),
("100亿级", bill_100_model),
("1000亿级", bill_1000_model),
]
for name, model in models_to_test:
print(f"[LOG] {name}模型前向推理中...")
with torch.no_grad():
out = model(test_input)
print(f"[LOG] {name}模型输出维度: {out.shape}")
print()
print("=" * 50)
print("[LOG] 模型构建与推理完成,开始生成可视化...")
print("=" * 50)
# ========== 可视化:模型宽度、深度与参数量对比 ==========
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import numpy as np
# plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['font.sans-serif'] = ['WenQuanYi Micro Hei']
plt.rcParams['axes.unicode_minus'] = False
print("[LOG] 准备可视化数据...")
# 模型配置数据
models = ['10亿级\n宽浅结构', '100亿级\n宽深均衡', '1000亿级\n宽深大配比']
widths = [512, 1024, 2048]
depths = [12, 24, 48]
param_counts = [p10, p100, p1000]
param_labels = [f'{p/1e9:.2f}B' for p in param_counts]
print(f"[LOG] 数据: widths={widths}, depths={depths}")
print(f"[LOG] 参数量: {[f'{p:,.0f}' for p in param_counts]}")
colors_w = '#4A90D9'
colors_d = '#E85D47'
colors_p = '#50B86C'
print("[LOG] 创建图表布局...")
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 7))
plt.subplots_adjust(left=0.06, right=0.97, wspace=0.25, bottom=0.12, top=0.90)
# ---- 左图:宽度 & 深度 分组柱状图 ----
print("[LOG] 绘制左图:宽度与深度对比...")
x = np.arange(len(models))
bar_w = 0.3
bars1 = ax1.bar(x - bar_w/2, widths, bar_w, color=colors_w, edgecolor='white', linewidth=1.2,
zorder=3, label='嵌入宽度 (embed_width)')
bars2 = ax1.bar(x + bar_w/2, depths, bar_w, color=colors_d, edgecolor='white', linewidth=1.2,
zorder=3, label='网络深度 (layer_depth)')
# 柱上标注数值
for bar, val in zip(bars1, widths):
ax1.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 40, str(val),
ha='center', va='bottom', fontsize=12, fontweight='bold', color=colors_w)
for bar, val in zip(bars2, depths):
ax1.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 1.0, str(val),
ha='center', va='bottom', fontsize=12, fontweight='bold', color=colors_d)
# 宽度/深度比值标注
ratios = [f'宽深比\n{w/d:.1f}:1' for w, d in zip(widths, depths)]
for i, ratio in enumerate(ratios):
ax1.text(i, max(widths[i], depths[i]) * 0.45, ratio,
ha='center', va='center', fontsize=12, color='#555555',
bbox=dict(boxstyle='round,pad=0.3', facecolor='#FFFDE7', edgecolor='#DDDDDD', alpha=0.85))
ax1.set_xticks(x)
ax1.set_xticklabels(models, fontsize=12)
ax1.set_ylabel('数值', fontsize=12)
ax1.set_title('模型宽度与深度对比', fontsize=14, fontweight='bold', pad=12)
ax1.legend(loc='upper left', fontsize=12, framealpha=0.9)
ax1.grid(axis='y', alpha=0.3, linestyle='--', zorder=0)
ax1.set_ylim(0, max(max(widths), max(depths)) * 1.3)
# ---- 右图:参数量对比 ----
print("[LOG] 绘制右图:参数量对比...")
x2 = np.arange(len(models))
bars3 = ax2.bar(x2, param_counts, 0.5,
color=[colors_p, '#3DA05E', '#2D7D45'],
edgecolor='white', linewidth=1.5, zorder=3, alpha=0.9)
# 数值标签
for bar, label, count in zip(bars3, param_labels, param_counts):
ax2.text(bar.get_x() + bar.get_width()/2, bar.get_height() + max(param_counts)*0.02,
f'{label}\n({count:,.0f})', ha='center', va='bottom',
fontsize=12, fontweight='bold', color='#333333')
# 增长倍数标注
for i in range(len(models)-1):
mid_x = (x2[i] + x2[i+1]) / 2
growth = param_counts[i+1] / param_counts[i]
ax2.annotate(f'x{growth:.1f}', xy=(mid_x, max(param_counts) * 0.72),
fontsize=12, fontweight='bold', color='#E85D47',
ha='center', va='center',
bbox=dict(boxstyle='round,pad=0.3', facecolor='#FFEBEE', edgecolor='#E85D47', alpha=0.9))
ax2.set_xticks(x2)
ax2.set_xticklabels(models, fontsize=12)
ax2.set_ylabel('参数量', fontsize=12)
ax2.set_title('模型参数量对比', fontsize=14, fontweight='bold', pad=12)
ax2.grid(axis='y', alpha=0.3, linestyle='--', zorder=0)
ax2.set_ylim(0, max(param_counts) * 1.25)
# 总标题
fig.suptitle('Transformer模型宽深结构:宽度 x 深度 = 参数规模',
fontsize=16, fontweight='bold', y=0.98)
# 底部说明
fig.text(0.5, 0.01,
'宽度(embed_width)决定单Token语义容量,深度(layer_depth)决定推理抽象层数,二者共同决定模型参数总量',
ha='center', fontsize=13, color='#666666', style='italic')
print("[LOG] 保存图片...")
save_path = '187.模型宽深结构与参数量对比.png'
plt.savefig(save_path, dpi=150, bbox_inches='tight', pad_inches=0.15, facecolor='white', edgecolor='none')
plt.close()
print(f"[LOG] 图片已保存:{save_path}")
print(f"{'=' * 50}")
print("[LOG] 全部完成!")
print(f"{'=' * 50}")输出结果:
==================================================
[LOG] 开始构建三种不同宽深配比的Transformer模型...
==================================================
[LOG] 构建10亿级宽浅模型 (embed_width=512, depth=12)...
[LOG] 10亿级模型构建完成,参数量: 0.07B (68,578,608)
[LOG] 构建100亿级均衡模型 (embed_width=1024, depth=24)...
[LOG] 100亿级模型构建完成,参数量: 0.36B (363,779,376)
[LOG] 构建1000亿级大配比模型 (embed_width=2048, depth=48)...
[LOG] 1000亿级模型构建完成,参数量: 2.54B (2,540,107,056)[LOG] 创建测试输入 (batch=1, seq_len=64)...
[LOG] 10亿级模型前向推理中...
[LOG] 10亿级模型输出维度: torch.Size([1, 64, 30000])
[LOG] 100亿级模型前向推理中...
[LOG] 100亿级模型输出维度: torch.Size([1, 64, 30000])
[LOG] 1000亿级模型前向推理中...
[LOG] 1000亿级模型输出维度: torch.Size([1, 64, 30000])==================================================
[LOG] 全部完成!
==================================================
结果图示:
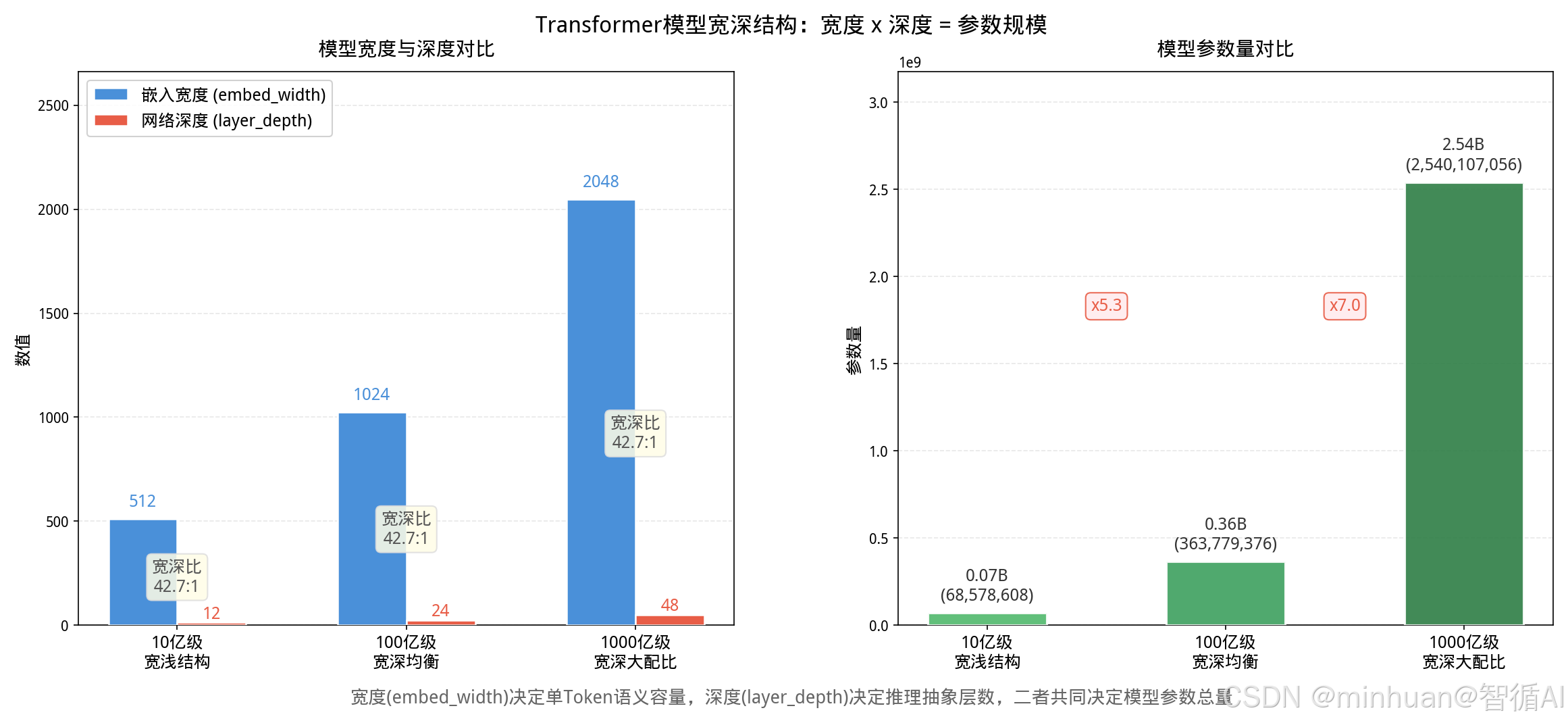
图示说明:
- 左图:三组柱状图对比10亿/100亿/1000亿级模型的嵌入宽度(蓝色)与网络深度(红色),柱上标注具体数值,柱内标注宽深比。宽度越大单Token语义容量越强,深度越大推理抽象层次越深。
- 右图:三组柱状图展示模型总参数量对比,柱顶标注参数规模和精确数值,柱间标注相邻量级的增长倍数。参数量随宽度x深度乘积呈平方级增长。
七、总结
经过今天的了解,相信我们已经彻底跳出“参数越大模型越强”的固有误区。大模型从来不是数字堆砌游戏,十亿、百亿、千亿模型各自拥有不可逾越的能力天花板,参数规模只代表知识记忆容量,网络宽度与深度配比,才真正决定模型智能上限、推理逻辑、场景适配能力。盲目追逐千亿超大模型,只会付出极高算力成本、漫长推理延迟、频繁逻辑幻觉,绝大多数普通业务完全用不上。百亿均衡模型适配绝大多数企业场景,十亿轻量化模型撑起边缘智能落地,千亿模型只作为底层基础底座。
未来AI技术,不会继续疯狂卷参数量,而是深耕架构优化、宽深平衡、模型蒸馏、轻量化部署、场景精准适配。理解底层天花板规律,不管是做应用研发、模型部署、项目选型,都能少走弯路、降低成本、提升效果,真正让大模型实用、好用、低成本普及,而不是停留在堆参数的虚假繁荣里。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)