(Embedding + 向量数据库)RAG +React+ollama 代码学习 主体代码实现
目录
序言
前面在文章https://blog.csdn.net/csdnliuxin123524/article/details/161294282?spm=1001.2014.3001.5502
中详细的讲解了使用TF-IDF检索本地知识库的方式实现了RAG。
本篇文章我们增强RAG的功能,不自己写检索知识库的功能了。而是使用ollama提供的embadding模型来读取知识库,使检索知识库的效果更好。
对比下二者
|
维度 |
普通 RAG(BM25) |
Embedding RAG(Vector RAG) |
|---|---|---|
|
检索原理 |
关键词匹配 + 统计权重 |
语义向量相似度 |
|
语义理解 |
❌ 弱 |
✅ 强 |
|
精确术语/ID |
✅ 好 |
⚠️ 一般 |
|
同义词/改写 |
❌ 不敏感 |
✅ 敏感 |
|
实现复杂度 |
低 |
中–高 |
|
典型存储 |
倒排索引(Elasticsearch) |
向量数据库(FAISS / Milvus) |
总结就是:普通 RAG 靠"字面对得上",Embedding RAG 靠"意思相近";工业级系统通常两者结合使用。
给知识库的数据生成词向量
给数据库document_chunks表 添加词向量字段
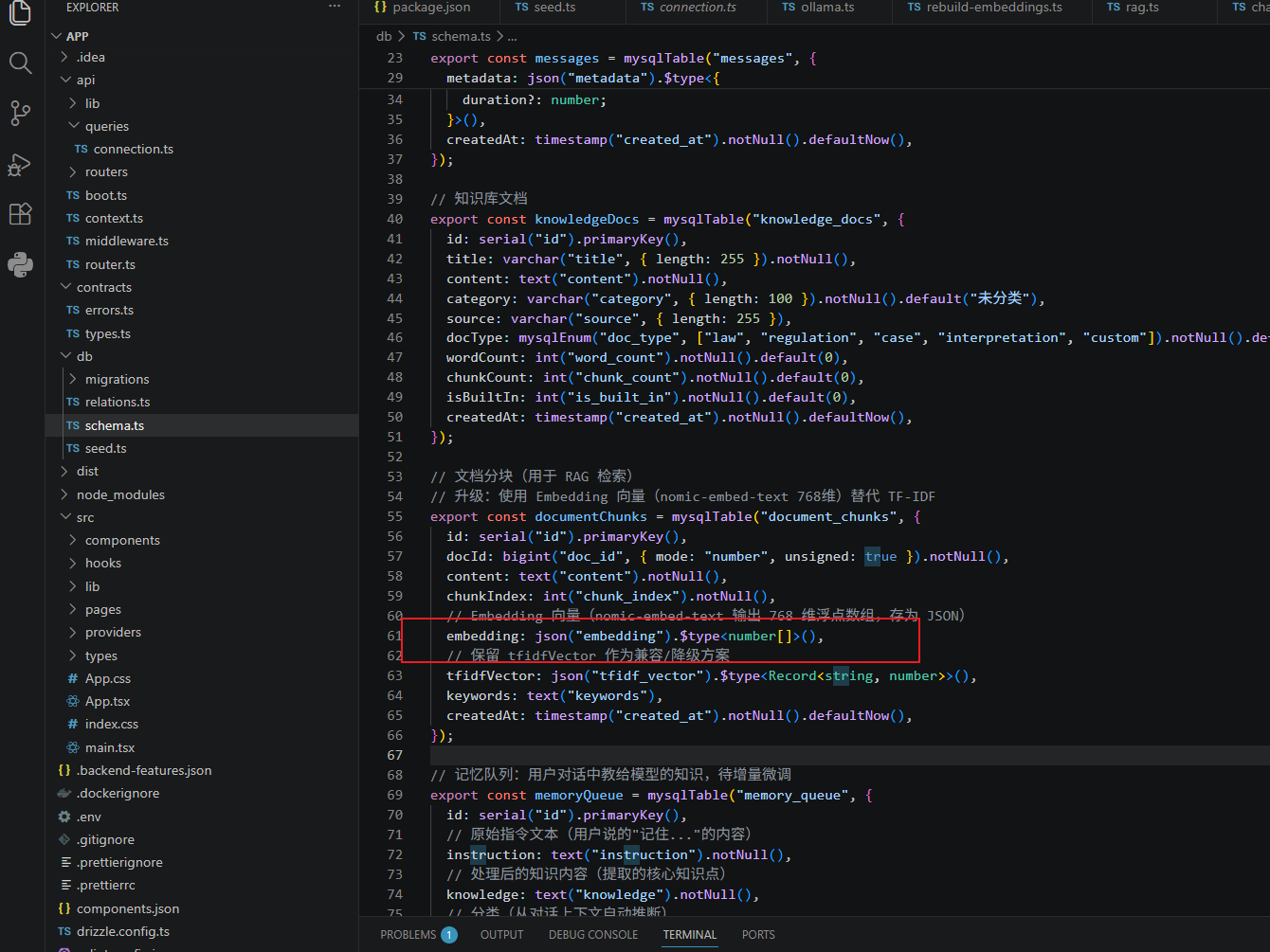
// 文档分块(用于 RAG 检索)
// 升级:使用 Embedding 向量(nomic-embed-text 768维)替代 TF-IDF
export const documentChunks = mysqlTable("document_chunks", {
id: serial("id").primaryKey(),
docId: bigint("doc_id", { mode: "number", unsigned: true }).notNull(),
content: text("content").notNull(),
chunkIndex: int("chunk_index").notNull(),
// Embedding 向量(nomic-embed-text 输出 768 维浮点数组,存为 JSON)
embedding: json("embedding").$type<number[]>(),
// 保留 tfidfVector 作为兼容/降级方案
tfidfVector: json("tfidf_vector").$type<Record<string, number>>(),
keywords: text("keywords"),
createdAt: timestamp("created_at").notNull().defaultNow(),
});然后重新执行 npx tsx db/seed.ts 生成表结构。
接着创建一个脚本文件 给 Embedding 的文档块生成向量。
在db目录下创建rebuild-embeddings.ts文件
/**
* 为知识库中所有缺失 Embedding 的文档块生成向量
* 执行方式: npx tsx db/rebuild-embeddings.ts
*/
import { getDb } from "../api/queries/connection";
import { documentChunks, knowledgeDocs } from "./schema";
import { eq, sql } from "drizzle-orm";
const OLLAMA_URL = "http://localhost:11434";
const EMBEDDING_MODEL = "nomic-embed-text";
/**
* 调用 Ollama 生成 Embedding
*/
async function generateEmbedding(text: string): Promise<number[]> {
const res = await fetch(`${OLLAMA_URL}/api/embeddings`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: EMBEDDING_MODEL,
prompt: text.slice(0, 8000),
}),
});
if (!res.ok) {
throw new Error(`HTTP ${res.status}: ${await res.text()}`);
}
const data = (await res.json()) as { embedding?: number[] };
return data.embedding || [];
}
/**
* 主函数:为所有缺失 embedding 的文档块生成向量
*/
async function main() {
const db = getDb();
console.log("========================================");
console.log("开始为知识库生成 Embedding 向量...");
console.log("========================================\n");
// 1. 统计当前状态
const totalResult = await db
.select({ count: sql<number>`count(*)` })
.from(documentChunks);
const embeddedResult = await db
.select({ count: sql<number>`count(*)` })
.from(documentChunks)
.where(sql`${documentChunks.embedding} IS NOT NULL`);
const missingResult = await db
.select({ count: sql<number>`count(*)` })
.from(documentChunks)
.where(sql`${documentChunks.embedding} IS NULL`);
const total = totalResult[0]?.count || 0;
const embedded = embeddedResult[0]?.count || 0;
const missing = missingResult[0]?.count || 0;
console.log(`总文档块: ${total}`);
console.log(`已有向量: ${embedded}`);
console.log(`待生成: ${missing}`);
console.log("");
if (missing === 0) {
console.log("所有文档块已有 Embedding,无需处理!");
return;
}
// 2. 获取所有缺失 embedding 的文档块
const chunks = await db
.select()
.from(documentChunks)
.where(sql`${documentChunks.embedding} IS NULL`);
console.log(`开始处理 ${chunks.length} 个文档块...\n`);
// 3. 逐个生成 Embedding(带进度显示)
let success = 0;
let failed = 0;
const startTime = Date.now();
for (let i = 0; i < chunks.length; i++) {
const chunk = chunks[i];
const progress = `[${i + 1}/${chunks.length}]`;
try {
const embedding = await generateEmbedding(chunk.content);
if (embedding.length > 0) {
await db
.update(documentChunks)
.set({ embedding })
.where(eq(documentChunks.id, chunk.id));
success++;
console.log(`${progress} ✓ 成功 (维度: ${embedding.length})`);
} else {
failed++;
console.log(`${progress} ✗ 返回空向量`);
}
} catch (err) {
failed++;
console.log(`${progress} ✗ 错误: ${err instanceof Error ? err.message : String(err)}`);
}
// 每 10 个显示一次进度
if ((i + 1) % 10 === 0) {
const elapsed = ((Date.now() - startTime) / 1000).toFixed(1);
const avgTime = ((Date.now() - startTime) / (i + 1) / 1000).toFixed(1);
console.log(`\n--- 进度: ${i + 1}/${chunks.length} | 成功: ${success} | 失败: ${failed} | 耗时: ${elapsed}s | 平均: ${avgTime}s/个 ---\n`);
}
}
const totalTime = ((Date.now() - startTime) / 1000).toFixed(1);
console.log("\n========================================");
console.log("Embedding 生成完成!");
console.log(`总计: ${chunks.length} | 成功: ${success} | 失败: ${failed}`);
console.log(`总耗时: ${totalTime} 秒`);
console.log("========================================");
}
main().catch((err) => {
console.error("执行失败:", err);
process.exit(1);
});其实上面的逻辑也很简单,就是调把知识库中的字符串文本发给ollama的embadding模型,然后返回这个句子文本的一组词向量,保存即可。
执行方式: npx tsx db/rebuild-embeddings.ts
可以看到有类似如下日志:
PS D:\Downloads\Kimi_Agent_Embedding_RAG\app> npx tsx db/rebuild-embeddings.ts
========================================
开始为知识库生成 Embedding 向量...
========================================
总文档块: 74
已有向量: 73
待生成: 1
开始处理 1 个文档块...
[1/1] ✓ 成功 (维度: 768)
========================================
Embedding 生成完成!
总计: 1 | 成功: 1 | 失败: 0
总耗时: 0.7 秒
========================================并且数据库中embadding字段也都有值了。
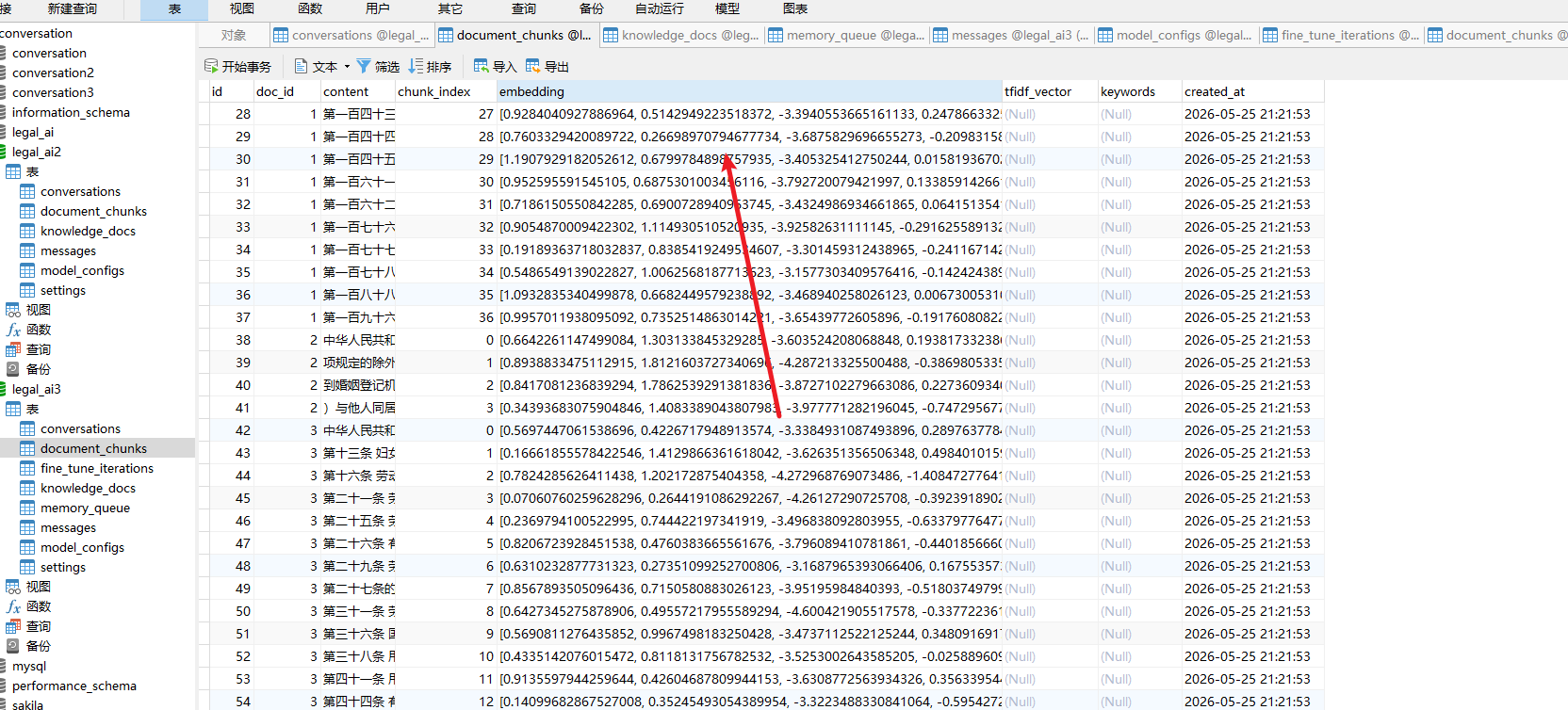
重新梳理对话流程代码
*相对于TF-IDF的方式,区别就是把用户输入的句子调用ollama的embadding向量模型,会得到这个句子的一组向量
然后再拿这个向量跟已经训练好的知识库每个句子的向量做余弦相似度对比。达到一定相似程度,并且取前几个。
后面就跟TF-IDF的处理方式一样了。汇总输入句子和知识库中的句子,融入到系统提示词中。
*最后就可以请求ollama大模型了。
主要代码修改:
- 调用词向量模型给输入句子生成文本的向量表示
/**
* 调用 Ollama nomic-embed-text 生成文本的向量表示
*
* 原理:把一段文字转换成 768 个数字(浮点数数组)
* 语义相近的文字,向量距离也相近
* 例如:"离婚财产" 和 "夫妻财产分割" 的向量距离很近
*
* @param text - 要编码的文本
* @returns 768 维浮点数组,失败返回空数组
*/
export async function generateEmbedding(text: string): Promise<number[]> {
try {
const res = await fetch(`${OLLAMA_BASE_URL}/api/embeddings`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: EMBEDDING_MODEL,
prompt: text.slice(0, 8000), // 截断超长文本
}),
});
if (!res.ok) {
console.error(`[Embedding] HTTP ${res.status}: ${await res.text()}`);
return [];
}
const data = (await res.json()) as { embedding?: number[] };
if (!data.embedding || data.embedding.length === 0) {
console.error("[Embedding] 返回空向量");
return [];
}
// 验证维度
if (data.embedding.length !== EMBEDDING_DIMENSION) {
console.warn(`[Embedding] 维度不匹配: 期望 ${EMBEDDING_DIMENSION}, 实际 ${data.embedding.length}`);
}
return data.embedding;
} catch (err) {
console.error(`[Embedding] 请求失败:`, err instanceof Error ? err.message : String(err));
return [];
}
}- 检索相关文档块,对比输入词性向量和知识库词向量的余弦相似度
/**
* 检索相关文档块(Embedding 版)
*
* 流程:
* 1. 把用户问题转成 Embedding 向量
* 2. 从数据库取出所有文档块的 Embedding
* 3. 逐个计算余弦相似度
* 4. 按相似度排序,返回 topK
*
* @param query - 用户问题
* @param options - 检索参数
* @returns 相关文档块数组(已按相似度降序排列)
*/
export async function searchRelevantChunks(
query: string,
options: {
topK?: number; // 返回几条结果
minScore?: number; // 最低相似度阈值(0-1)
category?: string; // 限定检索类别
} = {}
): Promise<SearchResult[]> {
const { topK = 5, minScore = 0.3, category } = options;
// --- 步骤 1:生成查询的 Embedding ---
console.log(`[RAG-Embed] 正在生成查询向量...`);
const queryEmbedding = await generateEmbedding(query);
if (queryEmbedding.length === 0) {
console.error("[RAG-Embed] 查询向量生成失败,返回空结果");
return [];
}
console.log(`[RAG-Embed] 查询向量已生成,维度: ${queryEmbedding.length}`);
// --- 步骤 2:从数据库取出文档块 ---
const db = getDb();
let chunks: Array<{
id: number;
docId: number;
content: string;
embedding: number[] | null;
chunkIndex: number;
}>;
if (category) {
// 限定类别:先查该类别下的文档 ID
const docs = await db
.select({ id: knowledgeDocs.id })
.from(knowledgeDocs)
.where(eq(knowledgeDocs.category, category));
const docIds = docs.map((d: { id: number }) => d.id);
if (docIds.length === 0) return [];
chunks = await db
.select({
id: documentChunks.id,
docId: documentChunks.docId,
content: documentChunks.content,
embedding: documentChunks.embedding,
chunkIndex: documentChunks.chunkIndex,
})
.from(documentChunks)
.where(sql`${documentChunks.docId} IN (${docIds.join(",")})`);
} else {
// 全库检索(只取有 embedding 的)
chunks = await db
.select({
id: documentChunks.id,
docId: documentChunks.docId,
content: documentChunks.content,
embedding: documentChunks.embedding,
chunkIndex: documentChunks.chunkIndex,
})
.from(documentChunks)
.where(sql`${documentChunks.embedding} IS NOT NULL`);
}
console.log(`[RAG-Embed] 数据库中有 ${chunks.length} 个带向量的文档块`);
if (chunks.length === 0) {
console.warn("[RAG-Embed] 没有可用的 Embedding 向量,请先重建索引");
return [];
}
// --- 步骤 3:计算相似度 ---
const results: SearchResult[] = [];
for (const chunk of chunks) {
if (!chunk.embedding || chunk.embedding.length === 0) continue;
const similarity = cosineSimilarity(queryEmbedding, chunk.embedding);
if (similarity >= minScore) {
// 获取文档标题
const doc = await db
.select()
.from(knowledgeDocs)
.where(eq(knowledgeDocs.id, chunk.docId))
.limit(1);
results.push({
chunkId: chunk.id,
docId: chunk.docId,
content: chunk.content,
similarity,
docTitle: doc[0]?.title || "未知文档",
docCategory: doc[0]?.category || "未分类",
});
}
}
// --- 步骤 4:排序取 topK ---
results.sort((a, b) => b.similarity - a.similarity);
const topResults = results.slice(0, topK);
console.log(`[RAG-Embed] 检索完成!找到 ${results.length} 条相关(>=${minScore}),返回 top${topK}`);
topResults.forEach((r, i) => {
console.log(`[RAG-Embed] 结果 ${i + 1}: [相似度 ${(r.similarity * 100).toFixed(1)}%] ${r.docTitle}`);
});
return topResults;
}就改这两块。
给出相关修改的两个文件:
- lib/rag.ts
import { getDb } from "../queries/connection";
import { documentChunks, knowledgeDocs } from "@db/schema";
import { eq, sql } from "drizzle-orm";
import { env } from "./env";
export interface SearchResult {
chunkId: number;
docId: number;
content: string;
similarity: number;
docTitle: string;
docCategory: string;
}
// 中文分词:按标点、空格分句,然后按字/词提取
function tokenize(text: string): string[] {
const cleaned = text.replace(/[\s\n\r\t]+/g, " ")
.replace(/[,。、;:?!""''()《》【】]/g, " ")
.trim();
const tokens: string[] = [];
// 把上面那些符合都变成空格后,下面就直接用空格分割了
const words = cleaned.split(/\s+/);
// 这里是滑动窗口形式的分词分割,不用过的研究
for (const word of words) {
if (word.length <= 1) continue;
tokens.push(word);
for (let i = 0; i < word.length - 1; i++) {
tokens.push(word.slice(i, i + 2));
if (i < word.length - 2) {
tokens.push(word.slice(i, i + 3));
}
}
}
return tokens;
}
/**
* 计算“词频(Term Frequency)” 每个 token 在文本中出现的相对频率
* 统计每个词出现了多少次 → 再除以总词数 → 得到归一化的 TF
* @param tokens
* @returns Map<string, number> 注意声明方法返回类型的方式
*/
function computeTF(tokens: string[]): Map<string, number> {
const tf = new Map<string, number>();
for (const token of tokens) {
tf.set(token, (tf.get(token) || 0) + 1);
}
const total = tokens.length;
for (const [key, val] of tf) {
tf.set(key, val / total);
}
return tf;
}
/**
* 计算“逆文档频率(IDF)”
* 衡量 一个词在整个知识库中有多“稀有”
* 这里计算的是词出现的文档个数,不是词的总出现次数
* @returns
*/
async function computeGlobalIDF(): Promise<Map<string, number>> {
const db = getDb();
const chunks = await db
.select({ content: documentChunks.content })
.from(documentChunks);
const docFreq = new Map<string, number>();
const totalDocs = chunks.length;
if (totalDocs === 0) return new Map();
for (const chunk of chunks) {
const tokens = new Set(tokenize(chunk.content));
for (const token of tokens) {
docFreq.set(token, (docFreq.get(token) || 0) + 1);
}
}
const idf = new Map<string, number>();
for (const [term, df] of docFreq) {
idf.set(term, Math.log(totalDocs / (df + 1)) + 1);
}
return idf;
}
/**
* 把“词频(TF)”和“稀缺度(IDF)”乘起来 得到 综合重要性
* @param tf 这个词在当前文档有多常见
* @param idf 这个词在整个库有多稀有
* @returns 综合重要性
*/
function computeTFIDF(
tf: Map<string, number>,
idf: Map<string, number>
): Map<string, number> {
const tfidf = new Map<string, number>();
for (const [term, tfVal] of tf) {
const idfVal = idf.get(term) || 0;
tfidf.set(term, tfVal * idfVal);
}
return tfidf;
}
/**
* 计算两个向量的余弦相似度
*
* 相似度范围:-1(完全相反)到 1(完全相同)
* 通常Embedding向量都在0-1之间
* 余弦相似度就是= a点乘b/(根号a*a) * (根号b*b)
* @param vecA - 向量 A
* @param vecB - 向量 B
* @returns 相似度得分(0-1 之间)
*/
export function cosineSimilarity(vecA: number[], vecB: number[]): number {
if (vecA.length !== vecB.length) {
console.warn(`[RAG] 向量维度不匹配: ${vecA.length} vs ${vecB.length}`);
return 0;
}
let dotProduct = 0;
let normA = 0;
let normB = 0;
for (let i = 0; i < vecA.length; i++) {
dotProduct += vecA[i] * vecB[i];
normA += vecA[i] * vecA[i];
normB += vecB[i] * vecB[i];
}
if (normA === 0 || normB === 0) return 0;
const similarity = dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));
// 将 -1~1 映射到 0~1(便于阈值比较)
return (similarity + 1) / 2;
}
let globalIDF: Map<string, number> | null = null;
let lastChunkCount = 0;
/**
* 只在 文档数量变化时 才重新计算, 否则直接返回缓存
* @returns
*/
async function getIDF(): Promise<Map<string, number>> {
const db = getDb();
const countResult = await db
.select({ count: sql<number>`count(*)` })
.from(documentChunks);
const count = countResult[0]?.count || 0;
if (!globalIDF || count !== lastChunkCount) {
globalIDF = await computeGlobalIDF();
lastChunkCount = count;
}
return globalIDF;
}
const OLLAMA_BASE_URL = env.ollamaUrl || "http://localhost:11434";
/** Embedding 模型名称,通过 Ollama 本地运行 */
const EMBEDDING_MODEL = "nomic-embed-text";
/** 向量维度(nomic-embed-text 输出 768 维) */
export const EMBEDDING_DIMENSION = 768;
/**
* 调用 Ollama nomic-embed-text 生成文本的向量表示
*
* 原理:把一段文字转换成 768 个数字(浮点数数组)
* 语义相近的文字,向量距离也相近
* 例如:"离婚财产" 和 "夫妻财产分割" 的向量距离很近
*
* @param text - 要编码的文本
* @returns 768 维浮点数组,失败返回空数组
*/
export async function generateEmbedding(text: string): Promise<number[]> {
try {
const res = await fetch(`${OLLAMA_BASE_URL}/api/embeddings`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: EMBEDDING_MODEL,
prompt: text.slice(0, 8000), // 截断超长文本
}),
});
if (!res.ok) {
console.error(`[Embedding] HTTP ${res.status}: ${await res.text()}`);
return [];
}
const data = (await res.json()) as { embedding?: number[] };
if (!data.embedding || data.embedding.length === 0) {
console.error("[Embedding] 返回空向量");
return [];
}
// 验证维度
if (data.embedding.length !== EMBEDDING_DIMENSION) {
console.warn(`[Embedding] 维度不匹配: 期望 ${EMBEDDING_DIMENSION}, 实际 ${data.embedding.length}`);
}
return data.embedding;
} catch (err) {
console.error(`[Embedding] 请求失败:`, err instanceof Error ? err.message : String(err));
return [];
}
}
/**
* 检索相关文档块(Embedding 版)
*
* 流程:
* 1. 把用户问题转成 Embedding 向量
* 2. 从数据库取出所有文档块的 Embedding
* 3. 逐个计算余弦相似度
* 4. 按相似度排序,返回 topK
*
* @param query - 用户问题
* @param options - 检索参数
* @returns 相关文档块数组(已按相似度降序排列)
*/
export async function searchRelevantChunks(
query: string,
options: {
topK?: number; // 返回几条结果
minScore?: number; // 最低相似度阈值(0-1)
category?: string; // 限定检索类别
} = {}
): Promise<SearchResult[]> {
const { topK = 5, minScore = 0.3, category } = options;
// --- 步骤 1:生成查询的 Embedding ---
console.log(`[RAG-Embed] 正在生成查询向量...`);
const queryEmbedding = await generateEmbedding(query);
if (queryEmbedding.length === 0) {
console.error("[RAG-Embed] 查询向量生成失败,返回空结果");
return [];
}
console.log(`[RAG-Embed] 查询向量已生成,维度: ${queryEmbedding.length}`);
// --- 步骤 2:从数据库取出文档块 ---
const db = getDb();
let chunks: Array<{
id: number;
docId: number;
content: string;
embedding: number[] | null;
chunkIndex: number;
}>;
if (category) {
// 限定类别:先查该类别下的文档 ID
const docs = await db
.select({ id: knowledgeDocs.id })
.from(knowledgeDocs)
.where(eq(knowledgeDocs.category, category));
const docIds = docs.map((d: { id: number }) => d.id);
if (docIds.length === 0) return [];
chunks = await db
.select({
id: documentChunks.id,
docId: documentChunks.docId,
content: documentChunks.content,
embedding: documentChunks.embedding,
chunkIndex: documentChunks.chunkIndex,
})
.from(documentChunks)
.where(sql`${documentChunks.docId} IN (${docIds.join(",")})`);
} else {
// 全库检索(只取有 embedding 的)
chunks = await db
.select({
id: documentChunks.id,
docId: documentChunks.docId,
content: documentChunks.content,
embedding: documentChunks.embedding,
chunkIndex: documentChunks.chunkIndex,
})
.from(documentChunks)
.where(sql`${documentChunks.embedding} IS NOT NULL`);
}
console.log(`[RAG-Embed] 数据库中有 ${chunks.length} 个带向量的文档块`);
if (chunks.length === 0) {
console.warn("[RAG-Embed] 没有可用的 Embedding 向量,请先重建索引");
return [];
}
// --- 步骤 3:计算相似度 ---
const results: SearchResult[] = [];
for (const chunk of chunks) {
if (!chunk.embedding || chunk.embedding.length === 0) continue;
const similarity = cosineSimilarity(queryEmbedding, chunk.embedding);
if (similarity >= minScore) {
// 获取文档标题
const doc = await db
.select()
.from(knowledgeDocs)
.where(eq(knowledgeDocs.id, chunk.docId))
.limit(1);
results.push({
chunkId: chunk.id,
docId: chunk.docId,
content: chunk.content,
similarity,
docTitle: doc[0]?.title || "未知文档",
docCategory: doc[0]?.category || "未分类",
});
}
}
// --- 步骤 4:排序取 topK ---
results.sort((a, b) => b.similarity - a.similarity);
const topResults = results.slice(0, topK);
console.log(`[RAG-Embed] 检索完成!找到 ${results.length} 条相关(>=${minScore}),返回 top${topK}`);
topResults.forEach((r, i) => {
console.log(`[RAG-Embed] 结果 ${i + 1}: [相似度 ${(r.similarity * 100).toFixed(1)}%] ${r.docTitle}`);
});
return topResults;
}
/**
* 按字符长度切分文本,并在句号处尽量断句,同时保留上下文重叠
* @param content
* @param chunkSize
* @param overlap
* @returns
*/
export function splitIntoChunks(
content: string,
chunkSize: number = 500,
overlap: number = 100,
): string[] {
const chunks: string[] = [];
let start = 0;
while (start < content.length) {
const end = Math.min(start + chunkSize, content.length);
let splitPoint = end;
if (end < content.length) {
const lastPeriod = content.lastIndexOf("。", start + chunkSize);
if (lastPeriod > start + chunkSize * 0.5) {
splitPoint = lastPeriod + 1;
}
}
chunks.push(content.slice(start, splitPoint).trim());
start = splitPoint - overlap;
if (start < splitPoint * 0.5) start = splitPoint;
}
return chunks.filter((c) => c.length > 20);
}
/**
* 为某个文档的所有 chunk 预计算 TF‑IDF 向量并写回数据库
* @param docId
*/
export async function indexDocumentChunks(docId: number) {
const db = getDb();
const chunks = await db
.select()
.from(documentChunks)
.where(eq(documentChunks.docId, docId));
//解释下 这里调用函数为啥要用await,因为getIdf是用async修饰了。
// 表示异步,但是我们不想这个方法异步操作,而是同步,就需要用await
// 所以await和async是一起存在的
// 还有因为数据库是I/0操作,也就是要等,但是Node.js是单线程的,不能因为这个操作就卡住其他的功能,所以用都用了异步操作
// 而java这种语言就是多线程,即使一个线程卡住,不影响其他的请求。
const idf = await getIDF();
for (const chunk of chunks) {
const tokens = tokenize(chunk.content);
const tf = computeTF(tokens);
const tfidf = computeTFIDF(tf, idf);
const vectorObj: Record<string, number> = {};
for (const [k, v] of tfidf) {
vectorObj[k] = v;
}
await db
.update(documentChunks)
.set({
tfidfVector: vectorObj,
keywords: Array.from(tf.keys()).slice(0, 20).join(","),
})
.where(eq(documentChunks.id, chunk.id));
}
await db
.update(knowledgeDocs)
.set({ chunkCount: chunks.length })
.where(eq(knowledgeDocs.id, docId));
globalIDF = null;
}
export async function clearAllChunks() {
const db = getDb();
await db.delete(documentChunks);
globalIDF = null;
lastChunkCount = 0;
}
/**
* 统计知识库的整体规模与分类信息
*
* 注意这个方法没有定义返回类型,因为TS 会自动推断出返回类型 Promise<{
totalDocs: number;
totalChunks: number;
categories: string[];
}>
但是建议 强制写返回类型,防止不小心改返回值,可以在编码阶段就发现错误。
* @returns
*/
export async function getKnowledgeStats() {
const db = getDb();
const docsCount = await db
.select({ count: sql<number>`count(*)` })
.from(knowledgeDocs);
const chunksCount = await db
.select({ count: sql<number>`count(*)` })
.from(documentChunks);
const categories = await db
.selectDistinct({ category: knowledgeDocs.category })
.from(knowledgeDocs);
return {
totalDocs: docsCount[0]?.count || 0,
totalChunks: chunksCount[0]?.count || 0,
categories: categories.map((c: { category: string }) => c.category),
};
}
- lib/chat-stream-handler.ts
/**
* Hono 流式对话处理器
* 完整数据流转:
* 1,接受post请求
* 2,保存用户消息到数据库
* 3,RAG检索本地知识库
* 4,组装系统提示词
* 5,获取历史消息
* 6,发送给ollama
* 7,读取sse流式处理,逐个token推送给前端
* 8,流结束时保存助手回复到数据库
*/
import { getDb } from "../queries/connection";
import { conversations, messages } from "@db/schema";
import { eq, desc, asc } from "drizzle-orm";
import { searchRelevantChunks } from "./rag";
import { getLegalSystemPrompt, type OllamaMessage } from "./ollama";
import { env } from "./env";
const OLLAMA_BASE_URL = env.ollamaUrl || "http://localhost:11434";
// interface是声明一个结构的描述 不是类,不能new 跟java挺像的,java的interface也是不能new的。只是作为一种类型,用来引用的。
// 更形象的解释:只要一个对象满足:有 content(string)有 model(string)它就是 StreamBody
interface StreamBody {
// ?表示可有可没有,没有问号就必须要有了
conversationId?: number;
content: string;
model: string;
useRAG?: boolean;
temperature?: number;
topP?: number;
topK?: number;
numCtx?: number;
repeatPenalty?: number;
category?: string;
}
/**
* 处理流式对话请求
* 相对于TF-IDF的方式,区别就是把用户输入的句子调用ollama的embadding向量模型,会得到这个句子的一组向量
* 然后再拿这个向量跟已经训练好的知识库每个句子的向量做余弦相似度对比。达到一定相似程度,并且取前几个。
* 后面就跟TF-IDF的处理方式一样了。汇总输入句子和知识库中的句子,融入到系统提示词中。
* 最后就可以请求ollama大模型了。
*
* 日志输出说明(查看方式:终端窗口中会打印):
* - [RAG] 开头:知识库检索相关日志
* - [Ollama] 开头:模型调用相关日志
* - [Chat] 开头:整体流程日志
*
*
*/
export async function handleChatStream(body: StreamBody) {
const db = getDb();
const startTime = Date.now();
console.log("\n========================================");
console.log(`[Chat] 收到新请求: "${body.content.slice(0, 60)}..."`);
console.log(`[Chat] 模型: ${body.model} | RAG: ${body.useRAG !== false}`);
console.log("========================================\n");
// 保存对话模型
let conversationId = body.conversationId;
if (!conversationId) {
const result = await db.insert(conversations).values({
title: body.content.slice(0, 30) + "...",
model: body.model,
});
conversationId = Number(result[0].insertId);
console.log(`[Chat] 创建新对话: ID=${conversationId}`);
} else {
console.log(`[Chat] 继续对话: ID=${conversationId}`);
}
// ========== 步骤 2:保存用户消息 ==========
await db.insert(messages).values({
conversationId,
role: "user",
content: body.content,
});
console.log(`[Chat] 用户消息已保存(${body.content.length} 字)`);
// ========== 步骤 3:RAG 检索知识库 ==========
// let sources:是在声明一个变量的类型。 这也是ts编程的特点,先定义类型,跟js不一样, js的话 一上来就let sources=值。
let sources: Array<{ title: string; content: string; similarity: number }> = []
let contextChunks: string[] = [];
if (body.useRAG != false) {
console.log("[RAG]开始检索知识库。。。");
const ragStart = Date.now();
const results = await searchRelevantChunks(body.content, {
topK: 5,
minScore: 0.03,
category: body.category,
});
//计算检索时间
const ragDuration = Date.now() - ragStart;
if (results.length > 0) {
console.log(`[RAG] 检索完成!找到 ${results.length} 条相关内容(耗时 ${ragDuration}ms)`);
sources = results.map((r) => ({
title: `${r.docTitle}(${r.docCategory})`,
content: r.content,
similarity: Math.round(r.similarity * 1000) / 1000,
}));
contextChunks = results.map((r) => `[来源:${r.docTitle}]\n${r.content}`);
// 打印检索到的内容摘要
results.forEach((r, i) => {
console.log(`[RAG] 结果 ${i + 1}: [相似度 ${(r.similarity * 100).toFixed(1)}%] ${r.docTitle}`);
console.log(`[RAG] 内容: ${r.content.slice(0, 100)}...`);
});
} else {
console.log(`[RAG] 警告!未找到相关内容(耗时 ${ragDuration}ms),将使用模型自身知识回答`);
}
} else {
console.log(`[RAG] 知识库检索已关闭,跳过`);
}
// ========== 步骤 4:组装系统提示词 ==========
const systemPrompt = getLegalSystemPrompt(
contextChunks.length > 0 ? contextChunks : undefined
);
console.log(`\n[Chat] 系统提示词长度: ${systemPrompt.length} 字`);
if (contextChunks.length > 0) {
console.log(`[Chat] 提示词中包含 ${contextChunks.length} 条参考资料`);
}
// ========== 步骤 5:获取历史消息 ==========
const history = await db
.select()
.from(messages)
.where(eq(messages.conversationId, conversationId))
.orderBy(asc(messages.createdAt))
.limit(20);
console.log(`[Chat] 历史消息: ${history.length} 条`);
// ========== 步骤 6:构建 Ollama 消息列表 ==========
const ollamaMessages: OllamaMessage[] = [];
ollamaMessages.push({ role: "system", content: systemPrompt });
// 把相关的历史问答都加到提示词中
for (const msg of history) {
if (msg.role === "user" || msg.role === "assistant") {
ollamaMessages.push({ role: msg.role, content: msg.content });
}
}
// ========== 步骤 7:调用 Ollama ==========
//解释下这里的变量为啥要用${}, 因为这里是字符串模板,在字符串中插入变量,所以要用$,这点跟python和shell脚本很像。
console.log(`\n[Ollama] 发送请求到 ${OLLAMA_BASE_URL}`);
console.log(`[Ollama] 模型: ${body.model}`);
console.log(`[Ollama] 参数: temperature=${body.temperature ?? 0.7}, top_p=${body.topP ?? 0.9}, num_ctx=${body.numCtx ?? 4096}`);
console.log(`[Ollama] 提示词:`, JSON.stringify(ollamaMessages, null, 2))
const ollamaStart = Date.now();
const ollamaRes = await fetch(`${OLLAMA_BASE_URL}/api/chat`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: body.model,
messages: ollamaMessages,
stream: true,
options: {
temperature: body.temperature ?? 0.7,
top_p: body.topP ?? 0.9,
top_k: body.topK ?? 40,
num_ctx: body.numCtx ?? 4096,
repeat_penalty: body.repeatPenalty ?? 1.1,
},
}),
});
if (!ollamaRes.ok || !ollamaRes.body) {
console.error(`[Ollama] 请求失败: HTTP ${ollamaRes.status}`);
throw new Error(`Ollama 请求失败: ${ollamaRes.status}`);
}
const ollamaConnectTime = Date.now() - ollamaStart;
console.log(`[Ollama] 连接成功(耗时 ${ollamaConnectTime}ms),开始接收流...\n`);
// ========== 步骤 8:组装 SSE 响应 ==========
/**
* “Server-Sent Events(SSE)流式响应”
* 👉 一边从 Ollama 拿 token
* 👉 一边往前端的浏览器推
* 👉 结束后一次性写入数据库
*
* */
//创建编码器
const encoder = new TextEncoder();
let fullContent = "";
let tokenCount = 0;
/**
* ReadableStream是关键
* 基本结构:
* new ReadableStream({
start(controller) {
// 这里写“怎么产生数据”
}
});
* */
return new ReadableStream({
//这里start(controller)很奇怪 没有地方传入controller?
// 因为这是在node,hono内部调用的。 是ReadableStream是关键的基本结构
// controller是一个回调函数参数
async start(controller) {
try {
const reader = ollamaRes.body!.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
const lines = chunk.split("\n").filter((l) => l.trim());
for (const line of lines) {
try {
const json = JSON.parse(line) as {
message?: { content?: string };
done?: boolean;
eval_count?: number;
prompt_eval_count?: number;
};
if (json.message?.content) {
fullContent += json.message.content;
tokenCount++;
controller.enqueue(
encoder.encode(
`data: ${JSON.stringify({
type: "token",
content: json.message.content,
})}\n\n`
)
);
}
if (json.done) {
const totalDuration = Date.now() - startTime;
console.log("\n========================================");
console.log(`[Chat] 生成完成!总耗时 ${totalDuration}ms`);
console.log(`[Chat] 生成 token 数: ~${tokenCount}`);
console.log(`[Chat] 回复长度: ${fullContent.length} 字`);
console.log(`[Chat] 使用了 ${sources.length} 条参考资料`);
console.log("========================================\n");
// 保存助手回复到数据库
await db.insert(messages).values({
conversationId,
role: "assistant",
content: fullContent || "(无回复)",
sources: sources.length > 0 ? sources : undefined,
metadata: {
temperature: body.temperature ?? 0.7,
topP: body.topP ?? 0.9,
topK: body.topK ?? 40,
numCtx: body.numCtx ?? 4096,
duration: totalDuration,
},
});
// 更新对话时间
await db
.update(conversations)
.set({ updatedAt: new Date() })
.where(eq(conversations.id, conversationId));
controller.enqueue(
encoder.encode(
`data: ${JSON.stringify({
type: "done",
conversationId,
sources,
})}\n\n`
)
);
controller.close();
return;
}
} catch {
// 忽略解析失败的行
}
}
}
// 流正常结束但没有 done 标记(保险处理)
if (fullContent) {
await db.insert(messages).values({
conversationId,
role: "assistant",
content: fullContent,
sources: sources.length > 0 ? sources : undefined,
});
}
controller.enqueue(
encoder.encode(
`data: ${JSON.stringify({ type: "done", conversationId, sources })}\n\n`
)
);
controller.close();
} catch (err) {
console.error(`[Chat] 流处理错误:`, err);
controller.error(err);
}
},
});
}
调用接口:http://localhost:3000/api/chat/stream
参数:{"conversationId":12,"content":"劳动合同纠纷如何处理?","model":"qwen2.5:7b","useRAG":true,"temperature":1.4,"topP":0.4,"topK":40,"numCtx":4096,"repeatPenalty":1.1}
调用日志如下:
PS D:\workplace\AI\rag-embadding-legal-ai-app> npm rum dev
> rag-embadding-legal-ai-app@0.0.0 dev
> vite
VITE v7.3.0 ready in 534 ms
➜ Local: http://localhost:3000/
➜ Network: http://192.168.0.102:3000/
➜ press h + enter to show help
sddssd
========================================
[Chat] 收到新请求: "劳动合同纠纷如何处理?..."
[Chat] 模型: qwen2.5:7b | RAG: true
========================================
[Chat] 继续对话: ID=12
[Chat] 用户消息已保存(11 字)
[RAG]开始检索知识库。。。
[RAG-Embed] 正在生成查询向量...
[RAG-Embed] 查询向量已生成,维度: 768
[RAG-Embed] 数据库中有 72 个带向量的文档块
[RAG-Embed] 检索完成!找到 72 条相关(>=0.03),返回 top5
[RAG-Embed] 结果 1: [相似度 88.7%] 中华人民共和国劳动法
[RAG-Embed] 结果 2: [相似度 88.4%] 中华人民共和国民法典 - 婚姻家庭编
[RAG-Embed] 结果 3: [相似度 87.9%] 中华人民共和国劳动法
[RAG-Embed] 结果 4: [相似度 86.9%] 中华人民共和国民法典 - 总则编
[RAG-Embed] 结果 5: [相似度 86.4%] 中华人民共和国劳动法
[RAG] 检索完成!找到 5 条相关内容(耗时 198ms)
[RAG] 结果 1: [相似度 88.7%] 中华人民共和国劳动法
[RAG] 内容: 第二十一条 劳动合同可以约定试用期。试用期最长不得超过六个月。...
[RAG] 结果 2: [相似度 88.4%] 中华人民共和国民法典 - 婚姻家庭编
[RAG] 内容: )与他人同居;(三)实施家庭暴力;(四)虐待、遗弃家庭成员;(五)有其他重大过错。...
[RAG] 结果 3: [相似度 87.9%] 中华人民共和国劳动法
[RAG] 内容: 第三十一条 劳动者解除劳动合同,应当提前三十日以书面形式通知用人单位。...
[RAG] 结果 4: [相似度 86.9%] 中华人民共和国民法典 - 总则编
[RAG] 内容: 第一百一十八条 民事主体依法享有债权。债权是因合同、侵权行为、无因管理、不当得利以及法律的其他规定,权利人请求特定义务人为或者不为一定行为的权利。
第六章 民事法律行为...
[RAG] 结果 5: [相似度 86.4%] 中华人民共和国劳动法
[RAG] 内容: 第二十六条 有下列情形之一的,用人单位可以解除劳动合同,但是应当提前三十日以书面形式通知劳动者本人:(一)劳动者患病或者非因工负伤,医疗期满后,不能从事原工作也不能从事由用人单位另行安排的工作的;(二...
[Chat] 系统提示词长度: 696 字
[Chat] 提示词中包含 5 条参考资料
[Chat] 历史消息: 5 条
[Ollama] 发送请求到 http://localhost:11434
[Ollama] 模型: qwen2.5:7b
[Ollama] 参数: temperature=1.4, top_p=0.4, num_ctx=4096
[Ollama] 提示词: [
{
"role": "system",
"content": "你是一位专业的中国法律顾问,精通宪法、民法典、刑法、行政法、商法、劳动法等各领域的法律法规。\n\n工作原则:\n1. 基于用户提供的参考资料回答问题,优先引用具体法条\n2. 如果问题涉及多个法律领域,分层次说明\n3. 对复杂问题,先给出结论,再展开法律依据\n4. 不确定的问题明确告知用户需要咨询专业律师\n5. 回答使用中文,保持专业、客观、严谨\n6. 引用法条时标注法律名称和具体条款\n\n参考资料:\n[来源:中华人民共和国劳动法]\n第二十一条 劳动合同可以约定试用期。试用期最长不得超过六个月。\n---\n[来源:中华人民共和国民法典 - 婚姻家庭编]\n)与他人同居;(三)实施家庭暴力;(四)虐待、遗弃家庭成员;(五)有其他重大过错。\n---\n[来源:中华人民共和国劳动法]\n第三十一条 劳动者解除劳动合同,应当提前三十日以书面形式通知用人单位。\n---\n[来源:中华人民共和国民法典 - 总则编]\n第一百一十八条 民事主体依法享有债权。债权是因合同、侵权行为、无因管理、不当得利以及法律的其他规定,权利人请求特定义务人为或者不为一定行为的权利。\n\n第六章 民事法律行为\n---\n[来源:中华人民共和国劳动法]\n第二十六条 有下列情形之一的,用人单位可以解除劳动合同,但是应当提前三十日以书面形式通知劳动者本人:(一)劳动者患病或者非因工负伤,医疗期满后,不能从事原工作也不能从事由用人单位另行安排的工作的;(二)劳动者不能胜任工作,经过培训或者调整工作岗位,仍不能胜任工作的;(三)劳动合同订立时所依据的客观情况发生重大变化,致使原劳动合同无法履行,经当事人协商不能就变更劳动合同达成协议的。"
},
{
"role": "user",
"content": "劳动合同纠纷如何处理?"
},
{
"role": "assistant",
"content": "劳动合同纠纷是指劳动者与用人单位之间因劳动关系而产生的争议。这类纠纷通常涉及工资、工时、福利待遇、工作条件、合同条款等方面的问题。根据《中华人民共和国劳动法》及相关法律法规,劳动合同纠纷的处理可以遵循以下步骤:\n\n1. **协商解决**:首先鼓励双方通过友好协商的方式自行解决纠纷。这是最直接和高效的方法。\n\n2. **调解**:如果协商不成,劳动者或用人单位可以向本单位劳动争议调解委员会申请调解;也可以向依法设立的基层人民调解组织、在乡镇、街道设立的具有劳动争议调解职能的组织申请调解。\n\n3. **仲裁**:若调解未果,任何一方均可自争议发生之日起一年内向劳动争议仲裁委员会提出书面仲裁申请。劳动争议仲裁委员会是处理劳动争议案件的专业机构,其裁决对双方都有约束力。\n\n4. **诉讼**:对于不服劳动争议仲裁委员会裁决的当事人,可以在收到裁决书之日起十五日内向人民法院提起诉讼。法院将根据事实和法律作出判决。\n\n具体到不同类型的劳动合同纠纷,可能还需要适用特定的法律规定。例如:\n\n- **工资争议**:依据《中华人民共和国劳动法》第四十六条、第五十条等相关规定处理。\n- **解除合同争议**:参照《中华人民共和国劳动法》第三十一条关于劳动者提前三十日以书面形式通知用人单位的规定;以及《劳动合同法》第三十八条至四十七条关于解除或终止劳动合同的补偿等条款。\n\n在处理过程中,应当注意保留相关证据材料,如劳动合同、工资条、考勤记录等。必要时可寻求专业律师的帮助进行法律咨询和代理诉讼事宜。"
},
{
"role": "user",
"content": "劳动合同纠纷如何处理?"
},
{
"role": "assistant",
"content": "劳动合同纠纷是指劳动者与用人单位之间因劳动关系而产生的争议。这类纠纷通常涉及工资、工时、福利待遇、工作条件、合同条款等方面的问题。根据《中华人民共和国劳动法》及相关法律法规,劳动合同纠纷的处理可以遵循以下步骤:\n\n1. **协商解决**\n - 首先鼓励双方通过友好协商的方式自行解决纠纷。\n - 双方应尽量保持沟通,明确争议的具体问题,并寻求合理的解决方案。\n\n2. **调解**\n - 如果协商未果,劳动者或用人单位可以向本单位劳动争议调解委员会申请调解。\n - 也可以向依法设立的基层人民调解组织、在乡镇、街道设立的具有劳动争议调解职能的组织申请调解。\n\n3. **仲裁**\n - 若调解未果,任何一方均可自争议发生之日起一年内向劳动争议仲裁委员会提出书面仲裁申请。\n - 劳动争议仲裁委员会是处理劳动争议案件的专业机构,其裁决对双方都有约束力。根据《中华人民共和国劳动争议调解仲裁法》第二条的规定,因确认劳动关系发生的争议、因订立、履行、变更、解除和终止劳动合同发生的争议等均属于劳动争议仲裁的范围。\n\n4. **诉讼**\n - 对于不服劳动争议仲裁委员会裁决的当事人,可以在收到裁决书之日起十五日内向人民法院提起诉讼。\n - 法院将根据事实和法律作出判决。根据《中华人民共和国民事诉讼法》第一百二十二条的规定,对符合起诉条件的案件应当受理。\n\n具体到不同类型的劳动合同纠纷,可能还需要适用特定的法律规定:\n\n- **工资争议**:依据《中华人民共和国劳动法》第四十六条、第五十条等相关规定处理。\n - 第四十六条规定:“劳动者在法定休假日和婚丧假期间以及依法参加社会活动期间,用人单位应当依法支付工资。”\n - 第五十条规定:“工资应当以货币形式按月支付给劳动者本人。不得克扣或者无故拖欠劳动者的工资。”\n\n- **解除合同争议**:参照《中华人民共和国劳动合同法》第三十八条至四十七条关于解除或终止劳动合同的补偿等条款。\n - 第三十八条规定了劳动者可以单方解除劳动合同的情形,如用人单位未及时足额支付劳动报酬、未依法为劳动者缴纳社会保险费等。\n - 第四十七条规定了经济补偿金的计算标准。\n\n在处理过程中,应当注意保留相关证据材料,如劳动合同、工资条、考勤记录等。必要时可寻求专业律师的帮助进行法律咨询和代理诉讼事宜。"
},
{
"role": "user",
"content": "劳动合同纠纷如何处理?"
}
]
[Ollama] 连接成功(耗时 52678ms),开始接收流...
========================================
[Chat] 生成完成!总耗时 138177ms
[Chat] 生成 token 数: ~637
[Chat] 回复长度: 1207 字
[Chat] 使用了 5 条参考资料
========================================相关源码见:https://download.csdn.net/download/csdnliuxin123524/92909941
记录一个清包命令:
-
Remove-Item -Recurse -Force node_modules

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)