为什么我的 DPDK 程序明明没有丢包,但业务就是“卡”?一次排查让我彻底理解 queue backlog
我在做 DPDK 开发时,判断系统是否健康,通常会先看:
- PPS
- CPU
- 丢包率
- NIC error
- descriptor usage
因为默认认为:没有丢包 = 系统没问题。
但我曾经遇到一个非常诡异的问题:
系统:
- 没有丢包
- CPU 没打满
- 网卡正常
- RX/TX descriptor 正常
- worker 也没 crash
然而:业务层却明显感觉:“系统越来越卡”。
表现为:
- RTT 逐渐升高
- 请求响应越来越慢
- ping 抖动明显
- tail latency 爆炸
- PPS 看起来却依然稳定
最奇怪的是:所有监控:都“正常”。
第一次遇到时,我怀疑过:
- NUMA
- false sharing
- RX descriptor
- burst 太大
- CPU 降频
最后才发现:
真正的问题竟然是:queue backlog(队列积压)。
而这个问题,也让我真正理解了:
高性能系统里:“不丢包”不代表“低时延”。
一、问题现场
系统结构:
RX core:收包。
worker core:业务处理。
TX core:发包。
中间通过:DPDK Ring 进行线程通信。
二、系统指标一切正常
监控显示:
CPU
70%PPS
稳定。
网卡
无 error。
丢包
0但业务层反馈:
越来越慢三、真正奇怪的地方
系统不是:“瞬间卡死”。
而是:延迟越来越高。
例如:
初始 RTT
40us半小时后
200us高峰期
2ms但:依然:不丢包。
四、第一反应:是不是 burst 太大
因为:之前遇到过:burst batching delay。
于是:调小:
rte_eth_rx_burst(..., 8)结果:稍微改善。但问题仍然存在。
五、后来终于发现关键问题
打印:
rte_ring_count()结果发现:ring 长度:持续增加。
例如:
初始
32一段时间后
500高峰期
2000+这里终于暴露问题。
六、什么是 queue backlog
即:包没有丢。
但:正在队列里排队等待。
七、为什么“不丢包”反而更危险
很多系统:队列很深。
例如:
RX descriptor
software ring
worker queue
TX queue
这些 queue:可以暂时“吞掉”压力。
于是:看起来:系统没丢包。
但实际上:latency 正在疯狂增长。
八、这本质上是“排队论”问题
系统处理速度:略低于:流量进入速度。
例如:
ingress
10.2 Mppsprocessing
10.0 Mpps每秒:
积压:
0.2 M packet短时间:看不出来。
但时间一长:queue 越来越深。
九、为什么 PPS 看起来仍然正常
因为:系统最终还是:“处理完了”。
所以:吞吐没明显下降。
但:packet 已经在 queue 中等待了很久。
十、这就是 latency creep
即:时延缓慢增长。
它不像:瞬间丢包。
更隐蔽。也更难排查。
十一、为什么 CPU 没打满
因为:瓶颈不一定是:算力。
而可能是:
某个 worker imbalance
某个 flow hotspot
cache miss
memory stall
导致:
pipeline 某一级:
略慢。
十二、进一步理解 pipeline
DPDK 程序本质是:packet pipeline。
结构:
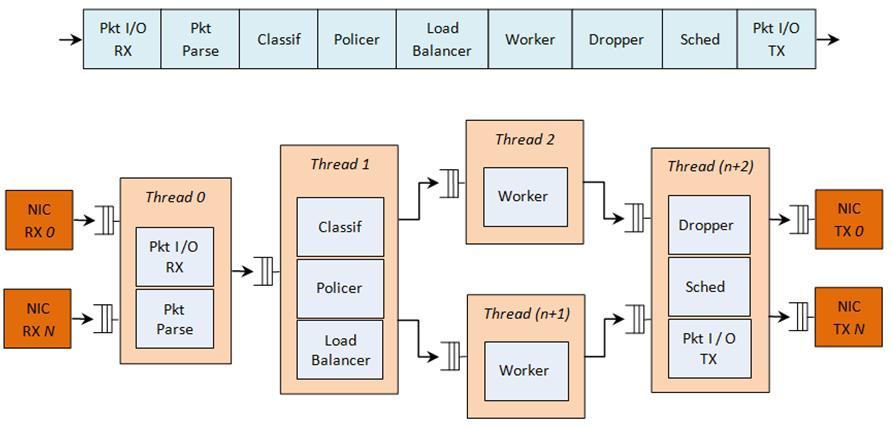
RX -> ring -> worker -> TX只要任意一级:处理略慢。
queue 就会积压。
十三、为什么 latency 会指数恶化
因为:queue waiting time:不是线性增长。
在高 utilization 下:会急剧放大。
这是经典:queueing theory。
十四、一个非常经典的误区
很多人优化:
只关注:
maximum throughput但真实系统:更重要的是:sustained throughput。
即:长期稳定处理能力。
十五、真正危险的是“长期略慢”
如果:worker 永远比 ingress 慢:
1%最终:queue 一定爆炸。
只是:时间问题。
十六、为什么大 queue 有时是坏事
很多人喜欢:
把 ring 调很大因为:“不容易丢包”。
但实际上:大 queue:
可能只是:把丢包变成高延迟。
十七、为什么 tail latency 会爆炸
因为:后进入 queue 的 packet:必须等待:前面所有 packet。
于是:
average latency
可能正常。
P99/P999
会非常难看。
十八、真正修复思路
后来做了几个关键优化。
1. 增加 backpressure
当 queue 超过 watermark:主动限流。
2. ring 设置合理大小
避免无限积压。
3. hotspot flow 分流
避免单 worker 被打爆。
4. worker pipeline 优化
减少单包处理波动。
十九、另一个关键优化:及时丢包
后来甚至主动:
early drop即:queue 过深时:提前丢弃。
二十、为什么“主动丢包”反而更好
因为:真实业务:通常:更怕高时延。
而不是:少量丢包。
尤其:
实时语音
游戏
金融
高 latency:
比 packet loss 更致命。
二十一、优化后结果
优化前:
| 指标 | 数值 |
|---|---|
| PPS | 稳定 |
| Avg RTT | 60us |
| P999 | 8ms |
优化后:
| 指标 | 数值 |
|---|---|
| PPS | 略降 |
| Avg RTT | 45us |
| P999 | 120us |
业务体验:大幅提升。
二十二、为什么很多 benchmark 没意义
很多 benchmark:
只看:
是否丢包或者:
最大 PPS但真实系统:真正关键的是:
queue depth
latency stability
tail latency
sustained load
二十三、进一步理解 DPDK 哲学
DPDK 真正复杂的部分:从来不是:API。
而是:pipeline behavior。
因为:高 PPS 系统:本质就是:
queue
scheduling
buffering
backpressure
之间的平衡。
二十四、工程经验总结
做高性能网络开发:
一定要监控:
ring depth
queue latency
burst accumulation
worker imbalance
P99/P999 latency
不要只看:
drop=0二十五、这次排查真正学到什么
以前我以为:“没有丢包”:就代表系统健康。
后来才意识到:真正危险的是:queue silently growing。
因为:系统可能正在:慢慢进入:高延迟状态。而你却完全看不出来。
二十六、总结
为什么 DPDK 程序没有丢包,但业务却越来越“卡”?
很多时候不是:
- CPU 不够
- NUMA 问题
- NIC 问题
而是:queue backlog。
通过这次问题,我们真正理解了:
核心概念
- queue backlog
- pipeline latency
- backpressure
- tail latency
- queueing theory
- sustained throughput
这也是高性能网络开发真正进入“系统稳定性优化”的开始:
系统最危险的时候,可能并不是:开始丢包。
而是:还没丢包。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)