从“能召回”到“召回准”:RAG 检索优化与幻觉控制实践总结
一、前言:RAG 不只是“向量检索 + 大模型回答”
最近在学习 RAG 的过程中,我一开始对它的理解比较简单:
用户提问 → 问题向量化 → 去向量数据库中查相似文档 → 拼到 Prompt 中 → 交给大模型回答。
这个流程确实是 RAG 的核心,但真正深入以后会发现,一个能用的 RAG 系统和一个效果好的 RAG 系统,中间差距非常大。
尤其是在实际项目中,经常会遇到这些问题:
- 用户问题表达不清楚,导致召回不到正确文档;
- 向量检索语义相似,但结果并不一定准确;
- 关键词很重要,但单纯向量检索可能忽略;
- 召回了很多内容,但真正有用的片段排在后面;
- 大模型拿到错误上下文后,容易一本正经地胡说;
- 没有检索到内容时,大模型仍然可能编造答案。
所以,RAG 的重点不只是“有没有检索”,而是:
如何让系统召回更准、排序更合理、上下文更可信,并最终降低大模型幻觉。
二、RAG 的整体链路回顾
一个完整的 RAG 系统一般可以拆成两条链路:
1. 离线知识入库链路
也就是用户上传文档之后,系统如何把文档处理成可检索的数据。

常见步骤包括:
| 步骤 | 作用 |
|---|---|
| 文件解析 | 把 PDF、Word、Markdown 等文件转成纯文本 |
| 文本清洗 | 去掉无用字符、页眉页脚、乱码等 |
| 文档切割 | 把长文档切成多个 Chunk |
| 向量化 | 使用 Embedding 模型把文本转成向量 |
| 存储 | 存入 Milvus、Elasticsearch、Redis Vector 等检索系统 |
这里需要注意一点:
如果要做混合检索,通常不只是把数据存进向量库,还要把文本内容同步存入支持关键词检索的系统,比如 Elasticsearch。
这也是之前我疑惑的地方:
如果 RAG 使用混合检索,是不是就要同时维护向量索引和关键词索引?
答案是:是的,通常需要。
因为混合检索本质上是两条召回路径:
- 一路走向量语义检索;
- 一路走关键词 / BM25 检索;
- 最后再融合结果。
这确实会增加系统复杂度,但换来的是更高的召回稳定性。
三、RAG 在线问答链路
当用户真正发起问题时,系统进入在线检索和生成阶段。

这个流程里,最关键的优化点主要有五个:
- Query 改写
- 多 Query 扩展
- 混合检索
- RRF 融合
- Rerank 重排序
下面逐个展开。
四、Query 改写:让用户问题更适合检索
用户输入的问题,很多时候并不适合直接拿去检索。
比如用户问:
“这个怎么部署?”
如果没有上下文,系统根本不知道“这个”指的是什么。
再比如:
“它和 ES 有啥区别?”
这里的“它”可能是 Milvus,也可能是 Redis Vector,也可能是某个向量数据库。
所以 Query 改写的目的就是:
把用户自然语言问题,改写成更完整、更适合检索的问题。
例如:
原始问题:
它和 ES 有什么区别?
结合上下文后改写:
Milvus 向量数据库和 Elasticsearch 在 RAG 检索场景中的区别是什么?这样改写后的问题就更适合去召回相关文档。
Query 改写是不是也要用 LLM?
很多时候是的。
这也是我之前比较疑惑的地方:
RAG 最后不是已经要调用大模型回答了吗?为什么前面 Query 改写还要调用一次大模型?
其实这是正常的。
在一个 RAG 系统中,大模型不一定只用一次,它可以在不同阶段承担不同角色:
| 阶段 | 大模型作用 |
|---|---|
| Query 改写 | 把用户问题改成适合检索的形式 |
| 多 Query 扩展 | 从多个角度生成检索问题 |
| 最终回答 | 基于召回上下文生成答案 |
| 幻觉校验 | 判断答案是否有依据 |
所以可以理解为:
LLM 不只是回答器,也可以是检索前的 Query 理解器。
当然,项目中为了降低成本,也可以不用大模型改写,而是使用规则、模板、历史对话拼接等方式完成简单改写。
五、多 Query 扩展:从多个角度提高召回率
多 Query 扩展可以理解为:
不只用用户原始问题检索,而是让系统从多个角度生成多个问题,再分别检索。
例如用户问:
RAG 中如何优化检索效果?系统可以扩展成:
1. RAG 检索优化有哪些常见策略?
2. 如何提高向量检索的召回准确率?
3. RAG 中混合检索如何实现?
4. RAG 中 Rerank 重排序有什么作用?
5. 如何降低 RAG 系统中的大模型幻觉?然后这些 Query 分别去检索,最后合并召回结果。
多 Query 在整个链路中的位置
之前我有一个误区:
我以为多 Query 是向量检索里面的一个小步骤。
但更准确地说:
多 Query 应该处在检索链路的更上层。
也就是:
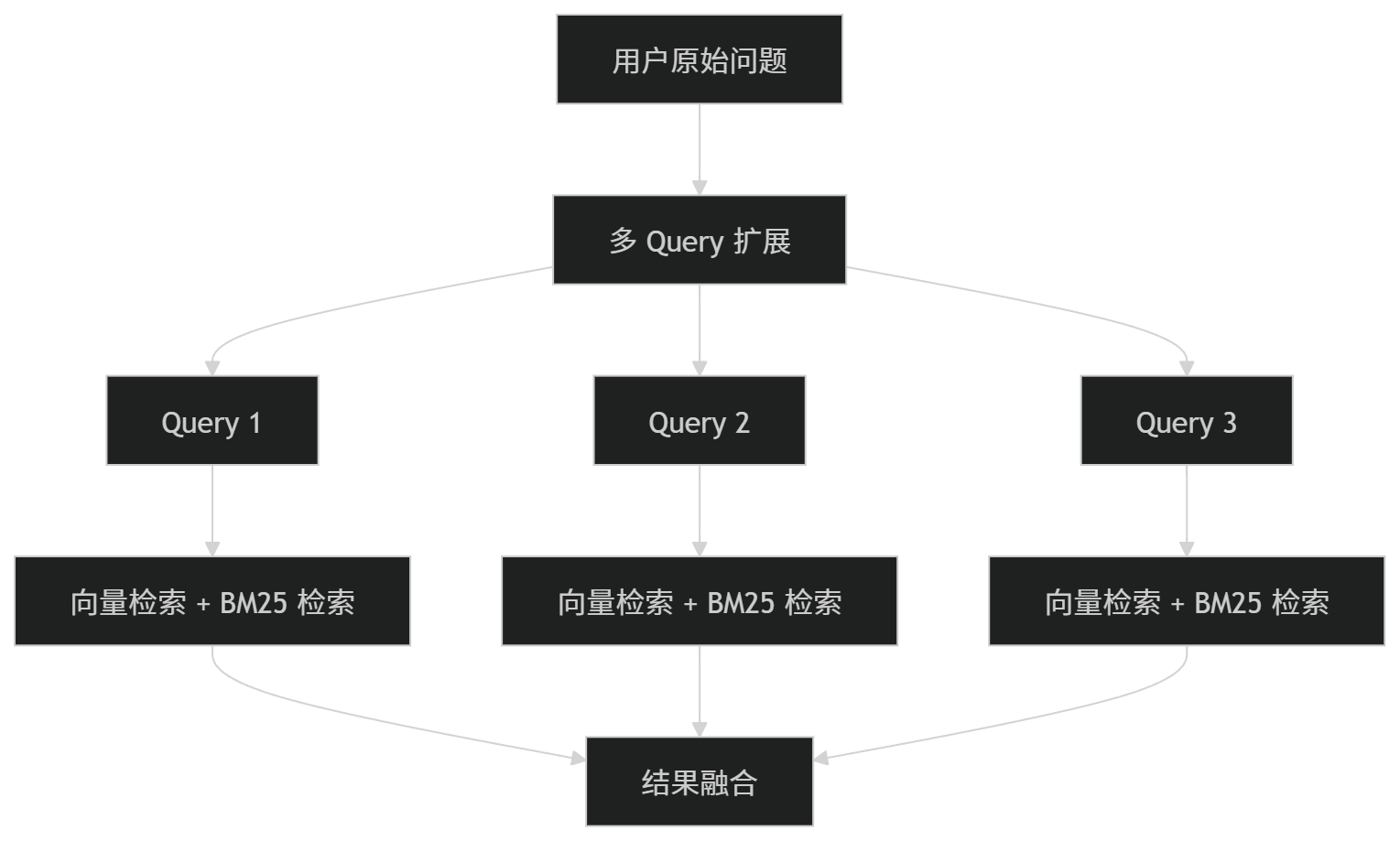
也就是说,多 Query 不是只服务于向量检索,它可以同时服务于:
- 向量检索;
- BM25 关键词检索;
- Elasticsearch 全文检索;
- 混合检索;
- 后续 Rerank。
所以它更像是检索前的 Query 扩展层。
六、向量检索:解决语义相似问题
向量检索的核心是 Embedding。
它会把文本转换成高维向量,比如:
“如何部署 Milvus?”
↓
[0.123, -0.231, 0.456, ...]然后系统会拿用户问题的向量,去和文档 Chunk 的向量做相似度匹配。
它擅长解决的是:
用户表达和文档表达不完全一样,但语义接近的情况。
比如用户问:
怎么把文件内容存进知识库?文档中写的是:
系统会先解析上传文件,然后进行文本切割、向量化,并写入向量数据库。虽然关键词不完全一致,但语义上非常接近,向量检索就能召回。
向量检索的问题
但是向量检索也不是万能的。
它可能存在这些问题:
| 问题 | 说明 |
|---|---|
| 对精确关键词不敏感 | 比如错误码、类名、方法名、配置项 |
| 语义相似不等于答案正确 | 召回内容看起来相关,但不一定能回答问题 |
| 依赖 Embedding 模型质量 | 模型不好,向量效果就差 |
| 长文本容易语义稀释 | Chunk 太大时,向量表达不够精确 |
比如在 Java 项目中,用户问:
defaultTools 报错怎么解决?如果只走向量检索,它可能召回到“工具调用”相关内容,但未必能精准找到 defaultTools 这个具体方法变化。
这时候关键词检索就很重要。
七、BM25:关键词检索的经典算法
BM25 是信息检索领域非常经典的关键词相关性算法,常见于 Elasticsearch、Lucene 等搜索系统中。
它解决的问题是:
用户问题中的关键词,和文档中的关键词匹配程度有多高?
简单来说,BM25 会考虑几个因素:
| 因素 | 含义 |
|---|---|
| 词频 TF | 查询词在文档中出现越多,相关性越高 |
| 逆文档频率 IDF | 越少见的词,区分度越高 |
| 文档长度 | 避免长文档因为词多而天然占优势 |
举个例子:
用户问:
Spring AI defaultTools 报错原因如果某个 Chunk 中明确出现了:
defaultTools 在新版本 Spring AI 中已经被调整,需要使用新的工具注册方式。那么 BM25 很容易把这个 Chunk 排到前面。
因为 Spring AI、defaultTools、报错 这些关键词都高度匹配。
BM25 和向量检索的区别
| 对比项 | 向量检索 | BM25 检索 |
|---|---|---|
| 核心依据 | 语义相似度 | 关键词匹配度 |
| 适合场景 | 概念解释、语义模糊问题 | 类名、方法名、错误码、配置项 |
| 优点 | 能理解相近表达 | 精准、稳定、可解释 |
| 缺点 | 可能语义相似但不准确 | 同义词、改写表达能力弱 |
所以两者不是替代关系,而是互补关系。
八、混合检索:向量检索和 BM25 双路召回
混合检索的核心思想是:
不要只相信一种检索方式,而是让不同检索方式分别召回,再融合结果。
常见结构如下:
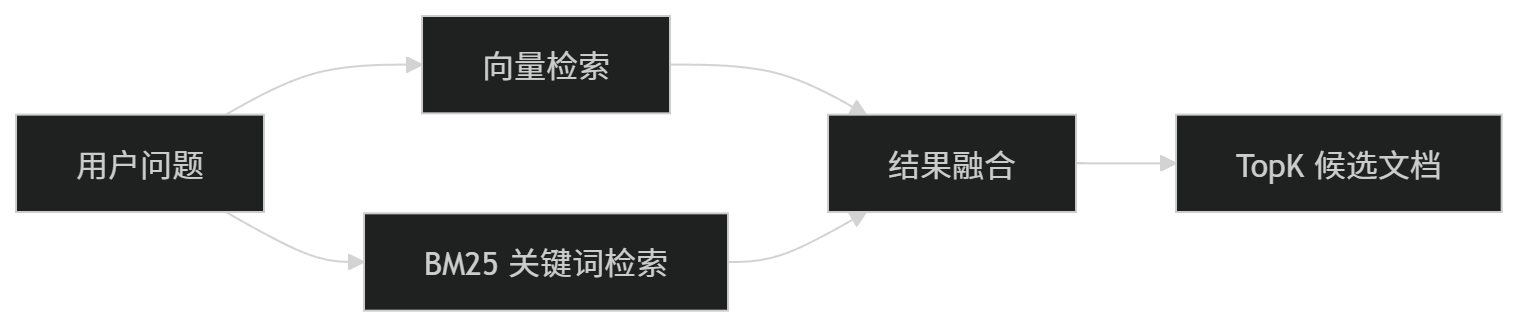
比如:
用户问题:Spring AI defaultTools 报错怎么办?向量检索可能召回:
工具调用、Function Calling、Tool 注册相关内容BM25 可能召回:
包含 defaultTools、Spring AI 版本升级、API 变更的内容最终融合后,系统就能同时兼顾:
- 语义理解能力;
- 关键词精准匹配能力。
混合检索是不是要同时存两份索引?
一般是的。
比如项目中可以这样设计:
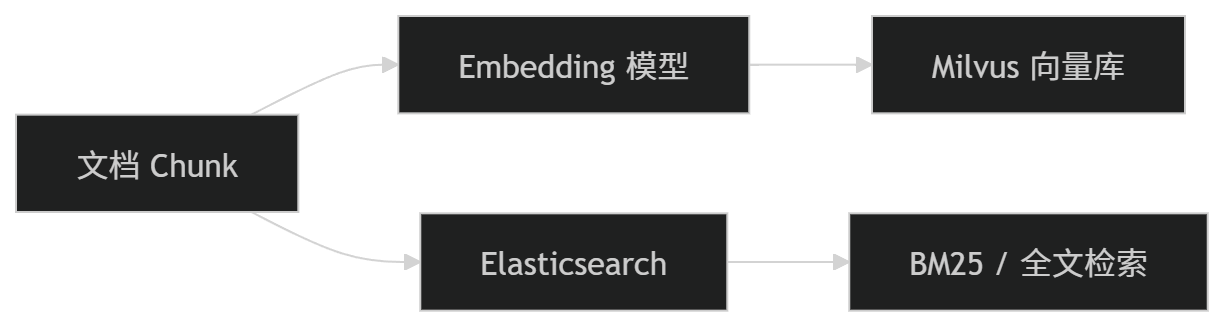
也就是说:
- Milvus 负责向量检索;
- Elasticsearch 负责关键词检索;
- 两边都存 Chunk 的信息;
- 通过 chunkId、documentId 等字段关联。
这确实会麻烦一点,但在真实项目里是很常见的设计。
因为单纯向量检索很难解决所有问题,尤其是技术文档、日志、报错、代码类场景,关键词检索非常重要。
九、RRF 融合:把多路召回结果合并起来
当系统同时走向量检索和 BM25 检索后,会得到两份排序结果。
例如:
向量检索结果:
A, B, C, D
BM25 检索结果:
C, A, E, F那么问题来了:
最终应该怎么排序?
这时候可以用 RRF,也就是 Reciprocal Rank Fusion。
它的思想很简单:
一个文档在多个检索结果中排名都靠前,那么它就更可能重要。
简单理解:
文档 A:
向量检索第 1 名
BM25 检索第 2 名
=> 综合分高
文档 C:
向量检索第 3 名
BM25 检索第 1 名
=> 综合分也高
文档 F:
只在 BM25 中第 4 名出现
=> 综合分相对低RRF 的优势是:
- 不强依赖不同检索方式的原始分数;
- 更关注排名位置;
- 适合融合向量检索、BM25、多 Query 检索结果;
- 实现相对简单。
RRF 简化公式
score(d) = Σ 1 / (k + rank(d))其中:
| 参数 | 含义 |
|---|---|
| d | 某个文档 |
| rank(d) | 文档在某一路检索结果中的排名 |
| k | 平滑参数,通常用于降低排名差距影响 |
不用太纠结公式,核心记住一句话:
多个检索通道都认为重要的文档,最终排名就应该更靠前。
十、Rerank:对候选结果做精排
RRF 融合之后,通常还会得到一批候选文档。
但是这些候选文档不一定都是最适合最终回答的,所以还需要 Rerank。
Rerank 可以理解为:
先粗召回一批文档,再用更强的模型重新判断这些文档和问题的相关性。
流程如下:

Rerank 一定要用大模型吗?
不一定,但一般会使用专门的 Rerank 模型。
常见方式有:
| 方式 | 说明 |
|---|---|
| Cross-Encoder Rerank | 输入 Query + 文档,直接判断相关性 |
| BGE Reranker | 常见中文 / 多语言重排序模型 |
| Cohere Rerank | 云服务 Rerank 接口 |
| LLM Rerank | 让大模型判断哪些片段更相关 |
| 规则重排 | 根据关键词、时间、权限、文档类型加权 |
在项目中比较常见的是:
向量检索 / BM25:负责多召回
Rerank 模型:负责精排序
大模型:负责最终回答所以 Rerank 不一定是最终回答用的那个大模型。
它可以是一个专门的小模型,成本更低、速度更快,也更适合做相关性判断。
十一、如何避免 RAG 中的大模型幻觉?
RAG 的目标之一就是降低幻觉,但 RAG 本身并不能彻底消灭幻觉。
因为如果召回内容错误、缺失或者无关,大模型仍然可能编造答案。
所以幻觉控制应该从多个层面一起做。
1. 提高召回质量
这是最根本的。
如果检索阶段拿到的上下文就不对,后面再怎么 Prompt 约束也很难救回来。
可以使用:
- Query 改写;
- 多 Query 扩展;
- 混合检索;
- RRF 融合;
- Rerank 重排序;
- 合理的 Chunk 切割;
- metadata 权限过滤;
- 文档质量清洗。
一句话:
先让大模型拿到正确材料,再让它回答。
2. Prompt 中明确约束不能编造
可以在系统提示词中加入类似约束:
你必须严格基于提供的上下文回答问题。
如果上下文中没有答案,请明确回答“根据当前知识库资料无法确定”,不要编造。
回答时尽量引用上下文中的关键依据。这类 Prompt 不能百分百解决幻觉,但能明显降低模型自由发挥的概率。
3. 检索不到结果时拒答
如果系统召回结果为空,或者相关性分数过低,不应该继续让大模型强行回答。
可以设计一个阈值:
if retrievedDocs.isEmpty() or topScore < threshold:
return "根据当前知识库资料,暂时无法回答该问题。"这一步非常重要。
很多 RAG 系统幻觉严重,不是因为大模型太差,而是因为:
明明没检索到有效内容,却还让大模型继续回答。
4. 给答案加引用来源
RAG 系统中最好让每段答案都能追溯到来源文档。
例如:
根据《Spring AI 工具调用说明》第 3 节,当前版本推荐通过 ToolCallbackProvider 注册工具。这样有几个好处:
- 用户可以验证答案来源;
- 系统更容易调试;
- 可以减少模型胡说;
- 面试中也更能体现工程完整性。
5. 答案生成后做一致性检查
可以在回答生成后,再做一次校验:
问题:用户原始问题
上下文:召回文档
答案:模型生成答案
请判断答案是否完全来自上下文。
如果存在上下文中没有的信息,请指出。这个阶段可以用 LLM,也可以用规则或事实校验模型。
对于普通项目来说,不一定一开始就做得很复杂,但在简历项目里可以作为亮点:
引入基于上下文一致性的回答校验机制,降低知识库问答中的模型幻觉风险。
十二、一个更完整的 RAG 检索优化方案
综合来看,一个比较完整的 RAG 检索链路可以这样设计:
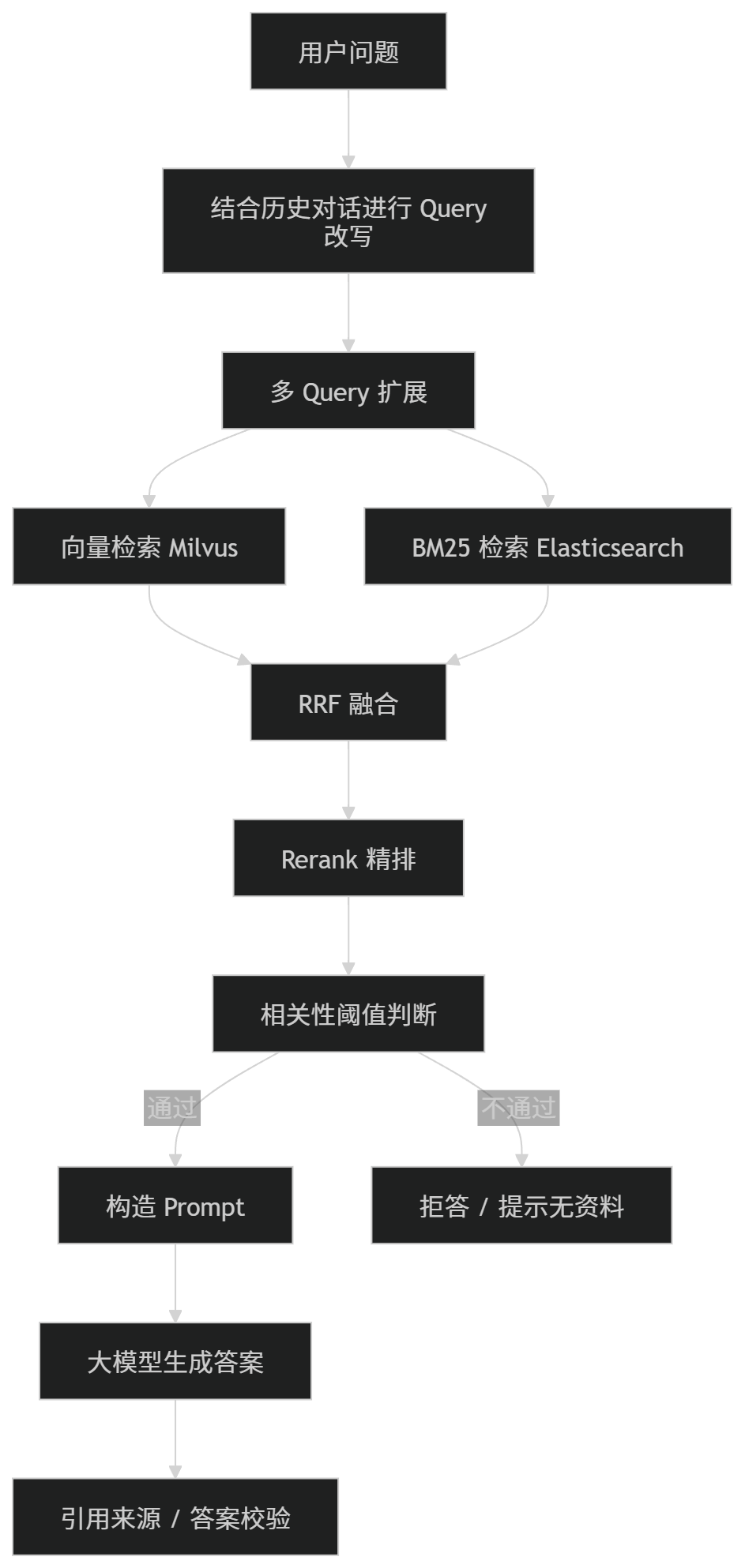
这个链路相比最基础的 RAG,多了很多工程优化点:
| 模块 | 作用 |
|---|---|
| Query 改写 | 解决用户问题不完整 |
| 多 Query | 提高召回覆盖率 |
| 向量检索 | 解决语义匹配 |
| BM25 | 解决关键词精准匹配 |
| RRF | 融合多路召回结果 |
| Rerank | 提高最终上下文质量 |
| 阈值判断 | 避免无依据回答 |
| 引用来源 | 增强答案可信度 |
| 一致性校验 | 降低幻觉风险 |
十三、结合 Java / Spring AI 项目的理解
如果放到 Java 项目中,可以把 RAG 检索链路理解成几个核心服务:
QueryRewriteService // 问题改写
MultiQueryService // 多 Query 扩展
VectorSearchService // 向量检索
KeywordSearchService // BM25 / ES 检索
FusionService // RRF 融合
RerankService // 重排序
PromptBuildService // 构造 Prompt
ChatService // 调用大模型生成回答伪代码可以这样理解:
public String chat(String userQuestion) {
// 1. Query 改写
String rewrittenQuery = queryRewriteService.rewrite(userQuestion);
// 2. 多 Query 扩展
List<String> queries = multiQueryService.expand(rewrittenQuery);
// 3. 多路召回
List<DocumentChunk> vectorResults = vectorSearchService.search(queries);
List<DocumentChunk> keywordResults = keywordSearchService.search(queries);
// 4. RRF 融合
List<DocumentChunk> fusedResults = fusionService.rrf(vectorResults, keywordResults);
// 5. Rerank 精排
List<DocumentChunk> rerankedResults = rerankService.rerank(userQuestion, fusedResults);
// 6. 判断是否有有效上下文
if (rerankedResults.isEmpty()) {
return "根据当前知识库资料,暂时无法回答该问题。";
}
// 7. 构造 Prompt
String prompt = promptBuildService.build(userQuestion, rerankedResults);
// 8. 调用大模型回答
return chatClient.prompt()
.user(prompt)
.call()
.content();
}当然,真实项目中还要考虑:
- 用户权限过滤;
- 文档所属知识库;
- 组织标签;
- TopK 控制;
- 分数阈值;
- 历史对话;
- Token 长度限制;
- 日志记录;
- 异常兜底。
这些都是把 RAG 从 Demo 变成项目的关键点。
十四、面试中可以怎么表达?
如果面试官问:
你们的 RAG 是怎么优化检索效果的?
可以这样回答:
我们不是单纯使用向量检索,而是设计了一套多阶段检索链路。
首先,在用户提问后,会结合历史对话对 Query 做改写,解决指代不明和问题不完整的问题。然后通过多 Query 扩展,从多个角度生成检索问题,提高召回覆盖率。
在召回阶段,我们同时使用向量检索和 Elasticsearch 的 BM25 关键词检索。向量检索负责语义相似召回,BM25 负责方法名、错误码、配置项等精确关键词匹配。两路结果召回后,通过 RRF 进行融合,再使用 Rerank 模型对候选片段进行精排,最终选出 TopK 文档片段构造 Prompt。
同时,我们在 Prompt 中约束大模型必须基于上下文回答,并在检索结果为空或相关性低时进行拒答,避免模型在没有依据的情况下编造答案。这段回答比只说“我们用了向量数据库做 RAG”要强很多。
因为它体现了:
- 你理解 RAG 的完整链路;
- 你知道向量检索的缺点;
- 你知道混合检索的价值;
- 你知道 Rerank 的作用;
- 你考虑过幻觉控制;
- 你有工程落地思维。
十五、总结
今天这部分学习让我对 RAG 的理解更进一步。
最开始我以为 RAG 的核心只是:
把文档向量化,然后根据用户问题召回相似内容。
但现在看,真正的 RAG 优化重点在于:
让检索结果更准,让上下文更可信,让大模型少胡说。
可以简单总结为一句话:
基础 RAG 解决的是“能不能检索到”,高级 RAG 解决的是“检索得准不准、排序合不合理、答案有没有依据”。
一个可靠的 RAG 系统,通常需要组合使用:
- Query 改写;
- 多 Query 扩展;
- 向量检索;
- BM25 关键词检索;
- 混合检索;
- RRF 结果融合;
- Rerank 重排序;
- Prompt 约束;
- 阈值拒答;
- 来源引用;
- 答案校验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)