day32_注意力机制与Transformer入门
一、注意力机制
1.什么是注意力机制
举个栗子
当你看到一张包含"锦江饭店"的照片时,短时间内大脑可能只对"锦江饭店"这个地方有印象,而忽略了电话号码、行人、"喜运来大酒家"等信息。这就是人类视觉的注意力机制——我们不是从头到尾观察一遍事物后才有判断,而是把注意力放在最具有辨识度的地方,从而快速做出判断。
📝 注意力机制(Attention Mechanism) 就是把这种人类感知方式,应用到深度神经网络中:让机器学会感知数据中重要的部分和不重要的部分,在提取特征时把精力放在最关键的地方。
2.为什么需要注意力机制
先从RNN模型的角度来看它的缺陷:
| RNN的问题 | 说明 |
|---|---|
| 串行效率低 | 一个时间步一个时间步提取特征,无法并行 |
| 长序列遗忘 | 前面单词的特征会随着序列增长而被稀释,没有重点 |
而带有注意力机制的模型:
| 注意力机制的优势 | 说明 |
|---|---|
| 并行提取特征 | 可以同时处理所有时间步,效率高 |
| 关注关键点 | 能注意到最重要的信息,不眉毛胡子一把抓 |
所以,带有注意力机制的模型,提取特征更灵活、更高效。
3.注意力机制的QKV
注意力机制的核心是 Q、K、V 三个张量,用档案柜找文件的场景来理解:
| 概念 | 比喻 | 说明 |
|---|---|---|
| Query(查询)Q | 正在研究的课题(便利贴) | 表示输入序列要查询的问题 |
| Key(键)K | 文件夹上贴的标签(key#1, key#2) | 表示关注内容的索引/关键字 |
| Value(值)V | 文件柜里的文档资料 | 表示实际要关注的内容 |
4.注意力机制的实现步骤
第1步:Q和K进行相似度运算
得到注意力权重分布(一个系数数组),例如:
[0.001, 0.3, 0.5, 0.002, 0.001, 0.00003, ...][0.001,\ 0.3,\ 0.5,\ 0.002,\ 0.001,\ 0.00003,\ ...][0.001, 0.3, 0.5, 0.002, 0.001, 0.00003, ...]
这个权重分布表示"当前词对序列中每个词的关注程度"。
第2步:权重分布与V加权求和
attentionq=∑iweighti⋅Vi\text{attention}_q = \sum_i \text{weight}_i \cdot V_iattentionq=i∑weighti⋅Vi
例如:0.001×⟨s⟩+0.3×a+0.5×robot+...=attention_q0.001 \times \langle s \rangle + 0.3 \times a + 0.5 \times robot + ... = attention\_q0.001×⟨s⟩+0.3×a+0.5×robot+...=attention_q
📝 本质上:通过QKV运算,把普通的Q升级成一个更强大的Q——这个新的Q包含了上下文中最值得关注的信息。
⚠️ 一开始权重分布可能不准确,但不要紧。注意力机制只是前向计算路径中的一个小策略,最终靠损失函数和反向传播来更新权重参数,让模型学会从数据中快速获取关键特征。
二、Seq2Seq架构
1.Seq2Seq基本概念
Seq2Seq(Sequence-to-Sequence) 最早于2014-2015年被提出,也叫编码器-解码器(Encoder-Decoder)模型。核心是使用RNN、GRU或LSTM作为基础组件,用于处理输入和输出都是长度可变的序列任务。
比如将英文 “How are you” 映射为法文 “Comment allez-vous”,输入输出长度不同,传统模型无法直接处理,Seq2Seq正是为这类场景设计的。
2.Seq2Seq的组成
Seq2Seq由两个主要部分组成:
编码器(Encoder)
- 接收输入序列(单词 tokens x1,x2,...,xTx_1, x_2, ..., x_Tx1,x2,...,xT)
- 逐个处理每个时间步,生成一个上下文向量(Context Vector),也叫中间语义张量C
- 这个向量试图包含整个输入序列的语义信息
解码器(Decoder)
- 以编码器的输出作为初始隐藏状态
- 逐个生成输出序列,每个时刻的输出会作为下一时刻的输入(自回归生成)
- 通常会包含注意力机制,以便在生成过程中动态关注输入序列的不同部分
3.Seq2Seq中的注意力机制
在解码器中加入注意力机制时,QKV分别是什么?
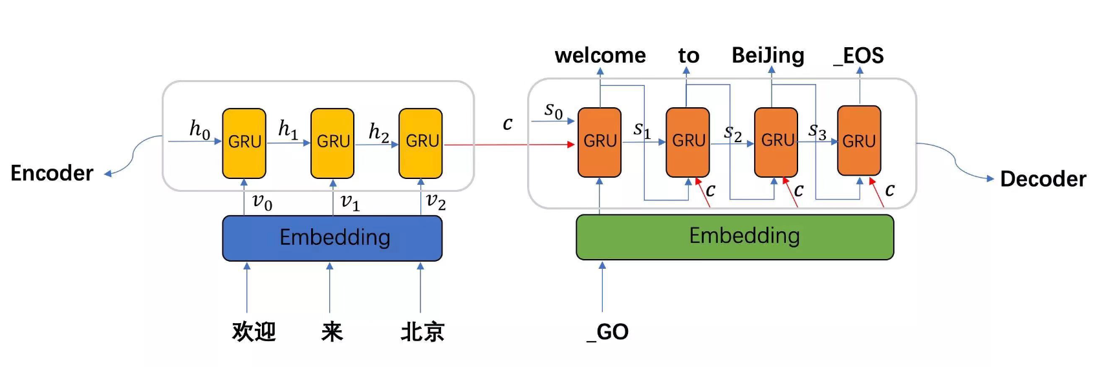
| 字母 | 含义 | 说明 |
|---|---|---|
| Q | 经过词嵌入后的张量 | Q查询谁就是谁的查询张量 |
| K | 上一个时间步的隐藏层输出 | 作为注意力比的键向量 |
| V | 中间语义张量C | 编码器生成的上下文向量 |
📝 每个时间步都要进行QKV运算,把Q升级成更强大的Q,后续解码流程和以前一样继续进行。
注意力机制只是一小段计算路径,最终还是要靠损失函数 + 反向传播三大件配合,才能真正学会特征。
三、Transformer
1.Transformer诞生背景
📝 Transformer于2017年被Google团队提出,论文题目震耳欲聋:《Attention is All You Need》。
这篇论文开创了一种全新的模型架构——用纯注意力机制取代了RNN,同时继承了Seq2Seq的编码器-解码器架构、自回归生成方式和训练推理策略,一举解决了RNN的长距离依赖和并行计算两大痛点。
Transformer的出现引发了NLP领域的革命,成为机器翻译、文本摘要、对话生成等任务的基础。随后基于Transformer的变种模型相继涌现:
| 模型 | 时间 | 意义 |
|---|---|---|
| BERT | 2018年10月 | Google发布,横扫NLP领域11项SOTA! |
| GPT系列 | 后续 | OpenAI基于Transformer的生成式突破 |
| XLNET、RoBERTa | 后续 | 击败BERT,但核心仍是Transformer |
📝 SOTA = State Of The Art,指在该研究任务中目前最好最先进的模型,简单理解就是"当前最佳/世界纪录级别"。
2.Tranformer相比RNN/LSTM的 又是
| 对比项 | LSTM/GRU | Transformer |
|---|---|---|
| 并行训练 | ❌ 串行,一个时间步一个时间步处理 | ✅ 可以利用分布式GPU并行训练 |
| 长文本处理 | ❌ 间隔较长的语义关联效果差,易梯度消失/爆炸 | ✅ 捕捉长距离语义关联效果更好 |
| 市场占有 | 逐渐被取代 | 几乎所有排名靠前的模型都在用 |
3.Transformer总体架构
Transformer共分为4个部分:
输入部分 → 编码器部分 → 解码器部分 → 输出部分
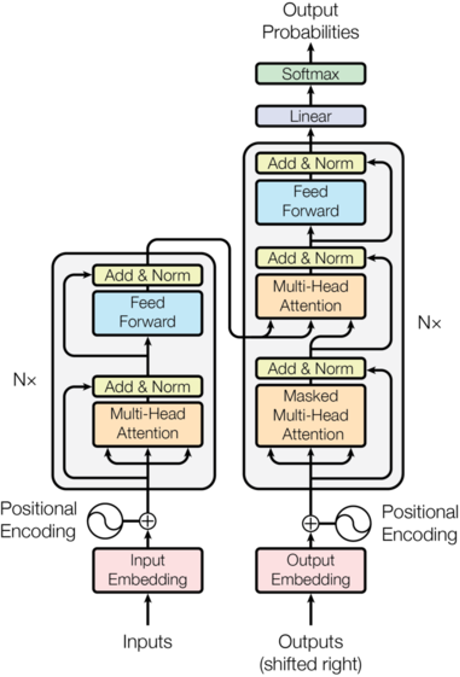
输入部分
- 源文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
输出部分
- 线性层
- Softmax层
编码器部分
- 由 N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成:
| 子层 | 包含 |
|---|---|
| 第一个 | 多头自注意力子层 + 规范化层 + 残差连接 |
| 第二个 | 前馈全连接子层 + 规范化层 + 残差连接 |
解码器部分
- 由 N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成:
| 子层 | 包含 |
|---|---|
| 第一个 | 多头自注意力子层 + 规范化层 + 残差连接 |
| 第二个 | 多头注意力子层 + 规范化层 + 残差连接 |
| 第三个 | 前馈全连接子层 + 规范化层 + 残差连接 |
4.编码器和解码器的连接方式
编码器层与层如何连接?
编码器每层都会生成K(键向量)和V(值向量),传递给解码器使用。
解码器层与层如何连接?
解码器采用自回归方式,每层的输出作为下一层的输入,同时利用编码器传来的K、V进行注意力计算。
📝 NLP核心任务划分:自然语言理解(NLU)和自然语言生成(NLG)
四、总结
| 知识点 | 一句话总结 |
|---|---|
| 注意力机制 | 让模型学会把注意力放在数据中最具辨识度的地方 |
| QKV | Q=查询、K=键索引、V=内容,通过QK相似度 + VW加权求和得到强化Q |
| RNN缺陷 | 串行效率低 + 长序列遗忘问题 |
| 注意力优势 | 并行提取特征 + 关注关键信息 |
| Seq2Seq | 编码器处理输入生成中间语义C,解码器自回归生成输出 |
| Seq2Seq+注意力 | Q=词嵌入后张量、K=上一隐藏层输出、V=中间语义C |
| Transformer | 2017年Google提出,用纯注意力机制取代RNN,解决并行和长距离依赖问题 |
| Transformer架构 | 4部分:输入(嵌入+位置编码)→ 编码器(N层双子层)→ 解码器(N层三子层)→ 输出(线性+softmax) |
📝 核心公式:
attention(Q,K,V)=softmax(QKTdk)Vattention(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) Vattention(Q,K,V)=softmax(dkQKT)V
这就是Transformer中大名鼎鼎的 Scaled Dot-Product Attention,也是Attention is All You Need的真谛。
注意力机制是现代NLP的基石——它不仅让Seq2Seq模型如虎添翼,更催生了Transformer这个革命性架构,最终衍生出BERT、GPT等改变世界的大模型。理解注意力机制,就理解了当代NLP的半壁江山。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)