《从 0 实现 SGLang》第 5 篇 · 实现 KV Cache
千行代码,一步步搭出一个现代 LLM 推理引擎,掌握大模型推理的每一项关键技术。
1. 介绍
上一篇引出无 KV cache 的代价: 每步从头跑整段 forward, 前面位置的 K/V 在下一步又被重算一遍, 带来大量重复计算。
本篇来实现一个最小的 KV cache (连续张量, 不分页、不复用前缀), 改造前文的 Qwen3 attention 让它能读写 cache, 然后用 Qwen3-0.6B 跑通, 并分析 KV cache 对 token 生成速度的影响
2. 总览
KV cache 是一块 4 维张量, K 和 V 各占一份。每一层一张二维网格, 网格的每一行 (slot) 装一个 token 在这一层的 KV (8 个 head 各一个 128 维向量)。
Qwen3-0.6B 上的具体取值:
| 维度 | 含义 | 取值 |
|---|---|---|
num_layers |
decoder 层数 | 28 |
max_seq_len |
预留最大长度 (教学用) | 256 |
num_kv_heads |
GQA 的 KV 头数 | 8 |
head_dim |
每头维度 | 128 |
dtype |
半精度 | bfloat16 |
单请求消耗显存 = 2 (K+V) × 28 × 256 × 8 × 128 × 2 byte ≈ 29 MB — 小得可以塞进任何一张消费级显卡。
3. 实现 KVCache
KVCache 是一个 class
实例变量:
self.k: 所有层所有 token 的 Kself.v: 所有层所有 token 的 Vself.length: 当前已写入的 token 数 (0 = 空, prefill 后置为 L, decode 每步 +1)
方法:
store(): 写 KVget(layer_id, end_pos): 读 KVreset(): 重置 (张量本身不清空, 下一轮覆盖写)
import torch
class KVCache:
"""连续张量版 KV cache. 不分页、不复用前缀. 单条请求专用.
"""
def __init__(self, num_layers: int, max_seq_len: int, num_kv_heads: int,
head_dim: int, dtype: torch.dtype, device: torch.device):
shape = (num_layers, max_seq_len, num_kv_heads, head_dim)
self.k = torch.zeros(shape, dtype=dtype, device=device)
self.v = torch.zeros(shape, dtype=dtype, device=device)
self.length = 0 # 当前已写入的 token 数, 0 表示空
def store(self, layer_id: int, start_pos: int, k_new: torch.Tensor, v_new: torch.Tensor) -> None:
"""把新位置的 K/V 写进 slot[start_pos : start_pos + n_new].
Args:
k_new / v_new: (n_new, num_kv_heads, head_dim)
"""
n_new = k_new.shape[0]
end = start_pos + n_new
self.k[layer_id, start_pos:end] = k_new
self.v[layer_id, start_pos:end] = v_new
def get(self, layer_id: int, end_pos: int) -> tuple[torch.Tensor, torch.Tensor]:
"""读出 slot[0 : end_pos] 的完整 K/V (前缀 + 当前)."""
return self.k[layer_id, :end_pos], self.v[layer_id, :end_pos]
def reset(self) -> None:
"""清空 cache (length 归零). 张量本身不重置, 下一轮会覆盖写入."""
self.length = 0
shape 设计哲学
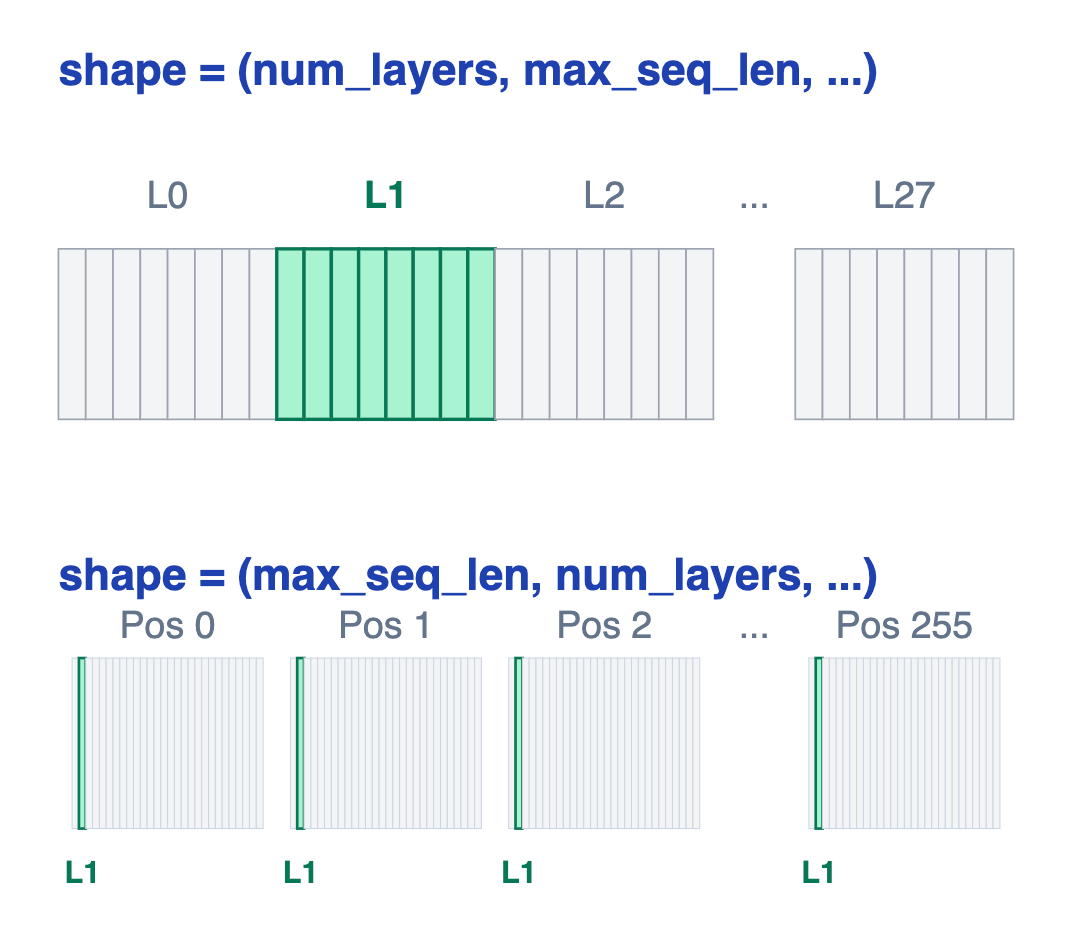
(num_layers, max_seq_len, num_kv_heads, head_dim) 中维度顺序, 蕴含了对内存访问模式的极致优化。
为什么 num_layers 在 max_seq_len 前
PyTorch 张量虽然是多维,但底层数据还是按照数组排布。
把底层数据想象成一条笔直的长街, 上面排着一栋栋房子。tensor 的 shape 只是告诉你"每多少栋算一个小区"——内存本身是平铺的, 没有真正的多维。访问快慢, 就看你要的房子是挨在一起、还是散在街上各处。
- 情况一:
t.shape = (28, 256, ...)
内存被切成 28 个大块, 每块里挨着塞了 256 × ... 个元素:
[块0..............][块1..............][块2..............]...[块27.............]
t[2] = “给我第 2 个大块”。指针跳到块 2 起点, 一口气读到块 2 末尾——一段连续内存, 一次性搬完。
CPU 缓存预取器 (prefetcher) 最爱这种读取模式, 因为它能猜到你下一步还要后面的数据, 提前塞进 cache。这就是所谓零拷贝, 一次定位。
- 情况二:
t.shape = (256, 28, ...)
现在内存被切成 256 个小行, 每行只有 28 × ... 个元素:
[行0:28个][行1:28个][行2:28个]...[行255:28个]
t[:, 2] = “每一行的第 2 个给我”。这些元素散在 256 个不同位置, 每隔 28 个才有一个你要的。CPU 必须:
跳到行 0 偏移 2 读一个 → 跳到行 1 偏移 2 读一个 → …… 一共跳 256 次。
每次跳都可能 cache miss, 预取器也猜不准你下一步去哪。慢, 且浪费内存带宽。
KVCache 只有两种访问模式:
- 写入: attention 算完新 token K/V → 写进某层某个 slot →
cache.k[layer_id, start_pos:end_pos] - 读出: attention 要读取某条序列完整的K/V →
cache.k[layer_id, :end_pos]
两种都"先按 layer 切, 再按 seq 切"。把 num_layers 放最外、max_seq_len 放第二, 让两种操作都可访问连续内存, 零拷贝。如果把 max_seq_len 放最外, 单层 slice 就变成跨步取 256 个不连续片段, CPU/GPU 都得多次小读取。
为什么 max_seq_len 在 num_kv_heads 前
Attention 计算需要的 layout 是 (num_heads, seq, head_dim)。这里存的是 (seq, num_heads, head_dim), 需要一次 transpose(0, 1)。那为什么不直接存 SDPA 要的样子?
因为 decode 时每步只写 1 个 token。如果 num_heads 维在 seq 前, 新 token 不是在最末尾追加, 而是要在每个 head 中间各插一行 (内存不连续)。把 seq 维放前面, append 一个 token = 在最外层加一行, 最自然。读出后 SDPA 前 transpose 一次, 是廉价的 view 变换 (不拷贝数据), 不影响性能。

为什么没有 num_heads (Q 头数) 维
cache 只存 K 和 V, 不存 Q。Q 是每一步现算的 (新位置才有 Q, 前缀的 Q 用完即丢)。所以维度跟 num_kv_heads (8), 不跟 num_heads (16)。这正是 GQA 的本质收益 — cache 大小由 KV head 数决定, 把它从 16 减到 8, cache 直接砍半。GQA 设计的目的就是为了省 KV cache, 不是为了少算 attention。
4. 改造 attention
attention 内部多了两步 (store + get) 与 cache 交互: QKV → SDPA → o_proj 变成 QKV → store → get → SDPA → o_proj。
新增 forward 参数:
kv_cache: KVCache 实例layer_id: 本层下标 (0…27)start_pos: 写入 cache 的起始位置 (prefill=0, decode=cache.length)
4 步流程:
- 算: QKV 投影只对
n_new个新位置算 (prefill 时 L 个, decode 时 1 个) - 存: 新 K/V 写 cache
slot[start_pos : end_pos] - 取: 从 cache 读
slot[0 : end_pos]→ K_full, V_full (前缀 + 当前) - 算 attention: SDPA(Q, K_full, V_full)
import torch.nn.functional as F
from topic3_qwen3_architecture.qwen3 import (
Qwen3Attention,
Qwen3DecoderLayer,
Qwen3Model,
Qwen3ForCausalLM,
apply_rope,
)
def _attn_fwd_cache(
self, x, cos, sin, kv_cache, layer_id, start_pos,
):
"""attention.forward 加上 cache 读写.
多 3 参数, 内部多 2 步 (store / get).
"""
# x: (n_new, 1024)
# prefill 时 n_new = L; decode 时 n_new = 1
n_new = x.shape[0]
end_pos = start_pos + n_new
# ─── 老步骤: QKV + QK-Norm + RoPE ───
# 只对 n_new 个新位置算
# q: (n_new, 16, 128)
# kv: (n_new, 8, 128)
nq, nkv, d = self.n_q, self.n_kv, self.d
q = self.q_proj(x).view(n_new, nq, d)
k_new = self.k_proj(x).view(n_new, nkv, d)
v_new = self.v_proj(x).view(n_new, nkv, d)
q = self.q_norm(q)
k_new = self.k_norm(k_new)
q = apply_rope(q, cos, sin)
k_new = apply_rope(k_new, cos, sin)
# ─── ★ 新增: 写 cache + 读完整 K/V ───
# k_full / v_full: (end_pos, 8, 128)
kv_cache.store(layer_id, start_pos, k_new, v_new)
k_full, v_full = kv_cache.get(layer_id, end_pos)
# ─── 老步骤: GQA + SDPA + o_proj ───
# GQA: KV head 复制到 Q head 数
# k_full / v_full: (end_pos, 16, 128)
rep = self.repeat
k_full = k_full.repeat_interleave(rep, dim=1)
v_full = v_full.repeat_interleave(rep, dim=1)
# SDPA 要 head 在前
# q: (16, n_new, 128)
# k_full: (16, end_pos, 128)
q = q.transpose(0, 1)
k_full = k_full.transpose(0, 1)
v_full = v_full.transpose(0, 1)
# causal mask 两种状态:
# - prefill (n_new > 1): 多 Q 互相也要遵守因果序,
# 位置 i 不能看 j > i 的 K. 必须开.
# - decode (n_new = 1): 单 Q 看完所有 K,
# 无"未来"可遮; 短 Q × 长 K 本身只用前 end_pos 列.
is_causal = (n_new > 1)
# attn: (16, n_new, 128)
attn = F.scaled_dot_product_attention(
q, k_full, v_full, is_causal=is_causal,
)
# merge heads + o_proj
# → (n_new, 2048) → (n_new, 1024)
attn = attn.transpose(0, 1)
attn = attn.reshape(n_new, nq * d)
return self.o_proj(attn)
def _layer_fwd_cache(
self, x, cos, sin, kv_cache, layer_id, start_pos,
):
"""x: (n_new, 1024) → (n_new, 1024).
cache / layer_id / start_pos 透传给 self_attn.
"""
h = self.input_layernorm(x)
x = x + self.self_attn(
h, cos, sin, kv_cache, layer_id, start_pos,
)
h = self.post_attention_layernorm(x)
x = x + self.mlp(h)
return x
def _model_fwd_cache(
self, input_ids, cos, sin, kv_cache, start_pos,
):
"""input_ids: (n_new,) → (n_new, 1024).
遍历 layers 时给每层 layer_id.
"""
x = self.embed_tokens(input_ids)
for layer_id, layer in enumerate(self.layers):
x = layer(
x, cos, sin, kv_cache, layer_id, start_pos,
)
return self.norm(x)
def _lm_fwd_cache(
self, input_ids, cos, sin, kv_cache, start_pos,
):
"""input_ids: (n_new,) → logits (n_new, 151936)."""
h = self.model(
input_ids, cos, sin, kv_cache, start_pos,
)
return self.lm_head(h)
# 把 4 个新 forward 装回原类.
# 最小侵入的 wrapper:类结构 / 字段 / 权重命名都没动.
Qwen3Attention.forward = _attn_fwd_cache
Qwen3DecoderLayer.forward = _layer_fwd_cache
Qwen3Model.forward = _model_fwd_cache
Qwen3ForCausalLM.forward = _lm_fwd_cache
小结:
- 4 个 forward 方法都加 3 个参数 (
kv_cache/layer_id/start_pos) 一路透传, 一直到 Attention 才用上 - 真正用到 cache 的只有 Attention 内部 — store + get 两行新代码
is_causal = (n_new > 1)一行自动适应 prefill / decode 两态
5. 改造 prefill 和 decode
prefill 与 decode 共用同一个 forward + 同一份 cache, 只在 3 处取值不同。
prefill (跑 1 次, 一次性吞 prompt):
input_ids: 完整 prompt (L 个 token)start_pos = 0,n_new = L- 取
logits[-1].argmax()→ 第一个 next token - 完毕后
cache.length = L
decode (循环, 每次只生成 1 个 token):
input_ids: 上一步的 1 个 next tokenstart_pos = cache.length,n_new = 1- 取
logits[0].argmax()→ 下一个 next token - 每步
cache.length += 1, 直到 EOS 或max_tokens
# 加载权重
from topic3_qwen3_architecture.qwen3 import (
Qwen3Config,
pick_device_dtype,
load_weights,
precompute_rope_cache,
)
MODEL_DIR = "Qwen/Qwen3-0.6B"
device, dtype = pick_device_dtype()
cfg = Qwen3Config()
model = Qwen3ForCausalLM(cfg)
n_tensors = load_weights(model, MODEL_DIR)
model = model.to(device, dtype).eval()
print(f"loaded {n_tensors} tensors")
print(f"device={device} dtype={dtype}")
2026-05-26 17:56:47,802 - modelscope - INFO - Target directory already exists, skipping creation.
Downloading Model from https://www.modelscope.cn to directory: /DATA/disk5/cache/modelscope/models/Qwen/Qwen3-0.6B
loaded 311 tensors
device=cuda dtype=torch.bfloat16
from modelscope import snapshot_download
from transformers import AutoTokenizer
# 已缓存时直接返回本地路径, 不会重下
local_path = snapshot_download(MODEL_DIR)
tokenizer = AutoTokenizer.from_pretrained(local_path)
# 预先算 cos/sin 表
cos_full, sin_full = precompute_rope_cache(
cfg.head_dim,
cfg.max_position_embeddings,
cfg.rope_theta,
device, dtype,
)
def generate(prompt, max_new_tokens=100, cache_max_len=256):
"""完整的 prefill + decode 流程, 全程用 KV cache."""
# 1) tokenize + chat template
msgs = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
msgs,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False,
)
ids = tokenizer(text, return_tensors="pt").input_ids
input_ids = ids[0].to(device)
L = len(input_ids)
# 2) 新建 cache
cache = KVCache(
num_layers=cfg.num_layers,
max_seq_len=cache_max_len,
num_kv_heads=cfg.num_kv_heads,
head_dim=cfg.head_dim,
dtype=dtype,
device=torch.device(device),
)
# 3) prefill: 一次写 L 个 slot
with torch.no_grad():
logits = model(
input_ids,
cos_full[:L], sin_full[:L],
cache, start_pos=0,
)
cache.length = L
next_id = logits[-1].argmax().item()
output_ids = [next_id]
# 4) decode 循环: 每步只传 1 个 token
eos = tokenizer.eos_token_id
for _ in range(max_new_tokens - 1):
if next_id == eos:
break
x = torch.tensor([next_id], device=device)
pos = cache.length
with torch.no_grad():
logits = model(
x,
cos_full[pos:pos+1],
sin_full[pos:pos+1],
cache, start_pos=pos,
)
cache.length += 1
next_id = logits[0].argmax().item()
output_ids.append(next_id)
return output_ids, input_ids.tolist()
# 试跑一次
_out, _prompt = generate(
"你是哪一个模型", max_new_tokens=100,
)
print(f"prompt: {len(_prompt)} tokens")
print(f"output: {len(_out)} tokens")
print(f"答: {tokenizer.decode(_out, skip_special_tokens=True)}")
Downloading Model from https://www.modelscope.cn to directory: /DATA/disk5/cache/modelscope/models/Qwen/Qwen3-0.6B
2026-05-26 17:56:49,340 - modelscope - INFO - Target directory already exists, skipping creation.
prompt: 15 tokens
output: 37 tokens
答: 我是基于多模态大模型设计的多模态语言模型,我能够理解多种语言并生成自然的文本。如果您有任何问题或需要帮助,请随时告诉我!
全流程视频演示。
prefill-decode-kvcache
6. 性能对比
# 速度对比 — 同一 prompt, 跑 N=30 步, 记录每步耗时
import time
import matplotlib.pyplot as plt
def time_each_step(use_cache: bool, prompt: str = "你是哪一个具体的模型", n_steps: int = 30):
"""返回 [每步耗时 (ms)] 长度 n_steps 的列表."""
msgs = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(msgs, tokenize=False, add_generation_prompt=True, enable_thinking=False)
input_ids = tokenizer(text, return_tensors="pt").input_ids[0].to(device)
cache = KVCache(num_layers=cfg.num_layers, max_seq_len=256,
num_kv_heads=cfg.num_kv_heads, head_dim=cfg.head_dim,
dtype=dtype, device=torch.device(device))
L = len(input_ids)
# prefill 不计入 (两种模式 prefill 一样)
with torch.no_grad():
logits = model(input_ids, cos_full[:L], sin_full[:L], cache, start_pos=0)
cache.length = L
next_id = logits[-1].argmax().item()
generated = [next_id]
timings = []
for step in range(n_steps):
if torch.cuda.is_available(): torch.cuda.synchronize()
t0 = time.perf_counter()
if use_cache:
x = torch.tensor([next_id], device=device)
pos = cache.length
with torch.no_grad():
logits = model(x, cos_full[pos:pos+1], sin_full[pos:pos+1], cache, start_pos=pos)
cache.length += 1
next_id = logits[0].argmax().item()
else:
full = torch.cat([input_ids, torch.tensor(generated, device=device)])
cache.reset()
Lf = len(full)
with torch.no_grad():
logits = model(full, cos_full[:Lf], sin_full[:Lf], cache, start_pos=0)
next_id = logits[-1].argmax().item()
if torch.cuda.is_available(): torch.cuda.synchronize()
timings.append((time.perf_counter() - t0) * 1000)
generated.append(next_id)
return timings
# warmup (尤其 CUDA 第一次 launch 慢)
_ = time_each_step(use_cache=True, n_steps=3)
_ = time_each_step(use_cache=False, n_steps=3)
t_cached = time_each_step(use_cache=True, n_steps=30)
t_nocache = time_each_step(use_cache=False, n_steps=30)
# 画图
fig, ax = plt.subplots(figsize=(7, 3.5))
ax.plot(range(1, 31), t_nocache, "o-", color="#d9534f", label="no cache")
ax.plot(range(1, 31), t_cached, "o-", color="#4caf50", label="KV cache")
ax.set_xlabel("decode step")
ax.set_ylabel("time cost (ms)")
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 汇总
total_cached = sum(t_cached)
total_nocache = sum(t_nocache)
print(f"无 cache 30 步累计: {total_nocache:7.1f} ms")
print(f"有 cache 30 步累计: {total_cached:7.1f} ms")
print(f"加速比: {total_nocache / total_cached:5.2f}x")
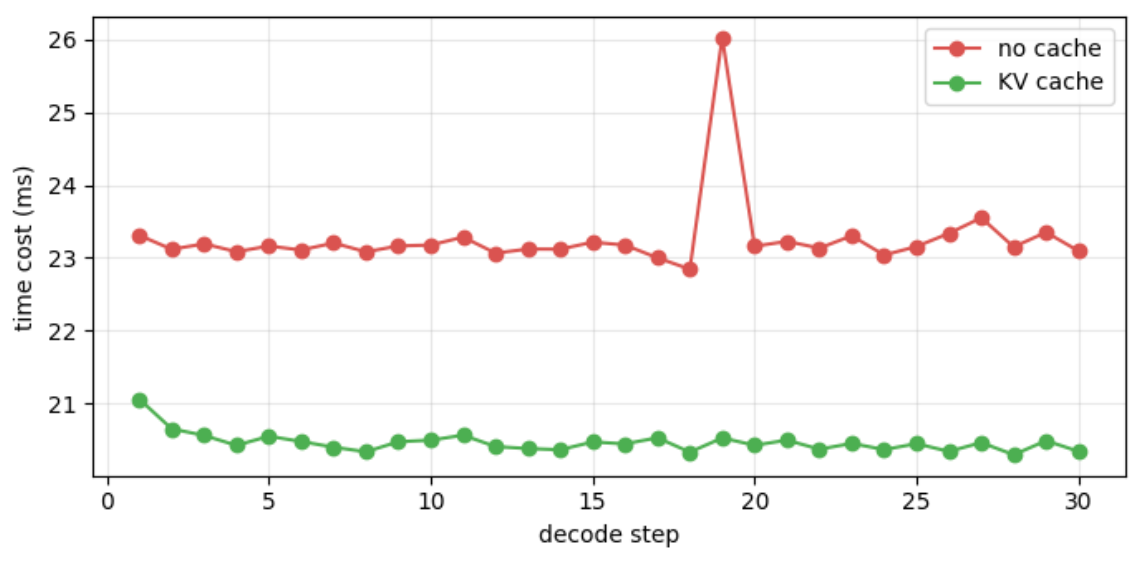
无 cache 30 步累计: 697.9 ms
有 cache 30 步累计: 613.8 ms
加速比: 1.14x
KV cache 加速效果和上下文长度成正比,这里上下文较短,加速比不明显。
7. 小结
本篇做了三件事:
- 实现 KVCache — 两块连续张量存储 K/V,shape 设计优化 K/V 读写效率
- 改造 attention — forward 多 3 个参数, 内部多 2 步 (store + get), 让 K/V 来源从"重新算"换成"从 cache 拿";
- 改造 prefill 和 decode — prefill 一次写 L 个, decode 每步只写 1 个, 把每步 forward 经过的 token 数从
L+k降到1, 累计 O(N²) → O(N)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)