TSBS 实测:KaiwuDB vs InfluxDB,时序数据库性能差多少?
在工业物联网、智能运维监控等时序业务场景中,时序数据库的写入吞吐能力、查询响应效率以及高负载下的系统稳定性,直接决定了业务系统的可靠性与可扩展性。本次测试基于行业通用的时序数据库基准测试工具——TSBS (Time Series Benchmark Suite),在完全一致的硬件、操作系统与容器环境下,对 KaiwuDB V3.1.0 与 InfluxDB V1.6.4 两款产品进行了全场景性能对比,用真实测试数据给时序库选型做直观参考。
测试工具仓库来源>>https://gitee.com/kwdb/kwdb-tsbs
本文为个人技术分享,测试结果仅针对本次测试环境与版本,不同部署模式、不同版本的性能表现可能存在差异。
一、测试环境说明
为了保证测试的公平性与可复现性,本次测试全程采用 Docker 容器化部署,两个数据库的运行环境完全一致,排除了环境差异对测试结果的干扰:
|
配置项 |
详情 |
|
操作系统 |
Ubuntu 22.04.5 LTS(内核5.15.0-138-generic) |
|
系统架构 |
x86_64 |
|
资源限制 |
单节点 16 核 CPU、32GB 内存 |
|
存储 |
单容器绑定 1.8TiB Intel NVMe 硬盘 |
|
测试工具 |
TSBS 时序基准测试套件(适配版) |
|
测试版本 |
KaiwuDB 3.1.0、InfluxDB v1.6.4 |
二、先上结论
1. 写入性能:KaiwuDB 全场景领先,中小规模吞吐达 7 倍优势
2. 查询性能:分场景呈现出差异化表现,InfluxDB 的简单查询有小幅优势;KaiwuDB 在大规模、超大规模时序业务场景性能衰减更小,复杂查询时延可控
3. 稳定性:KaiwuDB 高负载鲁棒性显著领先,InfluxDB 面对大规模/超大规模数据场景频繁宕机,无法支撑大规模的时序业务
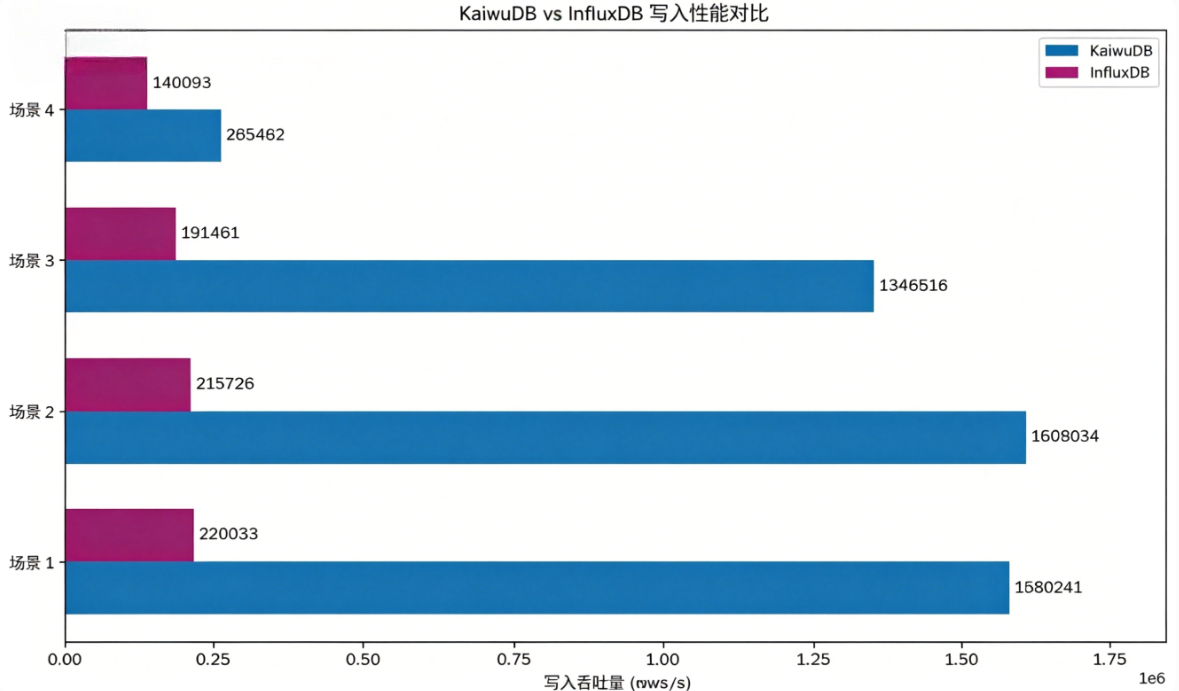
三、写入性能对比(rows/s,数值越高越好)
写入吞吐是时序库核心能力,4 组场景实测数据如下:
|
结果参数 |
KaiwuDB |
InfluxDB |
|
|
场景1 |
insert(rows/s) |
1580241.06 |
220032.98 |
|
insert(metics/s) |
15802410.60 |
2200329.76 |
|
|
场景2 |
insert(rows/s) |
1608033.76 |
215726.02 |
|
insert(metics/s) |
16080337.60 |
2157260.17 |
|
|
场景3 |
insert(rows/s) |
1346516.28 |
191460.82 |
|
insert(metics/s) |
13465162.80 |
1914608.22 |
|
|
场景4 |
insert(rows/s) |
265462.34 |
140092.62 |
|
insert(metics/s) |
2654623.40 |
1400926.22 |
从结果能明显看出,四个场景 KaiwuDB 全部大幅领先,场景 1、2 吞吐接近 7 倍差距,场景 4 也有近 2 倍优势,InfluxDB 的写入上限明显低很多。
四、查询性能对比(ms,数值越低越好)
测试覆盖极小规模(100 设备)、中规模(4000 设备)、大规模(10 万 / 100 万设备),分 Worker1(低并发)、 Worker8(高并发),包含简单分组、复杂聚合、高负载查询等 15 类核心场景。
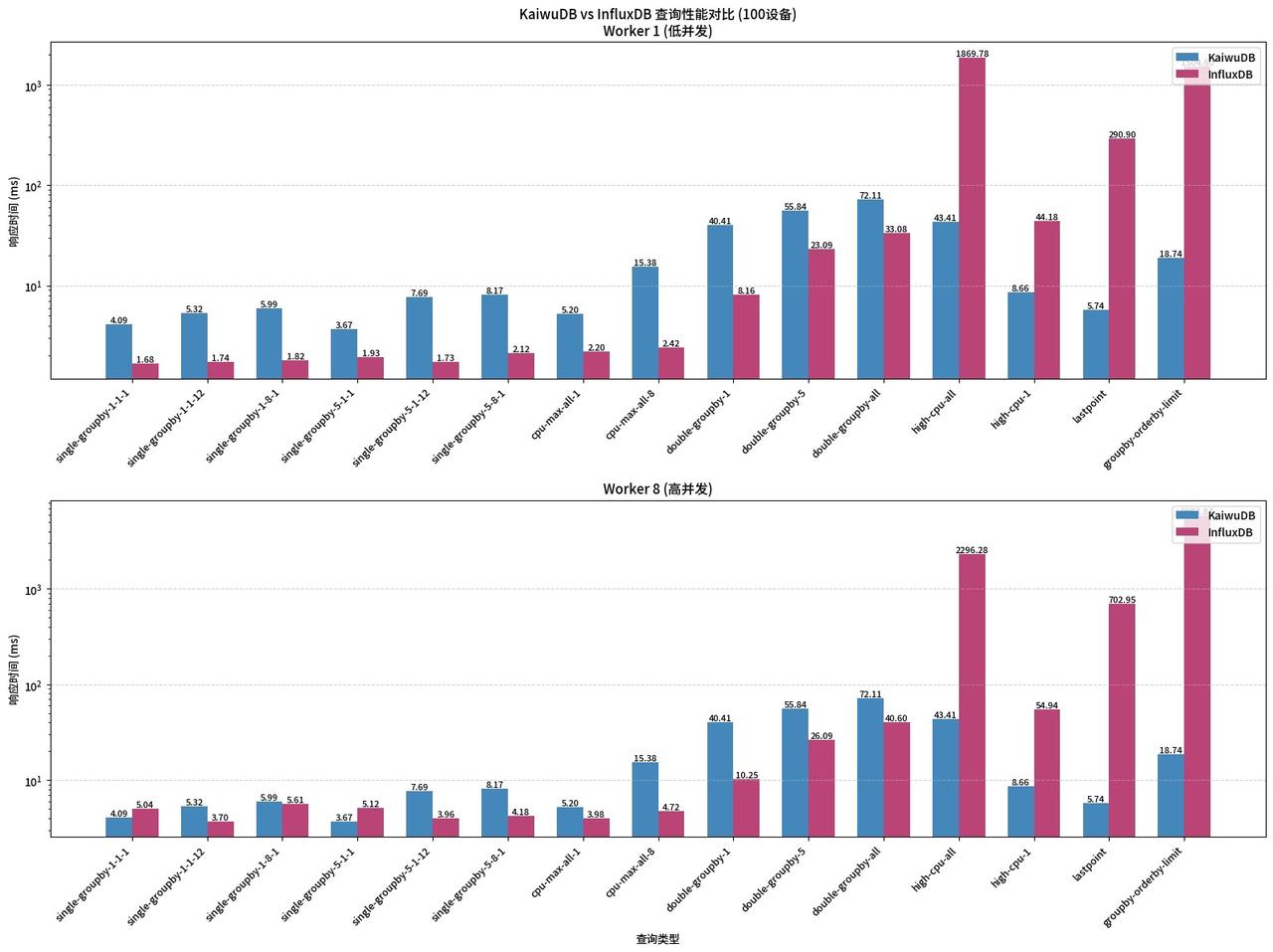
4.1 场景一:极小数据规模(100 设备)
-
对于
single-groupby、cpu-max这类简单的聚合查询,InfluxDB 的响应时间略快于 KaiwuDB,存在 1-3ms 的小幅优势; -
但对于
high-cpu-all、lastpoint、groupby-orderby-limit这类复杂的高负载查询,InfluxDB 的响应时间出现了剧烈的飙升,达到了千毫秒级,而 KaiwuDB 的响应时间始终稳定在几十毫秒以内,差距悬殊。
worker1
|
query type |
scale |
query count |
kaiwudb(ms) |
influxdb (ms) |
|
single-groupby-1-1-1 |
100 |
10 |
4.09 |
1.68 |
|
single-groupby-1-1-12 |
100 |
10 |
5.32 |
1.74 |
|
single-groupby-1-8-1 |
100 |
10 |
5.99 |
1.82 |
|
single-groupby-5-1-1 |
100 |
10 |
3.67 |
1.93 |
|
single-groupby-5-1-12 |
100 |
10 |
7.69 |
1.73 |
|
single-groupby-5-8-1 |
100 |
10 |
8.17 |
2.12 |
|
cpu-max-all-1 |
100 |
10 |
5.2 |
2.20 |
|
cpu-max-all-8 |
100 |
10 |
15.38 |
2.42 |
|
double-groupby-1 |
100 |
10 |
40.41 |
8.16 |
|
double-groupby-5 |
100 |
10 |
55.84 |
23.09 |
|
double-groupby-all |
100 |
10 |
72.11 |
33.08 |
|
high-cpu-all |
100 |
10 |
43.41 |
1869.78 |
|
high-cpu-1 |
100 |
10 |
8.66 |
44.18 |
|
lastpoint |
100 |
10 |
5.74 |
290.90 |
|
groupby-orderby-limit |
100 |
10 |
18.74 |
1504.60 |
worker8
当查询并发提升到 8Worker 后,InfluxDB 的简单查询优势已经消失,复杂查询的时延进一步恶化,groupby-orderby-limit查询耗时超 5 秒,KaiwuDB 稳定控制在 20ms 内。
|
query type |
scale |
query count |
kaiwudb(ms) |
influxdb (ms) |
|
single-groupby-1-1-1 |
100 |
10 |
4.09 |
5.04 |
|
single-groupby-1-1-12 |
100 |
10 |
5.32 |
3.70 |
|
single-groupby-1-8-1 |
100 |
10 |
5.99 |
5.61 |
|
single-groupby-5-1-1 |
100 |
10 |
3.67 |
5.12 |
|
single-groupby-5-1-12 |
100 |
10 |
7.69 |
3.96 |
|
single-groupby-5-8-1 |
100 |
10 |
8.17 |
4.18 |
|
cpu-max-all-1 |
100 |
10 |
5.2 |
3.98 |
|
cpu-max-all-8 |
100 |
10 |
15.38 |
4.72 |
|
double-groupby-1 |
100 |
10 |
40.41 |
10.25 |
|
double-groupby-5 |
100 |
10 |
55.84 |
26.09 |
|
double-groupby-all |
100 |
10 |
72.11 |
40.60 |
|
high-cpu-all |
100 |
10 |
43.41 |
2296.28 |
|
high-cpu-1 |
100 |
10 |
8.66 |
54.94 |
|
lastpoint |
100 |
10 |
5.74 |
702.95 |
|
groupby-orderby-limit |
100 |
10 |
18.74 |
5853.84 |
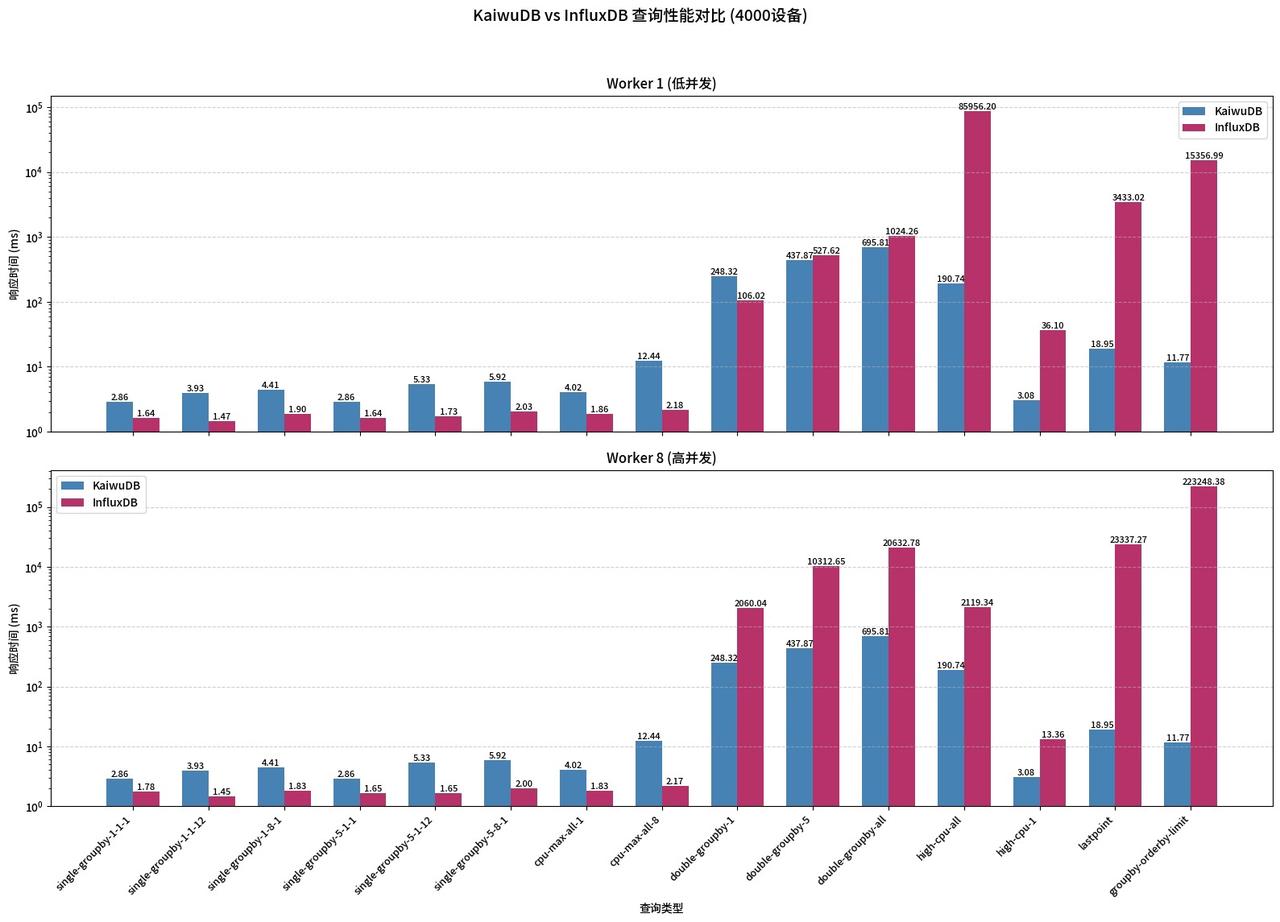
4.2 场景二:中数据规模(4000 设备)
当数据规模扩大到 4000 设备后,InfluxDB 的性能衰减已经非常明显:
-
简单查询的小幅优势依然存在,但已经非常微弱;
-
复杂查询的时延出现了断崖式的下跌,
double-groupby-all查询的时延超过了 20 秒,high-cpu-all查询的时延竟然达到了 85 秒,而 KaiwuDB 的这些查询时延依然稳定在百毫秒级; -
在高并发场景下,InfluxDB 的
groupby-orderby-limit查询时延甚至超过了 220 秒,完全无法满足业务的查询需求,而 KaiwuDB 的性能没有出现任何波动。
worker1
|
query type |
scale |
query count |
kaiwudb(ms) |
influxdb (ms) |
|
single-groupby-1-1-1 |
4000 |
10 |
2.86 |
1.64 |
|
single-groupby-1-1-12 |
4000 |
10 |
3.93 |
1.47 |
|
single-groupby-1-8-1 |
4000 |
10 |
4.41 |
1.90 |
|
single-groupby-5-1-1 |
4000 |
10 |
2.86 |
1.64 |
|
single-groupby-5-1-12 |
4000 |
10 |
5.33 |
1.73 |
|
single-groupby-5-8-1 |
4000 |
10 |
5.92 |
2.03 |
|
cpu-max-all-1 |
4000 |
10 |
4.02 |
1.86 |
|
cpu-max-all-8 |
4000 |
10 |
12.44 |
2.18 |
|
double-groupby-1 |
4000 |
10 |
248.32 |
106.02 |
|
double-groupby-5 |
4000 |
10 |
437.87 |
527.62 |
|
double-groupby-all |
4000 |
10 |
695.81 |
1024.26 |
|
high-cpu-all |
4000 |
10 |
190.74 |
85956.20 |
|
high-cpu-1 |
4000 |
10 |
3.08 |
36.10 |
|
lastpoint |
4000 |
10 |
18.95 |
3433.02 |
|
groupby-orderby-limit |
4000 |
10 |
11.77 |
15356.99 |
worker8
|
query type |
scale |
query count |
kaiwudb(ms) |
influxdb (ms) |
|
single-groupby-1-1-1 |
4000 |
10 |
2.86 |
1.78 |
|
single-groupby-1-1-12 |
4000 |
10 |
3.93 |
1.45 |
|
single-groupby-1-8-1 |
4000 |
10 |
4.41 |
1.83 |
|
single-groupby-5-1-1 |
4000 |
10 |
2.86 |
1.65 |
|
single-groupby-5-1-12 |
4000 |
10 |
5.33 |
1.65 |
|
single-groupby-5-8-1 |
4000 |
10 |
5.92 |
2.00 |
|
cpu-max-all-1 |
4000 |
10 |
4.02 |
1.83 |
|
cpu-max-all-8 |
4000 |
10 |
12.44 |
2.17 |
|
double-groupby-1 |
4000 |
10 |
248.32 |
2060.04 |
|
double-groupby-5 |
4000 |
10 |
437.87 |
10312.65 |
|
double-groupby-all |
4000 |
10 |
695.81 |
20632.78 |
|
high-cpu-all |
4000 |
10 |
190.74 |
2119.34 |
|
high-cpu-1 |
4000 |
10 |
3.08 |
13.36 |
|
lastpoint |
4000 |
10 |
18.95 |
23337.27 |
|
groupby-orderby-limit |
4000 |
10 |
11.77 |
223248.38 |
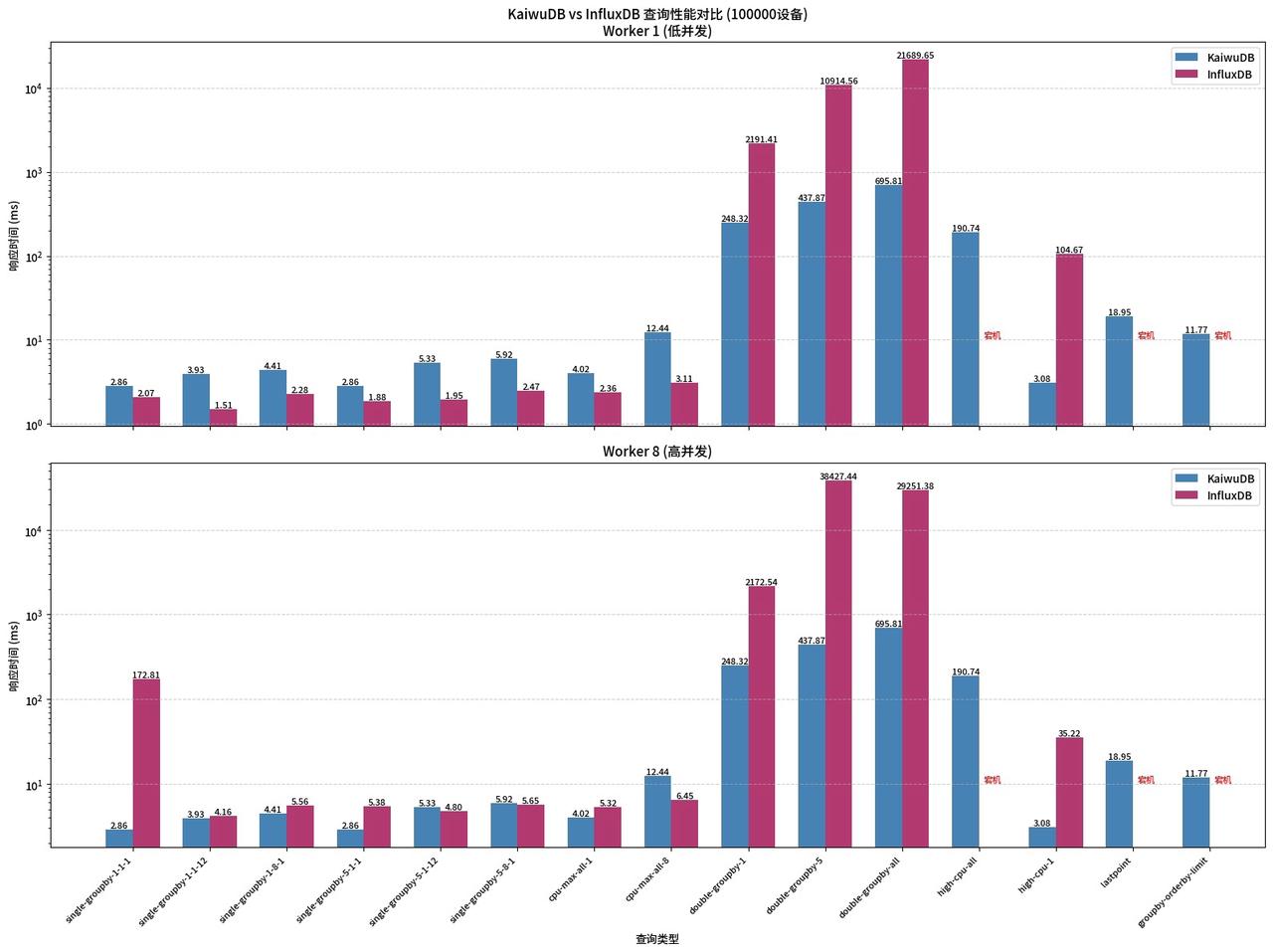
4.3 场景三:大规模数据(10 万设备)
从这个场景开始,InfluxDB 已经无法支撑高负载的查询压力了。在核心高负载查询中直接出现了宕机,无法完成查询任务。KaiwuDB 全部正常执行,无失败、无中断。
简单查询 InfluxDB 仍有微弱优势,但 double-groupby-5、double-groupby-all 延迟高达 1 万 - 2 万 ms,KaiwuDB 仅 400-700ms,差距达到数十倍。
最关键的 high-cpu-all、lastpoint、groupby-orderby-limit 查询,InfluxDB 全盘崩溃,所有高负载查询直接宕机。KaiwuDB 的所有查询都稳定完成,没有任何失败。
worker1
|
query type |
scale |
query count |
kaiwudb(ms) |
influxdb (ms) |
|
single-groupby-1-1-1 |
100000 |
10 |
2.86 |
2.07 |
|
single-groupby-1-1-12 |
100000 |
10 |
3.93 |
1.51 |
|
single-groupby-1-8-1 |
100000 |
10 |
4.41 |
2.28 |
|
single-groupby-5-1-1 |
100000 |
10 |
2.86 |
1.88 |
|
single-groupby-5-1-12 |
100000 |
10 |
5.33 |
1.95 |
|
single-groupby-5-8-1 |
100000 |
10 |
5.92 |
2.47 |
|
cpu-max-all-1 |
100000 |
10 |
4.02 |
2.36 |
|
cpu-max-all-8 |
100000 |
10 |
12.44 |
3.11 |
|
double-groupby-1 |
100000 |
10 |
248.32 |
2191.41 |
|
double-groupby-5 |
100000 |
10 |
437.87 |
10914.56 |
|
double-groupby-all |
100000 |
10 |
695.81 |
21689.65 |
|
high-cpu-all |
100000 |
10 |
190.74 |
宕机 |
|
high-cpu-1 |
100000 |
10 |
3.08 |
104.67 |
|
lastpoint |
100000 |
10 |
18.95 |
宕机 |
|
groupby-orderby-limit |
100000 |
10 |
11.77 |
宕机 |
worker8
|
query type |
scale |
query count |
kaiwudb(ms) |
influxdb (ms) |
|
single-groupby-1-1-1 |
100000 |
10 |
2.86 |
172.81 |
|
single-groupby-1-1-12 |
100000 |
10 |
3.93 |
4.16 |
|
single-groupby-1-8-1 |
100000 |
10 |
4.41 |
5.56 |
|
single-groupby-5-1-1 |
100000 |
10 |
2.86 |
5.38 |
|
single-groupby-5-1-12 |
100000 |
10 |
5.33 |
4.80 |
|
single-groupby-5-8-1 |
100000 |
10 |
5.92 |
5.65 |
|
cpu-max-all-1 |
100000 |
10 |
4.02 |
5.32 |
|
cpu-max-all-8 |
100000 |
10 |
12.44 |
6.45 |
|
double-groupby-1 |
100000 |
10 |
248.32 |
2172.54 |
|
double-groupby-5 |
100000 |
10 |
437.87 |
38427.44 |
|
double-groupby-all |
100000 |
10 |
695.81 |
29251.38 |
|
high-cpu-all |
100000 |
10 |
190.74 |
宕机 |
|
high-cpu-1 |
100000 |
10 |
3.08 |
35.22 |
|
lastpoint |
100000 |
10 |
18.95 |
宕机 |
|
groupby-orderby-limit |
100000 |
10 |
11.77 |
宕机 |
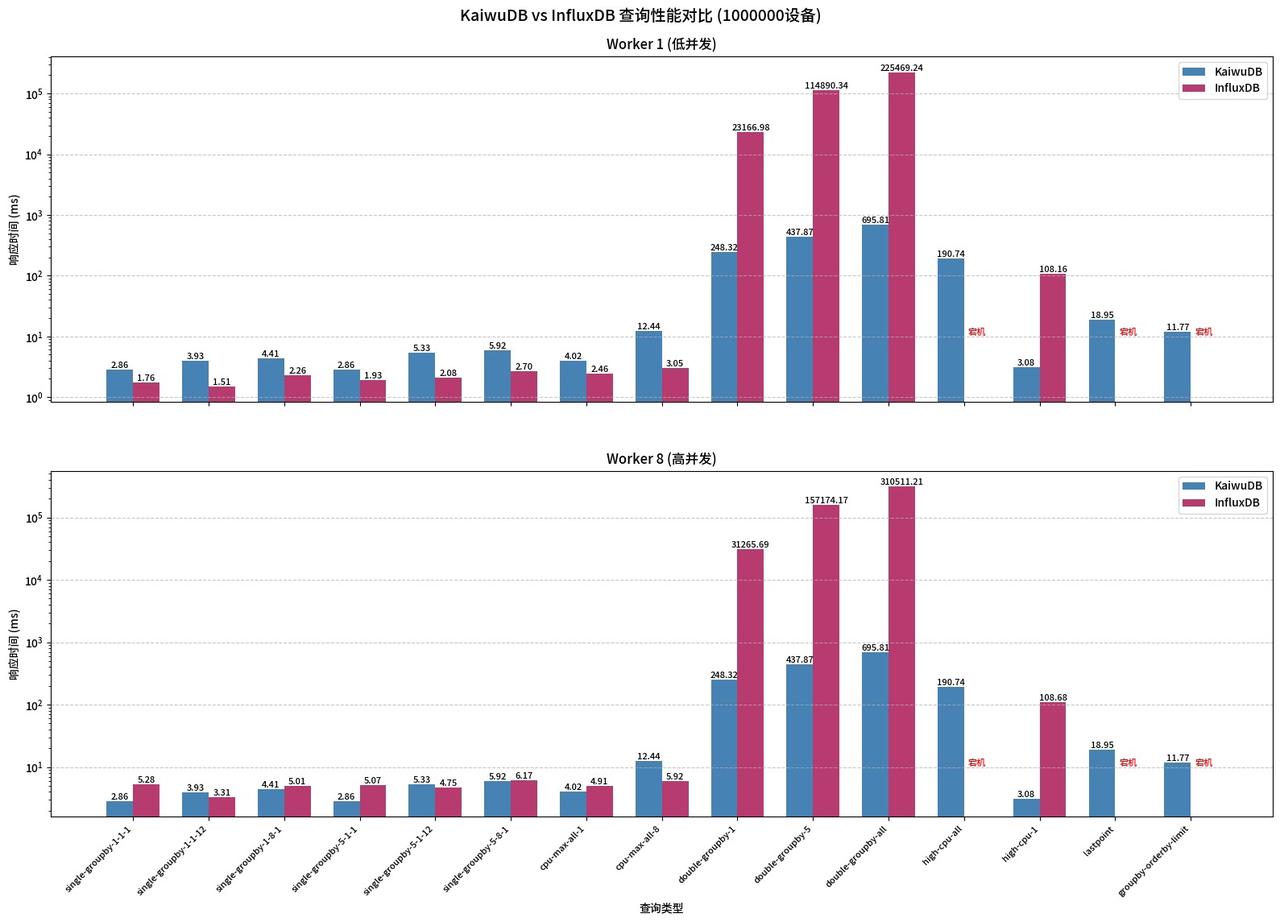
4.4 场景四:超大规模数据(100 万设备)
在百万设备的超大规模场景下,InfluxDB 已经彻底无法支撑高负载查询了:所有的高负载查询全部宕机,double-groupby 系列查询的时延最高达到了 31 万毫秒(也就是超过 5 分钟),完全无法满足业务的实时查询需求。
而 KaiwuDB 在这个场景下,依然保持了稳定的性能,所有查询都正常完成,复杂查询的时延依然控制在百毫秒级,没有出现任何性能衰减或者服务异常。
worker1
简单查询 InfluxDB 勉强略快,但 double-groupby 延迟飙升至 2 万 - 22 万 ms,KaiwuDB 仅 250-700ms。high-cpu-all、lastpoint、groupby-orderby-limit InfluxDB 宕机,KaiwuDB 稳定执行。
|
query type |
scale |
query count |
kaiwudb(ms) |
influxdb (ms) |
|
single-groupby-1-1-1 |
1000000 |
10 |
2.86 |
1.76 |
|
single-groupby-1-1-12 |
1000000 |
10 |
3.93 |
1.51 |
|
single-groupby-1-8-1 |
1000000 |
10 |
4.41 |
2.26 |
|
single-groupby-5-1-1 |
1000000 |
10 |
2.86 |
1.93 |
|
single-groupby-5-1-12 |
1000000 |
10 |
5.33 |
2.08 |
|
single-groupby-5-8-1 |
1000000 |
10 |
5.92 |
2.70 |
|
cpu-max-all-1 |
1000000 |
10 |
4.02 |
2.46 |
|
cpu-max-all-8 |
1000000 |
10 |
12.44 |
3.05 |
|
double-groupby-1 |
1000000 |
10 |
248.32 |
23166.98 |
|
double-groupby-5 |
1000000 |
10 |
437.87 |
114890.34 |
|
double-groupby-all |
1000000 |
10 |
695.81 |
225469.24 |
|
high-cpu-all |
1000000 |
10 |
190.74 |
宕机 |
|
high-cpu-1 |
1000000 |
10 |
3.08 |
108.16 |
|
lastpoint |
1000000 |
10 |
18.95 |
宕机 |
|
groupby-orderby-limit |
1000000 |
10 |
11.77 |
宕机 |
worker8
|
query type |
scale |
query count |
kaiwudb(ms) |
influxdb (ms) |
|
single-groupby-1-1-1 |
1000000 |
10 |
2.86 |
5.28 |
|
single-groupby-1-1-12 |
1000000 |
10 |
3.93 |
3.31 |
|
single-groupby-1-8-1 |
1000000 |
10 |
4.41 |
5.01 |
|
single-groupby-5-1-1 |
1000000 |
10 |
2.86 |
5.07 |
|
single-groupby-5-1-12 |
1000000 |
10 |
5.33 |
4.75 |
|
single-groupby-5-8-1 |
1000000 |
10 |
5.92 |
6.17 |
|
cpu-max-all-1 |
1000000 |
10 |
4.02 |
4.91 |
|
cpu-max-all-8 |
1000000 |
10 |
12.44 |
5.92 |
|
double-groupby-1 |
1000000 |
10 |
248.32 |
31265.69 |
|
double-groupby-5 |
1000000 |
10 |
437.87 |
157174.17 |
|
double-groupby-all |
1000000 |
10 |
695.81 |
310511.21 |
|
high-cpu-all |
1000000 |
10 |
190.74 |
宕机 |
|
high-cpu-1 |
1000000 |
10 |
3.08 |
108.68 |
|
lastpoint |
1000000 |
10 |
18.95 |
宕机 |
|
groupby-orderby-limit |
1000000 |
10 |
11.77 |
宕机 |
五、实测总结
综合全场景的测试结果,我们可以对两个数据库的表现做一个客观的总结:
-
写入能力:KaiwuDB 具备显著优势 KaiwuDB 的写入引擎在全场景下都展现出了更强的硬件利用效率,中小规模场景下的吞吐能力达到了 InfluxDB 的 7 倍,能够支撑工业物联网、车联网这类海量写入的业务场景,写入上限远高于 InfluxDB。
-
小数据场景:InfluxDB 的简单查询有小幅优势 在极小数据规模、低并发的简单查询场景下,InfluxDB 的响应速度略快,适合轻量的小数据业务场景,比如个人开发者的小型监控项目、非核心的轻量数据统计。
-
中大规模场景:KaiwuDB 的稳定性与性能全面领先 当数据规模超过 4000 设备后,InfluxDB 的性能出现了断崖式的下跌,复杂查询的时延飙升,甚至出现服务宕机的情况,无法支撑大规模的时序业务;而 KaiwuDB 在全规模下都保持了稳定的性能,复杂查询的时延始终可控,能够支撑超大规模的时序数据业务。
-
高并发场景:KaiwuDB 的性能衰减更小 在高并发的查询压力下,InfluxDB 的性能衰减非常明显,简单查询的时延也会出现上升,而 KaiwuDB 的性能始终保持稳定,能够支撑高并发的查询业务。
六、选型建议
基于本次的测试结果,我们可以针对不同的业务场景,给出以下中立的选型建议:
推荐选择 KaiwuDB 的场景
如果你的业务符合以下特征,KaiwuDB 会是更合适的选择:
-
海量时序数据写入:比如工业物联网、车联网、能源监测这类业务,每秒需要处理数十万甚至百万级的写入点,KaiwuDB 的高写入吞吐能够更好地支撑这类业务的压力。
-
中大规模数据 + 复杂查询:比如企业级的运维监控、AIOps 异常检测、多维度的时序数据分析,这类业务不仅数据量大,还需要大量的复杂聚合查询,KaiwuDB 的稳定查询性能能够保障业务的实时性。
-
核心业务的高可用需求:如果是核心业务系统,不能容忍查询导致的服务宕机,KaiwuDB 在高负载下的鲁棒性能够保障服务的稳定性,避免因为高负载查询导致整个服务不可用。
-
高并发查询场景:如果业务需要支撑大量的并发查询,比如多租户的监控平台,KaiwuDB 的高并发性能能够保障所有用户的查询体验。
推荐选择 InfluxDB 的场景
如果你的业务符合以下特征,InfluxDB 也可以是一个合适的选择:
-
极小数据规模的轻量业务:比如个人开发者的小型项目、非核心的轻量监控,数据量很小,查询都是简单的聚合查询,InfluxDB 的简单查询小幅优势可以得到发挥,同时部署也比较轻量。
-
非核心的临时数据统计:对于一些非核心的、对查询响应时间要求不高的临时统计业务,如果数据量不大,InfluxDB 也可以满足需求。
注意:本次测试仅针对单节点场景下的 KaiwuDB 3.1.0 与 InfluxDB v1.6.4 版本进行对比,不同版本、不同部署模式(比如分布式集群)下的性能表现可能存在差异,建议用户在选型时,结合自己的实际业务场景进行针对性的测试验证。
以上就是本次 KaiwuDB 与 InfluxDB 全场景实测对比的全部内容,如果你在项目落地、数据库选型、时序业务优化中遇到困惑,或是有不同场景的实测体验、使用心得,欢迎在评论区积极交流、一起探讨。想看其他数据库的对标测试、专属场景性能测评,欢迎随时留言交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)